使用Nodejs基于DeepSeek加chromadb实现RAG检索增强生成 本地知识库
定义
检索增强生成(RAG)的基本定义
检索增强生成(Retrieval-Augmented Generation,简称RAG)是一种结合了信息检索技术与语言生成模型的人工智能技术。RAG通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力。这种技术能够有效提升模型在问答、文本摘要、内容生成等自然语言处理任务中的表现。
RAG的工作机制
RAG的工作机制主要包括三个核心部分:检索(Retrieval)、增强(Augmentation)和生成(Generation)。
检索(Retrieval):RAG流程的第一步是从预先建立的知识库中检索与问题相关的信息。这一步骤的目的是为后续的生成过程提供有用的上下文信息和知识支撑。检索模块通常依赖于向量检索技术,将查询转换为向量表示,然后与知识库中的向量进行比对,找到最相似的内容。
增强(Augmentation):在RAG中增强是将检索到的信息用作生成模型(即大语言模型)的上下文输入,以增强模型对特定问题的理解和回答能力。这一步的目的是将外部知识融入生成过程中,使生成的文本内容更加丰富、准确和符合用户需求。
生成(Generation):生成是RAG流程的最后一步。这一步的目的是结合LLM生成符合用户需求的回答。生成器会利用检索到的信息作为上下文输入,并结合大语言模型来生成文本内容,最终输出准确、有用的回答。
实现
实现思路
文件上传 读取 语句的分割还有向量化 然后对用户的提问在向量库中进行检索
通过langchain文档工具进行文档的分割
通过chromadb进行向量转换和语义检索
其实完全可以通过python实现但是我看官方有提供的js的插件包 于是在用node写了一套 之后又用python写了一套
怎么说呢 看你喜欢用哪一种吧 反正离不开python环境
第一步安装python环境
有更多教你安装的帖子链接在下面 可以去看看
https://blog.csdn.net/qq_45502336/article/details/109531599?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522d97c47b484bd158f0638dbc85d5e8b2c%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=d97c47b484bd158f0638dbc85d5e8b2c&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-109531599-null-null.14 2
第二步安装chromadb
chromadb 官网地址
pip install chromadb然后肯定要持久化客户端运行
官网有几种启动方式 既然我们要用node实现 那其他的都不用看了 cmd 命令行启动客户端
搞个空的文件夹就行 (注意 安装完环境之后 把py环境变量搞上 要不然可能chroma run 无法运行)
chroma run --path C:\Users\Administrator\Desktop\database# 本地数据库地址
注意 这里有坑 因为我用的win系统 chroma-hnswlib 最新版本有问题所以每个集合只能插入99条坑爹 然后客户端莫名就报错崩溃
我以为是官方提供的node包有问题 后来我用python实现了一遍 不报错但就是插不进去🙂 一查只有99条
所以在启动之前把chroma-hnswlib版本降下来!!! 可能会有提示版本不兼容 无需理会
pip install chroma-hnswlib==0.7.3 -i https://pypi.tuna.tsinghua.edu.cn/simple看一下版本降下来没有
pip show chroma-hnswlib开始安装node插件包
安装chromadb 和 chromadb-default-embed
npm install --save chromadb chromadb-default-embed插入示例
import { ChromaClient } from "chromadb";
//path 是chroma启动的客户端地址默认是8000
const client = new ChromaClient({path: "http://localhost:8000"});
//name 是集合名 getOrCreateCollection 查询集合没有就创建集合
const collection = await client.getOrCreateCollection({ name: "test-8" });
//根据id进行更新插入 有就更新没有就添加 这里如果说没有对 chroma-hnswlib进行降级每个集合插入99条之后客户端就会崩溃
await collection.upsert({ids: ["id1", "id2", "id3"], metadatas: [ { chapter: "3", verse: "16" },{ chapter: "3", verse: "5" },{ chapter: "29", verse: "11" },],documents: ["i am ggbond", "she is cat", "he is dog"],
});查询示例
当然还有其他查询参数可以查看官网
await collection.query({queryTexts: ["Who is a dog"],nResults: 10, //返回前10条
})然后就可以拿着这些数据作为提示词给DeepSeek做参考回答用户问题了
以上示例是最基础的默认的embeddings模型是 all-MiniLM-L6-v2 所以不用传embeddings也是可以的虽然说可能对中文的调教不是很好 当然也可以自定义embeddings模型 下面有示例
综合示例 结合 langchain 文件分割插入数据库
我这里用了langchain提供的包方便一些
文档地址 langchainChroma
npm i langchain @langchain/community @langchain/core chromadb pdf-parse const { Chroma } = require("@langchain/community/vectorstores/chroma");
const { HuggingFaceTransformersEmbeddings } = require("@langchain/community/embeddings/huggingface_transformers");
const { PDFLoader } = require("@langchain/community/document_loaders/fs/pdf");
const { TextLoader } = require("langchain/document_loaders/fs/text");
const { DocxLoader } = require("@langchain/community/document_loaders/fs/docx");
const { EPubLoader } = require("@langchain/community/document_loaders/fs/epub");
const { RecursiveCharacterTextSplitter } = require("langchain/text_splitter");
//加载模型 其实不用这一步也可以 有默认的模型的 主要是提示一下可以通过model使用自定义模型
const allMiniLML6V2 = new HuggingFaceTransformersEmbeddings({model: "Xenova/all-MiniLM-L6-v2",
});
//文档分割
async function documentReading(filepath, filename) {let mimeType = filepath.split(".")[1];console.log("文件类型", mimeType);//加载分块const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500, //500字符一分割 这个参数可能影响最终查询的质量 根据自己实际情况来});// 加载const loader = this.documentClassification(filepath, mimeType);console.log("文档读取");const docs = await loader.load();// 分割const splitterDocs = await splitter.splitDocuments(docs);console.log(splitterDocs, "文档分割完成");return { splitterDocs };
}
//文件分类加载
function documentClassification(filepath, mimeType) {if (!filepath) throw new Error(`路径出现问题:${filepath}`);let loader = null;switch (mimeType) {case "pdf":loader = new PDFLoader(filepath);break;case "epub":loader = new EPubLoader(filepath);break;case "txt":loader = new TextLoader(filepath);break;case "docx":loader = new DocxLoader(filepath);break;default:break;}if (!loader) throw new Error(`无法解析的类型:${mimeType}`);return loader;
}
// 查询
async function query(collectionName, queryText) {const vectorStore = new Chroma(allMiniLML6V2, {url: "http://localhost:8000", //客户端地址collectionName, // 注意 集合名 一般都是文件名的英文 filename 我这里随便写的});return await vectorStore.similaritySearch(queryText, 2);
}
// 上传示例
documentReading(filepath, filename).then(({ splitterDocs }) => {const vectorStore = new Chroma(allMiniLML6V2, {url: "http://localhost:8000", //客户端地址collectionName: "test", // 注意 集合名 一般都是文件名的英文 filename 我这里随便写的});//二次分割 文件比较大的话插入会很卡const chunkSize = 20;const chunkedDocs = Array.from({length: Math.ceil(splitterDocs.length / chunkSize),},(_, index) => splitterDocs.slice(index * chunkSize, (index + 1) * chunkSize));// 开始插入chunkedDocs.forEach(async (docs, index) => {await vectorStore.addDocuments(docs).then((res) => {console.log(index, "插入成功");}).catch((err) => {console.log(index, "插入失败");});});
});
补充关于自定义模型
const allMiniLML6V2 = new HuggingFaceTransformersEmbeddings({ model: "Xenova/all-MiniLM-L6-v2", });再进行这一步的时候可能因为下载的地址在国内访问会导致很慢
可以在node_models 下 @xenova/transformers/src/env 文件下remoteHost 地址更换为国内镜像地址 https://hf-mirror.com/
或则直接在.cache文件下加你下好的模型 Xenova/all-MiniLM-L6-v2 就是 .cache/Xenova/all-MiniLM-L6-v2

结束
剩下和DeepSeek对接需要根据每个人的项目来
chromadb只能作为检索工具来作为提示词为AI提供额外的定制化数据 来增强 AI
相关文章:
使用Nodejs基于DeepSeek加chromadb实现RAG检索增强生成 本地知识库
定义 检索增强生成(RAG)的基本定义 检索增强生成(Retrieval-Augmented Generation,简称RAG)是一种结合了信息检索技术与语言生成模型的人工智能技术。RAG通过从外部知识库中检索相关信息,并将其作为提示&…...

笔试刷题专题(一)
文章目录 最小花费爬楼梯(动态规划)题解代码 数组中两个字符串的最小距离(贪心(dp))题解代码 点击消除题解代码 最小花费爬楼梯(动态规划) 题目链接 题解 1. 状态表示࿱…...

LeetCode977有序数组的平方
思路①:先平方,后快排,输出(基准元素,左小右大) 时间复杂度:O(nlogn) 思路②:双指针左右开弓,首先原数组已经是按照非递减顺序排序,那…...

React.js 基础与进阶教程
React.js 基础与进阶教程 React.js 是由 Facebook 开发的流行前端 JavaScript 库,专为构建用户界面(UI)设计,尤其适用于单页面应用(SPA)。它采用组件化开发模式,使 UI 结构更加清晰、可维护性更…...

网络变压器的主要电性参数与测试方法(4)
Hqst盈盛(华强盛)电子导读:网络变压器的主要电性参数与测试方法(4).. 今天我们继续来看看网络变压器的2个重要电性参数与它的测试方法: 1.反射损耗(Return loss&…...
)
【实战ES】实战 Elasticsearch:快速上手与深度实践-8.1.1基于ES的语义搜索(BERT嵌入向量)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 基于Elasticsearch与BERT的语义搜索架构设计与实战1. 传统搜索的局限性与语义搜索的崛起1.1 关键词搜索 vs 语义搜索1.2 Elasticsearch向量检索演进历程关键版本特性对比 2.…...

Windows10 WSL又又又一次崩了 Docker Desktop - Unexpected WSL error
问题:Windows10 WSL又又又一次崩了 这回报错: 然后再打开WSL Ubuntu就卡住了,等很长时间没反应,就关掉了。 手动启动Docker Desktop,报错: An unexpected error occurred while executing a WSL comman…...
和XML之间的关系)
XMI(XML Metadata Interchange)和XML之间的关系
XMI(XML Metadata Interchange)和XML之间的关系可以从以下几个方面进行阐述: 一、定义与背景 XML: XML(eXtensible Markup Language)是一种标记语言,被设计用来传输和存储数据。它是一种自描述…...

《深度剖析:鸿蒙系统下智能NPC与游戏剧情的深度融合》
在游戏开发领域,鸿蒙系统的崛起为开发者们带来了前所未有的机遇与挑战。尤其是在开发基于鸿蒙系统的人工智能游戏时,实现智能NPC的行为逻辑与游戏剧情紧密结合,成为了打造沉浸式游戏体验的关键。 鸿蒙系统作为一款面向全场景的分布式操作系统…...

【前端基础】:HTML
超链接标签: a href: 必须具备, 表示点击后会跳转到哪个页面. target: 打开方式. 默认是 _self. 如果是 _blank 则用新的标签页打开 <a href"http://www.baidu.com">百度</a>链接的几种形式: 外部链接: href 引用其他网站的地址 <a href"http…...

JVM垃圾收集器合集
前言:JVM GC收集器的回顾与比较 JVM(Java虚拟机)中的垃圾收集器是自动管理内存的重要机制,旨在回收不再使用的对象所占用的内存空间。以下是JVM中几种常见的垃圾收集器的详细介绍: 一、新生代垃圾收集器 1.Serial收集…...

Sourcetree——使用.gitignore忽略文件或者文件夹
一、为何需要文件忽略机制? 1.1 为什么要会略? 对于开发者而言,明智地选择忽略某些文件类型,能带来三大核心优势: 仓库纯净性:避免二进制文件、编译产物等污染代码库 安全防护:防止敏感信息&…...
)
unity使用mesh 画图(1)
plane 圆 空心椭圆 椭圆 using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEngine.UI;public class DrawMeshManager {static DrawMeshManager instance;public static DrawMeshManager Instance {get {if (instance ! null){retu…...

本地部署 OpenManus 保姆级教程(Windows 版)
一、环境搭建 我的电脑是Windows 10版本,其他的没尝试,如果大家系统和我的不一致,请自行判断,基本上没什么大的出入啊。 openManus的Git地址:https://github.com/mannaandpoem/OpenManus 根据官网的两种安装推荐方式如…...

视频推拉流:EasyDSS平台直播通道重连转推失败原因排查与解决
视频推拉流EasyDSS视频直播点播平台,集视频直播、点播、转码、管理、录像、检索、时移回看等功能于一体,可提供音视频采集、视频推拉流、播放H.265编码视频、存储、分发等视频能力服务。 用户使用EasyDSS平台对直播通道进行转推,发现只要关闭…...

机器人领域专业名词汇总
1. 电机与驱动 电机类型 DC Motor(直流电机):通过直流电源驱动的电机。Stepper Motor(步进电机):通过脉冲信号控制旋转角度的电机。Servo Motor(伺服电机):带有反馈控制的…...

成为超人 21:超人怎么学?技能的学习,如编程
成为超人 21:超人怎么学?技能的学习,如编程 ① 搞定全能自恋② 超人怎么学?③ 耐心怎么来? 宇树机器人王兴兴:奇迹也有算法,做成事没有那么难,就是把不可能三个字,拆解成…...

【科研绘图系列】python绘制分组点图(grouped dot plot)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载导入数据函数`generateRectBoxDF` 函数主要作用参数解释逻辑流程`nmfDotPlot` 函数主要作用参数解释逻辑流程画图1画图2画图3画图4介绍 【科研绘图系列】python绘制…...

Springfox、Springdoc和Swagger
Springfox、Swagger 和 Springdoc Springfox、Swagger 和 Springdoc 是用于在 Spring Boot 项目中生成API文档的工具,但它们之间有显著的区别和演进关系: 1.Swagger 简介 Swagger 是一个开源项目,旨在为 RESTful APIs 提供交互式文档。最…...

在Spring Boot项目中如何实现获取FTP远端目录结构
Java语言实现获取FTP远端目录结构的实现方式有多种,在Spring Boot 项目中,最简单和快速的方式就是使用Spring Integration 实现FTP相关的功能。 前言 本篇的示例和演示基于Windows 的FTP 服务,关于如何在Windows 开启FTP服务可以参考: Windows 如何开启和使用FTP服务 本…...

Flutter_学习记录_device_info_plus 插件获取设备信息
引入三方库device_info_plus导入头文件 import package:device_info_plus/device_info_plus.dart;获取设备信息的主要代码 DeviceInfoPlugin deviceInfoPlugin DeviceInfoPlugin(); BaseDeviceInfo deviceInfo await deviceInfoPlugin.deviceInfo;完整案例 import package…...

Java高频面试之集合-10
hello啊,各位观众姥爷们!!!本baby今天来报道了!哈哈哈哈哈嗝🐶 面试官:详解红黑树?HashMap为什么不用二叉树/平衡树呢? 一、红黑树(Red-Black Treeÿ…...

never_give_up
一个很有意思的题: never_give_up - Bugku CTF平台 注意到注释里面有1p.html,我们直接在源代码界面看,这样就不会跳转到它那个链接的: 然后解码可得: ";if(!$_GET[id]) {header(Location: hello.php?id1);exi…...
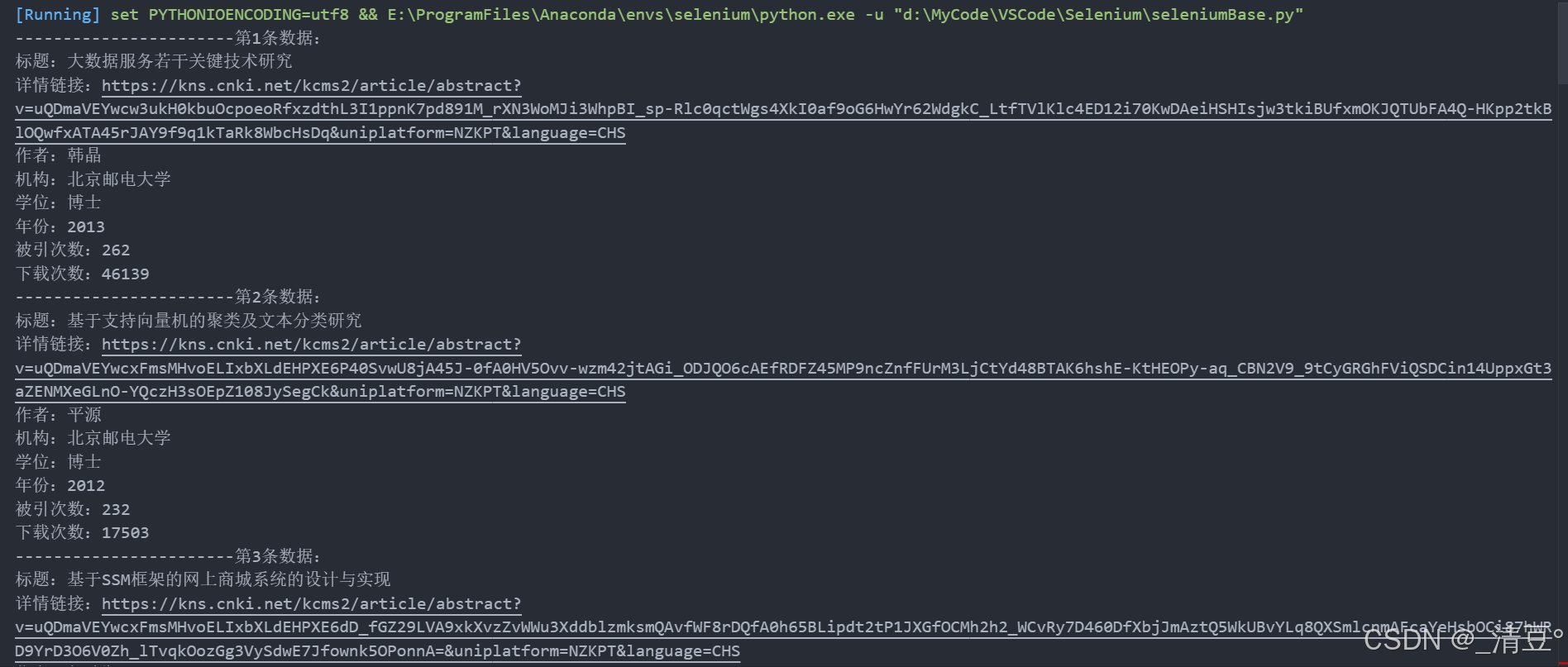
Python Selenium库入门使用,图文详细。附网页爬虫、web自动化操作等实战操作。
文章目录 前言1 创建conda环境安装Selenium库2 浏览器驱动下载(以Chrome和Edge为例)3 基础使用(以Chrome为例演示)3.1 与浏览器相关的操作3.1.1 打开/关闭浏览器3.1.2 访问指定域名的网页3.1.3 控制浏览器的窗口大小3.1.4 前进/后…...

聊天室Python脚本——ChatGPT,好用
下面提供两个 Python 脚本,一个作为服务器端(chat_server.py),一个作为客户端(chat_client.py)。你可以在一台电脑上运行服务器脚本,然后在不同电脑上运行客户端脚本(连接时指定服务…...

AI4CODE】3 Trae 锤一个贪吃蛇的小游戏
【AI4CODE】目录 【AI4CODE】1 Trae CN 锥安装配置与迁移 【AI4CODE】2 Trae 锤一个 To-Do-List 这次还是采用 HTML/CSS/JAVASCRIPT 技术栈 Trae 锤一个贪吃蛇的小游戏。 1 环境准备 创建一个 Snake 的子文件夹,清除以前的会话记录。 2 开始构建 2.1 输入会…...
)
【语料数据爬虫】Python爬虫|批量采集会议纪要数据(1)
前言 本文是该专栏的第2篇,后面会持续分享Python爬虫采集各种语料数据的的干货知识,值得关注。 在本文中,笔者将主要来介绍基于Python,来实现批量采集“会议纪要”数据。同时,本文也是采集“会议纪要”数据系列的第1篇。 采集相关数据的具体细节部分以及详细思路逻辑,笔…...

Linux 进程的一生(一):进程与线程的创建机制解析
在 Linux 操作系统中,每个任务都以「进程」的形式存在。但 Linux 下的「线程」又是什么?Linux 并没有单独定义一种全新数据结构来表示线程,而是将线程视为一种特殊的进程——一种共享资源的轻量级进程。然而,在具体实现和运行机制…...

【面试题集合】
目录 强缓存VS协商缓存**一、强缓存(本地缓存)**1. **定义**2. **核心 HTTP 头**3. **缓存生效流程**4. **应用场景** **二、协商缓存(条件请求)**1. **定义**2. **核心 HTTP 头**3. **缓存生效流程**4. **应用场景** **三、强缓存…...

【Academy】SSRF ------ Server-side request forgery
SSRF ------ Server-side request forgery 1. 什么是 SSRF?2. SSRF 攻击的影响是什么?3. 常见的 SSRF 攻击3.1 针对服务器的 SSRF 攻击3.2 针对其他后端系统的 SSRF 攻击 4. 规避常见的 SSRF 防御4.1 具有基于黑名单的输入过滤器的 SSRF4.2 具有基于白名…...