自然语言模型的演变与未来趋势:从规则到多模态智能的跨越
自然语言模型的演变与未来趋势:从规则到多模态智能的跨越
自然语言处理(NLP)作为人工智能领域最具挑战性的分支之一,在过去几十年经历了翻天覆地的变化。从最初基于规则的系统到如今拥有万亿参数的大型语言模型(LLMs),这一技术革新不仅彻底改变了人机交互方式,更在医疗、教育、金融等专业领域展现出巨大潜力。本文将系统梳理语言模型的历史演变轨迹,深入分析当前核心技术架构,全面展示其多元化应用场景,并前瞻性地探讨未来发展趋势及面临的伦理挑战。通过这一全景式分析,我们不仅能够理解语言模型如何从简单统计工具发展为通用智能基座,更能洞察这一技术将如何重塑未来社会的信息处理与知识创造方式。## 语言模型的历史演变轨迹自然语言处理技术的发展历程是一部人类试图用机器理解和生成自然语言的探索史。这一历程大致可分为四个主要阶段:基于规则的早期探索、统计方法的兴起、神经网络革命以及大模型时代的到来。每个阶段的突破都建立在计算能力提升和算法创新的基础上,同时也反映了人们对语言本质认识的不断深化。基于规则的语言系统(1950s-1980s)代表了最早的尝试,语言学家们试图通过编写大量语法规则和词典来让计算机理解人类语言。这一时期的典型代表是Eliza(1966)和SHRDLU(1972)等系统,它们能够在受限领域内进行简单对话。然而,这种方法很快暴露出扩展性差和适应性弱的致命缺陷——语言规则过于复杂多变,难以手工编码覆盖所有情况。当面对真实世界语言的模糊性、歧义性和创造性时,基于规则的系统往往束手无策。20世纪90年代,随着计算能力的提升和电子文本数据的积累,统计语言模型开始崭露头角。这一时期的核心技术是N-gram模型,它通过计算词语序列的联合概率来预测下一个词。例如,给定"人工智能是"这一前缀,模型会统计语料库中后续词(“未来”、"技术"等)的出现频率,选择概率最高的作为预测结果。统计方法的最大优势是数据驱动,不再依赖人工编写规则,而是从大规模文本中自动学习语言规律。IBM的语音识别系统和Google的早期机器翻译都采用了这一范式。然而,N-gram模型受限于上下文窗口固定和数据稀疏问题,难以捕捉长距离依赖关系。21世纪前十年,深度学习技术的引入带来了语言处理的第三次浪潮。循环神经网络(RNN)及其改进版本长短期记忆网络(LSTM)和门控循环单元(GRU)能够处理变长序列数据,通过隐藏状态传递历史信息,显著提升了模型对上下文的理解能力。这一时期的重要里程碑包括Seq2Seq架构(2014)和注意力机制(2015)的提出,它们使机器翻译质量实现了质的飞跃。然而,RNN系列模型仍存在训练效率低和长程依赖捕捉不足的问题,这促使研究者寻求更强大的架构。2017年,Google提出的Transformer架构彻底改变了语言模型的游戏规则。通过自注意力机制,Transformer能够并行处理整个序列,直接建模任意距离的词间关系,同时大幅提升训练效率。这一创新为大型预训练语言模型(PLMs)的诞生铺平了道路。2018年,GPT和BERT的问世标志着语言模型进入"预训练+微调"的新范式——模型首先在无标注海量文本上进行自监督预训练,学习通用语言表示,然后针对特定任务进行微调。这种范式显著降低了NLP应用的门槛,一个模型可适应多种任务。2020年后,语言模型进入大模型时代,参数规模从亿级迅速膨胀至万亿级。GPT-3(1750亿参数)展示了少样本学习和跨任务泛化的惊人能力;ChatGPT(2022)通过人类反馈强化学习(RLHF)实现了与人类意图的对齐;而GPT-4(2023)更进一步,成为支持多模态输入的第一个主流大语言模型。这一阶段最显著的特点是模型能力的涌现性——当规模超过临界点后,模型会突然展现出训练目标中未明确指定的新能力,如复杂推理、代码生成等。大语言模型(LLMs)已从专用工具演变为通用智能基座,正在重塑整个人工智能领域的研究范式和应用生态。表:语言模型发展主要阶段与技术特点| 发展阶段 | 时间跨度 | 代表技术 | 主要特点 | 局限性 ||--------------|--------------|--------------|--------------|------------|| 基于规则 | 1950s-1980s | Eliza, SHRDLU | 依赖语言学知识,规则明确 | 扩展性差,难以处理歧义 || 统计方法 | 1990s-2000s | N-gram模型 | 数据驱动,概率计算 | 上下文窗口固定,数据稀疏 || 神经网络 | 2010s-2017 | RNN/LSTM/GRU | 端到端学习,序列建模 | 训练效率低,长程依赖弱 || Transformer | 2017-2019 | BERT, GPT-1 | 自注意力,并行计算 | 需要大量标注数据微调 || 大模型时代 | 2020至今 | GPT-3/4, ChatGPT | 少样本学习,多模态,涌现能力 | 计算成本高,可解释性差 |## 现代语言模型的核心技术架构当代最先进的自然语言处理系统建立在几项关键技术创新之上,这些技术共同构成了大语言模型的能力基础。理解这些核心技术不仅有助于把握当前语言模型的优势与局限,更能预见未来可能的发展方向。从模型架构到训练方法,从注意力机制到对齐技术,每一项突破都为语言模型注入了新的活力。Transformer架构无疑是现代语言模型最重要的基础发明,它彻底解决了传统序列模型的效率瓶颈。与RNN逐个处理词不同,Transformer通过自注意力机制(Self-Attention)并行分析整个输入序列中所有词之间的关系。具体而言,对每个词,模型计算其与序列中所有其他词的注意力权重,决定在编码该词时应该"关注"哪些上下文词。这种机制有三大优势:一是直接建模长距离依赖,不受序列长度限制;二是高度并行化,充分利用GPU/TPU等硬件加速;三是可解释性,通过分析注意力权重可了解模型关注的重点。实践中,Transformer采用多头注意力,即并行运行多组注意力机制,捕获不同类型的上下文关系,如语法结构、语义关联等。预训练与微调范式是另一个根本性创新,它解决了传统监督学习需要大量标注数据的问题。现代语言模型通常分两阶段训练:首先在海量无标注文本上进行自监督预训练,学习通用语言表示;然后在特定任务的小规模标注数据上进行有监督微调,使模型适应具体应用。预训练阶段的核心目标是语言建模——根据上文预测下一个词(自回归模型如GPT)或根据上下文预测被掩码的词(双向模型如BERT)。这一过程使模型掌握了词汇、语法、常识甚至推理能力。OpenAI的研究表明,预训练模型构建通常包含四个关键阶段:预训练、有监督微调、奖励建模和强化学习,每个阶段需要不同规模的数据集和算法。这种范式显著提高了数据效率,一个预训练模型可通过不同微调服务于多种任务。随着模型规模扩大,扩展法则(Scaling Laws)成为指导大模型开发的重要原则。研究发现,语言模型的性能与训练数据量、模型参数量和计算量呈幂律关系——按特定比例同步增加这三要素,模型能力会持续提升。例如,GPT-3的参数从GPT-2的15亿暴增至1750亿,训练数据也从40GB增至570GB,使其具备了少样本学习能力。截至2023年,顶尖模型的参数量级已突破万亿,如GPT-4据估计有约1.8万亿参数。这种扩展带来了涌现能力(Emergent Abilities)——当模型规模超过临界阈值后,会突然展现出训练目标中未明确指定的新能力,如数学推理、代码生成等。然而,单纯扩大规模也面临边际效益递减和能耗剧增的问题,促使研究者探索更高效的架构和训练方法。人类反馈强化学习(RLHF)是ChatGPT等对话系统实现自然交互的关键技术。传统语言模型仅通过预测下一个词训练,可能生成不准确、有害或无用的内容。RLHF则在预训练基础上引入人类偏好数据,通过强化学习调整模型行为。具体分为三步:首先用人工标注的示范数据微调模型;然后训练奖励模型预测人类对回答的评分;最后通过近端策略优化(PPO)等算法最大化预期奖励。这一过程使模型学会遵循指令、拒绝不当请求、承认知识边界等符合人类期望的行为。RLHF虽然大幅提升了交互质量,但也面临标注成本高和奖励黑客(Reward Hacking)等挑战——模型可能找到欺骗奖励函数的方式,而非真正理解意图。多模态扩展代表了语言模型的最新发展方向,使模型能够理解和生成跨媒介内容。GPT-4 Vision等系统不仅能处理文本,还可分析图像、音频甚至视频。技术实现上主要有两种路径:一是联合训练,将不同模态的编码器(如CNN处理图像,Transformer处理文本)连接到一个共享表示空间;二是适配器方法,保持语言模型核心不变,添加轻量级模块处理新模态。多模态能力极大扩展了应用场景,如根据医学影像生成诊断报告、分析设计草图生成代码等。然而,跨模态理解仍面临语义鸿沟——不同媒介的信息表达方式差异巨大,模型容易产生幻觉或误解。表:现代语言模型关键技术比较| 技术要素 | 核心创新 | 代表应用 | 优势 | 挑战 ||--------------|--------------|--------------|----------|----------|| Transformer架构 | 自注意力机制,并行处理 | BERT, GPT系列 | 长距离依赖,高效训练 | 计算复杂度随序列长度平方增长 || 预训练+微调 | 自监督学习,迁移学习 | 大多数现代LLM | 数据高效,多任务通用 | 微调需要领域适配 || 扩展法则 | 模型/数据/计算同步增长 | GPT-3, PaLM | 涌现能力,少样本学习 | 资源消耗大,边际效益递减 || RLHF | 人类偏好对齐 | ChatGPT, Claude | 符合伦理,交互自然 | 标注成本高,奖励黑客风险 || 多模态 | 跨媒介统一表示 | GPT
相关文章:

自然语言模型的演变与未来趋势:从规则到多模态智能的跨越
自然语言模型的演变与未来趋势:从规则到多模态智能的跨越 自然语言处理(NLP)作为人工智能领域最具挑战性的分支之一,在过去几十年经历了翻天覆地的变化。从最初基于规则的系统到如今拥有万亿参数的大型语言模型(LLMs),这一技术革新不仅彻底改…...
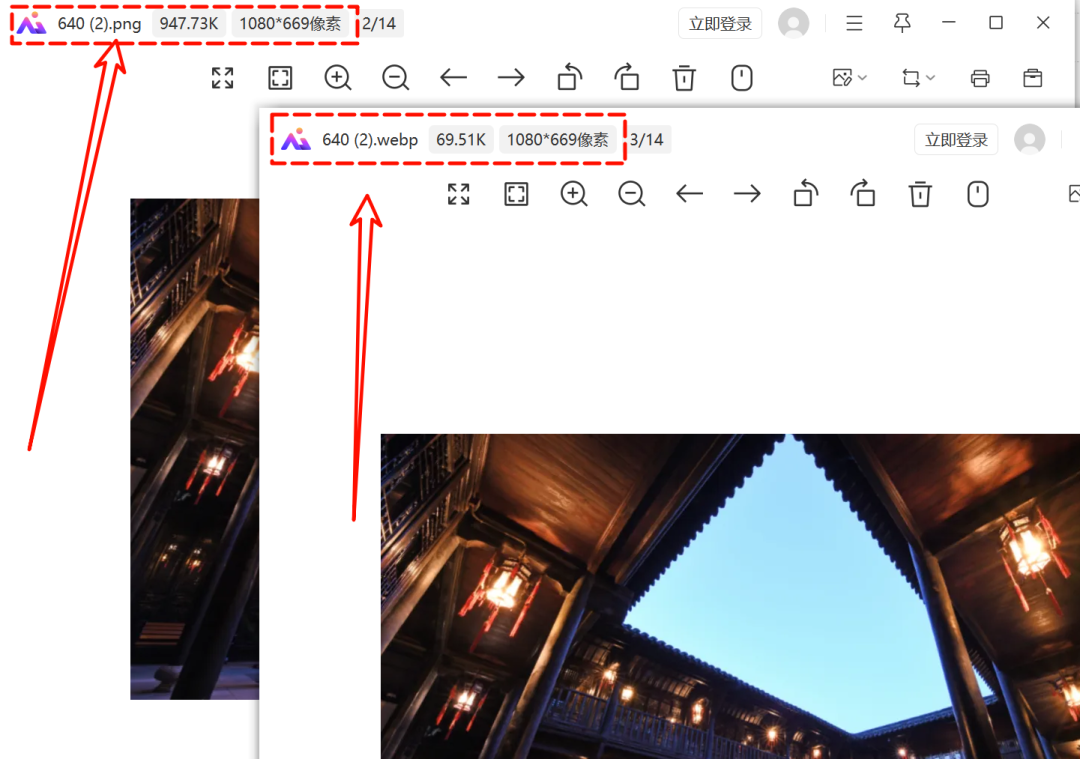
集多功能为一体的软件,支持批量操作。
今天我给大家分享一个超实用的小工具,真的是太好用了!这个软件是吾爱大神无知灰灰制作的,它能直接一键把webp格式的图片转换成png格式。 webp转为png 一键操作,支持压缩 其实,作者最近在工作中经常遇到webp格式的图片…...

linux压缩指令
今天我们来了解一下linux压缩指令,压缩是我们文件传输的一种重要手段,对此,我们是必须学习压缩指令的,那么话不多说,来看. 1.grep过滤查找,管道符,“|”,表示将前一个命令的处理结果输出传递给后面的命令处理。 基本语法&#x…...

C++细节知识for面试
1. linux上C程序可用的栈和堆大小分别是多少,为什么栈大小小于堆? 1. 栈(Stack)大小 栈默认为8MB,可修改。 为什么是这个大小: 安全性:限制栈大小可防止无限递归或过深的函数调用导致内存…...

Appium中元素定位的注意点
应用场景 了解这些注意点可以以后在出错误的时候,更快速的定位问题原因。 示例 使用 find_element_by_xx 或 find_elements_by_xx 的方法,分别传入一个没有的“特征“会是什么结果呢? 核心代码 driver.find_element_by_id("xxx") drive…...

污水处理厂人员定位方案-UWB免布线高精度定位
1. 方案概述 本方案采用免布线UWB基站与北斗卫星定位融合技术,结合UWBGNSS双模定位工卡,实现污水处理厂室内外人员高精度定位(亚米级)。系统通过低功耗4G传输数据,支持实时位置监控、电子围栏、聚集预警、轨迹回放等功…...
)
蓝桥刷题note11(好数)
1,好数 一个整数如果按从低位到高位的顺序,奇数位 (个位、百位、万位 ⋯⋯ ) 上的数字是奇数,偶数位 (十位、千位、十万位 ⋯⋯ ) 上的数字是偶数,我们就称之为 “好数”。 给定一个正整数 NN,请计算从 1 到 NN 一共…...
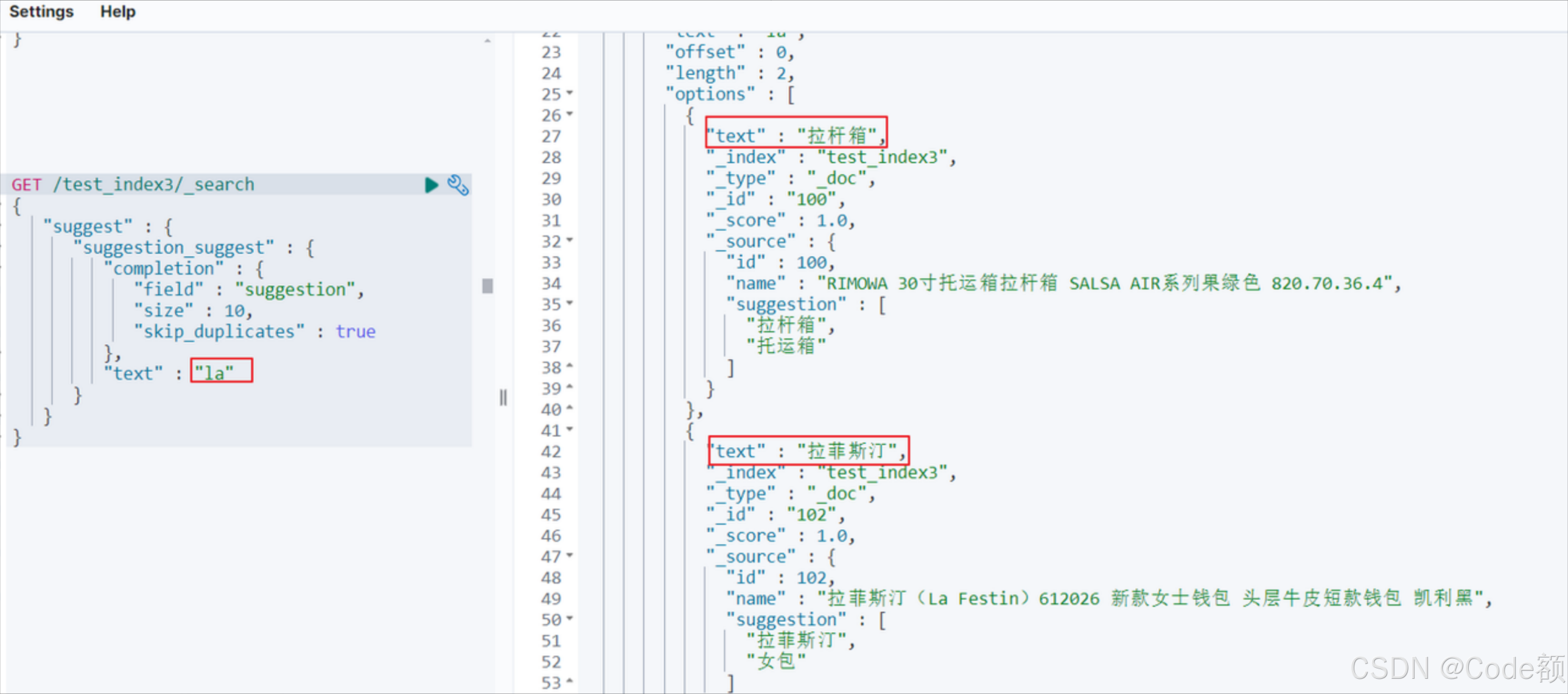
Elasticsearch 高级
Elasticsearch 高级 建议阅读顺序: Elasticsearch 入门Elasticsearch 搜索Elasticsearch 搜索高级Elasticsearch高级(本文) 1. nested 类型 1.1 介绍 Elasticsearch 中的 nested 类型允许你在文档内存储复杂的数据结构,比如一个…...

SQL Server 2022常见问题解答
以下是SQL Server 2022的常见问题解答,按主题分类整理: 一、安装与升级 SQL Server 2022的系统要求是什么? 支持的操作系统:Windows Server 2016及以上、Linux(Ubuntu 20.04/22.04, RHEL 8/9等)。内存:至少4GB(建议8GB+)。磁盘空间:6GB以上,具体取决于安装组件。如何…...

基于LLM的实时信息检索汇总分析系统
基于用户需求和技术发展趋势,设计基于LLM的实时信息检索汇总分析系统,方案如下: 一、系统架构设计 1. 分层多模态数据采集层 动态渲染适配引擎 采用混合爬虫技术: 静态页面:优化Scrapy框架,集成XPath模板库…...

C语言笔记数据结构(链表)
希望文章能对你有所帮助,有不足的地方请在评论区留言指正,一起交流学习! 目录 1.链表 1.1 链表概念和组成 1.2 链表的分类 1.3 顺序表和链表 2.单链表(无头单向不循环链表) 2.1 结点的创建 2.2 创建新的结点 2.3 单链表的打印 2.4 尾…...

Leetcode 两数相除
✅ LeetCode 29. 两数相除 — 思路总览 🧩 题目要求 给定两个整数 dividend 和 divisor,实现 整数除法,不能使用乘法 *、除法 / 和取余 % 运算符。 要求返回的结果应为 向零截断的整数商,即: 正数向下取整…...
)
C++ 初阶总复习 (16~30)
C 初阶总复习 (16~30) 目的16. 2009. volatile关键字的作用17. 2010.什么是多态 简单介绍下C的多态18. 2011. 什么是虚函数 介绍下C中虚函数的原理19. 2012 构造函数可以是虚函数嘛20. 2013.析构函数一定要是虚函数嘛?21. 2015. 什么是C中的虚…...

Koordinator-Metric查询
以CollectAllPodMetricsLast()举例,看看koordinator怎样使用tsdb进行查询。 CollectAllPodMetricsLast() GenerateQueryParamsLast()传入metric采集间隔2倍时间调用CollectAllPodMetrics()func CollectAllPodMetricsLast(statesInformer statesinformer.StatesInformer, metr…...

人工智能图像识别Scala介绍
Scala 一.Scala 简介 Scala即Scalable Language(可伸缩的语言),Scala 语言是由 Martin Odersky 等人在 2003 年开发的,并于 2004 年首次发布。意味着这种语言设计上支持大规模软件开发,是一门多范式的编程语言。 Sc…...

PCL 点云多平面探测
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 这里实现了一种点云多平面探测的算法,该算法使用基于鲁棒统计的方法进行平面补丁检测。该算法具体过程:首先将点云细分为更小的块(使用二分法),然后尝试为每个点云块匹配一个平面。如果平面通过了鲁棒平面性测试…...

npm i 出现的网络问题
npm i 出现的网络问题 解决方案: npm config list 查看.npmrc文件中是否配置了proxy删除.npmrc文件中的proxy,保存。重新执行npm i命令。 顺便说说解决这个问题的心里路程 每次安装vue的环境的时候,经常遇到npm安装一些插件或者是依赖的时…...

C++中使用CopyFromRecordset将记录集拷贝到excel中时,如果记录集为0个,函数崩溃,是什么原因
文章目录 原因分析解决方案1. 检查记录集是否为空2. 安全调用COM方法3.进行异常捕获4. 替代方案:手动处理空数据 总结 在C中使用CopyFromRecordset将空记录集(0条记录)复制到Excel时崩溃的原因及解决方法如下: 原因分析 空记录集…...

代码随想录算法训练营--打卡day3
复习:标注感叹号的需要在电脑上重新做几遍 一.两两交换链表中的节点!! 1.题目链接 24. 两两交换链表中的节点 - 力扣(LeetCode) 2.思路 画图 3.代码 class Solution {public ListNode swapPairs(ListNode head) …...

c#的.Net Framework 的console 项目找不到System.Window.Forms 引用
首先确保是建立的.Net Framework 的console 项目,然后天健reference 应用找不到System.Windows.Forms 引用 打开对应的csproj 文件 在第一个PropertyGroup下添加 <UseWindowsForms>true</UseWindowsForms> 然后在第一个ItemGroup 下添加 <Reference Incl…...

蓝桥杯嵌入式学习笔记
用博客来记录一下参加蓝桥杯嵌入式第十六届省赛的学习经历 工具环境准备cubemx配置外部高速时钟使能设置串口时钟配置项目配置 keil配置烧录方式注意代码规范头文件配置 模块ledcubemx配置keil代码实现点亮一只灯实现具体操作的灯,以及点亮还是熄灭 按键cubemx配置k…...

zookeeper详细介绍以及使用
Zookeeper 是一个开源的分布式协调服务,提供了一个高效的分布式数据一致性解决方案。它的主要作用是维护集群中各个节点之间的状态信息,协调节点之间的工作,并处理节点宕机等故障情况。Zookeeper 的核心功能包括数据发布/订阅、分布式锁、集群…...

Blender多摄像机怎么指定相机渲染图像
如题目所说,当blender的场景里面有摄像机的时候,按F12可以预览渲染结果,但是当有多个摄像机的时候就不知道使用哪个进行渲染了。 之前在网上没有找到方法,就用笨方法,把所有的摄像机删除,然后设置自己需要…...

Redis场景问题1:缓存穿透
Redis 缓存穿透是指在缓存系统(如 Redis)中,当客户端请求的数据既不在缓存中,也不在数据库中时,每次请求都会直接穿透缓存访问数据库,从而给数据库带来巨大压力,甚至可能导致数据库崩溃。下面为…...

CSS 如何设置父元素的透明度而不影响子元素的透明度
CSS 如何设置父元素的透明度而不影响子元素的透明度 在 CSS 中,设置父元素的透明度(如通过 opacity 属性)会影响所有子元素的透明度,因为 opacity 是作用于整个元素及其内容的。如果想让父元素透明但不影响子元素的透明度&#x…...

Java的string默认值
在Java中,String类型的默认值取决于其定义和实例化的方式。 以下是关于String默认值的详细说明 未实例化的String变量 如果定义一个String变量但未对其进行实例化(即未使用new关键字或直接赋值),其默认值为:ml-search[null]。这…...

从 MySQL 到时序数据库 TDengine:Zendure 如何实现高效储能数据管理?
小T导读:TDengine 助力广州疆海科技有限公司高效完成储能业务的数据分析任务,轻松应对海量功率、电能及输入输出数据的实时统计与分析,并以接近 1 : 20 的数据文件压缩率大幅降低存储成本。此外,taosX 强大的 transform 功能帮助用…...
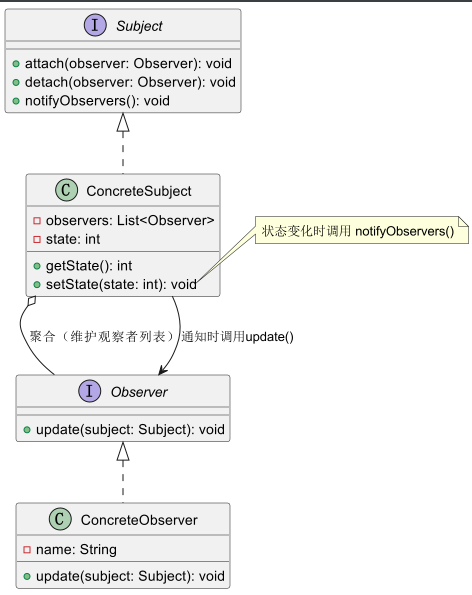
观察者模式:解耦对象间的依赖关系
观察者模式:解耦对象间的依赖关系 JDK 中曾直接提供对观察者模式的支持,但因其设计局限性,现已被标记为“过时”(Deprecated)。不过,观察者模式的思想在 JDK 的事件处理、spring框架等仍有广泛应用。下面我…...

windows第二十章 单文档应用程序
文章目录 单文档定义新建一个单文档应用程序单文档应用程序组成:APP应用程序类框架类(窗口类)视图类(窗口类,属于框架的子窗口)文档类(对数据进行保存读取操作) 直接用向导创建单文档…...

通信协议之串口
文章目录 简介电平标准串口参数及时序USART与UART过程引脚配置 简介 点对点,只能两设备通信只需单向的数据传输时,可以只接一根通信线当电平标准不一致时,需要加电平转换芯片(一般从控制器出来的是信号是TTL电平)地位…...