数据结构day04
一 栈
1栈的基本概念

 各位同学大家好,从这个小节开始,我们会正式进入第三章的学习,我们会学习栈和队列,那这个小节中我们会先认识栈的基本概念。我们会从栈的定义和栈的基本操作来认识栈这种数据结构,也就是要探讨栈的逻辑结构,还有我们需要实现的一些基本运算。在后续的小节,我们再来探讨用不同的存储结构实现栈。
各位同学大家好,从这个小节开始,我们会正式进入第三章的学习,我们会学习栈和队列,那这个小节中我们会先认识栈的基本概念。我们会从栈的定义和栈的基本操作来认识栈这种数据结构,也就是要探讨栈的逻辑结构,还有我们需要实现的一些基本运算。在后续的小节,我们再来探讨用不同的存储结构实现栈。

那这一页的课件和线性表的第一页课件,其实几乎是一模一样的。因为无论我们讨论什么样的数据结构,肯定都需要从数据结构的三要素作为出发点来依次分析和探讨。那我们这个小节中要学习的栈和线性表之间其实有很紧密的联系,
那这是我们之前学过的线性表的概念。
1.1 栈的定义

而栈其实也是一种特殊的线性表,只不过对于普通的线性表来说,当我们要插入一个数据元素或者删除一个数据元素的时候,我们可以在任意一个地方插入和删除,但是对于栈这种数据结构来说,我们会限制它的插入和删除操作。插入和删除操作只能在线性表的一端进行。也就说,如果我们要插入一个数据元素,那我们只能在表尾的这个位置进行。我们不可以在其他的这些地方进行插入操作,这是栈这种数据结构所不允许的。同样的,如果要删除一个数据元素的话,那我们同样只能从这边进行依次的删除。
其实栈的英文术语也就是stack,它的含义可以很好的表现出它这所说的这种性质来看一下。stack有个含义,叫做整齐的一堆,这儿给了一张图片,一个整齐的小石头堆好,那现在如果你有一个新的石头,想要放到这个石头堆里,你是不是只能放到?这个石头堆堆顶的位置啊。而如果你要拿走一个石头的话,你也只能从顶部拿走一个,如果你强行把中间的某一个石头直接抽掉的话,
那整个石头堆它就散了,对吧?所以其实这个英文术语的含义更能体现栈这种数据结构的一个呃核心的特性

那我们的生活中其实也有很多栈,比如说大家帮家里洗碗的时候呃,你洗的这些碟子一个一个落起来,这其实也是一个栈。如果你想放入一个新的盘子,那你是不是只能放到这个顶部,也就只能从顶部这一端进行插入操作?同样的,如果你想拿走一个盘子的话,那同样的,你只能从顶部拿走,最上面这个盘子。也就是从顶部这一端进行删除操作。
另外还有大家吃的烤串,那些烤串师傅在穿这些肉串的时候,肯定是先把下面的这些肉给穿进去。永远是从上方进行插入操作,同样的,当你在吃烤串的时候,你是不是也只能从上往下吃啊?也是只能从上面这一端进行删除操作。所以这就是栈,它也是一种线性表,因为这些数据元素之间,我们从逻辑上看,它也是穿成了一条线,也是有这样一前一后一对一的关系。只不过栈这种特殊的线性表,它的插入操作和删除操作是有限制的,只能从其中的一端进行插入和删除

好,接下来看一下和栈相关的几个比较重要的术语,栈顶栈底和空栈,那空栈很简单,就是这个栈里边没有存任何数据元素。其实就对应线性表的空表对吧,然后我们往一个栈里边放入元素的时候,肯定是从其中一端一个一个压入的。所以栈顶和栈底这两个术语其实也很直观,栈顶就是指允许进行插入和删除的这一端,而栈底指的是不允许插入和删除的这一端。那相应的,最上面的这个元素被称为栈顶元素,最下面的这个称为栈底元素。
那刚才的动画中,这几个数据元素的进栈顺序分别是a1a2a3a4a5,依次被压入栈中。那接下来如果让这几个数据元素出栈,或者说依次删除这些数据元素的话,那么出栈的顺序应该是a5先出,接下来是a4a3a2a1。刚好是进栈顺序的一个逆序。所以栈的特点就是后进先出,后进入这个栈的数据元素,会先出栈。那很多地方,在描述后进先出这种特性的时候,会用这样的一个英文缩写。lifo就是last in first out一个缩写。
因此,通过刚才的这些讲解,可以看到栈是一种特殊的线性表,它和普通的线性表相比,其实逻辑结构是一样的。这些数据元素之间有这样一对一,一前一后的逻辑关系。只不过和普通的线性表相比,栈这种数据结构,它的插入和删除操作只能在栈顶的这一端进行。这一点是和普通的线性表有区别的
 1.2 栈的基本操作
1.2 栈的基本操作

那接下来我们要看一下栈相关的基本操作,首先快速的回顾一下线性表相关的基本操作。其实就是创建销毁,还有增删查这几个基本操作,
那栈需要实现的基本操作也是一样的,首先是创建和销毁。创建一个栈,也就是初始化一个栈,就是要分配相应的内存空间,而销毁一个栈,就是要释放这个栈所占用的内存空间。那接下来是增删两个操作,我们用push和pop来表示进栈和出栈,也就分别对应增加一个数据元素和删除一个数据元素,这两个基本操作。所谓进栈,就是要把数据元素x放到栈s的栈顶,而出栈,就是要把栈s它的栈顶元素给删除,并且用x这个变量给带回去。所以这才加了一个引用符号。
好再往后的操作,是读取栈顶元素get top会用变量x返回这个栈顶的元素。那这个基本操作和上面这个基本操作(pop)的区别是上面出栈的这个基本操作,除了返回栈点元素之外,还会把栈点元素给删除。但是get top这个基本操作,它只会读取栈点元素,用x来返回,但是并不会把栈点元素给删除。那get top这个基本操作,其实就是对应了查,在普通的线性表当中,我们需要实现按位序查找这样的功能,但是对于栈的使用场景来说。大部分情况下,当我们要访问一个数据元素的时候,通常只需要访问栈顶的这个元素,所以在查找数据元素的时候,通常我们只需要找到这个栈顶的元素就可以。
好再往后还有比较常用的这个基本操作,就是判断这个栈是否是一个空栈,如果是空的话返回去,否则返回FALSE这个和线性表的判空是。是几乎一样的。好,那这是栈相关的重要的基本操作,


总之核心就是我们要知道栈这种数据结构,我们的插入和删除操作只能在栈顶进行。它是一种操作受限的线性表,而由于插入和删除,只能在栈顶进行,因此它就拥有一个特性,叫做后进先出,后进入栈的数据元素,反而会先出栈。
2 顺序栈的实现


各位同学大家好,在这个小节中,我们会探讨顺序栈的实现,也就是怎么用顺序存储的方式来实现一个栈。那在确定了存储结构之后,根据这个存储结构还需要探讨与它相对应的一系列基本操作应该怎么完成,那顺序栈相关的基本操作其实和我们之前学过的顺序表链表那些是很类似的。比较重要的是,如何初始化,然后怎么实现进栈,也就是怎么增加一个数据元素,还有怎么实现出栈,也就是删除一个数据元素。另外,还需要探讨如何获取栈点元素,还有如何判断一个栈空,如何判断栈满这几个问题。
2.1 顺序栈的定义
 它既然是用顺序存储的方式实现的,那它的代码的定义实现方式其实就和我们的顺序表是非常类似的,你看这个地方定义了一个struct结构体,然后我们用type def把它重命名为SqStack,然后这个结构体里边包含了一个静态的数组data用于存放栈中的各个元素,那这地方SQ就是sequence的缩写,也就是顺序的意思,所以接下来我们就可以在自己的函数里边用这样的方式声明一个顺序栈。
它既然是用顺序存储的方式实现的,那它的代码的定义实现方式其实就和我们的顺序表是非常类似的,你看这个地方定义了一个struct结构体,然后我们用type def把它重命名为SqStack,然后这个结构体里边包含了一个静态的数组data用于存放栈中的各个元素,那这地方SQ就是sequence的缩写,也就是顺序的意思,所以接下来我们就可以在自己的函数里边用这样的方式声明一个顺序栈。
那在执行了这句代码之后,就会在内存当中分配这样的一整片的连续的空间,这整片空间的大小应该是max size,也就是栈的最大容量再乘以每一个数据元素,它的大小,另外还需要在内存当中分配四个字节的大小,用于存放top这个变量。那这个变量,它其实是栈顶指针,就是用于指向此时这个栈的栈顶元素。一般来说,这个栈顶指针,它记录的是数组的下标,也就是从零开始的好,
那假设现在我们的栈中已经压入了这样的几个数据元素,那此时这个栈顶指针的值就应该是四,也就是指向栈顶元素的这个位置,这个是数组的下标
2.2顺序栈的初始化操作

那在分配了存储空间之后,接下来需要进行初始化的操作。那刚才我们说过,这个栈顶指针要让它指向此时栈顶元素的位置,所以刚开始的时候top指针指向零这个位置其实是不合理的。因为data 0这个位置,此时还没有存放数据元素,所以刚开始我们可以让top的值指向负一。
因此,按照这儿的逻辑,我们要判断一个栈是否为空的时候,只需要判断它的top指针是否等于负一就可以。好,那到这一步,我们就完成了栈的初始化工作,接下来就可以进行一些后续的操作,也就是增删改查那些东西,对吧?
2.3进栈操作(增)

我们首先来看一下增,也就是增加一个数据元素的操作,那对于栈这种数据结构的插入操作,我们通常把它称为进栈。
好来看一下,怎么把数据元素x放到栈s当中?首先第一步需要判断这个栈此时是否已满,
因为顺序栈是用静态数组的方式实现的,它有一个最大容量的上限好,那在右边这种情况下,此时暂时不满的,因此可以继续往后执行。接下来我们是不是想往这个data【 0】这个位置给插入一个新的数据元素?因此,我们可以把top指针先让它加一,也就是从负一变为零,然后接下来把此次传入的这个数据元素x把它存到data数组里边,也就是此时top指针所指向的这个位置,也就是放到这个地方。然后给调用者返回一个true表示,此次入栈操作成功好,
那接下来如果还要进行进栈操作的话,那是不是依然需要把top指针?让它往后移一位,然后再把这一次的数据元素给放到相应的位置,总之由于我们的top指针,它永远都是指向此时的这个栈顶元素的位置。因此,当一个新元素入栈的时候,我们肯定都需要先让top指针加一,然后再往top指针指向的位置放入新的元素,
那我们的课本当中给了一种更简洁的写法,就是这样的。这儿用的是加加top,而不是top加加,这个跨考的同学需要注意一下,那这句代码和左边的这种写法是等价的,
加加top的意思就是说先让top的值加一,然后再来使用这个top的值。而如果你没注意写成了top加加的话,那么就相当于你先使用了top的值,然后再让top的值加一。放在右边这个例子当中,假设我们此时想要插入一个新的数据元素c,那c,这个数据元素它合法的呃,我们期待的插入位置应该是插入到这个地方,也就data 【2】这个位置。好!此时top的值是一,那如果你使用的是top加加这样的写法的话,那么就相当于你先把此次要传入的这个数据元素c。先把它放到了呃data 【1】当中,也就相当于你让数据元素c把以前的这个数据元素b给覆盖了。然后接下来才进行top+1的操作,也就让top指针指向这个位置。所以这种执行就是一种错误的结果,因此基础不太好的同学一定要注意这个小细节啊,比较容易出错。


好,接下来看一下这个顺序栈已经存满的情况,那我们的顺序栈它的容量是十。此时已经全部存满了那top指针,指向栈顶元素,也就指向这个位置,它的值应该是九,在这种情况下,
如果继续调用入栈操作,那么由于top的值此时是等于max- 1,也就是等于九,所以这就意味着此时栈已经满了,因此会直接返回一个FALSE给函数的调用者一个反馈。好,那这是进栈操作的实现
2.4出栈操作(删)

接下来看一下出栈操作,出栈操作其实就对应了增删改查的删,也就是要删除栈顶的一个元素,并且用变量x来返回。那这个地方x这个变量加了引用符号,也就是说这个出栈操作的调用者,他首先会在自己的函数里边定义一个。一个变量叫做x,这个变量存放在内存中的某一个位置,那由于这儿加了引用符号,所以在出栈操作里边操作的这个变量x和函数的调用者定义的这个变量x对应的是同一份数据,而不是它的复制品。好,接下来要判断这个栈是否为空,如果栈空的话,那么肯定不能让它进行删除的操作,也就是出栈的操作。
那在右边这个例子当中,此时栈是非空的,所以接下来会把栈顶指针所指向的这个元素,把它赋给x,这个变量也就是把这个值复制到内存里的这小片区域当中。接下来让top的值减一,也就是栈顶指针下移,然后给函数的调用者返回。一个true表示,此次的调用成功。
那在这个删除操作当中,我们把top指针让它往下移了一位,其实只是在逻辑上删除了之前的这个栈顶元素,但是其实k这个数据元素的数据依然还是残留在内存当中的。它只是在逻辑上被删除了而已,
那和入栈操作类似,我们可以把这两句代码合并成一个更简洁的写法,这使用了top减减,也就是说。先使用top的值,再让top的值减一类似的,如果你写的是减减top,那你的这些代码运行就会出现问题。
来看右边这个例子,此时栈顶元素应该是j这个元素,也就是说我们要让x返回的是j这个数据元素,那如果说我们使用的是减减top这样的写法的话。那首先会让top的值减一,也就是先让top指向这个位置,接下来才把top指向的这个元素把它赋给变量x。也就说x返回的是I这个元素,而不是j这个元素,那这并不是我们所期待的正确结果,所以这个跨考的同学一定要注意。
当然,这个代码千万不要背,一定是要基于理解的基础上能够自己分析到底用哪种写法。好,那这是出栈操作
2.5读栈顶元素的操作(查)

接下来看读取栈顶元素的操作,其实这个操作和出栈操作几乎一模一样,唯一不同的是出栈操作会让top指针减减往下移一位。但是读栈顶元素这个操作,它只是把此时top指针指向的这些数据元素用x给返回,但并不会让top指针减减。所以这个很简单,就不再赘述好,

那刚才我们提到所有的这些代码都是让top指针指向此时的栈顶元素,用了这样的一个方案。
那其实我们还可以用另外一种方式来设计,我们可以让top指针刚开始指向零这个位置,那相应的判断栈是否为空,就是看top是否为零。那这儿的这种实现方式,我们是让top指针指向了下一个,我们可以插入元素的位置。因此,如果接下来有一些数据元素入栈的话,那么top指针应该是指向这个位置。

好,那如果我们这么设计的话,那当我们想要让一个新的数据元素x入栈的时候,我们是不是需要先把x?放到此时top指针指向的这个位置,
然后再让top指针加一对吧,这和之前的那种方式刚好是相反的,在这种情况下,我们就应该用top加加,而不是加加top。
那类似的,如果此时要让栈顶元素出栈的话,那么我们应该先让top的值先减一,然后再把top指向的数据元素给传回去,因此就应该用减减top这样的操作。所以大家在做题的时候一定要注意审题,这个top指针它到底是要让它指向栈顶元素,还是要让它指向栈顶元素后面的一个位置?两种方式的实现代码是不一样的
如果这个栈已经存满了的话,那么top指针它的值应该是等于max size,也就是等于十。因此,判断栈满的条件也会不一样。那可以看到,由于顺序栈是用了一个静态数组来存放数据元素,因此当这个静态数组被存满的时候,它的容量是不可以改变的。那这是顺序栈的一个缺点,
如何解决这个问题呢?可以用链式存储的方式来实现栈,或者我们也可以在刚开始的时候给这个栈分配一个比较大片的连续的存储空间。但是刚开始就分配大片的存储空间,这会导致内存资源的浪费,

那其实可以用共享栈的方式来提高这一整片内存空间的利用率。共享栈的意思就是说两个栈共享同一片存储空间,我们会设置两个栈顶指针,分别是零号栈和一号栈的栈顶指针。然后零号栈的栈顶指针刚开始是负一,一号站的栈顶指针,刚开始是max size,接下来如果要往零号栈放入数据元素的话,那么就是从下往上依次递增的。而如果要往一号栈放入数据元素的话,那么这个栈的栈顶又是从上往下依次递增的,那这样的话,在逻辑上,我们这实现了两个栈。但是物理上它们又是共享着同一片的存储空间。这就会提高内存资源的利用率好,
那这个共享栈它也是会被存满的,判断共享栈是否满了的条件就是你判断一下top 0它再加一是否等于top 1的值。好,那共享栈相关的代码,有兴趣的同学也可以自己去实现一下

这一小节中,我们学习了如何用顺序存储的方式实现栈?那用这种方式实现的栈就称为顺序栈。我们要定义一个静态数组来存放数据元素,另外还需要在struct结构体里边啊,定义一个栈顶指针。我们可以让这个栈顶指针指向当前的栈顶元素,也可以让栈顶指针指向接下来可以插入数据元素的这个位置。两种设计方式所对应的初始化操作会各不相同,
另外再增加一个数据元素和删除一个数据元素的时候,代码实现也会有所不同。这个是比较容易错的地方,所有的这些基本操作都可以在o(1)的时间复杂度内完成。那怎么销毁一个顺序栈呢?首先是要在逻辑上把这个栈给清空,接下来再回收这个栈所占用的内存资源。在逻辑上,清空一个栈其实只需要让top指针指向初始化的那个位置就可以了。在这个小节的代码当中,我们是使用了变量声明的这种方式来分配相应的内存空间,并没有使用malloc函数。所以给这个栈分配的内存空间也会在你的这个函数结束之后,由系统自动的回收,所以其实回收内存资源这个事情你并不需要管。
3 链栈的实现

 各位同学大家好,在这个小节中我们会学习如何用链式存储的方式来实现栈,那用链式存储的方式实现的栈叫做链栈。同样的,在确定了存储结构之后,我们也需要探讨基于这种存储结构怎么实现相应的这些重要的基本操作。
各位同学大家好,在这个小节中我们会学习如何用链式存储的方式来实现栈,那用链式存储的方式实现的栈叫做链栈。同样的,在确定了存储结构之后,我们也需要探讨基于这种存储结构怎么实现相应的这些重要的基本操作。 
好,那我们先穿越到之前单链表相关的一个课件,用头插法来建立单链表,所谓用头插法建立一个单链表,就是指当我们要插入一个数据元素的时候,我们都是把它插入到这个头结点之后的位置。就像这个样子。那可以看到,刚才我们对这个单链表进行插入操作的时候,都是在这一端进行插入的,那这其实不就是栈的进栈操作吗?如果我们规定只能在单链表的这一端进行插入操作的话,那这就是进栈操作,

好那类似的,如果我们规定当我们对这个单链表进行删除操作的时候,我们同样只能在这一端进行删除操作,就像这个样子。那这种有限制的删除操作,不就是我们栈里边的出栈操作吗?
所以其实用链式存储实现的栈,它本质上也是一个单链表,只不过我们会规定只能在这个单链表的这一端进行插入和删除操作,也就是把链头的这一端把它看作是我们的栈顶的一端。
所以大家会看到,对于链栈的定义,其实和单链表的定义几乎没有任何区别,只是这些名字稍微改了一下而已。

那和单链表类似,当我们用链式存储的方式来实现链栈的时候,我们是不是也可以实现带头节点的版本和不带头节点的版本?当然,两种设计方式对于栈是否为空的这个判断会不一样。那进栈和出栈操作,其实就是对应了单链表当中的插入数据元素和删除数据元素的操作,只不过插入和删除我们只能在这个表头的位置进行。
那如何在表头的位置插入和删除这个,我们在单链表那个小节当中已经讲的非常详细了,这就不再赘述。

二 队列
1 队列基本概念


各位同学大家好,从这个小节开始,我们会学习一种新的数据结构队列,那和之前那些数据结构一样,我们会先探讨它的逻辑结构,还有我们需要实现的一些基本操作。之后再来探讨如何用不同的存储结构来实现队列,
1.1队列的定义

那队列其实它也是一种操作受限的线性表。之前我们学习的栈是只允许在线性表的某一端进行插入和删除,而队列这种数据结构是只允许在其中的一端进行插入,在另一端进行删除。对队列的插入操作,一般把它称为入队,而对队列的删除操作,一般把它称为出队。其实,相比于之前学习的站。队列这个术语一看就知道它是什么意思

我们的生活中就有许多队列,比如说大家去食堂打饭的时候,其实就是排成了一个队列,如果此时有一个人,他也想打饭的话。那他只能插入到这个队列的队尾,如果新到的这个人想插入到队头,是不是其他人都不愿意?也就是说,这个入队或者说插入的操作,只允许在队尾的这一端进行好,
那相应的食堂大师傅每一次只能给这个对头的人打饭。然后当这个人打完饭之后,他就可以离开,也就是说进行了一个删除操作,每一次离开队列的一定是这个对头的元素,也就是说只能从另一端进行删除。那还有大家坐车过收费站的时候,是不是也是排成了一个汽车的队列?那队列的一个特点就是先进入队列的这些元素,它可以先出队列。

好,那需要注意和队列相关的几个术语,队头队尾和空队列其实很好理解,对吧?如果一个队列里边此时没有任何数据元素的话,那么这个队列就是一个空队列。我们可以往一个队列中插入数据元素,那么允许插入数据元素的这一端,我们就把它称为队尾。此时队列中最靠近队尾的这个元素,就是对尾元素,那相应的可以进行删除操作的这一端,我们就把它称为队头。再次强调队列的特点叫先进先出,很多时候在考试中喜欢用这种英文缩写来表示先进先出。fifo也就是first in first out的缩写好,那这儿顺道回忆一下栈的特点是叫后进先出对吧?lifo也就是last in first out。好,
那这就是队列这种数据结构,其实本质上它也是一种线性表,只不过对队列的插入和删除操作是有限制的,只能在一端进行插入,另一端进行删除
1.2队列的基本操作

那我们需要实现的对队列的基本操作,其实和线性表也是一样的,就是创销增删改查这些东西。创建一个队列和销毁一个队列,其实就是给这个队列分配相应的内存空间和回收相应的内存空间。其实和我们之前学过的内容几乎是一样的,只不过对队列的插入操作,我们通常把它称为入队,而对队列的删除操作通常把它称为出队。
并且新的数据元素x,它只能从对尾的这个位置入队,出队这个操作会把对头元素删除,同时用x给返回。和它很像的是,读队头元素这个操作,但是这个操作只会把队头元素的值用x这个变量给返回,但是并不会删除队头元素。这个其实和栈的出栈,还有读栈顶元素是相对应的,另外判断一个队列是否为空也是一个很常用的操作。同时,这也是选择题中比较喜欢考的一个考点。

好,那这一小节的内容十分简单,特别是学了之前的栈之后,就很容易理解什么叫做操作受限的线性表。由于插入操作只能在对尾删除操作,只能在队头进行,所以这就导致了队列拥有先进先出的特点。好,那对队列的这些基本操作,我们之后还会结合呃不同的存储结构来进行更进一步的讲解,那以上就是这个小节的全部内容。
2 队列的顺序实现


各位同学大家好,在这个小节中我们会学习如何用顺序存储的方式实现队列,那在确定了存储结构之后,也需要讨论基于这种存储结构如何实现队列相关的这一系列重要的基本操作。

好,那之前我们说过队列,它其实也是一种特殊的线性表,只不过是一种操作受限的线性表,因此基于之前学习的知识,不难想到如果要用顺序存储的方式实现队列的话。那我们可以用静态数组来存储队列当中的数据元素,同时由于队列的操作受限,我们只能从对头删除元素,只能从对尾插入元素,因此我们还需要设置两个变量用来标记队列的队头和队尾。
好,那定义了队列的结构体之后,我们就可以用变量声明的方式来声明,这样的一个队列执行这句代码会导致系统在背后给我们分配这样的一整篇连续空间。这片空间的大小是可以存放十个数据元素,也就是十个allen type,那如果此时队列中有这样的一些数据元素,然后下面是队头,上面是队尾的话。我们可以规定,让队头指针指向这个队头元素,让队尾指针指向队尾元素的后一个位置,也就是接下来我们应该插入数据元素的这个位置。因此,在右边这种情况下front的值应该是零,而rear的值应该是五。好,那既然对为指针是要指向接下来应该插入数据元素的那个位置。
2.1初始化操作

因此,按照这样的设计逻辑,我们就可以在初始化的时候,让队尾指针和队头指针同时指向零。因为队尾指针指向的这个位置,应该是接下来应该插入数据元素的位置,那我们可以用队尾指针和队头指针,它们所指向的位置是否相等来判断这个队列此时是否为空。好,那完成了队列的初始化工作之后,接下来就可以进行一系列后续的操作,
也就是增删改查那些操作。
2.2入队操作

先来看如何在队列中增加一个数据元素,也就是如何入队,
那我们只能从队尾的方向让新元素入队。好,那由于这个队列是用静态数组实现的,它的容量有限,所以当我们在插入之前,是不是需要先判断一下这个队列是否已经存满?如果没有存满,才可以往队列当中放入新的数据元素,那如何判断队列已满?这个我们一会儿再来讨论,我们先来看一下如何插入数据元素。
第一步,把这一次传入的参数x,也就是此次要插入的数据元素,把它放到队尾指针所指向的这个呃位置,也就是这儿。第二步,再把队尾指针加一,也就是往后移一位,这就完成了一次简单的入队操作,好,那再往后如果还按这样的逻辑啊,让其他的数据元素依次入队的话。那么,rear指针会依次往后移,当整个静态数组都被存满之后,rear指针应该是十这样的值。

好,那我们是不是可以认为当队尾指针的值等于这个max size的时候就认为队列它是满的呢?(并不是)。好来看一下,如果接下来依次让几个队头元素出队的话,那么我们的队头指针会依次往后移。同时,这个静态数组前面这些区域是不是就已经空闲了?所以接下来如果还有新元素要入队,那我们可以把它插入到前面这些位置,因此当rear也就是队尾指针等于max size的时候,其实这个队列并没有存满。那怎么让rear指针重新指挥到这儿呢?其实很简单,我们只需要用一个取余的操作就可以完成这个事情。来看一下,
假设此时队尾指针的值是九,也就是指向了这个数组的最后一个位置。接下来,新元素应该是插入到队尾指针所指的这个位置,再往后的一句代码会让rear指针的值等于rear+1。再对max size取模,也就是九+1再对十取模,这个运算的结果是零,因此执行完第二句之后rear指针又会指向这个位置。那这儿照顾一下跨考的同学,可能有人不知道模运算或者取余运算是什么意思?a对b进行取余运算的结果其实就相当于a÷b,然后它们的余数是多少?其实就是我们小学时候学的最简单的那些除法,那在有的地方也会用a mod b来表示,这个取余运算。很显然,任何一个整数x它除以七,最终得到的这个余数只有可能是零一二。三四五六这样的几个可能性,这个余数不可能大于等于七,对吧?所以这种模运算或者说取余的运算,其实是把无限的整数域把它映射到了有限的整数集合上。因此,我们这儿利用了曲域运算,让对尾指针的变化是从下到上,然后再回到最下面,然后再往上。这样循环往复的变化,
2.3循环队列

这样循环往复的变化,其实就相当于把我们这儿这样的一个线状的存储空间在逻辑上把它变成了这样的一个环状的存储空间。那刚才说过这儿的第二句代码会导致队尾指针指向下一个应该插入数据元素的位置。基础不好的同学可以暂停捋一捋,由于这个队列的存储空间在逻辑上看似乎是一个环状,是一个循环,所以我们把用这种方式实现的队列称为循环队列。这个术语是有可能在选择题当中出现的好,那由于此时还有空闲空间,因此我们还可以继续往这个呃队列当中插入新的数据元素,同时也需要让这个队尾指针不断的后移。
当这个队列还剩最后一个存储空间的时候,我们就认为此时队列已经满了,可能有同学会觉得奇怪,这儿不是还有一个空闲的空间可以利用吗?往这儿插入一个新的数据元素,同时让rear指针指向后一个位置,这样不是也可以吗?但是需要注意的是,我们在初始化队列的时候,我们是让front指针和rear指针指向了同一个位置。同时,我们也是通过这两个指针,是否指向同一个位置来判断这个队列是否为空的。如果像刚才说的这样,往这个位置也插入了数据元素,同时让rear指针和front指针指向同一个位置的话,那按刚才说的逻辑,这两个指针指向同一个位置是否就意味着这个队列为空了呢?这显然不对,对吧?所以没办法,我们必须牺牲这样的一个存储单元,
2.3.1循环链表--入队操作

因此在新元素入队之前,我们可以检查队尾指针的后一个位置,它是否等于队头指针所指向的这个位置?如果满足这个条件,说明队列已经存满了,就直接return一个FALSE表示插入失败 。
2.3.2循环队列--出队操作

接下来看怎么实现出队操作,也就是删除一个数据元素,
那我们只能让队头元素出队,那第一步首先判断一下这个队列是否为空。如果队列空的话,直接就return一个FALSE表示出队操作失败,如果队列不空,那么就把队头指针指向的数据元素把它赋给变量x。用这个变量让数据元素返回,接下来让front指针往后移一位。当然,我们这儿也要对max size取模,这样才可以让front指针呃转着圈圈移动。好,那接下来类似的,只要这个队列不空,那么就可以继续让这个队列的对头元素依次的出对。
每一次出对的都是front指针所指向的元素,并且队头指针会每次往后移一位,那当队头指针和队尾指针再次指向同一个位置的时候。此时就说明这个队列已经被取空了,此时就不能再进行出队操作。那这是出队操作的实现,也就是增删改查的删,
那增删改查的查怎么实现呢啊?在队列当中,我们通常只需要查询,或者说只需要读取队头的那个元素。所以它的实现很简单,把此时队头指针指向的这个元素赋给x。用x返回就可以了,其实就是把出队操作的这句给删掉。不要让对头指针往后移就可以。
2.3.3方案1:判断队列已满、已空

好,那刚才我们设计的这种方案当中,我们要判断一个循环队列是否已满的条件,是是要看一下这个队尾指针的后面一个位置是否和队头指针指向的是同一个地方满足这个条件,那么就说明此时队列已满,而如果队头指针和队尾指针指向同一个地方的话,那么就说明此时队列已经空了。我们可以很方便的用队尾指针和队头指针的值计算出这个队列当中当前有多少个数据元素。计算方法就是这样,比如在左边这个例子当中,此时队尾指针的值是二。队头指针的值是三,那按照这儿的算法,整个队列的数据元素个数就应该是二,加上max size是十,然后再减掉三再对max size进行取余也就等于九对十取余。计算结果是九,也就是说此时队列中有九个数据元素,其他的情况同学们可以自己验证一下。学过数论的同学可以用模运算的性质来证明这个式子不会证明的同学,也需要把这个记住,这个还是挺常考的。大家可以多找一些例子来验证一下这种计算方式的合法性好,
那刚才我们设计的这种判断对满和对空的方式其实是以牺牲了一片存储空间作为代价的。其实自己写代码,做自己的项目的话,使用这种方式就已经完全OK了,但是我们的出题老师不会这么想,有的题目会要求我们说不能浪费这一片存储空间。
但是之前我们又说了,如果继续往这儿存入数据元素,同时让这个对尾指针往后移一位的话,那么队满和队空所表现出来的状态其实就是一样的,我们就没办法用代码逻辑来判断这个队列到底是满的还是空的,那怎么解决这个问题呢?
2.3.4方案2

其实可以在我们的队列结构当中定义一个变量size。这个变量来记录队列当中,此时存放了几个数据元素,也就是说刚开始我们要把size的值设为零。之后,每一个新元素入队成功,我们都需要让size的值加加每一个对头元素出队成功,我们都需要让size的值减减。
这样的话,我们就可以根据size的值来判断队满和队空了,那在左边这个情况下,此时size的值应该是九,接下来如果再往里边插入一个元素,然后让rear往后移位的话。那么size的值就会变成十,也就是等于max size,此时队列就是满的,而右边这种情况,此时队列中只有一个数据元素,也就是说size的值是一。接下来再让这个队头元素出队,然后front指针往后移位,那由于删除成功之后size的值都需要减减,因此size的值就变成了零。那此时队列为空,可以看到,虽然队头指针和队尾指针都是指向同一个位置,但是由于我们设置了这个新的变量size,因此我们可以用这个变量来判断队列此时到底是满的还是空的?那这是另一种判断,对空和对满的方法
2.3.5方案3
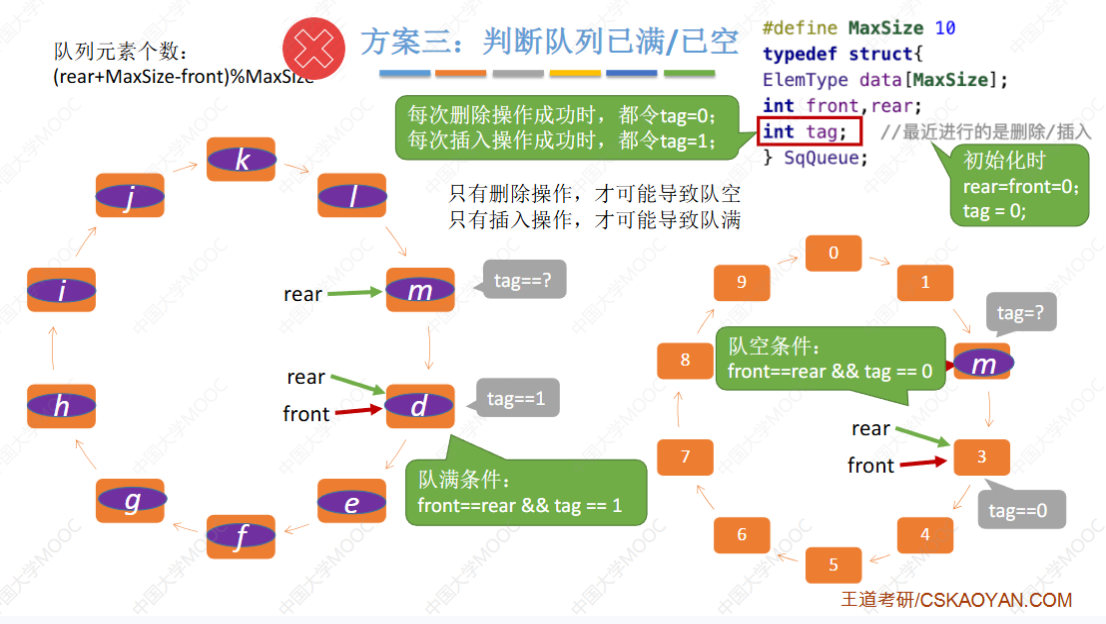
再来一种方法,我们可以设置一个变量tag。当这个变量的值为零的时候,表示最近一次执行了一次删除操作,当这个变量的值为一的时候,表示最近执行过一次插入操作。
那不难理解,只有删除操作才有可能导致队列变空,只有插入操作才有可能导致队列变满。来看左边这个例子,此时还剩最后一个空闲的空间,那不管tag的值此时是多少,只要我们往这个地方插入一个新的数据元素。这个插入操作成功之后,我们都需要把tag的值把它设置为一,并且让rear指针往后移一位。那这种情况下,队头指针和队尾指针指向同一个位置,是由于插入操作导致的,因此肯定是队列已满的情况。
再看右边这个例子,此时队列中还有最后一个数据元素,那无论此时tag的值是多少,只要我们删除了这个数据元素之后,都肯定需要把tag的值设置为零,那在这种情况下,头指针和尾指针指向同一个位置,是由于删除操作而导致的,因此此时肯定是队列为空的情况。好,所以虽然队列为空和队列为满的时候都是队头队尾指向同一个位置,但是由于我们用tag这个变量来标记最近我们到底是执行了删除操作,还是插入操作?因此,结合tag变量的值,我们就可以判断出此时到底是队空还是队满。好,那这是第三种实现方案,我们同样没有浪费任何的存储空间。
2.4 其他出题方式

好,那到目前为止,我们讲的所有的这些方法都是基于队尾指针,指向队尾元素的下一个位置,这样的一个前提条件进行的,那在考试中也有可能遇到对尾指针,是指向对尾元素这样的情况。那这种情况呢?代码实现又会有一些些的不同,
比如在入队的时候,右边这种情况,我们需要先让队尾指针往后移一位。也就指向这个位置,然后再往这个位置当中写入新的数据元素x。所以考试的时候一定要注意审题啊,这个队尾指针它到底是指向什么位置?除了入队操作之外,当我们采用右边的这种设计方式的时候。在进行队列初始化的时候,也需要进行一些调整。由于每一次新元素入队,都是先让队尾指针先往后移,然后再往里面插入数据元素。所以我们在初始化的时候啊,比较合理的方式是可以让front指针指向零这个位置,让rear指针指向n- 1这个位置。这样的话,插入第一个数据元素的时候,就会先让rear指针先往后移一位,也就指向这个位置,然后再往这个位置插入新的数据元素x。所以你看这种初始化的方式,可能就是大家不太容易想到的,就可能不太符合我们的直觉好,那采用这种设计方式的话,如果要判断队列是否为空,我们就需要判断。队尾指针的下一个位置是不是队头好,再来看怎么判断队列已满好,那和之前讲的类似,


如果我们让所有的地方都填满数据元素的话。那这种情况下,我们就没办法通过头指针和尾指针的这种位置关系来判断这个队列到底是满还是空了。那处理方法和之前一样,我们可以规定头指针前面的这个存储单元不可以存放数据元素,那就意味着尾指针最多只有可能指向这个位置。这样的话,在队满和队空的时候,这两个指针之间的这种相对位置关系是不是就会呈现出两种状态?如果头指针在尾指针后一个位置的话,那就意味着此时队列是空的,而如果头指针是在尾指针后面的两个位置,那就说明此时队列是满的。所以我们可以通过牺牲一个存储单元来区分这个对空和对满的情况,当然我们同样也可以像刚才一样,
就是增加一个辅助变量。就是增加一个size变量,或者一个tag变量,这两种方法都OK的,这就不再展开好

那这个小节当中我们学习了,如何用顺序存储的方式来实现队列?那由于静态数组的容量是有限的,所以我们必须使用模运算,或者说取余运算来重复的利用静态数组当中的呃,各个空闲的存储空间。这个小节很容易在选择题中进行考察,需要注意这样的两个方面,首先你要注意对尾指针,它到底是指向了对尾元素的后一个位置。还是说它就是指向了对尾元素,另外还需要注意题目给的条件到底是怎么判断,队列空和队列满的。可以牺牲一个存储单元来区分空和满的两种状态,当然也可以增加一个辅助变量来标记这个队列空和满的状态。那刚才我们详细介绍了让对尾指针指向这个对尾元素后一个位置,同时我们牺牲一个存储单元来区分对空和对满的情况。在这种情况下,这个初始化入队出队怎么实现?还有怎么判空怎么判满怎么计算队列长度?这些问题我们在刚才都已经详细的啊谈过。那大家可以暂停思考一下,如果说让这个对尾指针指向对尾元素,同时我们采用的是增加一个size变量来记录队列长度。如果采用这样的策略的话,
那么这些基本操作又应该怎么实现呢?把这几种情况想明白了,那基本上这个小节的考题没有任何可以难得住大家的。所以可以暂停来思考一下,好的,那么以上就是这个小节的全部内容。











相关文章:
数据结构day04
一 栈 1栈的基本概念 各位同学大家好,从这个小节开始,我们会正式进入第三章的学习,我们会学习栈和队列,那这个小节中我们会先认识栈的基本概念。我们会从栈的定义和栈的基本操作来认识栈这种数据结构,也就是要探讨栈的…...

质量工程:数字化转型时代的质量体系重构
前言:质量理念的范式转移阅读原文 如果把软件开发比作建造摩天大楼: 传统测试 竣工后检查裂缝(高成本返工) 质量工程 从地基开始的全流程监理体系(设计图纸→施工工艺→建材选择→竣工验收) IEEE研究…...
)
数据结构C语言练习(单双链表)
本篇练习题(单链表): 1.力扣 203. 移除链表元素 2.力扣 206. 反转链表 3.力扣 876. 链表的中间结点 4.力扣 21. 合并两个有序链表 5. 牛客 链表分割算法详解 6.牛客 链表回文结构判断 7. 力扣 160. 相交链表 8. 力扣 141 环形链表 9. 力扣 142 环形链表 II…...
)
QScreen 捕获屏幕(截图)
一、QScreen核心能力解析 硬件信息获取 // 获取主屏幕对象 QScreen* primaryScreen QGuiApplication::primaryScreen();// 输出屏幕参数 qDebug() << "分辨率:" << primaryScreen->size(); qDebug() << "物理尺寸:" << primar…...

pyQt学习笔记——Qt资源文件(.qrc)的创建与使用
Qt资源文件(.qrc)的创建与使用 1. 选择打开资源2. 创建新资源3. 添加资源文件夹4. 选择要加载的图片文件5. 编译resource.qrc文件6. 替换PySlide6为PyQt57. 其他说明 1. 选择打开资源 在Qt项目中,可以通过windowIcon点击选择打开资源。 2. 创…...

优雅的开始一个Python项目
优雅的开始一个Python项目 这是我在初始化一个Python项目时,一键生成的项目文件。它自动完成了git初始化、环境管理、日志模块这三件事情,并在最后进入了虚拟环境。 uv安装 uv是一个现代的Python包管理和项目管理工具。uv中文文档 安装uv: # unix: …...

[学成在线]07-视频转码
视频转码 视频上传成功后需要对视频进行转码处理。 首先我们要分清文件格式和编码格式: 文件格式:是指.mp4、.avi、.rmvb等这些不同扩展名的视频文件的文件格式 ,视频文件的内容主要包括视频和音频,其文件格式是按照一定的编码…...

qt+opengl 加载三维obj文件
1前面我们已经熟悉了opengl自定义顶点生成一个立方体,并且我们实现了立方体的旋转,光照等功能。下面我们来用opengl来加载一个obj文件。准备我们首先准备一个简单的obj文件(head.obj)。资源在本页下载 2 在obj文件里面,…...

一个简单的用C#实现的分布式雪花ID算法
雪花ID是一个依赖时间戳根据算法生成的一个Int64的数字ID,一般用来做主键或者订单号等。以下是一个用C#写的雪花ID的简单实现方法 using System; using System.Collections.Concurrent; using System.Diagnostics;public class SnowflakeIdGenerator {// 配置常量p…...

【实战ES】实战 Elasticsearch:快速上手与深度实践-2.2.1 Bulk API的正确使用与错误处理
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 Elasticsearch Bulk API 深度实践:性能调优与容错设计1. Bulk API 核心机制解析1.1 批量写入原理剖析1.1.1 各阶段性能瓶颈 2. 高性能批量写入实践2.1 客户端最佳…...

鸿蒙Flutter开发故事:不,你不需要鸿蒙化
在华为牵头下,Flutter 鸿蒙化如火如荼进行,当第一次看到一份上百个插件的Excel 列表时,我也感到震惊,排名前 100 的插件赫然在列,这无疑是一次大规模的军团作战。 然后,参战团队鱼龙混杂,难免有…...

中间件框架漏洞攻略
中间件(英语:Middleware)是提供系统软件和应⽤软件之间连接的软件,以便于软件各部件之间的沟通。 中间件处在操作系统和更⾼⼀级应⽤程序之间。他充当的功能是:将应⽤程序运⾏环境与操作系统隔离,从⽽实…...

第21周:RestNet-50算法实践
目录 前言 理论知识 1.CNN算法发展 2.-残差网络的由来 一、导入数据 二、数据处理 四、编译 五、模型评估 六、总结 前言 🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 理论知识 1.CNN算法发展 该图列举出…...

构建大语言模型应用:数据准备(第二部分)
本专栏通过检索增强生成(RAG)应用的视角来学习大语言模型(LLM)。 本系列文章 简介数据准备(本文)句子转换器向量数据库搜索与检索大语言模型开源检索增强生成评估大语言模型服务高级检索增强生成 RAG 如上…...

AI-Sphere-Butler之Ubuntu服务器如何部署Nginx代理,并将HTTP升级成HTTPS,用于移动设备访问
环境: AI-Sphere-Butler WSL2 Ubuntu22.04 Nginx 问题描述: AI-Sphere-Butler之Ubuntu服务器如何部署Nginx代理,并将HTTP升级成HTTPS,用于移动设备访问 解决方案: 一、生成加密证书 1.配置OpenSSL生成本地不加…...

飞致云荣获“Alibaba Cloud Linux最佳AI镜像服务商”称号
2025年3月24日,阿里云云市场联合龙蜥社区发布“2024年度Alibaba Cloud Linux最佳AI镜像服务商”评选结果。 经过主办方的严格考量,飞致云(即杭州飞致云信息科技有限公司)凭借旗下MaxKB开源知识库问答系统、1Panel开源面板、Halo开…...

Django项目之订单管理part6(message组件和组合搜索组件)
一.前言 我们前面讲的差不多了,接着上节课讲,今天要来做一个撤单要求,我们可以用ajax请求,但是我这里介绍最后一个知识点,message组件,但是我会把两种方式都讲出来的,讲完这个就开始讲我们最重…...

Taro创建微信小程序项目 第一步搭建项目
1.node: 2.第一步: 安装taro npm install -g tarojs/cli 3.创建文件夹wxxcx, 创建demos的文件夹的项目(demos项目名称) taro init demos 出现以下信息:可以根据自己的需求选择 出现安装项目依赖失败不要紧 4.进入demos文件夹…...

S32K144外设实验(六):FTM输出单路PWM
文章目录 1. 概述1.1 时钟系统1.2 实验目的2. 代码的配置2.1 时钟配置2.2 FTM模块配置2.3 输出引脚配置2.4 API函数调用1. 概述 1.1 时钟系统 FTM的CPU接口时钟为SYS_CLK,在RUN模式下最高80MHz。模块的时钟结构如下图所示。 从上图中可以看出,FTM模块的功能时钟为SYS_CLK,…...

前端工程化开篇
前端发展史梳理: 最早的html,css,js是前端三剑客,足以实现所有的前端开发任务,但是呢,一个简单的前端交互效果可能就需要一大堆的代码去实现。 后来呢,有了前端库jQuery,他可以使前…...

地下管线三维建模软件工具MagicPipe3D V3.6.1
经纬管网建模系统MagicPipe3D,基于二维矢量管线管点数据本地离线参数化构建地下管网三维模型(包括管道、接头、附属设施等),输出标准3DTiles、Obj模型等格式,支持Cesium、Unreal、Unity、Osg等引擎加载进行三维可视化、…...

iOS自定义collection view的page size(width/height)分页效果
前言 想必大家工作中或多或少会遇到下图样式的UI需求吧 像这种cell长度不固定,并且还能实现的分页效果UI还是很常见的 实现 我们这里实现主要采用collection view,实现的方式是自定义一个UICollectionViewFlowLayout的子类,在这个类里对…...

以科技赋能,炫我云渲染受邀参加中关村文化科技融合影视精品创作研讨会!
在文化与科技深度融合的时代浪潮下,影视创作行业经历着前所未有的变革。影视创作行业发展态势迅猛, 同时也面临着诸多挑战。为促进影视创作行业的创新发展,加强业内交流与合作, 3月25日下午,海淀区文化创意产业协会举办…...

华为、浪潮、华三链路聚合概述
1、华为 链路聚合可以提高链路带宽和链路冗余性。有三种类型,分别是手工链路聚合,静态lacp链路聚合,动态lacp链路聚合。 手工链路模式:也称负载分担模式,需手动指定链路,各链路之间平均分担流量。静态LAC…...
介绍)
Android 蓝牙/Wi-Fi通信协议之:经典蓝牙(BT 2.1/3.0+)介绍
在 Android 开发中,经典蓝牙(BT 2.1/3.0)支持多种协议,其中 RFCOMM/SPP(串口通信)、A2DP(音频流传输)和 HFP(免提通话)是最常用的。以下是它们在 Android 中的…...

【go微服务】Golang微服务之基--rpc的实现原理以及应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

Redis的List类型
Redis的List类型 一.List类型简单介绍 二.List的常用命令1.LPUSH2.LRANGE3.LPUSHX4.RPUSH5.RPUSHX6.LPOP7.RPOP8.LINDEX9.LINSERT10.LLEN11.LREM12.LTRIM13.LSET 三.阻塞命令1.BRPOP(i)针对不是空的列表进行操作:(ii)针…...
【C语言】分支与循环(下)
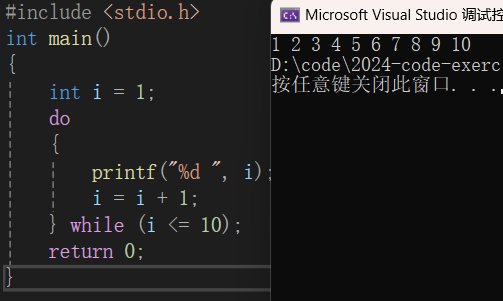
前言:小飞在(上)篇总结了分支结构的内容,本文接上,总结循环结构的知识。 看完觉得有帮助的话记得点赞收藏加关注哦~ 目录 一、while循环 二、for循环 三、do-while循环 四、循环中的break和continue 五、循环结构…...

Android 中两个 APK 之间切换的几中方法
在 Android 中,两个 APK(应用程序)之间的切换通常是通过 Intent 来实现的。以下是一些常见的方法和注意事项,帮助你实现两个 APK 之间的切换。 一、启动目标 APK 的主 Activity 1、setPackage 方法 使用 Intent 的 setPackage …...

SpringBoot集成腾讯云OCR实现身份证识别
OCR身份证识别 官网地址:https://cloud.tencent.com/document/product/866/33524 身份信息认证(二要素核验) 官网地址:https://cloud.tencent.com/document/product/1007/33188 代码实现 引入依赖 <dependency><…...