排序算法1--插入排序
目录
1.常见排序算法
2.排序算法的预定函数
2.1交换函数
2.2测试算法运行时间的函数
3.插入排序
3.1直接插入排序
3.2希尔排序
3.3插入排序的时间复杂度分析
4.总结
1.常见排序算法

我将分别讲解五种排序算法,但是不代表只有五种固定的代码,之后会进行延伸扩展出很多种,每一个我都将分为一篇来进行讲解。但是有些算法的实现将依靠之前的数据结构知识,所以如果想要看懂这些算法的实现需要打牢数据结构的基础。每一个算法都需要一定的测试函数,所以我们需要给定一些测试用例来测试该算法是否适用于每一个算法,我们现在给定一些测试用例:1 2 3 4 5 6 7 8 9;9 8 4 2 4 1 3 7 5 ;2 3 4 3 4 2 7 9 2 4;100 101 195 124 125 129;以上四种测试用例对于不同的排序算法每一个测试用例可能会表现出不同的时间复杂度,每一个测试用例也有每一个测试用例对应的时间复杂度最好的一种或几种算法,我们在实现排序时我们需要一些预定的函数,如:交换函数,测试运行时间的函数等。
2.排序算法的预定函数
2.1交换函数
我们需要两个整型类型的指针(之后我们排序排列的都是整型),我们暂时不用typedef了,否则这样比较难理解。
//交换函数
void Swap(int* a, int* b)
{int p = *a;*a = *b;*b = p;
}2.2测试算法运行时间的函数
这个函数我们权当只是用来测试每一个排序算法最终在实际运用时的表现,我们先进行自己的测试用例的测试,代码无误了再进行实际运用的测试。我们每一次学完这个算法就把这个算法的注释删除即可。
// 测试排序的性能对⽐
void TestOP()
{srand(time(0));const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];a7[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();int begin3 = clock();SelectSort(a3, N);int end3 = clock();int begin4 = clock();HeapSort(a4, N);int end4 = clock();int begin5 = clock();QuickSort(a5, 0, N - 1);int end5 = clock();int begin6 = clock();MergeSort(a6, N);int end6 = clock();int begin7 = clock();BubbleSort(a7, N);int end7 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);printf("SelectSort:%d\n", end3 - begin3);printf("HeapSort:%d\n", end4 - begin4);printf("QuickSort:%d\n", end5 - begin5);printf("MergeSort:%d\n", end6 - begin6);printf("BubbleSort:%d\n", end7 - begin7);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);free(a7);
}上面的排序算法除了冒泡排序外我们之前基本上没学过,所以每一次我们都和冒泡排序进行比较。
3.插入排序
插入排序是把待排序的记录按照其关键码值的大小逐个插入奥一个已经排好序的序列中,直到所有的记录插完为止。就和我们平时打扑克牌的时候进行一张张插入。
3.1直接插入排序
当插入第i(i>=1)个元素是,前面的arr[0]到arr[i-1]已经排好序,我们把arr[i]和arr[i-1]进行比较,我们假设是排成升序,则如果arr[i]>arr[i-1],我们就把arr[i]插入到arr[i-1]后面一位;如果小于或等于,则arr[i-1]后移一位,然后arr[i]和arr[i-2]进行相同的操作,直至arr[0]为止。所以最终代码如下:
//直接插入排序(升序)
void InsertSort1(int* arr, int n)
{for (int i = 0; i < n - 1; i++){//我们把需要比较的数放入tmp中,然后先与第i个数据比较,依次往前进行比较插入int end = i;int tmp = arr[end + 1];while (end >= 0){if (arr[end] > tmp){arr[end + 1] = arr[end];end--;}else{break;}}//如果end=-1我们不能进行数组越界,所以要进行+1操作arr[end + 1] = tmp;}
}
int main()
{int a[] = { 5,3,9,6,2,4,7,1,8 };//int a[] = { 1,2,3,4,5,6,7,8,9 };//int a[] = { 9,8,4,2,4,1,3,7,5 };//int a[] = { 2,3,4,3,4,2,7,9,2,4 };//int a[] = { 100,101,195,124,125,129 };int n = sizeof(a) / sizeof(a[0]);printf("排序之前: ");for (int i = 0; i < n; i++){printf("%d ", a[i]);}InsertSort1(a, n);printf("\n排序之后: ");for (int i = 0; i < n; i++){printf("%d ", a[i]);}return 0;
}由于我们包含的头文件中含有InsertSort所以我定义的时候我们需要把名字改一下(我们需要手动实现,不能用头文件的)





在VS2022编译器上我们需要把之前的函数TestOP注释掉,否则会报错哦。我们发现每一个排序都没有问题,所以代码无误。我们用测试函数测试一下:
![]() 记得把其他没用的函数先注释掉并且把TestOP中的函数名字改为InsertSort1。代码就不放在这里了。我们发现:100000个数据竟然排了13秒的时间,所以这个算法时间复杂度比较高,但是很好理解,所以这个算法只起到教学的作用。
记得把其他没用的函数先注释掉并且把TestOP中的函数名字改为InsertSort1。代码就不放在这里了。我们发现:100000个数据竟然排了13秒的时间,所以这个算法时间复杂度比较高,但是很好理解,所以这个算法只起到教学的作用。
3.2希尔排序
希尔排序又称为缩小增量法。希尔排序法基本思想是:先选定一个整数通常是gap=n/3+1,把待排序的数据分在同一组内,并对每一组内的记录进行排序,然后gap=gap/3+1得到下一个整数,再将数组分成各组,进行插入排序,当gap=1时,就相当于直接插入排序。比如有一组数据为9 1 2 5 7 4 8 6 3 5,这个gap就相当于我们每隔gap个数据进行取数,比如gap=2,就把9 2 7 8 3放入一个数组中,然后在这个数组中进行排序,这样使这个原数组基本上有序了,所以我们之后到gap=1时就会少循环次数,至于gap开始取多少,我们一般取n/3+1,后面我们取gap/3+1这样最后一次一定是直接插入排序,所以能这样进行排序,但是相当于直接插入排序我们的for循环要进行i+=gap吗?并且后面我们交换的时候是直接进行gap+end和end进行交换吗?至于解释我们要看代码才能理解,每一次调整的时候我们也需要让end-=gap,并且我们最外层需要多添加一个while循环来判断gap是否为1,所以最终代码如下:
//希尔排序
void ShellSort1(int* arr, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = arr[end + gap];while (end >= 0){if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end + gap] = tmp;}}
}运行结果为




运行结果没有问题,解决一下为什么里面还是i++,因为我们分为了n/gap组,我们每次都是先从第一个组进行排序,再是第二个组,我们是先排序第一个数组的第一个元素,后面是第二个数组的第一个元素,依次类推,这就是原因,之后我们来测试希尔排序的时间:

可以发现:虽然我们有三层循环,但是时间复杂度降低了很多,所以说希尔排序在特定情况下是一种好的算法。
3.3插入排序的时间复杂度分析
直接插入排序的时间复杂度比较高,我们发现在最好的情况下,就是如果数组已经是升序的情况下,内层循环需要1次,而外层循环需要n次,所以最好情况下的时间复杂度为O(n),但是一般条件下我们是看其最坏的情况下,是降序排列的话,里面循环1+2+3+4+……+n次,而外层循环为n-1次,大概是O(n^2)所以直接插入排序不是很好的算法。但是希尔排序我们无法估计,通过很多测试得到的是其近似值,一般为O(n^1.3),这是平均情况,最好的当然是O(n),我们只要知道希尔排序时比较好的即可,因为gap的值可以取的情况很多,我们无法估计!
4.总结
插入排序理解和实现相对简单,但是之后的排序相对于这个排序更好一些,所以还要多知道一些排序算法更好一点,我们遇到的题目很多,我们也要很多的手段来应对每一种题目,所以继续加油吧!

相关文章:
排序算法1--插入排序
目录 1.常见排序算法 2.排序算法的预定函数 2.1交换函数 2.2测试算法运行时间的函数 3.插入排序 3.1直接插入排序 3.2希尔排序 3.3插入排序的时间复杂度分析 4.总结 1.常见排序算法 我将分别讲解五种排序算法,但是不代表只有五种固定的代码,之后…...

PolarDB数据库表恢复实战指南:通过控制台恢复表的完整操作流程
在数据库运维过程中,表数据恢复是一项常见且关键的操作。本文将详细介绍如何通过阿里云PolarDB控制台从备份中恢复特定表,并通过表重命名操作确保业务平稳过渡。 一、背景介绍 在日常数据库运维中,我们可能会遇到以下场景需要从备份中恢复表: 表数据被误删或损坏需要获取历…...

业之峰与宏图智能战略携手,开启家装数字化新篇章
3月8日,业之峰装饰集团董事长张钧携高管团队与宏图智能董事长庭治宏及核心团队,在业之峰总部隆重举行了战略合作签约仪式,标志着双方将携手探索业之峰的数字化转型之路,共同推动家装行业的变革与发展。 近年来,家装行业…...

matplotlib标题比x,y轴字体大,明明标题字体更大?
原始代码: plt.xlabel(训练轮次(Epochs), fontsize14, fontweightbold, fontpropertieschinese_font) # 设置中文字体、加大、加粗 plt.ylabel(R值, fontsize14, fontweightbold, fontpropertieschinese_font) # 设置中文字体、加大、加粗…...

【云原生】docker 搭建单机PostgreSQL操作详解
目录 一、前言 二、前置准备 2.1 服务器环境 2.2 docker环境 三、docker安装PostgreSQL过程 3.1 获取PostgreSQL镜像 3.2 启动容器 3.2.1 创建数据卷目录 3.2.2 启动pg容器 3.3 客户端测试连接数据库 四、创建数据库与授权 4.1 进入PG容器 4.2 PG常用操作命令 4.2…...

解决 Gradle 构建错误:Could not get unknown property ‘withoutJclOverSlf4J’
解决 Gradle 构建错误:Could not get unknown property ‘withoutJclOverSlf4J’ 在构建 Spring 源码或其他基于 Gradle 的项目时,可能会遇到如下错误: Could not get unknown property withoutJclOverSlf4J for object of type org.gradle…...

免费使用!OpenAI 全量开放 GPT-4o 图像生成能力!
2025年3月26日,OpenAI正式推出GPT-4o原生图像生成功能,这一更新不仅标志着多模态AI技术的重大突破,更引发了全球AI厂商的激烈竞争。从免费用户到企业开发者,从创意设计到科学可视化,GPT-4o正在重塑图像生成的边界。本文…...
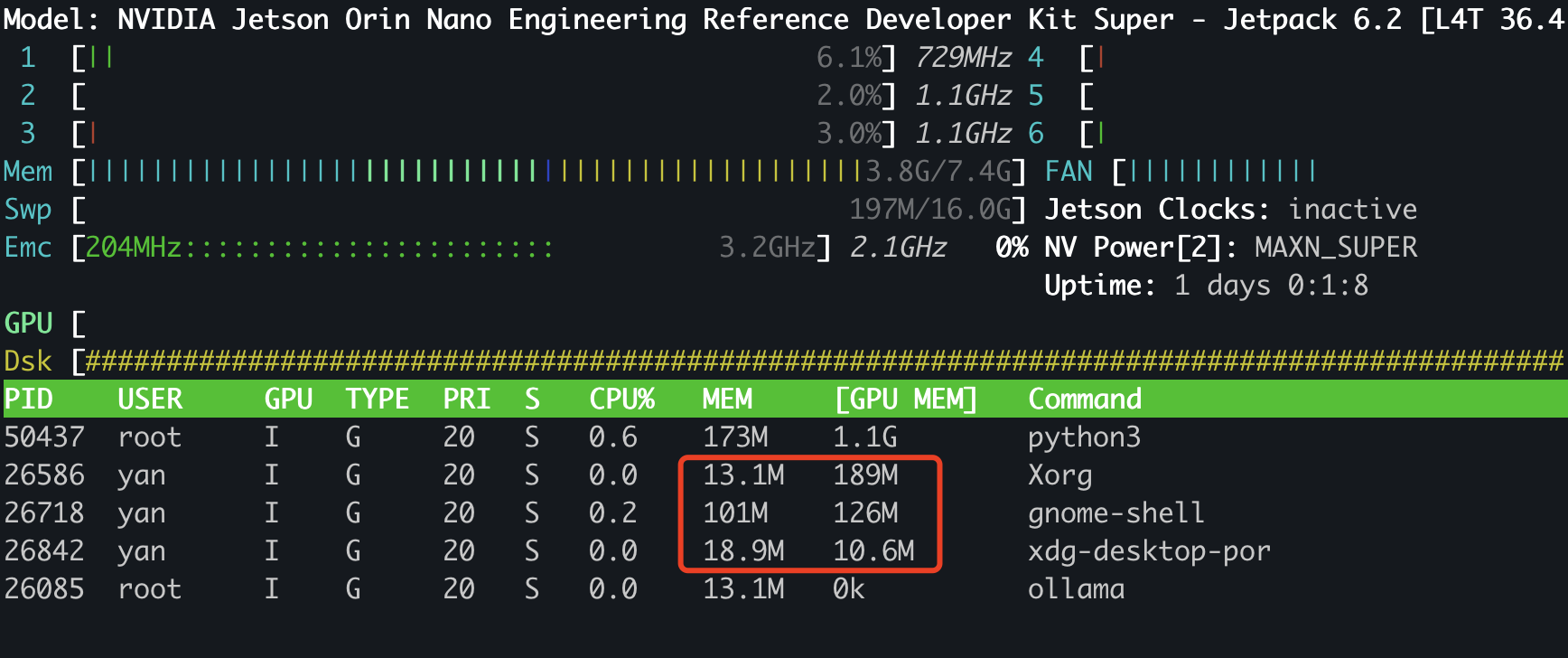
jetson orin nano super AI模型部署之路(三)stable diffusion部署
先看一下部署后的界面和生成的图片。 在jetson orin nano super上部署stable diffusion比较简单,有现成的docker image和代码可用。 docker image拉取 使用的docker image是dustynv/stable-diffusion-webui,对于jetson orin nano super的jetpack6.2来说…...

深入理解:阻塞IO、非阻塞IO、水平触发与边缘触发
深入理解:阻塞IO、非阻塞IO、水平触发与边缘触发 在网络编程和并发处理中,理解不同的 I/O 模型和事件通知机制至关重要。本文将深入探讨阻塞IO(Blocking IO)、非阻塞IO(Non-Blocking IO)、水平触发&#x…...

WebRTC的ICE之TURN协议的交互流程中继转发Relay媒体数据的turnserver的测试
WebRTC的ICE之TURN协议的交互流程和中继转发Relay媒体数据的turnserver的测试 WebRTC的ICE之TURN协议的交互流程中继转发Relay媒体数据的turnserver的测试 WebRTC的ICE之TURN协议的交互流程和中继转发Relay媒体数据的turnserver的测试前言一、TURN协议1、连接Turn Server 流程①…...

HTTP---基础知识
天天开心!!! 文章目录 一、HTTP基本概念1. 什么是HTTP,又有什么用?2. 一次HTTP请求的过程3.HTTP的协议头4.POST和GET的区别5. HTTP状态码6.HTTP的优缺点 二、HTTP的版本演进1.各个版本的应用场景2、注意要点 三、HTTP与…...

Redis6数据结构之List类型
redis的List类型底层结构是双向链表,插入删除时间复杂度O(1)快,查找为O(n)慢。 应用场景:简单队列、最新评论列表、非实时排行榜(定时计算榜单,如笔记本日销榜单)。 常用命令: lpush将一个或多个值从左边…...

DeepSeek接入飞书多维表格,效率起飞!
今天教大家把DeepSeek接入飞书表格使用。 准备工作:安装并登录飞书;可以准备一些要处理的数据,确保数据格式正确,如 Excel、CSV 等,也可直接存储到飞书多维表格。 创建飞书多维表格:打开飞书,点…...

[FGPA基础学习]分秒计数器的制作
分秒计数器设计 本次实验内容为:DE2-115板子上用 Verilog编程实现一个 分秒计数器,并具备按键暂停、按键消抖功能 一、系统架构设计 顶层模块划分 顶层模块(top) ├── 按键消抖模块(key_debounce) ├…...

【Spring Boot 与 Spring Cloud 深度 Mape 之十】体系整合、部署运维与进阶展望
【Spring Boot 与 Spring Cloud 深度 Mape 之十】体系整合、部署运维与进阶展望 #微服务实战 #Docker #Kubernetes #SpringSecurity #OAuth2 #分布式事务 #Seata #ServiceMesh #总结 #SpringCloud #SpringBoot 系列终章:经过前九篇 [【深度 Mape 系列】] 的系统学习…...
】ELK日志管理系统的全面应用)
【商城实战(97)】ELK日志管理系统的全面应用
【商城实战】专栏重磅来袭!这是一份专为开发者与电商从业者打造的超详细指南。从项目基础搭建,运用 uniapp、Element Plus、SpringBoot 搭建商城框架,到用户、商品、订单等核心模块开发,再到性能优化、安全加固、多端适配,乃至运营推广策略,102 章内容层层递进。无论是想…...

高并发系统下的订单号生成服务设计与实现
目录 引言 订单号设计的关键考量因素 基础需求分析 唯一性保障 数据量预估 可读性设计 系统架构考量 分库分表兼容 可扩展性设计 技术选型与比较 性能优化 高可用性保障 实践案例:高并发系统订单号结构设计 结构详解 业务类型标识(2位) 唯一标识部分…...

每日算法-250329
记录今天学习的三道算法题:两道滑动窗口和一道栈的应用。 2904. 最短且字典序最小的美丽子字符串 题目描述 思路 滑动窗口 解题过程 题目要求找到包含 k 个 ‘1’ 的子字符串,并且需要满足两个条件: 最短长度:在所有包含 k 个 …...

向量数据库学习笔记(2) —— pgvector 用法 与 最佳实践
关于向量的基础概念,可以参考:向量数据库学习笔记(1) —— 基础概念-CSDN博客 一、 pgvector简介 pgvector 是一款开源的、基于pg的、向量相似性搜索 插件,将您的向量数据与其他数据统一存储在pg中。支持功能包括&…...

蓝桥杯 之 二分
文章目录 习题肖恩的n次根分巧克力2.卡牌 二分是十分重要的一个算法,常常用于求解一定范围内,找到满足条件的边界值的情况主要分为浮点数二分和整数二分二分问题,最主要是写出这个check函数,这个check函数最主要就是使用模拟的方法…...

从零开始研发GPS接收机连载——18、北斗B1的捕获和跟踪
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 从零开始研发GPS接收机连载——18、北斗B1的捕获和跟踪 B1信号的捕获B1信号的跟踪 前面已经验证了射频能够接收到B1的信号,通过FPGA采集了IQ信号之后能够通过matl…...

sqlalchemy:将mysql切换到OpenGauss
说明 之前python的项目使用的mysql,近期要切换到国产数据库OpenGauss。 之前的方案是fastapisqlalchemy,测试下来发现不用改代码,只要改下配置即可。 切换方案 安装openGauss-connector-python-psycopg2 其代码工程在:https:…...

memtest86检测内存
上次在R730安装万兆网卡的时候,使用过memtest64进行测试。这个操作肯定是有用的,我就用这个方法查出有问题的内存条,及时找商家进行了更换。 但是该方案有个问题,只能锁定部分内存,如下图,只测试到了23G左…...
用于实现图像拼接过程中的时间流逝(timelapse)效果的一个类cv::detail::Timelapser)
OpenCV图像拼接(10)用于实现图像拼接过程中的时间流逝(timelapse)效果的一个类cv::detail::Timelapser
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::detail::Timelapser 是 OpenCV 库中用于实现图像拼接过程中的时间流逝(timelapse)效果的一个类。它通常用于将一系列…...
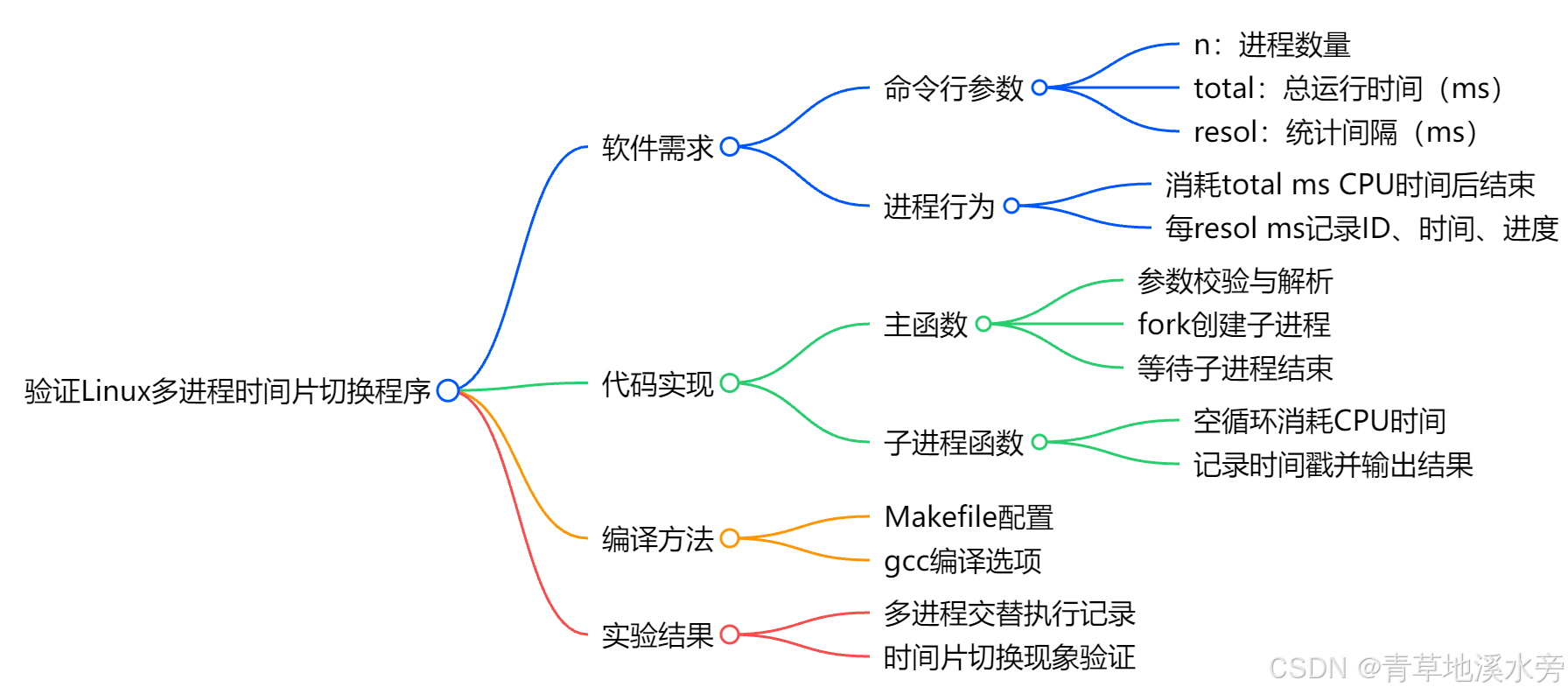
验证linux多进程时间片切换的程序
一、软件需求 在同时运行一个或多个一味消耗 CPU 时间执行处理的进程时,采集以下统计信息。 ・在某一时间点运行在逻辑 CPU 上的进程是哪一个 ・每个进程的运行进度 通过分析这些信息,来确认本章开头对调度器的描述是否正确。实验程序的…...

【Basys3】外设-灯和数码管
灯 约束文件 set_property PACKAGE_PIN W5 [get_ports CLK] set_property PACKAGE_PIN U18 [get_ports rst] set_property PACKAGE_PIN U16 [get_ports {led[0]}] set_property PACKAGE_PIN E19 [get_ports {led[1]}] set_property PACKAGE_PIN U19 [get_ports {led[2]}] set…...

axios文件下载使用后端传递的名称
java后端通过HttpServletResponse 返回文件流 在Content-Disposition中插入文件名 一定要设置Access-Control-Expose-Headers,代表跨域该Content-Disposition返回Header可读,如果没有,前端是取不到Content-Disposition的,可以在统…...

从零开始搭建Anaconda环境
Anaconda是一个流行的Python数据科学平台,包含conda包管理器、Python解释器和大量预装的数据科学工具包。以下是详细的安装和配置步骤: 1. 下载Anaconda 访问Anaconda官方网站 根据你的操作系统(Windows/macOS/Linux)选择相应版本 推荐下载Python 3.x版…...

TDengine 中的命名与边界
简介 本章主要介绍命名的合法字符集和限制规则,这对于正确使用 TDengine,减小报错很重要,这些规则在 SQL 语句中都生效,在使用过程中要注意,避免不必要的错误。 名称命名规则 合法字符:英文字符、数字和…...

软件架构设计中的软件过程模型初识
软件架构设计中的软件过程模型是指导软件开发过程的框架,它们定义了软件开发的不同阶段、活动、任务和角色。结合具体的使用场景,可以更好地理解这些模型如何在实际项目中应用。以下将详细介绍几种常见的软件过程模型,并结合典型场景进行讲解…...