《强化学习基础概念:四大模型与两大损失》
- 强化学习基础概念
- 一、策略模型
- 1. 策略的定义
- 2. 策略的作用
- 3.策略模型
- 二、价值模型
- 1. 价值函数的定义
- (1)状态值函数(State Value Function)
- (2)动作值函数(Action Value Function)
- 2. 价值函数的作用
- (1)评估策略
- (2)指导策略改进
- (3)帮助决策
- 3. 价值模型
- 三、奖励模型
- 奖励模型的定义
- 奖励模型的作用
- 奖励模型的类型
- 奖励模型总结
- 四、参考模型
- 参考模型的定义
- 参考模型的应用
- 参考模型的作用
- 参考模型的总结
- 五、策略损失
- 1. 策略损失的定义
- 2. 常见的策略损失形式
- (1)策略梯度损失(Policy Gradient Loss)
- (2)PPO(Proximal Policy Optimization)损失
- (3)DPO(Direct Preference Optimization)损失
- 3. 策略损失的作用
- 4. 策略损失的优化
- 策略梯度损失的计算
- 策略梯度损失的优化
- 策略梯度损失与深度学习梯度下降的对比
- 5. 策略损失的总结
- 六价值损失
- 价值损失的定义
- 常见的价值损失形式
- 价值损失的作用
- 价值损失的优化
- 总结
- 七、基于策略的强化学习优化目标
- 1. 基于策略的强化学习的优化目标
- 2. 策略梯度定理
- 3. 策略损失函数
- 4. 策略优化方法
- (1)REINFORCE算法
- (2)PPO(Proximal Policy Optimization)
- (3)Actor-Critic方法
- 5. 总结
强化学习基础概念
首先介绍四个模型和两个损失
一、策略模型
什么是强化学习的策略:
在强化学习中,策略(Policy)是核心概念之一,它定义了智能体(Agent)在给定状态下如何选择动作。
1. 策略的定义
策略是一个函数,它将状态映射到动作的概率分布。用数学符号表示为 π ( a ∣ s ) \pi(a|s) π(a∣s),其中 s s s 表示状态, a a a 表示动作, π ( a ∣ s ) \pi(a|s) π(a∣s) 表示在状态 s s s 下选择动作 a a a 的概率。策略决定了智能体在环境中如何行动,从而影响其获得的奖励和最终的学习效果。
- 确定性策略(Deterministic Policy):对于每个状态 s s s,策略 π \pi π 映射到一个唯一确定的动作 a a a,即 π ( s ) = a \pi(s) = a π(s)=a。在这种情况下,智能体在给定状态下总是选择同一个动作。
- 随机性策略(Stochastic Policy):对于每个状态 s s s,策略 π \pi π 给出一个动作的概率分布 π ( a ∣ s ) \pi(a|s) π(a∣s),智能体根据这个概率分布随机选择动作。随机性策略在探索环境中非常有用,因为它允许智能体尝试不同的动作,从而发现更好的行为模式。
2. 策略的作用
- 决策依据:策略是智能体在环境中做出决策的依据。智能体根据当前状态和策略来选择动作,从而与环境进行交互。
- 影响轨迹:策略决定了智能体在环境中的行动轨迹(Trajectory),即状态和动作的序列。不同的策略会导致不同的轨迹,进而影响智能体获得的奖励。
- 学习目标:在强化学习中,学习的目标是找到一个最优策略 π ∗ \pi^* π∗,使得智能体在该策略下能够获得最大的累积奖励。通过不断调整策略,智能体可以逐步改进其行为,从而更好地适应环境。
3.策略模型
我们可以使用大模型来表示策略模型,比如使用一个神经网络来表示策略模型,在PPO算法中,我们可以将语言模型当作策略,它是待优化的模型,参与参数更新
二、价值模型
价值用于衡量智能体在特定状态下或采取特定动作时的长期收益。价值函数是强化学习算法中用于评估策略优劣的关键工具,通过价值函数,智能体可以判断在给定策略下,不同状态或动作的相对重要性。
1. 价值函数的定义
价值函数(Value Function)是衡量智能体在给定策略下,从某个状态或状态-动作对开始,能够获得的长期累积奖励的期望值。根据其定义的侧重点不同,价值函数主要分为以下两种类型:
(1)状态值函数(State Value Function)
状态值函数 V π ( s ) V_\pi(s) Vπ(s) 表示在策略 π \pi π 下,从状态 s s s 开始,智能体能够获得的累积奖励的期望值。数学上可以表示为:
V π ( s ) = E π [ ∑ t = 0 ∞ γ t R t + 1 ∣ S t = s ] V_\pi(s) = \mathbb{E}_\pi\left[\sum_{t=0}^{\infty} \gamma^t R_{t+1} \mid S_t = s\right] Vπ(s)=Eπ[t=0∑∞γtRt+1∣St=s]
其中:
-
R t + 1 R_{t+1} Rt+1 是在时间步 t + 1 t+1 t+1 获得的奖励。
-
γ \gamma γ 是折扣因子( 0 ≤ γ < 1 0 \leq \gamma < 1 0≤γ<1),用于衡量未来奖励的当前价值, γ \gamma γ 越接近 1,未来奖励的当前价值越高。
-
E π \mathbb{E}_\pi Eπ 表示在策略 π \pi π 下的期望。
状态值函数反映了在给定策略下,某个状态的“价值”或“重要性”。值越高,说明从该状态开始,智能体能够获得更多的累积奖励。
(2)动作值函数(Action Value Function)
动作值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 表示在策略 π \pi π 下,从状态 s s s 开始并采取动作 a a a 后,智能体能够获得的累积奖励的期望值。数学上可以表示为:
Q π ( s , a ) = E π [ ∑ t = 0 ∞ γ t R t + 1 ∣ S t = s , A t = a ] Q_\pi(s, a) = \mathbb{E}_\pi\left[\sum_{t=0}^{\infty} \gamma^t R_{t+1} \mid S_t = s, A_t = a\right] Qπ(s,a)=Eπ[t=0∑∞γtRt+1∣St=s,At=a]
动作值函数不仅考虑了当前状态,还考虑了当前采取的动作,因此它能够更细致地评估在特定状态下采取不同动作的优劣。
2. 价值函数的作用
价值函数在强化学习中具有以下重要作用:
(1)评估策略
通过计算状态值函数 V π ( s ) V_\pi(s) Vπ(s) 或动作值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a),可以评估当前策略 π \pi π 的性能。如果一个策略在所有状态下的价值函数值都较高,说明该策略能够使智能体获得更多的累积奖励,是一个较好的策略。
(2)指导策略改进
价值函数可以为策略的改进提供指导。例如,在策略迭代(Policy Iteration)算法中,通过计算状态值函数来评估当前策略,然后根据状态值函数来改进策略,使得智能体在每个状态下都选择价值最高的动作。
在值函数迭代(Value Iteration)算法中,直接通过动作值函数来更新策略,选择使 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 最大的动作作为新的策略。
(3)帮助决策
在实际决策过程中,智能体可以根据动作值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 来选择动作。例如,在 ϵ \epsilon ϵ-贪婪策略中,智能体以 1 − ϵ 1 - \epsilon 1−ϵ 的概率选择使 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 最大的动作,以 ϵ \epsilon ϵ 的概率随机选择动作,从而在探索和利用之间进行平衡。
3. 价值模型
在PPO算法中我们可以使用大模型来作为价值模型,它可以计算当前动作和状态的期望回报,可有奖励模型和策略模型初始化而成,参与参数更新
三、奖励模型
奖励模型(Reward Model)是强化学习中一个关键的组成部分,它通过为智能体的行为或输出分配奖励值,来指导智能体的学习方向。以下是关于奖励模型的详细介绍:
- 单步奖励 :根据当前状态、动作和下一个状态由奖励模型得到的即时奖励,评估当前动作的好坏
- 累计奖励:一条完整轨迹的单步奖励之和
- 折扣奖励:平衡即时奖励和长期奖励之间的关系,使得智能体在决策时不经要考虑当前的奖励,还要考虑未来的潜在奖励。
- 轨迹:轨迹由一系列的状态、动作组成,代表一次完整的采样,即大模型生成一条完整的句子。
奖励模型的定义
奖励模型是一种用于量化评估智能体行为或输出质量的模型,其核心任务是根据给定的输入和反馈来预测奖励值。在强化学习中,奖励模型的输出通常是一个标量值,表示对某个行为或输出的奖励,这个奖励值用于指导策略模型的优化。
奖励模型的作用
- 指导策略优化:奖励模型的输出作为强化学习算法中的奖励信号,直接指导策略模型的优化方向。例如,在RLHF(Reinforcement Learning from Human Feedback)中,奖励模型通过整合人类反馈,帮助强化学习算法更有效地优化策略。
- 评估输出质量:奖励模型可以对智能体的输出进行质量评估,判断其是否符合人类偏好或任务要求。
- 替代环境奖励:在一些场景中,环境提供的奖励信号可能不够准确或难以获取,奖励模型可以替代环境奖励,成为策略模型优化的唯一奖励来源。
奖励模型的类型
常见的奖励模型主要有以下两种形式:
- 结果奖励模型(Outcome Reward Model,ORM):这种模型关注的是最终结果的质量,即对生成的输出整体进行打分评估。例如,在文本生成任务中,ORM会对生成的完整文本进行评分。
- 过程奖励模型(Process Reward Model,PRM):与ORM不同,PRM不仅关注最终结果,还会在生成过程中对每一步进行打分,是一种更细粒度的奖励模型。
奖励模型总结
计算当前的动作的即时奖励,不参与参数更新。
四、参考模型
在强化学习和人工智能领域,参考模型(Reference Model) 是一种用于辅助训练和优化的模型,它通常作为基准或对比标准,帮助指导策略模型的训练方向。以下是参考模型的详细解释:
参考模型的定义
参考模型是一种预训练好的模型,通常用于在训练过程中提供额外的约束或指导。它可以帮助策略模型(Actor Model)在优化过程中保持稳定,避免过度偏离初始的策略或生成不符合要求的结果。
参考模型的应用
在强化学习中,参考模型的应用场景主要包括以下几种:
- 约束策略更新:在RLHF(Reinforcement Learning from Human Feedback)和PPO(Proximal Policy Optimization)等算法中,参考模型通常是一个经过监督微调(SFT)的模型,用于计算KL散度(Kullback-Leibler Divergence),以约束策略模型的更新,防止其偏离初始策略。
- 对比学习:在DPO(Direct Preference Optimization)等算法中,参考模型用于对比策略模型的输出,帮助优化策略模型,使其生成的结果更符合人类偏好。
- 提供基线:在一些强化学习算法中,参考模型可以提供一个基线性能,用于评估策略模型的改进程度。
参考模型的作用
- 保持稳定性:通过约束策略模型的更新,参考模型可以帮助训练过程保持稳定,避免策略模型在优化过程中出现剧烈波动。
- 提高对齐性:参考模型可以作为人类偏好的代理,帮助策略模型生成更符合人类期望的结果。
- 简化训练流程:在某些算法中,参考模型可以替代复杂的奖励模型或价值函数,从而简化训练流程。
参考模型的总结
参考模型是用来限制策略模型在更新时不让其偏离基础模型太远,不参与参数更新,由策略模型进行初始化。
五、策略损失
在强化学习中,策略损失(Policy Loss) 是衡量当前策略性能的一个关键指标,它反映了当前策略与最优策略之间的差距。策略损失通常用于指导策略模型(Policy Model)的优化,通过最小化策略损失,可以逐步改进策略,使其能够获得更高的累积奖励。
1. 策略损失的定义
策略损失是通过某种方式量化当前策略 π θ \pi_\theta πθ 与最优策略 π ∗ \pi^* π∗ 之间的差异。在不同的强化学习算法中,策略损失的定义和计算方式可能有所不同,但其核心目标是通过优化策略参数 θ \theta θ 来最大化累积奖励的期望值。
2. 常见的策略损失形式
以下是几种常见的策略损失形式及其计算方式:
(1)策略梯度损失(Policy Gradient Loss)
策略梯度方法通过最大化累积奖励的期望值来优化策略。策略梯度损失通常定义为:
L ( θ ) = − E π θ [ ∑ t = 0 T γ t R t + 1 ] L(\theta) = -\mathbb{E}_{\pi_\theta}\left[\sum_{t=0}^{T} \gamma^t R_{t+1}\right] L(θ)=−Eπθ[t=0∑TγtRt+1]
其中:
- π θ \pi_\theta πθ 是当前策略。
- R t + 1 R_{t+1} Rt+1 是在时间步 t + 1 t+1 t+1 获得的奖励。
- γ \gamma γ 是折扣因子。
- T T T 是轨迹的长度。
策略梯度损失的目标是最小化这个损失函数,从而最大化累积奖励的期望值。通过计算这个损失函数的梯度,并使用梯度上升方法更新策略参数 θ \theta θ,可以逐步改进策略。
(2)PPO(Proximal Policy Optimization)损失
PPO 是一种改进的策略梯度方法,它通过引入截断的概率比来防止策略更新过大,从而提高训练的稳定性。PPO 的策略损失定义为:
L C L I P ( θ ) = E t [ min ( π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A t , clip ( π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) , 1 − ϵ , 1 + ϵ ) A t ) ] L^{CLIP}(\theta) = \mathbb{E}_t\left[\min\left(\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} A_t, \text{clip}\left(\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}, 1 - \epsilon, 1 + \epsilon\right) A_t\right)\right] LCLIP(θ)=Et[min(πθold(at∣st)πθ(at∣st)At,clip(πθold(at∣st)πθ(at∣st),1−ϵ,1+ϵ)At)]
其中:
- π θ o l d \pi_{\theta_{old}} πθold 是上一次更新的策略。
- A t A_t At 是优势函数(Advantage Function),表示在状态 s t s_t st 下采取动作 a t a_t at 的优势。
- ϵ \epsilon ϵ 是一个超参数,用于控制截断的范围。
PPO 损失通过限制策略更新的幅度,防止策略在每次更新时发生过大的变化,从而提高训练的稳定性和收敛速度。
(3)DPO(Direct Preference Optimization)损失
DPO 是一种基于人类偏好的强化学习方法,它直接优化策略以生成更符合人类偏好的输出。DPO 的策略损失定义为:
L D P O ( θ ) = E s , a , a ′ [ log ( π θ ( a ∣ s ) π θ ( a ∣ s ) + π θ ( a ′ ∣ s ) ) ] L^{DPO}(\theta) = \mathbb{E}_{s, a, a'}\left[\log\left(\frac{\pi_\theta(a|s)}{\pi_\theta(a|s) + \pi_\theta(a'|s)}\right)\right] LDPO(θ)=Es,a,a′[log(πθ(a∣s)+πθ(a′∣s)πθ(a∣s))]
其中:
- s s s 是状态。
- a a a 和 a ′ a' a′ 是两个动作,其中 a a a 是更受人类偏好的动作。
- π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 是策略在状态 s s s 下选择动作 a a a 的概率。
DPO 损失通过优化策略,使其更倾向于选择人类偏好的动作,从而提高生成结果的质量。
3. 策略损失的作用
策略损失在强化学习中具有以下重要作用:
- 指导策略优化:通过最小化策略损失,可以逐步改进策略,使其能够获得更高的累积奖励。
- 衡量策略性能:策略损失可以作为衡量当前策略性能的一个指标,通过观察策略损失的变化,可以判断策略是否在逐步优化。
- 控制策略更新:在一些算法中,策略损失可以通过引入约束或截断机制,控制策略更新的幅度,防止策略在每次更新时发生过大的变化,从而提高训练的稳定性。
4. 策略损失的优化
优化策略损失是强化学习中的一个核心问题,常见的优化方法包括:
- 梯度上升:通过计算策略损失的梯度,并使用梯度上升方法更新策略参数 θ \theta θ,从而最大化累积奖励的期望值。
- 截断概率比:在 PPO 中,通过引入截断的概率比,限制策略更新的幅度,从而提高训练的稳定性。
- 对比学习:在 DPO 中,通过对比两个动作的概率,优化策略使其更倾向于选择人类偏好的动作。
策略梯度损失的计算
策略梯度损失的计算涉及以下步骤:
- 采样轨迹:从当前策略 π θ \pi_\theta πθ 中采样一条轨迹 τ = ( s 0 , a 0 , r 1 , s 1 , a 1 , r 2 , … , s T , a T , r T + 1 ) \tau = (s_0, a_0, r_1, s_1, a_1, r_2, \ldots, s_T, a_T, r_{T+1}) τ=(s0,a0,r1,s1,a1,r2,…,sT,aT,rT+1)。
- 计算累积奖励:对于每个时间步 t t t,计算从 t t t 开始到轨迹结束的累积奖励:
G t = ∑ k = t T γ k − t R k + 1 G_t = \sum_{k=t}^{T} \gamma^{k-t} R_{k+1} Gt=k=t∑Tγk−tRk+1
- 计算梯度:对于每个时间步 t t t,计算策略梯度损失函数的梯度:
∇ θ L ( θ ) = − ∇ θ log π θ ( a t ∣ s t ) ⋅ G t \nabla_\theta L(\theta) = -\nabla_\theta \log \pi_\theta(a_t|s_t) \cdot G_t ∇θL(θ)=−∇θlogπθ(at∣st)⋅Gt
- 更新策略参数:沿着梯度的方向更新策略参数 θ \theta θ:
θ ← θ + α ∇ θ L ( θ ) \theta \leftarrow \theta + \alpha \nabla_\theta L(\theta) θ←θ+α∇θL(θ)
其中 α \alpha α 是学习率。
策略梯度损失的优化
策略梯度方法通过不断采样轨迹、计算梯度和更新策略参数,从而逐步改进策略,使其能够获得更高的累积奖励。这个过程可以看作是在策略空间中进行梯度下降,不断接近策略梯度损失函数的最低点。
策略梯度损失与深度学习梯度下降的对比
- 目标不同:深度学习中的梯度下降是为了最小化损失函数,而策略梯度是为了最大化累积奖励的期望值。
- 梯度方向不同:深度学习中的梯度下降是沿着梯度的反方向更新参数,而策略梯度是沿着梯度的方向更新参数。
- 采样方式不同:深度学习中的梯度下降通常使用整个数据集或其子集来计算梯度,而策略梯度是通过采样轨迹来计算梯度。
5. 策略损失的总结
策略损失是强化学习中用于衡量当前策略性能的一个关键指标,通过最小化策略损失,可以逐步改进策略,使其能够获得更高的累积奖励。不同的强化学习算法中,策略损失的定义和计算方式可能有所不同,但其核心目标是通过优化策略参数,提高策略的性能。
六价值损失
在强化学习中,价值损失(Value Loss) 是用于衡量价值函数估计的准确性的损失函数。它通常用于优化价值函数,使其能够更准确地预测在给定策略下从某个状态或状态-动作对开始的累积奖励的期望值。
价值损失的定义
价值损失函数是针对价值函数(如状态值函数 V π ( s ) V_\pi(s) Vπ(s) 或动作值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a))的优化目标。它的目的是最小化价值函数的估计值与真实值之间的差异。常见的价值损失函数包括均方误差(Mean Squared Error, MSE)和二元交叉熵损失(Binary Cross-Entropy Loss)。
常见的价值损失形式
-
均方误差损失(MSE Loss):
均方误差损失是最常用的价值损失函数之一,它计算价值函数的估计值与目标值之间的平方差的均值。对于状态值函数 V π ( s ) V_\pi(s) Vπ(s),其损失函数可以表示为:
L V ( θ V ) = E s [ ( V π ( s ) − V θ ( s ) ) 2 ] L_V(\theta_V) = \mathbb{E}_s\left[(V_\pi(s) - V_\theta(s))^2\right] LV(θV)=Es[(Vπ(s)−Vθ(s))2]
其中 V θ ( s ) V_\theta(s) Vθ(s) 是价值函数的估计值, V π ( s ) V_\pi(s) Vπ(s) 是目标值(通常是通过贝尔曼方程计算得到的)。 -
二元交叉熵损失(Binary Cross-Entropy Loss):
二元交叉熵损失在某些情况下也被用于价值函数的优化,尤其是在处理概率分布或分类问题时。它能够提供更稳定的梯度,尤其是在目标值为0或1的情况下。
价值损失的作用
价值损失在强化学习中具有以下重要作用:
- 优化价值函数:通过最小化价值损失,可以优化价值函数的参数,使其能够更准确地预测累积奖励的期望值。
- 指导策略优化:准确的价值函数可以为策略优化提供更好的指导,帮助策略模型更有效地选择动作。
价值损失的优化
优化价值损失通常涉及以下步骤:
- 采样数据:从环境中采样状态或状态-动作对及其对应的奖励和下一个状态。
- 计算目标值:根据贝尔曼方程计算目标值,例如对于状态值函数:
V π ( s ) = R t + 1 + γ V π ( S t + 1 ) V_\pi(s) = R_{t+1} + \gamma V_\pi(S_{t+1}) Vπ(s)=Rt+1+γVπ(St+1) - 计算损失:根据选择的价值损失函数(如MSE或二元交叉熵损失)计算当前估计值与目标值之间的损失。
- 更新参数:通过反向传播计算损失函数的梯度,并更新价值函数的参数。
总结
价值损失是强化学习中用于优化价值函数的关键工具。通过最小化价值损失,可以提高价值函数的准确性,从而为策略优化提供更好的指导。常见的价值损失函数包括均方误差损失和二元交叉熵损失,它们各有优缺点,适用于不同的场景。
七、基于策略的强化学习优化目标
1. 基于策略的强化学习的优化目标
基于策略的强化学习的优化目标是最大化累积奖励的期望值。具体来说,优化目标可以表示为:
max π E π [ ∑ t = 0 ∞ γ t R t + 1 ] \max_\pi \mathbb{E}_\pi\left[\sum_{t=0}^{\infty} \gamma^t R_{t+1}\right] πmaxEπ[t=0∑∞γtRt+1]
公式解释:
- π \pi π 是策略函数,表示在给定状态下选择动作的概率分布。
- R t + 1 R_{t+1} Rt+1 是在时间步 t + 1 t+1 t+1 获得的奖励。
- γ \gamma γ 是折扣因子,用于衡量未来奖励的当前价值,取值范围为 0 ≤ γ < 1 0 \leq \gamma < 1 0≤γ<1。
- E π \mathbb{E}_\pi Eπ 表示在策略 π \pi π 下的期望,即考虑所有可能的轨迹及其概率。
具体含义:
这个公式表示我们希望找到一个策略 π \pi π,使得从初始状态开始,按照该策略行动所获得的累积奖励的期望值最大化。累积奖励是所有未来奖励的折扣和,折扣因子 γ \gamma γ 用于减少未来奖励的权重,使得近期奖励比远期奖励更重要。
2. 策略梯度定理
为了实现上述优化目标,基于策略的方法通常使用策略梯度定理(Policy Gradient Theorem)。策略梯度定理提供了策略性能的梯度的解析表达式,使得可以通过梯度上升方法优化策略参数。
策略梯度定理表明,策略性能的梯度可以表示为:
∇ θ J ( θ ) = E π [ ∑ t = 0 ∞ γ t ∇ θ log π θ ( a t ∣ s t ) ⋅ G t ] \nabla_\theta J(\theta) = \mathbb{E}_\pi\left[\sum_{t=0}^{\infty} \gamma^t \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot G_t\right] ∇θJ(θ)=Eπ[t=0∑∞γt∇θlogπθ(at∣st)⋅Gt]
公式解释:
- J ( θ ) J(\theta) J(θ) 是策略性能,即累积奖励的期望值。
- π θ ( a t ∣ s t ) \pi_\theta(a_t|s_t) πθ(at∣st) 是在策略 π \pi π 下,状态 s t s_t st 下选择动作 a t a_t at 的概率。
- G t G_t Gt 是从时间步 t t t 开始的累积奖励:
G t = ∑ k = t ∞ γ k − t R k + 1 G_t = \sum_{k=t}^{\infty} \gamma^{k-t} R_{k+1} Gt=k=t∑∞γk−tRk+1
- ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta \log \pi_\theta(a_t|s_t) ∇θlogπθ(at∣st) 是策略函数的对数概率关于参数 θ \theta θ 的梯度。
具体含义:
这个公式表示策略性能的梯度可以通过采样轨迹来估计。对于每条采样的轨迹 τ = ( s 0 , a 0 , r 1 , s 1 , a 1 , r 2 , … ) \tau = (s_0, a_0, r_1, s_1, a_1, r_2, \ldots) τ=(s0,a0,r1,s1,a1,r2,…),可以计算每个时间步 t t t 的梯度:
∇ θ J ( θ ) ≈ ∑ t = 0 T γ t ∇ θ log π θ ( a t ∣ s t ) ⋅ G t \nabla_\theta J(\theta) \approx \sum_{t=0}^{T} \gamma^t \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot G_t ∇θJ(θ)≈t=0∑Tγt∇θlogπθ(at∣st)⋅Gt
其中 T T T 是轨迹的长度。通过这个梯度,我们可以使用梯度上升方法更新策略参数 θ \theta θ,从而逐步改进策略。
3. 策略损失函数
在实际实现中,策略梯度方法通常会定义一个策略损失函数(Policy Loss Function),并通过最小化这个损失函数来优化策略。策略损失函数通常定义为:
L ( θ ) = − E π [ ∑ t = 0 ∞ γ t log π θ ( a t ∣ s t ) ⋅ G t ] L(\theta) = -\mathbb{E}_\pi\left[\sum_{t=0}^{\infty} \gamma^t \log \pi_\theta(a_t|s_t) \cdot G_t\right] L(θ)=−Eπ[t=0∑∞γtlogπθ(at∣st)⋅Gt]
公式解释:
- log π θ ( a t ∣ s t ) \log \pi_\theta(a_t|s_t) logπθ(at∣st) 是策略函数的对数概率。
- G t G_t Gt 是从时间步 t t t 开始的累积奖励。
- E π \mathbb{E}_\pi Eπ 表示在策略 π \pi π 下的期望。
具体含义:
这个损失函数是策略梯度的负值。通过最小化这个损失函数,可以最大化策略性能 J ( θ ) J(\theta) J(θ)。在实际操作中,我们通常使用采样轨迹来近似计算这个期望值。
4. 策略优化方法
基于策略的强化学习方法通过优化策略损失函数来改进策略。以下是一些常见的策略优化方法:
(1)REINFORCE算法
REINFORCE算法是最简单的策略梯度方法之一,它直接使用采样轨迹来估计策略梯度。REINFORCE算法的更新规则为:
θ ← θ + α ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) ⋅ G t \theta \leftarrow \theta + \alpha \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot G_t θ←θ+αt=0∑T∇θlogπθ(at∣st)⋅Gt
公式解释:
- α \alpha α 是学习率,控制参数更新的步长。
- T T T 是轨迹的长度,表示采样轨迹的结束时间步。
具体含义:
REINFORCE算法通过采样一条完整的轨迹,计算每个时间步的梯度 ∇ θ log π θ ( a t ∣ s t ) ⋅ G t \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot G_t ∇θlogπθ(at∣st)⋅Gt,并累加这些梯度来更新策略参数 θ \theta θ。这种方法简单易实现,但其方差较高,可能导致训练不稳定。
(2)PPO(Proximal Policy Optimization)
PPO是一种改进的策略梯度方法,通过引入剪切机制(Clipping Mechanism)来限制策略更新的幅度,从而提高训练的稳定性。PPO的策略损失函数定义为:
L C L I P ( θ ) = E t [ min ( r t ( θ ) A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) ] L^{CLIP}(\theta) = \mathbb{E}_t\left[\min\left(r_t(\theta) A_t, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) A_t\right)\right] LCLIP(θ)=Et[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
公式解释:
- r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st) 是新策略与旧策略的概率比率。
- A t A_t At 是优势函数,表示在状态 s t s_t st 下采取动作 a t a_t at 的优势。
- ϵ \epsilon ϵ 是一个超参数,通常取值为0.1或0.2。
- clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) clip(rt(θ),1−ϵ,1+ϵ) 是对概率比率 r t ( θ ) r_t(\theta) rt(θ) 的剪切操作,限制其在 [ 1 − ϵ , 1 + ϵ ] [1 - \epsilon, 1 + \epsilon] [1−ϵ,1+ϵ] 范围内。
具体含义:
PPO通过剪切机制,限制新策略与旧策略之间的概率比率,防止策略更新过大。这样可以提高训练的稳定性和收敛速度。PPO的目标函数结合了未剪切和剪切后的概率比率,取两者的最小值,从而在优化过程中保持策略更新的稳定性。
(3)Actor-Critic方法
Actor-Critic方法结合了策略梯度方法和价值函数方法的优点。其中,Actor负责优化策略,Critic负责估计价值函数。通过Critic提供的价值估计,可以降低策略梯度的方差,从而提高训练的稳定性。
5. 总结
基于策略的强化学习的优化目标是最大化累积奖励的期望值。通过策略梯度定理,可以计算策略性能的梯度,并使用梯度上升方法优化策略参数。常见的策略优化方法包括REINFORCE算法、PPO算法和Actor-Critic方法。这些方法通过不同的策略损失函数和优化机制,逐步改进策略,使其能够获得更高的累积奖励。
相关文章:

《强化学习基础概念:四大模型与两大损失》
强化学习基础概念一、策略模型1. 策略的定义2. 策略的作用3.策略模型 二、价值模型1. 价值函数的定义(1)状态值函数(State Value Function)(2)动作值函数(Action Value Function) 2.…...

Headless Chrome 优化:减少内存占用与提速技巧
在当今数据驱动的时代,爬虫技术在各行各业扮演着重要角色。传统的爬虫方法往往因为界面渲染和资源消耗过高而无法满足大规模数据采集的需求。本文将深度剖析 Headless Chrome 的优化方案,重点探讨如何利用代理 IP、Cookie 和 User-Agent 设置实现内存占用…...

知识就是力量——HELLO GAME WORD!
你好!游戏世界! 简介环境配置前期准备好文章介绍创建头像小功能组件安装本地中文字库HSV颜色空间音频生成空白的音频 游戏UI开发加载动画注册登录界面UI界面第一版第二版 第一个游戏(贪吃蛇)第二个游戏(俄罗斯方块&…...

电脑连不上手机热点会出现的小bug
一、问题展示 注意: 不要打开 隐藏热点 否则他就会在电脑上 找不到自己的热点 二、解决办法 把隐藏热点打开即可...

unity 做一个圆形分比图
// 在其他脚本中控制多段进度 using System.Collections.Generic; using UnityEngine;public class GameManager : MonoBehaviour {public MultiCircleProgress circleProgress;void Start(){// 初始化数据circleProgress.segments new List<MultiCircleProgress.ProgressS…...
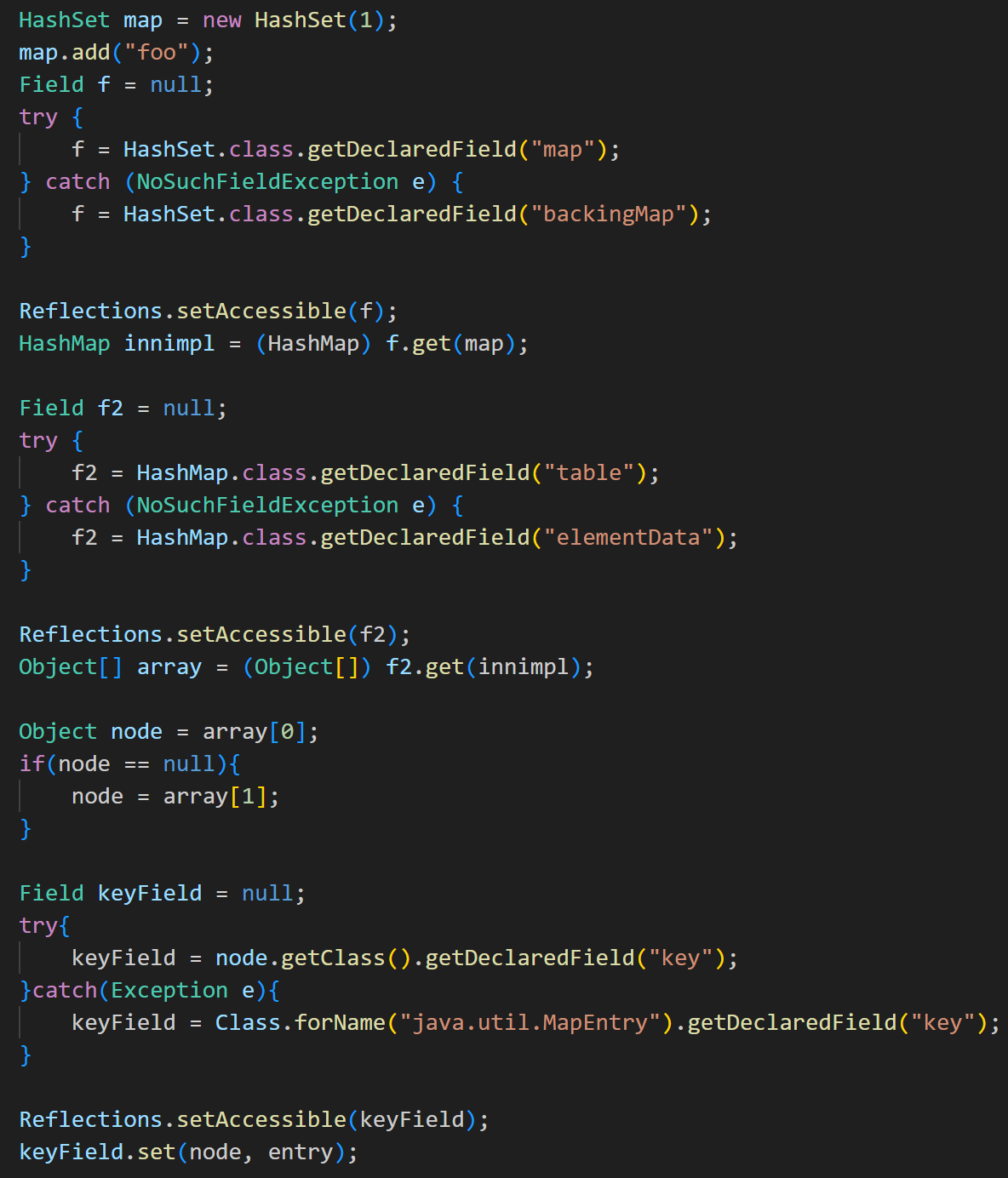
JAVA反序列化深入学习(八):CommonsCollections6
与CC5相似: 在 CC5 中使用了 TiedMapEntry#toString 来触发 LazyMap#get在 CC6 中是通过 TiedMapEntry#hashCode 来触发 LazyMap#get 之前看到了 hashcode 方法也会调用 getValue() 方法然后调用到其中 map 的 get 方法触发 LazyMap,那重点就在于如何在反…...

鸿蒙项目源码-外卖点餐-原创!原创!原创!
鸿蒙外卖点餐外卖平台项目源码含文档包运行成功ArkTS语言。 我半个月写的原创作品,请尊重原创。 原创作品,盗版必究!!! 原创作品,盗版必究!!! 原创作品,盗版…...

计算机二级WPS Office第十一套WPS演示
解题过程...

React程序打包与部署
===================== 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 为生产环境准备React应用最小化和打包环境变量错误处理部署到托管服务部署到Netlify探索高级主题:Hooks、Su…...

ubuntu 创建新用户
给实验室服务器建用户,会担心除了基本的用户创建以外有没有别的没考虑到的。问了一下似乎没有,就按最基础的来就可以 # linux 自带的基础命令 # 创建用户,指定 home,设置 owner,设置密码 sudo useradd -d /home/abc a…...
106.从中序与后序遍历序列构造二叉树(▲)
代码随想录刷题day53|(二叉树篇)106.从中序与后序遍历序列构造二叉树(▲
目录 一、二叉树理论知识 二、构造二叉树思路 2.1 构造二叉树流程(给定中序后序 2.2 整体步骤 2.3 递归思路 2.4 给定前序和后序 三、相关算法题目 四、易错点 一、二叉树理论知识 详见:代码随想录刷题day34|(二叉树篇)二…...

Leetcode算法方法总结
1. 双指针法解决链表/数组题目 只要数组有序,就要想到双指针做法。还有二分法 回文串一般也会用到双指针,回文串的长度由于可能是奇数也可能是偶数,所以在寻找时,既需要寻找奇数长度的回文串,也需要寻找偶数长度的回文…...

全包圆玛奇朵样板间亮相,极简咖啡风引领家装新潮流
在追求品质生活的当下,家居装修风格的选择成为了许多消费者关注的焦点。近日,全包圆家居装饰有限公司精心打造的玛奇朵样板间正式对外开放,以其独特的咖啡色系极简风格,为家装市场带来了一股清新的潮流。玛奇朵样板间不仅展示了全…...

小红书多账号运营:如何实现每个账号独立 IP发布文章
一、多账号管理与 IP 隔离方案 1.电脑端实现:推荐使用指纹浏览器工具,为每个账号生成独立设备指纹(模拟不同 MAC 地址、内存等信息),并搭配兔子ip代理等服务商的 SOCKS5 代理,实现一机多开且每个账号独立 …...

大数据学习(92)-spark详解
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

免费下载 | 2025年网络安全报告
报告总结了2024年的网络安全态势,并对2025年的安全趋势进行了预测和分析。报告涵盖了勒索软件、信息窃取软件、云安全、物联网设备安全等多个领域的安全事件和趋势,并提供了安全建议和最佳实践。 一、报告背景与目的 主题:2024企业信息安全峰…...

《Android低内存设备性能优化实战:深度解析Dalvik虚拟机参数调优》
1. 痛点分析:低内存设备的性能困局 现象描述:大应用运行时频繁GC导致卡顿 根本原因:Dalvik默认内存参数与硬件资源不匹配 解决方向:动态调整堆内存参数以平衡性能与资源消耗 2. 核心调优参数全景解析 关键参数矩阵࿱…...

RCE--解法
目录 一、利用php伪协议 1.代码分析 2.过程 3.结果 编辑 4.防御手段 二、RCE(php中点的构造) 1.代码分析 2.过程 一、利用php伪协议 <?php error_reporting(0); if(isset($_GET[c])){$c $_GET[c];if(!preg_match("/flag|system|php|cat|sort…...

JAVA反序列化深入学习(九):CommonsCollections7与CC链总结
CC7 依旧是寻找 LazyMap 的触发点 CC6使用了 HashSet而CC6使用了 Hashtable JAVA环境 java version "1.8.0_74" Java(TM) SE Runtime Environment (build 1.8.0_74-b02) Java HotSpot(TM) 64-Bit Server VM (build 25.74-b02, mixed mode) 依赖版本 Apache Commons …...

HTML元素小卖部:表单元素 vs 表格元素选购指南
刚学HTML的同学经常把表单和表格搞混,其实它们就像超市里的食品区和日用品区——虽然都在同一个超市,但用途完全不同。今天带你3分钟分清这两大元素家族! 一、表单元素家族(食品区:收集用户输入) 1. <i…...

如何使用 Bash 脚本自动化清理 Nacos 日志文件
如何使用 Bash 脚本自动化清理 Nacos 日志文件 在现代的分布式系统中,Nacos 作为服务发现、配置管理和动态服务管理的核心组件,其日志文件的管理显得尤为重要。随着系统的运行,日志文件会不断累积,占用大量磁盘空间。如果不及时清理,可能会导致磁盘空间不足,影响系统性能…...

群体智能优化算法-算术优化算法(Arithmetic Optimization Algorithm, AOA,含Matlab源代码)
摘要 算术优化算法(Arithmetic Optimization Algorithm, AOA)是一种新颖的群体智能优化算法,灵感来源于加、减、乘、除四种基本算术运算。在优化过程中,AOA 通过乘除操作实现全局探索,通过加减操作强化局部开发&#…...

Redis6数据结构之String类型
redis的String类型是存储字符串类型的key-value。 应用场景:验证码、计数器(包括点赞数、文章/视频浏览数)、订单重复提交、用户登录信息、商品详情。 常用命令: set/get设置和获取key-valuemset/mget批量设置或获取多个key的…...

uniapp中的流式输出
一、完整代码展示 目前大多数的ai对话都是流式输出,也就是对话是一个字或者多个字逐一进行显示的下面是一个完整的流式显示程序,包含的用户的消息发出和ai的消息回复 <template><view class"chat-container"><view class&quo…...
)
理解 C++ 中的顶层 const 与底层 const(二十四)
1. 示例解析 下面的代码展示了不同 const 限定符的组合及其含义: int i 0; int *const p1 &i; // p1 是一个常量指针:p1 本身不可改变(顶层 const),但 *p1 所指的 int 可修改 const int ci 42; …...

Linux之数据链路层
Linux之数据链路层 一.以太网1.1以太网帧格式1.2MAC地址1.3MTU 二.ARP协议2.1ARP协议工作流程2.2ARP协议格式 三.NAT技术四.代理服务4.1正向代理4.2反向代理 五.四大层的学习总结 一.以太网 在我们学习完了网络层后我们接下来就要进入数据链路层的学习了,在学习完网…...

如何在 vue 渲染百万行数据,vxe-table 渲染百万行数据性能对比,超大量百万级表格渲染
vxe-table 渲染百万行数据性能对比,超大量百万级表格渲染;如何在 vue 渲染百万行数据;当在开发项目时,遇到需要流畅支持百万级数据的表格时, vxe-table 就可以非常合适了,不仅支持强大的功能,虚…...

std::reference_wrapper 和 std::function的详细介绍
关于 std::reference_wrapper 和 std::function 的详细介绍及具体测试用例: 1. std::reference_wrapper(引用包装器) 核心功能 包装引用:将引用转换为可拷贝、可赋值的对象支持隐式转换:可自动转换为原始引用类型容器…...

如何封装一个上传文件组件
#今天用el-upload感到很多不方便,遂决定自己封装一个。注:本文不提供表面的按钮样式和文件上传成功后的样式,需要自己创建。本文仅介绍逻辑函数# 1,准备几个表面用来指引上传的元素 2,创造统一的隐藏文件上传输入框&…...

MySQL-5.7.37安装配置(Windows)
1.下载MySQL-5.7.37软件包并解压 2.配置本地环境变量 打开任务栏 搜索高级系统设置 新建MySQL的环境变量 然后在path中添加%MYSQL_HOME%\bin 3.在MySQL-5.7.37解压的文件夹下新建my.ini文件并输入以下内容 [mysqld]#端口号port 3306#mysql-5.7.27-winx64的路径basedirC:\mysq…...