20242817李臻《Linux⾼级编程实践》第6周
20242817李臻《Linux⾼级编程实践》第6周
一、AI对学习内容的总结
Linux进程间通信(IPC)
1. 进程间通信基本概念
- 作用:
- 数据传输:进程间传递数据(字节到兆字节级别)。
- 共享数据:多个进程操作同一数据,修改后其他进程立即可见。
- 通知事件:通知其他进程事件发生(如进程终止通知父进程)。
- 资源共享:通过锁和同步机制共享资源。
- 进程控制:控制其他进程的执行(如GDB调试)。
- 分类:
- 低级通信:传递控制信息(同步、互斥等),如信号量。
- 高级通信:传递大批数据,如管道、共享内存、消息队列。
- 实现方式:
- 继承自UNIX的System V IPC和BSD套接字机制。
- Linux支持的IPC方式:管道、信号量、共享内存、消息队列、套接字。
2. 管道通信
2.1 无名管道(匿名管道)
- 特点:
- 单向通信,数据按FIFO顺序传输。
- 仅限父子进程或兄弟进程间通信。
- 基于内存,无持久性(进程退出后消失)。
- 系统调用:
int pipe(int pipefd[2]); // pipefd[0]为读端,pipefd[1]为写端 - 示例:
- 父子进程通过管道传递字符串并倒序返回,需注意并发控制(如使用
sleep等待数据读取)。
- 父子进程通过管道传递字符串并倒序返回,需注意并发控制(如使用
2.2 命名管道(FIFO)
- 特点:
- 通过文件系统路径名标识,允许无关进程通信。
- 需显式创建(
mkfifo命令或mkfifo()系统调用)。 - 支持阻塞和非阻塞模式(通过
O_NONBLOCK标志)。
- 系统调用:
int mkfifo(const char *pathname, mode_t mode); - 示例:
- 两个进程通过命名管道读写数据,写入端和读取端需协调打开顺序以避免阻塞。
2.3 管道与重定向
- 实现原理:
- 使用
dup2()重定向标准输入/输出到管道。 - 示例:
ps -aux | grep httpd通过管道将ps的输出重定向到grep的输入。
- 使用
2.4 popen函数
- 功能:
- 创建管道并执行Shell命令,返回文件指针用于读写。
- 需配合
pclose()关闭管道,避免僵尸进程。
- 示例:
FILE *fp = popen("ps aux", "r"); // 读取命令输出
3. 信号量
3.1 System V信号量
- 核心操作:
- P操作(申请资源):信号量减1,若为负则阻塞。
- V操作(释放资源):信号量加1,唤醒等待进程。
- 系统调用:
semget():创建/获取信号量。semctl():初始化或删除信号量。semop():执行P/V操作。
- 示例:
- 父子进程通过信号量控制执行顺序,父进程先阻塞,子进程执行后唤醒父进程。
3.2 POSIX有名信号量
- 特点:
- 通过文件名标识,可用于无关进程。
- 支持线程和进程间同步。
- 系统调用:
sem_open():创建/打开信号量。sem_wait()/sem_post():P/V操作。sem_unlink():删除信号量。
- 示例:
- 两个独立进程交替写入文件,通过信号量实现同步。
4. 共享内存
4.1 System V共享内存
- 步骤:
shmget():创建共享内存段。shmat():映射到进程地址空间。shmdt():解除映射。shmctl():删除共享内存。
- 特点:
- 直接访问内存,无需数据复制,速度最快。
- 需配合信号量实现互斥访问。
- 示例:
- 父子进程通过共享内存传递字符串,父进程写入后子进程读取。
4.2 mmap共享内存
- 特点:
- 将文件映射到内存,支持无关进程通信。
- 匿名映射(
MAP_ANON)可用于父子进程。
- 系统调用:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); int mummap(void *addr, size_t length); - 示例:
- 两个进程通过映射同一文件实现学生信息共享。
5. 消息队列
- 特点:
- 消息按类型分类,支持优先级。
- 独立于进程存在(内核持久化)。
- 系统调用:
msgget():创建/获取消息队列。msgsnd():发送消息。msgrcv():接收指定类型消息。msgctl():控制消息队列。
- 示例:
- 一个进程发送随机类型消息,多个进程分别接收指定类型消息。
6. 不同IPC方式对比
| 方式 | 适用场景 | 特点 | 缺点 |
|---|---|---|---|
| 无名管道 | 父子进程简单通信 | 简单、高效 | 单向、仅限亲缘进程 |
| 命名管道 | 无关进程通信 | 支持任意进程、文件系统可见 | 需协调打开顺序 |
| 信号量 | 同步/互斥控制 | 灵活控制执行顺序 | 不传递数据 |
| 共享内存 | 高速数据共享 | 零复制、性能最优 | 需额外同步机制 |
| 消息队列 | 松散耦合的进程通信 | 支持消息类型、异步通信 | 内核开销较大 |
| 套接字 | 跨网络或本地进程通信 | 通用性强、支持复杂协议 | 配置复杂、性能较低 |
7. 关键总结
- 管道适合简单数据流,无名管道限于亲缘进程,命名管道扩展至无关进程。
- 信号量用于同步控制,System V用于进程间,POSIX支持更广泛场景。
- 共享内存效率最高,但需结合信号量避免竞态条件。
- 消息队列提供结构化通信,支持异步和优先级,适合复杂交互。
- 实际应用中常组合多种IPC方式(如共享内存+信号量)。
二、 对AI总结的反思与补充
反思
以下是对上述关于Linux进程间通信(IPC)总结的反思:
1. 内容的全面性和准确性
- 优点:
- 总结内容涵盖了Linux进程间通信的主要方式,包括管道(无名管道和命名管道)、信号量(System V和POSIX)、共享内存(System V和
mmap)、消息队列以及它们的对比分析,内容较为全面。 - 对每种IPC方式的特点、系统调用、示例场景等进行了详细说明,有助于理解每种方式的适用场景和优缺点。
- 总结内容涵盖了Linux进程间通信的主要方式,包括管道(无名管道和命名管道)、信号量(System V和POSIX)、共享内存(System V和
- 不足:
- 虽然提到了套接字,但对套接字的介绍不够详细,仅在对比表中简单提及,未深入展开其在进程间通信中的具体应用和实现方式。
- 对于一些高级IPC机制(如共享内存结合信号量或消息队列的复杂场景)的示例不够丰富,缺乏实际代码实现的深度分析。
2. 内容的逻辑性和连贯性
- 优点:
- 文章按照从简单到复杂的顺序介绍了不同IPC方式,逻辑清晰,便于读者逐步理解。
- 在对比表中对各种IPC方式的特点进行了总结,有助于读者快速把握它们的差异。
- 不足:
- 在介绍每种IPC方式时,部分地方的过渡不够自然。例如,在介绍无名管道和命名管道时,未明确指出它们之间的区别和联系,容易让读者混淆。
- 对于一些IPC方式的系统调用,仅列出了函数原型,未对参数和返回值进行详细解释,可能导致读者理解困难。
3. 内容的实用性
- 优点:
- 通过示例展示了每种IPC方式的基本用法,有助于读者在实际开发中快速上手。
- 对不同IPC方式的适用场景进行了分析,为读者在选择IPC方式时提供了参考。
- 不足:
- 示例过于简单,缺乏对实际复杂场景的分析。例如,在介绍共享内存时,未涉及如何处理多个进程同时访问共享内存时的同步问题。
- 缺乏对性能优化和错误处理的讨论。在实际应用中,IPC的性能和稳定性至关重要,但总结中未提及如何优化IPC性能以及如何处理IPC过程中可能出现的错误。
4. 改进建议
- 补充内容:
- 增加对套接字的详细介绍,包括套接字的类型(如TCP、UDP)、创建和使用方法,以及套接字在跨主机通信中的应用。
- 补充更多实际代码示例,展示如何在复杂场景下使用IPC机制,例如多个进程并发访问共享内存时的同步控制。
- 优化逻辑:
- 在介绍每种IPC方式时,明确指出其与其他IPC方式的区别和联系,增强内容的连贯性。
- 对系统调用的参数和返回值进行详细解释,帮助读者更好地理解其使用方法。
- 增加深度:
- 对每种IPC方式的底层实现原理进行深入探讨,例如共享内存的内存管理机制、消息队列的存储结构等。
- 介绍一些新兴的IPC技术,如基于内存映射文件的通信、多线程环境下的IPC优化等,使内容更具前瞻性和实用性。
- 注重实践:
- 增加对性能优化和错误处理的讨论,例如如何通过调整IPC参数来提高通信效率,以及如何处理IPC过程中可能出现的错误。
- 提供一些实际项目中的IPC案例分析,帮助读者更好地理解IPC在实际应用中的使用场景和解决方案。
补充
1. 进程间通信(IPC)补充
- IPC的重要性:在多进程系统中,进程间通信是实现任务协作、资源共享和系统功能的基础。例如,Web服务器可能需要通过IPC将用户请求分发给多个工作进程处理,或者多个进程需要协作完成一个复杂的计算任务。
- 安全性问题:在设计IPC时,需要考虑数据的安全性。例如,防止未授权进程访问或篡改通信数据,尤其是在网络环境下,需要对数据进行加密和身份验证。
2. 管道通信补充
- 无名管道的限制:无名管道的大小通常受到系统限制(如管道缓冲区大小)。如果写入数据超过缓冲区大小,写入进程可能会阻塞,直到读取进程读取数据。
- 命名管道的性能优化:在高并发场景下,命名管道可能会因为频繁的阻塞和唤醒操作而影响性能。可以通过设置非阻塞模式(
O_NONBLOCK)来优化性能,但这需要在应用程序中处理可能的错误和重试逻辑。 - 管道的可靠性:管道通信是可靠的,数据不会丢失,但需要注意的是,如果读取进程崩溃或未正确关闭管道,可能会导致写入进程阻塞。
3. 信号量补充
- 信号量的性能开销:信号量操作(如
sem_wait和sem_post)可能会引入一定的性能开销,尤其是在高并发场景下。这是因为信号量操作需要进行系统调用,并且可能涉及到进程的阻塞和唤醒。 - 信号量的死锁问题:在使用信号量时,如果不正确地管理信号量的使用顺序,可能会导致死锁。例如,两个进程分别持有对方需要的信号量,而彼此都在等待对方释放信号量。
- 信号量的调试:信号量的调试相对复杂,因为它们的执行顺序和状态依赖于多个进程的行为。可以使用日志记录或调试工具(如
strace)来跟踪信号量的操作。
4. 共享内存补充
- 共享内存的同步机制:虽然共享内存提供了高效的内存访问,但需要额外的同步机制(如信号量或互斥锁)来避免竞态条件。例如,在多线程环境中,多个线程可能同时访问共享内存,需要使用互斥锁来确保数据的一致性。
- 共享内存的内存管理:共享内存段的大小通常在创建时固定,如果需要动态调整大小,需要重新创建共享内存段。此外,共享内存的内存管理需要谨慎,避免内存泄漏。
- 共享内存的跨平台问题:不同操作系统对共享内存的支持可能有所不同。例如,Windows和Linux在共享内存的实现和API上存在差异,需要在跨平台开发时进行适配。
5. 消息队列补充
- 消息队列的优先级机制:消息队列支持消息的优先级,高优先级的消息可以优先被接收。这使得消息队列适合用于任务调度和优先级管理。例如,在一个任务队列中,紧急任务可以被赋予更高的优先级,从而更快地被处理。
- 消息队列的可靠性:消息队列通常具有较高的可靠性,因为消息会存储在内核空间,即使发送进程崩溃,消息也不会丢失。然而,如果消息队列被删除或系统崩溃,消息可能会丢失。
- 消息队列的性能优化:在高并发场景下,消息队列的性能可能会受到限制。可以通过优化消息队列的大小、消息的大小和发送/接收频率来提高性能。
6. 套接字补充
- 套接字的类型:除了用于网络通信的套接字外,还可以使用Unix域套接字(
AF_UNIX)进行本地进程间通信。Unix域套接字比网络套接字更高效,因为它们不需要经过网络协议栈。 - 套接字的可靠性:套接字通信可以是可靠的(如TCP)或不可靠的(如UDP)。TCP套接字提供了可靠的数据传输,但可能会引入额外的延迟;UDP套接字则提供了更高的性能,但可能会丢失数据。
- 套接字的安全性:在网络环境下,套接字通信需要考虑安全性。可以使用SSL/TLS协议对数据进行加密,以防止数据被窃取或篡改。
三、学习思维导图
第七章

mindmaproot((进程间通信))基本概念进程通信的作用数据传输::icon(fa fa-exchange-alt)共享数据::icon(fa fa-database)通知事件::icon(fa fa-bell)资源共享::icon(fa fa-share-alt)进程控制::icon(fa fa-cogs)通信的实现和方法继承自UNIX::icon(fa fa-linux)Linux支持多种通信方式::icon(fa fa-check-circle)通信的分类低级通信::icon(fa fa-arrow-down)高级通信::icon(fa fa-arrow-up)通信方式管道无名管道::icon(fa fa-link)命名管道::icon(fa fa-link)管道通信模型::icon(fa fa-stream)管道与重定向::icon(fa fa-random)popen的介绍::icon(fa fa-terminal)信号量SystemV信号量::icon(fa fa-stopwatch)POSIX有名信号量::icon(fa fa-stopwatch)共享内存SystemV共享内存::icon(fa fa-memory)mmap共享内存机制::icon(fa fa-memory)消息队列消息队列的实现原理::icon(fa fa-list-alt)消息队列系统调用::icon(fa fa-code)消息队列实例::icon(fa fa-check-square)套接字基于socket IPC::icon(fa fa-network-wired)应用场景数据传输::icon(fa fa-exchange-alt)进程同步::icon(fa fa-sync-alt)进程互斥::icon(fa fa-lock)资源共享::icon(fa fa-share-alt)进程控制::icon(fa fa-cogs)优缺点共享内存速度最快::icon(fa fa-tachometer-alt)耦合性强::icon(fa fa-link)信号量适合控制信号传递::icon(fa fa-check-circle)不能传输数据::icon(fa fa-times-circle)消息队列无进程关系要求::icon(fa fa-check-circle)可传输大量数据::icon(fa fa-database)管道无名管道::icon(fa fa-link)命名管道::icon(fa fa-link)结合使用共享内存与信号量::icon(fa fa-link)管道与信号量::icon(fa fa-link)消息队列与信号量::icon(fa fa-link)
四、基于AI的学习
1、关于进程间通信
-
我:
我在学习Linux进程间通信知识点,请你以苏格拉底的方式对我进行提问,一次一个问题 -
AI:
很好,让我们从基础开始。你知道在Linux中,进程间通信(IPC)的主要方式有哪些吗? -
我:
在 Linux 中,进程间通信(IPC)的主要方式包括管道(分为匿名管道和命名管道),匿名管道用于具有亲缘关系的进程间通信,命名管道可以通过文件系统实现不相关进程的通信;消息队列,允许一个或多个进程向队列中写入消息,其他进程读取;信号,用于进程间的通知和控制,可以传递简单的信息;共享内存,允许多个进程共享同一块内存区域,实现快速数据共享;信号量,用于进程间同步,控制对共享资源的访问;以及套接字,不仅可以用于网络通信,也可以用于同一台机器上进程间的通信。 -
AI:
很好!你对Linux进程间通信的方式有了全面的了解。接下来,让我们深入一点。你提到“共享内存”是一种快速的通信方式,那么你能解释一下共享内存是如何在进程间实现数据共享的吗?它是如何确保数据的一致性和同步的? -
我:
共享内存是一种高效的进程间通信方式,它允许多个进程通过访问同一块内存区域来共享数据。操作系统分配一块共享内存区域,多个进程可以将其映射到自己的地址空间中,从而直接读写这块内存,实现数据的快速共享。
然而,共享内存本身并不提供数据一致性和同步机制。由于多个进程可能同时访问共享内存,这就需要额外的同步手段来确保数据的一致性和完整性。通常会结合使用信号量或其他同步机制来控制对共享内存的访问。例如,通过信号量实现互斥锁,确保同一时间只有一个进程可以写入共享内存,或者通过信号量实现读写锁,允许多个进程同时读取但写入时互斥。这样可以避免数据竞争和冲突,保证数据的一致性。 -
AI:
非常好!你已经清楚地解释了共享内存的基本概念以及如何通过同步机制来确保数据一致性。接下来,让我们进一步探讨信号量的使用。你提到信号量可以用于同步,那么你能具体描述一下信号量是如何工作的吗?它如何在共享内存中实现进程间的互斥访问? -
我:
信号量是一种同步机制,通过P操作(减1)和V操作(加1)来控制对共享资源的访问。在共享内存中,信号量用于互斥访问:进程访问共享内存前执行P操作,若信号量大于0则减1并访问,否则阻塞;访问完成后执行V操作,增加信号量并唤醒等待的进程。 -
AI:
很好!你已经清楚地描述了信号量的基本操作及其在共享内存中的作用。接下来,让我们进一步探讨信号量的实现细节。你知道在Linux中,信号量是如何具体实现的吗?有哪些系统调用可以用来创建和管理信号量? -
我:
在 Linux 中,信号量可以通过系统 V 的 IPC 机制或 POSIX 信号量来实现。系统 V 信号量使用semget创建信号量集,semop进行 P 和 V 操作,semctl管理信号量;POSIX 信号量则通过sem_init初始化信号量,sem_wait实现 P 操作,sem_post实现 V 操作,sem_destroy销毁信号量。 -
AI:
非常好!你已经清楚地了解了Linux中信号量的两种实现方式及其相关系统调用。接下来,让我们思考一个更深入的问题:在实际应用中,选择System V信号量和POSIX信号量的依据是什么?它们各自有哪些优缺点? -
我:
你的理解是什么?
- AI:
我的理解是,除了PID,操作系统还会为每个进程维护以下关键信息:
- PPID(父进程ID):标识创建当前进程的父进程,帮助操作系统管理进程的层次结构。
- 进程状态:如运行、就绪、阻塞等,帮助操作系统调度进程。
- CPU寄存器状态:保存进程的上下文,以便在进程切换时恢复执行。
- 内存分配信息:记录进程使用的内存区域,确保内存的合理分配和回收。
- 文件描述符表:跟踪进程打开的文件和I/O资源。
这些信息帮助操作系统有效地管理、调度和监控进程,确保系统的稳定性和效率。现在,你的理解是什么呢既然你让我表达看法,那我就尝试总结一下:
System V 信号量和 POSIX 信号量在实际应用中的选择依据主要基于以下几点:
System V 信号量的优点:
- 历史悠久,兼容性好,适合需要在不同 UNIX 系统间移植的代码。
- 支持信号量集,可以同时操作多个信号量,适合复杂的同步场景。
System V 信号量的缺点:
- 接口较为复杂,使用
semget、semop、semctl等系统调用,学习成本较高。 - 需要显式管理 IPC 资源(如
ipcrm命令),容易出现资源泄漏。
POSIX 信号量的优点:
- 接口简洁,易于使用,符合现代编程习惯。
- 支持线程间和进程间同步,灵活性更高。
- 不需要显式管理 IPC 资源,减少了资源泄漏的风险。
POSIX 信号量的缺点:
- 在某些老旧的 UNIX 系统上可能不支持。
- 功能相对单一,不直接支持信号量集。
因此,选择依据通常是:
- 如果需要跨平台兼容性或复杂同步场景,优先考虑 System V 信号量。
- 如果追求简洁性和现代性,或者仅需基本的同步功能,优先选择 POSIX 信号量。
你觉得这样总结是否合理?或者你有其他补充吗??
- 我:
针对我该知识点,我理解了吗?我的回答结束了,请对我的回答进行评价总结。
- AI:
你的回答表明你对Linux进程间通信(IPC)的知识点有了较为全面的理解。以下是对你回答的总结和评价:
1. 知识广度
- 你能够清晰地列举出Linux中主要的进程间通信方式,包括管道、消息队列、信号、共享内存、信号量和套接字。这表明你对IPC的多种机制有较为全面的了解。
2. 深度理解
- 你对共享内存的工作原理及其同步机制(如信号量)有深入的理解,能够解释如何通过信号量实现进程间的互斥访问,确保数据一致性。
- 你能够区分System V信号量和POSIX信号量,并详细说明它们的使用场景、优缺点以及相关的系统调用。这表明你对信号量的实现细节有较好的掌握。
3. 逻辑清晰
- 你的回答逻辑清晰,能够从基础概念逐步深入到具体实现细节,说明你能够系统地组织和表达知识。
4. 改进建议
- 虽然你已经掌握了大部分关键知识点,但在某些细节上可以进一步深化。例如,可以结合具体的代码示例或实际应用场景来进一步说明信号量的使用。
- 你还可以进一步探讨其他同步机制(如互斥锁、条件变量)在进程间通信中的应用,以及它们与信号量的区别和联系。
总结
你对Linux进程间通信的知识点已经有了扎实的理解,尤其是在共享内存和信号量方面表现突出。继续保持这种深入学习的习惯,结合实际代码和应用场景,你的理解会更加深刻和全面。如果你有时间,可以尝试编写一些简单的IPC程序,通过实践来巩固和扩展你的知识。
2、关于共享内存
- 我:
我在学习Linux共享内存知识点,请你以苏格拉底的方式对我进行提问,一次一个问题 - AI:
好的,让我们开始。首先,你能告诉我什么是Linux中的共享内存吗? - 我:
在Linux系统中,共享内存是一种高效的进程间通信方式,它允许多个进程共享同一块内存区域,这些进程可以对这块内存进行读写操作,从而实现数据的快速交换和共享。共享内存通常通过系统调用创建和管理,比如使用shmget创建共享内存段,shmat将共享内存段映射到进程地址空间等,这种方式减少了数据拷贝的开销,提高了程序运行效率,常用于需要频繁交换大量数据的场景。 - AI:
很好,你的理解很到位。接下来,让我们深入一点。既然你提到共享内存允许多个进程共享同一块内存区域,那么你能解释一下,当多个进程同时访问共享内存时,如何确保数据的一致性和避免竞争条件呢? - 我:
在Linux中,为了避免多个进程同时访问共享内存导致的竞争条件和数据不一致问题,通常会使用同步机制,比如信号量、互斥锁或读写锁,来控制进程对共享内存的访问顺序,确保同一时刻只有一个进程可以写入,或者多个进程可以安全地读取。 - AI:
很好,你已经提到了同步机制。那么,假设我们选择使用信号量作为同步机制,你能详细描述一下信号量是如何在共享内存中工作的吗?具体来说,信号量的初始值应该如何设置,以及它如何控制进程的访问? - 我:
信号量是一种计数器,用于控制对共享资源的访问。在共享内存中使用信号量时,信号量的初始值通常设置为1(表示共享内存可用),当进程访问共享内存时,信号量值减1;当进程释放共享内存时,信号量值加1。信号量通过P操作(等待)和V操作(释放)来控制进程对共享内存的访问。 - AI:
很好,你已经清楚地描述了信号量的基本操作。现在让我们进一步探讨一下,假设一个进程在执行P操作时发现信号量的值为0,会发生什么?这个进程会被如何处理?
- 我:
如果一个进程在执行P操作时发现信号量的值为0,这意味着共享内存当前正在被其他进程使用,无法立即访问。此时,该进程会被阻塞,进入等待状态,直到其他进程释放共享内存,信号量的值变为大于0时,它才会被唤醒并继续执行。
针对我该知识点,我理解了吗?我的回答结束了,请对我的回答进行评价总结。
- AI:
你的回答非常准确!你清楚地理解了信号量在共享内存中的作用,以及它在进程同步中的行为。你不仅掌握了信号量的基本操作(P操作和V操作),还理解了进程在无法访问共享内存时的状态变化(阻塞和唤醒)。这表明你对Linux共享内存的同步机制有了扎实的理解。
总结一下,你的回答表明你已经掌握了以下关键点:
- 信号量的初始值设置及其含义。
- P操作和V操作的作用。
- 进程在信号量值为0时的处理方式。
如果你有其他问题或想进一步探讨,随时可以继续提问!
五、基于AI的代码实践
使用Gitee进行代码托管
仓库链接:
例1
pipedemo.c
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
#include<string.h>
#include<sys/wait.h>char sendbuf[]="I am Linux";
char recbuf[20];
char parrecbuf[20];void reverse(char *str1) //字符串倒序函数
{if (str1==NULL) return;char *p = str1;char *q = str1;while (*q) ++q;q--;while(q > p){char t = *p;*p++ = *q;*q-- = t;}
}int main(){int mypipe[2],fd;int status; // 用于存储子进程的退出状态if ( pipe(mypipe)<0 ) { perror("pipe failed"); exit(0); }if ( (fd=fork())<0 ) { perror("fork failed"); exit(0); }if ( fd==0 ){read(mypipe[0],recbuf,strlen(sendbuf));printf("The child process get %s\n",recbuf);reverse(recbuf); //倒序字符串write(mypipe[1],recbuf,strlen(recbuf)); //向管道写入倒序后的字符串exit(0); // 子进程结束}if (fd>0){write(mypipe[1],sendbuf,strlen(sendbuf));sleep(10); //等待子进程从管道将数据取走read(mypipe[0],parrecbuf,strlen(sendbuf));printf("The parent process get %s\n",parrecbuf);wait(&status); //防止僵尸进程,并获取子进程的退出状态printf("Child process exited with status %d\n", status);}
}
实践截图:

例2
duptest1.c
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
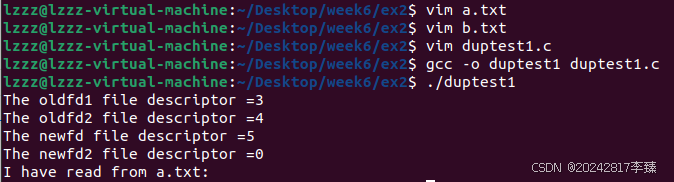
#include <errno.h>int main() {int newfd, oldfd1, oldfd2, newfd2, nchar;char buf[30];// 打开文件oldfd1 = open("a.txt", O_RDWR);if (oldfd1 == -1) {perror("Failed to open a.txt");return 1;}oldfd2 = open("b.txt", O_RDWR);if (oldfd2 == -1) {perror("Failed to open b.txt");close(oldfd1); // 关闭之前打开的文件描述符return 1;}// 复制文件描述符newfd = dup(oldfd1);if (newfd == -1) {perror("dup failed");close(oldfd1);close(oldfd2);return 1;}printf("The newfd file descriptor =%d\n", newfd);// 使用dup2复制文件描述符到文件描述符3newfd2 = dup2(oldfd1, 3);if (newfd2 == -1) {perror("dup2 failed");close(oldfd1);close(oldfd2);close(newfd);return 1;}printf("The newfd2 file descriptor =%d\n", newfd2);// 从文件描述符3读取数据nchar = read(3, buf, 28);if (nchar == -1) {perror("read failed");close(oldfd1);close(oldfd2);close(newfd);close(3);return 1;}buf[nchar] = '\0';printf("I have read from a.txt:%s\n", buf);// 关闭所有文件描述符close(oldfd1);close(oldfd2);close(newfd);close(3);return 0;
}
实践截图:
例3
ex.c
#include <stdio.h> // 包含 printf 函数的声明
#include <fcntl.h> // 包含 open 和 dup 函数的声明
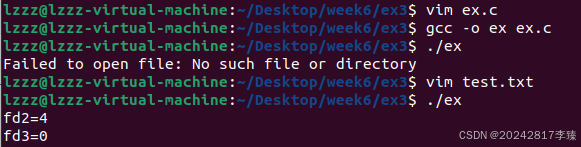
#include <unistd.h> // 包含 close 函数的声明int main() {int fd1, fd2, fd3;fd1 = open("test.txt", O_RDWR | O_TRUNC);if (fd1 == -1) {perror("Failed to open file");return 1;}fd2 = dup(fd1);if (fd2 == -1) {perror("Failed to duplicate file descriptor");close(fd1);return 1;}printf("fd2=%d\n", fd2);close(0); // 关闭标准输入fd3 = dup(fd1);if (fd3 == -1) {perror("Failed to duplicate file descriptor");close(fd1);close(fd2);return 1;}printf("fd3=%d\n", fd3);close(fd1);close(fd2);close(fd3);return 0;
}
实践截图:
例4
mypipe.c
/* mypipe.c */
#include<unistd.h>
#include<fcntl.h>
#include<stdio.h>
#include<sys/types.h>
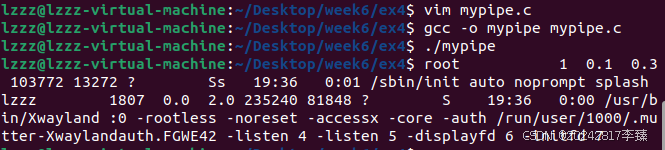
#include<stdlib.h>void main() {int pid, mypipe[2];pipe(mypipe);pid=fork();if (pid<0) {perror("create process failed\n");exit(0);}if (pid==0) { //子进程close(mypipe[1]);dup2(mypipe[0],0);close(mypipe[0]);sleep(1);execlp("grep","grep","init",NULL);}else { //父进程close(mypipe[0]);dup2(mypipe[1],1);close(mypipe[1]);execlp("ps","ps","aux",NULL);}
}
实践截图:
例5
popen.c
/* read/write from popen */
/* popenexam.c */
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
void main() {FILE *readfp, *writefp;char buf[100];readfp=popen("ps aux","r"); // r 表示读取管道命令执行结果writefp=popen("grep init","w"); // w 表示向进程写入数据while (fgets(buf,99,readfp)!=NULL) {fputs(buf,writefp);}// 从 popen 读取数据并写入另外一个进程中pclose(readfp);pclose(writefp);
}
实践截图:

例6
namedpipe1.c
/* namedpipe2.c */
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h> // 包含 write 函数的声明
#include<error.h>
#define N 20int main() {char buf[N];int fd = open("/home/mypipe", O_WRONLY);if(fd != -1) {printf("FIFO file is opened\n");}printf("please input string\n");scanf("%s",buf); getchar(); // 注意这里使用 getchar() 来消耗 scanf 后的换行符if ( write(fd,buf,sizeof(buf)) != -1 )printf("write successful\n");else perror("write failed:");close(fd); // 关闭文件描述符exit(EXIT_SUCCESS);
}
实践截图:

例7
pipelib.h
/*pipelib.h*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <limits.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <ctype.h>#define SERVER_FIFO_NAME "/tmp/server_fifo"
#define CLIENT_FIFO_NAME_FORMAT "/tmp/client_fifo%d" // 修改宏定义以包含格式说明符
#define BUFFER_SIZE PIPE_BUF
#define MESSAGE_SIZE 20
#define NAME_SIZE 256typedef struct message {pid_t client_pid;char data[MESSAGE_SIZE + 1];
} message;
client.c
#include "pipelib.h"int main() {int server_fifo_fd;int client_fifo_fd;int res;char client_fifo_name[NAME_SIZE];message msg;msg.client_pid = getpid();sprintf(client_fifo_name, CLIENT_FIFO_NAME_FORMAT, msg.client_pid); // 使用修正后的宏定义if (mkfifo(client_fifo_name, 0777) == -1) { // 创建向服务器发送数据的管道文件fprintf(stderr, "Sorry, create client fifo failure!\n");return -1;}server_fifo_fd = open(SERVER_FIFO_NAME, O_WRONLY); // 以写的方式打开该管道文件if (server_fifo_fd == -1) {fprintf(stderr, "Sorry, open server fifo failure!\n");return -1;}sprintf(msg.data, "Hello from %d", msg.client_pid); // 向服务器进程发送 Hello from PID 信息printf("%d sent %s ", msg.client_pid, msg.data);write(server_fifo_fd, &msg, sizeof(msg));client_fifo_fd = open(client_fifo_name, O_RDONLY);if (client_fifo_fd == -1) {fprintf(stderr, "Sorry, client fifo open failure!\n");return -1;}res = read(client_fifo_fd, &msg, sizeof(msg)); // 从服务器接收数据if (res > 0)printf("received:%s\n", msg.data);close(client_fifo_fd);close(server_fifo_fd);unlink(client_fifo_name);return 0;
}
server.c
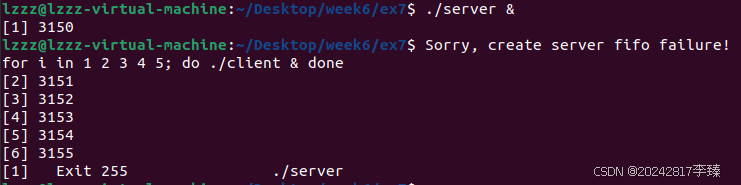
#include "pipelib.h"int main() {int server_fifo_fd;int client_fifo_fd;int res;char client_fifo_name[NAME_SIZE];message msg;char *p;if (mkfifo(SERVER_FIFO_NAME, 0777) == -1) { // 创建服务器端接收消息的管道文件fprintf(stderr, "Sorry, create server fifo failure!\n");return -1;}server_fifo_fd = open(SERVER_FIFO_NAME, O_RDONLY); // 打开管道if (server_fifo_fd == -1) {fprintf(stderr, "Sorry, server fifo open failure!\n");return -1;}sleep(5);while ((res = read(server_fifo_fd, &msg, sizeof(msg))) > 0) {// 从服务器端读取客户端发送过来的数据并在循环体中处理p = msg.data;while (*p) {*p = toupper(*p); // 转换为大写字母p++;}sprintf(client_fifo_name, "/tmp/client_fifo%d", msg.client_pid); // 修正宏定义的使用client_fifo_fd = open(client_fifo_name, O_WRONLY); // 打开客户端的管道if (client_fifo_fd == -1) {fprintf(stderr, "Sorry, client fifo open failure!\n");return -1;}write(client_fifo_fd, &msg, sizeof(msg)); // 将消息通过 client 的管道发送给客户端close(client_fifo_fd);}close(server_fifo_fd);unlink(SERVER_FIFO_NAME); // 删除管道文件exit(EXIT_SUCCESS);
}
实践截图:

例8
semlib.h
#ifndef SEMLIB_H
#define SEMLIB_H#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>#define DELAY_TIME 2union semun {int val;struct semid_ds *buf;unsigned short *array;
};int init_sem(int sem_id, int init_value);
int del_sem(int sem_id);
int sem_p(int sem_id);
int sem_v(int sem_id);#endif /* SEMLIB_H */
semlib.c
#include "semlib.h"int init_sem(int sem_id, int init_value) {union semun sem_union;sem_union.val = init_value;if (semctl(sem_id, 0, SETVAL, sem_union) == -1) {perror("initializing semaphore");return -1;}return 0;
}int del_sem(int sem_id) {union semun sem_union;if (semctl(sem_id, 0, IPC_RMID, sem_union) == -1) {perror("delete semaphore failed");return -1;}return 0;
}int sem_p(int sem_id) {struct sembuf sem_b;sem_b.sem_num = 0;sem_b.sem_op = -1;sem_b.sem_flg = SEM_UNDO;if (semop(sem_id, &sem_b, 1) == -1) {perror("P operation failed");return -1;}return 0;
}int sem_v(int sem_id) {struct sembuf sem_b;sem_b.sem_num = 0;sem_b.sem_op = 1;sem_b.sem_flg = SEM_UNDO;if (semop(sem_id, &sem_b, 1) == -1) {perror("V operation failed");return -1;}return 0;
}
semexample.c
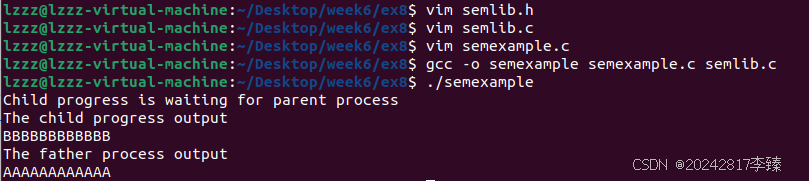
#include "semlib.h"int main(void) {pid_t result;int sem_id;sem_id = semget(ftok("./a", 'a'), 1, 0666 | IPC_CREAT);init_sem(sem_id, 0);result = fork();if (result == -1) {perror("Fork failed\n");} else if (result == 0) { /* 子进程 */printf("Child progress is waiting for parent process\n");sleep(DELAY_TIME);printf("The child progress output\n");printf("BBBBBBBBBBBB\n");sem_v(sem_id); // V 操作} else { /* 父进程 */sem_p(sem_id); // P 操作printf("The father process output \n");printf("AAAAAAAAAAAA\n");del_sem(sem_id);}exit(0);
}
实践截图:
例9
semlib.h
#ifndef SEMLIB_H
#define SEMLIB_H#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>#define SHMSZ 27union semun {int val;struct semid_ds *buf;unsigned short *array;
};int init_sem(int sem_id, int init_value);
int del_sem(int sem_id);
int sem_p(int sem_id);
int sem_v(int sem_id);#endif /* SEMLIB_H */
semlib.c
#include "semlib.h"int init_sem(int sem_id, int init_value) {union semun sem_union;sem_union.val = init_value;if (semctl(sem_id, 0, SETVAL, sem_union) == -1) {perror("initializing semaphore");return -1;}return 0;
}int del_sem(int sem_id) {union semun sem_union;if (semctl(sem_id, 0, IPC_RMID, sem_union) == -1) {perror("delete semaphore failed");return -1;}return 0;
}int sem_p(int sem_id) {struct sembuf sem_b;sem_b.sem_num = 0;sem_b.sem_op = -1;sem_b.sem_flg = SEM_UNDO;if (semop(sem_id, &sem_b, 1) == -1) {perror("P operation failed");return -1;}return 0;
}int sem_v(int sem_id) {struct sembuf sem_b;sem_b.sem_num = 0;sem_b.sem_op = 1;sem_b.sem_flg = SEM_UNDO;if (semop(sem_id, &sem_b, 1) == -1) {perror("V operation failed");return -1;}return 0;
}
outab.c
#include "semlib.h"char SEM_NAME[] = "process1";int main() {int fd;sem_t *mutex;mutex = sem_open(SEM_NAME, O_CREAT, 0777, 1);if (mutex == SEM_FAILED) {perror("unable to execute semaphore");exit(-1);}fd = open("a.txt", O_CREAT | O_WRONLY | O_TRUNC | O_APPEND);if (fd == -1) {perror("open failed");sem_close(mutex);exit(-1);}while (1) {sem_wait(mutex); // P 操作write(fd, "ABC\n", sizeof("ABC\n") - 1);close(fd);fd = open("a.txt", O_WRONLY | O_APPEND);sleep(1);sem_post(mutex); // V 操作}sem_close(mutex);sem_unlink(SEM_NAME);close(fd);exit(0);
}
outdef.c
#include "semlib.h"char SEM_NAME[] = "process1";int main() {int fd;sem_t *mutex;mutex = sem_open(SEM_NAME, O_CREAT, 0777, 1);if (mutex == SEM_FAILED) {perror("unable to execute semaphore");exit(-1);}fd = open("a.txt", O_CREAT | O_WRONLY | O_TRUNC | O_APPEND);if (fd == -1) {perror("open failed");sem_close(mutex);exit(-1);}while (1) {sem_wait(mutex); // P 操作write(fd, "DEF\n", sizeof("DEF\n") - 1);close(fd);fd = open("a.txt", O_WRONLY | O_APPEND);sleep(1);sem_post(mutex); // V 操作}sem_close(mutex);sem_unlink(SEM_NAME);close(fd);exit(0);
}
实践截图:

例10
share.c
#include <sys/shm.h>
#include <error.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/ipc.h>
#include <stdint.h> // 添加此头文件以使用 intptr_t#define SIZE 1024int main() {int shmid; // 共享内存段标识符char *shmaddr;char buff[30];int shmstatus; // 获取共享内存属性信息int pid;shmid = shmget(IPC_PRIVATE, SIZE, IPC_CREAT | 0600);if (shmid < 0) {perror("get shm ipc_id error");return -1;}pid = fork(); // 子进程向共享内存中写入数据if (pid == 0) { // 子进程向共享内存中写入数据shmaddr = (char *)shmat(shmid, NULL, 0); // 映射共享内存,可读写if ((intptr_t)shmaddr == -1) { // 修正此处的类型转换perror("shmat addr error");return -1;}strcpy(shmaddr, "Hello World!\n");shmdt(shmaddr);return 0;} else if (pid > 0) {sleep(10);shmaddr = (char *)shmat(shmid, NULL, 0);if ((intptr_t)shmaddr == -1) { // 修正此处的类型转换perror("shmat addr error");return -1;}strcpy(buff, shmaddr);printf("I have got from shared memory :%s\n", buff);shmdt(shmaddr);shmctl(shmid, IPC_RMID, NULL);} else {perror("fork error");shmctl(shmid, IPC_RMID, NULL);}return 0;
}
实践截图:

例11
memshare.c
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/sem.h>
#include "semilib.h" //前面章节的信号量操作库函数
#include <string.h>
#include <sys/wait.h> // 添加此头文件以解决 waitpid 的警告
#define BUFFER_SIZE 2048int main()
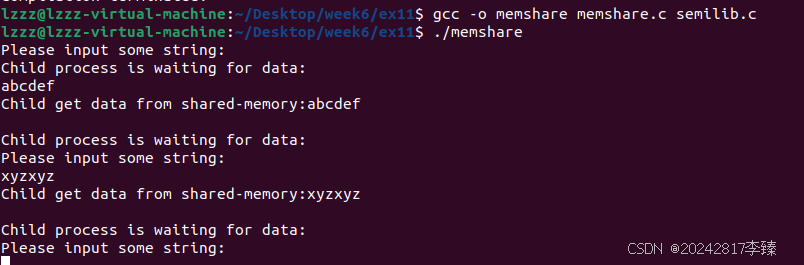
{pid_t pid;int sem_id; //信号量IDint shmid; //共享内存段IDchar *shm_addr = NULL; //共享内存首地址char buff[BUFFER_SIZE]; //字符串int i = 0;sem_id = semget(ftok(".", 'a'), 1, 0666 | IPC_CREAT); //信号量init_sem(sem_id, 0); //信号量初始化if ((shmid = shmget(IPC_PRIVATE, BUFFER_SIZE, 0666)) < 0){perror("shmget");return -1;}pid = fork();if (pid == -1){perror("fork");return -1;}else if (pid == 0){if ((shm_addr = shmat(shmid, 0, 0)) == (char *)-1){perror("shmat");return -1;}while (i < 3){printf("Child process is waiting for data:\n");sem_p(sem_id); //P操作strcpy(buff, shm_addr); //读取数据printf("Child get data from shared-memory:%s\n", buff);sem_v(sem_id); //V操作i++;}del_sem(sem_id); //删除信号量if (shmdt(shm_addr) < 0){perror("shmdt");return -1;}if (shmctl(shmid, IPC_RMID, NULL) == -1){perror("child process delete shared memory ");return -1;}}else{if ((shm_addr = shmat(shmid, 0, 0)) == (char *)-1){perror("Parent shmat failed");return -1;}while (i < 3){printf("Please input some string:\n");fgets(buff, BUFFER_SIZE, stdin);strncpy(shm_addr, buff, strlen(buff));sem_v(sem_id); //V操作sem_p(sem_id); //P操作i++;}if (shmdt(shm_addr) < 0){perror("Parent:shmdt");exit(1);}waitpid(pid, NULL, 0);}return 0;
}
实践截图:
例12
first.c
#include <sys/mman.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h> // 添加此头文件以声明 perror 函数
#include <stdlib.h> // 添加此头文件以声明 exit 函数typedef struct {char name[4];int age;
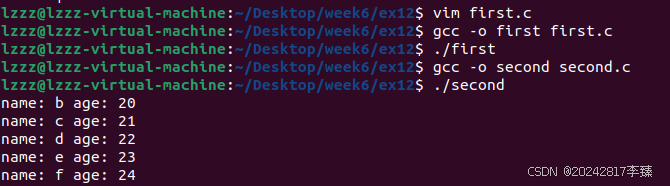
} student;int main(int argc, char** argv) {int fd, i;student *p_map;char temp;fd = open("stu.txt", O_CREAT | O_RDWR | O_TRUNC, 00777);lseek(fd, sizeof(student) * 5 - 1, SEEK_SET);write(fd, "", 1);p_map = (student *)mmap(NULL, sizeof(student) * 10, PROT_READ | PROT_WRITE,MAP_SHARED, fd, 0);if (p_map == (void *)-1) {perror("mmap failed\n");exit(0);}close(fd);temp = 'a';for (i = 0; i < 10; i++) {temp += 1; // 学生姓名memcpy((*(p_map + i)).name, &temp, 2);(*(p_map + i)).name[1] = '\0';(*(p_map + i)).age = 20 + i; // 学生年龄}sleep(10);munmap(p_map, sizeof(student) * 10);return 0;
}
second.c
#include <sys/mman.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>typedef struct {char name[4];int age;
} student;int main(int argc, char** argv) {int fd, i;student *p_map;fd = open("stu.txt", O_CREAT | O_RDWR, 00777);p_map = (student *)mmap(NULL, sizeof(student) * 10, PROT_READ | PROT_WRITE,MAP_SHARED, fd, 0);for (i = 0; i < 10; i++) {printf("name: %s age: %d\n", (*(p_map + i)).name, (*(p_map + i)).age);}munmap(p_map, sizeof(student) * 10);return 0;
}
实践截图:
例13
msgexamp.h
#ifndef MSGQUE_EXAMP
#define MSGQUE_EXAMP
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <errno.h>
#include <unistd.h>
#include <sys/msg.h>
#include <sys/stat.h>
#define MAX_TEXT 512
#define MSG_KEY 335struct my_msg_st {long my_msg_type; // 消息类型,其值分别为 1,2,3,代表不同交易消息char text[MAX_TEXT]; // 存放具体消息内容
};
#endif
msgsnd.c
#include "msgexamp.h"
#include <stdlib.h>
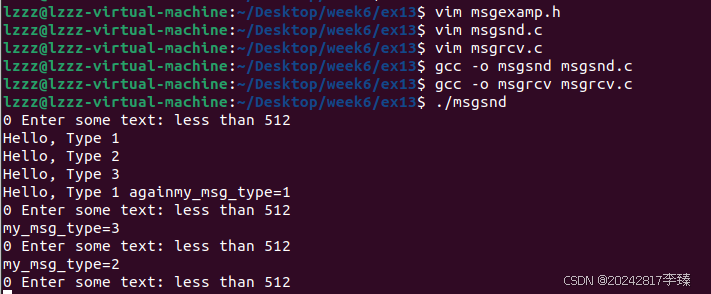
#include <time.h>int main() {int index = 1;struct my_msg_st some_data;int msgid;char buffer[BUFSIZ];msgid = msgget((key_t)MSG_KEY, IPC_CREAT | S_IRUSR | S_IWUSR);if (msgid == -1) {perror("create message queue failed");return -1;}srand((int)time(0));while (index < 5) {printf("%d Enter some text: less than %d\n", msgid, MAX_TEXT);fgets(buffer, BUFSIZ, stdin);some_data.my_msg_type = rand() % 3 + 1; // 随机产生消息类型 1~3 值printf("my_msg_type=%ld\n", some_data.my_msg_type);strcpy(some_data.text, buffer);if (msgsnd(msgid, (void *)&some_data, sizeof(some_data), 0) == -1) {fprintf(stderr, "msgsnd failed\n");exit(-1);}index++;}exit(0);
}
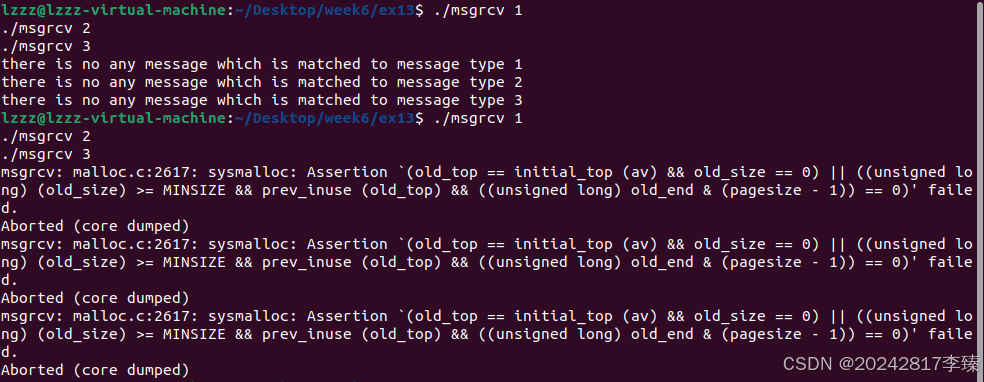
msgrcv.c
#include "msgexamp.h"int main(int argc, char **argv) {int msgid;int type;struct my_msg_st *my_data = (struct my_msg_st *)malloc(sizeof(struct my_msg_st));if (argc < 2) {printf("USAGE: msgexample msgtype\n");return -1;}type = atoi(argv[1]);if (type < 0 || type > 3) {printf("msgtype should be one of 1,2,3\n");return -1;}msgid = msgget((key_t)MSG_KEY, IPC_CREAT | S_IRUSR | S_IWUSR);if (msgid == -1) {perror("get message queue failed");return -1;}while (1) {if (msgrcv(msgid, (void *)my_data, sizeof(struct my_msg_st), (long)type, IPC_NOWAIT) != -1) {printf("The message type is:%ld\n", my_data->my_msg_type);printf("The message content is:%s\n", my_data->text);} else if (ENOMSG == errno) {printf("there is no any message which is matched to message type %d\n", type);break;}}return 0;
}
实践截图:
习题1
进程间通信(IPC)的几种主要方式包括管道(Pipe)、消息队列(Message Queue)、共享内存(Shared Memory)、信号量(Semaphore)和套接字(Socket)。它们的特点和不同点如下:
-
管道(Pipe)
- 特点:单向通信,数据以字节流形式传输。
- 不同点:适用于有亲缘关系的进程间通信,不适合大量数据传输。
-
消息队列(Message Queue)
- 特点:允许消息以队列形式存储和传输,支持异步通信。
- 不同点:可以跨网络通信,适合大量数据传输。
-
共享内存(Shared Memory)
- 特点:进程间共享一块内存区域,通信速度快。
- 不同点:需要同步机制,适合大量数据传输。
-
信号量(Semaphore)
- 特点:用于进程间同步,控制对共享资源的访问。
- 不同点:主要用于同步,不用于数据传输。
-
套接字(Socket)
- 特点:支持不同主机间的进程通信,灵活。
- 不同点:可以跨网络通信,适合远程通信。
习题2
System V和POSIX是两种不同的进程间通信(IPC)标准,它们之间的差异性主要包括:
-
标准来源:
- System V:源自UNIX System V操作系统。
- POSIX:由IEEE制定的可移植操作系统接口标准。
-
兼容性:
- System V:特定于UNIX系统,兼容性较差。
- POSIX:跨平台,兼容性好,支持多种操作系统。
-
功能实现:
- System V:功能实现较为简单,直接。
- POSIX:功能实现更为复杂,但更标准化。
-
API设计:
- System V:API设计较为简单,使用方便。
- POSIX:API设计更复杂,但更统一和规范。
-
应用范围:
- System V:主要应用于UNIX和类UNIX系统。
- POSIX:广泛应用于各种操作系统,包括Linux、Windows等。
-
发展和维护:
- System V:发展和维护较为封闭。
- POSIX:由IEEE维护,更新和改进更为开放和活跃。
总的来说,POSIX标准在兼容性、标准化和跨平台方面具有优势,而System V则在某些特定环境中可能更为简单直接。
习题3
pipe.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/wait.h>#define BUFFER_SIZE 1024void child_process(int read_fd) {char buffer[BUFFER_SIZE];ssize_t bytes_read;// 打开接收文件int file_fd = open("received.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);if (file_fd < 0) {perror("open received file");exit(1);}// 从管道读取数据并写入接收文件while ((bytes_read = read(read_fd, buffer, sizeof(buffer))) > 0) {write(file_fd, buffer, bytes_read);}close(read_fd);close(file_fd);
}void parent_process(const char* filename, int write_fd) {// 打开发送文件int file_fd = open(filename, O_RDONLY);if (file_fd < 0) {perror("open file");exit(1);}char buffer[BUFFER_SIZE];ssize_t bytes_read;// 从发送文件读取数据并写入管道while ((bytes_read = read(file_fd, buffer, sizeof(buffer))) > 0) {write(write_fd, buffer, bytes_read);}close(file_fd);close(write_fd);
}int main(int argc, char* argv[]) {if (argc != 2) {fprintf(stderr, "Usage: %s <filename>\n", argv[0]);return 1;}// 创建管道int pipefd[2];if (pipe(pipefd) == -1) {perror("pipe");return 1;}// 创建子进程pid_t pid = fork();if (pid == -1) {perror("fork");return 1;} else if (pid == 0) { // 子进程close(pipefd[1]); // 关闭写端child_process(pipefd[0]);exit(0);} else { // 父进程close(pipefd[0]); // 关闭读端parent_process(argv[1], pipefd[1]);wait(NULL); // 等待子进程结束}return 0;
}
实践截图:

运行完成后生成了received.txt且内容与test.tst中的一致。
习题4
fd1打开文件 “a.txt” 用于读取,其值是文件 “a.txt” 的文件描述符。fd2打开文件 “b.txt” 用于写入,其值是文件 “b.txt” 的文件描述符。fd3是fd1的副本,因此fd3和fd1都指向文件 “a.txt”。fd4通过dup2被设置为与fd2相同,所以fd4也指向文件 “b.txt”。
fd1 和 fd3 指向同一个文件 “a.txt”,fd2 和 fd4 指向同一个文件 “b.txt”。
习题5
六、学习实践过程遇到的问题与解决方式
1. fork()函数的使用与理解
2. 僵尸进程的产生与处理
七、参考资料
- AI工具(你使用的AI工具及其链接)
- 问小白
- Kimi
- 图书
- 《Linux编程基础.李养群》电子版
- 网站
- CSDN
“20242817李臻 原创作品转载请注明出处 《Linux高级编程实践》”**
相关文章:
20242817李臻《Linux⾼级编程实践》第6周
20242817李臻《Linux⾼级编程实践》第6周 一、AI对学习内容的总结 Linux进程间通信(IPC) 1. 进程间通信基本概念 作用: 数据传输:进程间传递数据(字节到兆字节级别)。共享数据:多个进程操作同一数据&…...

Vue 3中的Provide与Inject
在Vue 3中,provide和inject机制为组件间的通信提供了一种新的方式。不同于传统的父子组件通过props传递数据的方式,provide和inject允许祖先组件向其所有子孙组件提供数据,而无需通过中间层手动传递。这使得跨层级的组件通信变得更加直接和简…...

深入解析SQL2API平台:数据交互革新者
在数字化转型持续深入的当下,企业对数据的高效利用与管理的需求愈发迫切。SQL2API平台应运而生,成为助力企业突破数据交互困境的有力工具,特别是它由麦聪软件基于DaaS(数据即服务)产品创新衍生而来,备受业界…...
)
蓝桥杯算法题分享(二)
蓝桥杯算法题分享 本文将继续分享三道经典的蓝桥杯算法题,包括题目描述、解题思路和 Java 代码实现,帮助大家更好地理解算法的应用。对算法感兴趣的朋友可以点开我的主页查看我上周分享的另三道题。 第一题:次数差 题目描述 x 星球有 26 只…...

实战-MySQL5.7升级8.0遇到的四个问题
近期几个项目的MySQL由5.7升级到8.0,升级过程中遇到四个问题,记录下来分享一下: 第一个问题详见之前的文章: MySQL 5.7升级8.0报异常:处理新增关键字 第二个问题详见之前的文章: MySQL 5.7升级8.0报异常…...

为什么递归用栈?动态分配用堆?
文章目录 1. 区别2. 栈空间特点优点缺点 3. 堆空间特点优点缺点 4. 栈和堆的对比5. 总结 1. 区别 栈空间和堆空间是程序内存中的两块不同区域,分别用于不同的用途。 栈空间: 栈空间是由操作系统自动管理的内存区域,用于存储局部变量、函数…...

Java 中装饰者模式与策略模式在埋点系统中的应用
前言 在软件开发中,装饰者模式和策略模式是两种常用的设计模式,它们在特定的业务场景下能够发挥巨大的作用。本文将通过一个实际的埋点系统案例,探讨如何在 Java 中运用装饰者模式和策略模式,以及如何结合工厂方法模式来优化代码…...

计算机视觉总结
以下是针对上述问题的详细解答,并结合代码示例进行说明: 1. 改进YOLOv5人脸检测模块,复杂光照场景准确率从98.2%提升至99.5% 优化具体过程: 光照补偿:在数据预处理阶段,采用自适应光照补偿算法,对图像进行实时增强,以减少光照变化对人脸检测的影响。数据增强:在训练…...

无人设备遥控器之调度自动化技术篇
一、技术原理 信息采集与处理: 通过传感器、仪表等设备采集无人设备的各种数据,如位置、速度、状态等。 将采集到的数据传输到调度自动化系统中进行处理和分析,以获取设备的实时状态。 系统建模与优化: 调度自动化系统会根据…...

【AI】Orin Nano+ubuntu22.04上移植YoloV11,并使用DeepStream测试成功
【AI】郭老二博文之:AI学习目录汇总 1、准备工作 使用 sdk-manager 烧写 OrinNano, JetPack版本为6.0 DP,对应操作系统为:Ubuntu22.04 参见博客:【NVIDIA】Jetson Orin Nano系列:烧写Ubuntu22.04 2、安装 PyTorch 2.1 下载依赖 1)安装onnx pip install onnx -i h…...

K8S学习之基础四十五:k8s中部署elasticsearch
k8s中部署elasticsearch 安装并启动nfs服务yum install nfs-utils -y systemctl start nfs systemctl enable nfs.service mkdir /data/v1 -p echo /data/v1 *(rw,no_root_squash) >> /etc/exports exports -arv systemctl restart nfs创建运行nfs-provisioner需要的sa账…...

如何在 Windows 上安装并使用 Postman?
Postman 是一个功能强大的API测试工具,它可以帮助程序员更轻松地测试和调试 API。在本文中,我们将讨论如何在 Windows 上安装和使用 Postman。 Windows 如何安装和使用 Postman 教程?...
)
Langchain 提示词(Prompt)
基本用法 1. 基本概念 提示词模板 是一个字符串模板,其中包含一些占位符(通常是 {variable} 形式的),这些占位符可以在运行时被实际值替换。LangChain 提供了多种类型的提示词模板,以适应不同的使用场景。 2. 主要类…...

什么是PHP伪协议
PHP伪协议是一种特殊的URL格式,允许开发者以不同于传统文件路径访问和操作资源。以下是一些常见的PHP伪协议及其详细介绍: 常见的PHP伪协议 1. **file://** - **用途**:访问本地文件系统。 - **示例**:file:///path/to/file.txt。…...

python脚本处理excel文件
1.对比perl和python 分别尝试用perl和python处理excel文件,发现perl的比较复杂,比如说read excel就有很多方式 Spreadsheet::Read use Spreadsheet::ParseExcel 不同的method,对应的取sheet的cell方式也不一样。更复杂的是处理含有中文内…...

【腾讯云架构师技术沙龙2025.03.22】
大模型技术演进与行业影响分析 日期:2025年3月22日 主讲人:李建忠 《DeepSeek实战驱动行业智变—AI应用寒武纪》 整理:飞书语音转化DeepSeek分析汇总 一、技术演进:从快思考到慢思考 1. 早期争议与能力局限(2022-202…...

【SOC 芯片设计 DFT 学习专栏 -- IDDQ 测试 与 Burn-In 测试】
文章目录 IDDQ 测试与 Burn-In 测试IDDQ 测试工作原理测试过程优点局限性示例 2. Burn-In 测试工作原理测试过程优点局限性示例 总结对比 IDDQ 测试和 Burn-in 测试: IDDQ 测试与 Burn-In 测试 本文将详细介绍 DFT 中 IDDQ测试 和 burn-in测试模式 IDDQ 测试 IDD…...

Axure RP 9.0教程: 基于动态面板的元件跟随来实现【音量滑块】
文章目录 引言I 音量滑块的实现步骤添加底层边框添加覆盖层基于覆盖层创建动态面板添加滑块按钮设置滑块拖动效果引言 音量滑块在播放器类APP应用场景相对较广,例如调节视频的亮度、声音等等。 I 音量滑块的实现步骤 添加底层边框 在画布中添加一个矩形框:500 x 32,圆…...

JS—call,apply,bind:1分钟掌握三者的区别
个人博客:haichenyi.com。感谢关注 一. 目录 一–目录二–call三–apply四–bind五–三者对比 二. call 作用: 立即调用函数,显式指定this值,并逐个传递参数。 语法: func.call(thisArg, arg1, arg2, …) 特点&…...

Linux TTY设备汇总
目录 1. tty(终端设备统称) 2. ptm(伪终端主设备)与pts(伪终端从设备) 3. ttys(串行端口终端) 4. ttyACM(USB CDC ACM设备) 5. ttyGS(USB Gadget Serial设备) 主要联系 典型应用场景 TTY_CORE: drivers/tty/tty_io.c:tty_register_driver…...

WPF 与 C# 开发深度剖析
一、引言 在当今的软件开发领域,Windows 平台依旧占据着重要的地位。而 WPF(Windows Presentation Foundation)作为微软推出的一款强大的用户界面(UI)框架,为开发者提供了丰富的功能和灵活的设计方式&…...

好消息!软航文档控件(NTKO WebOffice)在Chrome 133版本上提示扩展已停用的解决方案
软航文档控件现有版本依赖Manifest V2扩展技术支持才能正常运行,然而这个扩展技术到2025年6月在Chrome高版本上就彻底不支持了,现在Chrome 133开始的版本已经开始弹出警告,必须手工开启扩展支持才能正常运行。那么如何解决这个技术难题呢&…...

通过仿真确定抗积分饱和策略的最佳系数
通过仿真确定抗积分饱和策略的最佳系数(如PID参数 ( K_p, K_i, K_d ) 以及抗饱和参数 ( K_{\text{back}} )、积分限幅值等)是一个系统化的过程。以下是具体步骤和示例: — 1. 建立仿真模型 1.1 模型组成 被控对象:例如电机、温…...

消息队列(Kafka及RocketMQ等对比联系)
目录 消息队列 一、为什么使用消息队列?消息队列有什么优点/缺点?介绍下Kafka、ActiveMQ、RabbitMQ、RocketMQ有什么优点缺点,如何取舍? 1.公司业务场景是什么,这个业务场景有什么挑战,如果不用MQ有什么麻…...

GitHub开源的容器管理面板-Dpanel
dpanel Docker安装部署二进制部署 GitHub官网 一块轻量化docker可视化管理面板,由国人开发,个人觉得是比较好用的,功能都很齐全,并且可以通过修改源码,自定义前端样式等。 Docker安装部署 官网 部署环境࿱…...

【HarmonyOS Next】三天撸一个BLE调试精灵
【HarmonyOS Next】三天撸一个BLE调试精灵 一、功能介绍 BLE调试精灵APP属于工具类APP,在用户使用的过程中,负责调试BLE设备从机端,比如蓝牙耳机、低功耗设备、带有BLE的空调等设备,可以在页面中清晰看到设备的厂商,…...

java 批量下载doc\excle\pdf
指定图片集合 下载到指定文件夹 import java.io.*; import java.net.HttpURLConnection; import java.net.URL; import java.util.Arrays; import java.util.List;public class OfficeFileDownloader {/*** 需要下载的Office文档URL列表*/private static final List<Strin…...

软件性能效率测试工具有哪些?专业第三方软件检测机构推荐
在软件开发的新时代,软件性能效率测试已经成为每个企业不可或缺的一部分。无论是在竞争激烈的市场中,还是在追求卓越用户体验的过程中,都需要进行有效的性能测试。 一、软件性能效率测试的目标 1、响应时间:确保用户请求的响…...

使用flask_restful快速构建接口
Flask-RESTful 是一个用于快速构建 RESTful API 的 Flask 扩展。它简化了创建、管理和文档化 REST API 的过程。利用 Flask-RESTful,你可以更容易地将你的 Flask 应用程序组织成 RESTful 原则的风格 安装包 pip install flask_restful 快速构建接口 from flask im…...

centos 7 部署FTP 服务用shell 搭建脚本,使用时稍微修改自己所需需求
#!/bin/bash # 检查是否为 root 用户 if [ "$(id -u)" ! "0" ]; then echo "此脚本需要以 root 用户身份运行。" exit 1 fi # 安装 vsftpd yum install vsftpd -y # 备份原始配置文件 cp /etc/vsftpd/vsftpd.conf /etc/vsftpd/vsftpd…...