VectorBT:使用PyTorch+LSTM训练和回测股票模型 进阶二
VectorBT:使用PyTorch+LSTM训练和回测股票模型 进阶二
本方案基于LSTM神经网络构建多时间尺度股票收益率预测模型,结合VectorBT进行策略回测。核心原理是通过不同时间窗口(5/10/20/30日)捕捉股价的短期、中期、长期模式,使用注意力机制融合多尺度特征,最终生成交易信号。
文中内容仅限技术学习与代码实践参考,市场存在不确定性,技术分析需谨慎验证,不构成任何投资建议。适合量化新手建立系统认知,为策略开发打下基础。

本文是进阶指南🚀,推荐先阅读了解基础知识‼️
- VectorBT:Python量化交易策略开发与回测评估详解 🔥
- VectorBT:使用PyTorch+LSTM训练和回测股票模型 进阶一 🔥
一、知识点总结
在A股市场量化中低频交易背景下,单窗口和多窗口滑动各有优劣,以下是两者的总结:
单窗口滑动
- 含义:使用一个固定大小的窗口进行滑动,每次移动一个时间步,利用当前窗口内的数据预测下一个时间步的值。
- 适用场景:
- 短期波动捕捉:A股市场波动较大时,单窗口滑动可以更及时地捕捉到短期变化,快速做出反应。
- 短期套利交易:在短期套利机会中,单窗口滑动能够提供更精准的短期价格信息,帮助交易者迅速判断并采取行动。
- 优缺点:
- 优点:预测结果更准确,能更好地捕捉短期波动和趋势反转;计算成本相对较低,适合高频交易。
- 缺点:对于多步预测,需要多次调用模型,计算成本较高;可能忽略更长时间尺度上的趋势和特征。
多窗口滑动
- 含义:同时使用多个不同大小的窗口进行滑动,从不同时间尺度上提取特征。
- 适用场景:
- 趋势跟踪:在市场呈现出明显趋势时,多窗口滑动能够从不同时间尺度上捕捉到趋势的延续性和稳定性。
- 风险管理:当风险管理是交易的重点时,多窗口滑动可以提供更全面的市场信息,帮助交易者从多个时间维度评估风险。
- 优缺点:
- 优点:能够从不同时间尺度上提取特征,使模型对数据的理解更加全面;可以一次性得到多个预测值,减少模型调用次数,提高效率。
- 缺点:预测的准确性可能不如单窗口滑动,尤其是对于较远的未来值;计算成本较高,适合中低频交易。
综合建议
- 结合使用:在实际应用中,可以考虑结合单窗口和多窗口滑动策略。例如,在市场波动较大时,以单窗口滑动为主,快速捕捉短期机会;在市场趋势明显时,以多窗口滑动为主,把握长期趋势。
- 根据交易目标选择:如果交易目标是短期套利或高频交易,单窗口滑动可能更合适;如果是中低频交易或需要全面的风险管理,多窗口滑动则更具优势。
二、具体实现
1. 方案特点
- 分层特征工程:价格/技术指标/成交量特征分层处理
- 动态特征选择:互信息+随机森林+SFS三级筛选机制
- 多尺度建模:并行LSTM处理不同时间窗口数据
- 自适应策略:波动率调整仓位+动态分位数阈值
架构图
2. 关键步骤讲解
2.1 完整流程
- 数据预处理:对齐时间序列,计算收益率
- 特征工程:生成技术指标+统计特征
- 特征选择:三级筛选保留有效特征
- 数据标准化:分层处理不同特征类型
- 模型训练:多窗口LSTM联合训练
- 策略生成:动态阈值+仓位控制
- 回测验证:VectorBT模拟交易
2.2 序列图
3. 代码实现
3.1 环境设置
import numpy as np # 导入NumPy库,用于数值计算
import optuna # 导入Optuna库,用于超参数优化
import pandas as pd # 导入Pandas库,用于数据处理
import torch # 导入PyTorch库,用于深度学习
import torch.nn as nn # 导入PyTorch的神经网络模块
import torch.optim as optim # 导入PyTorch的优化器模块
import vectorbt as vbt # 导入VectorBT库,用于金融回测
from sklearn.ensemble import ExtraTreesRegressor, RandomForestRegressor # 导入Scikit-Learn的集成回归模型
from sklearn.feature_selection import SequentialFeatureSelector, mutual_info_regression # 导入特征选择工具
from sklearn.preprocessing import MinMaxScaler, RobustScaler # 导入数据预处理工具
from torch.utils.data import DataLoader, Dataset # 导入PyTorch的数据加载工具
from tqdm.auto import tqdm # 导入tqdm库,用于进度条显示print(f"PyTorch版本: {torch.__version__}") # 打印PyTorch版本
print(f"VectorBT版本: {vbt.__version__}") # 打印VectorBT版本vbt.settings.array_wrapper["freq"] = "D" # 设置VectorBT的时间频率为日
vbt.settings.plotting["layout"]["template"] = "vbt_dark" # 设置VectorBT的绘图模板为暗色
vbt.settings.plotting["layout"]["width"] = 1200 # 设置VectorBT绘图宽度为1200
vbt.settings.portfolio["init_cash"] = 100000.0 # 设置初始资金为100000 CNY
vbt.settings.portfolio["fees"] = 0.0025 # 设置交易费用为0.25%
vbt.settings.portfolio["slippage"] = 0.0025 # 设置滑点为0.25%device = torch.device("cuda"if torch.cuda.is_available() # 如果CUDA可用,使用GPUelse "mps" if torch.backends.mps.is_available() # 如果MPS可用,使用MPSelse "cpu" # 否则使用CPU
)3.2 特征工程模块
def feature_engineering(df):"""特征增强与分层处理"""# 基础特征price_features = ["open", "high", "low", "close"] # 价格特征tech_features = ["ma3","ma5","ma10","ma20","ma30","rsi","macd","macdsignal","macdhist","bb_upper","bb_middle","bb_lower","momentum","roc","atr",] # 技术指标特征volume_features = ["vol", "obv"] # 成交量特征# 新增特征(滞后、统计量、技术指标增强)for window in [3, 5, 10, 20, 30]: # 不同窗口大小df[f"return_{window}d"] = df["close"].pct_change(window) # 计算不同窗口的收益率df[f"vol_ma_{window}"] = df["vol"].rolling(window).mean() # 计算成交量的移动平均df[f"close_ma_{window}"] = df["close"].rolling(window).mean() # 计算收盘价的移动平均df["ma5_velocity"] = df["ma5"].pct_change(3) # 计算MA5的速度df["vol_zscore"] = (df["vol"] - df["vol"].rolling(20).mean()) / df["vol"].rolling(20).std() # 计算成交量的Z分数df["range_ratio"] = (df["high"] - df["low"]) / df["close"].shift(1) # 计算波动范围比率df["volume_ma_ratio"] = df["vol"] / df["vol"].rolling(5).mean() # 计算成交量与移动平均的比率df["close_velocity"] = df["close"].pct_change(3) # 计算收盘价的速度df["volatility"] = df["close"].rolling(20).std() / df["close"].rolling(20).mean() # 计算波动率df["price_volume_corr"] = df["close"].rolling(10).corr(df["vol"]) # 计算价格与成交量的相关性# 新增特征分组enhanced_features = ["ma5_velocity","vol_zscore","range_ratio","volume_ma_ratio","close_velocity","volatility","price_volume_corr",]for window in [3, 5, 10, 20, 30]:enhanced_features.extend([f"return_{window}d", f"vol_ma_{window}", f"close_ma_{window}"])# 分层标准化price_scaler = RobustScaler().fit(df[price_features]) # 价格特征的RobustScalertech_scaler = MinMaxScaler().fit(df[tech_features]) # 技术指标特征的MinMaxScalervolume_scaler = MinMaxScaler().fit(df[volume_features]) # 成交量特征的MinMaxScalerenhanced_scaler = RobustScaler().fit(df[enhanced_features]) # 新增特征的RobustScalerprocessed_features = np.hstack([price_scaler.transform(df[price_features]), # 标准化价格特征tech_scaler.transform(df[tech_features]), # 标准化技术指标特征volume_scaler.transform(df[volume_features]), # 标准化成交量特征enhanced_scaler.transform(df[enhanced_features]), # 标准化新增特征])return pd.DataFrame(processed_features, index=df.index) # 返回处理后的特征数据框
3.3 动态特征选择
# %%
# 动态特征选择
def feature_selection(X, y):"""混合特征选择策略"""# 第一阶段:互信息筛选mi_scores = mutual_info_regression(X, y) # 计算每个特征与目标变量的互信息selected = mi_scores > np.quantile(mi_scores, 0.2) # 选择互信息大于0.2分位数的特征X_mi = X[:, selected].astype(np.float32) # 将选择的特征转换为float32类型print(f"[Stage 1] 互信息筛选后特征数: {X_mi.shape[1]}") # 打印筛选后的特征数量# 第二阶段:随机森林重要性rf = RandomForestRegressor(n_estimators=100, n_jobs=-1) # 初始化随机森林回归模型rf.fit(X_mi, y) # 使用选择的特征训练随机森林模型importances = rf.feature_importances_ # 获取特征重要性rf_selected = importances > np.mean(importances) # 选择重要性大于平均值的特征X_rf = X_mi[:, rf_selected].astype(np.float32) # 将选择的特征转换为float32类型print(f"[Stage 2] 随机森林筛选后特征数: {X_rf.shape[1]}") # 打印筛选后的特征数量## 获取筛选后的二维特征矩阵X_selected = X_rf.astype(np.float32) # 将选择的特征转换为float32类型y_tensor = y.astype(np.float32).ravel() # 将目标变量转换为一维数组并转换为float32类型# 第三阶段:使用随机森林进行递归特征消除 SFS/RFE# estimator = RandomForestRegressor(n_estimators=100, n_jobs=-1) # 随机森林回归模型estimator = ExtraTreesRegressor(n_estimators=100, n_jobs=-1) # 初始化ExtraTrees回归模型n_features_to_select = min(12, X_selected.shape[1]) # 选择最多12个特征if n_features_to_select < X_selected.shape[1]: # 如果选择的特征数小于当前特征数sfs = SequentialFeatureSelector(estimator,n_features_to_select=n_features_to_select,direction="forward",scoring="neg_mean_squared_error",n_jobs=-1,) # 初始化顺序特征选择器final_features = sfs.fit_transform(X_selected, y_tensor) # 进行特征选择# rfe = RFE(estimator, n_features_to_select=n_features_to_select) # RFE特征选择器# final_features = rfe.fit_transform(X_selected, y_tensor) # RFE特征选择print(f"[Stage 3] SFS筛选后特征数: {final_features.shape[1]}") # 打印筛选后的特征数量else:final_features = X_selected # 如果不需要进一步选择,直接使用当前特征print(f"[Stage 3] SFS未执行,特征数: {final_features.shape[1]}") # 打印特征数量return final_features.astype(np.float32) # 返回最终选择的特征
3.4 多尺度LSTM模型
class MultiScaleLSTM(nn.Module):"""多尺度LSTM模型"""def __init__(self, input_dim, windows=[5, 10, 20, 30], hidden_dim=128):super().__init__() # 调用父类的初始化方法self.lstms = nn.ModuleList([nn.LSTM(input_dim, hidden_dim, batch_first=True) for _ in windows]) # 初始化多个LSTM层,每个窗口一个self.attention = nn.Sequential(nn.Linear(hidden_dim, 16), # 线性层,将隐藏维度映射到16nn.Tanh(), # Tanh激活函数nn.Linear(16, 1), # 线性层,将16映射到1nn.Softmax(dim=1) # Softmax激活函数,用于计算注意力权重)self.fc = nn.Sequential(nn.Linear(len(windows) * hidden_dim, 128), # 全连接层,将多个LSTM输出拼接后映射到128nn.ReLU(), # ReLU激活函数nn.Dropout(0.3), # Dropout层,防止过拟合nn.Linear(128, 1) # 最终全连接层,映射到1)def forward(self, x_multi):"""输入为不同窗口长度的数据列表"""contexts = [] # 存储每个窗口的上下文向量for lstm, x in zip(self.lstms, x_multi): # 遍历每个LSTM和对应的输入数据out, _ = lstm(x) # 前向传播LSTMattn = self.attention(out) # 计算注意力权重context = torch.sum(attn * out, dim=1) # 计算加权后的上下文向量contexts.append(context) # 将上下文向量添加到列表中return self.fc(torch.cat(contexts, dim=1)) # 拼接所有上下文向量并通过全连接层
3.5 数据处理模块
def prepare_data(df):"""数据处理"""# 特征工程df_engineered = feature_engineering(df) # 对输入的DataFrame进行特征工程df_engineered.dropna(inplace=True) # 删除含有NaN值的行# 确保索引对齐X = df_engineered # 将特征工程后的DataFrame赋值给Xy = df.reindex(df_engineered.index)["returns"].values.ravel() # 重新索引并提取返回值# 动态特征选择selected_features = feature_selection(X.values, y) # 对特征进行动态选择# 数据标准化scaler = MinMaxScaler(feature_range=(-1, 1)) # 初始化MinMaxScaler,范围为-1到1scaled_data = scaler.fit_transform(selected_features) # 对选择后的特征进行标准化# 使用固定窗口列表(与MultiScaleLSTM设计一致)fixed_windows = [5, 10, 20, 30] # 定义固定窗口列表# 生成每个窗口的独立序列def create_window_sequences(data, window):sequences = []for i in range(window, len(data)):seq = data[i - window : i] # 提取当前窗口的数据sequences.append(seq) # 将窗口数据添加到序列列表中return np.array(sequences, dtype=np.float32) # 返回numpy数组,确保数据类型为float32# 为每个窗口生成序列X_windows = []for w in fixed_windows:X_win = create_window_sequences(scaled_data, w) # 为每个窗口生成序列X_windows.append(X_win) # 将生成的序列添加到X_windows列表中# 统一样本数量(以最小窗口样本数为准)min_samples = min(len(x) for x in X_windows) # 找出所有窗口中的最小样本数X_windows = [x[-min_samples:] for x in X_windows] # 对齐尾部数据y = y[-min_samples:] # 对齐y标签# 数据分割split = int(0.8 * min_samples) # 计算训练集和测试集的分割点X_train = [x[:split] for x in X_windows] # 分割训练集X_test = [x[split:] for x in X_windows] # 分割测试集y_train, y_test = y[:split], y[split:] # 分割y标签print(f"训练集维度: 窗口7{X_train[0].shape} 窗口14{X_train[1].shape} 窗口30{X_train[2].shape}") # 打印训练集维度信息return (X_train, y_train), (X_test, y_test), scaler # 返回训练集、测试集和缩放器
3.6 自定义多窗口数据集
class MultiWindowDataset(Dataset):"""自定义多窗口数据集"""def __init__(self, X_windows, y):"""初始化多窗口数据集X_windows: 包含多个窗口数据的列表,每个元素形状为 (num_samples, window_size, num_features)y: 标签数据,形状 (num_samples,)"""self.X_windows = [x.astype(np.float32) for x in X_windows] # 显式转换为float32类型self.y = y.astype(np.float32) # 将标签数据转换为float32类型def __len__(self):"""返回数据集的长度"""return len(self.y) # 返回标签数据的长度def __getitem__(self, idx):"""返回一个样本的所有窗口数据和对应标签输出格式:([窗口1数据, 窗口2数据,...], 标签)"""# 获取每个窗口的对应样本数据window_samples = [torch.from_numpy(x[idx]).float() for x in self.X_windows # 明确指定数据类型]label = torch.tensor(self.y[idx], dtype=torch.float32) # 将标签转换为torch张量return window_samples, label # 返回窗口数据和标签
3.6 自定义批处理函数
def collate_fn(batch):"""处理批次数据:输入:batch是包含多个元组的列表,每个元组为 (window_samples, label)输出:([窗口1批次数据, 窗口2批次数据,...], 标签批次)"""# 解压批次数据windows_data, labels = zip(*batch) # 解压批次数据为窗口数据和标签# 重新组织窗口数据维度# 将每个窗口的样本堆叠成 (batch_size, window_size, num_features)transposed_windows = list(zip(*windows_data)) # 转置窗口数据batched_windows = [torch.stack(window_batch, dim=0).float()for window_batch in transposed_windows # 明确指定数据类型]# 堆叠标签 (batch_size,)batched_labels = torch.stack(labels, dim=0).float() # 明确指定数据类型return batched_windows, batched_labels # 返回批量窗口数据和标签
3.7 训练模型
def train_model(config, train_data):"""训练模型"""X_train, y_train = train_data # 解包训练数据# 创建多窗口数据集和数据加载器train_dataset = MultiWindowDataset(X_train, y_train) # 初始化多窗口数据集train_loader = DataLoader(train_dataset,batch_size=config["batch_size"], # 设置批量大小shuffle=True, # 打乱数据collate_fn=collate_fn, # 使用自定义批处理函数drop_last=True, # 丢弃最后一个不完整的批次)# 初始化模型(输入维度从数据中自动获取)input_dim = X_train[0].shape[-1] # 获取特征维度windows = (config["windows"]if isinstance(config["windows"], (list, tuple))else [config["windows"]]) # 确保窗口是一个列表或元组hidden_dim = config["hidden_dim"] # 获取隐藏层维度model = MultiScaleLSTM(input_dim=input_dim, windows=windows, hidden_dim=hidden_dim).to(device) # 初始化多尺度LSTM模型并移动到指定设备# 配置优化器optimizer = optim.AdamW(model.parameters(), lr=config["lr"], weight_decay=config["weight_decay"]) # 使用AdamW优化器scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100) # 使用余弦退火学习率调度器criterion = nn.HuberLoss() # 使用Huber损失函数# 训练循环for epoch in tqdm(range(config["epochs"]), desc="Training"): # 进行多个epoch的训练model.train() # 将模型设置为训练模式for X_batch, y_batch in train_loader: # 遍历每个批次# 将每个窗口的数据移动到设备X_batch = [x.to(device) for x in X_batch] # 将每个窗口的数据移动到指定设备y_batch = y_batch.to(device).unsqueeze(1) # 将标签数据移动到指定设备并增加一个维度optimizer.zero_grad() # 清零梯度preds = model(X_batch) # 前向传播loss = criterion(preds, y_batch) # 计算损失loss.backward() # 反向传播nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 梯度裁剪optimizer.step() # 更新参数scheduler.step() # 更新学习率return model # 返回训练好的模型
3.8 模型评估
def evaluate_model(model, val_data, device):"""评估模型"""X_val, y_val = val_data # 解包验证数据# 创建多窗口数据集和数据加载器val_dataset = MultiWindowDataset(X_val, y_val) # 初始化多窗口数据集val_loader = DataLoader(val_dataset,batch_size=config["batch_size"], # 设置批量大小shuffle=False, # 不打乱数据collate_fn=collate_fn, # 使用自定义批处理函数drop_last=False, # 不丢弃最后一个不完整的批次)model.eval() # 将模型设置为评估模式criterion = nn.HuberLoss() # 使用Huber损失函数total_loss = 0.0 # 初始化总损失num_samples = 0 # 初始化样本数量with torch.no_grad(): # 关闭梯度计算for X_batch, y_batch in val_loader: # 遍历每个批次# 将每个窗口的数据移动到设备X_batch = [x.to(device) for x in X_batch] # 将每个窗口的数据移动到指定设备y_batch = y_batch.to(device).unsqueeze(1) # 将标签数据移动到指定设备并增加一个维度preds = model(X_batch) # 前向传播loss = criterion(preds, y_batch) # 计算损失total_loss += loss.item() * len(y_batch) # 累加当前批次的损失num_samples += len(y_batch) # 累加当前批次的样本数量avg_loss = total_loss / num_samples # 计算平均损失return avg_loss # 返回平均损失
3.9 双均线策略
class DualMovingAverageStrategy:"""双均线策略"""def __init__(self, pred_returns, volatility, params):"""初始化双均线策略:param pred_returns: 预测收益率序列:param volatility: 波动率序列:param params: 策略参数字典"""self.pred_returns = pred_returns # 预测收益率序列self.volatility = volatility.clip(lower=0.01) # 波动率序列,防止零波动self.params = params # 策略参数字典def generate_signals(self):"""生成交易信号:return: 交易信号和仓位大小"""# 获取参数short_window = self.params.get("short_window", 5) # 短期窗口,默认5天long_window = self.params.get("long_window", 20) # 长期窗口,默认20天# 计算短期和长期的简单移动平均线short_mavg = self.pred_returns.rolling(window=short_window, min_periods=1).mean() # 短期移动平均线long_mavg = self.pred_returns.rolling(window=long_window, min_periods=1).mean() # 长期移动平均线# 创建一个空的信号序列signals = pd.Series(0, index=self.pred_returns.index)# 当短期均线上穿长期均线时,设置买入信号signals[(short_mavg > long_mavg) & (short_mavg.shift(1) <= long_mavg.shift(1))] = 1# 当短期均线下穿长期均线时,设置卖出信号signals[(short_mavg < long_mavg) & (short_mavg.shift(1) >= long_mavg.shift(1))] = -1# 波动率调整仓位position_size = np.tanh(self.pred_returns.abs() / self.volatility) # 根据预测收益率和波动率计算仓位大小position_size = position_size.clip(0.1, 0.8) # 限制仓位大小在0.1到0.8之间# 打印信号统计信息print("Long Conditions:", (signals == 1).sum()) # 打印买入信号数量print("Short Conditions:", (signals == -1).sum()) # 打印卖出信号数量print("Signals Distribution:\n", signals.value_counts()) # 打印信号分布return signals, position_size # 返回交易信号和仓位大小
3.10 动态阈值策略
class AdaptiveStrategy:"""动态阈值策略"""def __init__(self, pred_returns, volatility, params):"""初始化动态阈值策略:param pred_returns: 预测收益率序列:param volatility: 波动率序列:param params: 策略参数字典"""self.pred_returns = pred_returns # 预测收益率序列self.volatility = volatility.clip(lower=0.01) # 波动率序列,防止零波动self.params = params # 策略参数字典def generate_signals(self):"""生成交易信号:return: 交易信号和仓位大小"""# 获取参数rolling_window = self.params.get("window", 5) # 滚动窗口,默认5天# 计算动态分位数阈值upper_thresh = self.pred_returns.rolling(rolling_window).quantile(0.7) # 上阈值(70%分位数)lower_thresh = self.pred_returns.rolling(rolling_window).quantile(0.3) # 下阈值(30%分位数)# 波动率调整仓位position_size = np.tanh(self.pred_returns.abs() / self.volatility) # 根据预测收益率和波动率计算仓位大小position_size = position_size.clip(0.1, 0.8) # 限制仓位大小在0.1到0.8之间# 生成信号long_cond = (self.pred_returns > upper_thresh) & (position_size > 0.2) # 买入条件short_cond = (self.pred_returns < lower_thresh) & (position_size > 0.2) # 卖出条件# 创建一个空的信号序列signals = pd.Series(0, index=self.pred_returns.index)# 设置买入信号signals[long_cond] = 1# 设置卖出信号signals[short_cond] = -1# 打印信号统计信息print("Long Conditions:", long_cond.sum()) # 打印买入信号数量print("Short Conditions:", short_cond.sum()) # 打印卖出信号数量print("Signals Distribution:\n", signals.value_counts()) # 打印信号分布return signals, position_size # 返回交易信号和仓位大小
3.11 回测引擎
def backtest_strategy(model, test_data, scaler, df):"""回测引擎"""X_test, y_test = test_data # 分解测试数据# 生成预测model.eval() # 将模型设置为评估模式with torch.no_grad(): # 禁用梯度计算test_tensor = [torch.FloatTensor(x).to(device) for x in X_test] # 将测试数据转换为Tensor并移动到设备preds = model(test_tensor).cpu().numpy().flatten() # 生成预测值并转换为NumPy数组# 对齐时间索引test_dates = df.index[-len(preds) :] # 获取与预测值对齐的时间索引result_df = pd.DataFrame({"close": df["close"].values[-len(preds) :], # 闭盘价"pred_returns": preds.flatten(), # 预测收益率"volatility": df["atr"].values[-len(preds) :] / df["close"].values[-len(preds) :], # 波动率},index=test_dates,)# 检查预测值分布print("Predicted Returns Stats:", result_df["pred_returns"].describe()) # 打印预测收益率统计信息print("Predicted Returns Mean:", result_df["pred_returns"].mean()) # 打印预测收益率均值print("Predicted Returns Max/Min:",result_df["pred_returns"].max(),result_df["pred_returns"].min(),) # 打印预测收益率最大值和最小值# 检查波动率计算异常print("Volatility Stats:", result_df["volatility"].describe()) # 打印波动率统计信息# 动态阈值策略# strategy = AdaptiveStrategy(# pred_returns=result_df["pred_returns"],# volatility=result_df["volatility"],# params={"window": 14},# )# 双均线策略strategy = DualMovingAverageStrategy(pred_returns=result_df["pred_returns"], # 预测收益率volatility=result_df["volatility"], # 波动率params={"short_window": 5, "long_window": 20}, # 策略参数)# 生成信号signals, position_size = strategy.generate_signals() # 生成交易信号和仓位大小# 构建投资组合pf = vbt.Portfolio.from_signals(close=result_df["close"], # 闭盘价entries=signals == 1, # 买入信号exits=signals == -1, # 卖出信号size=position_size.abs(), # 仓位大小size_type="percent", # 仓位类型(百分比)freq="D", # 时间频率(日)# 增强参数accumulate=False, # 禁止累积仓位log=True, # 记录交易日志call_seq="auto", # 自动处理订单顺序)return pf, result_df # 返回投资组合对象和结果DataFrame
3.12 主程序运行
# 示例数据加载
# 选择要加载的股票代码
ts_code = "600000.SH" # 浦发银行(600000.SH)# 读取处理后的Parquet文件
df = pd.read_parquet(f"./data/processed_{ts_code}.parquet")# 检查 close 列的数据类型是否为数值型
print(df["close"].dtype) # 应为 float64 或 int64# 检查 close 列是否有缺失值
print(df["close"].isna().sum()) # 应为 0# 将 trade_date 列转换为 datetime 类型
df["trade_date"] = pd.to_datetime(df["trade_date"], format="%Y%m%d")# 将 trade_date 列设置为索引
df.set_index("trade_date", inplace=True)# 计算每日收益率,并将结果向前移动一天
df["returns"] = df["close"].pct_change().shift(-1)# 删除所有包含 NaN 的行
df.dropna(inplace=True)# 数据准备
train_data, test_data, scaler = prepare_data(df) # 调用prepare_data函数进行数据准备# Optuna超参优化
def objective(trial):"""定义Optuna的优化目标函数"""config = {"hidden_dim": trial.suggest_int("hidden_dim", 64, 256), # 建议隐藏层维度在64到256之间"windows": trial.suggest_categorical("windows", [5, 10, 20, 30]), # 建议窗口大小"lr": trial.suggest_float("lr", 1e-4, 1e-3, log=True), # 建议学习率在1e-4到1e-3之间(对数尺度)"batch_size": trial.suggest_categorical("batch_size", [32, 64, 128]), # 建议批量大小"weight_decay": trial.suggest_float("weight_decay", 1e-6, 1e-4), # 建议权重衰减在1e-6到1e-4之间"epochs": 100, # 固定训练轮数为100}model = train_model(config, train_data) # 训练模型val_loss = evaluate_model(model, test_data) # 评估模型return val_loss # 返回验证损失# 创建Optuna研究对象,目标是最小化验证损失
study = optuna.create_study(direction="minimize")
# 运行优化,最多10次试验,显示进度条,超时时间为1小时
study.optimize(objective, n_trials=10, show_progress_bar=True, timeout=3600)# 最佳模型回测
best_config = study.best_params # 获取最佳参数
best_config["epochs"] = 100 # 设置训练轮数为100
best_model = train_model(best_config, train_data) # 使用最佳参数训练模型# 训练完成后保存模型和参数
model_path = "./models/pytorch_lstm_model.pth" # 模型保存路径
torch.save({"model_state_dict": best_model.state_dict(), # 保存模型状态字典"scaler": scaler, # 保存特征缩放器**best_config, # 保存最佳配置},model_path,
)
print(f"PyTorch LSTM model and parameters saved to {model_path}") # 打印保存路径# 加载最佳模型
checkpoint = torch.load( # 加载模型检查点"./models/pytorch_lstm_model.pth", weights_only=False, map_location=device
)X_train, y_train = train_data # 获取训练数据# 确保 windows 是一个列表或元组
windows = checkpoint.get("windows", [5, 10, 20, 30]) # 获取窗口大小
if not isinstance(windows, (list, tuple)):windows = [windows] # 如果不是列表或元组,则转换为列表
hidden_dim = checkpoint["hidden_dim"] # 获取隐藏层维度# 初始化多尺度LSTM模型
best_model = MultiScaleLSTM(input_dim=X_train[0].shape[-1], windows=windows, hidden_dim=hidden_dim
).to(device)
best_model.load_state_dict(checkpoint["model_state_dict"]) # 加载模型状态字典# 回测
pf, result_df = backtest_strategy(best_model, test_data, scaler, df) # 进行回测# 绩效分析
print(pf.stats()) # 打印投资组合统计信息
pf.plot().show() # 显示投资组合图表# 可视化结果
import plotly.graph_objects as go
from plotly.subplots import make_subplotsfig = make_subplots(specs=[[{"secondary_y": True}]])# 主坐标轴(价格)
fig.add_trace(go.Scatter(x=result_df.index, # 时间索引y=result_df["close"], # 实际价格name="Actual Price", # 图例名称),secondary_y=False, # 主坐标轴
)# 次坐标轴(收益率)
fig.add_trace(go.Bar(x=result_df.index, # 时间索引y=result_df["pred_returns"], # 预测收益率name="Predicted Returns", # 图例名称marker=dict(opacity=0.8), # 设置柱状图透明度width=86400000, # 设置柱宽为1天(毫秒单位)),secondary_y=True, # 次坐标轴
)# 设置布局
fig.update_layout(title="Price vs Predicted Returns", # 图表标题template="vbt_dark", # 使用vbt_dark模板legend=dict(orientation="h", yanchor="bottom", y=1.02), # 图例设置hovermode="x unified", # 悬停模式width=800, # 图表宽度
)# 设置坐标轴标签
fig.update_yaxes(title_text="Price", secondary_y=False, showgrid=False, tickprefix="¥") # 主坐标轴标签
fig.update_yaxes(title_text="Returns", secondary_y=True, showgrid=False, tickformat=".2%" # 次坐标轴标签
)fig.show() # 显示图表
4. 关键类和函数说明
类
MultiScaleLSTM
- 描述: 多尺度LSTM模型,用于处理不同窗口长度的数据。
- 参数:
input_dim: 输入特征的维度。windows: 不同窗口长度的列表,默认为[5, 10, 20, 30]。hidden_dim: LSTM隐藏层的维度,默认为128。
- 方法:
forward(x_multi): 前向传播函数,输入为不同窗口长度的数据列表。
MultiWindowDataset
- 描述: 自定义多窗口数据集类,用于生成多窗口数据。
- 参数:
X_windows: 包含多个窗口数据的列表,每个元素形状为(num_samples, window_size, num_features)。y: 标签数据,形状为(num_samples,)。
- 方法:
__len__(): 返回数据集的长度。__getitem__(idx): 返回一个样本的所有窗口数据和对应标签。
DualMovingAverageStrategy
- 描述: 双均线策略类,用于生成交易信号。
- 参数:
pred_returns: 预测收益率。volatility: 波动率。params: 策略参数字典,包含短期和长期窗口长度。
- 方法:
generate_signals(): 生成买卖信号和仓位大小。
AdaptiveStrategy
- 描述: 动态阈值策略类,用于生成交易信号。
- 参数:
pred_returns: 预测收益率。volatility: 波动率。params: 策略参数字典,包含滚动窗口长度。
- 方法:
generate_signals(): 生成买卖信号和仓位大小。
函数
feature_engineering(df)
- 描述: 特征工程模块,对输入数据进行特征增强和分层处理。
- 参数:
df: 输入的DataFrame数据。
- 返回值: 处理后的特征数据。
feature_selection(X, y)
- 描述: 动态特征选择策略,通过互信息、随机森林重要性和递归特征消除进行特征选择。
- 参数:
X: 输入特征矩阵。y: 目标变量。
- 返回值: 选择后的特征矩阵。
prepare_data(df)
- 描述: 数据处理模块,包括特征工程、特征选择、数据标准化和生成多窗口序列。
- 参数:
df: 输入的DataFrame数据。
- 返回值: 训练数据、测试数据和特征缩放器。
collate_fn(batch)
- 描述: 自定义批处理函数,用于处理多窗口数据集的批次数据。
- 参数:
batch: 包含多个元组的列表,每个元组为(window_samples, label)。
- 返回值: 批次窗口数据和标签。
train_model(config, train_data)
- 描述: 训练多尺度LSTM模型。
- 参数:
config: 模型配置字典,包含超参数。train_data: 训练数据。
- 返回值: 训练好的模型。
evaluate_model(model, val_data)
- 描述: 评估多尺度LSTM模型。
- 参数:
model: 待评估的模型。val_data: 验证数据。
- 返回值: 验证损失。
backtest_strategy(model, test_data, scaler, df)
- 描述: 回测引擎,使用训练好的模型进行回测。
- 参数:
model: 训练好的模型。test_data: 测试数据。scaler: 特征缩放器。df: 原始数据。
- 返回值: 回测结果和预测数据。
5. 优化建议
| 方向 | 具体措施 |
|---|---|
| 特征工程 | 增加行业因子/市场情绪指标 |
| 模型结构 | 引入Transformer替代LSTM |
| 策略优化 | 加入止损机制和仓位再平衡 |
| 计算优化 | 实现增量训练和在线学习 |
风险提示与免责声明
本文内容基于公开信息研究整理,不构成任何形式的投资建议。历史表现不应作为未来收益保证,市场存在不可预见的波动风险。投资者需结合自身财务状况及风险承受能力独立决策,并自行承担交易结果。作者及发布方不对任何依据本文操作导致的损失承担法律责任。市场有风险,投资须谨慎。
相关文章:
VectorBT:使用PyTorch+LSTM训练和回测股票模型 进阶二
VectorBT:使用PyTorchLSTM训练和回测股票模型 进阶二 本方案基于LSTM神经网络构建多时间尺度股票收益率预测模型,结合VectorBT进行策略回测。核心原理是通过不同时间窗口(5/10/20/30日)捕捉股价的短期、中期、长期模式,…...

蓝桥杯 第十二天 819 递增序列
注意注意:不考虑左上的情况,因为题目给的样例没有 public static int is1(char ch[][],int m,int n){int ans0;for (int i0;i<m;i){//起始点在哪for (int j0;j<n;j){int add1;while(jadd<n){if(ch[i][j]<ch[i][jadd]) ans; //横add;}add1…...
与陷阱(内存泄漏))
ThreadLocal 的妙用(线程隔离)与陷阱(内存泄漏)
前言 在Java开发中,线程安全是一个高频关键词。当我们使用多线程处理共享数据时,常常需要加锁或使用同步机制来避免数据混乱。但有一把“锁”却能让每个线程拥有自己的独立数据副本,它就是ThreadLocal。接下来通过实际案例,带你理…...

【YOLOv11】目标检测任务-实操过程
目录 一、torch环境安装1.1 创建虚拟环境1.2 启动虚拟环境1.3 安装pytorch1.4 验证cuda是否可用 二、yolo模型推理2.1 下载yolo模型2.2 创建模型推理文件2.3 推理结果保存路径 三、labelimg数据标注3.1 安装labelimg3.2 解决浮点数报错3.3 labelimg UI界面介绍3.4 数据标注案例…...

C++_STL之vector篇
一、vector的常见用法 注:C中若使用vector需包含头文件<vector>. 1.vector的构造函数 int n 10,ret1;vector<int> nums(n,ret); //n表示vector初始的容量 ret表示vector中初始化的值for (auto e : nums)cout << e << " "; 扩展…...

Imgui处理glfw的鼠标键盘的方法
在Imgui初始化时,会重新接手glfw的键盘鼠标事件。也就是遇到glfw的键盘鼠标事件时,imgui先会运行自己的处理过程,然后再去处理用户自己注册的glfw的键盘鼠标事件。 看imgui_impl_glfw.cpp源码的安装回调函数部分代码 void ImGui_ImplGlfw_In…...

【松子悲剧的七层本质】
松子悲剧的七层本质 核心命题:松子的悲剧是人性与社会结构的双重绞杀,本质是“爱的异化”与“自我消解”的终极悖论。 第一层:家庭缺爱的童年烙印 现象:松子因父亲对病弱妹妹的偏爱,长期处于情感匮乏状态,…...
sqli-labs靶场 less 9
文章目录 sqli-labs靶场less 9 时间盲注 sqli-labs靶场 每道题都从以下模板讲解,并且每个步骤都有图片,清晰明了,便于复盘。 sql注入的基本步骤 注入点注入类型 字符型:判断闭合方式 (‘、"、’、“”…...

2-1 MATLAB鮣鱼优化算法ROA优化LSTM超参数回归预测
本博客来源于CSDN机器鱼,未同意任何人转载。 更多内容,欢迎点击本专栏目录,查看更多内容。 目录 0.ROA原理 1.LSTM程序 2.ROA优化LSTM 3.主程序 4.结语 0.ROA原理 具体原理看原文,但是今天咱不用知道具体原理,只…...

fircrawl本地部署
企业内部的网站作为知识库给dify使用,使用fircrawl来爬虫并且转换为markdown。 git clone https://github.com/mendableai/firecrawl.gitcd ./firecrawl/apps/api/ cp .env.example .env cd ~/firecrawl docker compose up -d 官方: https://githu…...

Labview学习记录
1.快捷键 ctrlR 运行 ctrlB 去除断线 ctrlH 即时帮助 ctrlE 前后面板切换 2.画面移动 ctrlshift鼠标左键...

【Golang】第八弹----面向对象编程
🔥 个人主页:星云爱编程 🔥 所属专栏:Golang 🌷追光的人,终会万丈光芒 🎉欢迎大家点赞👍评论📝收藏⭐文章 前言:Go语言面向对象编程说明 Golang也支持面向对…...

java基础以及内存图
java基础 命名: 大驼峰:类名 小驼峰:变量名方法名等其他的 全部大写:常量名字.. // 单行注释 /**/ 多行注释 变量类型 变量名 一、基本类型(8个) 整数:byte-8bit short-16bit int 32-b…...

【嵌入式学习3】TCP服务器客户端 - UDP发送端接收端
目录 1、TCP TCP特点 TCP三次握手(建立TCP连接): TCP四次握手【TCP断开链接的时候需要经过4次确认】: TCP网络程序开发流程 客户端开发:用户设备上的程序 服务器开发:服务器设备上的程序 2、UDP 为…...

Linux之基础知识
目录 一、环境准备 1.1、常规登录 1.2、免密登录 二、Linux基本指令 2.1、ls命令 2.2、pwd命令 2.3、cd命令 2.4、touch命令 2.5、mkdir命令 2.6、rmdir和rm命令 2.7man命令 2.8、cp命令 2.9、mv命令 2.10、cat命令 2.11、echo命令 2.11.1、Ctrl r 快捷键 2…...

llamafactory微调效果与vllm部署效果不一致如何解决
在llamafactory框架训练好模型之后,自测chat时模型效果不错,但是部署到vllm模型上效果却很差 这实际上是因为llamafactory微调时与vllm部署时的对话模板不一致导致的。 对应的llamafactory的代码为 而vllm启动时会采用大模型自己本身设置的对话模板信息…...

Python控制结构详解
前言 一、控制结构概述 二、顺序结构 三、选择结构(分支结构) 1. 单分支 if 2. 双分支 if-else 3. 多分支 if-elif-else 4.实际应用: 四、循环结构 1. for循环 2. while循环 3. 循环控制语句 五、异常处理(try-except)…...
:深度解析Sysbench压测(从入门到MySQL服务器性能验证))
Mysql-经典实战案例(11):深度解析Sysbench压测(从入门到MySQL服务器性能验证)
引言 如何用Sysbench压测满足mysql生产运行的服务器? Sysbench返回的压测结果如何解读? 别急,本文会教大家如何使用并且如何解读压测的结果信息,如何对mysql服务器进行压测! 一、Sysbench核心功能全景解析 1.1 工…...

WebSocket通信的握手阶段
1. 客户端建立连接时,通过 http 发起请求报文,报文表示请求服务器端升级协议为 WebSocket,与普通的 http 请求协议略有区别的部分在于如下的这些协议头: 上述两个字段表示请求服务器端升级协议为 websocket 协议。 2. 服务器端响…...
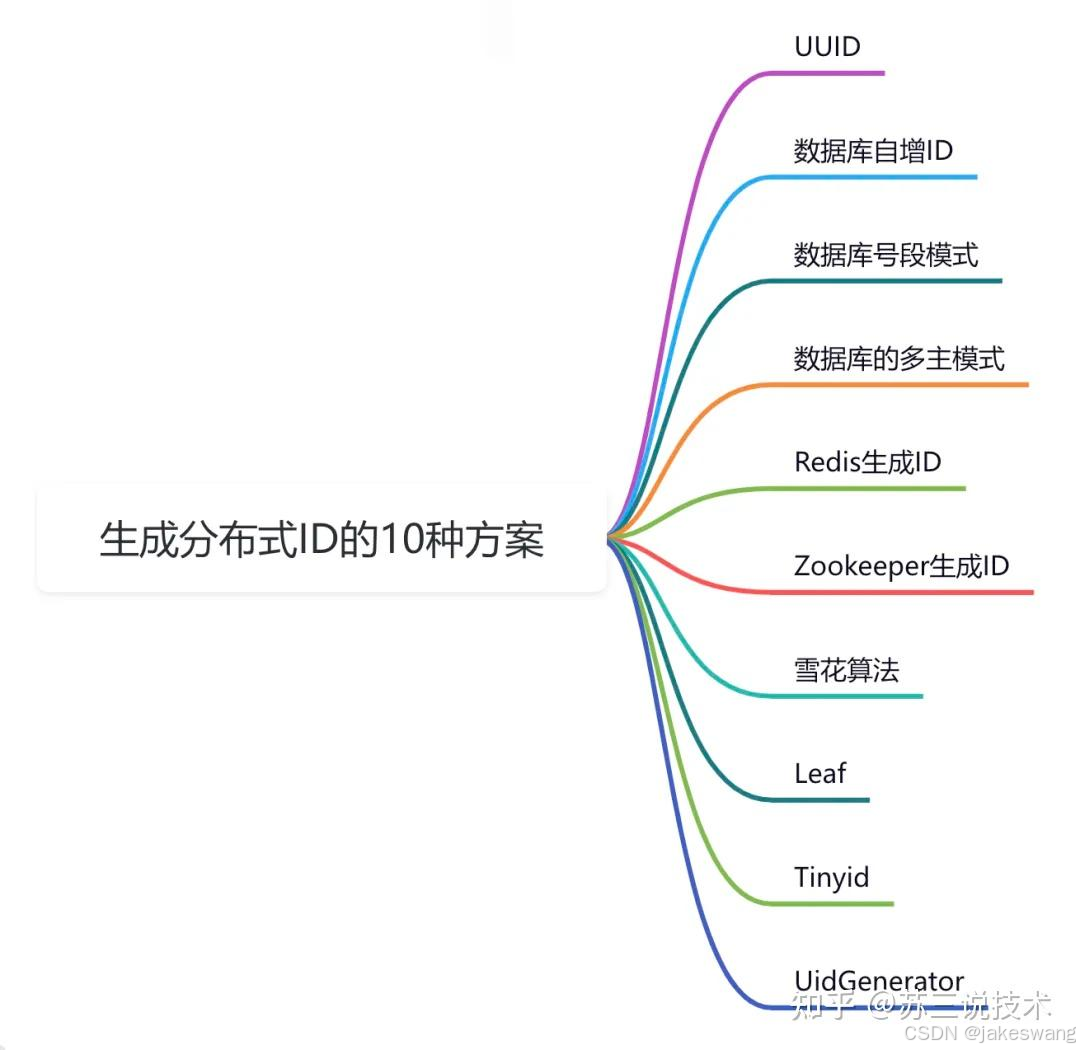
分布式ID服务实现全面解析
分布式ID生成器是分布式系统中的关键基础设施,用于在分布式环境下生成全局唯一的标识符。以下是各种实现方案的深度解析和最佳实践。 一、核心需求与设计考量 1. 核心需求矩阵 需求 重要性 实现难点 全局唯一 必须保证 时钟回拨/节点冲突 高性能 高并发场景…...

dom0运行android_kernel: do_serror of panic----failed to stop secondary CPUs 0
问题描述: 从日志看出,dom0运行android_kernel,刚开始运行就会crash,引发panic 解决及其原因分析: 最终问题得到解决,发现是前期在调试汇编阶段代码时,增加了汇编打印的指令,注释掉这些指令,问题得到解决。…...

HarmonyOS NEXT——【鸿蒙原生应用加载Web页面】
鸿蒙客户端加载Web页面: 在鸿蒙原生应用中,我们需要使用前端页面做混合开发,方法之一是使用Web组件直接加载前端页面,其中WebView提供了一系列相关的方法适配鸿蒙原生与web之间的使用。 效果 web页面展示: Column()…...

HTML输出流
HTML 输出流 JavaScript 中**「直接写入 HTML 输出流」**的核心是通过 document.write() 方法向浏览器渲染过程中的数据流动态插入内容。以下是详细解释: 一、HTML 输出流的概念 1. 动态渲染过程 HTML 文档的加载是自上而下逐行解析的。当浏览器遇到 <script&…...

std::countr_zero
一 基本功能 1 作用 std::countr_zero 是 C++20 标准引入的位操作函数,用于计算无符号整数的二进制表示中末尾零(Trailing Zeros)的数量。 定义:位于 <bit> 头文件中,是标准库的一部分。 2 示例 #include <bit> unsigned int x = 12; // 二进…...

优选算法的慧根之翼:位运算专题
专栏:算法的魔法世界 个人主页:手握风云 一、位运算 基础位运算 共包含6种&(按位与,有0就是0)、|(按位或有1就是1)、^(按位异或,相同为0,相异为1)、~(按位取反,0变成1,1变成0)、<<(左…...

图论问题集合
图论问题集合 寻找特殊有向图(一个节点最多有一个出边)中最大环路问题特殊有向图解析算法解析步骤 1 :举例分析如何在一个连通块中找到环并使用时间戳计算大小步骤 2 :抽象成算法注意 实现 寻找特殊有向图(一个节点最多…...

【数据结构】栈 与【LeetCode】20.有效的括号详解
目录 一、栈1、栈的概念及结构2、栈的实现3、初始化栈和销毁栈4、打印栈的数据5、入栈操作---栈顶6、出栈---栈顶6.1栈是否为空6.2出栈---栈顶 7、取栈顶元素8、获取栈中有效的元素个数 二、栈的相关练习1、练习2、AC代码 个人主页,点这里~ 数据结构专栏,…...

实时目标检测新突破:AnytimeYOLO——随时中断的YOLO优化框架解析
目录 一、论文背景与核心价值 二、创新技术解析 2.1 网络结构革新:Transposed架构 2.2 动态路径优化算法 三、实验结果与性能对比 3.1 主要性能指标 3.2 关键发现 四、应用场景与部署实践 4.1 典型应用场景 4.2 部署注意事项 五、未来展望与挑战 一、论文背景与核心…...

Redis设计与实现-哨兵
哨兵模式 1、启动并初始化sentinel1.1 初始化服务器1.2 使用Sentinel代码1.3 初始化sentinel状态1.4 初始化sentinel状态的master属性1.5 创建连向主服务器的网络连接 2、获取主服务器信息3、获取从服务器的信息4、向主从服务器发送信息5、接受主从服务器的频道信息6、检测主观…...

C++进阶——封装哈希表实现unordered_map/set
与红黑树封装map/set基本相似,只是unordered_map/set是单向迭代器,模板多传一个HashFunc。 目录 1、源码及框架分析 2、模拟实现unordered_map/set 2.1 复用的哈希表框架及Insert 2.2 iterator的实现 2.2.1 iteartor的核心源码 2.2.2 iterator的实…...