【实战ES】实战 Elasticsearch:快速上手与深度实践-2.2.1 Bulk API的正确使用与错误处理
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- Elasticsearch Bulk API 深度实践:性能调优与容错设计
- 1. `Bulk API` 核心机制解析
- 1.1 批量写入原理剖析
- 1.1.1 各阶段性能瓶颈
- 2. 高性能批量写入实践
- 2.1 客户端最佳配置
- 2.1.1 主流客户端对比
- 2.1.2 Python 优化示例
- 2.2 服务端关键参数
- 3. 错误处理与容错设计
- 3.1 错误分类与处理策略
- 3.2 重试机制实现方案
- 3.2.1 重试参数计算公式
- 4. 性能优化案例
- 4.1 日志采集系统调优
- 4.1.1 原始性能
- 4.1.2 优化措施
- 4.1.3 优化结果
- 4.2 电商订单数据同步
- 4.2.1 挑战
- 4.2.2 解决方案
- 4.2.3 效果验证
- 5. 监控与问题诊断
- 5.1 关键监控指标
- 5.2 性能问题排查流程
- 6. 进阶优化策略
- 6.1 硬件级优化
- 6.2 数据建模优化
Elasticsearch Bulk API 深度实践:性能调优与容错设计
- Elasticsearch Bulk API 是 Elasticsearch 提供的一种
批量操作 API,允许在单个请求中执行多个索引、更新或删除操作。 - 使用 Bulk API
可以显著提高数据导入和处理的效率,因为它减少了与 Elasticsearch 集群之间的网络往返次数,从而减少了网络开销,提高了整体性能。
1. Bulk API 核心机制解析
1.1 批量写入原理剖析
Elasticsearch 批量写入吞吐量主要受以下因素影响:

1.1.1 各阶段性能瓶颈
| 阶段 | 典型耗时占比 | 关键影响因素 | 优化杠杆点 |
|---|---|---|---|
| 客户端构建 | 10%-15% | 序列化效率/数据格式 | NDJSON 流式构建 |
| 网络传输 | 20%-30% | 压缩算法/批量大小 | Gzip压缩/5-15MB 包体 |
| 节点处理 | 40%-50% | 线程池配置/索引刷新间隔 | 调整 bulk 线程池队列 |
| 分片写入 | 15%-25% | 分片数/副本策略 | 动态分片策略 |
-
基准测试数据:单节点 16C32G SSD 磁盘,10KB/doc,不同批量大小的吞吐量对比:
批量大小 QPS网络耗时占比 CPU利用率 100 8,200 38% 65% 500 14,500 24% 82% 1000 18,300 18% 91% 5000 21,000 12% 95%
2. 高性能批量写入实践
2.1 客户端最佳配置
2.1.1 主流客户端对比
| 客户端 | 并发模型 | 内存管理 | 推荐场景 |
|---|---|---|---|
RestHighLevel | 同步阻塞 | 全量缓冲 | 小规模数据 |
Jest | 异步回调 | 部分缓冲 | 中等吞吐 |
| Elastic-py | 协程异步 | 流式处理 | 高吞吐低延迟 |
| Go-elastic | Goroutine | 零拷贝 | 极致性能需求 |
2.1.2 Python 优化示例
# 从 elasticsearch 库中导入 helpers 模块
# helpers 模块提供了一些实用的工具函数,用于简化与 Elasticsearch 的交互,例如批量操作
from elasticsearch import helpers
import datetimedef gen_data():"""这是一个生成器函数,用于流式生成要插入到 Elasticsearch 中的数据。流式生成数据的好处是可以避免一次性将大量数据加载到内存中,从而防止内存溢出。"""# 循环 100000 次,模拟生成 100000 条数据for _ in range(100000):# 使用 yield 关键字将数据逐个生成# 每次生成的数据是一个字典,包含两个主要部分:_index 和 _sourceyield {# _index 指定数据要插入到的 Elasticsearch 索引名称# 这里将数据插入到名为 "logs" 的索引中"_index": "logs",# _source 包含了实际要存储的数据"_source": {# timestamp 字段记录当前的时间戳# 使用 datetime.now() 获取当前的日期和时间"timestamp": datetime.now(),# message 字段是一个示例消息,这里用 "..." 表示"message": "..." }}# 关键参数调优
# 使用 helpers.bulk 函数将生成的数据批量插入到 Elasticsearch 中
# 该函数返回两个值:success 表示成功插入的文档数量,failed 表示插入失败的文档数量
success, failed = helpers.bulk(# es_client 是 Elasticsearch 客户端实例,用于与 Elasticsearch 服务器进行通信# 这里假设 es_client 已经在代码的其他部分正确初始化es_client,# gen_data() 是前面定义的生成器函数,用于提供要插入的数据gen_data(),# chunk_size 指定每一批次插入的文档数量# 这里设置为 2000,意味着每次批量插入 2000 条文档chunk_size=2000,# max_retries 指定插入失败时的最大重试次数# 如果某一批次的插入操作失败,会尝试重新插入,最多重试 3 次max_retries=3,# initial_backoff 指定重试等待的基数(单位:秒)# 第一次重试前会等待 2 秒,之后每次重试的等待时间会根据一定规则递增initial_backoff=2,# request_timeout 指定单批插入操作的超时时间(单位:秒)# 如果某一批次的插入操作在 120 秒内没有完成,会被视为超时request_timeout=120
)
2.2 服务端关键参数
# elasticsearch.yml 调优项
# 批量操作线程池队列大小(控制并发写入能力)
thread_pool.bulk.queue_size: 2000 # 默认200易满
# ▶ 作用:设置批量操作(如 bulk API)的请求队列容量
# ▶ 调优:从默认200提升至2000,适应高并发批量写入场景(如日志采集、数据迁移)
# ▶ 场景:当写入量超过线程池处理能力时,队列可暂存请求(避免立即报错)
# ▶ 风险:过大可能导致内存溢出,需结合 heap size 调整(建议 ≤ 1/4 堆内存)# 索引内存缓冲区大小(影响文档刷新频率)
indices.memory.index_buffer_size: 20% # 堆内存占比
# ▶ 作用:控制每个索引的内存缓冲区占 JVM 堆的比例
# ▶ 调优:从默认10%提升至20%,增加单次刷新的文档数量(减少 I/O 次数)
# ▶ 机制:缓冲区满时触发 refresh(生成新的 segment)
# ▶ 场景:写入密集型业务(如实时日志、监控数据)# 索引刷新间隔(影响搜索可见性)
index.refresh_interval: 120s # 刷新间隔
# ▶ 作用:控制 Lucene 索引的刷新频率(数据写入后对搜索可见的时间)
# ▶ 调优:从默认1s延长至120s,降低 refresh 频率(提升写入性能)
# ▶ 权衡:牺牲实时性(120s 后数据可搜索)换取更高吞吐量
# ▶ 场景:离线分析、批量导入等对实时性要求不高的场景# 事务日志持久化策略(平衡写入性能与数据安全)
index.translog.durability: async # 异步写translog
# ▶ 作用:控制 translog(事务日志)的写入方式
# ▶ 模式:
# - async(异步):写入内存后立即返回(最快,可能丢数据)
# - request(同步):写入磁盘后返回(安全,性能低)
# ▶ 调优:异步模式提升写入速度(适合非关键数据或异步复制场景)
# ▶ 风险:节点宕机可能丢失最后一次 fsync 后的所有操作
3. 错误处理与容错设计
3.1 错误分类与处理策略
| 错误类型 | HTTP状态码 | 典型原因 | 重试策略 |
|---|---|---|---|
| 版本冲突 | 409 | 文档ID重复/版本号不匹配 | 丢弃或合并文档 |
| 限流拒绝 | 429 | 线程池满/队列超限 | 指数退避重试 |
| 分片未分配 | 503 | 节点故障/分片迁移中 | 等待集群恢复后重试 |
| 语法错误 | 400 | 字段类型不匹配/JSON格式 | 必须修复后重新提交 |
3.2 重试机制实现方案

3.2.1 重试参数计算公式

-
initial_backoff:初始退避时间(如 2 秒),建议设为 1-5 秒(平衡响应速度与服务器压力)。 -
retry_count:当前重试次数(从 0 开始),建议设为 30-120 秒(避免过长的等待时间)。 -
max_backoff:最大退避时间(如 60 秒),通过max_backoff防止间隔无限增长(如网络长期不可达时)。 -
推荐参数组合:
场景 initial_backoffmax_backoff最大重试次 网络抖动1s 10s 3 节点故障 5s 60s 5 集群维护 30s 300s ∞ -
对比其他退避策略

4. 性能优化案例
4.1 日志采集系统调优
4.1.1 原始性能
- 吞吐量:12,000 docs/sec
- CPU利用率:75%
主要瓶颈:小批量频繁提交
4.1.2 优化措施
-
- 批量大小从500调整至2000
-
- 启用gzip压缩(节省40%带宽)
-
- 客户端从同步改为异步模式
4.1.3 优化结果
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 吞吐量 | 12k/s | 34k/s | 183% |
| CPU利用率 | 75% | 88% | - |
| 网络包量 | 520/s | 150/s | -71% |
4.2 电商订单数据同步
4.2.1 挑战
数据突增:大促期间写入量增长20倍- 时效要求:95%数据需在5分钟内入ES
4.2.2 解决方案

4.2.3 效果验证
压力等级 | 平均延迟 | 写入成功率 | 系统负载 |
|---|---|---|---|
| 日常 | 2.1s | 99.98% | 45% |
| 大促 | 8.7s | 99.83% | 91% |
5. 监控与问题诊断
5.1 关键监控指标
| 指标名称 | 计算公式 | 健康阈值 | 告警策略 |
|---|---|---|---|
| Bulk队列等待时间 | thread_pool.bulk.queue | <1000 | 持续>500告警 |
写入拒绝率 | bulk.rejected / bulk.total | <0.1% | >1%立即告警 |
| JVM Old GC频率 | jvm.gc.old.count | <5次/分钟 | >10次/分钟告警 |
5.2 性能问题排查流程

6. 进阶优化策略
6.1 硬件级优化
| 硬件组件 | 优化方向 | 预期收益 | 成本评估 |
|---|---|---|---|
| CPU | 高频核心(3.6GHz+) | 提升15%-20% | $$$ |
| 内存 | 保持50%空闲内存 | 减少GC暂停 | $$ |
| 磁盘 | NVMe SSD RAID0 | 降低50% IO延迟 | $$$$ |
| 网络 | 25Gbps RDMA | 减少30%延迟 | $$$$$ |
6.2 数据建模优化
- 分片策略:
按时间范围分片(hot-warm架构) - 字段设计:
禁用 _all 字段,限制 nested 对象 - 索引模板:预定义字段类型,避免动态映射
- 关键结论:
- 通过合理配置批量大小(建议5-15MB)、实施指数退避重试策略、配合服务端线程池调优,
可提升Bulk API吞吐量3-5倍。 - 在极端场景下,
采用Kafka等中间件作为缓冲层 !!!,可确保系统弹性。持续的监控与硬件优化可将性能推向理论极限。
- 通过合理配置批量大小(建议5-15MB)、实施指数退避重试策略、配合服务端线程池调优,
相关文章:
【实战ES】实战 Elasticsearch:快速上手与深度实践-2.2.1 Bulk API的正确使用与错误处理
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 Elasticsearch Bulk API 深度实践:性能调优与容错设计1. Bulk API 核心机制解析1.1 批量写入原理剖析1.1.1 各阶段性能瓶颈 2. 高性能批量写入实践2.1 客户端最佳…...

鸿蒙Flutter开发故事:不,你不需要鸿蒙化
在华为牵头下,Flutter 鸿蒙化如火如荼进行,当第一次看到一份上百个插件的Excel 列表时,我也感到震惊,排名前 100 的插件赫然在列,这无疑是一次大规模的军团作战。 然后,参战团队鱼龙混杂,难免有…...

中间件框架漏洞攻略
中间件(英语:Middleware)是提供系统软件和应⽤软件之间连接的软件,以便于软件各部件之间的沟通。 中间件处在操作系统和更⾼⼀级应⽤程序之间。他充当的功能是:将应⽤程序运⾏环境与操作系统隔离,从⽽实…...

第21周:RestNet-50算法实践
目录 前言 理论知识 1.CNN算法发展 2.-残差网络的由来 一、导入数据 二、数据处理 四、编译 五、模型评估 六、总结 前言 🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 理论知识 1.CNN算法发展 该图列举出…...

构建大语言模型应用:数据准备(第二部分)
本专栏通过检索增强生成(RAG)应用的视角来学习大语言模型(LLM)。 本系列文章 简介数据准备(本文)句子转换器向量数据库搜索与检索大语言模型开源检索增强生成评估大语言模型服务高级检索增强生成 RAG 如上…...

AI-Sphere-Butler之Ubuntu服务器如何部署Nginx代理,并将HTTP升级成HTTPS,用于移动设备访问
环境: AI-Sphere-Butler WSL2 Ubuntu22.04 Nginx 问题描述: AI-Sphere-Butler之Ubuntu服务器如何部署Nginx代理,并将HTTP升级成HTTPS,用于移动设备访问 解决方案: 一、生成加密证书 1.配置OpenSSL生成本地不加…...

飞致云荣获“Alibaba Cloud Linux最佳AI镜像服务商”称号
2025年3月24日,阿里云云市场联合龙蜥社区发布“2024年度Alibaba Cloud Linux最佳AI镜像服务商”评选结果。 经过主办方的严格考量,飞致云(即杭州飞致云信息科技有限公司)凭借旗下MaxKB开源知识库问答系统、1Panel开源面板、Halo开…...

Django项目之订单管理part6(message组件和组合搜索组件)
一.前言 我们前面讲的差不多了,接着上节课讲,今天要来做一个撤单要求,我们可以用ajax请求,但是我这里介绍最后一个知识点,message组件,但是我会把两种方式都讲出来的,讲完这个就开始讲我们最重…...

Taro创建微信小程序项目 第一步搭建项目
1.node: 2.第一步: 安装taro npm install -g tarojs/cli 3.创建文件夹wxxcx, 创建demos的文件夹的项目(demos项目名称) taro init demos 出现以下信息:可以根据自己的需求选择 出现安装项目依赖失败不要紧 4.进入demos文件夹…...

S32K144外设实验(六):FTM输出单路PWM
文章目录 1. 概述1.1 时钟系统1.2 实验目的2. 代码的配置2.1 时钟配置2.2 FTM模块配置2.3 输出引脚配置2.4 API函数调用1. 概述 1.1 时钟系统 FTM的CPU接口时钟为SYS_CLK,在RUN模式下最高80MHz。模块的时钟结构如下图所示。 从上图中可以看出,FTM模块的功能时钟为SYS_CLK,…...

前端工程化开篇
前端发展史梳理: 最早的html,css,js是前端三剑客,足以实现所有的前端开发任务,但是呢,一个简单的前端交互效果可能就需要一大堆的代码去实现。 后来呢,有了前端库jQuery,他可以使前…...

地下管线三维建模软件工具MagicPipe3D V3.6.1
经纬管网建模系统MagicPipe3D,基于二维矢量管线管点数据本地离线参数化构建地下管网三维模型(包括管道、接头、附属设施等),输出标准3DTiles、Obj模型等格式,支持Cesium、Unreal、Unity、Osg等引擎加载进行三维可视化、…...

iOS自定义collection view的page size(width/height)分页效果
前言 想必大家工作中或多或少会遇到下图样式的UI需求吧 像这种cell长度不固定,并且还能实现的分页效果UI还是很常见的 实现 我们这里实现主要采用collection view,实现的方式是自定义一个UICollectionViewFlowLayout的子类,在这个类里对…...

以科技赋能,炫我云渲染受邀参加中关村文化科技融合影视精品创作研讨会!
在文化与科技深度融合的时代浪潮下,影视创作行业经历着前所未有的变革。影视创作行业发展态势迅猛, 同时也面临着诸多挑战。为促进影视创作行业的创新发展,加强业内交流与合作, 3月25日下午,海淀区文化创意产业协会举办…...

华为、浪潮、华三链路聚合概述
1、华为 链路聚合可以提高链路带宽和链路冗余性。有三种类型,分别是手工链路聚合,静态lacp链路聚合,动态lacp链路聚合。 手工链路模式:也称负载分担模式,需手动指定链路,各链路之间平均分担流量。静态LAC…...
介绍)
Android 蓝牙/Wi-Fi通信协议之:经典蓝牙(BT 2.1/3.0+)介绍
在 Android 开发中,经典蓝牙(BT 2.1/3.0)支持多种协议,其中 RFCOMM/SPP(串口通信)、A2DP(音频流传输)和 HFP(免提通话)是最常用的。以下是它们在 Android 中的…...

【go微服务】Golang微服务之基--rpc的实现原理以及应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

Redis的List类型
Redis的List类型 一.List类型简单介绍 二.List的常用命令1.LPUSH2.LRANGE3.LPUSHX4.RPUSH5.RPUSHX6.LPOP7.RPOP8.LINDEX9.LINSERT10.LLEN11.LREM12.LTRIM13.LSET 三.阻塞命令1.BRPOP(i)针对不是空的列表进行操作:(ii)针…...
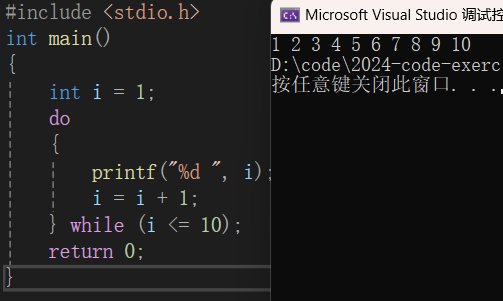
【C语言】分支与循环(下)
前言:小飞在(上)篇总结了分支结构的内容,本文接上,总结循环结构的知识。 看完觉得有帮助的话记得点赞收藏加关注哦~ 目录 一、while循环 二、for循环 三、do-while循环 四、循环中的break和continue 五、循环结构…...

Android 中两个 APK 之间切换的几中方法
在 Android 中,两个 APK(应用程序)之间的切换通常是通过 Intent 来实现的。以下是一些常见的方法和注意事项,帮助你实现两个 APK 之间的切换。 一、启动目标 APK 的主 Activity 1、setPackage 方法 使用 Intent 的 setPackage …...

SpringBoot集成腾讯云OCR实现身份证识别
OCR身份证识别 官网地址:https://cloud.tencent.com/document/product/866/33524 身份信息认证(二要素核验) 官网地址:https://cloud.tencent.com/document/product/1007/33188 代码实现 引入依赖 <dependency><…...

留记录excel 模板导入
Data EqualsAndHashCode public class FillData {ExcelProperty(value "姓名", index 0)private String name;ExcelProperty(value "数值", index 1)private double number;ExcelProperty(value "日期", index 2)private Date date; }pack…...

【C++数据库】SQLite3数据库连接与操作
注意:本文代码均为C++20标准下实现 一、SQLite3库安装 1.1 安装库文件 【工具】跨平台C++包管理利器vcpkg完全指南 vcpkg install sqlite3# 集成至系统目录,之前执行过此命令的无需再次执行 vcpkg integrate install1.2 验证代码 在VS2022中新建控制台项目,测试代码如下…...

【机器学习基础 4】 Pandas库
一、Pandas库简介 Pandas 是一个开源的 Python 数据分析库,主要用于数据清洗、处理、探索与分析。其核心数据结构是 Series(一维数据)和 DataFrame(二维表格数据),可以让我们高效地操作结构化数据。Pandas …...

如何在根据名称或id找到json里的节点以及对应的所有的父节点?
函数如下: 数据如下: [{ "name": "数据看板", "id": "data", "pageName": "tableeauData", "list": [] }, { "name": "审计模块", "id": &quo…...

JS—异步编程:3分钟掌握异步编程
个人博客:haichenyi.com。感谢关注 一. 目录 一–目录二–引言三–JavaScript 事件循环机制四–定时器的秘密:setTimeout 和 setInterval五–异步编程模型对比 二. 引言 在现代Web开发中,异步编程是提升性能的关键技术。无论是脚本加载&am…...

mxgraph编辑器的使用
前端JS如何使用mxgraph编辑器 说明:此项目是JS项目,目前还不支持TS 引入资源 可以直接从官网上拿下来,或者从其他地方获取 官网编辑器 如果只是展示图形的话只引入 mxClient.js就可以了 一个免费在线编辑器 自己用它做了一个在线编辑器&#…...

electron打包vue2项目流程
1,安装一个node vue2 的项目 2,安装electron: npm install electron -g//如果安装还是 特比慢 或 不想安装cnpn 淘宝镜像查看是否安装成功:electron -v 3,进入到项目目录:cd electron-demo 进入项目目录…...

STM32F103_LL库+寄存器学习笔记11 - 串口收发的中断优先级梳理
导言 推荐的STM32 USARTDMA 中断优先级设置(完整方案): 以你的STM32F103 USART1 DMA实例为例: 推荐中断优先级设置中断优先级USART1空闲中断(接收相关)优先级0DMA1通道5接收中断(半满/满传输…...
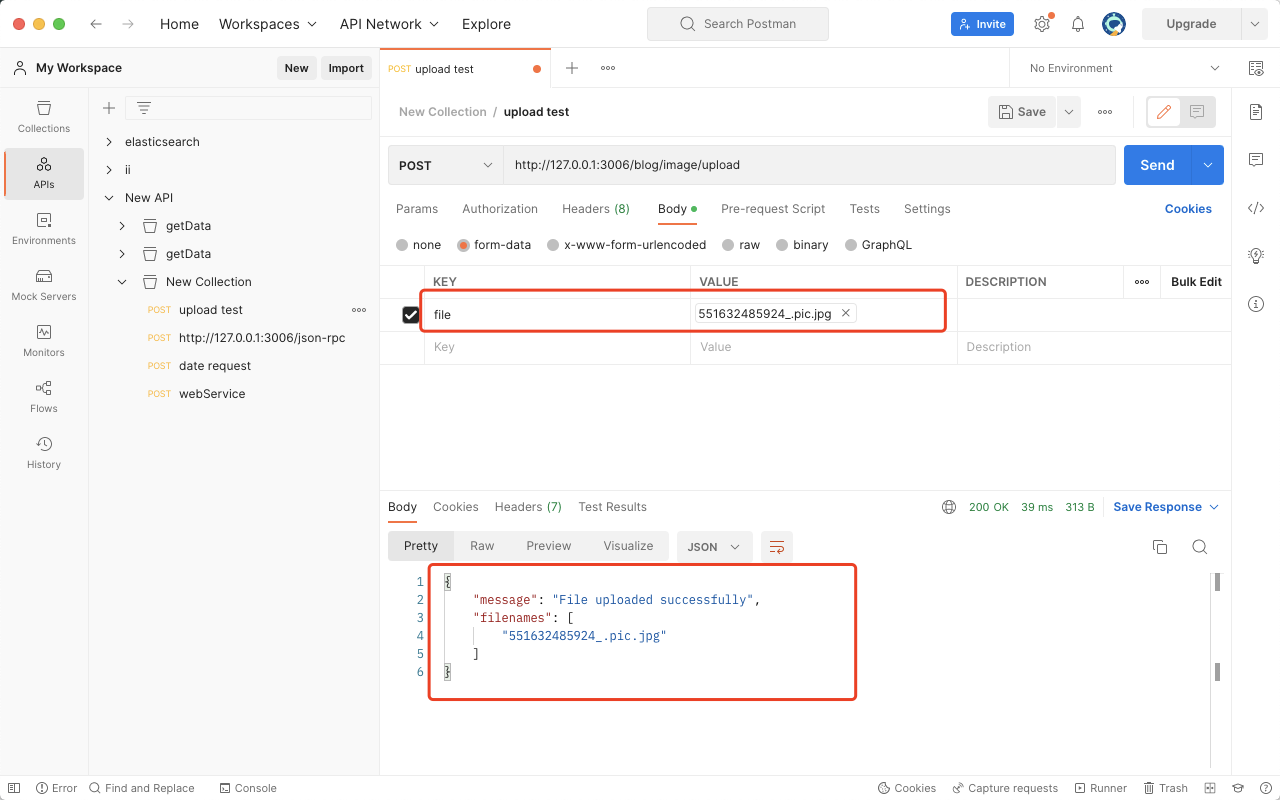
Postman 如何发送 Post 请求上传文件? 全面指南
写一个后端接口,肯定离不开后续的调试,所以我使用了 Postman 来进行上传图片接口的调试,调试步骤也很简单: 第一步:填写请求 URL第二步:选择请求类型第三步:选择发送文件第四步:点击…...