向量数据库技术系列四-FAISS介绍
一、前言
FAISS(Facebook AI Similarity Search)是由Facebook AI Research开发的一个开源库,主要用于高效地进行大规模相似性搜索和聚类操作。主要功能如下:
-
向量索引与搜索:FAISS提供了多种索引和搜索向量的方法,包括暴力搜索(Flat)、倒排索引(IVF)、分层可导航小世界图(HNSW)和乘积量化(PQ)等。这些方法可以根据应用场景在速度、准确性和内存使用之间进行权衡。
-
支持多种距离度量:FAISS支持多种距离度量方式,如L2距离(欧几里得距离)、余弦相似度和内积(点积),适用于不同的应用场景。
-
CPU和GPU支持:FAISS能够利用CPU和GPU加速索引和搜索过程,在大规模数据集上表现出色,尤其适合需要实时搜索的场景。
具有以下的特点:
-
高效性:FAISS针对大规模数据集进行了优化,能够快速处理数十亿向量。
-
可扩展性:FAISS设计用于处理大规模数据集,能够有效管理数十亿向量。
-
灵活性:FAISS允许用户根据应用需求调整索引和搜索参数,并且可以动态添加、更新和删除向量。
-
开源性:作为开源库,FAISS提供了广泛的定制化和集成能力。
二、基本操作
1、安装版本
faiss分为cpu和gpu两个版本,一般情况下,安装cpu版本就够用了。
# 安装CPU版本
pip install faiss-cpu# 安装GPU版本(需要CUDA支持)
pip install faiss-gpu2、导入库并设置基本参数
import faiss
import numpy as np # 〇,基本参数设置
d = 64 # 向量维度
nb = 100000 # index向量库的数据量
nq = 1000 # 待检索query的数目
index_type = 'Flat' # index 类型
metric_type = faiss.METRIC_INNER_PRODUCT # 度量(相似度/距离)类型引入numpy库是为了后续构造多维数组数据。我们先定义向量索引的主要参数,其说明如下:
- d(dimension),待构造向量的维度
- nb,待构造的向量库中的数据量。
- nq,待构造的检索向量的数据量。
- index_type,索引的类型,索引类型有很多种,可以参考这篇文章(Faiss(4):索引(Index)_faiss index-CSDN博客),主要类型如下:
1、Flat(暴力检索),该方法是Faiss所有index中最准确的,召回率最高的方法,但速度慢,占内存大,一般用于小于50万数据,且内存不紧张的场景中。
2、IVFx Flat(倒排暴力检索),通过倒排的思想,先聚类中心,通过减少搜索范围,提升搜索效率,相比Flat其速度大大提升,建议百万级向量可以使用。IVFx中的x是k-means聚类中心的个数,比如"IVF100,Flat"。
3、PQx(乘积量化),将一个向量的维度切成x段,进行检索在取交集,得出最后的Top-K,其速度很快,而且占用内存较小,召回率也相对较高。适用于内存及其稀缺,并且需要较快的检索速度,不那么在意召回率。Qx中的x为将向量切分的段数,如"PQ16"。
4、LSH(局部敏感哈希),局部敏感哈希依赖碰撞来进行分桶和聚类,聚类较近的归属同一个桶的概率很大。其index占内存很小,检索也比较快,但是召回率非常拉垮,适用于候选向量库非常大,离线检索,内存资源比较稀缺的情况。
5、HNSWx(分层导航),这是一种基于图检索的改进方法,检索速度极快,10亿级别秒出检索结果,召回率也非常惊人,但是内存占用极大,适用于于不在乎内存,并且有充裕的时间来构建index。HNSWx中的x为构建图时每个点最多连接多少个节点。
这里我们为了演示,选用简单的Flat模式。
- metric_type,相似度距离,主要有METRIC_L2(欧几里得距离,L2距离),METRIC_INNER_PRODUCT(余弦相似度)。这里我们选用余弦相似度。
3、准备向量数据构建库索引
由于FAISS没有默认的向量化模型,我们暂且直接使用向量数据来构建。首先使用numpy库创建向量数据。
# 一,准备向量库向量
print('============================== 1,base vector ==============================')
np.random.seed(1234) #设置种子
xb = np.random.random((nb, d)).astype('float32') #生成nb行,d列的数组,并转为float32类型
xb[:, 0] += np.arange(nb) / 1000. # 第一列添加唯一的偏移量
faiss.normalize_L2(xb) #对向量进行L2归一化
print('xb.shape = ',xb.shape,'\n')#============================== 1,base vector ==============================
#xb.shape = (100000, 64) 这里准备了100000行64维的向量数据。接下来就添加到库中,并构建索引。
# 二,构建向量库索引
print('============================== 2,create&train ==============================')
index = faiss.index_factory(d,index_type,metric_type) #通过ndex_factory构建索引,等价于 faiss.IndexFlatIP(d)
print('index.is_trained=',index.is_trained) # 输出为True,代表该类index不需要训练,只需要add向量进去即可
index.train(xb)
index.add(xb) # 将向量库中的向量加入到index中
print('index.ntotal=',index.ntotal,'\n') # 输出index中包含的向量总数,为100000 #============================== 2,create&train ==============================
#index.is_trained= True
#index.ntotal= 100000 4、准备查询向量数据并向量检索
有了数据后,就可以检索。这里准备10000行待检索的向量数据。
# 三,准备查询向量
print('============================== 3,query vector ==============================')
xq = np.random.random((nq, d)).astype('float32') #准备nq行,d维的查询向量数组
xq[:, 0] += np.arange(nq) / 1000. # 待检索的query向量
faiss.normalize_L2(xq)
print('xq.shape = ',xq.shape,'\n')检索并返回前5个向量的最相似结果。
# 四,相似向量查询
print('============================== 4, search ==============================')
k = 4 # topK的K值
D, I = index.search(xq, k) # xq为待检索向量,返回的I为每个待检索query最相似TopK的索引list,D为其对应的距离print('nearest vector ids:\n',I[:5],'\n')
print('metric(distances/scores) to query:\n',D[-5:],'\n')#============================== 4, search ==============================
#nearest vector ids:
# [[ 207 381 1394 1019]
# [ 300 911 142 526]
# [ 838 1541 527 148]
# [ 196 359 184 466]
# [ 526 120 917 765]]#metric(distances/scores) to query:
# [[0.87687665 0.86128217 0.85667735 0.85451 ]
# [0.870294 0.8666884 0.8593493 0.852314 ]
# [0.86291504 0.8580746 0.8538497 0.84994483]
# [0.86920005 0.8660047 0.8647547 0.8634623 ]
# [0.85396254 0.8491496 0.84744585 0.8432566 ]]5、新增和删除索引向量
对于现有的向量数据,可以通过add和remove_ids指令进行新增和删除。
# 五,增删索引向量
print('============================== 5, add&remove ==============================')
xa = np.random.random((10000, d)).astype('float32') #新增10000行
xa[:, 0] += np.arange(len(xa)) / 1000.
faiss.normalize_L2(xa)
index.add(xa)
print('after add, index.ntotal=',index.ntotal)
index.remove_ids(np.arange(1000,1111)) #删除1000-1111的向量
print('after remove, index.ntotal=',index.ntotal,'\n') #============================== 5, add&remove ==============================
#after add, index.ntotal= 110000
#after remove, index.ntotal= 1098896、保存并加载索引
以上创建好的索引可以持久化保存到本地,并重新读取继续操作。
# 六,保存加载索引
print('============================== 6, write&read ==============================')
faiss.write_index(index, "large.index")
index_loaded = faiss.read_index('large.index')
print('index_loaded.ntotal=', index_loaded.ntotal)三、案例实践
接下来,我们将一些短语,通过嵌入式模型向量化后,再通过FAISS进行检索。其输入和输出短语与上一篇一样。
首先安装sentence_transformers库,使用它加载预训练嵌入式模型,
pip install sentence_transformers嵌入式模型使用all-MiniLM-L6-v2,与上篇保持一致。如果本地没有该模型,会自动从hungface上下载,如果网络的原因,要使用其国内的镜像。
import os
#使用hf的国内镜像,设置为环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'from sentence_transformers import SentenceTransformer
import faiss
import numpy as np# 加载预训练模型,使用ll-MiniLM-L6-v2最为embedding模型
model = SentenceTransformer("all-MiniLM-L6-v2")对待加载以及待检索的短语进行向量化
# 待加载的短语
corpus = ["海内存知己,天涯若比邻","大漠孤烟直,长河落日圆","春眠不觉晓,处处闻啼鸟","会当凌绝顶,一览众山小","海上生明月,天涯共此时","举头望明月,低头思故乡","山重水复疑无路,柳暗花明又一村","不识庐山真面目,只缘身在此山中","采菊东篱下,悠然见南山","谁言寸草心,报得三春晖","忽如一夜春风来,千树万树梨花开","落霞与孤鹜齐飞,秋水共长天一色","青山遮不住,毕竟东流去","春江潮水连海平,海上明月共潮生","两岸猿声啼不住,轻舟已过万重山","问渠那得清如许?为有源头活水来","竹外桃花三两枝,春江水暖鸭先知","身无彩凤双飞翼,心有灵犀一点通","众里寻他千百度,蓦然回首,那人却在,灯火阑珊处","莫愁前路无知己,天下谁人不识君"
]
# 通过embedding模型将短语向量化
corpus_embeddings = model.encode(corpus)# 待查询短语
query = "明月几时有,把酒问青天"
# 通过embedding模型将查询短语向量化
query_embedding = model.encode([query])初始化faiss索引,并将短句的向量数据添加到索引中
# 初始化 Faiss 索引
dimension = corpus_embeddings.shape[1] # 向量维度
print("dimension:", dimension)
index = faiss.IndexFlatL2(dimension) # 使用 L2 距离
index.add(corpus_embeddings) # 添加语料库向量到索引检索待查询语句的相似语句,并返回前top5
# 检索与查询向量最接近的前 k 个结果
k = 5 # 返回前 5 个最相似的结果
distances, indices = index.search(query_embedding, k)# 打印检索结果
print("Query:", query)
print("Top K Results:")
for i, idx in enumerate(indices[0]):print(f"Rank {i+1}: {corpus[idx]} (Distance: {distances[0][i]:.4f})")打印的结果如下:
Query: 明月几时有,把酒问青天
Top K Results:
Rank 1: 举头望明月,低头思故乡 (Distance: 0.4828)
Rank 2: 海上生明月,天涯共此时 (Distance: 0.5092)
Rank 3: 青山遮不住,毕竟东流去 (Distance: 0.5768)
Rank 4: 海内存知己,天涯若比邻 (Distance: 0.5937)
Rank 5: 莫愁前路无知己,天下谁人不识君 (Distance: 0.5976)可以看到与前一篇的结果一致。
四、总结
本文介绍了FAISS的基本用法,并通过案例实践,演示了嵌入向量,创建索引以及检索的过程。
附件
向量数据库技术系列一-基本原理
向量数据库技术系列二-Milvus介绍
向量数据库技术系列三-Chroma介绍
向量数据库技术系列四-FAISS介绍
向量数据库技术系列五-Weaviate介绍
相关文章:

向量数据库技术系列四-FAISS介绍
一、前言 FAISS(Facebook AI Similarity Search)是由Facebook AI Research开发的一个开源库,主要用于高效地进行大规模相似性搜索和聚类操作。主要功能如下: 向量索引与搜索:FAISS提供了多种索引和搜索向量的方法&…...

人工智能中的线性代数基础详解
线性代数是人工智能领域的重要数学基础之一,是人工智能技术的底层数学支柱,它为数据表示、模型构建和算法优化提供了核心工具。其核心概念与算法应用贯穿数据表示、模型训练及优化全过程。更多内容可看我文章:人工智能数学基础详解与拓展-CSDN博客 一、基本介绍 …...

格雷码.
格雷码 - OI Wiki 格雷码_百度百科 简介 格雷码(Gray Code),又称为二进制格雷码或循环二进制码,是一种二进制编码方式。它得名于贝尔实验室的工程师弗兰克格雷(Frank Gray),他于1940年代提出…...

【毕业论文格式】word分页符后的标题段前间距消失
文章目录 【问题描述】 分页符之后的段落开头,明明设置了标题有段前段后间距,但是没有显示间距: 【解决办法】 选中标题,选择边框 3. 选择段前间距,1~31磅的一个数 结果...

kubernetes对于一个nginx服务的增删改查
1、创建 Nginx 服务 1.1、创建 Deployment Deployment 用于管理 Pod 副本和更新策略。 方式一:命令式创建 kubectl create deployment nginx-deployment --imagenginx:latest --replicas3 --port80--replicas3:指定副本数为 3 --port80:容…...

PackageManagerService
首语 PackageManagerService(以下简称PMS)是Android最核心的系统服务之一,它是应用程序包管理服务,管理手机上所有的应用程序,包括应用程序的安装、卸载、更新、应用信息的查询、应用程序的禁用和启用等。 职责 在Android系统启动过程中扫…...

【蓝桥杯每日一题】3.16
🏝️专栏: 【蓝桥杯备篇】 🌅主页: f狐o狸x 目录 3.9 高精度算法 一、高精度加法 题目链接: 题目描述: 解题思路: 解题代码: 二、高精度减法 题目链接: 题目描述&…...

2.7 滑动窗口专题:串联所有单词的子串
LeetCode 30. 串联所有单词的子串算法对比分析 1. 题目链接 LeetCode 30. 串联所有单词的子串 2. 题目描述 给定一个字符串 s 和一个字符串数组 words,words 中所有单词长度相同。要求找到 s 中所有起始索引,使得从该位置开始的连续子串包含 words 中所…...

电脑实用小工具--VMware常用功能简介
一、创建、编辑虚拟机 1.1 创建新的虚拟机 详见文章新创建虚拟机流程 1.2 编辑虚拟机 创建完成后,点击编辑虚拟机设置,可对虚拟机内存、处理器、硬盘等各再次进行编辑设置。 二、虚拟机开关机 2.1 打开虚拟机 虚拟机创建成功后,点击…...

为训练大模型而努力-分享2W多张卡通头像的图片
最近我一直在研究AI大模型相关的内容,想着从现在开始慢慢收集各种各样的图片,万一以后需要训练大模型的时候可以用到,或者自己以后也许会需要。于是决定慢慢收集这些图片,为未来的学习和训练大模型做一些铺垫,哈哈。 …...

从零开始学习机器人---如何高效学习机械原理
如何高效学习机械原理 1. 理解课程的核心概念2. 结合图形和模型学习3. 掌握公式和计算方法4. 理论与实践相结合5. 总结和复习6. 保持好奇心和探索精神 总结 机械原理是一门理论性和实践性都很强的课程,涉及到机械系统的运动、动力传递、机构设计等内容。快速学习机械…...

JVM 垃圾回收器的选择
一:jvm性能指标吞吐量以及用户停顿时间解释。 二:垃圾回收器的选择。 三:垃圾回收器在jvm中的配置。 四:jvm中常用的gc算法。 一:jvm性能指标吞吐量以及用户停顿时间解释。 在 JVM 调优和垃圾回收器选择中࿰…...

使用GPTQ量化Llama-3-8B大模型
使用GPTQ量化8B生成式语言模型 服务器配置:4*3090 描述:使用四张3090,分别进行单卡量化,多卡量化。并使用SGLang部署量化后的模型,使用GPTQ量化 原来的模型精度为FP16,量化为4bit 首先下载gptqmodel量化…...

2025-03-16 学习记录--C/C++-PTA 习题4-2 求幂级数展开的部分和
合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。💪🏻 一、题目描述 ⭐️ 习题4-2 求幂级数展开的部分和 已知函数e^x可以展开为幂级数1xx^2/2!x^3/3!⋯x^k/k!⋯。现给定一个实数x&a…...

【C#】Http请求设置接收不安全的证书
在进行HTTP请求时,出现以下报错,可设置接收不安全证书跳过证书验证,建议仅测试环境设置,生产环境可能会造成系统漏洞 /// <summary> /// HttpGet请求方法 /// </summary> /// <param name"requestUrl"&…...

从PDF文件中提取数据
笔记 import pdfplumber # 打开PDF文件 with pdfplumber.open(数学公式.pdf) as pdf:for i in pdf.pages: # 遍历页print(i.extract_text()) # extract_text()方法提取内容print(f---------第{i.page_number}页结束---------)...

【k8s001】K8s架构浅析
Kubernetes 架构浅析 #mermaid-svg-irCZnQUuietSX3Ro {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-irCZnQUuietSX3Ro .error-icon{fill:#552222;}#mermaid-svg-irCZnQUuietSX3Ro .error-text{fill:#552222;stroke…...

NPU、边缘计算与算力都是什么啊?
考虑到灵活性和经济性,公司购置一台边缘计算机,正在尝试将PCGPU的计算机视觉项目转到边缘计算机NPU上。本文简单整理了三个概念,并试图将其做个概要的说明。 一、算力:数字世界的“基础能源” 1.1 算力是什么 **算力(…...
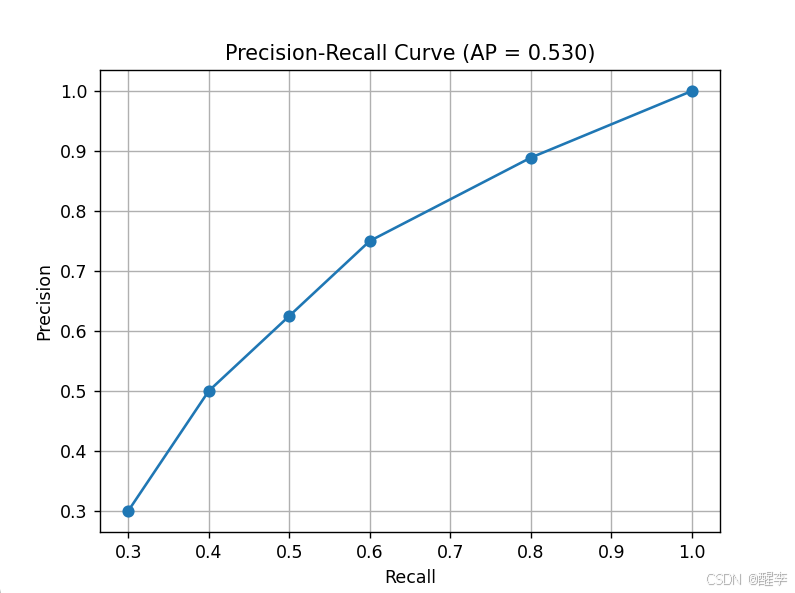
AP AR
混淆矩阵 真实值正例真实值负例预测值正例TPFP预测值负例FNTN (根据阈值预测) P精确度计算:TP/(TPFP) R召回率计算:TP/(TPFN) AP 综合考虑P R 根据不同的阈值计算出不同的PR组合, 画出PR曲线,计算曲线…...
Leetcode-1278.Palindrome Partitioning III [C++][Java]
目录 一、题目描述 二、解题思路 【C】 【Java】 Leetcode-1278.Palindrome Partitioning IIIhttps://leetcode.com/problems/palindrome-partitioning-iii/description/1278. 分割回文串 III - 力扣(LeetCode)1278. 分割回文串 III - 给你一个由小写…...

Java集合 - ArrayList
ArrayList 是 Java 集合框架中最常用的动态数组实现类,位于 java.util 包中。它基于数组实现,支持动态扩容和随机访问。 1. 特点 动态数组:ArrayList 的底层是一个数组,可以根据需要动态扩展容量。 有序:元素按照插入…...

C++特性——智能指针
为什么需要智能指针 对于定义的局部变量,当作用域结束之后,就会自动回收,这没有什么问题。 当时用new delete的时候,就是动态分配对象的时候,如果new了一个变量,但却没有delete,这会造成内存泄…...

ctf web入门知识合集
文章目录 01做题思路02信息泄露及利用robots.txt.git文件泄露dirsearch ctfshow做题记录信息搜集web1web2web3web4web5web6web7web8SVN泄露与 Git泄露的区别web9web10 php的基础概念php的基础语法1. PHP 基本语法结构2. PHP 变量3.输出数据4.数组5.超全局变量6.文件操作 php的命…...

DeepSeek:技术教育领域的AI变革者——从理论到实践的全面解析
一、技术教育为何需要DeepSeek? 在数字化转型的浪潮下,技术教育面临着知识更新快、实践门槛高、个性化需求强三大核心挑战。传统的教学模式难以满足开发者快速掌握前沿技术、构建复杂系统能力的需求。DeepSeek作为国产开源大模型的代表,凭借…...

MySQL-存储过程和自定义函数
存储过程 存储过程,一组预编译的 SQL 语句和流程控制语句,被命名并存储在数据库中。存储过程可以用来封装复杂的数据库操作逻辑,并在需要时进行调用。 使用存储过程 创建存储过程 create procedure 存储过程名() begin存储过程的逻辑代码&…...

图——表示与遍历
图的两种主要表示方法 图有两种常用的表示方法,一种是邻接表法(adjacency-list),另一种是邻接矩阵法(adjacency-matrix)。 邻接表法储存数据更紧凑,适合稀疏的图(sparse graphs&am…...

新手村:数据预处理-异常值检测方法
机器学习中异常值检测方法 一、前置条件 知识领域要求编程基础Python基础(变量、循环、函数)、Jupyter Notebook或PyCharm使用。统计学基础理解均值、中位数、标准差、四分位数、正态分布、Z-score等概念。机器学习基础熟悉监督/无监督学习、分类、聚类…...
测试与系统化整改)
电磁兼容性|电子设备(EMC)测试与系统化整改
在现代电子工程领域,5G通信、物联网与人工智能技术深度融合,电磁兼容性(EMC)已成为衡量设备可靠性的关键指标。据国际电磁兼容协会(IEEE EMC Society)2024年度报告显示,全球因EMC问题导致的电子…...

联合体定义与应用
引言 讲到了结构体,那同时类似的结构就还有联合体,本文就将详解介绍联合体。 在C语言中,联合体(union)是一种特殊的数据结构,它与结构体(struct)相似,但有一个显著的不同:联合体的所有成员共用同一块内存空间。这意味着在任何时候,联合体中只能有一个成员保存有效数…...

ChatGPT-4
第一章:ChatGPT-4的技术背景与核心架构 1.1 生成式AI的发展脉络 生成式人工智能(Generative AI)的演进历程可追溯至20世纪50年代的早期自然语言处理研究。从基于规则的ELIZA系统到统计语言模型,再到深度学习的革命性突破&#x…...