多层感知机实现
激活函数
非线性
ReLU函数
修正线性单元 rectified linear unit
relu(x)=max(0,x)

relu的导数:

sigmoid函数
s i g m o i d ( x ) = 1 1 + e − x sigmoid(x)=\frac{1}{1+e^{-x}} sigmoid(x)=1+e−x1
是一个早期的激活函数
缺点是:
- 幂运算相对耗时,因此函数计算量较大
- 在反向传播时容易出现梯度消失的情况
- 收敛缓慢

导数是sigmoid(x)(1-sigmoid(x)):

Tanh 函数
双曲正切函数
t a n h ( x ) = 1 − e − 2 x 1 + e − 2 x tanh(x)=\frac{1-e^{-2x}}{1+e^{-2x}} tanh(x)=1+e−2x1−e−2x

导数: 1 − t a n h 2 ( x ) 1-tanh^2(x) 1−tanh2(x)

幂运算,同样存在计算量大的问题
阶跃函数

Leaky ReLU 函数 (LReLU)

如果在学习过程中,a 并不设定为一个常量,而是一个可通过反向传播算法学习的变量,则此时带泄露线性整流又被称为参数线性整流 (Parametric ReLU, PReLU)。
SoftPlus 函数
可以看成是 ReLU 函数的平滑版

多层感知机
multilayer perceptron

手写实现
import torch
from torch import nn
from torchvision import transforms
import torchvision
from torch.utils import data
import matplotlib.pyplot as plt#加载fashion_mnist数据集
def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)#print(len(mnist_train),len(mnist_test))return (data.DataLoader(mnist_train, batch_size, shuffle=True),data.DataLoader(mnist_test, batch_size, shuffle=False)) #windows下不能多进程,linux下可以#批大小
batch_size = 256
#训练和测试的迭代器
train_iter, test_iter = load_data_fashion_mnist(batch_size)num_inputs,num_outputs,num_hiddens=784,10,256W1=nn.Parameter(torch.randn(num_inputs,num_hiddens,requires_grad=True)*0.01)
b1=nn.Parameter(torch.zeros(num_hiddens),requires_grad=True)
W2=nn.Parameter(torch.randn(num_hiddens,num_outputs,requires_grad=True)*0.01)
b2=nn.Parameter(torch.zeros(num_outputs),requires_grad=True)
params=[W1,b1,W2,b2]def relu(x):a=torch.zeros_like(x)return torch.max(x,a)
def net(x):x=x.reshape(-1,num_inputs)h=relu(x@W1+b1)return (h@W2+b2)
loss=nn.CrossEntropyLoss(reduction='none')
num_epochs,lr=10,0.01
updater=torch.optim.SGD(params,lr=lr)
def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):"""设置matplotlib的轴"""axes.set_xlabel(xlabel)axes.set_ylabel(ylabel)axes.set_xscale(xscale)axes.set_yscale(yscale)axes.set_xlim(xlim)axes.set_ylim(ylim)if legend:axes.legend(legend)axes.grid()
class Animator: """在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):# 增量地绘制多条线if legend is None:legend = []self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]# 使⽤lambda函数捕获参数self.config_axes = lambda: set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):# 向图表中添加多个数据点if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()#display.display(self.fig)# 通过以下两行代码实现了在PyCharm中显示动图plt.draw()#plt.pause(interval=0.001)#display.clear_output(wait=True)
#精度计算函数
def accuracy(y_hat, y): """计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())
class Accumulator: """在n个变量上累加"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]
#训练单轮
def train_epoch_ch3(net, train_iter, loss, updater): """训练模型⼀个迭代周期(定义⻅第3章)"""# 将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 训练损失总和、训练准确度总和、样本数metric = Accumulator(3)for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):# 使⽤PyTorch内置的优化器和损失函数updater.zero_grad() #清除梯度l.mean().backward() #反向传播updater.step()else:# 使⽤定制的优化器和损失函数l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度return metric[0] / metric[2], metric[1] / metric[2]
#训练
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save"""训练模型(定义⻅第3章)"""animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch_ch3(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metrics# assert train_loss < 0.5, train_loss# assert train_acc <= 1 and train_acc > 0.7, train_acc# assert test_acc <= 1 and test_acc > 0.7, test_acctrain_ch3(net,train_iter,test_iter,loss,num_epochs,updater)
plt.show()def get_fashion_mnist_labels(labels):text_labels=['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]
#展示数据集图片的函数
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): """绘制图像列表"""figsize = (num_cols * scale, num_rows * scale)_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):# 图⽚张量ax.imshow(img.numpy())else:# PIL图⽚ax.imshow(img)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])plt.show()return axes
def predict_ch3(net, test_iter, n=6):"""预测标签(定义⻅第3章)"""for X, y in test_iter:breaktrues = get_fashion_mnist_labels(y)preds = get_fashion_mnist_labels(net(X).argmax(axis=1))titles = [true +'\n' + pred for true, pred in zip(trues, preds)]show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])predict_ch3(net, test_iter)
结果:


调库实现
import torch
from torch import nn
from torchvision import transforms
import torchvision
from torch.utils import data
import matplotlib.pyplot as pltnet=nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10) )
def init_weights(m):if type(m)==nn.Linear:nn.init.normal_(m.weight,std=0.01)
net.apply(init_weights)
batch_size,lr,num_epochs=256,0.1,10
loss=nn.CrossEntropyLoss(reduction='none')
trainer=torch.optim.SGD(net.parameters(),lr=lr)
def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)#print(len(mnist_train),len(mnist_test))return (data.DataLoader(mnist_train, batch_size, shuffle=True),data.DataLoader(mnist_test, batch_size, shuffle=False)) #windows下不能多进程,linux下可以
train_iter, test_iter = load_data_fashion_mnist(batch_size)
def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):"""设置matplotlib的轴"""axes.set_xlabel(xlabel)axes.set_ylabel(ylabel)axes.set_xscale(xscale)axes.set_yscale(yscale)axes.set_xlim(xlim)axes.set_ylim(ylim)if legend:axes.legend(legend)axes.grid()
class Animator: """在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):# 增量地绘制多条线if legend is None:legend = []self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]# 使⽤lambda函数捕获参数self.config_axes = lambda: set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):# 向图表中添加多个数据点if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()#display.display(self.fig)# 通过以下两行代码实现了在PyCharm中显示动图plt.draw()#plt.pause(interval=0.001)#display.clear_output(wait=True)
#精度计算函数
def accuracy(y_hat, y): """计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())
class Accumulator: """在n个变量上累加"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]
#训练单轮
def train_epoch_ch3(net, train_iter, loss, updater): """训练模型⼀个迭代周期(定义⻅第3章)"""# 将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 训练损失总和、训练准确度总和、样本数metric = Accumulator(3)for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):# 使⽤PyTorch内置的优化器和损失函数updater.zero_grad() #清除梯度l.mean().backward() #反向传播updater.step()else:# 使⽤定制的优化器和损失函数l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度return metric[0] / metric[2], metric[1] / metric[2]
#训练
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save"""训练模型(定义⻅第3章)"""animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch_ch3(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metrics# assert train_loss < 0.5, train_loss# assert train_acc <= 1 and train_acc > 0.7, train_acc# assert test_acc <= 1 and test_acc > 0.7, test_acctrain_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
plt.show()

欠拟合和过拟合
影响模型泛化的因素:
- 参数的数量,越多越容易过拟合
- 参数的取值,取值范围越大,越容易过拟合
- 训练样本的数量,越少越容易过拟合
欠拟合:泛化能力差,训练样本集准确率低,测试样本集准确率低。
过拟合:泛化能力差,训练样本集准确率高,测试样本集准确率低。
合适的拟合程度:泛化能力强,训练样本集准确率高,测试样本集准确率高
欠拟合原因:
- 训练样本数量少
- 模型复杂度过低
- 参数还未收敛就停止循环
欠拟合的解决办法:
- 增加样本数量
- 增加模型参数,提高模型复杂度
- 增加循环次数
- 查看是否是学习率过高导致模型无法收敛
防止过拟合的方法:
- 增加训练集的样本数
- 交叉验证
- 数据增强
- 早停法
- 降低模型复杂度
- Dropout(随机丢弃)
- 正则化regularization(在loss里加入惩罚项)
权重衰减 weight_decay是正则化技术之一,即L2正则化
L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。
L ( w , b ) + λ 2 ∣ ∣ w ∣ ∣ 2 L(w,b)+\frac{\lambda}{2}||w||^2 L(w,b)+2λ∣∣w∣∣2
L2正则化线性模型构成岭回归算法,L1构成套索回归算法。
def l2_penalty(w):return (w**2).sum() / 2
l = loss(net(X, w, b), y) + lambd * l2_penalty(w)
暂退法dropout
手动实现
import torch
from torch import nn
from torchvision import transforms
import torchvision
from torch.utils import data
import matplotlib.pyplot as pltnum_inputs,num_outputs,num_hiddens1,num_hiddens2=784,10,256,256
dropout1,dropout2=0.2,0.5
def dropout_layer(x,dropout):assert 0<=dropout<=1if dropout==1:return torch.zeros_like(x)if dropout==0:return xmask=(torch.rand(x.shape)>dropout).float()return mask*x/(1.0-dropout)class Net(nn.Module):def __init__(self,num_inputs,num_outputs,num_hiddens1,num_hiddens2,is_training=True):super(Net,self).__init__()self.num_inputs=num_inputsself.training=is_trainingself.lin1=nn.Linear(num_inputs,num_hiddens1)self.lin2=nn.Linear(num_hiddens1,num_hiddens2)self.lin3=nn.Linear(num_hiddens2,num_outputs)self.relu=nn.ReLU()def forward(self,x):h1=self.relu(self.lin1(x.reshape((-1,self.num_inputs))))if self.training==True:h1=dropout_layer(h1,dropout1)h2=self.relu(self.lin2(h1))if self.training==True:h2=dropout_layer(h2,dropout2)out=self.lin3(h2)return outnet=Net(num_inputs,num_outputs,num_hiddens1,num_hiddens2)num_epochs,lr,batch_size=10,0.5,256
loss=nn.CrossEntropyLoss(reduction='none')def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)#print(len(mnist_train),len(mnist_test))return (data.DataLoader(mnist_train, batch_size, shuffle=True),data.DataLoader(mnist_test, batch_size, shuffle=False)) #windows下不能多进程,linux下可以
train_iter, test_iter = load_data_fashion_mnist(batch_size)trainer=torch.optim.SGD(net.parameters(),lr=lr)def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):"""设置matplotlib的轴"""axes.set_xlabel(xlabel)axes.set_ylabel(ylabel)axes.set_xscale(xscale)axes.set_yscale(yscale)axes.set_xlim(xlim)axes.set_ylim(ylim)if legend:axes.legend(legend)axes.grid()
class Animator: """在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):# 增量地绘制多条线if legend is None:legend = []self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]# 使⽤lambda函数捕获参数self.config_axes = lambda: set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):# 向图表中添加多个数据点if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()#display.display(self.fig)# 通过以下两行代码实现了在PyCharm中显示动图plt.draw()#plt.pause(interval=0.001)#display.clear_output(wait=True)
#精度计算函数
def accuracy(y_hat, y): """计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())
class Accumulator: """在n个变量上累加"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]
#训练单轮
def train_epoch_ch3(net, train_iter, loss, updater): """训练模型⼀个迭代周期(定义⻅第3章)"""# 将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 训练损失总和、训练准确度总和、样本数metric = Accumulator(3)for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):# 使⽤PyTorch内置的优化器和损失函数updater.zero_grad() #清除梯度l.mean().backward() #反向传播updater.step()else:# 使⽤定制的优化器和损失函数l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度return metric[0] / metric[2], metric[1] / metric[2]
#训练
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save"""训练模型(定义⻅第3章)"""animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch_ch3(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metrics# assert train_loss < 0.5, train_loss# assert train_acc <= 1 and train_acc > 0.7, train_acc# assert test_acc <= 1 and test_acc > 0.7, test_acctrain_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
plt.show()

调库实现
import torch
from torch import nn
from torchvision import transforms
import torchvision
from torch.utils import data
import matplotlib.pyplot as plt
dropout1,dropout2=0.2,0.5
net=nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Dropout(dropout1),nn.Linear(256,256),nn.ReLU(),nn.Dropout(dropout2),nn.Linear(256,10)
)
def init_weights(m):if type(m)==nn.Linear:nn.init.normal_(m.weight,std=0.01)
net.apply(init_weights)num_epochs,lr,batch_size=10,0.5,256
loss=nn.CrossEntropyLoss(reduction='none')def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)#print(len(mnist_train),len(mnist_test))return (data.DataLoader(mnist_train, batch_size, shuffle=True),data.DataLoader(mnist_test, batch_size, shuffle=False)) #windows下不能多进程,linux下可以
train_iter, test_iter = load_data_fashion_mnist(batch_size)trainer=torch.optim.SGD(net.parameters(),lr=lr)def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):"""设置matplotlib的轴"""axes.set_xlabel(xlabel)axes.set_ylabel(ylabel)axes.set_xscale(xscale)axes.set_yscale(yscale)axes.set_xlim(xlim)axes.set_ylim(ylim)if legend:axes.legend(legend)axes.grid()
class Animator: """在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):# 增量地绘制多条线if legend is None:legend = []self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]# 使⽤lambda函数捕获参数self.config_axes = lambda: set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):# 向图表中添加多个数据点if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()#display.display(self.fig)# 通过以下两行代码实现了在PyCharm中显示动图plt.draw()#plt.pause(interval=0.001)#display.clear_output(wait=True)
#精度计算函数
def accuracy(y_hat, y): """计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())
class Accumulator: """在n个变量上累加"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]
#训练单轮
def train_epoch_ch3(net, train_iter, loss, updater): """训练模型⼀个迭代周期(定义⻅第3章)"""# 将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 训练损失总和、训练准确度总和、样本数metric = Accumulator(3)for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):# 使⽤PyTorch内置的优化器和损失函数updater.zero_grad() #清除梯度l.mean().backward() #反向传播updater.step()else:# 使⽤定制的优化器和损失函数l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度return metric[0] / metric[2], metric[1] / metric[2]
#训练
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save"""训练模型(定义⻅第3章)"""animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch_ch3(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metrics# assert train_loss < 0.5, train_loss# assert train_acc <= 1 and train_acc > 0.7, train_acc# assert test_acc <= 1 and test_acc > 0.7, test_acctrain_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
plt.show()

梯度消失
gradient vanishing =梯度弥散=参数更新过小,每次基本不会移动
sigmoid会导致这个问题
梯度爆炸
初始化设置不合理,没有机会让梯度下降优化器收敛,解决方法:参数初始化
初始化可以是正态分布,或者框架的默认初始化方法。
或Xavier初始化方法:从均值为0,方差为 2 n i n + n o u t \frac{2}{n_{in}+n_{out}} nin+nout2的高斯分布里抽样权重,或从同方差的均匀分布里抽样(均匀分布U(-a,a)的方差是a^2/3),这个初始化方法很常用。
相关文章:
多层感知机实现
激活函数 非线性 ReLU函数 修正线性单元 rectified linear unit relu(x)max(0,x) relu的导数: sigmoid函数 s i g m o i d ( x ) 1 1 e − x sigmoid(x)\frac{1}{1e^{-x}} sigmoid(x)1e−x1 是一个早期的激活函数 缺点是: 幂运算相对耗时&…...

ngx_http_index_set_index
定义在 src\http\modules\ngx_http_index_module.c static char * ngx_http_index_set_index(ngx_conf_t *cf, ngx_command_t *cmd, void *conf) {ngx_http_index_loc_conf_t *ilcf conf;ngx_str_t *value;ngx_uint_t i, n;ngx_http_inde…...

怎样实现CAN数据的接收和发送?
在裸机环境下实现CAN数据的接收和发送,需要通过 硬件寄存器操作 或 HAL库函数 结合 手动实现的队列 来完成。以下是完整的接收和发送流程实现: 1. 硬件初始化 首先初始化CAN控制器和GPIO: void CAN_Init(void) {// 1. 使能CAN时钟__HAL_RCC…...

Linux笔记---动静态库(使用篇)
目录 1. 库的概念 2. 静态库(Static Libraries) 2.1 静态库的制作 2.2 静态库的使用 2.2.1 显式指定库文件及头文件路径 2.2.2 将库文件安装到系统目录 2.2.3 将头文件安装到系统目录 3. 动态库 3.1 动态库的制作 3.2 动态库的使用 3.2.1 显式…...

关于matlab和python谁快的问题
关于matlab和python谁快的问题,python比matlab在乘法上快10倍,指数计算快4倍,加减运算持平,略慢于matlab。或许matlab只适合求解特征值。 import torch import timen 50000 # 矩阵规模 M torch.rand(n, 31)start_time time.t…...

基于 ffmpeg 实现合并视频
ffmpeg是一个强大的多媒体处理工具,支持视频文件的合并。 列出目录下所有MP4文件 import os import glob# 当前目录 directory os.getcwd() directory "/directory/to/mp4/*"# 列出目录下所有MP4文件 files glob.glob(directory)# 排序 files.sort(…...

手机销售终端MPR+LTC项目项目总体方案P183(183页PPT)(文末有下载方式)
资料解读:手机销售终端 MPRLTC 项目项目总体方案 详细资料请看本解读文章的最后内容。在当今竞争激烈的市场环境下,企业的销售模式和流程对于其发展起着至关重要的作用。华为终端正处于销售模式转型的关键时期,波士顿 - 华为销售终端 MPRLTC …...

【Python LeetCode Patterns】刷力扣,15 个学习模式总结
1. 前缀和(Prefix Sum)—— 查询子数组中元素和303. 区域和检索 - 数组不可变304. 二维区域和检索 - 矩阵不可变 2. 双指针(Two Pointers)—— 移向彼此或远离彼此3. 滑动窗口(Sliding Window)—— 找到满足…...

蓝桥杯单片机刷题——串口发送显示
设计要求 通过串口接收字符控制数码管的显示,PC端发送字符A,数码管显示A,发送其它非法字符时,数码管显示E。 数码管显示格式如下: 备注: 单片机IRC振荡器频率设置为12MHz。 串口通信波特率:…...

DeepSeek V3-0324升级:开启人机共创新纪元
一、技术平权:开源协议重构AI权力格局 DeepSeek V3选择MIT协议开源6850亿参数模型,本质上是一场针对技术垄断的“数字起义”。这一决策的深层影响在于: 商业逻辑的重构 闭源AI公司依赖API收费的商业模式面临根本性挑战。当顶级模型能力可通过…...

探索抓包利器ProxyPin,实现手机APP请求抓包,支持https请求
以下是ProxyPin的简单介绍: - ProxyPin是一个开源免费HTTP(S)流量捕获神器,支持 Windows、Mac、Android、IOS、Linux 全平台系统- 可以使用它来拦截、检查并重写HTTP(S)流量,支持捕获各种应用的网络请求。ProxyPin基于Flutter开发࿰…...

K8S接口请求过程
K8S接口请求过程 1. 宿主机IP (Host IP)2. Service IP3. NodePort4. Pod端口 (Pod Port)5. 容器端口 (Container Port)6. 应用端口 (Application Port)例子:外部流量如何进入应用配置流量路径表详细说明补充说明--连通性测试: 在Kubernetes(k…...

文献学习:单细胞+临床+模型构建 | 一篇Molecular Cancer文献如何完整解读CDK4/6i耐药机制
👋 欢迎关注我的生信学习专栏~ 如果觉得文章有帮助,别忘了点赞、关注、评论! 📌一、研究背景:CDK4/6i 是不是“万无一失”? HR/HER2- 是最常见的乳腺癌亚型,占比超过70%。近年来,随…...

3.26前端模拟面试
包含 Vue 3、TypeScript、性能优化、工程化等方面,偏八股文。 基础知识 Vue 3 响应式原理:Vue 3 如何实现响应式系统?Proxy 和 Reflect 的作用是什么? TypeScript 类型体操:实现一个 TypeScript 类型 DeepPartial&am…...

Python SciPy面试题及参考答案
目录 什么是 SciPy?它与 NumPy 有什么区别? 如何在 Python 中安装 SciPy? 如何导入 SciPy 库? SciPy 中有哪些子模块?简要介绍它们的功能。 如何使用 SciPy 进行数值积分?请举例说明。 SciPy 中提供了哪些求解微分方程的函数? 什么是插值?SciPy 中如何进行插值?…...

数据库——MySQL基础
一、建立数据库 新建 create 删除 drop 修改 alter 数据库 database 数据表 table 建数据表 create table stu( 字段名 类型 [ 约束 ] [ 主键 ] [注释] ); 二、数据类型 数字 整数 tinyint (小型数据)一般用来做状态…...

Jetpack LiveData 使用与原理解析
一、引言 在 Android 开发中,数据的变化需要及时反映到界面上是一个常见的需求。然而,传统的方式可能会导致代码复杂、难以维护,并且容易出现内存泄漏等问题。Jetpack 组件中的 LiveData 为我们提供了一种优雅的解决方案,它是一种…...

HarmonyOS Next~鸿蒙系统开发类Kit深度解析与应用实践
HarmonyOS Next~鸿蒙系统开发类Kit深度解析与应用实践 鸿蒙系统(HarmonyOS)凭借其分布式架构和全场景能力,为开发者提供了丰富的开发类Kit。本文将从安全、网络、基础功能、硬件及调测五大类Kit展开,深入探讨其核心技…...

网盘解析工具更新,解决了一些bug
解析工具v1.2.1版本更新,本次是小版本更新,修复了一些bug。 之前小伙伴反应的网盘进入文件后不能返回上一级,现在这个bug修复了,已经可以点击了。 点击资源后会回到资源那一级目录,操作上是方便了不少。 增加了检查自…...
 (DDL语句以及DML语句))
SQL语句及其应用(上) (DDL语句以及DML语句)
SQL语句的定义: 概述: 全称叫 Structured Query Language, 结构化查询语言, 主要是实现 用户(程序员) 和 数据库软件(例如: MySQL, Oracle)之间交互用的. 分类: DDL: 数据定义语言, 主要是操作 数据库, 数据表, 字段, 进行: 增删改查(CURD) 涉及到的关键字: create, drop, …...

混境之地1
问题描述 小蓝有一天误入了一个混境之地。 好消息是:他误打误撞拿到了一张地图,并从中获取到以下信息: 混境之地的大小为 n⋅mn⋅m,其中 # 表示这个位置很危险,无法通行,. 表示道路,可以通行。他…...

5种生成模型(VAE、GAN、AR、Flow 和 Diffusion)的对比梳理 + 易懂讲解 + 代码实现
目录 1 变分自编码器(VAE) 1.1 概念 1.2 训练损失 1.3 VAE 的实现 2 生成对抗网络(GAN) 2.1 概念 2.2 训练损失 a. 判别器的损失函数 b. 生成器的损失函数 c. 对抗训练的动态过程 2.3 GAN 的实现 3 自回归模型&am…...

doris:查询熔断
查询熔断是一种保护机制,用于防止长时间运行或消耗过多资源的查询对系统产生负面影响。当查询超过预设的资源或时间限制时,熔断机制会自动终止该查询,以避免对系统性能、资源使用以及其他查询造成不利影响。这种机制确保了集群在多用户环境下…...

多级缓存和数据一致性问题
一、什么是多级缓存? 多级缓存是一种分层的数据缓存策略,通过在不同层级(如本地、分布式、数据库)存储数据副本,结合各层缓存的访问速度和容量特性,优化系统的性能和资源利用率。其核心思想是让数据尽可能…...

计算机期刊推荐 | 计算机-人工智能、信息系统、理论和算法、软件工程、网络系统、图形学和多媒体, 工程技术-制造, 数学-数学跨学科应用
Computers, Materials & Continua 学科领域: 计算机-人工智能、信息系统、理论和算法、软件工程、网络系统、图形学和多媒体, 工程技术-制造, 数学-数学跨学科应用 期刊类型: SCI/SSCI/AHCI 收录数据库: SCI(SCIE),EI,Scopus,知网(CNK…...

全书测试:《C++性能优化指南》
以下20道多选题和10道设计题, 用于本书的测试。 以下哪些是C性能优化的核心策略?(多选) A) 优先优化所有代码段 B) 使用更高效的算法 C) 减少内存分配次数 D) 将所有循环展开 关于字符串优化,正确的措施包括ÿ…...

【教学类-58-14】黑白三角拼图12——单页1页图。参考图1页6张(黑白、彩色)、板式(无圆点、黑圆点、白圆点)、宫格2-10、张数6张,适合集体操作)
背景需求: 基于以下两个代码,设计一个单页1页黑白三角、彩色三角(包含黑点、白点、无点)的代码。 【教学类-58-12】黑白三角拼图10(N张参考图1张操作卡多张彩色白块,适合个别化)-CSDN博客文章…...

C++项目:高并发内存池_下
目录 8. thread cache回收内存 9. central cache回收内存 10. page cache回收内存 11. 大于256KB的内存申请和释放 11.1 申请 11.2 释放 12. 使用定长内存池脱离使用new 13. 释放对象时优化成不传对象大小 14. 多线程环境下对比malloc测试 15. 调试和复杂问题的调试技…...

消息队列性能比拼: Kafka vs RabbitMQ
本内容是对知名性能评测博主 Anton Putra Kafka vs RabbitMQ Performance 内容的翻译与整理, 有适当删减, 相关数据和结论以原作结论为准。 简介 在本视频中,我们将首先比较 Apache Kafka 和传统的 RabbitMQ。然后,在第二轮测试中,会将 Kaf…...
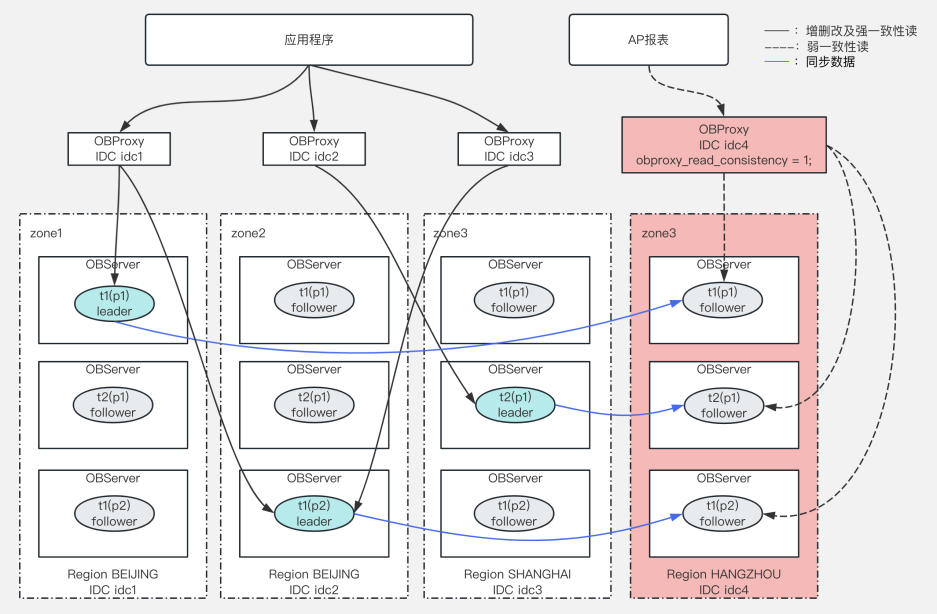
AP 场景架构设计(一) :OceanBase 读写分离策略解析
说明:本文内容对应的是 OceanBase 社区版,架构部分不涉及企业版的仲裁副本功能。OceanBase社区版和企业版的能力区别详见: 官网链接。 概述 当两种类型的业务共同运行在同一个数据库集群上时,这对数据库的配置等条件提出了较高…...