搜广推校招面经六十一
美团推荐算法
一、ANN算法了解么?说几种你了解的ANN算法
ANN 近似最近邻搜索(Approximate Nearest Neighbor Search)算法
1.1. KD-Tree(K-Dimensional Tree,K 维树)
- 类型: 空间划分数据结构
- 适用场景: 低维数据(通常小于 20 维)
- 原理:
- 递归地选择某个维度的中位数进行划分,构造二叉树
- 查询时回溯遍历最近邻点
- 优缺点:
- 适用于 低维欧几里得空间搜索
- 在 高维数据(>20 维) 下效率急剧下降(维度灾难)
1.2. LSH(局部敏感哈希,Locality-Sensitive Hashing)
- 类型: 基于哈希的近似最近邻搜索
- 适用场景: 高维数据、文本检索、推荐系统、图像搜索
- 原理:
- 通过 哈希函数 将相似向量映射到相同的桶
- 通过减少搜索空间,加速最近邻查找
- 经典方法:
- MinHash(Jaccard 相似度,用于集合相似性计算)
- SimHash(海量文本去重,如 Google 使用 SimHash 进行网页去重)
- 优缺点:
- 适用于高维数据,但精度可能不如图搜索(如 HNSW)
1.3. 倒排索引(Inverted Index)
- 类型: 基于索引的搜索方法
- 适用场景: 文本检索(如搜索引擎)、稀疏向量搜索
- 原理:
- 记录 关键词 -> 文档 ID 列表,可快速找到包含查询关键词的所有文档
- 向量检索时可以与 HNSW(Hierarchical Navigable Small World) 结合,提高搜索效率
- 优缺点:
- 适用于离散数据(如文本、关键词),对连续高维向量的搜索能力有限
1.4. HNSW(层次可导航小世界图,Hierarchical Navigable Small World)
- 类型: 基于图的近似最近邻搜索
- 适用场景: 高维向量检索(推荐系统、图像搜索)
- 原理:
- 构建 小世界图(Small World Graph),通过跳跃式邻居搜索快速找到最近邻
- 适用于 高维数据搜索,比 KD-Tree 和 LSH 更快、更精确
- 优缺点:
- 性能远优于 KD-Tree 和 LSH,适用于 超高维数据搜索
- 需要 较大的内存 来存储索引
1.5. FAISS(Facebook AI Similarity Search)
- 类型: 高维向量搜索库
- 适用场景: 图像检索、语音检索、推荐系统
- 原理:
- 支持 PQ(Product Quantization)、IVF(Inverted File Index)、HNSW 等多种索引方法
- 适用于 大规模向量搜索(如 十亿级别的向量数据库)
- 优缺点:
- 大规模向量搜索最优选择
- 需要 GPU 加速才能发挥最大效能
1.6. 推荐工具
- FAISS(Facebook AI): 适用于 GPU 加速的向量搜索
- Annoy(Spotify): 适用于内存受限的情况,构建高效 KD-Tree
- HNSWlib: 纯 C++ 实现的高效 HNSW 近似最近邻搜索
二、推荐算法 vs. 广告算法的区别
推荐算法(Recommendation Algorithm)和广告算法(Advertising Algorithm)在 目标、数据输入、优化目标、应用场景 等方面有较大不同,两者都涉及 个性化推荐 和 用户行为预测
2.1. 核心目标
| 推荐算法 | 广告算法 | |
|---|---|---|
| 核心目标 | 提高用户体验,增加用户粘性,提升内容消费 | 提高广告转化率(CTR、CVR),优化广告收益 |
| 优化目标 | 让用户更喜欢和更长时间停留在平台 | 让广告主的投放 ROI 最大化,提高收益 |
2.2. 算法模型
| 推荐算法 | 广告算法 | |
|---|---|---|
| 主流方法 | 协同过滤(CF)、矩阵分解、深度学习(DNN、Transformer)、强化学习 | 逻辑回归(LR)、GBDT、深度CTR模型(Wide & Deep、DeepFM、Transformer-based CTR) |
| 目标优化 | 召回 + 排序 | 预估 CTR/CVR + 竞价优化 |
| 在线/离线 | 大部分离线训练,部分在线更新 | 在线实时计算,多轮竞价 |
2.3. 核心流程
推荐算法流程
- 召回阶段(候选生成):快速筛选可能感兴趣的内容
- 基于协同过滤、用户兴趣模型、内容相似性等方法
- 粗排阶段:初步排序,过滤低质量内容
- 轻量级模型(如 GBDT、Embedding-based 方法)
- 精排阶段:更复杂的深度学习模型(DNN、Transformer)
- 预测用户点击率、停留时间、互动行为等
- 重排序 & 多目标优化:
- 结合用户体验、平台收益、内容多样性等
广告算法流程
- 广告召回:
- 召回匹配的广告(基于用户历史、关键词、兴趣等)
- CTR/CVR 预估:
- 预测该广告被点击(CTR)和转化(CVR)的概率
- eCPM 计算:
- eCPM = 预估点击率 × 出价
- 计算每个广告对平台的潜在收益
- 广告竞价:
- 竞价策略(如 Vickrey-Clarke-Groves 机制)
- 选择收益最高的广告展示
三、召回模型中的负样本选择:为什么要负采样?
在推荐系统的召回阶段,我们通常使用 监督学习 来训练模型,而监督学习需要 正样本(用户感兴趣的物品) 和 负样本(用户不感兴趣的物品)。由于真实世界中 负样本远多于正样本,因此需要 负采样(Negative Sampling) 来提升训练效率和模型效果。
3.1. 为什么要进行负采样?
3.1.1 计算资源限制
- 真实世界中,未点击的物品数量 远超已点击的物品,直接使用所有未点击的物品作为负样本,会导致 数据量过大,计算成本极高。
- 负采样可以 减少训练数据量,降低计算复杂度,提高训练速度。
3.1.2 训练效果优化
- 如果将 所有未交互的物品 作为负样本,容易导致数据 极度不均衡,模型可能会学习到 “不点击才是常态”,从而忽略正样本信息。
- 通过 合理的负采样策略,可以选取更具代表性的负样本,使模型更准确地学习用户的偏好。
3.1.3 解决数据偏差问题
- 在推荐系统中,用户未点击的内容并不一定是他们不感兴趣的(可能是 未曝光)。
- 直接将所有未点击的物品视为负样本可能会引入噪声,而负采样可以帮助过滤掉这些噪声。
3.2. 常见的负采样方法
3.2.1. 随机负采样(Random Negative Sampling)
- 方法:随机从未交互物品池中选择一定数量的物品作为负样本。
- 优点:简单易实现,计算成本低。
- 缺点:可能采样到无意义的负样本(如用户从未接触过的类别),影响训练效果。
3.2.2. 基于流行度的负采样(Popularity-based Negative Sampling)
- 方法:按照物品的流行度(如点击量、购买量)进行采样,越流行的物品被选中的概率越高。
- 优点:增加热门物品作为负样本,提高模型对流行趋势的学习能力。
- 缺点:可能导致模型偏向推荐热门物品,影响长尾物品的推荐效果。
3.2.3. 硬负采样(Hard Negative Sampling)
- 方法:选择 与用户历史兴趣最相似但未被点击 的物品作为负样本。例如,基于 Embedding 相似度 或 模型预测分数最高但未实际交互 的物品进行采样。
- 优点:
- 负样本质量高,提高模型的判别能力。
- 可以更好地区分 “用户可能感兴趣但未点击” 和 “用户完全不感兴趣” 的内容。
- 缺点:
- 计算成本较高,需要额外的相似度计算或预训练模型。
四、什么是哈利波特效应 和 新闻联播效应
4.1. 哈利波特效应
概念
- “哈利波特效应”(Harry Potter Effect)指的是 头部效应,即 极少数头部内容获得大量关注,而长尾内容则难以被发现。
- 这种现象广泛存在于 图书、电影、音乐、短视频、游戏等文娱产业,表现为 爆款作品 迅速吸引大部分用户的注意力,而其他内容则被冷落。
原因
- 马太效应(强者愈强,弱者愈弱):热门作品的知名度越高,越容易获得额外流量。
- 社交传播效应:热门内容容易被社交媒体讨论和推荐,形成病毒式传播。
- 平台推荐机制:算法倾向于推荐已有较高互动的内容,进一步放大头部效应。
影响
- 头部效应强化:资源和流量向头部内容集中,少量爆款内容占据市场大部分收益。
- 长尾内容难以崛起:中小创作者、独立作品难以获得曝光,导致内容多样性下降。
- 用户兴趣趋同:用户接触的信息可能变得越来越相似,难以发现个性化内容。
典型案例
- 哈利·波特系列图书:全球畅销,形成现象级 IP,而其他同类奇幻小说难以获得类似的市场份额。
- 抖音/B站爆款视频:少数高播放量的视频获得大量推荐和转发,而大部分普通创作者的视频很难出圈。
- 好莱坞电影:MCU(漫威电影宇宙)等超级IP大片持续主导市场,导致小成本电影生存空间缩小。
4.2. 新闻联播效应
概念
- “新闻联播效应”(Xinwen Lianbo Effect)指的是 内容同质化现象,即 所有用户看到的内容高度相似,缺乏多样性。
- 这种效应通常发生在 内容分发平台、社交媒体、搜索引擎等信息流推荐场景,由于算法或政策限制,用户被推送类似的信息,导致视野受限。
原因
- 信息茧房(Filter Bubble):推荐算法基于用户的历史行为,只推送用户“可能感兴趣”的内容,导致信息圈越来越封闭。
- 主流导向:官方或平台出于管理需求,可能会控制信息流,强调特定议题,削弱其他内容的曝光度。
- 算法收敛:推荐系统优化点击率,逐渐收敛到某些最受欢迎的内容,使得不同用户看到的内容趋于一致。
影响
- 用户多样化需求被忽视:用户接触到的信息局限于某一类型,减少了接触不同观点和内容的机会。
- 创新受限:内容创作者可能会趋同于热门话题,减少多样化创作。
- 社会认知固化:大众观点趋同,难以形成多元讨论,可能加剧偏见或误导公众认知。
典型案例
- 短视频平台的推荐机制:如果你刷短视频时喜欢看某类内容(如健身、美食),推荐算法会持续推送类似的视频,导致信息单一化。
- 微博热搜:某些新闻和话题反复出现,而其他可能同样重要的议题被忽视。
- 搜索引擎优化(SEO):搜索引擎根据用户的历史记录调整结果排序,用户可能总是看到相似的信息,而忽略其他观点。
4.3. 主要区别
| 维度 | 哈利波特效应 | 新闻联播效应 |
|---|---|---|
| 核心现象 | 头部内容占据绝大部分流量,长尾内容难以崛起 | 所有人看到的信息趋于相似,内容同质化 |
| 主要影响 | 资源向头部集中,爆款效应加剧,内容多样性受影响 | 信息茧房效应加剧,用户认知受限,创新受阻 |
| 主要原因 | 马太效应、社交传播、平台推荐机制 | 信息茧房、主流导向、算法收敛 |
| 典型案例 | 哈利·波特、抖音爆款视频、漫威电影 | 短视频推荐、微博热搜、SEO个性化搜索 |
五、3. 无重复字符的最长子串(力扣hot100_滑动窗口)

- 思路1:
维护一个tmp_s,遍历s,如果遇到重复字符,将tmp_s中重复字符及其之前的元素都删除。index= list.index(“s”) 就可以得到当前元素在列表中的第一个位置 - 代码:
class Solution:def lengthOfLongestSubstring(self, s: str) -> int:tmp_s = []max_len = 0for i in s:if i not in tmp_s:tmp_s.append(i)max_len = max(max_len, len(tmp_s))else:max_len = max(max_len, len(tmp_s))index = tmp_s.index(i) tmp_s = tmp_s[index+1:]tmp_s.append(i)return max_len
- 思路2:滑动窗口+哈希表
维护一个哈希表,记录每个字符最后出现的索引。遍历s,tmp_s的左边界为max(i.index, 左边界),右边界为当前字符i在s中的位置 - 代码:
class Solution:def lengthOfLongestSubstring(self, s: str) -> int:dic = {}left = -1res = 0for right, s1 in enumerate(s):if s1 in dic: # 出现重复字符left = max(dic[s1], left) # 计算当前重复字符上一个位置和字串的初始位置的最大dic[s1] = rightres = max(res, right-left)return res
相关文章:
搜广推校招面经六十一
美团推荐算法 一、ANN算法了解么?说几种你了解的ANN算法 ANN 近似最近邻搜索(Approximate Nearest Neighbor Search)算法 1.1. KD-Tree(K-Dimensional Tree,K 维树) 类型: 空间划分数据结构适用场景: 低…...

人工智能与软件工程结合的发展趋势
AI与软件工程的结合正在深刻改变软件开发的流程、工具和方法,其发展方向涵盖了从代码生成到系统维护的整个生命周期。以下是主要的发展方向和技术趋势: 1. 软件架构体系的重构 从“面向过程”到“面向目标”的架构转型: AI驱动软件设计以目标…...

nacos 外置mysql数据库操作(docker 环境)
目录 一、外置mysql数据库原因: 二、数据库准备工作 三、构建nacos容器 四、效果展示 一、外置mysql数据库原因: 想知道nacos如何外置mysql数据库之前,我们首先要知道为什么要外置mysql数据库,或者说这样做有什么优点和好处&am…...

动力电池热失控:新能源汽车安全的“隐形火山”如何预防?
一、火山爆发前的征兆:热失控的演化逻辑 在锂离子电池内部,正负极材料与电解液的 “亲密接触” 本是能量转换的基石,但当温度突破 180℃临界点,电解液就像被点燃的火药库。以三元锂电池为例,镍钴锰氧化物在 200℃以上…...

【数电】半导体存储电路
组合逻辑电路输入和输出之间是确定关系,与之前的历史记录没有任何关系。时序逻辑电路则有相应的存储元件,要把之前的状态保存起来。 要构成时序逻辑电路,必须要有相应的存储元件,第五章讲述相应的存储元件 一、半导体存储电路概…...

Jenkins插件安装失败如何解决
问题:安装Jenkins时候出现插件无法安装的情况。 测试环境: 操作系统:Windows11 Jenkins:2.479.3 JDK:17.0.14(21也可以) 解决办法一: 更换当前网络,局域网、移动、联通…...

postman测试文件上传接口详解
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 postman是一个很好的接口测试软件,有时候接口是Get请求方式的,肯定在浏览器都可以测了,不过对于比较规范的RestFul接口&#x…...

什么是贴源库
贴源库的定义与核心概念 贴源库(Operational Data Store, ODS)是数据架构中的基础层,通常作为数据仓库或数据中台的第一层,负责从业务系统直接抽取、存储原始数据,并保持与源系统的高度一致性。其核心在于“贴近源头”…...

UE5中开启ACES工作流程
首先要开启OCIO插件 OpenColorIO 创建配置 下载ACES https://github.com/colour-science/OpenColorIO-Configs/tree/feature/aces-1.2-config 加载ACES的ocio 选择Srgb 选择ACES 参考链接: https://zhuanlan.zhihu.com/p/534357694 https://www.youtube.com/watch?vBo3Bvh…...

数据湖的数据存储与管理策略:构建高效的数据管理框架
数据湖的数据存储与管理策略:构建高效的数据管理框架 在大数据时代,数据湖作为存储和管理海量数据的关键技术,已经成为众多企业数字化转型的重要组成部分。数据湖的核心优势在于其能够支持结构化、半结构化和非结构化数据的存储,然而,随着数据量的增加和复杂度的提升,如…...

Vue学习笔记集--watch
watch 在 Vue 3 的 Composition API 中,watch 和 watchEffect 是用于响应式侦听数据变化的核心 API。它们都能追踪依赖并执行副作用,但在使用方式和场景上有显著差异。以下是详细解析: watch 和 watchEffect 对比 特性watchwatchEffect依赖…...

基于springboot+vue的农产品电商平台
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...

解决Dubbo3调用Springcloud接口报No provider available from registry RegistryDirectory
解决Dubbo调用Springcloud接口报No provider available from registry RegistryDirectory 问题发现问题解决 问题发现 在学习Dubbo过程中,Dubbo官网有一篇文章《微服务最佳实践,零改造实现 Spring Cloud & Apache Dubbo 互通》,跟着示例…...

使用 Avada 主题实现高级表单功能的技术指南
Avada 是 WordPress 上功能最强大的多功能主题之一,其内置的 Avada Builder 和灵活的选项使其非常适合创建高级表单功能。无论是联系表单、注册表单还是复杂的多步骤表单,Avada 都能通过与插件的集成和自定义设计满足多样化需求。本文将详细介绍如何利用…...

2023第十四届蓝桥杯大赛软件赛国赛C/C++ 大学 B 组(真题题解)(C++/Java题解)
本来想刷省赛题呢,结果一不小心刷成国赛了 真是个小迷糊〒▽〒 但,又如何( •̀ ω •́ )✧ 记录刷题的过程、感悟、题解。 希望能帮到,那些与我一同前行的,来自远方的朋友😉 大纲: 一、子2023-ÿ…...

计算机底层基石:原码、反码、补码、移码深度剖析
在计算机的世界里,所有数据最终都以二进制的形式进行存储与运算。原码、反码、补码和移码作为二进制数据的重要编码方式,对计算机实现高效数据处理起着关键作用。接下来,我们将深入剖析这几种编码。 一、原码 1.1 定义 原码是最简单…...

第十四章:JSON和CSV格式详解及Python操作
在数据处理和开发工作中,JSON和CSV是两种非常常见的数据格式。它们各有特点,适用于不同的场景。本文将分别介绍这两种格式的产生原因、应用场景,并结合Python讲解如何操作这两种文件格式,最后用表格总结它们的常用操作及特性。资源…...

双磁条线跟踪控制
1问题 同学反馈小车跟随磁力线,双轮差速小车,左右侧各有2个磁条传感器和各1条磁条线,需要控制小车跟随磁条线轨迹。 2 方法 (1)普通小车可能没有速度反馈,则不考虑转弯半径,仅考虑一个控制关…...
)
【每日算法】Day 12-1:滑动窗口算法精讲——子串/子数组问题的优化利器(C++实现)
攻克子串问题的效率密码!今日深入解析滑动窗口算法的核心思想与实战技巧,覆盖最小覆盖子串、最长无重复子串等高频场景,彻底掌握O(n)时间复杂度的窗口滑动艺术。 一、滑动窗口核心思想 滑动窗口(Sliding Window) 是一…...

树莓派超全系列文档--(7)RaspberryOS播放音频和视频
播放音频和视频 播放音频和视频VLC 媒体播放器vlc GUIvlc CLI使用 cvlc 在没有图形用户界面的情况下播放媒体 在 Raspberry Pi OS Lite 上播放音频和视频指定音频输出设备指定视频输出设备同时指定音频和视频输出设备提高数据流播放性能 文章来源: http://raspberr…...

chrome浏览器下载和Chrome浏览器的跨域设置
Chrome浏览器的跨域设置 下载chrome浏览器设置chrome跨域 下载chrome浏览器 点击官方下载,然后逐步安装即可 设置chrome跨域 1、然后在D盘创建个文件夹命名为ChromeDevSession。 2、右击chrome浏览器选择属性。 3、在目标编辑栏的最后加上:–disabl…...

Android14 SystemUI中添加第三方AIDL
由于特殊需求,需要在SystemUI中添加第三方AIDL,去做一些客制化的修改。现在记录一下AIDL添加的过程。 1.将AIDL文件拷贝到frameworks/base/packages/SystemUI/src/下,我要添加的AIDL文件是com/test/myctr/IDevicectr.aidl,添加后的…...

Appium中元素定位之一组元素定位API
应用场景 和定位一个元素相同,但如果想要批量的获取某个相同特征的元素,使用定位一组元素的方式更加方便 在 Appium 中定位一组元素的 API 与定位单个元素的 API 类似,但它们返回的是一个元素列表(List<MobileElement>&am…...

【高并发内存池】第六弹---深入理解内存管理机制:ThreadCache、CentralCache与PageCache的回收奥秘
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】【C详解】【Linux系统编程】【Linux网络编程】【项目详解】 目录 1、threadcache回收内存 2、centralcache回收内存 3、pagecache回收内存 1、threadcache回收内…...
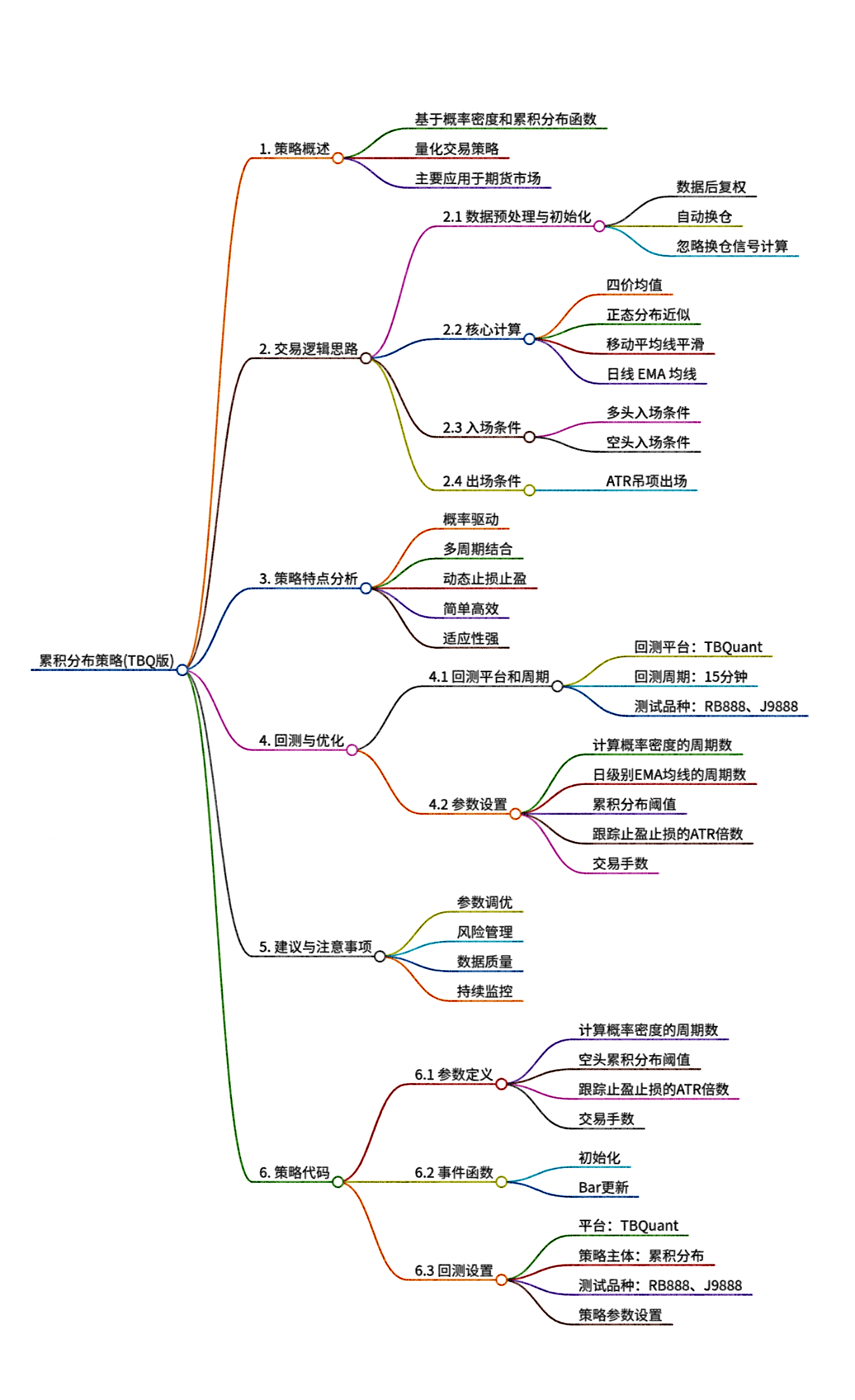
累积分布策略思路
一种基于概率密度和累积分布函数的量化交易策略,主要应用于期货市场。该策略通过计算价格数据的概率密度和累积分布函数(CDF),结合移动平均线和ATR(平均真实范围)等技术指标,实现多空交易的自动…...

【JavaScript】九、JS基础练习
文章目录 1、练习:对象数组的遍历2、练习:猜数字3、练习:生成随机颜色 1、练习:对象数组的遍历 需求:定义多个对象,存数组,遍历数据渲染生成表格 let students [{ name: 小明, age: 18, gend…...

RAG、大模型与智能体的关系
一句话总结: RAG(中文为检索增强生成) 检索技术 LLM 提示。 RAG、大模型与智能体的关系解析 1. 核心概念定义 RAG(检索增强生成) 是一种结合信息检索与生成式模型的框架,通过从外部知识库(如…...

使用firewall-cmd配置SIP端口转发,实现双网卡互通,内外网方式
使用firewall-cmd配置SIP端口转发,实现双网卡,内外网方式 脚本内容 这里以内网IP: 192.168.2.88 这里以外网IP: 10.3.3.3 以下是一个用于启用和停用端口转发的Shell脚本: #!/bin/bash# 配置变量 ZONE"public" TARGET_IP"192.168.2.88" POR…...

Oracle数据库数据编程SQL<3.2 PL/SQL 匿名块中的DML操作、动态SQL、实际应用场景、使用技巧>
匿名块是学习和测试PL/SQL代码的强大工具,特别适合执行一次性任务或快速验证业务逻辑。 目录 一、匿名块中的DML操作 1. INSERT 示例 2. UPDATE 示例 3. DELETE 示例 二、匿名块中的动态SQL 1. EXECUTE IMMEDIATE 2. 动态游标--下篇文章会具体展开详细分享该…...

Spring AI Alibaba 实战:集成 OpenManus 实现智能体应用开发
引言 2024 年 9 月,阿里云正式开源 Spring AI Alibaba,为 Java 开发者提供了一套完整的 AI 应用开发框架,支持与通义系列大模型深度集成,并覆盖了从模型调用到云原生部署的全链路能力。而近期,中国团队发布的通用型 A…...