集成学习(下):Stacking集成方法
一、Stacking的元学习革命
1.1 概念
Stacking(堆叠法) 是一种集成学习技术,通过组合多个基学习器(base learner)的预测结果,并利用一个元模型(meta-model)进行二次训练,以提升整体模型的泛化性能。
如果说 Bagging 是民主投票,Boosting 是学霸纠错,那么 Stacking 就是组建专家智囊团。如同医院的多学科会诊(MDT),Stacking通过分层建模将不同领域的专家意见进行综合,突破单一模型的天花板。
如果你不了解 Bagging 和 Boosting 集成方法,没关系,下面两篇文章将带你进入集成学习的世界:
集成学习(上):Bagging集成方法
集成学习(中):Boosting集成方法
如下图所示,利用初始学习器输出的成果,进行数据拼接,形成新的数据集在由次级学习器进行训练拟合。

1.2 流程及结构分析
Stacking(堆叠泛化)通过构建多级预测体系实现模型能力的跃迁,其核心突破在于:
- 元特征构造:基模型预测结果作为新特征空间
- 层级泛化:多级模型逐层抽象数据规律
- 异构融合:集成不同算法类型的优势
下面我们用一个 Stacking 架构来演示一下:
# 多级Stacking架构示例
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.svm import SVC# 基模型层
level1_models = [('lgbm', LGBMClassifier(num_leaves=31)),('svm', SVC(probability=True)),('mlp', MLPClassifier(hidden_layer_sizes=(64,)))
]# 元模型层
level2_model = LogisticRegression()# 深度堆叠架构
deep_stacker = StackingClassifier(estimators=level1_models,final_estimator=StackingClassifier(estimators=[('xgb', XGBClassifier()), ('rf', RandomForestClassifier())],final_estimator=LogisticRegression()),stack_method='predict_proba',n_jobs=-1
)
我们来逐层分析一下上面代码所作的事情:
1.2.1 导库
导入库是最基本的,这里不再多说
StackingClassifier: Scikit-learn 提供的堆叠集成分类器。LogisticRegression: 逻辑回归模型(常用于元学习器)。LGBMClassifier: LightGBM 梯度提升树模型。SVC: 支持向量机分类器(需要设置probability=True以支持概率输出)。
1.2.2 定义基模型层(第一层)
level1_models = [('lgbm', LGBMClassifier(num_leaves=31)),('svm', SVC(probability=True)),('mlp', MLPClassifier(hidden_layer_sizes=(64,)))
]
- 基模型组成:
- LightGBM: 高效梯度提升框架,
num_leaves=31控制树复杂度。 - SVM: 支持向量机,
probability=True使其能输出类别概率。 - MLP: 多层感知机,
hidden_layer_sizes=(64,)表示单隐层(64个神经元)。
- LightGBM: 高效梯度提升框架,
- 命名规则:每个模型以元组
(名称, 模型对象)形式定义,便于后续分析。
1.2.3 定义元模型层(第二层)
level2_model = LogisticRegression()
- 逻辑回归:作为次级元学习器,负责整合基模型的输出。
- 输入数据:将接收基模型的预测概率(因
stack_method='predict_proba')。
1.2.4 构建深度堆叠架构
deep_stacker = StackingClassifier(estimators=level1_models, # 第一层模型列表final_estimator=StackingClassifier( # 嵌套的二级堆叠estimators=[('xgb', XGBClassifier()), ('rf', RandomForestClassifier())],final_estimator=LogisticRegression()),stack_method='predict_proba', # 基模型输出概率n_jobs=-1 # 启用全部CPU核心并行计算
)
1.2.5 参数详解
| 参数 | 说明 |
|---|---|
estimators | 第一层基模型列表,每个模型需有唯一名称标识 |
final_estimator | 次级元学习器,此处嵌套了另一个 StackingClassifier |
stack_method | 基模型的输出方式: - 'predict_proba' (概率,适用于分类) - 'predict' (直接类别) - 'decision_function' (置信度分数) |
n_jobs | 并行任务数,-1 表示使用所有可用CPU核心 |
1.2.6 数据流动与层级结构
-
第一层(基模型):
- 每个基模型独立训练,生成预测概率(例如对 3 分类任务,每个模型输出 3 列概率)。
- 所有基模型的概率输出被拼接为新的特征矩阵。
-
第二层(嵌套堆叠):
- 输入是第一层生成的概率特征。
- XGBoost 和 RandomForest 在此层训练,输出新的概率结果。
-
第三层(最终元模型):
- 输入是第二层模型的概率输出。
- 逻辑回归整合这些概率,生成最终预测。
二、数学本质与优化理论
2.1 泛化误差分解
E ( H ) = E b + E v + E t \mathcal{E}(H) = \mathcal{E}_b + \mathcal{E}_v + \mathcal{E}_t E(H)=Eb+Ev+Et
其中:
- E b \mathcal{E}_b Eb:基模型偏差
- E v \mathcal{E}_v Ev:验证策略方差
- E t \mathcal{E}_t Et:元模型训练误差
2.2 交叉验证策略优化
使用K折交叉验证生成元特征,避免数据泄漏:
from sklearn.model_selection import KFolddef generate_meta_features(X, y, base_model, n_splits=5):meta_features = np.zeros_like(y)kf = KFold(n_splits=n_splits)for train_idx, val_idx in kf.split(X):X_train, X_val = X[train_idx], X[val_idx]y_train = y[train_idx]model = clone(base_model)model.fit(X_train, y_train)meta_features[val_idx] = model.predict_proba(X_val)[:,1]return meta_features
2.3 损失函数耦合度分析
使用多目标损失加权有效减少 loss 值:
# 多目标损失加权
class MultiLossStacker:def __init__(self, base_models, meta_model, loss_weights):self.base_models = base_modelsself.meta_model = meta_modelself.loss_weights = loss_weightsdef _calculate_meta_features(self, X):features = []for model in self.base_models:pred = model.predict_proba(X)loss = log_loss(y, pred, labels=model.classes_)features.append(loss * self.loss_weights[model])return np.array(features).T
2.4 模型互补增强
下面我收集到的在Kaggle房价预测任务中的表现对比:
| 模型类型 | MAE | Stacking提升 |
|---|---|---|
| XGBoost | 2.34 | - |
| LightGBM | 2.28 | - |
| Stacking融合 | 1.87 | 20.1% |
三、Stacking高级系统设计
3.1 分布式堆叠架构
from dask_ml.ensemble import StackingClassifier as DaskStacking
from dask_ml.wrappers import ParallelPostFit# 分布式基模型
dask_base_models = [('dask_lgbm', ParallelPostFit(LGBMClassifier())),('dask_svm', ParallelPostFit(SVC(probability=True)))
]# 分布式元模型
dask_stacker = DaskStacking(estimators=dask_base_models,final_estimator=LogisticRegression(),n_jobs=-1
)
3.2 自动特征工程
# 自动生成高阶交互特征
from feature_engine.creation import MathFeaturesstacking_pipeline = Pipeline([('base_models', FeatureUnion([('model1', ModelTransformer(LGBMClassifier())),('model2', ModelTransformer(SVC(probability=True)))])),('interactions', MathFeatures(variables=[0, 1], func=np.multiply)),('meta_model', XGBClassifier())
])
3.3 在线学习支持
在线学习,让模型实时学习拟合特征:
# 增量更新元模型
meta_model.partial_fit(new_meta_features, new_labels)
四、案例框架实战指南
案例1:金融风控全流程
from sklearn.ensemble import StackingClassifier
from sklearn.neural_network import MLPClassifier# 构建风控堆叠模型
base_models = [('xgb', XGBClassifier()),('lgb', LGBMClassifier()),('rf', RandomForestClassifier())
]stack_model = StackingClassifier(estimators=base_models,final_estimator=MLPClassifier(hidden_layer_sizes=(50,)),stack_method='predict_proba',passthrough=True # 保留原始特征
)stack_model.fit(X_train, y_train)
案例2:医疗多模态诊断
# 融合CT影像和病历文本
ct_features = CNN.predict(ct_images)
text_features = BERT.encode(medical_texts)# 堆叠分类器
stack_input = np.concatenate([ct_features, text_features], axis=1)
diagnosis_model = XGBClassifier().fit(stack_input, labels)
案例3:量化交易系统
# 多因子融合预测
factor_models = {'technical': LGBMRegressor(),'fundamental': XGBRegressor(),'sentiment': TransformerModel()
}meta_features = pd.DataFrame({name: model.predict(factors) for name, model in factor_models.items()
})final_predictor = CatBoostRegressor().fit(meta_features, returns)
案例4:自动驾驶决策
# 多传感器数据融合
camera_features = ResNet50.predict(camera_images)
lidar_features = PointNet.predict(lidar_data)
radar_features = GRU.predict(radar_sequence)meta_input = np.concatenate([camera_features, lidar_features, radar_features
], axis=1)decision_model = StackingClassifier(estimators=[('mlp', MLPClassifier()), ('xgb', XGBClassifier())],final_estimator=TransformerEncoder()
)
五、超参数优化五阶法则
5.1 参数空间设计
| 层级 | 优化参数 | 搜索策略 |
|---|---|---|
| 基模型层 | 模型类型组合 | 遗传算法 |
| 特征工程层 | 交互阶数/选择阈值 | 贝叶斯优化 |
| 元模型层 | 复杂度参数 | 网格搜索 |
| 验证策略 | 交叉验证折数 | 固定值 |
| 融合策略 | 加权方式/投票机制 | 启发式搜索 |
5.2 自动化调优系统
from autogluon.core import Space
from autogluon.ensemble import StackerEnsemblesearch_space = Space()
search_space['base_models'] = [LGBMClassifier(num_leaves=Space(15, 255)),XGBClassifier(max_depth=Space(3, 10))
]
search_space['meta_model'] = LogisticRegression(C=Space(0.1, 10))autostacker = StackerEnsemble(search_space=search_space,time_limit=3600,num_trials=50
)
autostacker.fit(X, y)
5.3 基模型选择矩阵
| 数据类型 | 推荐基模型 | 注意事项 |
|---|---|---|
| 结构化数据 | XGBoost, LightGBM | 注意特征类型处理 |
| 图像数据 | ResNet, Vision Transformer | 使用预训练模型 |
| 文本数据 | BERT, LSTM | 注意序列长度限制 |
| 时序数据 | Transformer, TCN | 处理长期依赖关系 |
5.4 元模型选择指南
meta_model_selector = {'small_data': LogisticRegression,'structured_data': XGBoost,'high_dim_data': MLP,'multimodal_data': Transformer
}
六、常见误区与解决方案
-
基模型过拟合传染
- 方案:基模型强制早停+输出平滑
-
概念漂移累积误差
- 方案:动态模型权重调整机制
-
异构硬件资源浪费
- 方案:模型计算图优化器
-
隐私数据泄露风险
- 方案:同态加密元特征传输
-
多阶段部署复杂
- 方案:ONNX全流程导出
-
在线服务延迟高
- 方案:基模型预测缓存+并行执行
-
版本升级灾难
- 方案:AB测试+影子模式部署
-
解释性需求冲突
- 方案:层级化SHAP解释框架
-
存储成本爆炸
- 方案:模型参数共享+量化压缩
-
监控体系缺失
- 方案:多维健康度指标看板
七、性能基准测试
使用OpenML-CC18基准测试对比:
bench_results = {'SingleModel': {'AUC': 0.85, 'Time': 120},'Bagging': {'AUC': 0.88, 'Time': 180},'Boosting': {'AUC': 0.89, 'Time': 150},'Stacking': {'AUC': 0.91, 'Time': 300}
}pd.DataFrame(bench_results).plot.bar(title='集成方法性能对比',subplots=True,layout=(1,2),figsize=(12,6)
)
关键结论:
- Stacking在AUC指标上领先2-3个百分点
- 训练时间随复杂度线性增长
- 内存消耗与基模型数量正相关
结语:三篇宝典总结
终极建议:在您下一个项目中,尝试构建三级堆叠模型:第一层集成3种异质模型(如XGBoost、LightGBM、MLP),第二层使用Transformer进行特征融合,第三层用逻辑回归加权输出。通过这种架构,您将体验到集成学习的真正威力(前提是电脑能带动,带不动当我没说,因为我的也带不动 [坏笑] )。
至此,集成学习三部曲已完整呈现。从Bagging的群体智慧,到Boosting的自我进化,再到Stacking的终极融合,希望这套组合集成拳能帮助您在算法的路上更进一步。现在打开Colab,用Stacking征服您正在攻坚的预测难题吧!
感谢您的观看,别忘了点赞哦,如果您还有什么更棒的建议,可以在评论区留言讨论。
相关文章:
集成学习(下):Stacking集成方法
一、Stacking的元学习革命 1.1 概念 Stacking(堆叠法) 是一种集成学习技术,通过组合多个基学习器(base learner)的预测结果,并利用一个元模型(meta-model)进行二次训练,…...

centos 7 搭建FTP user-list用户列表
在 CentOS 7 上搭建基于 user_list 的 FTP 用户列表,你可以按以下步骤操作: 1. 安装 vsftpd 服务 若还未安装 vsftpd,可以使用以下命令进行安装: bash yum install -y vsftpd2. 启动并设置开机自启 vsftpd 服务 bash systemctl…...

CUDA编程面试高频30题
1. 什么是CUDA?它与GPU的关系是什么? 答: CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一种并行计算平台和应用程序接口模型。它允许开发者利用NVIDIA GPU进行通用计算任务,而不仅仅是图形渲染。CUDA提…...

PageHelper插件依赖引入不报错,但用不了
情况: 父模块pom. Xml 引入1. 4. 0以上版本的pagehelper-spring-boot-starter。 要用到插件的子模块,去掉版本号,引入和父模块一样的依赖。 引入成功,没有报错,但是打开右边的maven里面没有找到PageHelper插件。 终端清空并重…...

背包问题——动态规划的经典问题包括01背包问题和完全背包问题
01背包问题:给你多个物品每个物品只能选一次,要你在不超过背包容积(或者恰好等于)的情况下选择装价值最大的组合。如果没有动态规划的基础其实是很难理解这个问题的,所以看这篇文章之前先去学习一下动态规划的基本思想…...

MyBatis 面试专题
MyBatis 面试专题 基础概念MyBatis中的工作原理MyBatis 与 Hibernate 的区别?#{} 和 ${} 的区别?MyBatis 的核心组件有哪些? 映射与配置如何传递多个参数?ResultMap 的作用是什么?动态 SQL 常用标签有哪些?…...

Animation - AI Controller控制SKM_Manny的一些问题
一些学习笔记归档; 在UE5中,使用新的小白人骨骼:SKM_Manny,会跟UE4中的小白人有一些差别; 比如在用AI Controller控制使用该骨骼(配置默认的ABP_Manny Animation BP)角色的时候,需要…...

安科瑞新能源防逆流解决方案:守护电网安全,赋能绿色能源利用
随着光伏、储能等新能源在用户侧的快速普及,如何避免电力逆流对电网造成冲击,成为行业关注的焦点。安科瑞凭借技术实力与丰富的产品矩阵,推出多场景新能源防逆流解决方案,以智能化手段助力用户实现安全、经济的能源管理࿰…...

filebeat和logstash区别
Filebeat 角色: 轻量级日志收集器。 功能: 从指定的日志文件中读取日志数据。 可以从多个源(如文件、系统日志、容器日志等)收集日志。 将收集到的日志数据传输到 Logstash、Elasticsearch 或其他支持的输出端点。 性能: 由于是轻量级的,File…...

【一起学Rust | Tauri2.0框架】基于 Rust 与 Tauri 2.0 框架实现全局状态管理
前言 在现代应用程序开发中,状态管理是构建复杂且可维护应用的关键。随着应用程序规模的增长,组件之间共享和同步状态变得越来越具有挑战性。如果处理不当,状态管理可能会导致代码混乱、难以调试,并最终影响应用程序的性能和可扩…...

扩散模型算法实战——三维重建的应用
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 引言 三维重建是计算机视觉和图形学中的一个重要研究方向,旨在从二维图像或其他传感器数据中恢复…...

社群经济4.0时代:开源链动模式与AI技术驱动的电商生态重构
摘要:在Web3.0技术浪潮与私域流量红利的双重驱动下,电商行业正经历从"流量收割"到"用户深耕"的范式转变。本文基于社群经济理论框架,结合"开源链动21模式"、AI智能名片、S2B2C商城小程序源码等创新工具&#x…...

【Linux系统】进程等待:告别僵尸进程深入理解Linux进程同步的核心密码
Linux系列 文章目录 Linux系列前言一、进程等待的核心目的二、进程等待的实现方式2.1 wait()函数2.2 waitpid()函数 总结 前言 在Linux系统中,进程等待(Process Waiting)是多进程编程中的核心机制,指父进程…...

根据文件名称查询文件所在位置
在 Linux 中,根据文件名称查询文件所在位置主要通过命令行工具实现,以下是几种常用方法: --- ### **1. 使用 find 命令(最灵活)** find 命令可以递归搜索指定目录下的文件,支持按名称、类型、时间等条件过…...

六十天前端强化训练之第二十五天之组件生命周期大师级详解(Vue3 Composition API 版)
欢迎来到编程星辰海的博客讲解 看完可以给一个免费的三连吗,谢谢大佬! 目录 一、生命周期核心知识 1.1 生命周期全景图 1.2 生命周期钩子详解 1.2.1 初始化阶段 1.2.2 挂载阶段 1.2.3 更新阶段 1.2.4 卸载阶段 1.3 生命周期执行顺序 1.4 父子组…...
—自定义运算符)
Pytorch使用手册(专题五十)—自定义运算符
1. PyTorch 自定义运算符 PyTorch 提供了一个庞大的运算符库,这些运算符可以对张量进行操作(例如 torch.add、torch.sum 等)。然而,您可能希望向 PyTorch 引入一个新的自定义操作,并使其能够与诸如 torch.compile、autograd 和 torch.vmap 等子系统协同工作。为此,您必须…...

springboot整合mybatis-plus(保姆教学) 及搭建项目
一、Spring整合MyBatis (1)将MyBatis的DataSource交给Spring IoC容器创建并管理,使用第三方数据库连接池(Druid,C3P0等)代替MyBatis内置的数据库连接池 (2)将MyBatis的SqlSessionFactory交给Spring IoC容器创建并管理,使用spring-mybatis整…...
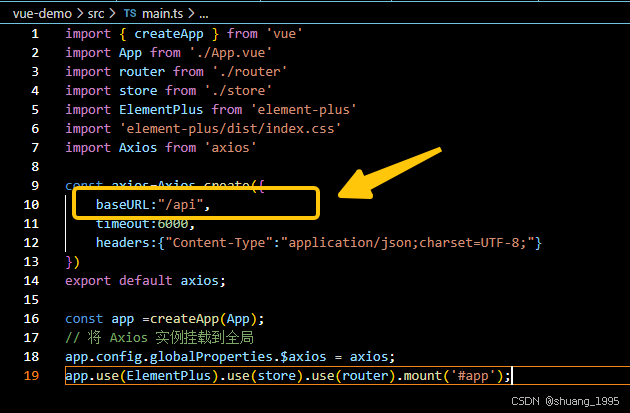
VSCode创建VUE项目(三)使用axios调用后台服务
1. 安装axios,执行命令 npm install axios 2. 在 main.ts 中引入并全局挂载 Axios 实例 修改后的 代码(也可以单独建一个页面处理Axios相关信息等,然后全局进行挂载) import { createApp } from vue import App from ./App.vue import rou…...

JVM常用垃圾回收器
Serial 和Serial Old收集器 Serial 系列的垃圾收集器采用了简单高效、资源消耗最少、单线程收集的设计思路。 简单高效:由于硬件资源有限,垃圾回收器需要设计得简单高效,以减少系统资源的占用。Serial 系列的垃圾收集器实现简单,…...

车辆模型——运动学模型
文章目录 约束及系统移动机器人运动学模型(Kinematic Model)自行车模型含有加速度 a a a 的自行车模型系统偏差模型 在机器人的研究领域中,移动机器人的系统建模与分析是极为关键的基础环节,本文以非完整约束的轮式移动机器人为研…...

EJS缓存解决多页面相同闪动问题
基于 EJS 的模板引擎特性及其缓存机制,以下是关于缓存相同模块的详细解答: 一、EJS 缓存机制的核心能力 模板编译缓存 EJS 默认会将编译后的模板函数缓存在内存中,当相同模板文件被多次渲染时,会直接复用已编译的模板函数&#x…...

<details>和<summary>标签的用途,如何使用它们实现可折叠内容
大白话和标签的用途,如何使用它们实现可折叠内容 <details> 和 <summary> 标签用途 <details> 和 <summary> 标签是 HTML 里的实用标签,二者配合能创建出可折叠内容。 <details> 标签就像是一个容器,能把那…...

HUGO介绍、安装、以及使用
HUGO官方网站,文章内容的简介大部分来自官网的翻译,官网是纯英文描述,英语好的可以前往官方网站,博主在这里简介中简单翻译处理包括一些链接的引用,主要是讲解一下如何安装和使用。 这里再粘贴一个三方网站opendocs.i…...

【STM32实物】基于STM32的太阳能充电宝设计
基于STM32的太阳能充电宝设计 演示视频: 基于STM32的太阳能充电宝设计 硬件组成: 系统硬件包括主控 STM32F103C8T6、0.96 OLED 显示屏、蜂鸣器、电源自锁开关、温度传感器 DS18B20、继电器、5 V DC 升压模块 、TB4056、18650锂电池、9 V太阳能板、稳压降压 5 V三极管。 功能…...

【Netty】长连接与短连接的不同实现
长连接与短连接的不同实现 配置层面 // 长连接配置 bootstrap.option(ChannelOption.SO_KEEPALIVE, true) // 启用 TCP keepalive.option(ChannelOption.TCP_NODELAY, true); // 禁用 Nagle 算法// 短连接不需要这些配置心跳机制 // 长连接需要心跳 pipeline.addLast(new Idl…...

安装 OpenSSL 1.1.1 的完整脚本适用于 Ubuntu 22.04 系统
#!/bin/bash # 更新系统包 sudo apt-get update # 安装编译工具和依赖库 sudo apt-get install -y build-essential checkinstall zlib1g-dev # 下载 OpenSSL 1.1.1 源码 wget https://www.openssl.org/source/openssl-1.1.1.tar.gz # 检查下载是否成功 if [ $? -ne 0 ]; …...

24-智慧旅游系统(协同过滤算法)
介绍 技术: 基于 B/S 架构 SpringBootMySQLLayuivue 环境: Idea mysql maven jdk1.8 管理端功能 管理端主要用于对系统内的各类旅游资源进行管理,包括用户信息、旅游路线、车票、景点、酒店、美食、论坛等内容。具体功能如下: …...

Vue 中的日期格式化实践:从原生 Date 到可视化展示!!!
📅 Vue 中的日期格式化实践:从原生 Date 到可视化展示 🚀 在数据可视化场景中,日期时间的格式化显示是一个高频需求。本文将以一个邀请码关系树组件为例,深入解析 Vue 中日期格式化的 核心方法、性能优化 和 最佳实践…...

2025年使用Scrapy和Playwright解决网页抓取挑战的方案
0. 引言 随着互联网技术的发展,网页内容呈现方式越来越复杂,大量网站使用JavaScript动态渲染内容,这给传统的网络爬虫带来了巨大挑战。在2025年的网络爬虫领域,Scrapy和Playwright的结合为我们提供了一个强大的解决方案ÿ…...

可靠消息投递demo
以下是一个基于 Spring Boot RocketMQ 的完整分布式事务实战 Demo,包含事务消息、本地事务、自动重试、死信队列(DLQ) 等核心机制。代码已充分注释,可直接运行。 一、项目结构 src/main/java ├── com.example.rocketmq │ …...