Spring Boot 整合 Elasticsearch 实践:从入门到上手
引言
Elasticsearch 是一个开源的分布式搜索引擎,广泛用于日志分析、搜索引擎、数据分析等场景。本文将带你通过一步步的教程,在 Spring Boot 项目中整合 Elasticsearch,轻松实现数据存储与查询。
1. 创建 Spring Boot 项目
首先,你需要创建一个 Spring Boot 项目。如果你还没有创建,可以使用 Spring Initializr 快速生成一个项目。在生成项目时,确保选择了以下依赖:
- Spring Web
- Spring Data Elasticsearch
- Spring Boot DevTools(可选)
2. 添加依赖
打开项目中的 pom.xml 文件,添加 Spring Data Elasticsearch 相关的依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId>
</dependency>
3. 配置 application.yml
在 src/main/resources/application.yml 或 application.properties 中配置 Elasticsearch 连接信息:
使用 application.yml
spring:data:elasticsearch:cluster-name: your-cluster-namecluster-nodes: localhost:9200
使用 application.properties
spring.data.elasticsearch.cluster-name=your-cluster-name
spring.data.elasticsearch.cluster-nodes=localhost:9200
请确保你的 Elasticsearch 服务已启动,通常默认地址是 localhost:9200。
4. 创建 Elasticsearch 实体类
接下来,我们需要创建一个实体类来映射到 Elasticsearch 中的文档。可以使用 @Document 注解来标识这个类为 Elasticsearch 文档。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;@Document(indexName = "user") // 定义索引名称
public class User {@Idprivate String id;private String name;private Integer age;// Getters and Setterspublic String getId() {return id;}public void setId(String id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}
}
5. 创建 Elasticsearch Repository 接口
使用 Spring Data Elasticsearch 提供的 ElasticsearchRepository 接口,可以轻松实现对 Elasticsearch 的 CRUD 操作。
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;public interface UserRepository extends ElasticsearchRepository<User, String> {// 自定义查询方法User findByName(String name);
}
6. 使用 Repository 进行数据操作
在 Controller 层注入 UserRepository,即可实现对 Elasticsearch 的基本数据操作。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;@RestController
public class UserController {@Autowiredprivate UserRepository userRepository;// 保存用户@PostMapping("/users")public User saveUser(@RequestBody User user) {return userRepository.save(user);}// 根据名字查询用户@GetMapping("/users")public User getUserByName(String name) {return userRepository.findByName(name);}
}
7. 启动 Elasticsearch 服务
确保你的 Elasticsearch 服务已经启动。你可以通过以下命令启动 Elasticsearch:
./bin/elasticsearch
启动成功后,访问 http://localhost:9200,你应该可以看到 Elasticsearch 的状态信息。
8. 测试 Spring Boot 与 Elasticsearch 的集成
启动 Spring Boot 项目后,使用 Postman 或 cURL 进行测试:
- 保存用户数据: 向
POST /users发送请求,传入用户数据(例如:{"name": "John", "age": 30})。 - 查询用户数据: 向
GET /users?name=John发送请求,查询刚刚保存的用户。
9. 进阶优化与配置
自定义 Elasticsearch 客户端配置
如果需要自定义连接池和配置 Elasticsearch 客户端,可以通过以下方式配置:
import org.apache.http.impl.client.HttpClients;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.RestClientBuilder;@Configuration
public class ElasticsearchConfig {@Beanpublic RestHighLevelClient client() {RestClientBuilder builder = RestClient.builder(new HttpHost("localhost", 9200, "http"));return new RestHighLevelClient(builder);}
}
优化性能
- 索引设置:适当设置索引的分片数和副本数。
- 查询优化:对查询进行分页和缓存优化,减少查询开销。
结语
通过本文,你已经学会了如何在 Spring Boot 项目中整合 Elasticsearch,进行基本的索引创建、文档操作以及查询。同时,掌握了一些优化技巧,可以帮助你在生产环境中更高效地使用 Elasticsearch。
如果你对 Elasticsearch 或 Spring Boot 集成有任何问题,欢迎在评论区留言。
相关文章:

Spring Boot 整合 Elasticsearch 实践:从入门到上手
引言 Elasticsearch 是一个开源的分布式搜索引擎,广泛用于日志分析、搜索引擎、数据分析等场景。本文将带你通过一步步的教程,在 Spring Boot 项目中整合 Elasticsearch,轻松实现数据存储与查询。 1. 创建 Spring Boot 项目 首先ÿ…...

使用外部事件检测接入 CDH 大数据管理平台告警
CDH 大数据管理平台 CDH(Cloudera Distribution Hadoop)是一个企业级的大数据平台,由 Cloudera 公司提供,它包含了 Apache Hadoop 生态系统中的多种开源组件,并对其进行了优化和集成,以支持大规模数据存储…...

RabbitMQ八股文
RabbitMQ RabbitMQ 核心概念与组件1. RabbitMQ 核心组件及其作用1.1 生产者(Producer)1.2 交换机(Exchange)1.3 队列(Queue)1.4 绑定(Binding)1.5 消费者(Consumer&#…...

MongoDB(五) - Studio 3T 下载与安装教程
文章目录 前言一、Studio 3T 简介二、下载及安装1. 下载2. 安装 三、使用Studio 3T连接MongoDB 前言 本文旨在全面且深入地为你介绍 Studio 3T。从其丰富的功能特性、跨平台使用的便捷性,到详细的下载安装步骤,以及关键的连接 MongoDB 操作,…...

2025高频面试算法总结篇【链表堆栈队列】
文章目录 直接刷题链接直达反转链表环形链表判断一个序列是否为合理的出栈顺序最长有效括号旋转链表复杂链表的复制约瑟夫环问题滑动窗口最大值 直接刷题链接直达 反转链表 206. 反转链表 环形链表 141. 环形链表142. 环形链表 II 判断一个序列是否为合理的出栈顺序 946.…...

Java主流开发框架之请求响应常用注释
1.RestController 标记一个类为 REST 控制器,处理 HTTP 请求并直接返回数据(如 JSON/XML),而不是视图(如 HTML),一般是放在类的上边 RestController public class UserController {GetMapping…...

汽车制造MES
一、整体生产工序 整车的车间主要分为4个部分:冲压、焊装、涂装、总装、整车入库 系统架构 二、车间概括 1.冲压车间 2.焊装车间 3.涂装车间 4.总装车间 1.整车装配的部件都要可追溯、数据实时性要求高、涉及分装与总装的协调、物流配送的协调、质量批处理的协调、…...
)
LeetCode 2643.一最多的行:模拟(更新答案)
【LetMeFly】2643.一最多的行:模拟(更新答案) 力扣题目链接:https://leetcode.cn/problems/row-with-maximum-ones/ 给你一个大小为 m x n 的二进制矩阵 mat ,请你找出包含最多 1 的行的下标(从 0 开始)以及这一行中…...

固定翼无人机姿态和自稳模式
固定翼无人机的姿态模式(Attitude/Angle Mode)和自稳模式(Stabilize Mode)是两种常见的飞行控制模式,它们在飞控系统介入程度、操作逻辑及适用场景上有显著区别。以下是两者的详细对比及使用指南: …...

K8S中若要挂载其他命名空间中的 Secret
在Kubernetes(k8s)里,若要挂载其他命名空间中的Secret,你可以通过创建一个 Secret 的 ServiceAccount 和 RoleBinding 来实现对其他命名空间 Secret 的访问,接着在 Pod 中挂载这个 Secret。下面是详细的步骤和示例代码…...

关于Unity的CanvasRenderer报错
MissingReferenceException: The object of type ‘CanvasRenderer’ has been destroyed but you are still trying to access it. Your script should either check if it is null or you should not destroy the object. UnityEngine.UI.GraphicRaycaster.Raycast (UnityEng…...
——返回产出artifact)
LangChain组件Tools/Toolkits详解(5)——返回产出artifact
LangChain组件Tools/Toolkits详解(5)——返回产出artifact 本篇摘要14. LangChain组件Tools/Toolkits详解14.5 返回产出artifact14.5.1 定义工具14.5.2 使用ToolCall调用工具14.5.3 与模型一起使用14.5.4 从子例化BaseTool返回参考文献本章目录如下: 《LangChain组件Tools/T…...

信奥赛CSP-J复赛集训(模拟算法专题)(26):P5412 [YNOI2019] 排队
信奥赛CSP-J复赛集训(模拟算法专题)(26):P5412 [YNOI2019] 排队 题目描述 小明所在的班级要举办一场课外活动,在活动开始之前老师告诉小明:“需要把男女生分成两队,并且每一队都要按照身高从矮到高进行排序”。但是由于小明的马虎,没有把老师的安排转达给同学,导致全…...

基于开源模型的微调训练及瘦身打造随身扫描仪方案__用AI把手机变成文字识别小能手
基于开源模型的微调训练及瘦身打造随身扫描仪方案__用AI把手机变成文字识别小能手 一、准备工作:组装你的"数码工具箱" 1. 安装基础工具(Python环境) 操作步骤: 访问Python官网下载安装包安装时务必勾选Add Python to…...

在 Offset Explorer 中配置多节点 Kafka 集群的详细指南
一、是否需要配置 Zookeeper? Kafka 集群的 Zookeeper 依赖性与版本及运行模式相关: Kafka 版本是否需要 Zookeeper说明0.11.x 及更早版本✅ 必须配置Kafka 完全依赖 Zookeeper 管理元数据2.8 及以下版本✅ 必须配置Kafka 依赖外置或内置的 Zookeeper …...

STM32基础教程——定时器
前言 TIM定时器(Timer):STM32的TIM定时器是一种功能强大的外设模块,通过时基单元(包含预分频器、计数器和自动重载寄存器)实现精准定时和计数功能。其核心原理是:内部时钟(CK_INT)或…...
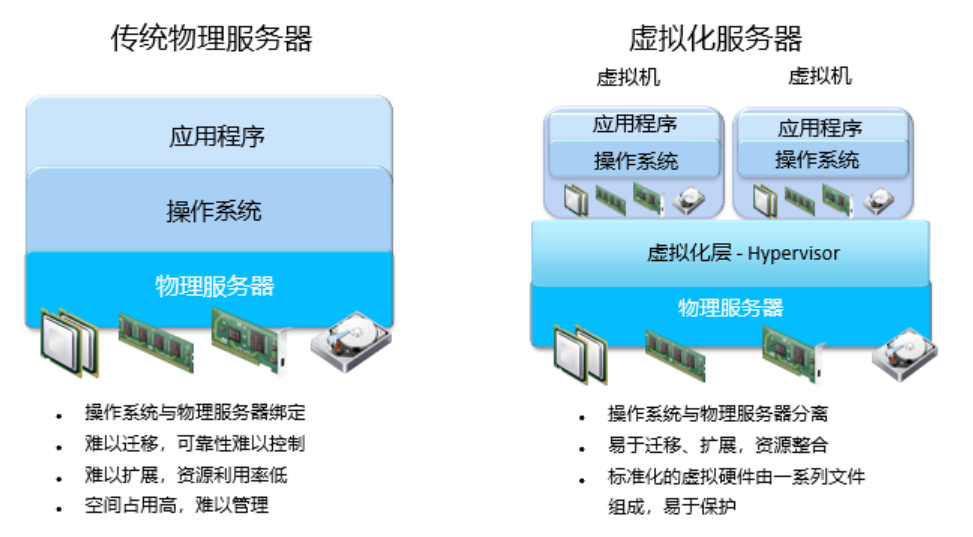
深入分析和讲解虚拟化技术原理
随着云计算和大数据技术的飞速发展,虚拟化技术应运而生,成为数据中心和IT基础设施的重要组成部分。本文将深入分析虚拟化的基本原理、主要类型以及在实际应用中的意义。 一、虚拟化技术的定义 虚拟化技术是通过软件将物理硬件资源抽象成虚拟资源的技术&…...

HarmonyOS Next~鸿蒙图形开发技术解析:AREngine与ArkGraphics 2D的核心能力与应用实践
HarmonyOS Next~鸿蒙图形开发技术解析:AREngine与ArkGraphics 2D的核心能力与应用实践 鸿蒙操作系统(HarmonyOS)在图形开发领域持续创新,其核心图形类Kit——**AREngine(增强现实引擎服务)与Ar…...

Can通信流程
下面给出一个更详细的 CAN 发送报文的程序流程说明,结合 HAL 库的使用及代码示例,帮助你了解每一步的具体操作和内部原理。 一、系统与外设初始化 1.1 HAL 库初始化 在 main() 函数开头,首先调用 HAL 库初始化函数: HAL_Init()…...

小白闯AI:Llama模型Lora中文微调实战
文章目录 0、缘起一、如何对大模型进行微调二、模型微调实战0、准备环境1、准备数据2、模型微调第一步、获取基础的预训练模型第二步:预处理数据集第三步:进行模型微调第四步:将微调后的模型保存到本地4、模型验证5、Ollama集成部署6、结果测试三、使用总结AI是什么?他应该…...

rip 协议详细介绍
以下是关于 RIP(Routing Information Protocol,路由信息协议) 的详细介绍,涵盖其工作原理、版本演进、配置方法、优缺点及实际应用场景。 1. RIP 协议概述 类型:动态路由协议,基于距离矢量算法(…...

同旺科技USB to SPI 适配器 ---- 指令之间延时功能
所需设备: 内附链接 1、同旺科技USB to SPI 适配器 1、指令之间需要延时发送怎么办?循环过程需要延时怎么办?如何定时发送?现在这些都可以轻松解决; 2、只要在 “发送数据” 栏的Delay单元格里面输入相应的延迟时间就…...

2024年MathorCup数学建模D题量子计算在矿山设备配置及运营中的建模应用解题文档与程序
2024年第十四届MathorCup高校数学建模挑战赛 D题 量子计算在矿山设备配置及运营中的建模应用 原题再现: 随着智能技术的发展,智慧矿山的概念越来越受到重视。越来越多的设备供应商正在向智慧矿山整体解决方案供应商转型,是否具备提供整体解…...
)
自动化机器学习(TPOT优化临床试验数据)
目录 自动化机器学习(TPOT优化临床试验数据)1. 引言2. 项目背景与意义2.1 临床试验数据分析的重要性2.2 自动化机器学习的优势2.3 工业级数据处理与GPU加速需求3. 数据集生成与介绍3.1 数据集构成3.2 数据生成方法4. 自动化机器学习与TPOT4.1 自动化机器学习简介4.2 TPOT在临…...

回归——数学公式推导全过程
文章目录 一、案例引入 二、如何求出正确参数 1. 最速下降法 1)多项式回归 2)多重回归 2. 随机梯度下降法 一、案例引入 以Web广告和点击量的关系为例来学习回归,假设投入的广告费和点击量呈现下图对应关系。 思考:如果花了…...

Redisson分布式锁(超时释放及锁续期)
🍓 简介:java系列技术分享(👉持续更新中…🔥) 🍓 初衷:一起学习、一起进步、坚持不懈 🍓 如果文章内容有误与您的想法不一致,欢迎大家在评论区指正🙏 🍓 希望这篇文章对你有所帮助,欢…...

音视频学习(三十):fmp4
FMP4(Fragmented MP4)是 MP4(MPEG-4 Part 14)的扩展版本,它支持流式传输,并被广泛应用于DASH(Dynamic Adaptive Streaming over HTTP)和HLS(HTTP Live Streaming…...
)
【语料数据爬虫】Python爬虫|批量采集讲话稿数据【范文网】(2)
前言 本文是该专栏的第7篇,后面会持续分享Python爬虫采集各种语料数据的的干货知识,值得关注。 本文,笔者将主要介绍基于Python,来实现批量采集范文网“讲话稿”数据。同时,本文也是采集“讲话稿”数据系列的第2篇。 采集相关数据的具体细节部分以及详细思路逻辑,笔者将…...

Java安全-类的动态加载
类的加载过程 先在方法区找class信息,有的话直接调用,没有的话则使用类加载器加载到方法区(静态成员放在静态区,非静态成功放在非静态区),静态代码块在类加载时自动执行代码,非静态的不执行;先父类后子类,…...

内存取证之windows-Volatility 3
一,Volatility 3下载 1.安装Volatility 3。 要求:python3.7以上的版本,我的是3,11,这里不说python的安装方法 使用 pip 安装 Volatility 3: pip install volatility3 安装完成后,验证安装: v…...