5种生成模型(VAE、GAN、AR、Flow 和 Diffusion)的对比梳理 + 易懂讲解 + 代码实现
目录
1 变分自编码器(VAE)
1.1 概念
1.2 训练损失
1.3 VAE 的实现
2 生成对抗网络(GAN)
2.1 概念
2.2 训练损失
a. 判别器的损失函数
b. 生成器的损失函数
c. 对抗训练的动态过程
2.3 GAN 的实现
3 自回归模型(AR)
3.1 概念
3.2 训练过程
a.核心思想: 用历史预测未来
b. Transformer 的损失计算:交叉熵监督预测
c. 损失计算的具体步骤
3.2 代码实现(Transformer-AR)
4 流模型(Flow)
4.1 概念
4.2 训练过程
4.2 代码实现(Flow)
5 扩散模型(Diffusion)
5.1 概念
5.2 训练过程
5.2 代码实现(Diffusion)
6 小结
随着Sora、diffusion、GPT等模型的大火,深度生成模型又成为了大家的焦点。
深度生成模型是一类强大的机器学习工具,它可以从输入数据学习其潜在的分布,进而生成与训练数据相似的新的样本数据,它在计算机视觉、密度估计、自然语言和语音识别等领域得到成功应用, 并给无监督学习提供了良好的范式。

本文汇总了常用的深度学习模型,深入介绍其原理及应用:VAE(变分自编码器)、GAN(生成对抗网络)、AR(自回归模型 如 Transformer)、Flow(流模型)和 Diffusion(扩散模型)
| 模型 | 核心目标 | 原理 | 优点 | 缺点 | 应用场景 | |
|---|---|---|---|---|---|---|
| VAE | 学习潜在空间分布,编码器-解码器生成与训练数据相似的样本 | 基于变分推断,将输入数据映射到潜在空间的正态分布,解码器重构数据,优化重构误差与KL散度 | 训练稳定,支持潜在空间插值;生成样本多样化 | 生成图像模糊;KL散度约束可能导致信息丢失 | 数据填充、特征提取、图像修复 | |
| GAN | 通过生成器与判别器的对抗训练,生成与真实数据难分的样本 | 生成器从噪声生成假数据,判别器区分真假;两者通过零和博弈优化,最终达到纳什均衡 | 生成图像细节丰富;单步推理速度快 | 训练不稳定;生成多样性不足;需精细调参 | 艺术创作、风格迁移、图像超分辨率 | |
| AR | 自回归地生成序列数据,逐个预测下一个元素的概率分布 | 基于条件概率分解(如Transformer),自注意力机制捕捉长程依赖,逐像素/逐token生成数据 | 建模能力强,支持长序列生成;训练稳定 | 生成速度慢 (逐步采样);高维数据计算成本高 | 文本生成、时序预测、图像生成 | |
| Flow | 可逆变换将简单分布转为复杂数据分布,实现精确概率密度估计 | 设计可逆神经网络层,利用变量变换公式计算数据对数似然,优化雅可比行列式。 | 支持精确密度估计;生成与重建可逆 | 高维数据下变换设计复杂;计算雅可比行列式开销大 | 语音合成、密度估计、图像生成 | |
| Diffusion | 通过逐步去噪过程从高斯噪声重建数据分布,生成高质量样本 | 正向扩散(逐步加噪)与逆向扩散(学习去噪)结合,基于马尔可夫链建模条件概率 | 生成质量最高;训练稳定 | 推理速度慢;显存占用高 | 高清图像生成、多模态/视频生成 |
1 变分自编码器(VAE)
1.1 概念
VAE是在自编码器(Auto-Encoder)的基础上,结合变分推断(Variational Inference)和贝叶斯理论提出的一种深度生成模型。VAE的目标是学习一个能够生成与训练数据相似样本的模型。它假设隐变量服从某种先验分布(如标准正态分布),并通过编码器将输入数据映射到隐变量的后验分布,再通过解码器将隐变量还原成生成样本。
补充
1. 先验分布的概念
假设我们要通过身高预测体重,贝叶斯理论会要求我们先对体重有一个 "初始认知"(比如平均体重 60kg,波动范围 ±10kg)。这个初始认知就是先验分布,它反映了我们在看到具体数据前对某个变量的信念
2. VAE 中的先验设计
在 VAE 中,隐变量(latent variable)z 被假设服从某种简单分布(通常是标准正态分布 N (0,1))。这就像我们在做图像生成任务时,先假设所有图像的潜在特征(比如形状、颜色)都符合 "常见特征分布"

1.2 训练损失
VAE的训练损失函数包括 重构损失(如均方误差)和 KL散度(衡量潜在分布与标准正态分布的差异)
损失函数:
![]()
- 重构项:衡量解码器重建输入数据的能力(如均方误差或交叉熵)
- KL散度项:约束潜在分布 q(z∣x) 与先验分布 p(z)(通常为标准正态分布)的相似性,平衡参数为 β(如 β-VAE)
优化目标:最大化证据下界(ELBO),同时保证潜在空间的结构化和连续性
补充
1. 损失函数的两大核心目标
VAE 的损失函数像一个 “双面裁判”,同时监督两个目标:
- 重建能力:"你生成的图片要和原图差不多!"(重构损失)
- 规则意识:"你不能乱想!生成规则要符合常识!"(KL 散度)
2. 重构损失:像照镜子的误差
- 作用:确保解码器能把隐变量 z 还原成接近原图的样子。
- 数学形式:
- 图像任务常用均方误差(MSE):计算每个像素点的误差平方和。
- 文本任务常用交叉熵:衡量生成分布与真实分布的差异。
3. KL 散度:用规则约束想象力
- 作用:强制隐变量 z 的分布接近先验(如正态分布)。
- 数学意义:
KL 散度 = 0 时,后验分布 q (z|x) 和先验 p (z) 完全一致;数值越大,说明模型越 "不守规矩"。4. β-VAE:用旋钮调节规则强度
- β 参数:像音量旋钮一样调节 KL 散度的权重。
- β=0 时:完全不管规则,可能生成奇形怪状的样本(如猫的耳朵长在尾巴上)。
- β 很大时:过于遵守规则,生成样本千篇一律(所有猫都长一个样)。
5. ELBO:为什么要同时优化这两个目标?
- ELBO 公式:
ELBO = 重构损失 - KL 散度
(更准确的数学表达需要结合概率模型,但这里简化理解)- 核心逻辑:
模型需要同时做到:
- 记住训练数据的特征(重构损失小)
- 把这些特征压缩到 "常识空间"(KL 散度小)
这就像学习绘画时,既要准确临摹(重构),又要符合透视、比例等规则(KL 约束)。详细介绍:
【VAE学习笔记】全面通透地理解VAE(Variational Auto Encoder)_vae架构-CSDN博客
1.3 VAE 的实现
import torch
import torch.nn as nn
import torch.nn.functional as Fclass VAE(nn.Module):def __init__(self, input_dim=784, hidden_dim=400, latent_dim=20):super(VAE, self).__init__()# 编码器:输入 → 隐藏层 → 均值和方差self.encoder = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, latent_dim * 2) # 输出均值和对数方差)# 解码器:潜在变量 → 隐藏层 → 重构输入self.decoder = nn.Sequential(nn.Linear(latent_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, input_dim),nn.Sigmoid() # 输出像素值在[0,1]区间)def reparameterize(self, mu, log_var):"""重参数化技巧:从N(μ, σ²)采样潜在变量z"""std = torch.exp(0.5 * log_var) # 计算标准差eps = torch.randn_like(std) # 生成随机噪声return mu + eps * std # 返回采样结果def forward(self, x):# 编码:x → μ和logσ²h = self.encoder(x)mu, log_var = torch.chunk(h, 2, dim=1) # 分割为均值和方差# 采样潜在变量zz = self.reparameterize(mu, log_var)# 解码:z → 重构xx_recon = self.decoder(z)return x_recon, mu, log_var# 损失函数:重构损失 + KL散度
def loss_function(x_recon, x, mu, log_var):recon_loss = F.binary_cross_entropy(x_recon, x, reduction='sum') # 重构损失(交叉熵)kl_div = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) # KL散度return recon_loss + kl_div2 生成对抗网络(GAN)
2.1 概念
GAN由两部分组成:生成器(Generator)和 判别器(Discriminator)
- 生成器的任务是生成尽可能接近真实数据的假数据
- 判别器的任务是区分输入数据是真实数据还是生成器生成的假数据
- 二者通过相互竞争与对抗,共同进化,最终生成器能够生成非常接近真实数据的样本

训练过程:
-
判别器接受真实数据和生成器生成的假数据,进行二分类训练,优化其判断真实或生成数据的能力
-
生成器根据判别器的反馈,尝试生成更加真实的假数据以欺骗判别器
-
交替训练判别器和生成器,直到判别器无法区分真实和生成数据,或达到预设的训练轮数
2.2 训练损失
a. 判别器的损失函数
- 判别器的目标是最大化正确判断的概率:
- 真实样本:输出 1(正确识别为真)。
- 生成样本:输出 0(正确识别为假)。
- 数学表达:
![]()
- 直观解释: 判别器的损失是两部分交叉熵的总和:
- 对真实样本判断错误的惩罚(希望 log D (x) 尽可能大,所以取负号)。
- 对生成样本判断错误的惩罚(希望 log (1-D (G (z))) 尽可能大,同样取负号)。
b. 生成器的损失函数
- 生成器的目标是让判别器误判生成样本为真:
- 生成样本:让判别器输出 1(即让 D (G (z)) 趋近于 1)。
- 数学表达:
![]()
- 直观解释: 生成器的损失是判别器误判生成样本的惩罚(希望 log D (G (z)) 尽可能大,所以取负号)。
c. 对抗训练的动态过程
-
第一轮训练:
- 生成器随机生成低质量样本(如模糊的人脸)。
- 判别器轻松识别真伪,损失很低(因为正确判断了大部分样本)。
- 生成器的损失很高(因为判别器几乎都识别为假)。
-
第二轮训练:
- 生成器改进造假技术(如生成更清晰的人脸)。
- 判别器被 “迷惑”,损失上升(因为部分生成样本被误判为真)。
- 生成器的损失下降(因为判别器误判增多)。
-
最终平衡:
- 生成器能生成足以以假乱真的样本。
- 判别器无法准确区分真伪,损失趋近于理论下限(交叉熵为 log (0.5))。
为什么使用交叉熵作为损失?
- 交叉熵的特性:
它衡量两个概率分布的差异。当判别器对真实样本输出 1、生成样本输出 0 时,交叉熵为 0(理想状态)。- 对抗的本质:
生成器希望让判别器的输出分布与 “全 1” 分布更接近(对生成样本),而判别器希望让输出分布与 “真实标签分布” 更接近(对真实样本为 1,生成样本为 0)。
2.3 GAN 的实现
class Generator(nn.Module):"""生成器:从噪声生成图像"""def __init__(self, noise_dim=100, output_dim=784):super(Generator, self).__init__()self.model = nn.Sequential(nn.Linear(noise_dim, 256),nn.ReLU(),nn.Linear(256, 512),nn.ReLU(),nn.Linear(512, output_dim),nn.Tanh() # 输出范围[-1,1],需在数据预处理时归一化)def forward(self, z):return self.model(z).view(-1, 1, 28, 28) # 输出形状为(B, 1, 28, 28)class Discriminator(nn.Module):"""判别器:区分真实图像与生成图像"""def __init__(self, input_dim=784):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, 512),nn.LeakyReLU(0.2),nn.Linear(512, 256),nn.LeakyReLU(0.2),nn.Linear(256, 1),nn.Sigmoid() # 输出概率值)def forward(self, x):x = x.view(-1, 784) # 展平输入return self.model(x)# 训练循环示例(简化版)
def train_gan():G = Generator()D = Discriminator()criterion = nn.BCELoss()# 交替优化生成器和判别器for real_images, _ in dataloader:# 训练判别器real_labels = torch.ones(real_images.size(0), 1)fake_labels = torch.zeros(real_images.size(0), 1)# 判别器对真实图像的损失real_loss = criterion(D(real_images), real_labels)# 生成假图像并计算判别器损失z = torch.randn(real_images.size(0), 100)fake_images = G(z)fake_loss = criterion(D(fake_images.detach()), fake_labels)d_loss = real_loss + fake_loss# 反向传播更新判别器d_loss.backward()optimizer_D.step()# 训练生成器g_loss = criterion(D(fake_images), real_labels) # 欺骗判别器g_loss.backward()optimizer_G.step()3 自回归模型(AR)
3.1 概念
算法原理:自回归模型是一种基于序列数据的生成模型,它通过预测序列中下一个元素的值来生成数据。给定一个序列(x_1, x_2, ..., x_n),自回归模型试图学习条件概率分布(P(x_t | x_{t-1}, ..., x_1)),其中(t)表示序列的当前位置。AR模型可以通过循环神经网络(RNN)或 Transformer 等结构实现。
如下以 Transformer 为例解析。
在深度学习的早期阶段,卷积神经网络(CNN)在图像识别和自然语言处理领域取得了显著的成功。然而,随着任务复杂度的增加,序列到序列(Seq2Seq)模型和循环神经网络(RNN)成为处理序列数据的常用方法。尽管RNN及其变体在某些任务上表现良好,但它们在处理长序列时容易遇到梯度消失和模型退化问题。为了解决这些问题,Transformer模型被提出。而后的GPT、Bert等大模型都是基于Transformer实现了卓越的性能!

3.2 训练过程
a.核心思想: 用历史预测未来
自回归模型的核心是根据过去的输出预测未来的输出。例如:
- 语言模型:根据 “今天天气” 预测下一个词 “很” 或 “热”。
- 时间序列预测:根据过去 10 天的股价预测第 11 天的股价。
Transformer 作为自回归模型: 它通过注意力机制捕捉序列中每个位置与之前所有位置的依赖关系,最终输出每个位置的预测概率分布。
b. Transformer 的损失计算:交叉熵监督预测
-
输入与输出的关系
- 输入序列:例如句子 “我喜欢”。
- 目标序列:将输入右移一位,得到 “喜欢天”(假设任务是补全句子)。
- 模型目标:对每个位置,预测下一个词的概率分布。
-
损失函数的数学表达
![]()
- 直观解释: 交叉熵损失衡量模型预测的概率分布与真实标签的差异。 例如:若真实词是 “天”,而模型预测 “天” 的概率为 0.8,则贡献的损失是 \(-\log(0.8) \approx 0.223\)。
c. 损失计算的具体步骤
-
(1) 嵌入与位置编码
- 将输入词(如 “我”“喜”“欢”)转换为向量,并添加位置信息。
-
(2) 因果掩码(Causal Masking)
- 在自注意力计算时,屏蔽未来信息。例如:预测 “欢” 时,只能看到 “我” 和 “喜”,看不到 “天”。
- (3) 多头注意力与前馈网络
- 通过注意力机制整合历史信息,生成每个位置的预测向量。
-
(4) 输出层与概率分布
- 将预测向量映射到词表的概率分布(如 10000 个词的 softmax 输出)。
-
(5) 计算损失
- 对比每个位置的预测概率与真实词的 one-hot 编码,累加交叉熵。
为什么使用交叉熵?
- 分类问题的天然选择:每个位置的预测是多分类任务(选择词表中的一个词)
直观案例:生成句子 “我喜欢晴天”
- 输入序列:["我", "喜", "欢"]
- 目标序列:["喜", "欢", "晴"]
- 损失计算:
- 预测第一个位置(“我”)的下一个词 “喜”,若正确则损失低
- 预测第二个位置(“喜”)的下一个词 “欢”,若正确则继续
- 预测第三个位置(“欢”)的下一个词 “晴”,若错误则贡献高损失
训练中的优化技巧
- 掩码填充(Padding Mask):忽略输入中的无效填充符号(如 “<pad>”)
- 学习率调度:使用 warm-up 策略避免初始训练时的不稳定
- 梯度裁剪:防止长序列反向传播时的梯度爆炸
与 VAE/GAN 损失的对比
模型 损失类型 监督方式 VAE 重构损失 + KL 散度 无监督(仅输入数据) GAN 对抗损失(交叉熵 / 其他) 无监督(仅输入数据) Transformer 交叉熵(自回归监督) 有监督(需目标序列)
详细解读: 注意力机制 → Transformer+位置编码(掩码softmax - 查询-键-值(Query-Key-Value,QKV)模式的理解)-CSDN博客
3.2 代码实现(Transformer-AR)
class TransformerAR(nn.Module):"""基于Transformer的自回归图像生成模型(Pixel Transformer)"""def __init__(self, vocab_size=256, embed_dim=128, num_heads=4, num_layers=3):super(TransformerAR, self).__init__()# 输入:图像展平为序列(如28x28 → 784像素)self.embedding = nn.Embedding(vocab_size, embed_dim)self.positional_enc = nn.Parameter(torch.randn(784, embed_dim)) # 位置编码# Transformer编码器(仅解码模式)encoder_layer = nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads, dim_feedforward=512)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)# 输出层:预测每个像素的概率分布self.fc = nn.Linear(embed_dim, vocab_size)def forward(self, x):# x形状:(B, seq_len) 每个位置是像素值(0-255)x = self.embedding(x) + self.positional_enc # 嵌入 + 位置编码# 自注意力掩码(防止看到未来信息)mask = torch.triu(torch.ones(784, 784), diagonal=1).bool()# Transformer处理out = self.transformer(x, mask=mask)# 预测每个像素的分布logits = self.fc(out)return logits# 生成示例(逐像素生成)
def generate(self, start_token, max_len=784):generated = start_tokenfor _ in range(max_len):logits = self(generated)next_pixel = torch.multinomial(F.softmax(logits[:, -1, :], dim=-1), 1)generated = torch.cat([generated, next_pixel], dim=1)return generated4 流模型(Flow)
4.1 概念
算法原理:流模型是一种基于可逆变换的深度生成模型。它通过一系列可逆的变换,将简单分布(如均匀分布或正态分布)转换为复杂的数据分布。

核心思想:用 “可逆魔法” 转换分布 流模型就像一个 “数据变形大师”,它的核心是可逆变换。想象你有一团标准形状的橡皮泥(简单分布,如正态分布),通过一系列可逆向操作的手法(比如拉伸、折叠,但随时能恢复原状),把它捏成跟真实数据(如图像、语音)分布一样复杂的形状。这种 “既能变形,又能变回去” 的特性,就是流模型的关键 —— 通过可逆函数,让简单分布 “流动” 成复杂数据分布。
生成过程类比:假设真实数据是 “猫咪图片” 的分布,流模型先从简单的正态分布中采样一个向量z(像随机选一块标准形状的橡皮泥),然后通过生成器G的一系列可逆变换(比如调整颜色、轮廓等操作),把z变成一张猫咪图片x。因为变换可逆,未来也能通过反向操作,从猫咪图片还原出最初的z。
4.2 训练过程
这里直接放豆包对图中损失函数的解读


4.2 代码实现(Flow)
class FlowModel(nn.Module):"""基于RealNVP的可逆流模型"""def __init__(self, input_dim=784, hidden_dim=512):super(FlowModel, self).__init__()# 定义可逆变换的参数网络self.scale_net = nn.Sequential(nn.Linear(input_dim//2, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, input_dim//2))self.shift_net = nn.Sequential(nn.Linear(input_dim//2, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, input_dim//2))def forward(self, x):# 分割输入为两部分(x1和x2)x1, x2 = x.chunk(2, dim=1)# 计算缩放和偏移参数s = self.scale_net(x1)t = self.shift_net(x1)# 变换x2z2 = x2 * torch.exp(s) + t# 合并结果并计算对数行列式z = torch.cat([x1, z2], dim=1)log_det = s.sum(dim=1) # 行列式的对数return z, log_detdef inverse(self, z):# 逆变换:从潜在变量恢复输入z1, z2 = z.chunk(2, dim=1)s = self.scale_net(z1)t = self.shift_net(z1)x2 = (z2 - t) * torch.exp(-s)x = torch.cat([z1, x2], dim=1)return x# 损失函数:负对数似然
def flow_loss(z, log_det):prior_logprob = -0.5 * (z ** 2).sum(dim=1) # 标准高斯先验return (-prior_logprob - log_det).mean()5 扩散模型(Diffusion)
5.1 概念
Diffusion Model(扩散模型)是一类深度生成模型,它的灵感来源于物理学中的扩散过程。与传统的生成模型(如VAE、GAN)不同,Diffusion Model通过模拟数据从随机噪声逐渐扩散到目标数据的过程来生成数据。这种模型在图像生成、文本生成和音频生成等领域都有出色的表现。

a. 核心思想:模拟 “破坏 - 修复” 的物理过程
- 扩散模型的灵感来自物理扩散现象,比如墨水滴入水中逐渐扩散
- 它把这个过程用在数据生成里,分两个阶段:
- 正向扩散(破坏):给干净数据(如图像)逐步加噪声,让数据从清晰变模糊,最后接近纯噪声(类似照片被雨水慢慢冲毁)
- 反向扩散(修复):从纯噪声出发,一步步去除噪声,恢复成清晰数据(类似修复老照片)通过学习这个过程,模型就能掌握数据的生成规律
b. 与其他模型的区别
- 传统生成模型(如 VAE、GAN)直接学习生成数据,而扩散模型像 “数据侦探”,通过拆解 “数据如何被噪声破坏” 的过程,反向学会 “如何从噪声还原数据”,生成的内容往往更细腻真实
5.2 训练过程

声。
图中损失函数的核心是衡量 “预测噪声” 与 “真实噪声” 的差距,常用均方误差(MSE):
- 逻辑:在正向扩散中,模型知道每个时间步加了多少真实噪声。训练时,U-net 根据带噪样本预测噪声,损失函数要求预测值尽可能接近真实噪声。就像教孩子 “找不同”,每次对比预测结果和真实答案,错得越多,损失越大,模型就会调整参数减少错误。
- 作用:通过最小化损失,U-net 学会分析带噪数据的特征,最终在反向扩散时,能用预测的噪声逐步还原出清晰数据。
详细介绍:
超详细的扩散模型(Diffusion Models)原理+代码 - 知乎
5.2 代码实现(Diffusion)
class DiffusionModel(nn.Module):"""基于UNet的扩散模型"""def __init__(self, image_size=28, channels=1):super(DiffusionModel, self).__init__()# 定义噪声预测网络(简化版UNet)self.net = nn.Sequential(nn.Conv2d(channels, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, channels, 3, padding=1))# 噪声调度参数self.num_steps = 1000self.betas = torch.linspace(1e-4, 0.02, self.num_steps)self.alphas = 1 - self.betasself.alpha_bars = torch.cumprod(self.alphas, dim=0)def forward(self, x, t):"""预测噪声ε"""return self.net(x)def train_step(self, x0):# 随机选择时间步tt = torch.randint(0, self.num_steps, (x0.size(0),))# 计算加噪后的xtsqrt_alpha_bar = torch.sqrt(self.alpha_bars[t]).view(-1, 1, 1, 1)sqrt_one_minus_alpha_bar = torch.sqrt(1 - self.alpha_bars[t]).view(-1, 1, 1, 1)epsilon = torch.randn_like(x0)xt = sqrt_alpha_bar * x0 + sqrt_one_minus_alpha_bar * epsilon# 预测噪声并计算损失epsilon_pred = self(xt, t)loss = F.mse_loss(epsilon_pred, epsilon)return lossdef sample(self, num_samples=16):"""从噪声逐步生成图像"""xt = torch.randn(num_samples, 1, 28, 28)for t in reversed(range(self.num_steps)):# 逐步去噪epsilon_pred = self(xt, t)xt = (xt - self.betas[t] * epsilon_pred) / torch.sqrt(self.alphas[t])if t > 0:xt += torch.sqrt(self.betas[t]) * torch.randn_like(xt)return xt6 小结
最后,简单回顾一下已经简单介绍过的5种常见的深度学习模型:
VAE(变分自编码器)、GAN(生成对抗网络)、AR(自回归模型 如 Transformer)、Flow(流模型)和 Diffusion(扩散模型)
我们可以看到不同模型的优缺点和适用场景:
- VAE和GAN是两种常用的深度生成模型,分别基于贝叶斯概率理论和对抗训练来生成样本
- AR模型则适用于处理具有时序依赖关系的数据,如序列数据
- Flow模型和Diffusion模型在生成样本上具有较好的稳定性和多样性,但需要较高的计算成本
最后提供一些潜在的问题和方法:
| 研究方向 | 核心问题 | 技术路径 | 典型应用场景 |
|---|---|---|---|
| 混合架构融合 | 单一模型难以兼顾生成质量与推理速度 | • Diffusion-GAN混合(扩散模型生成质量+GAN推理速度) • VAE-Transformer(压缩编码+序列建模) • 流模型与自回归模型联立训练 | • 高保真图像实时生成 • 长视频时序一致性优化 |
| 轻量化 | 大模型部署资源消耗过高 | • 知识蒸馏(教师-学生模型迁移) • 隐式神经表示(INR参数化生成) • 稀疏注意力机制与量化压缩 | • 移动端AI绘图APP • 边缘计算设备实时生成 |
| 物理约束嵌入 | 生成内容违反现实物理规律 | • 刚体动力学方程约束(牛顿力学+生成器) • 流体力学PDE求解器集成 • 符号逻辑引导的潜在空间优化 | • 科学模拟(气象/材料) • 机器人训练环境生成 |
部分参考:
数据派THU:必知!5大深度生成模型!
相关文章:

5种生成模型(VAE、GAN、AR、Flow 和 Diffusion)的对比梳理 + 易懂讲解 + 代码实现
目录 1 变分自编码器(VAE) 1.1 概念 1.2 训练损失 1.3 VAE 的实现 2 生成对抗网络(GAN) 2.1 概念 2.2 训练损失 a. 判别器的损失函数 b. 生成器的损失函数 c. 对抗训练的动态过程 2.3 GAN 的实现 3 自回归模型&am…...

doris:查询熔断
查询熔断是一种保护机制,用于防止长时间运行或消耗过多资源的查询对系统产生负面影响。当查询超过预设的资源或时间限制时,熔断机制会自动终止该查询,以避免对系统性能、资源使用以及其他查询造成不利影响。这种机制确保了集群在多用户环境下…...

多级缓存和数据一致性问题
一、什么是多级缓存? 多级缓存是一种分层的数据缓存策略,通过在不同层级(如本地、分布式、数据库)存储数据副本,结合各层缓存的访问速度和容量特性,优化系统的性能和资源利用率。其核心思想是让数据尽可能…...

计算机期刊推荐 | 计算机-人工智能、信息系统、理论和算法、软件工程、网络系统、图形学和多媒体, 工程技术-制造, 数学-数学跨学科应用
Computers, Materials & Continua 学科领域: 计算机-人工智能、信息系统、理论和算法、软件工程、网络系统、图形学和多媒体, 工程技术-制造, 数学-数学跨学科应用 期刊类型: SCI/SSCI/AHCI 收录数据库: SCI(SCIE),EI,Scopus,知网(CNK…...

全书测试:《C++性能优化指南》
以下20道多选题和10道设计题, 用于本书的测试。 以下哪些是C性能优化的核心策略?(多选) A) 优先优化所有代码段 B) 使用更高效的算法 C) 减少内存分配次数 D) 将所有循环展开 关于字符串优化,正确的措施包括ÿ…...

【教学类-58-14】黑白三角拼图12——单页1页图。参考图1页6张(黑白、彩色)、板式(无圆点、黑圆点、白圆点)、宫格2-10、张数6张,适合集体操作)
背景需求: 基于以下两个代码,设计一个单页1页黑白三角、彩色三角(包含黑点、白点、无点)的代码。 【教学类-58-12】黑白三角拼图10(N张参考图1张操作卡多张彩色白块,适合个别化)-CSDN博客文章…...

C++项目:高并发内存池_下
目录 8. thread cache回收内存 9. central cache回收内存 10. page cache回收内存 11. 大于256KB的内存申请和释放 11.1 申请 11.2 释放 12. 使用定长内存池脱离使用new 13. 释放对象时优化成不传对象大小 14. 多线程环境下对比malloc测试 15. 调试和复杂问题的调试技…...

消息队列性能比拼: Kafka vs RabbitMQ
本内容是对知名性能评测博主 Anton Putra Kafka vs RabbitMQ Performance 内容的翻译与整理, 有适当删减, 相关数据和结论以原作结论为准。 简介 在本视频中,我们将首先比较 Apache Kafka 和传统的 RabbitMQ。然后,在第二轮测试中,会将 Kaf…...
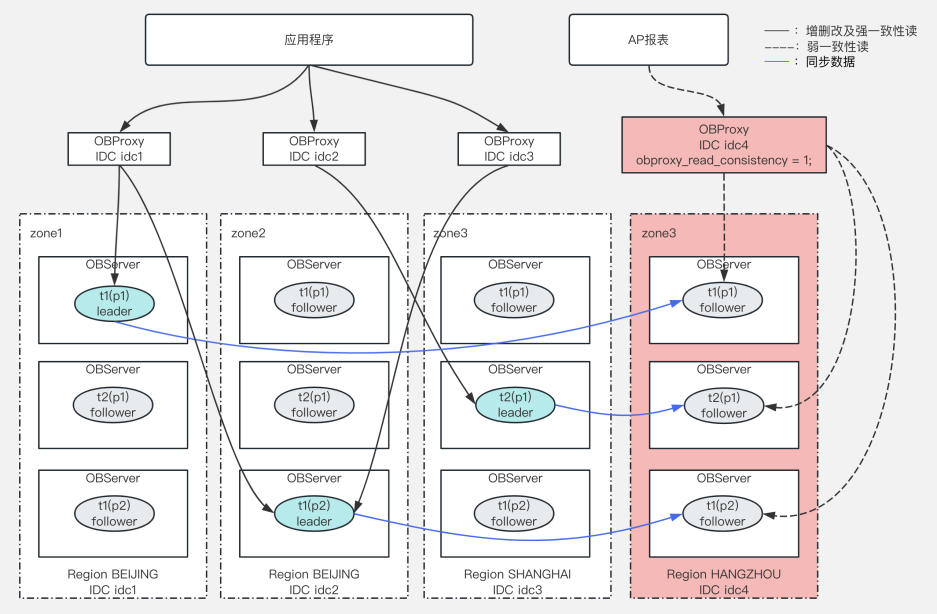
AP 场景架构设计(一) :OceanBase 读写分离策略解析
说明:本文内容对应的是 OceanBase 社区版,架构部分不涉及企业版的仲裁副本功能。OceanBase社区版和企业版的能力区别详见: 官网链接。 概述 当两种类型的业务共同运行在同一个数据库集群上时,这对数据库的配置等条件提出了较高…...

Java 大视界 -- Java 大数据在智能金融区块链跨境支付与结算中的应用(154)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

手把手教你在linux服务器部署deepseek,打造专属自己的数据库知识库
第一步:安装Ollama 打开官方网址:https://ollama.com/download/linux 下载Ollama linux版本 复制命令到linux操作系统执行 [rootpostgresql ~]# curl -fsSL https://ollama.com/install.sh | sh在Service中增加下面两行 [rootlocalhost ~]# vi /etc/…...

conda极速上手记录
什么是conda: Conda是一个跨平台的包管理工具和环境管理系统,支持Python、R、Java等多种语言。它能解决不同项目间的依赖冲突问题,例如: 项目A需要Python 3.6 NumPy 1.18; 项目B需要Python 3.10 NumPy 2.0。 通过创建独立环境&…...

C++ 继承:面向对象编程的核心概念(一)
文章目录 引言1. 继承的基本知识1.1 继承的关键词的区别1.2 继承类模版 2. 基类和派生类间的转换3. 继承中的作用域4. 派生类的默认成员函数4.1 默认成员函数的规则4.2 自己实现成员函数4.3 实现一个不能被继承的基类(基本不用) 引言 在C中,…...

蓝桥杯 临时抱佛脚 之 二分答案法与相关题目
二分答案法(利用二分法查找区间的左右端点) (1)估计 最终答案可能得范围 是什么 (2)分析 问题的答案 和 给定条件 之间的单调性,大部分时候只需要用到 自然智慧 (3)建…...

【图论】网络流算法入门
(决定狠狠加训图论了,从一直想学但没启动的网络流算法开始。) 网络流问题 • 问题定义:在带权有向图 G ( V , E ) G(V, E) G(V,E) 中,每条边 e ( u , v ) e(u, v) e(u,v) 有容量 c ( u , v ) c(u, v) c(u,v)&am…...

【算法day22】两数相除——给你两个整数,被除数 dividend 和除数 divisor。将两数相除,要求 不使用 乘法、除法和取余运算。
29. 两数相除 给你两个整数,被除数 dividend 和除数 divisor。将两数相除,要求 不使用 乘法、除法和取余运算。 整数除法应该向零截断,也就是截去(truncate)其小数部分。例如,8.345 将被截断为 8 &#x…...

《TypeScript 7天速成系列》第4天:TypeScript模块与命名空间:大型项目组织之道
在大型TypeScript项目中,良好的代码组织架构是保证项目可维护性的关键。本文将深入探讨TypeScript的模块系统和命名空间,为企业级项目提供最佳实践方案。 一、模块化开发:现代前端工程的基石 1.1 ES模块基础语法 TypeScript全面支持ES6模块…...

AutoCAD C#二次开发中WinForm与WPF的对比
在AutoCAD .NET二次开发中,选择WinForm还是WPF作为用户界面技术,需要根据项目需求、团队技能和AutoCAD版本等因素综合考虑。以下是详细对比: ## 1. 基础特性对比 | 特性 | WinForm | WPF | |------------|…...

关于服务器只能访问localhost:8111地址,局域网不能访问的问题
一、问题来源: 服务器是使用的阿里云的服务器,服务器端的8111端口没有设置任何别的限制,但是在阿里云服务器端并没有设置相应的tcp连接8111端口。 二、解决办法: 1、使用阿里云初始化好的端口;2、配置新的阿里云端口…...

基于ADMM无穷范数检测算法的MIMO通信系统信号检测MATLAB仿真,对比ML,MMSE,ZF以及LAMA
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1 ADMM算法 4.2 最大似然ML检测算法 4.3 最小均方误差(MMSE)检测算法 4.4 迫零(ZF)检测算法 4.5 OCD_MMSE 检测算法 4.6 LAMA检测算法 …...

Linux 配置时间服务器
一、同步阿里云服务器时间 服务端设置 1.检查chrony服务是否安装,设置chrony开机自启,查看chrony服务状态 [rootnode1-server ~]# rpm -q chrony # rpm -q 用于查看包是否安装 chrony-4.3-1.el9.x86_64 [rootnode1-server ~]# systemctl enable --n…...

可视化web组态开发工具
BY组态是一款功能强大的基于Web的可视化组态编辑器,采用标准HTML5技术,基于B/S架构进行开发,支持WEB端呈现,支持在浏览器端完成便捷的人机交互,简单的拖拽即可完成可视化页面的设计。可快速构建和部署可扩展的SCADA、H…...

深度学习驱动的车牌识别:技术演进与未来挑战
一、引言 1.1 研究背景 在当今社会,智能交通系统的发展日益重要,而车牌识别作为其关键组成部分,发挥着至关重要的作用。车牌识别技术广泛应用于交通管理、停车场管理、安防监控等领域。在交通管理中,它可以用于车辆识别、交通违…...

C++笔记-模板初阶,string(上)
一.模板初阶 1.泛型编程 以往我们要交换不同类型的两个数据就要写不同类型的交换函数,这是使用函数重载虽然可以实现,但是有以下几个不好的地方: 1.重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时&a…...

关于cmd中出现无法识别某某指令的问题
今天来解决以下这个比较常见的问题,安装各种软件都可能会发生,一般是安装时没勾选注册环境变量,导致cmd无法识别该指令。例如mysql,git等,一般初学者可能不太清楚。 解决这类问题最主要的是了解环境变量的概念&#x…...

绿联NAS安装内网穿透实现无公网IP也能用手机平板远程访问经验分享
文章目录 前言1. 开启ssh服务2. ssh连接3. 安装cpolar内网穿透4. 配置绿联NAS公网地址 前言 大家好,今天给大家带来一个超级炫酷的技能——如何在绿联NAS上快速安装cpolar内网穿透工具。想象一下,即使没有公网IP,你也能随时随地远程访问自己…...

d9-326
目录 一、添加逗号 二、爬楼梯 三、扑克牌顺子 添加逗号_牛客题霸_牛客网 (nowcoder.com) 一、添加逗号 没啥注意读题就是 注意逗号是从后往前加,第一位如果是3的倍数不需要加逗号,备注里面才是需要看的 count计数 是三的倍数就加逗号,…...
——汇编语言程序格式及MASM)
汇编(六)——汇编语言程序格式及MASM
汇编语言的实现也是先利用某种编辑器编写汇编语言源程序(*.ASM),然后经过汇编得到目标模块文件(*.OBJ)、连接后形成可执行文件(*.EXE)。 1、汇编语言程序的语句格式 汇编语源程序由语句序列构成…...

Win11+VS2022+CGAL5.6配置
1. CGAL库简介 CGAL(Computational Geometry Algorithms Library)是一个开源的计算几何算法库,主要用于处理几何问题和相关算法的实现。它提供了丰富的几何数据结构和高效算法,覆盖点、线、多边形、曲面等基本几何对象的表示与操…...

【Linux】MAC帧
目录 一、MAC帧 (一)IP地址和MAC地址 (二)MAC帧格式 (三)MTU对IP协议的影响、 (四)MTU对UDP协议的影响 (五)MTU对TCP协议的影响 二、以太网协议 &…...