Redis常见面试问题汇总
Redis 面试笔记整理
- 一、Redis 基础知识
- 1. Redis 概述
- Redis 是什么?主要特点有哪些?
- Redis 和 Memcached 的区别是什么?
- Redis 是单线程还是多线程?为什么单线程还能高效?
- Redis 6.0 之后的多线程模型是怎样的?
- 2. Redis 数据类型
- Redis 支持的数据类型及使用场景
- String(字符串)
- Hash(哈希)
- List(列表)
- Set(集合)
- ZSet(有序集合)
- Bitmap(位图)
- HyperLogLog(基数统计)
- GEO(地理空间)
- Stream(消息流)
- 底层实现原理
- ZSet实现(跳表+哈希表)
- Hash实现(压缩列表或哈希表)
- 3. Redis 持久化
- Redis 的持久化机制
- RDB 和 AOF 的区别与优缺点
- RDB 触发方式
- AOF 重写机制
- 生产环境配置建议
- 二、Redis 高可用与集群
- 1. 主从复制
- Redis 主从复制原理
- 主从复制常见问题
- 主从复制性能优化
- 2. Redis Sentinel(哨兵)
- Redis Sentinel 的作用
- 故障检测机制
- Sentinel 选举机制
- 3. Redis Cluster(集群)
- Redis Cluster 数据分片
- 节点通信机制
- 集群扩缩容
- 请求重定向机制
- 三、Redis 缓存问题
- 1. 缓存穿透、缓存雪崩、缓存击穿
- 缓存穿透
- 缓存雪崩
- 缓存击穿
- 2. 缓存一致性
- 如何保证缓存与数据库的数据一致性
- 先更新数据库再删缓存(推荐方案)
- 延迟双删策略
- 其他保障措施
- 缓存更新策略
- Cache Aside(旁路缓存)
- Read/Write Through
- Write Behind
- 3. 缓存淘汰策略
- Redis内存淘汰策略
- 策略选择建议
- 四、Redis 高级特性与优化
- 1. Redis 事务与 Lua 脚本
- Redis 事务(MULTI/EXEC)工作机制
- WATCH 命令(乐观锁实现)
- Lua 脚本优势及原子性保证
- 2. Redis 性能优化
- Redis Pipeline 机制
- BigKey 问题处理
- 慢查询分析
- 连接数优化
- 3. Redis 网络与安全
- Redis 通信协议 (RESP)
- 安全认证配置
- SCAN vs KEYS 命令
- 五、Redis 应用场景
- 1. 常见业务场景
- 分布式锁实现
- 限流方案
- 排行榜实现
- 消息队列方案
- Session共享
- 秒杀系统实现
- 2. 高级应用
- 布隆过滤器实现
- HyperLogLog统计UV
- GEO地理位置
- BitMap签到功能
- 六、Redis 与其他技术结合
- Spring Boot 集成 Redis
- Redis + MySQL 配合方案
- Redis 和本地缓存(Caffeine、Guava Cache)如何选择?
- 选择依据对比
- 电商分层缓存实战示例
- 场景:商品详情页缓存
- 选型建议
- 必须使用Redis的场景
- 优先本地缓存的场景
- 七、Redis 底层实现
- Redis 的 SDS(Simple Dynamic String)和 C 字符串区别
- Redis 字典(Hash 表)实现
- Redis 跳跃表(Skip List)工作原理
- Redis 过期键删除策略
一、Redis 基础知识
1. Redis 概述
Redis 是什么?主要特点有哪些?
- Redis(Remote Dictionary Server)是一个开源的、基于内存的键值存储系统
- 主要特点:
- 高性能:数据存储在内存中,读写速度极快(10万+ QPS)
- 支持多种数据结构:String、Hash、List、Set、ZSet等
- 持久化:支持RDB和AOF两种持久化方式
- 高可用:支持主从复制、哨兵、集群模式
- 原子操作:支持事务和Lua脚本保证原子性
Redis 和 Memcached 的区别是什么?
| 特性 | Redis | Memcached |
|---|---|---|
| 数据类型 | 支持多种数据结构 | 仅支持简单的key-value |
| 持久化 | 支持RDB和AOF持久化 | 不支持持久化 |
| 集群模式 | 原生支持Cluster模式 | 需要客户端实现分布式 |
| 线程模型 | 单线程(6.0+支持多线程I/O) | 多线程 |
| 内存管理 | 支持内存淘汰策略 | 固定大小内存,LRU淘汰 |
| 适用场景 | 缓存、消息队列、计数器等复杂场景 | 简单的键值缓存场景 |
Redis 是单线程还是多线程?为什么单线程还能高效?
- Redis 核心网络模型是单线程的(6.0之前是完全单线程)
- 高效的原因:
- 基于内存操作,没有磁盘I/O瓶颈
- 单线程避免了多线程的上下文切换和竞争条件
- 非阻塞I/O多路复用(epoll/kqueue)
- 精心优化的数据结构(如跳表、哈希表)
Redis 6.0 之后的多线程模型是怎样的?
- Redis 6.0 引入了多线程I/O(默认关闭,需配置)
- 模型特点:
- 主线程仍处理命令执行(保持单线程特性)
- 新增I/O线程(默认4个)负责:
- 网络读:解析客户端请求
- 网络写:返回结果给客户端
- 配置参数:
io-threads 4 # 启用4个I/O线程 io-threads-do-reads yes # 启用读多线程
- 注意:
- 实际命令执行仍是单线程
- 性能提升主要在超高并发网络I/O场景
2. Redis 数据类型
Redis 支持的数据类型及使用场景
String(字符串)
- 存储结构:二进制安全的字符串,最大512MB
- 典型场景:
- 缓存对象(JSON序列化存储)
- 计数器(INCR/DECR命令)
- 分布式锁(SETNX实现)
- 会话管理(Session存储)
- 特殊操作:
SETEX key seconds value # 带过期时间设置GETSET key new_value # 设置新值返回旧值MSET/MGET # 批量操作
Hash(哈希)
- 存储结构:field-value映射表
- 典型场景:
- 存储对象属性(用户资料)
- 购物车数据(用户ID+商品ID)
- 配置信息集合
- 优势:
- 比String更节省空间(避免重复key)
- 支持部分字段操作
List(列表)
- 存储结构:双向链表
- 典型场景:
- 消息队列(LPUSH+BRPOP)
- 最新消息排行(朋友圈)
- 数据分页(LRANGE)
- 特点:
LPUSH/RPUSH # 左右插入BLPOP/BRPOP # 阻塞式弹出
Set(集合)
- 存储结构:无序唯一集合
- 典型场景:
- 好友关系(共同好友SINTER)
- 抽奖活动(SRANDMEMBER)
- 标签系统
- 核心命令:
SADD/SREM # 增删元素SISMEMBER # 判断存在SUNION/SDIFF # 并集/差集
ZSet(有序集合)
- 存储结构:跳表+哈希表
- 典型场景:
- 排行榜(ZREVRANGE)
- 延迟队列(时间戳作为score)
- 优先级任务
- 特点:
ZADD key score member # 带分数插入ZRANGEBYSCORE # 按分数范围查询
Bitmap(位图)
- 存储结构:String的位操作
- 典型场景:
- 用户签到(SETBIT)
- 活跃用户统计
- 布隆过滤器实现
- 示例:
SETBIT sign:2023:user1 1 1 # 第1天签到BITCOUNT sign:2023:user1 # 签到总数
HyperLogLog(基数统计)
- 存储结构:概率算法
- 典型场景:
- UV统计(去重计数)
- 大规模数据去重
- 特点:
- 固定12KB存储空间
- 误差率约0.81%
PFADD/PFCOUNT # 添加/计数
GEO(地理空间)
- 存储结构:ZSet扩展
- 典型场景:
- 附近的人
- 位置搜索
- 距离计算
- 核心命令:
GEOADD key 经度 纬度 memberGEORADIUS # 半径查询
Stream(消息流)
- 存储结构:持久化消息队列
- 典型场景:
- 消息队列(替代List)
- 事件溯源
- 日志收集
- 特点:
XADD/XREAD # 生产/消费Consumer Groups # 消费者组支持
底层实现原理
ZSet实现(跳表+哈希表)
- 跳表结构:
- 多层链表,查询复杂度O(logN)
- 支持范围查询
- 哈希表:
- 存储member到score的映射
- O(1)时间复杂度查询单个元素
- 内存优化:
- 元素小于128字节且数量<512时使用ziplist
Hash实现(压缩列表或哈希表)
- ziplist条件:
- 所有field/value长度<64字节
- field数量<512
- hashtable:
- 字典结构(数组+链表)
- 渐进式rehash策略
- 转换阈值:
hash-max-ziplist-entries 512hash-max-ziplist-value 64
3. Redis 持久化
Redis 的持久化机制
Redis 提供两种持久化方式:
- RDB(Redis Database):定时生成内存快照
- AOF(Append Only File):记录所有写操作命令
RDB 和 AOF 的区别与优缺点
| 特性 | RDB | AOF |
|---|---|---|
| 持久化方式 | 二进制快照 | 命令追加日志 |
| 文件大小 | 较小(压缩存储) | 较大(持续增长) |
| 恢复速度 | 快 | 慢(需重放命令) |
| 数据安全性 | 可能丢失最后一次快照后的数据 | 可配置不同刷盘策略保证数据安全 |
| 性能影响 | 保存时影响性能 | 写入性能影响较小 |
| 恢复优先级 | 低 | 高(默认优先使用AOF恢复) |
RDB 触发方式
- 手动触发:
SAVE # 同步保存,阻塞主线程BGSAVE # 后台异步保存(fork子进程)
- 自动触发(redis.conf配置):
save 900 1 # 900秒内至少1个key变化save 300 10 # 300秒内至少10个key变化save 60 10000 # 60秒内至少10000个key变化
AOF 重写机制
-
作用:
- 压缩AOF文件体积(去除冗余命令)
- 重建更优的持久化命令序列
-
触发方式:
- 手动触发:
BGREWRITEAOF - 自动触发(需配置):
- 手动触发:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
- 优化策略:
- 使用AOF重写缓冲区
- 配置合理的重写触发阈值
- 开启AOF-RDB混合模式(4.0+)
生产环境配置建议
-
选择策略:
- 数据安全性要求高:AOF(appendfsync always)
- 快速恢复优先:RDB
- 折中方案:同时开启RDB+AOF
-
推荐配置:
appendonly yes # 开启AOFappendfsync everysec # 折中刷盘策略aof-use-rdb-preamble yes # 开启混合持久化(4.0+)save 900 1 # 保留RDB触发条件
- 注意事项:
- 同时开启时重启优先加载AOF文件
- 混合模式结合两者优势(4.0+版本)
- 监控持久化文件大小和性能影响
二、Redis 高可用与集群
1. 主从复制
Redis 主从复制原理
-
全量同步过程:
- 从节点发送SYNC命令
- 主节点执行BGSAVE生成RDB文件
- 主节点将RDB文件发送给从节点
- 从节点清空数据后加载RDB
- 主节点将缓冲区的写命令发送给从节点
-
增量同步过程:
- 主节点维护复制积压缓冲区(repl_backlog)
- 从节点断线重连后发送PSYNC命令
- 主节点发送缓冲区中缺失的命令
-
关键参数:
repl-backlog-size 1mb # 复制积压缓冲区大小repl-backlog-ttl 3600 # 缓冲区保留时间(秒)
主从复制常见问题
-
数据延迟:
- 原因:网络延迟、主节点写入量过大
- 监控:INFO replication查看slave_repl_offset
-
主从切换问题:
- 故障转移时可能丢失部分数据
- 新主节点选举期间服务不可用
-
其他问题:
- 全量同步导致主节点内存峰值
- 从节点过期key处理不及时
- 网络闪断导致频繁全量同步
主从复制性能优化
- 网络优化:
- 主从节点同机房部署
- 增大复制缓冲区大小:
repl-backlog-size 256mb
-
配置优化:
- 关闭从节点AOF(除非需要)
- 设置合理的主节点保存间隔:
save 300 100
-
其他优化:
- 使用SSD磁盘提高RDB传输速度
- 适当增大TCP缓冲区大小
- 监控复制延迟(redis-cli --latency)
-
特殊场景优化:
- 级联复制减轻主节点压力
- 读写分离时控制从节点数量
2. Redis Sentinel(哨兵)
Redis Sentinel 的作用
-
核心功能:
- 监控:持续检查主从节点运行状态
- 通知:通过API向管理员发送故障报警
- 自动故障转移:主节点故障时提升从节点为新主节点
- 配置中心:客户端自动获取最新主节点地址
-
故障转移流程:
- 检测主节点失效(主观下线→客观下线)
- 选举领头Sentinel
- 领头Sentinel执行故障转移:
- 选择最优从节点
- 将其提升为主节点
- 配置其他从节点复制新主节点
- 通知客户端配置变更
故障检测机制
-
主观下线(SDOWN):
- 单个Sentinel实例检测到主节点无响应
- 判定条件(可配置):
down-after-milliseconds 5000 # 5秒无响应
-
客观下线(ODOWN):
- 多个Sentinel达成共识认为主节点不可用
- 判定条件:
quorum 2 # 需要至少2个Sentinel同意
Sentinel 选举机制
-
选举触发条件:
- 主节点被判定为客观下线
- 需要执行故障转移操作
-
选举规则:
- 基于Raft算法实现
- 每个发现主节点下线的Sentinel都会要求其他Sentinel选举自己为leader
- 先到先得原则(先发送选举请求的优先)
- 获得多数票(>N/2+1)的Sentinel成为leader
-
选举相关配置:
sentinel monitor mymaster 127.0.0.1 6379 2 # 监控的主节点名称、IP、端口、quorum数
sentinel failover-timeout mymaster 180000 # 故障转移超时时间(毫秒) -
选举失败处理:
- 若选举超时(failover-timeout)仍未选出leader
- 等待一段时间后重新发起选举
3. Redis Cluster(集群)
Redis Cluster 数据分片
-
哈希槽分配:
- 整个集群被划分为16384个哈希槽(slot)
- 每个key通过CRC16算法计算后取模:
slot = CRC16(key) % 16384 - 每个节点负责一部分哈希槽范围
-
槽分配示例:
- 节点A:0-5460
- 节点B:5461-10922
- 节点C:10923-16383
-
数据分布特性:
- 支持key哈希标签:
{user1000}.profile和{user1000}.account会被分配到相同slot - 迁移过程中允许部分key访问
- 支持key哈希标签:
节点通信机制
-
Gossip协议:
- 节点间通过PING/PONG消息保持通信
- 每个节点随机选择部分节点进行通信(默认每秒10次)
- 传播的信息包括:
- 节点状态
- 哈希槽分配
- 集群配置epoch
-
通信优化:
cluster-node-timeout 15000 # 节点超时时间(毫秒)
cluster-require-full-coverage yes # 是否需要所有槽被覆盖
集群扩缩容
- 扩容流程:
# 添加新节点
redis-cli --cluster add-node new_host:new_port existing_host:existing_port # 重新分配槽
redis-cli --cluster reshard existing_host:existing_port# 输入要迁移的槽数量# 选择接收这些槽的目标节点ID# 选择从哪些源节点迁移槽
- 缩容流程:
# 迁移待删除节点的槽到其他节点redis-cli --cluster reshard del_node_host:del_node_port# 删除空节点redis-cli --cluster del-node del_node_host:del_node_port node_id
- 自动平衡:
redis-cli --cluster rebalance --use-empty-masters
请求重定向机制
-
MOVED重定向:
- 当客户端访问错误的节点时
- 节点返回:
MOVED 1234 10.0.0.2:6379 - 表示key属于槽1234,应由10.0.0.2:6379处理
- 客户端应更新本地slot缓存
-
ASK重定向:
- 发生在集群迁移过程中
- 返回格式:
ASK 1234 10.0.0.2:6379 - 表示key正在迁移,临时访问目标节点
- 客户端需先发送ASKING命令
-
智能客户端处理:
- 维护slot与节点的映射关系
- 自动处理重定向请求
- 定期更新集群拓扑信息
三、Redis 缓存问题
1. 缓存穿透、缓存雪崩、缓存击穿
缓存穿透
问题定义:大量请求查询不存在的数据,绕过缓存直接访问数据库
解决方案:
-
布隆过滤器(Bloom Filter):
- 前置过滤器拦截不存在key的请求
- 优点:内存占用极小
- 缺点:存在误判率(可配置)
-
空值缓存:
- 对查询结果为null的key也进行缓存
- 设置较短过期时间:
SET key_null "" EX 300
-
其他方案:
- 接口层增加参数校验
- 用户权限校验前置
缓存雪崩
问题定义:大量缓存同时失效,导致请求直接冲击数据库
解决方案:
-
过期时间随机化:
- 基础时间 + 随机偏移量
SET key value EX ${1800 + random(300)}
- 基础时间 + 随机偏移量
-
多级缓存架构:
- 本地缓存(Caffeine) + Redis集群
- 不同层级设置不同过期策略
-
其他方案:
- 热点数据永不过期(后台异步更新)
- 熔断降级机制(Hystrix/Sentinel)
缓存击穿
问题定义:热点key突然失效,大量并发请求直接访问数据库
解决方案:
- 互斥锁(分布式锁):
- 使用SETNX实现锁机制
if (redis.setnx("lock_key", 1, "EX", 10)) {try {// 查询数据库// 更新缓存} finally {redis.del("lock_key")}
}
-
热点数据永不过期:
- 不设置过期时间
- 后台定时任务异步更新
-
其他方案:
- 逻辑过期时间(value中存储过期时间戳)
- 请求合并(将多个并发查询合并为单个查询)
2. 缓存一致性
如何保证缓存与数据库的数据一致性
先更新数据库再删缓存(推荐方案)
-
操作流程:
- 先更新数据库
- 再删除缓存
- 后续读取时重新加载缓存
-
优点:
- 实现简单
- 避免大多数并发问题
-
潜在问题及解决方案:
- 删除缓存失败 → 加入重试机制(消息队列)
- 读请求在删除前加载旧数据 → 设置较短过期时间
延迟双删策略
-
操作流程:
- 先删除缓存
- 再更新数据库
- 延迟一定时间后再次删除缓存
-
典型实现:
// 第一次删除redis.del(key)// 更新数据库db.update(data) // 延迟删除(如500ms后)Thread.sleep(500)redis.del(key)
- 适用场景:
- 对一致性要求高的场景
- 能容忍短暂延迟
其他保障措施
-
版本号机制:
- 在缓存value中加入数据版本号
- 更新时校验版本号
-
异步监听binlog:
- 通过canal监听数据库变更
- 自动更新/删除缓存
缓存更新策略
Cache Aside(旁路缓存)
-
读流程:
- 先查缓存,命中则返回
- 未命中则查DB,并写入缓存
-
写流程:
- 直接更新DB
- 删除对应缓存
Read/Write Through
-
读流程:
缓存作为主要数据源,自动从DB加载 -
写流程:
先写缓存,由缓存系统负责同步写入DB
Write Behind
- 写流程:
先写缓存,异步批量更新DB - 特点:
高性能但可能丢失数据
3. 缓存淘汰策略
Redis内存淘汰策略
-
不淘汰:
noeviction→ 内存满时拒绝写入 -
全局淘汰:
allkeys-lru→ 最近最少使用
allkeys-lfu→ 最不经常使用
allkeys-random→ 随机淘汰 -
有过期时间的key淘汰:
volatile-lru→ 在过期key中LRU
volatile-lfu→ 在过期key中LFU
volatile-ttl→ 淘汰剩余TTL最短的
volatile-random→ 随机淘汰过期key
策略选择建议
-
常规场景:
allkeys-lru(平衡性好) -
热点数据明显:
allkeys-lfu(更精准) -
严格保证数据不过期:
noeviction+ 监控 -
混合使用场景:
volatile-lru+ 合理设置TTL -
配置方式:
maxmemory-policy allkeys-lru
maxmemory 4gb # 设置最大内存
四、Redis 高级特性与优化
1. Redis 事务与 Lua 脚本
Redis 事务(MULTI/EXEC)工作机制
- 基本流程:
- 使用MULTI开始事务
- 将多个命令入队
- 使用EXEC执行所有命令
- 示例:
MULTISET key1 value1INCR key2EXEC
-
ACID特性支持:
- 原子性(A):单条命令原子执行,但事务不保证(某条失败不影响其他命令)
- 一致性(C):总能保证数据一致性
- 隔离性(I):单线程模型天然隔离
- 持久性(D):取决于持久化配置
-
事务特点:
- 不支持回滚(与关系型数据库不同)
- 命令执行期间不会被其他客户端打断
WATCH 命令(乐观锁实现)
- 工作原理:
- 监视一个或多个key
- 如果在EXEC前这些key被修改,则事务失败
- 示例:
WATCH balanceval = GET balanceMULTISET balance val-100EXEC
-
典型应用场景:
- 账户余额修改
- 库存扣减
- 需要CAS(Compare-And-Swap)的场景
-
注意事项:
- 需要配合重试机制使用
- 不适用于高竞争场景(可能导致大量重试)
Lua 脚本优势及原子性保证
-
推荐使用原因:
- 减少网络开销(多个操作合并)
- 避免竞态条件(脚本整体原子执行)
- 复杂操作封装(如分布式锁实现)
- 执行效率高(脚本会被缓存)
-
原子性保证机制:
- Redis单线程执行Lua脚本
- 脚本执行期间不会处理其他命令
- 示例原子操作:
local current = redis.call('GET', KEYS[1])if current == ARGV[1] thenreturn redis.call('SET', KEYS[1], ARGV[2])end
- 最佳实践:
- 控制脚本复杂度(避免长时间阻塞)
- 使用SCRIPT LOAD预加载脚本
- 避免在脚本中使用随机写操作
2. Redis 性能优化
Redis Pipeline 机制
-
基本原理:
- 将多个命令打包一次性发送
- 减少网络往返时间(RTT)
- 服务端按顺序执行并批量返回结果
-
性能提升方式:
- 典型提升5-10倍吞吐量
- 适合批量写入/读取场景
- 示例实现:
Pipeline p = jedis.pipelined();for(int i=0; i<10000; i++){p.set("key"+i, "value"+i);}p.sync();
- 注意事项:
- 单次Pipeline不宜包含过多命令
- 不适用于有命令依赖的场景
- 需要合理设置超时时间
BigKey 问题处理
- 排查方法:
- 使用内置命令:
redis-cli --bigkeysMEMORY USAGE key
- 扫描分析工具:
redis-rdb-tools分析RDB文件
-
优化方案:
- 大Key拆分:
将hash拆分为多个小hash - 数据压缩:
使用Snappy等算法压缩value - 存储优化:
改用更适合的数据结构
- 大Key拆分:
-
预防措施:
- 设置监控告警
- 避免存储超大value(>10KB)
- 定期扫描清理
慢查询分析
- 配置与查看:
- 设置阈值(微秒):slowlog-log-slower-than 10000- 保留条数:slowlog-max-len 128- 查看慢日志:SLOWLOG GET 10
-
常见优化方向:
- 避免O(N)命令操作大数据集
- 优化复杂Lua脚本
- 合理使用索引
-
分析工具:
- redis-faina分析监控日志
- 可视化工具展示慢查询趋势
连接数优化
-
连接池配置:
- 最大连接数:
maxTotal 50 - 最大空闲连接:
maxIdle 10 - 最小空闲连接:
minIdle 5
- 最大连接数:
-
优化建议:
- 合理设置超时时间:
timeout 3000 - 使用连接池复用连接
- 避免短连接操作
- 合理设置超时时间:
-
问题排查:
- 查看当前连接:
CLIENT LIST - 分析连接来源:
INFO clients - 紧急断开连接:
CLIENT KILL
- 查看当前连接:
3. Redis 网络与安全
Redis 通信协议 (RESP)
-
协议特点:
- 二进制安全的文本协议
- 简单易实现
- 支持多种数据类型编码
-
协议格式:
- 简单字符串: “+OK\r\n”
- 错误: “-Error message\r\n”
- 整数: “:1000\r\n”
- 批量字符串: “$6\r\nfoobar\r\n”
- 数组: “*2\r\n$3\r\nfoo\r\n$3\r\nbar\r\n”
-
工作方式:
- 客户端-服务端基于TCP通信
- 默认端口6379
- 支持管道和批量操作
安全认证配置
-
密码认证设置:
redis.conf配置
requirepass your_strong_password客户端认证
AUTH your_strong_password -
防护措施:
- 修改默认端口
- 绑定指定IP:
bind 127.0.0.1 - 禁用危险命令:
rename-command FLUSHALL "" - 启用保护模式:
protected-mode yes
-
网络安全:
- 使用SSL隧道
- 配置防火墙规则
- 启用ACL(Redis 6.0+)
SCAN vs KEYS 命令
-
SCAN命令特点:
- 增量式迭代
- 不阻塞服务器
- 可能返回重复key
- 语法:
SCAN cursor [MATCH pattern] [COUNT count]
-
KEYS命令风险:
- 一次性返回所有匹配key
- 大数据量时会阻塞服务
- 导致性能骤降
-
生产环境建议:
- 永远禁用KEYS *
- 使用SCAN替代大数据量查询
- 监控脚本示例:
local cursor = "0"repeatlocal reply = redis.call("SCAN", cursor, "MATCH", "user:*")cursor = reply[1]-- 处理返回的keysuntil cursor == "0"
五、Redis 应用场景
1. 常见业务场景
分布式锁实现
核心方案:
-
基础实现:
SET lock_key unique_value NX EX 10- NX: 仅当key不存在时设置
- EX: 设置过期时间(秒)
- unique_value: 唯一标识(通常使用UUID)
-
优化版(Lua脚本保证原子性):
if redis.call("SETNX", KEYS[1], ARGV[1]) == 1 thenreturn redis.call("EXPIRE", KEYS[1], ARGV[2])elsereturn 0end
- 注意事项:
- 必须设置过期时间
- 解锁需验证value值
- 考虑锁续期问题
限流方案
INCR计数器方案:
- 固定窗口:
local counter = redis.call("INCR", KEYS[1])if counter == 1 thenredis.call("EXPIRE", KEYS[1], ARGV[1])endreturn counter <= tonumber(ARGV[2])
- 令牌桶算法:
- 使用Hash存储:last_time, tokens
- Lua脚本计算当前可用令牌数
- 补充速率控制
参数示例:
- KEYS[1]: rate_limiter:user1
- ARGV[1]: 时间窗口(如60秒)
- ARGV[2]: 最大请求数(如100)
排行榜实现
ZSet核心操作:
-
更新分数:
ZADD leaderboard 100 "user1" -
获取排名:
ZREVRANGE leaderboard 0 9 WITHSCORES -
用户排名:
ZREVRANK leaderboard "user1"
优化技巧:
- 定期持久化到数据库
- 分片存储超大排行榜
- 使用ZUNIONSTORE合并多个榜单
消息队列方案
List基础方案:
-
生产者:
LPUSH orders "order_data" -
消费者:
BRPOP orders 30
**Stream方案(Redis 5.0+):
-
生产消息:
XADD mystream * field1 value1 field2 value2 -
消费消息:
XREAD BLOCK 0 STREAMS mystream $ -
消费者组:
XGROUP CREATE mystream mygroup $
Session共享
实现方案:
-
存储结构:
SETEX session:sessionid 3600 "user_data" -
Spring集成配置:
spring.session.store-type=redis
server.servlet.session.timeout=3600 -
集群方案:
- 相同TTL配置
- 合理设置序列化方式
秒杀系统实现
库存扣减方案:
- Lua脚本保证原子性:
local stock = tonumber(redis.call("GET", KEYS[1]))if stock > 0 thenredis.call("DECR", KEYS[1])return 1endreturn 0
- 优化措施:
- 库存预热
- 分段锁减少竞争
- 异步扣减+结果通知
参数示例:
- KEYS[1]: seckill:stock:123
- ARGV[1]: 无(可扩展传用户ID)
2. 高级应用
布隆过滤器实现
-
RedisBloom模块:
- 加载模块:
redis-server --loadmodule /path/to/redisbloom.so - 基本命令:
BF.ADD myfilter item1
BF.EXISTS myfilter item1 - 参数配置:
BF.RESERVE myfilter 0.01 100000
- 加载模块:
-
原生实现方案:
- 使用Bitmap+多个哈希函数
- 示例SETBIT操作:
SETBIT bloom:filter hash1(item) 1
SETBIT bloom:filter hash2(item) 1
HyperLogLog统计UV
-
基础命令:
- 添加访问记录:
PFADD uv:20230515 user1 user2 user3 - 获取统计结果:
PFCOUNT uv:20230515 - 合并多日数据:
PFMERGE uv:week uv:day1 uv:day2
- 添加访问记录:
-
精度说明:
- 标准误差0.81%
- 固定使用12KB内存
- 适合大数据量去重
GEO地理位置
-
核心命令:
- 添加位置:
GEOADD locations 116.404 39.915 "user1" - 查询附近的人:
GEORADIUS locations 116.404 39.915 10 km WITHDIST - 计算距离:
GEODIST locations user1 user2 km
- 添加位置:
-
实现原理:
- 基于ZSet存储
- 使用Geohash编码
- 有效距离范围:-180到180经度
BitMap签到功能
-
每日签到:
- 用户签到:
SETBIT sign:user1:202305 15 1 - 查询签到:
GETBIT sign:user1:202305 15 - 统计签到:
BITCOUNT sign:user1:202305
- 用户签到:
-
连续签到计算:
- 获取位图数据:
GET sign:user1:202305 - 客户端解析连续天数
- 支持多维度统计:
BITOP AND result sign:user1:202305 sign:user1:202306
- 获取位图数据:
六、Redis 与其他技术结合
Spring Boot 集成 Redis
- 基础配置:
spring.redis.host=127.0.0.1
spring.redis.port=6379
spring.redis.password=yourpassword
spring.redis.lettuce.pool.max-active=8
- 核心组件:
RedisTemplate: 提供各种数据结构操作StringRedisTemplate: 字符串专用模板LettuceConnectionFactory: 默认连接池(优于Jedis)
- 典型用法:
@Autowired
private RedisTemplate<String, Object> redisTemplate;// 操作示例
redisTemplate.opsForValue().set("key", "value");
redisTemplate.opsForHash().put("user", "id", 1001);
Redis + MySQL 配合方案
- 缓存策略:
- Cache Aside Pattern:
- 读: 先查缓存→未命中查DB→回填缓存
- 写: 更新DB→删除缓存
- 双写一致性方案:
- 延迟双删:
- 删除缓存
- 更新数据库
- 延迟500ms再次删除
- 监听binlog变更(通过canal)
Redis 和本地缓存(Caffeine、Guava Cache)如何选择?
选择依据对比
| 特性 | Redis | Caffeine/Guava Cache |
|---|---|---|
| 数据范围 | 全集群共享 | 仅单机有效 |
| 性能 | 微秒级(网络IO影响) | 纳秒级(内存访问) |
| 容量 | 支持GB/TB级别 | 通常MB级别(受JVM堆限制) |
| 数据结构 | 支持丰富的数据结构 | 简单KV结构 |
| 持久化 | 支持 | 不支持 |
| 适用场景 | 分布式缓存、共享数据 | 高频热点数据、临时数据 |
电商分层缓存实战示例
场景:商品详情页缓存
-
架构设计:
用户请求 → Nginx → 本地缓存(Caffeine)→ Redis集群 → MySQL -
代码实现:
// 初始化多级缓存@Beanpublic Cache<String, Product> productCache() {return Caffeine.newBuilder().maximumSize(10_000) // 本地缓存1万个商品.expireAfterWrite(5, TimeUnit.MINUTES).build();}// 查询逻辑public Product getProduct(Long id) {String key = "product:" + id;// 先查本地缓存Product product = productCache.getIfPresent(key);if (product != null) return product;// 再查Redisproduct = redisTemplate.opsForValue().get(key);if (product == null) {product = productMapper.selectById(id); // 查数据库// 异步回填缓存executor.execute(() -> {redisTemplate.opsForValue().set(key, product, 1, TimeUnit.HOURS);productCache.put(key, product); });} else {productCache.put(key, product); // 回填本地缓存}return product;}
-
优势分析:
- 本地缓存:扛住90%以上的商品查询请求
- Redis层:保证集群各节点的数据一致性
- 数据库:最终数据源,流量削峰达99%
-
关键配置:
- 本地缓存TTL(5分钟)< Redis TTL(1小时)
- 本地缓存最大条目数根据内存调整
- 使用异步线程回填避免阻塞主流程
选型建议
必须使用Redis的场景
- 需要跨服务共享的数据(如库存)
- 需要持久化的关键数据
- 复杂数据结构需求(如排行榜)
优先本地缓存的场景
- 极端性能要求(秒杀系统)
- 不要求强一致性的数据(商品描述)
- 单机高频访问数据(用户基础信息)
七、Redis 底层实现
Redis 的 SDS(Simple Dynamic String)和 C 字符串区别
| 特性 | SDS | C 字符串 |
|---|---|---|
| 长度获取 | O(1) 直接读取len属性 | O(n) 需要遍历计算 |
| 缓冲区安全 | 自动扩容,不会缓冲区溢出 | 容易缓冲区溢出 |
| 二进制安全 | 可以存储任意二进制数据 | 只能存储文本,遇’\0’终止 |
| 内存分配 | 预分配+惰性释放策略 | 每次修改需重新分配 |
| 兼容性 | 末尾保留’\0’兼容C函数 | - |
Redis 字典(Hash 表)实现
-
核心结构:
- 哈希表数组 + 链表解决冲突
- 包含两个哈希表(ht[0]和ht[1])用于rehash
-
渐进式rehash过程:
- 扩容时机:负载因子 > 1 且允许rehash,或负载因子 > 5 强制rehash
- 步骤:
- 分配ht[1]空间(大小为第一个大于等于ht[0].used*2的2^n)
- 维护rehashidx计数器(初始为0)
- 每次CRUD操作时迁移ht[0][rehashidx]的键值对
- 全部迁移完成后用ht[1]替换ht[0]
-
优化特性:
- 单次迁移一个桶(链表)
- 期间查询会同时查两个表
- 定时任务辅助迁移
Redis 跳跃表(Skip List)工作原理
-
结构特点:
- 多层有序链表(默认最大32层)
- 每个节点包含:
- 成员对象(ele)
- 分值(score)
- 后退指针(BW)
- 层数组(level[]包含前进指针和跨度)
-
查找过程:
- 从最高层开始遍历
- 当前节点分值 < 目标分值 → 继续前进
- 当前节点分值 ≥ 目标分值 → 下降一层
- 时间复杂度:O(logN)
-
插入流程:
- 随机确定节点层数(幂次定律)
- 逐层更新前后节点指针
- 更新跨度信息
Redis 过期键删除策略
-
惰性删除:
- 触发时机:访问键时检查过期时间
- 优点:CPU友好
- 缺点:内存不及时释放
-
定期删除:
- 工作流程:
- 随机抽取20个键检查
- 删除其中已过期的键
- 如果超过25%键过期则重复过程
- 配置参数:
hz 10 # 每秒执行次数
- 工作流程:
-
内存淘汰触发删除:
- 当内存不足时,按策略淘汰键
- 相关配置:
maxmemory-policy volatile-lru
相关文章:

Redis常见面试问题汇总
Redis 面试笔记整理 一、Redis 基础知识1. Redis 概述Redis 是什么?主要特点有哪些?Redis 和 Memcached 的区别是什么?Redis 是单线程还是多线程?为什么单线程还能高效?Redis 6.0 之后的多线程模型是怎样的?…...

【redis】集群 如何搭建集群详解
文章目录 集群搭建1. 创建目录和配置2. 编写 docker-compose.yml完整配置文件 3. 启动容器4. 构建集群超时 集群搭建 基于 docker 在我们云服务器上搭建出一个 redis 集群出来 当前节点,主要是因为我们只有一个云服务器,搞分布式系统,就比较…...
——flash attention原理)
NLP高频面试题(二十)——flash attention原理
FlashAttention是一种针对Transformer模型中自注意力机制的优化算法,旨在提高计算效率并降低内存占用,特别适用于处理长序列任务。 在Transformer架构中,自注意力机制的计算复杂度和内存需求随着序列长度的平方增长。这意味着当处理较长序列时…...
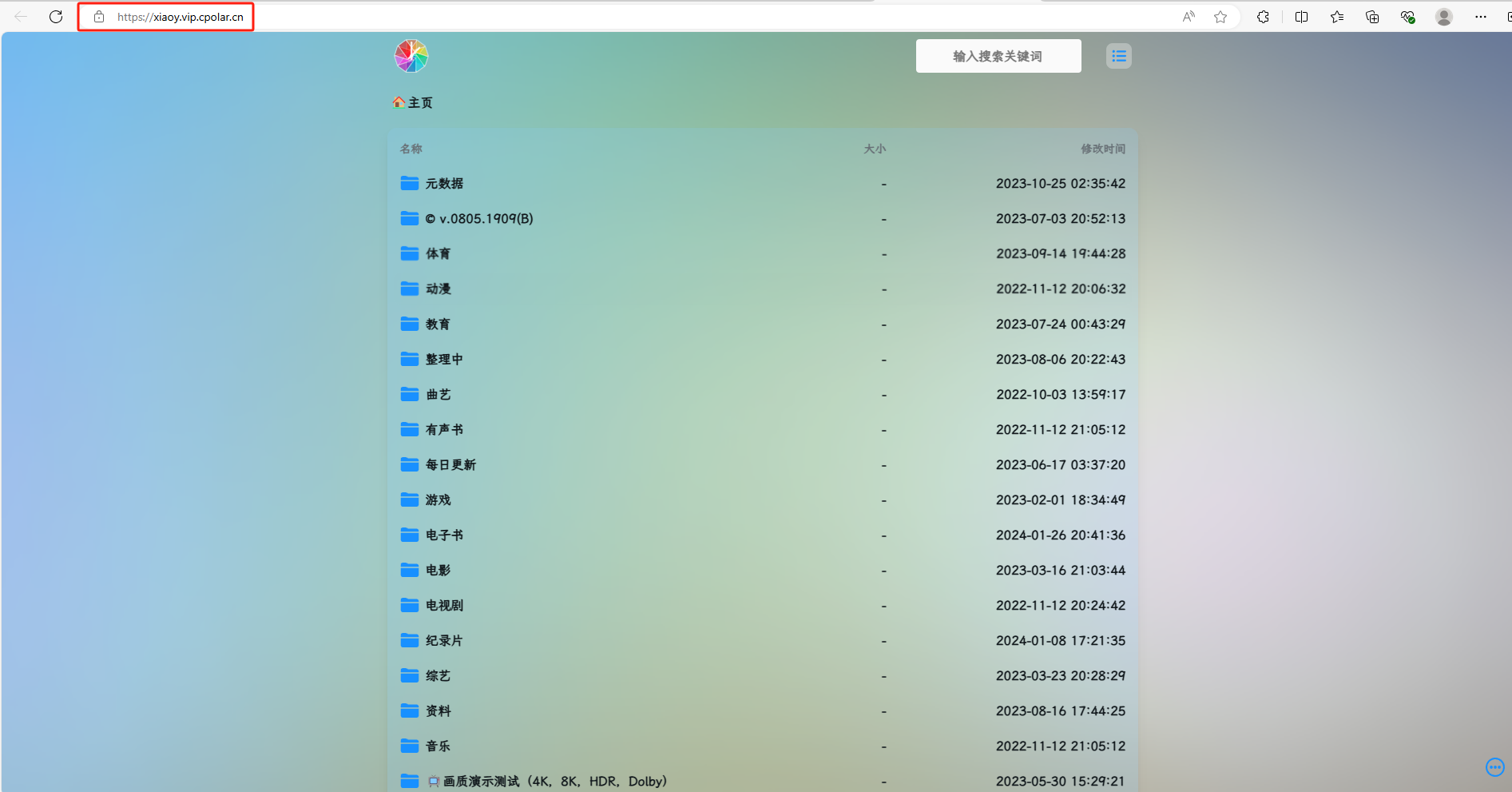
飞牛NAS本地部署小雅Alist结合内网穿透实现跨地域远程在线访问观影
文章目录 前言1. VMware安装飞牛云(fnOS)1.1 打开VMware创建虚拟机1.3 初始化系统 2. 飞牛云搭建小雅Alist3. 公网远程访问小雅Alist3.1 安装Cpolar内网穿透3.2 创建远程连接公网地址 4. 固定Alist小雅公网地址 前言 嘿,小伙伴们,…...

Episode, time step, batch, epoch
1. Episode(回合) 回合(episode)表示智能体从开始执行任务到完成任务(例如成功到达目标或触发失败条件)的全过程。 例如,如果我们训练一个四足机器人走到一个目标点,一个回合就是从…...

Linux版本控制器Git【Ubuntu系统】
文章目录 **前言**一、版本控制器二、Git 简史三、安装 Git四、 在 Gitee/Github 创建项目五、三板斧1、git add 命令2、git commit 命令3、git push 命令 六、其他1、git pull 命令2、git log 命令3、git reflog 命令4、git stash 命令 七、.ignore 文件1、为什么使用 .gitign…...

browser-use 库网页元素点击测试工具
目录 代码代码解释输出结果 代码 import asyncio import jsonfrom browser_use.browser.browser import Browser, BrowserConfig from browser_use.dom.views import DOMBaseNode, DOMElementNode, DOMTextNode from browser_use.utils import time_execution_syncclass Eleme…...

Vue 中使用 ECharts
在 Vue 中使用 ECharts 主要分为以下步骤,结合代码示例详细说明: 1. 安装 ECharts 通过 npm 或 yarn 安装 ECharts: npm install echarts --save # 或 yarn add echarts2. 基础使用(完整引入) 在 Vue 组件中使用 &…...

Spring AI + DeepSeek 构建大模型应用 Demo
Spring AI + DeepSeek 构建大模型应用 Demo 下面我将展示如何使用 Spring AI 框架结合 DeepSeek 的大模型能力构建一个简单的 AI 应用。 1. 环境准备 首先确保你已安装: JDK 17+Maven 3.6+Spring Boot 3.2+2. 创建 Spring Boot 项目 使用 Spring Initializr 创建项目,添加…...

解决GitLab无法拉取项目
1、验证 SSH 密钥是否已生成 ls ~/.ssh/ 如果看到类似 id_rsa 和 id_rsa.pub 的文件,则说明已存在 SSH 密钥。 避免麻烦,铲掉重来最方便。 如果没有,请生成新的 SSH 密钥: ssh-keygen -t rsa -b 4096 -C "your_emailexam…...

POSIX 线程取消与资源清理完全指南
POSIX 线程取消与资源清理完全指南 引言:为什么需要线程取消机制? 在多线程编程中,优雅地终止线程并确保资源释放是开发者面临的重要挑战。直接终止线程可能导致内存泄漏、文件未关闭等问题。POSIX 线程库提供了一套完整的线程取消和清理机…...

FPGA学习篇——Verilog学习之寄存器的实现
1 寄存器理论 这里在常见的寄存器种加了一个复位信号sys_rst_n。(_n后缀表示复位信号低电平有效,无这个后缀的则表示高电平有效) 这里规定在时钟的上升沿有效,只有当时钟的上升沿来临时,输出out 才会改变,…...

Cursor异常问题全解析-无限使用
title: Cursor异常问题全解析无限使用 tags: cursor categories:aiai编程 mathjax: true description: Cursor异常问题全解析与解决方案大全 abbrlink: 64908bd0 date: 2025-03-19 14:48:32 🤖 Assistant 🚨 Cursor异常问题全解析与解决方案大全 &…...

【VUE】ant design vue实现表格table上下拖拽排序
适合版本:ant design vue 1.7.8 实现效果: 代码: <template><div class"table-container"><a-table:columns"columns":dataSource"tableData":rowKey"record > record.id":row…...

Vue实现动态数据透视表(交叉表)
需求:需要根据前端选择的横维度、竖维度、值去生成一个动态的表格,然后把交叉的值放入到对应的横维度和竖维度之下,其实就是excel里面的数据透视表功能,查询交叉语句为sql语句。 实现页面: 选择一下横维度、竖维度、值之后点击查…...

推荐《人工智能算法》卷1、卷2和卷3 合集3本书(附pdf电子书下载)
今天,咱们就一同深入探讨人工智能算法的卷1、卷2和卷3,看看它们各自蕴含着怎样的奥秘,并且附上各自的pdf电子版免费下载地址。 《人工智能算法(卷1):基础算法》 下载地址:https://www.panziye…...

元宇宙浪潮下,数字孪生如何“乘风破浪”?
在当今科技飞速发展的时代,元宇宙的概念如同一颗璀璨的新星,吸引了全球的目光。元宇宙被描绘为一个平行于现实世界、又与现实世界相互影响且始终在线的虚拟空间,它整合了多种前沿技术,为人们带来沉浸式的交互体验。而数字孪生&…...

WPF 附加属性
在WPF(Windows Presentation Foundation)中,附加属性(Attached Properties)是一种特殊的依赖属性机制,它允许父元素为子元素提供额外的属性支持。这种特性特别适用于布局系统、输入处理和其他需要跨多个控件…...

数据分析 之 怎么看懂图 一
韦恩图怎么看 ①颜色:不同颜色代表不同的集合 ②)颜色重叠部分:表示相交集合共有的元素 ③颜色不重叠的部分:表示改集合独有的元素 ④数字:表示集合独有或共有的元素数量 ⑤百分比:表示该区域元素数占整体的比例 PCA图怎么看 ① 第一主成分坐标轴及主成分贡献率主成分贡献…...

手写数据库MYDB(一):项目启动效果展示和环境配置问题说明
1.项目概况 这个项目实际上就是一个轮子项目,现在我看到的这个市面上面比较火的就是这个首先RPC,好多的机构都在搞这个,还有这个消息队列之类的,但是这个是基于MYSQL的,我们知道这个MYSQL在八股盛宴里面是重点考察对象…...
深入理解椭圆曲线密码学(ECC)与区块链加密
椭圆曲线密码学(ECC)在现代加密技术中扮演着至关重要的角色,广泛应用于区块链、数字货币、数字签名等领域。由于其在提供高安全性和高效率上的优势,椭圆曲线密码学成为了数字加密的核心技术之一。本文将详细介绍椭圆曲线的基本原理…...

使用 PowerShell 脚本 + FFmpeg 在 Windows 系统中批量计算 MP4视频 文件的总时长
步骤 1:安装 FFmpeg 访问 FFmpeg 官网(Download FFmpeg),下载 Windows 版编译包(如 ffmpeg-release-full.7z)。或者到(https://download.csdn.net/download/zjx2388/90539014)下载完整资料 解压文件&#…...

中医气血精津辨证
中医气血精津辨证 一、气血精津辨证概述 基本概念: 气血精津是构成人体和维持生命活动的基本物质,其生成、运行、输布与脏腑功能密切相关。辨证核心:通过分析气血精津的盛衰、运行障碍及其相互关系,判断疾病本质。 生理关系&…...

Intellij IDEA2023 创建java web项目
Intellij IDEA2023 创建java web项目 零基础搭建web项目1、创建java项目2、创建web项目3、创建测试页面4、配置tomcat5、遇到的问题 零基础搭建web项目 小白一枚,零基础学习基于springMVC的web项目开发,记录开发过程以及中间遇到的问题。已经安装了Inte…...

Scrapy结合Selenium实现滚动翻页数据采集
引言 在当今的互联网数据采集领域,许多网站采用动态加载技术(如AJAX、无限滚动)来优化用户体验。传统的基于Requests或Scrapy的爬虫难以直接获取动态渲染的数据,而Selenium可以模拟浏览器行为,实现滚动翻页和动态内容…...

Node.js从0.5到1学习计划
以下是针对零基础学习者的10天Node.js高效学习计划,每天聚焦核心知识点并配合实战练习: 📆 10天Node.js速成计划(每日4-6小时) 核心目标:掌握Node.js核心机制 完成3个实战项目 📍 Day 1-2&…...

python 的 obj的key 变成双引号
在Python中,当你序列化一个对象(例如使用json.dumps()方法将对象转换为JSON字符串)时,默认情况下,字典的键(keys)会被转换为字符串。如果你的字典中的键本身就是字符串,并且你想要在…...

sqlmap 源码阅读与流程分析
0x01 前言 还是代码功底太差,所以想尝试阅读 sqlmap 源码一下,并且自己用 golang 重构,到后面会进行 ysoserial 的改写;以及 xray 的重构,当然那个应该会很多参考 cel-go 项目 0x02 环境准备 sqlmap 的项目地址&…...

DeepSeek 助力 Vue3 开发:打造丝滑的表格(Table)之添加行拖拽排序功能示例6,TableView16_06 分页表格拖拽排序
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...

asp.net mvc 向前端响应json数据。用到jquery
最近在给客户开发提醒软件时,用asp.net mvc 开发。该框架已经集成了bootstrap,直接贴asp.net mvc 端代码: {Layout null; }<!DOCTYPE html><html> <head><meta name"viewport" content"widthdevice-width" /…...