day1_Flink基础
文章目录
- Flink基础
- 今日课程内容目标
- 为什么要学Flink
- 技术更新迭代
- 市场需求
- 流式计算
- 批量计算
- 概念
- 特点
- 批量计算的优势和弊端
- 流式计算
- 生活中流场景
- 流式计算的概念
- Flink简介
- Flink历史
- Flink介绍
- Flink架构体系
- 已学过的框架技术
- Flink架构
- Flink集群搭建
- Flink的集群模式
- Standalone模式集群搭建
- 安装部署配置
- demo案例运行
- Flink入门案例
- Flink分层API
- Flink程序开发流程
- 搭建Flink工程
- 基于mvn创建项目
- 引入的基本依赖
- 入门案例
- 需求
- 分析
- 实现
- 批处理 - DataStream(从文件中读取批数据)
- 流处理 - DataStream(从socket中读取流数据)
- 流处理 - DataStream(扩展1:从socket中读取流数据,Lambda的方式实现)
- 流处理 - DataStream(扩展2:从socket中读取流数据,Lambda的方式实现)
- 流处理 -Table API
- 流处理 - SQL
- Flink程序提交部署
- Flink程序提交部署
- 以UI的方式递交
- 以命令的方式递交
- 今日总结
Flink基础
今日课程内容目标
- 为什么要学Flink
- 技术更新迭代
- 市场趋势
- 流式计算
- 批量计算
- 流式计算
- Flink简介
- Flink架构体系
- Flink安装部署
- Local
- Standalone
- Yarn【最后一天学习】
- Flink入门案例
- 批处理(已过期)
- 流处理(DataStream API、Table API、SQL)
为什么要学Flink
技术更新迭代

- 离线计算
Hadoop(MR) -> Tez(MR增强版) -> Spark(内存计算)
- 流式计算(实时计算)
Storm -> StructuredStreaming -> Flink
市场需求
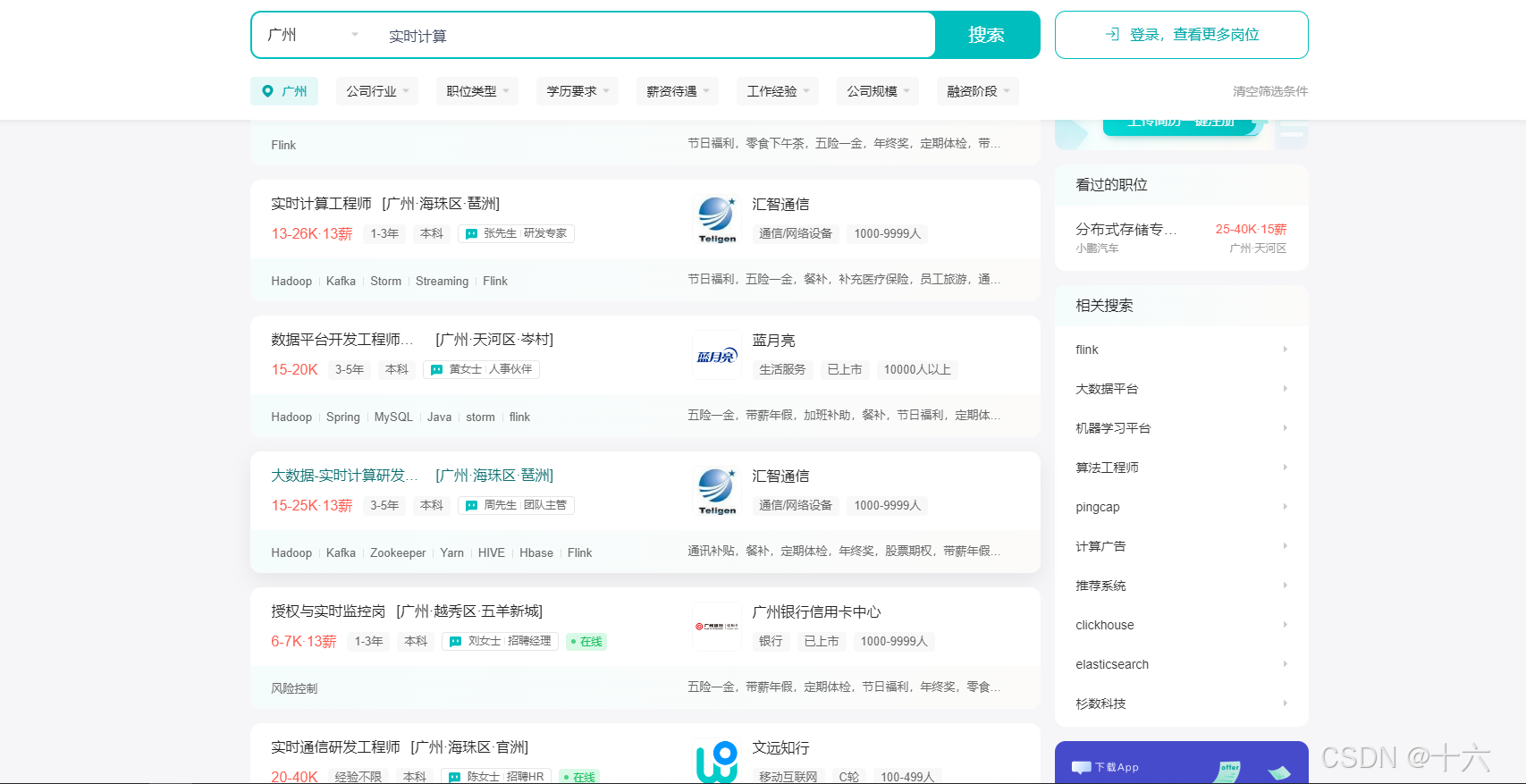
小结:流式计算需求趋向于火热。同时,由于大公司在推进,因此,互联网实时需求越来越旺盛。
流式计算
批量计算
概念
批量计算,数据是一批一批地计算,来一批处理一批。
特点
数据是有界的,数据是有开始,也有结束的。
数据一旦产生,不会更改
时效性低
批量计算的优势和弊端
批量计算的优势,是对历史数据的处理。对于时效性要求不高。
但是,对于一些时效性要求高的场景:
- 实时监控网站的异常情况
- 实时监控道路拥堵情况
- 实时监控全国疫情爆发情况
- 实时监控网站成交情况
这个时候,就需要流式计算了。
流式计算
生活中流场景
生活中的流式场景比较多,比如水流,车流,人流(行人),气流,电流,如下图(以水流为例)

这些流式场景,他们的共同点是:
-
数据是源源不断,也就是不间断
-
有开始,没有结束
-
来一条处理一条
流式计算的概念
基于数据流的计算,就叫做流式计算。
数据流:数据是流动的,是源源不断的,是没有结束的。
流式计算的框架:
- Storm
- StructuredStreaming
- Flink(主角)
Flink简介
Flink历史
2010-2014年,起源于欧洲柏林大学的一个StratoSphere项目
2014年4月,捐赠给了Apache软件基金会
在2014年底,称为Apache的顶级项目
2019年,Flink的母公司,被阿里巴巴收购
Flink的最新版:1.20.0
我们这次课程,也是基于1.20.0来讲解。
Flink介绍

Flink官网:https://flink.apache.org/
Flink:基于数据流上的有状态的计算。
数据流:流动的数据。
有状态:Flink会保存每个算子的计算中间结果,不需要用户操心。这也是相比Storm框架的优势。
Flink的编程模型【扩展】
- 数据输入
- MySQL数据
- 日志数据
- 物联网数据
- 点击埋点数据
- 数据处理
- Flink程序
- 数据输出
- 关系型数据库
- 文件
- K-V存储介质
Flink架构体系
已学过的框架技术
- HDFS
- NameNode(主)
- DataNode(从)
- Yarn
- ResourceManager(主)
- NodeManager(从)
- Spark
- Master(主)
- Worker(从)
- Flink
- JobManager(主)
- TaskManager(从)
Flink架构

Flink也是主从架构,分为如下:
- JobManager:负责集群管理,资源管理、任务调度、容错等。
- TaskManager:负责任务执行,心跳汇报
- Slot(槽)就是Flink具体任务的场所。Standalone模式下,槽位在集群启动时,就固定了。在Yarn下,可以动态申请TaskManager,因此可以动态增加槽位。
Flink集群搭建
Flink的集群模式
- Local模式【本地模式, 开发环境可用】
- 一个进程模拟全部的角色,处理所有的代码流程。
- Standalone模式【独立模式,测试或者生产环境可用】
- 每个进程都是互相独立的。
- Yarn模式【生产模式常用,基础课最后一天介绍】
- 不需要额外的搭建,只需要把Yarn、HDFS启动即可。
- 基于Yarn来运行Flink。(需要添加Flink基于HDFS的依赖jar包)
Standalone模式集群搭建
安装部署配置
#0.准备
cd /export/software#1.下载
wget https://archive.apache.org/dist/flink/flink-1.12.0/flink-1.12.0-bin-scala_2.12.tgz#2.解压
tar -zxvf flink-1.20.0-bin-scala_2.12.tgz -C /export/server/#3.进入
cd /export/server/#4.创建软连接
ln -s flink-1.20.0 flink#5.修改配置
82行:numberOfTaskSlots: 4
170行:address: node1
177行:bind-address: node1
随便找一行,添加:classloader.check-leaked-classloader: false#6.启动Flink
bin/start-cluster.sh#7.停止Flink
bin/stop-cluster.sh#8.FLINK_HOME配置
#FLINK_HOME
export FLINK_HOME=/export/server/flink
export PATH=$PATH:$FLINK_HOME/bin#9.source环境变量
source /etc/profile#10.查看WebUI登录页面
http://node1:8081
Flink安装目录介绍

demo案例运行
cd $FLINK_HOME
bin/flink run examples/batch/WordCount.jar
WebUI运行结果如下:

后台结果如下:

Flink入门案例
Flink分层API
Flink还是一个非常易于开发的框架,因为它拥有易于使用的分层API,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大,如下图所示:

- SQL/Table API(最顶层)StreamTableEnvironment
- DataStream API(中间层)StreamExecutionEnvironment
- Stateful Function(最底层)
注意:2020年12月8日发布的新版本1.12.0,已经完全实现了真正的流批一体,DataSetAPI已经处于软性弃用(soft deprecated)的状态,用DataStream API写好的一套代码,既可以处理流数据,也可以处理批数据,只需要设置不同的执行模式,这与之前版本处理有界流的方式是不一样的,Flink已专门对批处理数据做了优化处理,本课程基于Flink1.20版本研发,因此后续的学习以介绍DataStream API为主。
Flink程序开发流程
一个完整的flink作业无论简单与复杂,flink程序都由如下几个部分组成:

- 构建流式执行环境:获取一个编程、执行入口环境env【固定写法】
- 数据输入:通过数据源组件,加载、创建datastream
- 数据处理: 对datastream调用各种处理算子表达计算逻辑
- 数据输出:通过sink算子指定计算结果的输出方式
- 启动流式任务:在env上触发程序提交运行【固定写法】
注意:写完输出(sink)操作并不代表程序已经结束。因为当main()方法被调用时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据——因为数据可能还没来。Flink是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”。
所以我们需要显式地调用执行环境的execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
env.execute();
搭建Flink工程
基于mvn创建项目
-
创建一个新项目:
Create New Project
-
下一步,选择
maven项目,并且勾选:Create from archetype选项(目的是使用flink官方提供的项目模板快速生成项目结构)
如果是第一次创建项目,那么则需要添加一个新的模板文件,请选择:
Add Archetype按钮,并把官方提供的模板内容填写完整:

这里需要注意的是
Version字段,请确认你开发时的flink版本和你运行的环境版本是一致的,以免带来不必要的麻烦。比如:公司的
flink集群是是基于1.20.0版本,而你是基于1.10.0开发的代码,那么最终上线肯定会遇到兼容性问题的,所以请注意。添加好官方的模板后,我们便可以在以下的列表中选择基于该模板来创建项目基本结构:

-
下一步,配置项目名称,并且取一个唯一的
groupId名称: -
最后,直接下一步选择默认操作完成即可。整个项目目录结构创建完成,如下:

引入的基本依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.20.0</flink.version><parquet-avro>1.12.2</parquet-avro><log4j.version>2.17.1</log4j.version><mysql.version>5.1.48</mysql.version><lombok.version>1.18.22</lombok.version><hadoop.version>3.3.0</hadoop.version><target.java.version>1.8</target.java.version><scala.binary.version>2.12</scala.binary.version><maven.compiler.source>${target.java.version}</maven.compiler.source><maven.compiler.target>${target.java.version}</maven.compiler.target></properties><repositories><repository><id>apache.snapshots</id><name>Apache Development Snapshot Repository</name><url>https://repository.apache.org/content/repositories/snapshots/</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository></repositories><dependencies><!-- Apache Flink dependencies --><!-- These dependencies are provided, because they should not be packaged into the JAR file. --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>${flink.version}</version></dependency><!-- Add connector dependencies here. They must be in the default scope (compile). --><!-- Example:<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>3.0.0-1.17</version></dependency>--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>3.3.0-1.20</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.2.0-1.19</version></dependency><!-- flink连接器--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-parquet</artifactId><version>${flink.version}</version></dependency><!-- Add logging framework, to produce console output when running in the IDE. --><!-- These dependencies are excluded from the application JAR by default. --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><!--lombok插件--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version></dependency><!--第三方工具包--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.53</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.9</version></dependency></dependencies><build><plugins><!-- Java Compiler --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>${target.java.version}</source><target>${target.java.version}</target></configuration></plugin><!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --><!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><!-- Run shade goal on package phase --><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><createDependencyReducedPom>false</createDependencyReducedPom><artifactSet><excludes><exclude>org.apache.flink:flink-shaded-force-shading</exclude><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>org.apache.logging.log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>cn.itcast.DataStreamJob</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins><pluginManagement><plugins><!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. --><plugin><groupId>org.eclipse.m2e</groupId><artifactId>lifecycle-mapping</artifactId><version>1.0.0</version><configuration><lifecycleMappingMetadata><pluginExecutions><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><versionRange>[3.1.1,)</versionRange><goals><goal>shade</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><versionRange>[3.1,)</versionRange><goals><goal>testCompile</goal><goal>compile</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution></pluginExecutions></lifecycleMappingMetadata></configuration> </plugin></plugins></pluginManagement></build>
入门案例
需求
使用Flink程序,从文件里读取单词,进行Wordcount单词统计。
分析
#3.数据处理
#3.1,进行扁平化处理
hello hadoop hello
hello hive => 转换成如下 hadoophellohive#3.2把上述每个单词进行转换,转成(单词,1)
hello (hello,1)
hadoop => (hadoop,1)
hello (hello,1)
hive (hive,1)#3.3 把上述单词,按照word(单词)进行分组
(hello,1) (hello,1),(hello,1)
(hadoop,1) => (hadoop,1)
(hello,1) (hive,1)
(hive,1)#3.4 把相同组内的单词,进行sum求和
(hello,1),(hello,1) (hello,2)
(hadoop,1) => (hadoop,n)
(hive,1) (hive,n)
实现
批处理 - DataStream(从文件中读取批数据)
package day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @author: itcast* @date: 2022/10/26 16:48* @desc: Flink 程序实现Wordcount单词统计(批处理)*/
public class Demo01_WordCountBatch {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.setRuntimeMode(RuntimeExecutionMode.BATCH);//2.数据输入(数据源)DataStreamSource<String> source = env.readTextFile("D:\\word.txt");//3.数据处理,匿名内部类 new 接口类(){}//3.1 flatMap进行扁平化处理SingleOutputStreamOperator<String> flatMapStream = source.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}});//3.2 使用map方法,进行转换(单词,1)int -> IntegerSingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});//3.3 使用keyBy算子进行单词分组 (hello,1)KeyedStream<Tuple2<String, Integer>, String> keyedStream = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});//3.4进行reduce(sum)操作(hello,1),(hello,1)SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {return Tuple2.of(value1.f0, value1.f1 + value2.f1);}});//4.数据输出result.print();//5.启动流式任务env.execute();}
}
运行结果如下:

流处理 - DataStream(从socket中读取流数据)
package day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @author: itcast* @date: 2022/10/26 17:18* @desc: Flink 代码实现流处理,进行单词统计。数据源来自于socket数据。*/
public class Demo02_WordCountStream {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.STREAMING);env.setParallelism(1);//2.数据输入(数据源)//从socket读取数据,socket = hostname + portDataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理//3.1 使用flatMap进行扁平化处理SingleOutputStreamOperator<String> flatMapStream = source.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}});//3.2 使用map进行转换,转换成(单词,1)SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});//3.3使用keyBy进行单词分组KeyedStream<Tuple2<String, Integer>, String> keyedStream = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});//3.4 使用reduce(sum)进行聚合操作,sum:就是根据第一个元素(Integer)进行sum操作SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedStream.sum(1);//4.数据输出result.print();//5.启动流式任务env.execute();}
}运行结果如下:

流处理 - DataStream(扩展1:从socket中读取流数据,Lambda的方式实现)
package day01;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @author: itcast* @date: 2022/10/27 9:21* @desc: 扩展2:采用Lambda表达式的方式来编写Flink wordcount入门案例*/
public class Demo04_WordCountStream_03 {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.数据输入DataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理SingleOutputStreamOperator<Tuple2<String, Integer>> result = source.flatMap((String value, Collector<String> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}).returns(Types.STRING).map(value -> Tuple2.of(value, 1)).returns(Types.TUPLE(Types.STRING,Types.INT)).keyBy(value -> value.f0).sum(1);//4.数据输出result.print();//5.启动流式任务env.execute();}
}运行结果如下:

流处理 - DataStream(扩展2:从socket中读取流数据,Lambda的方式实现)
package day01;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;import java.util.Arrays;/*** @author: itcast* @date: 2022/10/27 9:21* @desc: 扩展3:采用Lambda表达式的方式来编写Flink wordcount入门案例*/
public class Demo04_WordCountStream_04 {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.数据输入DataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理SingleOutputStreamOperator<Tuple2<String, Integer>> result = source.flatMap((String value, Collector<String> out) -> {Arrays.stream(value.split(" ")).forEach(out::collect);}).returns(Types.STRING).map(value -> Tuple2.of(value, 1)).returns(Types.TUPLE(Types.STRING,Types.INT)).keyBy(value -> value.f0).sum(1);//4.数据输出result.print();//5.启动流式任务env.execute();}
}任务运行截图:

流处理 -Table API
package day01;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Expressions;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.TableDescriptor;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.util.concurrent.ExecutionException;/*** @author: itcast* @date: 2022/10/27 9:55* @desc: 使用Flink Table API进行wordcount单词统计。* Table:表,(MySQL、Hive、Spark)* 是不是需要先准备好表?* 在Flink里面,同样如此。* //1.构建流式执行环境* //2.数据输入(数据输入表)* //3.数据输出(数据输出表)* //4.数据处理(基于数据输入表、数据输出表进行业务处理(单词统计)* //5.启动流式任务*/
public class Demo05_WordCountTable {public static void main(String[] args) throws Exception {//1.构建流式执行环境//env 对象是基于DataStream API构建的,如果需要使用Table API/SQL来提交Flink任务,则需要使用Flink里的StreamTableEnvironment对象StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment t_env = StreamTableEnvironment.create(env);t_env.getConfig().set("parallelism.default","1");//2.数据输入(数据输入表)/*** createTemporaryTable(String tableName,TableDescriptor tableDescriptor);* tableName:表名* tableDescriptor:描述表的schema,column等信息的* connector: 就类似于jdbc的驱动类,但是Flink不叫驱动包(驱动类),Flink叫做Connector,连接器。* 连接器:就是用来连接外部数据源的。*//*** | word |* | hello |* | hive |* | flink |*/t_env.createTemporaryTable("source", TableDescriptor.forConnector("datagen").schema(Schema.newBuilder().column("word", DataTypes.STRING()).build()).option("rows-per-second","1").option("fields.word.kind","random").option("fields.word.length","1").build());//3.数据输出(数据输出表)/*** | word | counts |* | a | 2 |* | 1 | 3 |*/t_env.createTemporaryTable("sink",TableDescriptor.forConnector("print").schema(Schema.newBuilder().column("word",DataTypes.STRING()).column("counts",DataTypes.BIGINT()).build()).build());//4.数据处理(基于数据输入表、数据输出表进行业务处理(单词统计)/*** 处理逻辑:* 首先从源表把数据读取出来,根据单词进行分组,然后按照分组后的字段(word,count(*))进行统计。* from:从源表读取数据* groupBy:根据xx字段分组* select:分组后选择需要的数据,选择的数据&类型需要和目标表匹配* executeInsert:把最终结果插入到目标表中去* insert into sink* select word ,count(*) from source group by word*/t_env.from("source").groupBy(Expressions.$("word")).select(Expressions.$("word"),Expressions.lit(1).count()).executeInsert("sink").await();//5.启动流式任务env.execute();}
}执行结果如下:

流处理 - SQL
package day01;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.util.concurrent.ExecutionException;/*** @author: itcast* @date: 2022/10/27 10:42* @desc: 使用Flink SQL完成单词统计*/
public class Demo06_WordCountSQL {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment t_env = StreamTableEnvironment.create(env);t_env.getConfig().set("parallelism.default","1");//2.构建数据源表(数据输入)/*** | word |* | hello |* | hive |* | spark |* | flink |*/t_env.executeSql("create table source(" +"word varchar" +") with (" +"'connector' = 'datagen'," +"'rows-per-second' = '1'," +"'fields.word.kind' = 'random'," +"'fields.word.length' = '1'" +")");//3.构建数据输出表(数据输出)/** 表结构如下:* | word | counts |* | hello | 1 |* | hive | 2 |* | flink | 3 |*/t_env.executeSql("create table sink(" +"word varchar," +"counts bigint" +") with (" +"'connector' = 'print'" +")");//4.数据处理/*** 数据处理逻辑SQL如下:* insert into sink select word,count(*) from source group by word*/t_env.executeSql("insert into sink select word,count(*) from source group by word").await();//5.启动流式任务env.execute();}
}执行结果如下:

Flink程序提交部署
Flink程序提交部署
Flink程序递交方式有两种:
- 以UI的方式递交
- 以命令的方式递交
以UI的方式递交
提交步骤:
#1.使用idea自带的打包工具进行打包(双击package即可)
#2.使用瘦包即可(小的包)传到webUI上
#3.设置Entry class(day01.Demo02_WordCountStream)Parallelism(1)
#4.开启socket(nc -lk 9999)
#5.Submit提交
#6.在linux终端输入单词
-
指定递交参数

-
查看任务运行概述

-
查看任务运行结果
以命令的方式递交
-
上传作业jar包到linux服务器

-
配置执行模式(可选)

-
指定递交命令
flink run -c day01.Demo02_WordCountStream original-flinkbase-1.0-SNAPSHOT.jar -
查看任务运行概述

今日总结
- 学习 Flink 的入门和综述,主要介绍了 Flink 的起源和应用场景,引出了流处理相关 的一些重要概念,并通过介绍数据处理架构发展演变的过程,展示了 Flink 作为新一代分布式流处理器的架构思想。
- 实现了一个Flink 开发的入门程序——词频统计 WordCount。通过批处理和流处理两种不同模式的实现,可以对Flink的API风格和编程方式有所熟悉,并且可以更加深刻地理解批处理和流处理的不同。另外,通过读取有界数据(文件)和无界数据(Socket 文本流)进行流处理的比较,可以更加直观地体会Flink流处理的方式和特点。
相关文章:
day1_Flink基础
文章目录 Flink基础今日课程内容目标为什么要学Flink技术更新迭代市场需求 流式计算批量计算概念特点 批量计算的优势和弊端流式计算生活中流场景流式计算的概念 Flink简介Flink历史Flink介绍 Flink架构体系已学过的框架技术Flink架构 Flink集群搭建Flink的集群模式Standalone模…...

ctf-web: 不统一的解析 + sql注入要求输入与输出相等 -- tpctf supersqli
# 从 django.shortcuts 模块导入 render 函数,用于渲染模板 from django.shortcuts import render # 从 django.db 模块导入 connection 对象,用于数据库连接 from django.db import connection# 此模块用于创建视图函数 # 从 django.http 模块导入 Http…...

基于Java与Go的下一代DDoS防御体系构建实战
引言:混合云时代的攻防对抗新格局 2024年某金融平台遭遇峰值2.3Tbps的IPv6混合攻击,传统WAF方案在新型AI驱动攻击面前全面失效。本文将以Java与Go为技术栈,揭示如何构建具备智能决策能力的防御系统。 一、攻击防御技术矩阵重构 1.1 混合攻击特征识别 攻击类型Java检测方案…...

使用FastExcel时的单个和批量插入的问题
在我们用excel表进行插入导出的时候,通常使用easyexcel或者FastExcel,而fastexcel是easy的升级版本,今天我们就对使用FastExcel时往数据库插入数据的业务场景做出一个详细的剖析 场景1 现在我们数据库有一张组织表,组织表的字段…...
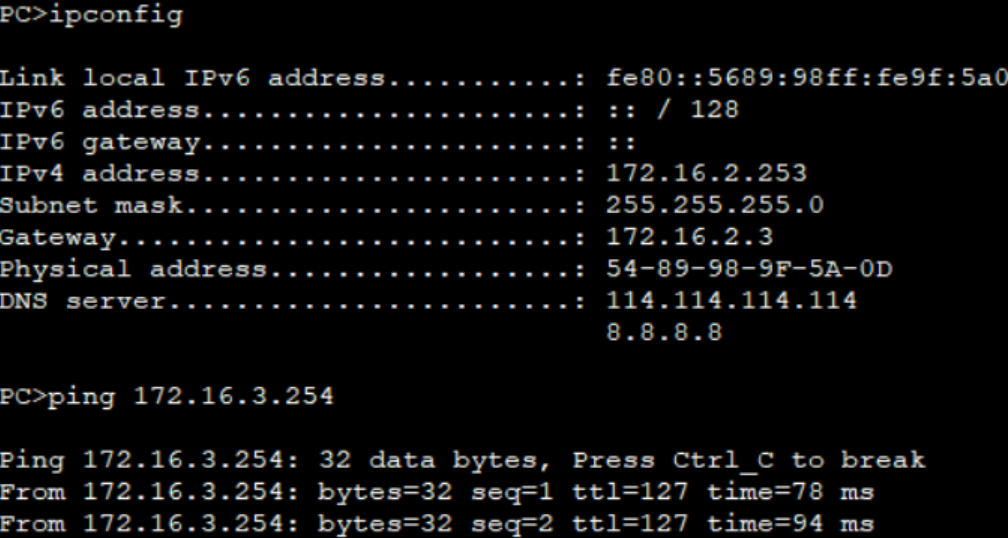
交换技术综合实验
一、实验拓扑 二、实验要求 内网IP地址使用172.16.0.0/16分配。 SW1和SW2之间互为备份。 VRRP/STP/VLAN/Eth-trunk均使用。 所有PC通过DHCP获取IP地址。 ISP只能配置IP地址。 所有电脑可以正常访问ISP路由器。 三、实验步骤 基于172.16.0.0/16进行划分 172.16.2.0/24&…...
)
软件工程之软件开发模型(瀑布、迭代、敏捷、DevOps)
1. 瀑布模型(Waterfall Model) 定义与流程 瀑布模型是线性顺序的开发流程,包含需求分析、设计、编码、测试、维护等阶段,每个阶段完成后才能进入下一阶段,类似“瀑布流水”逐级推进。 核心特点 严格阶段划分&#…...
和SerDes 加解串应用)
Display Serializer、Camera Deserializer(Camera Des)和SerDes 加解串应用
1. 概述:三者的核心定位 (1) SerDes(Serializer/Deserializer) 定义:通用高速数据传输技术,实现并行↔串行双向转换。角色:数据链路的“翻译官”,解决并行传输的带宽与距…...
)
Redis 常用数据结构及其对应的业务场景(总结)
1. String(字符串) 特点:最简单的键值对结构,可存储文本、数字或二进制数据(最大 512MB)。 适用场景: 缓存:存储用户信息、页面片段、商品详情等(如 SET user:1 "{…...

记录Jmeter 利用BeanShell 脚本解析JSON字符串
下载org.json包(文档说明) #下载地址 https://www.json.org/ # github 地址 https://github.com/stleary/JSON-java # api 文档说明 https://resources.arcgis.com/en/help/arcobjects-java/api/arcobjects/com/esri/arcgis/server/json/JSONObject.htmlBeanShell脚本 import…...

深入解析音频:格式、同步及封装容器
物理音频和数字音频 物理音频 定义:物理音频就是声音在自然界中的物理表现形式,本质上是一种机械波,通过空气或其他介质传播。例如,当我们说话、乐器演奏或物体碰撞时,都会产生振动,这些振动会引起周围介…...
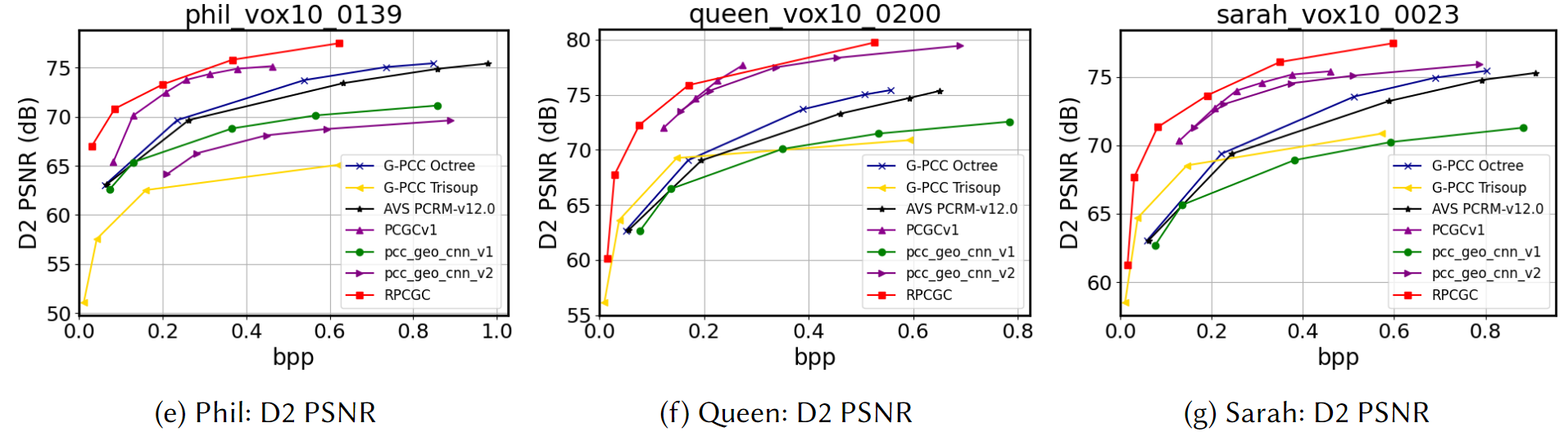
RPCGC阅读
24年的MM 创新 现有点云压缩工作主要集中在保真度优化上。 而在实际应用中,压缩的目的是促进机器分析。例如,在自动驾驶中,有损压缩会显着丢失户外场景的详细信息。在三维重建中,压缩过程也会导致场景数据中语义信息(Contour)的…...

医疗CMS高效管理:简化更新维护流程
内容概要 医疗行业内容管理系统(CMS)的核心价值在于应对医疗信息管理的多维复杂性。面对诊疗指南的动态更新、科研数据的快速迭代以及多机构协作需求,传统管理模式往往面临效率瓶颈与合规风险。现代化医疗CMS通过构建结构化权限管理矩阵&…...

《Spring Cloud Eureka 高可用集群实战:从零构建高可靠性的微服务注册中心》
从零构建高可用 Eureka 集群 | Spring Cloud 微服务架构深度实践指南 本文核心内容基于《Spring Cloud 微服务架构开发》第1版整理,结合生产级实践经验优化 实验环境:IntelliJ IDEA 2024 | JDK 1.8| Spring Boot 2.1.7.RELEASE | Spring Cloud Greenwich…...

PyQt6实例_批量下载pdf工具_主线程启用线程池
目录 前置: 代码: 视频: 前置: 1 本系列将以 “PyQt6实例_批量下载pdf工具”开头,放在 【PyQt6实例】 专栏 2 本系列涉及到的PyQt6知识点: 线程池:QThreadPool,QRunnable; 信号与…...

DSP+AI综合应用案例1——三种波形识别(预告)
采用1kHz采样率,识别方波、正弦波、三角波三种波形,算法采用傅里叶变换与神经网络,识别结果如下: 可以达到1ms内实现检测,逐渐完善到CanMV K230 或MCU中,待续...

去噪算法大比拼
目录 效果图: 实现代码: 密集抖动 pip install pykalman 效果图: 实现代码: import numpy as np import cv2 import matplotlib.pyplot as plt from scipy.ndimage import gaussian_filter1d from scipy.signal import butter, filtfilt, savgol_filter from pykalma…...

浅拷贝或深拷贝js数组或对象的方法
在js中,直接通过赋值操作拷贝数组,会导致新旧数组互相影响。 这是因为数组、对象等数据属于引用类型(Reference Type)数据。对引用类型数据进行赋值操作时,实际上拷贝的是其内存地址的引用(即指向堆内存中对…...

CKS认证 | Day3 K8s容器运行环境安全加固
一、最小特权原则(POLP) 1)最小特权原则 (Principle of least privilege,POLP) : 是一种信息安全概念,即为用户提供执行其工作职责所需的最 小权限等级或许可。 最小特权原则被广泛认为是网络安全的最佳实…...
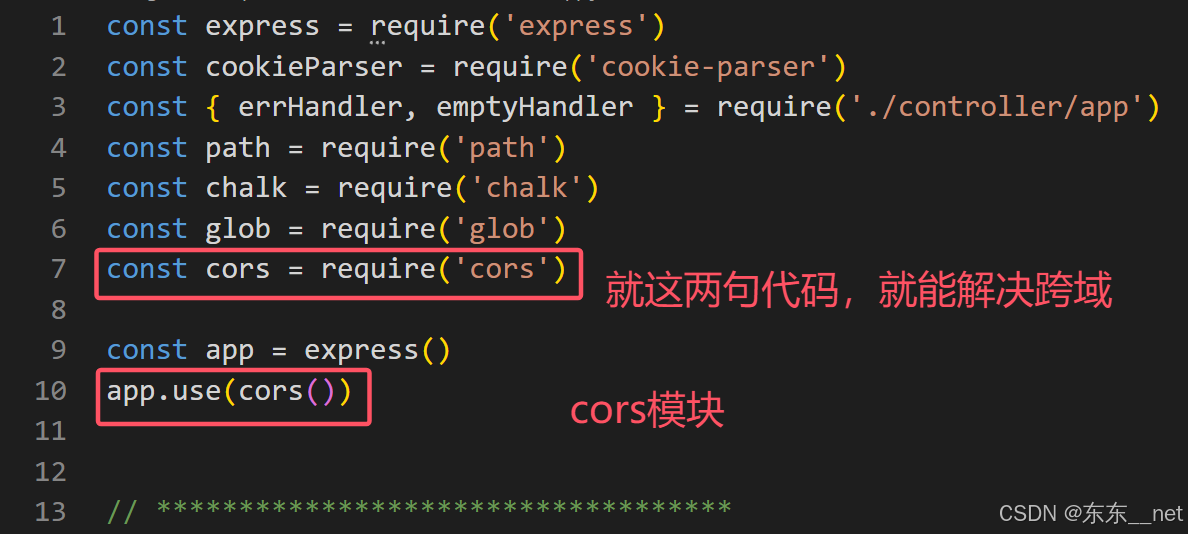
28_跨域
目录 promise promise的基本语法 async await try catch promise 静态方法 跨域 跨域的解决方案 1-cors 编辑 2-jsonp方案 3-代理服务器 promise promise 是一个es6新增的语法 承诺的意思 作用:是专门用来解决回调地狱!!!! promise的基本语法 // 基本语法:// Pr…...

Stable Diffusion太慢?国内Midjourney平替方案—商用合规部署
一、AI绘画商用核心痛点(为什么需要替代Stable Diffusion/Midjourney?) 1. 速度慢,高并发支持差 Stable Diffusion:单卡GPU生成1张图需3-10秒,并发超过10任务易崩溃Midjourney:排队制…...
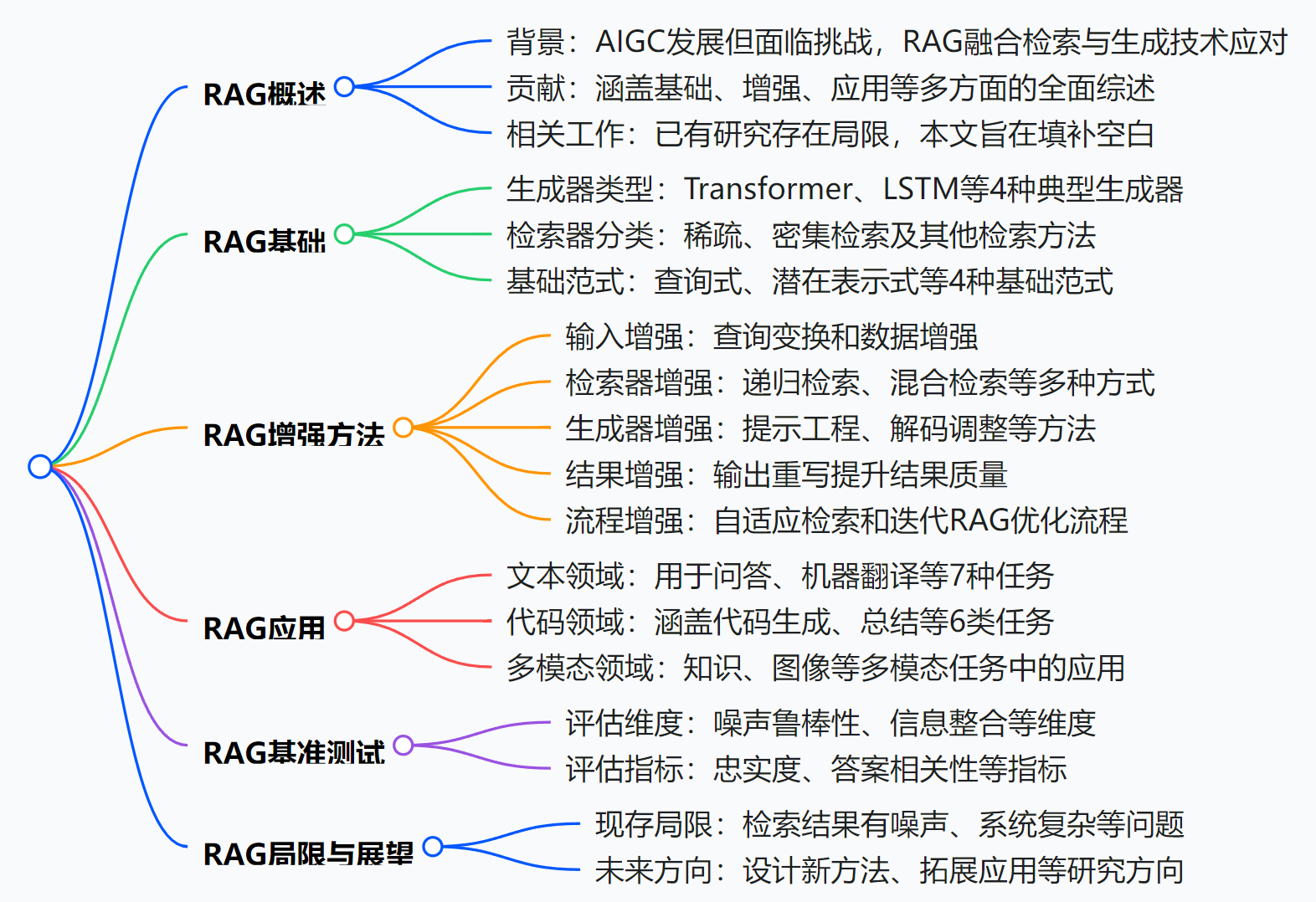
综述速读|086.04.24.Retrieval-Augmented Generation for AI-Generated Content A Survey
论文题目:Retrieval-Augmented Generation for AI-Generated Content: A Survey 论文地址:https://arxiv.org/abs/2402.19473 bib引用: misc{zhao2024retrievalaugmentedgenerationaigeneratedcontent,title{Retrieval-Augmented Generation…...

Spring @EnableAutoConfiguration 注解执行过程详解
Spring EnableAutoConfiguration 注解执行过程详解 核心流程 触发自动配置:通过 EnableAutoConfiguration 注解开启自动配置。加载配置类:根据 META-INF/spring.factories 文件加载默认的自动配置类。条件判断:每个自动配置类通过 Condition…...

JavaScript中的Math对象和随机数
目录 一、常用数学方法 1. 数值处理 2. 极值与运算 3. 三角函数(参数为弧度) 4. 对数与指数 5. 常量 二、随机数生成 Math.random() 1. 基础范围控制 2. 整数随机数 三、实际应用场景 1. 随机颜色生成 2. 数组随机排序 3. 概率控制 四、注…...

lxd-dashboard 图形管理LXD/LXC
前言 LXD-WEBGUI是一个完全用AngularJS编写的Web应用程序,无需应用服务器、数据库或其他后端服务支持。只需要简单地托管静态HTML和JavaScript文件,就能立即投入使用。这个项目目前处于测试阶段,提供了直观的用户界面,帮助用户便捷地管理和控制LXD实例。 安装lxd-dashboa…...

python纯终端实现图片查看器(全彩)(windows)
很多人作为命令行爱好者,无法在终端内直接查看图片是无法忍受的, 那就写一个! 先直接上代码 import os import sys from PIL import Image import numpy as np import colorama import msvcrt # Windows专用# 初始化colorama colorama.ini…...

【动态规划篇】- 路径问题
62. 不同路径 题目链接: 62. 不同路径 题目解析: 状态表示 dp[i][j]表示:以[i][j]为终点时,一共有多少种路径。 状态转移方程 以[i][j]最近的几步来分析问题,要么从[i-1][j]位置向下走一步到达[i][j],要么从[i][j-1…...

《新凯来:半导体设备制造领域的“国家队”》
《新凯来:半导体设备制造领域的“国家队”》 一、SEMICON China 爆火出圈:31 款设备背后的 “深圳力量” 1.1 展会现象级热度 在 2025 年 SEMICON China 展会现场,新凯来展台成了整届展会当之无愧的 “顶流”,被来自全球各地的专…...

AI大模型最新发布[update@202503]
OpenAI GPT-4o:多模态,“o”代表Omni,即全能的意思,凸显了其多功能的特性。 多模态交互,GPT-4o可以接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合输出。实时推理能力&#x…...

深入浅出 Embedding
1. 什么是 Embedding? Embedding(嵌入)是一种将高维数据映射到低维连续空间的技术,用于表达数据的语义关系。简单来说,它是一种向量化表示,将文本、图像、用户行为等信息转换为数值向量,使得相似的数据在向量空间中距离更近。 2. 如何理解 Embedding? 2.1 浅显易懂的…...

java项目之基于ssm的乡镇自来水收费系统(源码+文档)
项目简介 乡镇自来水收费系统实现了以下功能: 乡镇自来水收费系统在Eclipse环境中,使用Java语言进行编码,使用Mysql创建数据表保存本系统产生的数据。系统可以提供信息显示和相应服务,其管理员管理水表,审核用户更换…...