【机器学习基础 4】 Pandas库
一、Pandas库简介
Pandas 是一个开源的 Python 数据分析库,主要用于数据清洗、处理、探索与分析。其核心数据结构是 Series(一维数据)和 DataFrame(二维表格数据),可以让我们高效地操作结构化数据。Pandas 提供了许多灵活且高效的数据操作方法,能够快速地进行数据筛选、聚合、转换和可视化,是数据科学和机器学习工作流中非常重要的一环。
二、Pandas库安装
通常直接通过 pip 来安装;当然,在Anaconda虚拟环境中亦可用如下两种方式:
pip install pandasconda install pandas在编写中导入Pandas库,我们通常会习惯将其简化为pd:
import pandas as pd
三、常用的Pandas函数
1、数据读取
Pandas库支持多种数据格式的导入,例如 CSV、Excel、SQL 数据库、JSON 等,方便我们从各种数据源中获取数据。假设我们有一个CSV文件,内部如下:
ID,Name,Age,Score
1,Tom,22,85.0
2,Lily,21,92.0
3,Jack,23,78.0
4,Lucy,22,89.0
5,Rose,21,95.0
我们想要读取,则可以:
import pandas as pd# 读取 CSV 文件
df = pd.read_csv('sample.csv')
print(df.head()) # 查看前 5 行
样例输出:
ID Name Age Score
0 1 Tom 22 85.0
1 2 Lily 21 92.0
2 3 Jack 23 78.0
3 4 Lucy 22 89.0
4 5 Rose 21 95.0
2、查看数据
如果我们想快速检查数据的基本信息,如行数、列数、数据类型,则可以前面的基础上加上:
print(df.info()) # 查看数据的基本信息
print(df.describe()) # 生成数据的统计摘要
样例输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 4 columns):# Column Non-Null Count Dtype
--- ------ -------------- -----0 ID 5 non-null int641 Name 5 non-null object2 Age 5 non-null int643 Score 5 non-null float64
dtypes: float64(1), int64(2), object(1)
memory usage: 288.0+ bytes
NoneID Age Score
count 5.000000 5.00000 5.000000
mean 3.000000 21.80000 87.800000
std 1.581139 0.83666 6.610598
min 1.000000 21.00000 78.000000
25% 2.000000 21.00000 85.000000
50% 3.000000 22.00000 89.000000
75% 4.000000 22.00000 92.000000
max 5.000000 23.00000 95.0000003、数据选择与过滤
当然,我们还可以对数据进行选择和过滤,就像下面这样:
# 选择某一列
print(df['Name'],'\n') # 选择多列
print(df[['Name', 'Score']],'\n') # 选择特定行(iloc 按索引,loc 按标签)
print(df.iloc[1])
print(df.loc[df['Score'] > 90]) # 筛选成绩大于 90 的行
样例输出:
0 Tom
1 Lily
2 Jack
3 Lucy
4 Rose
Name: Name, dtype: object Name Score
0 Tom 85.0
1 Lily 92.0
2 Jack 78.0
3 Lucy 89.0
4 Rose 95.0 ID 2
Name Lily
Age 21
Score 92.0
Name: 1, dtype: objectID Name Age Score
1 2 Lily 21 92.0
4 5 Rose 21 95.04、数据清洗
Pandas库还可以处理缺失值(用dropna、fillna)、重复值(用drop_duplicates)、替换值(用replace)等。
例如:(我们先把CSV中Rose的score删掉)
# 删除缺失值
df_cleaned = df.dropna()
print("删除缺失值后的DataFrame:")
print(df_cleaned.head())# 填充缺失值
df_filled = df.fillna(value={'Score': df['Score'].mean()})
print("\n填充缺失值后的DataFrame:")
print(df_filled.head())# 删除重复值
df_unique = df.drop_duplicates()
print("\n删除重复值后的DataFrame:")
print(df_unique.head())# 替换值
df_replaced = df.replace({'Tom': 'Tommy'})
print("\n替换值后的DataFrame:")
print(df_replaced.head())
样例输出:
删除缺失值后的DataFrame:ID Name Age Score
0 1 Tom 22 85.0
1 2 Lily 21 92.0
2 3 Jack 23 78.0
3 4 Lucy 22 89.0 填充缺失值后的DataFrame:ID Name Age Score
0 1 Tom 22 85.0
1 2 Lily 21 92.0
2 3 Jack 23 78.0
3 4 Lucy 22 89.0
4 5 Rose 21 86.0 删除重复值后的DataFrame:ID Name Age Score
0 1 Tom 22 85.0
1 2 Lily 21 92.0
2 3 Jack 23 78.0
3 4 Lucy 22 89.0
4 5 Rose 21 NaN替换值后的DataFrame:ID Name Age Score
0 1 Tommy 22 85.0
1 2 Lily 21 92.0
2 3 Jack 23 78.0
3 4 Lucy 22 89.0
4 5 Rose 21 NaN5、数据的排序、分组求均值、合并、连接
排序会使用到sort_values函数,分组则使用groupby,合并使用merge,连接使用concat
例如:
# 按 'Score' 排序
df_sorted = df.sort_values(by='Score', ascending=False)
print("按 'Score' 排序后的数据:\n", df_sorted)# 分组并求均值
df_grouped = df.groupby('Age')['Score'].mean()
print("按 'Age' 分组并求 'Score' 的均值:\n", df_grouped)# 合并数据
df1 = pd.DataFrame({'ID': [1, 2, 3], 'Class': ['A', 'B', 'A']})
df_merged = df.merge(df1, on='ID', how='left')
print("合并后的数据:\n", df_merged)# 连接多个 DataFrame
df_concat = pd.concat([df, df1], axis=0)
print("连接后的数据:\n", df_concat) 注意:DataFrame 是Pandas库中的一个函数,用于创建一个数据框(DataFrame)。
{'ID': [1, 2, 3], 'Class': ['A', 'B', 'A']} 是一个字典,其中键是列名,值是对应的数据。
'ID' 是列名,对应的数据是 [1, 2, 3];'Class' 是列名,对应的数据是 ['A', 'B', 'A']。
df1 是一个新创建的数据框,包含两列:ID和Class
merge是Pandas中用于合并两个数据框的函数。
df1 是要与当前数据框 df 合并的另一个数据框。
on='ID' 指定了合并的键(key),即根据两表中的 ID列进行合并。
how='left' 指定了合并的方式为左连接(left join)。这意味着结果将包含左表(即 df)中的所有行,即使右表(即 df1)中没有匹配的行。如果右表中没有匹配的行,结果中对应的列将填充为NaN。
样例输出:
按 'Score' 排序后的数据:ID Name Age Score
4 5 Rose 21 95.0
1 2 Lily 21 92.0
3 4 Lucy 22 89.0
0 1 Tom 22 85.0
2 3 Jack 23 78.0
按 'Age' 分组并求 'Score' 的均值:Age
21 93.5
22 87.0
23 78.0
Name: Score, dtype: float64
合并后的数据:ID Name Age Score Class
0 1 Tom 22 85.0 A
1 2 Lily 21 92.0 B
2 3 Jack 23 78.0 A
3 4 Lucy 22 89.0 NaN
4 5 Rose 21 95.0 NaN
连接后的数据:ID Name Age Score Class
0 1 Tom 22.0 85.0 NaN
1 2 Lily 21.0 92.0 NaN
2 3 Jack 23.0 78.0 NaN
3 4 Lucy 22.0 89.0 NaN
4 5 Rose 21.0 95.0 NaN
0 1 NaN NaN NaN A
1 2 NaN NaN NaN B
2 3 NaN NaN NaN A6、数据转换
例如:
# 创建数据透视表
pivot_table = df.pivot_table(values='Score', index='Age', aggfunc='mean')
print("透视表:\n", pivot_table)# 使用 apply() 转换数据
df['Score_Squared'] = df['Score'].apply(lambda x: x ** 2)
print("转换后的数据:\n", df)# 更改数据类型
df['Age'] = df['Age'].astype(float)
print("更改数据类型后的数据:\n", df)样例输出:
透视表:Score
Age
21 93.5
22 87.0
23 78.0
转换后的数据:ID Name Age Score Score_Squared
0 1 Tom 22 85.0 7225.0
1 2 Lily 21 92.0 8464.0
2 3 Jack 23 78.0 6084.0
3 4 Lucy 22 89.0 7921.0
4 5 Rose 21 95.0 9025.0
更改数据类型后的数据:ID Name Age Score Score_Squared
0 1 Tom 22.0 85.0 7225.0
1 2 Lily 21.0 92.0 8464.0
2 3 Jack 23.0 78.0 6084.0
3 4 Lucy 22.0 89.0 7921.0
4 5 Rose 21.0 95.0 9025.07、日期与时间处理
例如:
# 创建日期列
df['Date'] = pd.to_datetime(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05'])# 提取年份、月份、星期
df['Year'] = df['Date'].dt.year
df['Month'] = df['Date'].dt.month
df['Weekday'] = df['Date'].dt.day_name()print(df)样例输出:
ID Name Age Score Date Year Month Weekday
0 1 Tom 22 85.0 2023-01-01 2023 1 Sunday
1 2 Lily 21 92.0 2023-01-02 2023 1 Monday
2 3 Jack 23 78.0 2023-01-03 2023 1 Tuesday
3 4 Lucy 22 89.0 2023-01-04 2023 1 Wednesday
4 5 Rose 21 95.0 2023-01-05 2023 1 Thursday相关文章:

【机器学习基础 4】 Pandas库
一、Pandas库简介 Pandas 是一个开源的 Python 数据分析库,主要用于数据清洗、处理、探索与分析。其核心数据结构是 Series(一维数据)和 DataFrame(二维表格数据),可以让我们高效地操作结构化数据。Pandas …...

如何在根据名称或id找到json里的节点以及对应的所有的父节点?
函数如下: 数据如下: [{ "name": "数据看板", "id": "data", "pageName": "tableeauData", "list": [] }, { "name": "审计模块", "id": &quo…...

JS—异步编程:3分钟掌握异步编程
个人博客:haichenyi.com。感谢关注 一. 目录 一–目录二–引言三–JavaScript 事件循环机制四–定时器的秘密:setTimeout 和 setInterval五–异步编程模型对比 二. 引言 在现代Web开发中,异步编程是提升性能的关键技术。无论是脚本加载&am…...

mxgraph编辑器的使用
前端JS如何使用mxgraph编辑器 说明:此项目是JS项目,目前还不支持TS 引入资源 可以直接从官网上拿下来,或者从其他地方获取 官网编辑器 如果只是展示图形的话只引入 mxClient.js就可以了 一个免费在线编辑器 自己用它做了一个在线编辑器&#…...

electron打包vue2项目流程
1,安装一个node vue2 的项目 2,安装electron: npm install electron -g//如果安装还是 特比慢 或 不想安装cnpn 淘宝镜像查看是否安装成功:electron -v 3,进入到项目目录:cd electron-demo 进入项目目录…...

STM32F103_LL库+寄存器学习笔记11 - 串口收发的中断优先级梳理
导言 推荐的STM32 USARTDMA 中断优先级设置(完整方案): 以你的STM32F103 USART1 DMA实例为例: 推荐中断优先级设置中断优先级USART1空闲中断(接收相关)优先级0DMA1通道5接收中断(半满/满传输…...
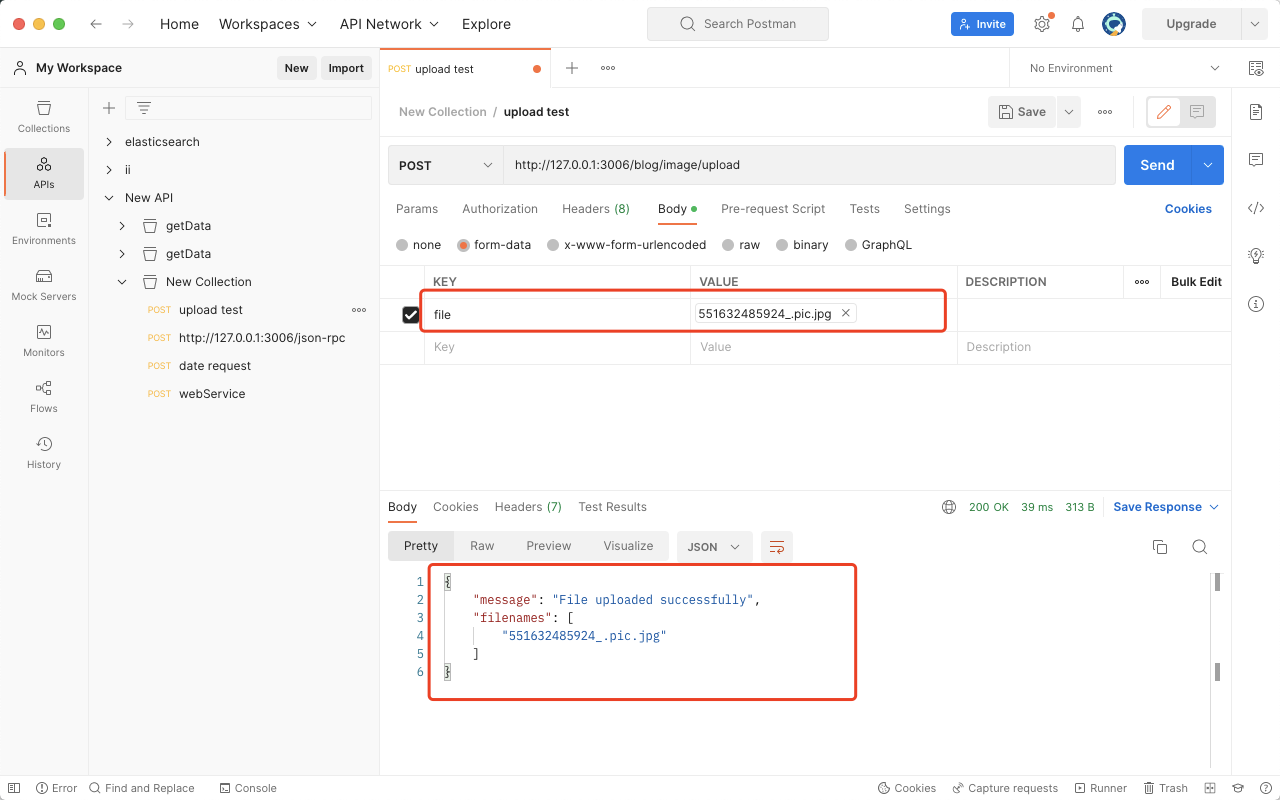
Postman 如何发送 Post 请求上传文件? 全面指南
写一个后端接口,肯定离不开后续的调试,所以我使用了 Postman 来进行上传图片接口的调试,调试步骤也很简单: 第一步:填写请求 URL第二步:选择请求类型第三步:选择发送文件第四步:点击…...

Mathtype无法插入到Word中
在word工具栏上有没有出现Mtahtype,会出现以下两种情况: 1. 没有出现Mtahtype 2. 出现Mtahtype,但是点击会出现弹窗 “ Couldnt find the MathPage.wll ” 解决方案 首先查看word版本是32位还是64位,这个位数是office安装位数…...

快速了解ES6Module模块化
ES6 Module 模块,是能够单独命名并独立完成一定功能程序语句的集合 定义听上去高大上,其实在日常项目中几乎每个文件都会用到,甚至很不起眼, react组件的引用: // router.js import { createHashRouter } from react…...

Spring Boot 三层架构【清晰易懂】
Spring Boot 的三层架构是一种常见的软件设计模式,它将应用程序分为三个主要部分:控制器层(Controller)、服务层(Service) 和 数据访问层(Repository)。这种分层架构有助于代码的模块…...
课程笔记)
并查集(Union-Find Set)课程笔记
目录 1. 并查集原理 2. 并查集的实现 3. 并查集应用 应用 1:省份数量问题 应用 2:等式方程的可满足性 1. 并查集原理 并查集用于处理需要将不同元素划分成若干不相交集合的问题。最开始时,每个元素都是单独的一个集合,随后根…...

Agent AI综述
Agent AI综述 研究背景:早期AI研究目标分散,如今大语言模型(LLMs)和视觉语言模型(VLMs)的发展带来新契机,促使AI向能在复杂环境中担当动态角色的方向转变。Agent AI正是在这种背景下应运而生,融合语言、视觉等多种能力,有望重塑人类体验和产业标准。 Agent AI的融合:…...

Linux 练习二 LVS的NAT模式
作业 要求:使用LVS的 NAT 模式实现 3 台 RS 的轮询访问。IP地址和主机自己规划。 节点规划 主机角色系统网络IPclientclientredhat 9.5仅主机192.168.60.100/24lvslvsredhat 9.5仅主机 NAT192.168.60.200/24 VIP 192.168.23.8/24 DIPnginxrs1redhat 9.5NAT192.16…...

MongoDB 与 Elasticsearch 使用场景区别及示例
一、核心定位差异 MongoDB 定位:通用型文档数据库,侧重数据的存储、事务管理及结构化查询,支持 ACID 事务。典型场景: 动态数据结构存储(如用户信息、商品详情)。需事务支持的场景…...

WPF ContentPresenter详解2
ContentPresenter与ContentControl的区别 ContentControl 和 ContentPresenter 是 WPF 中两个相关的控件,但它们在用途和功能上有一些关键的区别。理解这两者的区别和联系有助于更好地设计和开发用户界面。 1. 类层次结构 ContentControl:位于 WPF 控件…...

Ubuntu20.0.4创建ssh key以及repo命令的使用
创建ssh key ssh-keygen //一路回车,不用输入任何东西cat ~/.ssh/id_rsa.pub 配置git config git config --global user.name xxx // 设置git用户名git config --global user.email xxx.com.cn //设置git 邮箱git config --list// remove the git config// rm -fr …...

CSS——变换、过度与动画
巧妙的使用变换、过度与动画可以让页面设计更有趣、更吸引人,同时还能提高可用性和感知性能。 文章目录 一,变换(一)2D变换1,定义旋转2,定义缩放3,定义移动4,定义倾斜5,定…...

鸿蒙OS 5.0 服务能力框架深入剖析
鸿蒙OS 5.0 服务能力框架中关键类的作用分析 1\. 鸿蒙OS 5.0 服务能力框架导论 鸿蒙OS 5.0,亦称鸿蒙智联 5 1,标志着华为在分布式操作系统领域迈出的重要一步。与早期版本采用兼容安卓的AOSP层、Linux内核以及LiteOS内核不同,鸿蒙OS 5.0 专注…...

【PCB工艺】时序图(Timing Diagram)
时序图(Timing Diagram)是描述数字电路信号随时间变化的图示,广泛用于分析和设计时序逻辑电路,如锁存器(Latch)、触发器(Flip-Flop)、计数器、状态机等。这篇文章从时序图的原理、构…...

第四届能源、电力与电气国际学术会议(ICEPET 2025)
重要信息 地点:中国-成都 官网:www.icepet.net(了解参会投稿等信息) 时间:2025年4月25-27日 简介 第四届能源、电力与电气会(ICEPET 2025定于2025年4月25-27日在中国成都举办。 本次将围绕能源、电力及…...

el-table + el-pagination 前端实现分页操作
el-table el-pagination 前端实现分页操作 后端返回全部列表数据,前端进行分页操作 html代码 <div><el-table :data"tableData" border><el-table-column label"序号" type"index" width"50" /><el…...

Redis数据持久化机制 + Go语言读写Redis各种类型值
Redis(Remote Dictionary Server)作为高性能的键值存储系统,凭借其丰富的数据类型和原子性操作,成为现代分布式系统中不可或缺的组件。 1、Redis支持的数据类型 Redis支持的数据类型可归纳为以下9类: String&#x…...

【机器学习】什么是逻辑回归?
什么是逻辑回归? 逻辑回归(Logistic Regression)是一个用于分类问题的统计学模型,尽管名字里有“回归”二字,它其实是用来做分类的,不是做数值预测的。 通俗易懂的理解 我们可以通过一个简单的例子来理解…...

Unity程序嵌入Qt后点击UI按钮Button没有反应
一、前言 在一次项目中,需要将Unity程序嵌入qt中,并在主界面显示,根据网络资料与相关代码,成功将unity程序嵌入,但是在点击Unity的Button按钮时却没有响应,在查找相关资料后,解决问题ÿ…...

【Bug】记录2025年遇到的Bug以及修复方案
--------------------------------------------------------分割线 2025.3.25-------------------------------------------------------windows环境下通过命令行终端(必须是命令行下,直接赋值传递,代码正常)的形式传递字符串时&a…...

2025最新“科研创新与智能化转型“暨AI智能体开发与大语言模型的本地化部署、优化技术实践
第一章、智能体(Agent)入门 1、智能体(Agent)概述(什么是智能体?智能体的类型和应用场景、典型的智能体应用,如:Google Data Science Agent等) 2、智能体(Agent)与大语…...

VUE3+TypeScript项目,使用html2Canvas+jspdf生成PDF并实现--分页--页眉--页尾
使用html2CanvasJsPDF生成pdf,并实现分页添加页眉页尾 1.封装方法htmlToPdfPage.ts /**path: src/utils/htmlToPdfPage.tsname: 导出页面为PDF格式 并添加页眉页尾 **/ /*** 封装思路* 1.将页面根据A4大小分隔边距,避免内容被中间截断* 所有元素层级不要…...

【NLP 46、大模型技术发展】
目录 一、ELMo 2018 训练目标 二、GPT-1 2018 训练目标 三、BERT 2018 训练目标 四、Ernie —— baidu 2019 五、Ernie —— Tsinghua 2019 六、GPT-2 2019 七、UNILM 2019 八、Transformer - XL & XLNet 2019 1.模型结构 Ⅰ、循环机制 Recurrence Mechanism Ⅱ、相对位置…...

在 Ubuntu 上安装 Docker 的完整指南
1. 卸载旧版本(如有) 在安装新版本前,建议先卸载旧版本: sudo apt remove docker docker-engine docker.io containerd runc 2. 安装依赖包 更新软件包索引并安装必要的依赖: sudo apt update sudo apt install -y ca-certificates curl gnupg lsb-release 3. 添加 Do…...

可以把后端的api理解为一个目录地址,但并不准确
将后端的 API 理解为一个“目录地址”是可以的,但并不完全准确。让我们更详细地解释一下。 目录 1、生动形象了解api 2、后端 API 的作用 3、可以将 API 理解为“目录地址”的原因 (1)URL 路径 (2)层次结构 4、…...