python机器学习——新手入门学习笔记
一,概论
1.什么是机器学习
定义:
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
其实就是通过问题和数据,发现规律,并进行预测,与人脑相似。目的就是从历史数据当中获得规律,以及历史数据是什么样的格式
数据集由特征值和目标值构成,每一行数据可以称为样本,有些数据可以没有目标值。
例:
监督学习:
目标值——类别——演变成分类问题
目标值——连续型的数据——演变成回归问题
目标值——无——无监督学习
注:无监督学习的定义:输入数据是由输入特征值所组成
机器学习开发流程:
1.获取数据
2.数据处理
3.特征工程
4.机器学习算法训练到模型
5.模型评估
6.应用
2.数据集
可用数据集
学习阶段可用的数据集:
sklearn
kaggle
ucI
2.1.2 sklearn数据集
(一) scikit-learn数据集API介绍
(1)sklearn.datasets
加载获取流行数据集
(2)datasets.load_*()
获取小规模数据集,数据包含在datasets里
(3)datasets.fetch_*(data_home=None)
获取大规模数据集,需要从网络上下载,函数的第一个参数是 data_home,表示数据集下载的目录,默认是~/scikit_learn_data/
(二)sklearn小数据集
sklearn.datasets.load_iris()3 3sklearn大数据集
sklearn.datasets.fetch_20newsgroups(data home=None,subset='train')
sklearn数据集返回值介绍
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
(1) data:特征数据数组,是[n_samples* n_features]的二维 numpy.ndarray 数组
(2) target:标签数组,是n_samples的一维numpy.ndarray数组。 DESCR:数据描述
(3)feature_names:特征名,新闻数据,手写数字、回归数据集没有。 target_names:标签名
datasets.base.Bunch(继承自字典)
dict["key"l = values bunch.key = values
(三)机器学习一般的数据集会划分为两个部分:
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
训练集:70%80%75%
测试集:30%20% 30%
(四)数据集划分:
sklearn.model_selection.train_test_split(arrays, "options)
x数据集的特征值
y数据集的标签值
test_size测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同
的种子采样结果相同。
return训练集特征值,测试集特征值,训练集目标值,测试集目标值
2.2.2 什么是特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
意义:会直接影响机器学习的效果。
2.2.3特征工程的位置与数据处理的比较
pandas:一个数据读取非常方便以及基本的处理格式的工具
sklearn:对于特征的处理提供了强大的接口
特征工程包含内容:
特征抽取 :
机器学习算法-统计方法
文本类型 -> 数值类型 -> 数值
2.3.1特征提取
sklearn.feature extraction
2.3. 2 字典特征提取->类别 ->one-hot 编码
sklearn.feature_extraction.DictVectorizer(sparse= True,…)
vector 数学:向量。 物理:矢量
矩阵 matrix二维数组
向量 vector 一维数组
父类:转换器类
返回sparse矩阵
spare稀疏:将非0值 表示出来:节省内存—提高加载效率
应用场景:
(1)pclass,sex数据及当中类别特征比较多
1 将数据集的特征->字典类型
2 DictVectorizer转换
(2)本身拿到的数据就是字典类型
2.3.3 文本特征提取
单词作为特征
特征:特征词
方法1:CountVectorizer
统计每个样本特征出现的个数
stop_words停用的
停用词表
关键词:在某一个类别的文章中,出现的次数很多,但是在其他类别的文章当中出现很少
作用:对文本数据进行特征值化
(1)sklearn.feature_extraction.text.CountVectorizer(stop_words=0) 返回词频矩阵
(2)CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象返回值:返回sparse矩阵
(3)CountVectorizer.inverse_transform(X) X:array数组或者sparse矩阵返回值:转换之前数据格
(4)CountVectorizer.get_feature_names()返回值:单词列表
(5)sklearn.feature_extraction.text.TfidfVectorizer
该如何处理某个词或短语在多篇文章中出现的次数高这种情况
方法二:
TfidfVectorizer
Tf-idf文本特征提取
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
公式:词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率
逆向文档频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
tfidf¡,j= tfi,jx idf¡
最终得出结果可以理解为重要程度。
特征预处理 :
2.4.1定义:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
(1)包含内容
数值型数据的无量纲化:
归一化
标准化
特征预处理API:
sklearn.preprocessing
为什么我们要进行归一化/标准化?
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
2.4.2归一化
定义:通过对原始数据进行变换把数据映射到(默认为[0,1])之间
公式:

归一化API:
sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)...)
MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
2.4.3标准化:
1.定义:对原始数据进行变换把数据变换到均值为0,标准差为1范围内
2.公式:

即标准差:集中程度3.标准化API
sklearn.preprocessing.StandardScaler( )
处理之后,对每列来说,所有数据都聚集在均值为0附近,标准差为1。 StandardScaler.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
4.标准化应用场景:
在已有样本足够多的情况下,适合现代嘈杂的大数据场景。
总结:
对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变。
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
特征降维:
2.5降维->降低纬度
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。
2.5.1: ndarray
维数:嵌套的层数
0维 标量
1维 向量
2维 矩阵
3维...n维
处理对象:二维数组
此处的降维:降低随机变量(特征)个数。
效果:特征与特征之间互不相关
2.5.2 特征选择
1定义:数据中包括冗余或相关变量(或称特征属性指标等),旨在从原有特征中找出主要特征。
2方法
Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
方差选择法:低方差特征过滤
相关系数:特征与特征之间的相关程度
取值范围为[-1,+1]
如皮尔逊相关系数
Embedded(嵌入式):算法自动选择特征(特征与目标值之间的关联)
决策树:信息熵、信息增益
正则化:L1、L2
深度学习:卷积等
3模块:
sklearn.feature_selection
4过滤式
4.1低方差特征过滤
4.1.1 API
sklearn.feature_selection.VarianceThreshoid(threshold=0.0)
删除所有低方差特征
Variance.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非。零方差特征,即删除所有样本中具有相同值的特征。
4.2相关系数
4.2.3相关系数特点:
相关系数的值介于-1与+1之间,即-1≤r≤+1。其性质如下:
当r>0时,表示两变量正相关,r<0时,两变量为负相关
当|r|=1时,表示两变量为完全相关,当r=0时,表示两变量间无相关关系
当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r越接近于0,表示两变量的线性相关越弱
一般可按三级划分:|r|<0.4为低度相关;0.4≤|r|<0.7为显著性相关;0.7≤|r|<1为高度线性相关
这个符号:|r|为r的绝对值,|-5|=5
4.2.4 API
from scipy.stats import pearsonr
x:(N,) array_like
y :(N,) array_like Returns: (Pearson's correlation coefficient, p- value)
相关文章:
python机器学习——新手入门学习笔记
一,概论 1.什么是机器学习 定义: 机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。 其实就是通过问题和数据,发现规律,并进行预测,与人脑相似。目的就是从历史数据当中获得规律&#x…...

LabVIEW 与 PLC 通讯的常见方式
在工业自动化和数据采集系统中,PLC(可编程逻辑控制器) 广泛用于控制和监测各种设备,而 LabVIEW 作为强大的图形化编程工具,常用于上位机数据处理和可视化。为了实现 LabVIEW 与 PLC 的高效通讯,常见的方法包…...

深度学习 Deep Learning 第9章 卷积网络 CNN
深度学习 Deep Learning 第9章 卷积网络 章节概述 本章深入探讨了卷积网络的原理、变体及其在深度学习中的应用。卷积网络通过卷积操作实现了参数共享和稀疏连接,显著提高了模型的效率和性能。本章首先介绍了卷积操作的基本形式及其在不同数据维度上的应用&#x…...

Tekton系列之实践篇-从触发到完成的完整执行过程
以下介绍的是基于 Gitee 仓库 的 Tekton 工作流程 操作流程 定义task 克隆代码的task # task-clone.yaml apiVersion: tekton.dev/v1beta1 kind: Task metadata:name: git-clone spec:workspaces:- name: source # 工作目录params:- name: repo-url # 你的 Gitee 仓库地址…...

【简单学习】Prompt Engineering 提示词工程
一、Prompt 1、Prompt 是什么? Prompt 是一种人为构造的输入序列,用于引导 GPT 模型根据先前输入的内容生成相关的输出。简单来说,就是你向模型提供的 “提示词”。 在 ChatGpt 中,我们可以通过设计不同的 prompt,让…...

neo4j删除所有数据
neo4j删除所有数据 一次性删除 MATCH (n) DETACH DELETE n ;分批次删除 先删除关系 MATCH ()-[r]->()WITH r LIMIT 100000DELETE rRETURN count(r)在删除节点 MATCH (n)WITH n LIMIT 100000DELETE nRETURN count(n)验证 查询节点总数 MATCH (n) RETURN count(n) AS node…...

零基础入门网络爬虫第5天:Scrapy框架
4周 Srapy爬虫框架 不是一个简单的函数功能库,而是一个爬虫框架 安装:pip install scrapy 检测:scrapy -h Scrapy爬虫框架结构 爬虫框架 爬虫框架是实现爬虫功能的一个软件结构和功能组件集合爬虫框架是一个半成品,能够帮助…...
)
ARCGIS PRO DSK 栅格数据(Raster)
ArcGIS Pro 中与栅格相关的功能可以在两个单独程序集中的两个命名空间中找到。 1、ArcGIS.Core.dll 中的 ArcGIS.Core.Data.Raster 命名空间提供了栅格类和成员,用于处理栅格数据集、内存栅格、像素块和光标。 2、ArcGIS.Desktop.Mapping.dll 中的 ArcGIS.Desktop.M…...

C#设计模式快速回顾
知识点来源:人间自有韬哥在,豆包 目录 一、七大原则1. 单一职责原则 (Single Responsibility Principle)2. 开放封闭原则 (Open-Closed Principle)3. 里氏替换原则 (Liskov Substitution Principle)4. 接口隔离原则 (Interface Segregation Principle)5…...

分页查询互动问题(用户端)
文章目录 概要整体架构流程技术细节小结 概要 需求分析以及接口设计 技术细节 1.Controller层 GetMapping("/page")ApiOperation("分页查询问题")public PageDTO<QuestionVO> queryQuestionPage(QuestionPageQuery query){return questionService…...

【全队项目】智能学术海报生成系统PosterGenius(项目介绍)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏:🏀大模型实战训练营_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1. 前…...

P5356 [Ynoi Easy Round 2017] 由乃打扑克 Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),有 m m m 个操作分两种: add ( l , r , x ) \operatorname{add}(l,r,x) add(l,r,x):对每个 i ∈ [ l , r ] i\in[l,r] i∈[l,r] 执行 …...

【线程安全问题的原因和方法】【java形式】【图片详解】
在本章节中采用实例图片的方式,以一个学习者的姿态进行描述问题解决问题,更加清晰明了,以及过程中会发问的问题都会一一进行呈现 目录 线程安全演示线程不安全情况图片解释: 将上述代码进行修改【从并行转化成穿行的方式】不会出…...

MySQL-----视图与索引
目录 视图 1.视图 2.操作 11.索引 1.定义 2.优缺点: 3.分类 4.索引的设计原则 5.索引的使用 作业 视图 1.视图 ❓如果需要在原表中隐藏部分字段时,怎么办? 视图 📖视图: 是一个没有存储任何数据的表,可以对其CRUD视图…...

【差分隐私相关概念】约束下的列联表边缘分布计算方法
列联表及其边缘分布的详细解释 一、列联表的定义 列联表(Contingency Table) 是一种用于表示 多个分类变量联合分布 的表格。其核心是通过多维数组记录不同属性组合的频次。以下是关键点: 分类属性: 设有 k k k 个分类属性 A …...

解决IDEA中maven找不到依赖项的问题
直接去官网找到对应的依赖项jar包,并且下载到本地,然后安装到本地厂库中。 Maven官网:https://mvnrepository.com/ 一、使用mvn install:install-file命令 Maven提供了install:install-file插件,用于手动将jar包安装到本地仓库…...

pyside6的QGraphicsView体系,当鼠标位于不同的物体,显示不同的右键菜单
代码: # 设置样本图片的QGraphicsView模型 from PySide6.QtCore import Qt, QRectF, QObject from PySide6.QtGui import QPainter, QPen, QColor, QAction, QMouseEvent from PySide6.QtWidgets import QGraphicsView, QGraphicsScene, QGraphicsPixmapItem, QGra…...

Python自动化测试 之 DrissionPage 的下载、安装、基本使用详解
Python自动化测试 之 DrissionPage 使用详解 🏡前言:一、☀️DrissionPage的基本概述二、 🗺️环境安装2.1 ✅️️运行环境2.2 ✅️️一键安装 三、🗺️快速入门3.1 页面类🛰️ChromiumPage🛫 SessionPage&…...

Java替换jar包中class文件
在更新java应用版本的运维工作中,由于一些原因,开发没办法给到完整的jar包,这个时候,就可以只将修改后的某个Java类的class文件替换掉原来iar包中的class文件,重新启动服务即可: 1、将jar包和将要替换的cl…...

unix网络编程
unix网络编程 AI出来以后,软件不可能找到工作的,就算找到了也在走下坡路。再过几年,机器人发展起来,连流水线都找不到。人为什么整体不值钱,每个部位却很值钱。你说我初中辍学就去开直播结局会不会比现在好。 更新in…...
)
常考计算机操作系统面试习题(一下)
目录 操作系统基本类型 操作系统的功能 操作系统的主要任务 进程与线程 进程状态转变 内存管理 文件系统与文件管理 虚拟存储器 设备管理 磁盘调度 死锁 信号量机制 文件打开与管理 进程与线程的互斥与同步 进程同步 进程调度 文件分配磁盘块的方法 程序执行…...

2025_0321_生活记录
刚刚写完待会儿早上要汇报的文档,看了一眼时间,现在已经是凌晨2点多了。一直说要早睡,但是一直都没做到。。。算了,不苛求自己了。 昨天是春分,春分秋分,昼夜平分。不知不觉就到春天了,但房间里…...
)
三层网络 (服务器1 和 服务器2 在不同网段)
服务器1 和 服务器2 在不同网段,并且通过三层交换机实现通信 1. 网络拓扑 假设网络拓扑如下: 服务器1: mac0:IP 地址 192.168.1.10/24,网关 192.168.1.1 mac1:IP 地址 10.0.1.10/24,网关 10.0…...

AI Tokenization
AI Tokenization 人工智能分词初步了解 类似现在这个,一格子 一格子,拼接出来的,一行或者一句,像不像,我们人类思考的时候组装出来的话,并用嘴说出来了呢。...

关于大数据的基础知识(四)——大数据的意义与趋势
成长路上不孤单😊😊😊😊😊😊 【14后😊///计算机爱好者😊///持续分享所学😊///如有需要欢迎收藏转发///😊】 今日分享关于大数据的基础知识(四&a…...

某视频的解密下载
下面讲一下怎么爬取视频,这个还是比小白的稍微有一点绕的 首先打开网址:aHR0cDovL3d3dy5wZWFydmlkZW8uY29tL3BvcHVsYXJfNA 首页 看一下: 有一个标题和一个href,href只是一个片段,待会肯定要拼接, 先找一…...
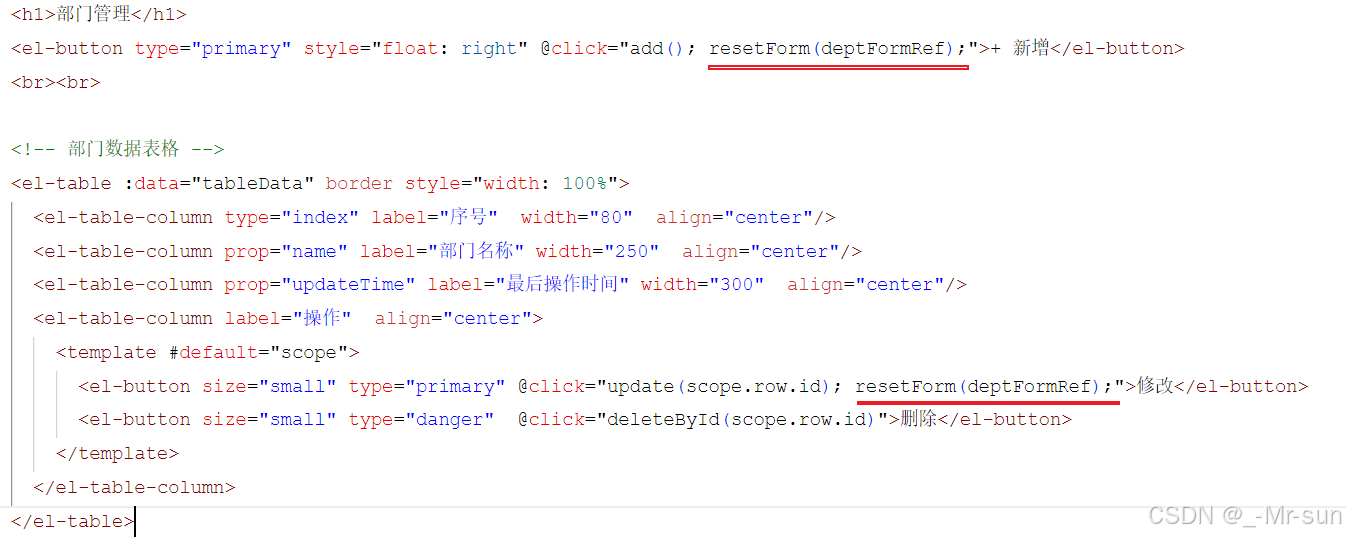
Day20-前端Web案例——部门管理
目录 部门管理1. 前后端分离开发2. 准备工作2.1 创建Vue项目2.2 安装依赖2.3 精简项目 3. 页面布局3.1 介绍3.2 整体布局3.3 左侧菜单 4. Vue Router4.1 介绍4.2 入门4.3 案例4.4 首页制作 5. 部门管理5.1部门列表5.1.1. 基本布局5.1.2 加载数据5.1.3 程序优化 5.2 新增部门5.3…...

从切图仔到鸿蒙开发01-文本样式
从切图仔到鸿蒙开发01-文本样式 本系列教程适合 HarmonyOS 初学者,为那些熟悉用 HTML 与 CSS 语法的 Web 前端开发者准备的。 本系列教程会将 HTML/CSS 代码片段替换为等价的 HarmonyOS/ArkUI 代码。 页面结构 HTML 与 ArkUI 在 Web 开发中,HTML 文档结…...

菱形虚拟继承的原理
一 :菱形继承的问题 普通的菱形继承存在数据冗余和二义性的问题 ,如下代码: class Person { public:string _name; //姓名 };class Student : public Person { protected:int _num; //学号 };class Teacher : public Person { protected:int…...

【数据结构】C语言实现树和森林的遍历
C语言实现树和森林的遍历 导读一、树的遍历二、森林的遍历2.1 为什么森林没有后序遍历?2.2 森林中存不存在层序遍历?三、C语言实现3.1 准备工作3.2 数据结构的选择3.3 树与森林的创建3.4 树与森林的遍历3.4.1 先根遍历3.4.2 后根遍历3.4.3 森林的遍历3.5 树与森林的销毁3.6 算…...