JVM 垃圾回收器的选择
一:jvm性能指标吞吐量以及用户停顿时间解释。
二:垃圾回收器的选择。
三:垃圾回收器在jvm中的配置。
四:jvm中常用的gc算法。
一:jvm性能指标吞吐量以及用户停顿时间解释。
在 JVM 调优和垃圾回收器选择中,吞吐量(Throughput) 和 用户停顿时间(Pause Time) 是两个非常重要的性能指标。它们分别反映了垃圾回收器在处理垃圾回收任务时对应用程序性能的影响。以下是对这两个概念的详细解释:
1. 吞吐量(Throughput)
含义:吞吐量是指应用程序在运行过程中,实际执行业务逻辑的时间与总运行时间的比值。它反映了应用程序在垃圾回收期间的效率。
计算公式:

- 高吞吐量:表示应用程序在大部分时间内都在执行业务逻辑,垃圾回收所占用的时间较少。这种情况下,应用程序的性能较高,适合对性能要求较高的场景。
- 低吞吐量:表示垃圾回收占用的时间较多,应用程序的实际运行时间较短。这种情况下,应用程序的性能会受到较大影响。
应用场景:
- 如果你的应用程序对性能要求较高,且用户对停顿时间不太敏感(例如后台数据处理任务),则应优先选择高吞吐量的垃圾回收器。
2. 用户停顿时间(Pause Time)
含义:用户停顿时间是指垃圾回收器在回收内存时,导致应用程序线程暂停的时间。垃圾回收器在执行某些操作(如 Full GC 或 Major GC)时,会暂停应用程序的执行,这种暂停被称为 Stop-The-World (STW)。
特点:
- 短停顿时间:表示垃圾回收器在执行回收任务时,对应用程序的暂停时间较短。这种情况下,用户体验较好,适合对响应时间敏感的应用。
- 长停顿时间:表示垃圾回收器在执行回收任务时,暂停应用程序的时间较长。这种情况下,用户体验可能会受到影响。
应用场景:
- 如果你的应用程序对响应时间要求较高(例如在线交易系统、实时交互系统),则应优先选择低停顿时间的垃圾回收器。
二:垃圾回收器的选择
根据吞吐量和停顿时间的需求,可以选择不同的垃圾回收器:
1 Serial 垃圾收集器
- 特点:单线程执行垃圾回收,停顿时间较短,但吞吐量较低。
- 适用场景:适用于单核 CPU 或对吞吐量要求不高的场景。
2 Parallel Scavenge + Parallel Old 组合(JDK8默认)
- 特点:多线程执行垃圾回收,吞吐量较高,但停顿时间可能较长。
- 适用场景:适用于多核 CPU,且对吞吐量要求较高的场景(如后台数据处理)。
3 ParNew + CMS 组合
- 特点:多线程执行垃圾回收,停顿时间较短,但吞吐量较低。
- 适用场景:适用于多核 CPU,且对停顿时间要求较高的场景(如在线交易系统)。
4 G1 垃圾收集器
- 特点:分代收集与并发收集结合,停顿时间可控,吞吐量也较高。
- 适用场景:适用于多核 CPU,且对停顿时间和吞吐量都有较高要求的场景(如大型企业级应用)。
5. 总结
- 吞吐量:反映应用程序在垃圾回收期间的实际运行效率,适合对性能要求较高的场景。
- 用户停顿时间:反映垃圾回收对应用程序的暂停时间,适合对响应时间敏感的场景。
- 垃圾回收器选择:根据应用程序的需求(吞吐量或停顿时间优先)和硬件环境(CPU 核数)选择合适的垃圾回收器。
在实际调优中,需要根据具体的应用场景和性能要求,综合考虑吞吐量和停顿时间的平衡。
三:垃圾回收器在jvm中的配置。
在 Java 应用程序中,配置垃圾回收器及其相关参数是 JVM 调优的重要部分。以下是如何配置不同垃圾回收器及其常用参数的详细说明:
1. 配置垃圾回收器
垃圾回收器的选择和配置通过 JVM 启动参数完成。以下是一些常见垃圾回收器的配置方法:
1.1 Serial 垃圾收集器
适用于单核 CPU 或小型应用,吞吐量较低,但停顿时间较短。
-XX:+UseSerialGC
1.2 Parallel Scavenge + Parallel Old 组合
适用于多核 CPU,吞吐量较高,适合对吞吐量要求较高的场景。
-XX:+UseParallelGC # 新生代使用 Parallel Scavenge
-XX:+UseParallelOldGC # 老年代使用 Parallel Old
1.3 ParNew + CMS 组合
适用于多核 CPU,停顿时间较短,适合对响应时间敏感的场景。
-XX:+UseParNewGC # 新生代使用 ParNew
-XX:+UseConcMarkSweepGC # 老年代使用 CMS
1.4 G1 垃圾收集器
适用于多核 CPU,兼顾吞吐量和停顿时间,适合大堆内存(6GB 以上)的场景。
-XX:+UseG1GC
1.5 ZGC 或 Shenandoah
适用于超大堆内存(TB 级别)和低延迟需求的场景。
-XX:+UseZGC # 使用 ZGC
# 或
-XX:+UseShenandoahGC # 使用 Shenandoah
2. 常用垃圾回收器参数配置
2.1 调整堆内存大小
- 初始堆大小(
-Xms):设置 JVM 启动时的堆大小。 - 最大堆大小(
-Xmx):设置 JVM 允许的最大堆大小。 - 新生代大小(
-Xmn):设置新生代的大小。
-Xms1024m -Xmx1024m -Xmn256m
2.2 调整新生代和老年代比例
-XX:NewRatio:设置新生代与老年代的比例(默认值为 2)。-XX:SurvivorRatio:设置伊甸园与幸存区的比例(默认值为 8)。
-XX:NewRatio=4 //表示新生代:老年代 = 1:4 即老年代占整个堆的4/5;默认值=2
-XX:SurvivorRatio=8 //伊甸园:幸存区=8:2-XX:NewRatio=12 //表示新生代与老年代的比例为 1:12
-XX:SurvivorRatio=11 //表示伊甸园与每个幸存区的比例为 11:1
2.3 调整垃圾回收目标
-XX:MaxGCPauseMillis:设置垃圾回收的最大停顿时间目标(单位为毫秒)。-XX:GCTimeRatio:设置垃圾回收的吞吐量目标(默认值为 99,表示吞吐量为 99%)。
-XX:MaxGCPauseMillis=100 -XX:GCTimeRatio=99
2.4 调整老年代回收策略
-
CMS 回收器:
-XX:CMSInitiatingOccupancyFraction:设置老年代占用比例达到多少时触发 CMS 回收(默认值为 68%)。
-XX:CMSInitiatingOccupancyFraction=70 -
G1 回收器:
-XX:InitiatingHeapOccupancyPercent:设置堆占用比例达到多少时触发混合垃圾回收(默认值为 45%)。-XX:G1MixedGCLiveThresholdPercent:设置对象存活比例达到多少时触发混合垃圾回收(默认值为 85%)。
-XX:InitiatingHeapOccupancyPercent=50 -XX:G1MixedGCLiveThresholdPercent=70
2.5 调整大对象处理
-XX:PretenureSizeThreshold:设置大对象直接进入老年代的阈值(单位为字节,默认为 0,表示关闭)。-XX:MaxTenuringThreshold:设置对象晋升到老年代的最大年龄(默认值为 15)。
-XX:PretenureSizeThreshold=1048576 -XX:MaxTenuringThreshold=7
2.6 其他参数
-XX:+PrintGCDetails:打印详细的垃圾回收日志。-XX:+PrintGCDateStamps:打印垃圾回收的时间戳。-Xlog:gc*:将垃圾回收日志输出到指定文件。
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xlog:gc*:gc.log
3. 示例配置
以下是一个完整的 JVM 参数配置示例,适用于多核 CPU 和对停顿时间要求较高的场景:
-Xms1024m -Xmx1024m -Xmn256m -XX:SurvivorRatio=8 -XX:NewRatio=4
-XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:GCTimeRatio=99
-XX:InitiatingHeapOccupancyPercent=50 -XX:G1MixedGCLiveThresholdPercent=70
-XX:PretenureSizeThreshold=1048576 -XX:MaxTenuringThreshold=7
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xlog:gc*:gc.log
4. 总结
- 根据应用需求选择合适的垃圾回收器。
- 使用 JVM 参数调整垃圾回收器的行为,包括堆内存大小、新生代和老年代比例、停顿时间目标等。
- 使用垃圾回收日志监控和分析垃圾回收行为,根据实际情况调整参数。
通过合理的配置,可以显著提升应用程序的性能和响应能力。
四:jvm中常用的gc算法
在 Java 中,垃圾回收(GC)主要通过以下四种算法实现:标记-清除、复制、标记-整理和分代收集。以下是这些算法的详细解释:
1. 标记-清除算法(Mark-Sweep)
原理:
- 标记阶段:从根对象(如全局变量、栈中的对象)出发,遍历所有可达对象,并标记它们为存活。
- 清除阶段:遍历整个堆内存,释放未被标记的对象所占用的内存。
优点:
- 实现简单,适用于大多数场景。
缺点:
- 会产生内存碎片,可能导致后续内存分配效率降低。
- 每次清除都需要扫描整个堆,效率较低。
适用场景:
- 主要用于老年代(如 CMS 收集器)。
2. 复制算法(Copying)
原理:
- 将存活对象从“From”区复制到“To”区,然后清空“From”区。
- 新生代通常分为 Eden 区和两个 Survivor 区(S0 和 S1),当 Eden 区满时,将存活对象复制到其中一个 Survivor 区。
优点:
- 无内存碎片,内存分配高效。
缺点:
- 内存利用率低,仅使用一半的内存。
适用场景:
- 主要用于新生代(如 Serial、ParNew 收集器)。
3. 标记-整理算法(Mark-Compact)
原理:
- 标记阶段:标记所有可达对象。
- 整理阶段:将存活对象移动到堆的一端,清理边界外的空间。
优点:
- 无内存碎片,内存利用率高。
缺点:
- 移动对象成本高,可能导致较长的停顿时间。
适用场景:
- 主要用于老年代(如 Parallel Old、G1 收集器)。
4. 分代收集算法(Generational Collection)
原理:
- 将堆内存分为新生代和老年代。
- 新生代:使用复制算法,因为大多数对象生命周期短。
- 老年代:使用标记-清除或标记-整理算法,因为对象生命周期长。
优点:
- 针对不同生命周期的对象采用不同的回收策略,提高了回收效率。
缺点:
- 实现复杂,需要维护多个代的内存区域。
适用场景:
- 现代 JVM 通常采用分代收集算法,适用于大多数应用场景。
5. 引用计数算法(Reference Counting)
原理:为每个对象维护一个引用计数器,记录该对象被引用的次数。当引用计数器的值为零时,表示该对象不再被任何变量引用,可以被垃圾回收。
优缺点及适用场景
引用计数法:通过维护引用计数器来管理对象的生命周期,优点是简单高效,缺点是无法处理循环引用,且性能开销较大。
适用场景:适用于简单场景和对停顿时间要求极高的实时系统。
在 Java 中:适用于简单场景,实时系统或混合使用。引用计数法不是主流垃圾回收算法,但它的原理有助于理解垃圾回收机制。
总结
- 标记-清除算法:简单但会产生内存碎片,适用于老年代。
- 复制算法:高效但内存利用率低,适用于新生代。
- 标记-整理算法:无碎片但停顿时间长,适用于老年代。
- 分代收集算法:综合多种算法,兼顾效率和内存利用率,是现代 JVM 的主流策略。
- 引用计数法:不是主流垃圾回收算法,但它的原理有助于理解垃圾回收机制
相关文章:
JVM 垃圾回收器的选择
一:jvm性能指标吞吐量以及用户停顿时间解释。 二:垃圾回收器的选择。 三:垃圾回收器在jvm中的配置。 四:jvm中常用的gc算法。 一:jvm性能指标吞吐量以及用户停顿时间解释。 在 JVM 调优和垃圾回收器选择中࿰…...

使用GPTQ量化Llama-3-8B大模型
使用GPTQ量化8B生成式语言模型 服务器配置:4*3090 描述:使用四张3090,分别进行单卡量化,多卡量化。并使用SGLang部署量化后的模型,使用GPTQ量化 原来的模型精度为FP16,量化为4bit 首先下载gptqmodel量化…...

2025-03-16 学习记录--C/C++-PTA 习题4-2 求幂级数展开的部分和
合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。💪🏻 一、题目描述 ⭐️ 习题4-2 求幂级数展开的部分和 已知函数e^x可以展开为幂级数1xx^2/2!x^3/3!⋯x^k/k!⋯。现给定一个实数x&a…...

【C#】Http请求设置接收不安全的证书
在进行HTTP请求时,出现以下报错,可设置接收不安全证书跳过证书验证,建议仅测试环境设置,生产环境可能会造成系统漏洞 /// <summary> /// HttpGet请求方法 /// </summary> /// <param name"requestUrl"&…...

从PDF文件中提取数据
笔记 import pdfplumber # 打开PDF文件 with pdfplumber.open(数学公式.pdf) as pdf:for i in pdf.pages: # 遍历页print(i.extract_text()) # extract_text()方法提取内容print(f---------第{i.page_number}页结束---------)...

【k8s001】K8s架构浅析
Kubernetes 架构浅析 #mermaid-svg-irCZnQUuietSX3Ro {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-irCZnQUuietSX3Ro .error-icon{fill:#552222;}#mermaid-svg-irCZnQUuietSX3Ro .error-text{fill:#552222;stroke…...

NPU、边缘计算与算力都是什么啊?
考虑到灵活性和经济性,公司购置一台边缘计算机,正在尝试将PCGPU的计算机视觉项目转到边缘计算机NPU上。本文简单整理了三个概念,并试图将其做个概要的说明。 一、算力:数字世界的“基础能源” 1.1 算力是什么 **算力(…...
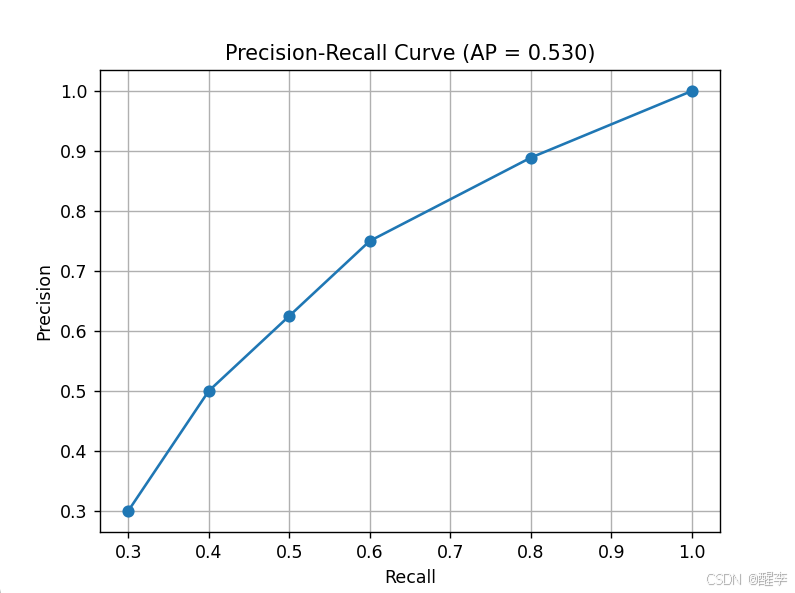
AP AR
混淆矩阵 真实值正例真实值负例预测值正例TPFP预测值负例FNTN (根据阈值预测) P精确度计算:TP/(TPFP) R召回率计算:TP/(TPFN) AP 综合考虑P R 根据不同的阈值计算出不同的PR组合, 画出PR曲线,计算曲线…...
Leetcode-1278.Palindrome Partitioning III [C++][Java]
目录 一、题目描述 二、解题思路 【C】 【Java】 Leetcode-1278.Palindrome Partitioning IIIhttps://leetcode.com/problems/palindrome-partitioning-iii/description/1278. 分割回文串 III - 力扣(LeetCode)1278. 分割回文串 III - 给你一个由小写…...

Java集合 - ArrayList
ArrayList 是 Java 集合框架中最常用的动态数组实现类,位于 java.util 包中。它基于数组实现,支持动态扩容和随机访问。 1. 特点 动态数组:ArrayList 的底层是一个数组,可以根据需要动态扩展容量。 有序:元素按照插入…...

C++特性——智能指针
为什么需要智能指针 对于定义的局部变量,当作用域结束之后,就会自动回收,这没有什么问题。 当时用new delete的时候,就是动态分配对象的时候,如果new了一个变量,但却没有delete,这会造成内存泄…...

ctf web入门知识合集
文章目录 01做题思路02信息泄露及利用robots.txt.git文件泄露dirsearch ctfshow做题记录信息搜集web1web2web3web4web5web6web7web8SVN泄露与 Git泄露的区别web9web10 php的基础概念php的基础语法1. PHP 基本语法结构2. PHP 变量3.输出数据4.数组5.超全局变量6.文件操作 php的命…...

DeepSeek:技术教育领域的AI变革者——从理论到实践的全面解析
一、技术教育为何需要DeepSeek? 在数字化转型的浪潮下,技术教育面临着知识更新快、实践门槛高、个性化需求强三大核心挑战。传统的教学模式难以满足开发者快速掌握前沿技术、构建复杂系统能力的需求。DeepSeek作为国产开源大模型的代表,凭借…...

MySQL-存储过程和自定义函数
存储过程 存储过程,一组预编译的 SQL 语句和流程控制语句,被命名并存储在数据库中。存储过程可以用来封装复杂的数据库操作逻辑,并在需要时进行调用。 使用存储过程 创建存储过程 create procedure 存储过程名() begin存储过程的逻辑代码&…...

图——表示与遍历
图的两种主要表示方法 图有两种常用的表示方法,一种是邻接表法(adjacency-list),另一种是邻接矩阵法(adjacency-matrix)。 邻接表法储存数据更紧凑,适合稀疏的图(sparse graphs&am…...

新手村:数据预处理-异常值检测方法
机器学习中异常值检测方法 一、前置条件 知识领域要求编程基础Python基础(变量、循环、函数)、Jupyter Notebook或PyCharm使用。统计学基础理解均值、中位数、标准差、四分位数、正态分布、Z-score等概念。机器学习基础熟悉监督/无监督学习、分类、聚类…...
测试与系统化整改)
电磁兼容性|电子设备(EMC)测试与系统化整改
在现代电子工程领域,5G通信、物联网与人工智能技术深度融合,电磁兼容性(EMC)已成为衡量设备可靠性的关键指标。据国际电磁兼容协会(IEEE EMC Society)2024年度报告显示,全球因EMC问题导致的电子…...

联合体定义与应用
引言 讲到了结构体,那同时类似的结构就还有联合体,本文就将详解介绍联合体。 在C语言中,联合体(union)是一种特殊的数据结构,它与结构体(struct)相似,但有一个显著的不同:联合体的所有成员共用同一块内存空间。这意味着在任何时候,联合体中只能有一个成员保存有效数…...

ChatGPT-4
第一章:ChatGPT-4的技术背景与核心架构 1.1 生成式AI的发展脉络 生成式人工智能(Generative AI)的演进历程可追溯至20世纪50年代的早期自然语言处理研究。从基于规则的ELIZA系统到统计语言模型,再到深度学习的革命性突破&#x…...

C语言_数据结构总结9:树的基础知识介绍
1. 树的基本术语 - 祖先:考虑结点K,从根A到结点K的唯一路径上的所有其它结点,称为结点K的祖先。 - 子孙:结点B是结点K的祖先,结点K是B的子孙。结点B的子孙包括:E,F,K,L。 - 双亲:路径上…...

基于ydoVr算法的车辆智能防盗系统的设计与实现
标题:基于ydoVr算法的车辆智能防盗系统的设计与实现 内容:1.摘要 随着汽车保有量的不断增加,车辆被盗问题日益严重,给车主带来了巨大的经济损失。为解决这一问题,本文旨在设计并实现基于ydoVr算法的车辆智能防盗系统。该系统综合运用传感器技…...

Python学习第十八天
Django模型 定义:模型是 Django 中用于定义数据库结构的 Python 类。每个模型类对应数据库中的一张表,类的属性对应表的字段。 作用:通过模型,Django 可以将 Python 代码与数据库表结构关联起来,开发者无需直接编写 S…...

蓝桥杯备考:图论之Prim算法
嗯。通过我们前面的学习,我们知道了,一个具有n个顶点的连通图,它的生成树包括n-1个边,如果边多一条就会变成图,少一条就不连通了 接下来我们来学一下把图变成生成树的一个算法 Prim算法,我们从任意一个结…...

min_element用法
查找字典中的最小value值 auto max_it std::min_element(my_map.begin(), my_map.end(),[](const auto& a, const auto& b) {return a.second < b.second; // 查找最小值});其中,这是一个查找最小值的自定义函数 [](const auto& a, const auto&am…...

列表动态列处理
1、在initialize()方法里,获取列表控件,添加CreateListColumnsListener监听 public void initialize(){ BillList billlist(BillList)this.getControl("billlistap"); billlist.addCreateListColumnsListener(this::beforeCreateListColumns)…...

科普:WOE编码与One-Hot编码
WOE编码是业务逻辑与统计建模的结合,适合强业务导向的场景; One-Hot编码是数据驱动的特征工程,适合追求模型性能的场景。 编码方式核心价值典型案例WOE编码保留变量预测能力,适配线性模型银行违约预测逻辑回归One-Hot编码释放特征…...

【Go语言圣经2.6】
目标 概念 GOPATH模型 GOPATH:GOPATH 是一个环境变量,指明 Go 代码的工作区路径。工作区通常包含三个目录: src:存放源代码,按照导入路径组织。例如,包 gopl.io/ch2/tempconv 应存放在 $GOPATH/src/gopl.i…...

Python的基本知识
Python是一种广泛使用的高级编程语言,以下是其基本用法的介绍: 变量与数据类型 - 变量定义:直接赋值即可创建变量,如 x 5 , name "John" 。 - 数据类型:包括 int (整数…...
)
QEMU源码全解析 —— 块设备虚拟化(4)
接前一篇文章:QEMU源码全解析 —— 块设备虚拟化(3) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM源码解析与应用》 —— 李强,机械工业出版社 类模板是创建类的模式_创建类是的模版-CSDN博客<...

34个适合机械工程及自动化专业【论文选题】
论文选题具有极其重要的意义,它直接关系到论文的质量、价值以及研究的可行性和顺利程度。选题明确了研究的具体领域和核心问题,就像给研究旅程设定了方向和目的地。例如,选择 “人工智能在医疗影像诊断中的应用” 这一选题,就确定…...