《Python实战进阶》No37: 强化学习入门加餐版3 之 Q-Learning算法可视化升级
连续第4篇文章写Q-Learning算法及可视化
Q-Learning强化学习算法在迷宫寻路中的应用
引言
强化学习是机器学习的一个重要分支,其核心理念是通过与环境的交互来学习最优策略。在上三篇文章中,《Python实战进阶》No37: 强化学习入门:Q-Learning 与 DQN-加餐版1 Q-Learning算法可视化 https://editor.csdn.net/md/?articleId=146573878 这篇文章特意专门写了一个算法可视化,仔细推敲后觉得不够清晰,本篇文章将升级可视化代码,让大家可以非常过瘾的看一个Q-Learning算法可视化过程,可以说是有史以来几乎最有趣的一个Q-Learning可视化算法案例,把算法原理和过程完全可视化实现,并且输出所有算法过程到日志文件中,值得一看。
以下部分详细介绍一种新的基于Q-Learning算法的迷宫寻路实现,该项目不仅展示了强化学习的基本原理,还通过可视化展示了学习过程,使算法的运作过程更加直观。
文章末尾有完整代码、运行输出截图、算法过程Log日志和配置环境说明。
可视化算法程序运行视频:
Q-Learning算法可视化-升级版
Q-Learning算法原理
基本概念
Q-Learning是一种无模型(model-free)的强化学习算法,它通过学习状态-动作对的价值(Q值)来找到最优策略。核心思想可以概括为:
- 状态(State): 环境的当前情况,在迷宫问题中就是智能体当前的位置
- 动作(Action): 智能体可以采取的行为,在迷宫中是上、下、左、右移动
- 奖励(Reward): 环境对动作的反馈,如移动一步的惩罚、到达目标的奖励
- Q值(Q-value): 在特定状态下采取特定动作的预期累积奖励
Q值更新公式
Q-Learning的核心是通过不断更新Q值表来学习最优策略:
Q(s,a) = Q(s,a) + α[R + γ·max Q(s',a') - Q(s,a)]
其中:
- Q(s,a): 在状态s下采取动作a的Q值
- α: 学习率,控制新信息对已有Q值的影响程度
- R: 即时奖励
- γ: 折扣因子,平衡当前奖励与未来奖励的重要性
- max Q(s’,a’): 下一状态的最大Q值
项目架构与实现
本项目使用Python实现,包含三个主要类:
- MazeEnv: 迷宫环境类
- QLearningAgent: Q-Learning学习智能体
- PygameHandler: 可视化界面管理类
迷宫环境 (MazeEnv)
迷宫环境负责定义迷宫结构、状态转换规则和奖励机制:
class MazeEnv:def __init__(self):# 定义8x8的迷宫,'.'表示可通行,'#'表示墙壁,'G'表示目标self.maze = [['.', '.', '.', '#', '.', '.', '.', '#'],# ...其他行...['.', '.', '.', '#', '.', '#', 'G', '#']]self.start = (0, 0) # 起点self.goal = (7, 6) # 终点self.actions = [(0, 1), (0, -1), (1, 0), (-1, 0)] # 右、左、下、上
关键方法包括:
- reset(): 重置环境到初始状态
- step(action): 执行一个动作并返回新状态、奖励和是否完成
- is_wall/is_goal: 判断位置是否为墙或目标
Q-Learning智能体 (QLearningAgent)
智能体是算法的核心,负责学习策略和做出决策:
class QLearningAgent:def __init__(self, env, learning_rate=0.1, discount_factor=0.9, epsilon=0.1):self.env = envself.q_table = {} # Q值表,存储(状态,动作)对应的Q值self.learning_rate = learning_rate # 学习率αself.discount_factor = discount_factor # 折扣因子γself.epsilon = epsilon # 探索率ε
智能体的主要方法包括:
- get_action(state): 根据ε-贪婪策略选择动作
- update_q_table(state, action, reward, next_state): 根据Q-Learning公式更新Q值
- update_optimal_path(): 根据当前Q值计算最优路径
- train(): 训练智能体
- test(): 测试已训练的智能体
可视化组件 (PygameHandler)
为了直观展示学习过程,使用Pygame库实现了可视化:
class PygameHandler:def __init__(self, env, agent, is_testing=False):# 初始化窗口和参数self.fps = 50 if not is_testing else 20 # 训练和测试阶段使用不同的速度
可视化包括:
- 迷宫的图形表示(墙壁、通道、目标)
- 智能体的位置
- 当前Q值和最优路径
- 实时Q值更新过程和计算公式
算法流程详解
训练过程
训练阶段是Q-Learning的核心,主要步骤如下:
- 初始化Q表: 将所有(状态,动作)对应的Q值初始化为0
- 回合循环: 执行预定数量的训练回合
a. 重置环境到初始状态
b. 在当前状态下根据ε-贪婪策略选择动作
c. 执行动作,获取新状态和奖励
d. 更新Q值
e. 转移到新状态,如果到达目标或最大步数则结束当前回合 - 探索与利用平衡: 通过ε-贪婪策略平衡探索与利用,确保既能尝试新路径又能应用已学知识
def train(self, num_episodes=1000, visualize=False):for episode in range(num_episodes):state = self.env.reset()done = Falsewhile not done:action, action_type, action_index = self.get_action(state)next_state, reward, done = self.env.step(action)self.update_q_table(state, action, reward, next_state)state = next_state

Q值更新
Q值更新是算法的核心步骤,它通过时序差分学习来改进价值估计:
def update_q_table(self, state, action, reward, next_state):old_q = self.get_q_value(state, action)max_next_q = max([self.get_q_value(next_state, a) for a in self.env.actions])new_q = old_q + self.learning_rate * (reward + self.discount_factor * max_next_q - old_q)self.q_table[(state, action)] = new_q
这里的步骤是:
- 获取当前状态-动作对的Q值
- 计算下一状态的最大Q值
- 根据公式更新当前Q值
- 存储新Q值到Q表
最优路径计算
智能体不断学习的过程中,会计算并更新从起点到终点的最优路径:
def update_optimal_path(self):path = []state = self.env.startwhile state != self.env.goal and step_count < max_steps:path.append(state)q_values = [self.get_q_value(state, action) for action in self.env.actions]action = self.env.actions[np.argmax(q_values)]next_state = (state[0] + action[0], state[1] + action[1])# 检查合法性,更新状态# ...self.optimal_path = path
此方法通过贪婪策略(始终选择Q值最高的动作)来构建从起点到终点的路径。
程序CMD窗口输出:
Hello from the pygame community. https://www.pygame.org/contribute.html
训练日志将保存至: logs/q_learning_20250328_232238.txt
回合 1/1000, 步数: 147, 总奖励: -136
回合 101/1000, 步数: 16, 总奖励: -5
回合 201/1000, 步数: 14, 总奖励: -3
回合 301/1000, 步数: 17, 总奖励: -6
回合 401/1000, 步数: 23, 总奖励: -12
回合 501/1000, 步数: 15, 总奖励: -4
回合 601/1000, 步数: 16, 总奖励: -5
回合 701/1000, 步数: 17, 总奖励: -6
回合 801/1000, 步数: 15, 总奖励: -4
回合 901/1000, 步数: 13, 总奖励: -2
测试日志已保存至: logs/q_learning_test_20250328_232247.txt
路径: [(0, 0), (0, 1), (0, 2), (1, 2), (2, 2), (3, 2), (4, 2), (5, 2), (5, 3), (5, 4), (6, 4), (6, 5), (6, 6), (7, 6)]
可视化效果与交互
项目的一大亮点是使用Pygame实现了实时可视化,让学习过程变得透明和直观:
- 迷宫界面:直观显示迷宫结构,用不同颜色表示墙壁、通路、目标
- 智能体位置:使用红色圆点表示智能体当前位置
- Q值显示:在每个格子内显示四个方向的Q值
- 最优路径:用黄色标记最优路径的格子,紫色线条连接路径上的点
- 信息面板:右侧实时显示状态、选择的动作和Q值更新过程
训练阶段自动进行,测试阶段允许用户按键控制速度,体验智能体的决策过程。
关键参数分析
Q-Learning算法的性能受多个参数影响:
- 学习率(α=0.1):控制新信息的学习速度,过大可能导致不稳定,过小则学习过慢
- 折扣因子(γ=0.9):决定未来奖励的重要性,接近1时更看重长期收益
- 探索率(ε=0.1):控制探索与利用的平衡,较高值促进探索,较低值促进利用
- 奖励设置:移动一步-1分,到达目标+10分,引导智能体寻找最短路径
应用扩展与启示
Q-Learning算法不仅适用于迷宫问题,还可以应用于:
- 机器人导航:在未知环境中学习最优路径
- 游戏AI:学习玩游戏的最优策略
- 资源调度:在动态变化的环境中优化资源分配
- 推荐系统:学习用户偏好,提供个性化推荐
本项目的实现提供了强化学习算法的直观展示,帮助理解其工作原理和应用场景。
总结
通过本项目,我们详细展示了Q-Learning算法在迷宫环境中的应用。从环境定义、智能体实现到可视化展示,完整呈现了强化学习算法的工作流程。Q-Learning算法通过不断尝试和学习,逐步发现环境中的最优路径,展示了"在行动中学习"的强大能力。
这种自主学习的方法不依赖于明确的环境模型,具有广泛的适应性和应用前景。理解和掌握这一算法的原理和实现,对于深入学习人工智能和强化学习具有重要意义。
程序配置环境和完整代码:
环境 基于Python3.11.5
accelerate==1.5.2
addict==2.4.0
aiohappyeyeballs==2.6.1
aiohttp==3.11.14
aiosignal==1.3.2
annotated-types==0.7.0
anyio==4.9.0
argon2-cffi==23.1.0
argon2-cffi-bindings==21.2.0
arrow==1.3.0
asttokens==3.0.0
async-lru==2.0.5
attrs==25.3.0
av==14.2.0
babel==2.17.0
beautifulsoup4==4.13.3
bleach==6.2.0
certifi==2025.1.31
cffi==1.17.1
charset-normalizer==3.4.1
cloudpickle==3.1.1
colorama==0.4.6
comm==0.2.2
contourpy==1.3.1
cycler==0.12.1
datasets==3.4.1
debugpy==1.8.13
decorator==5.2.1
defusedxml==0.7.1
dill==0.3.8
distro==1.9.0
einops==0.8.1
executing==2.2.0
fastjsonschema==2.21.1
filelock==3.13.1
fonttools==4.56.0
fqdn==1.5.1
frozenlist==1.5.0
fsspec==2024.6.1
gym==0.26.2
gym-notices==0.0.8
h11==0.14.0
httpcore==1.0.7
httpx==0.28.1
huggingface-hub==0.29.3
idna==3.10
ipykernel==6.29.5
ipython==9.0.2
ipython_pygments_lexers==1.1.1
isoduration==20.11.0
jedi==0.19.2
Jinja2==3.1.6
jiter==0.9.0
json5==0.10.0
jsonpointer==3.0.0
jsonschema==4.23.0
jsonschema-specifications==2024.10.1
jupyter-events==0.12.0
jupyter-lsp==2.2.5
jupyter_client==8.6.3
jupyter_core==5.7.2
jupyter_server==2.15.0
jupyter_server_terminals==0.5.3
jupyterlab==4.3.6
jupyterlab_pygments==0.3.0
jupyterlab_server==2.27.3
kiwisolver==1.4.8
MarkupSafe==3.0.2
matplotlib==3.10.1
matplotlib-inline==0.1.7
mistune==3.1.3
modelscope==1.24.0
mpmath==1.3.0
multidict==6.2.0
multiprocess==0.70.16
nbclient==0.10.2
nbconvert==7.16.6
nbformat==5.10.4
nest-asyncio==1.6.0
networkx==3.3
notebook==7.3.3
notebook_shim==0.2.4
numpy==2.1.2
openai==1.68.2
overrides==7.7.0
packaging==24.2
pandas==2.2.3
pandocfilters==1.5.1
parso==0.8.4
pillow==11.0.0
platformdirs==4.3.7
prometheus_client==0.21.1
prompt_toolkit==3.0.50
propcache==0.3.1
protobuf==6.30.2
psutil==7.0.0
pure_eval==0.2.3
pyarrow==19.0.1
pycparser==2.22
pydantic==2.10.6
pydantic_core==2.27.2
pygame==2.6.1
Pygments==2.19.1
pyparsing==3.2.3
python-dateutil==2.9.0.post0
python-json-logger==3.3.0
pytz==2025.2
pywin32==310
pywinpty==2.0.15
PyYAML==6.0.2
pyzmq==26.3.0
qwen-vl-utils==0.0.10
referencing==0.36.2
regex==2024.11.6
requests==2.32.3
rfc3339-validator==0.1.4
rfc3986-validator==0.1.1
rpds-py==0.23.1
safetensors==0.5.3
Send2Trash==1.8.3
six==1.17.0
sniffio==1.3.1
soupsieve==2.6
stack-data==0.6.3
sympy==1.13.1
terminado==0.18.1
tiktoken==0.9.0
tinycss2==1.4.0
tokenizers==0.21.1
torch==2.6.0+cu126
torchaudio==2.6.0+cu126
torchvision==0.21.0+cu126
tornado==6.4.2
tqdm==4.67.1
traitlets==5.14.3
transformers==4.50.1
transformers-stream-generator==0.0.5
types-python-dateutil==2.9.0.20241206
typing_extensions==4.13.0
tzdata==2025.2
uri-template==1.3.0
urllib3==2.3.0
wcwidth==0.2.13
webcolors==24.11.1
webencodings==0.5.1
websocket-client==1.8.0
xxhash==3.5.0
yarl==1.18.3
算法日志LOG文件:
Q-Learning 训练日志 - 2025-03-28 23:36:44
学习率: 0.1, 折扣因子: 0.9, 探索率: 0.1===== 回合 1 =====
状态: (0, 0), 动作: Right, 旧Q值: 0.0000, 奖励: -1, 下一状态最大Q值: 0.0000, 新Q值: -0.1000
计算公式: Q(s,a) = 0.00 + 0.1 * (-1 + 0.9 * 0.00 - 0.00)当前最优路径: [(0, 0)]。。。(中间省略) 。。。状态: (3, 2), 动作: Down, 旧Q值: -0.4341, 奖励: -1, 下一状态最大Q值: 0.6288, 新Q值: -0.4341
计算公式: Q(s,a) = -0.43 + 0.1 * (-1 + 0.9 * 0.63 - -0.43)当前最优路径: [(0, 0), (0, 1), (0, 2), (1, 2), (2, 2), (3, 2), (4, 2), (5, 2), (5, 3), (5, 4), (6, 4), (6, 5), (6, 6), (7, 6)]状态: (4, 2), 动作: Down, 旧Q值: 0.6288, 奖励: -1, 下一状态最大Q值: 1.8098, 新Q值: 0.6288
计算公式: Q(s,a) = 0.63 + 0.1 * (-1 + 0.9 * 1.81 - 0.63)当前最优路径: [(0, 0), (0, 1), (0, 2), (1, 2), (2, 2), (3, 2), (4, 2), (5, 2), (5, 3), (5, 4), (6, 4), (6, 5), (6, 6), (7, 6)]状态: (5, 2), 动作: Right, 旧Q值: 1.8098, 奖励: -1, 下一状态最大Q值: 3.1220, 新Q值: 1.8098
计算公式: Q(s,a) = 1.81 + 0.1 * (-1 + 0.9 * 3.12 - 1.81)当前最优路径: [(0, 0), (0, 1), (0, 2), (1, 2), (2, 2), (3, 2), (4, 2), (5, 2), (5, 3), (5, 4), (6, 4), (6, 5), (6, 6), (7, 6)]状态: (5, 3), 动作: Right, 旧Q值: 3.1220, 奖励: -1, 下一状态最大Q值: 4.5800, 新Q值: 3.1220
计算公式: Q(s,a) = 3.12 + 0.1 * (-1 + 0.9 * 4.58 - 3.12)当前最优路径: [(0, 0), (0, 1), (0, 2), (1, 2), (2, 2), (3, 2), (4, 2), (5, 2), (5, 3), (5, 4), (6, 4), (6, 5), (6, 6), (7, 6)]状态: (5, 4), 动作: Down, 旧Q值: 4.5800, 奖励: -1, 下一状态最大Q值: 6.2000, 新Q值: 4.5800
计算公式: Q(s,a) = 4.58 + 0.1 * (-1 + 0.9 * 6.20 - 4.58)当前最优路径: [(0, 0), (0, 1), (0, 2), (1, 2), (2, 2), (3, 2), (4, 2), (5, 2), (5, 3), (5, 4), (6, 4), (6, 5), (6, 6), (7, 6)]状态: (6, 4), 动作: Right, 旧Q值: 6.2000, 奖励: -1, 下一状态最大Q值: 8.0000, 新Q值: 6.2000
计算公式: Q(s,a) = 6.20 + 0.1 * (-1 + 0.9 * 8.00 - 6.20)当前最优路径: [(0, 0), (0, 1), (0, 2), (1, 2), (2, 2), (3, 2), (4, 2), (5, 2), (5, 3), (5, 4), (6, 4), (6, 5), (6, 6), (7, 6)]状态: (6, 5), 动作: Right, 旧Q值: 8.0000, 奖励: -1, 下一状态最大Q值: 10.0000, 新Q值: 8.0000
计算公式: Q(s,a) = 8.00 + 0.1 * (-1 + 0.9 * 10.00 - 8.00)当前最优路径: [(0, 0), (0, 1), (0, 2), (1, 2), (2, 2), (3, 2), (4, 2), (5, 2), (5, 3), (5, 4), (6, 4), (6, 5), (6, 6), (7, 6)]状态: (6, 6), 动作: Down, 旧Q值: 10.0000, 奖励: 10, 下一状态最大Q值: 0.0000, 新Q值: 10.0000
计算公式: Q(s,a) = 10.00 + 0.1 * (10 + 0.9 * 0.00 - 10.00)当前最优路径: [(0, 0), (0, 1), (0, 2), (1, 2), (2, 2), (3, 2), (4, 2), (5, 2), (5, 3), (5, 4), (6, 4), (6, 5), (6, 6), (7, 6)]回合 1000 完成: 步数=13, 总奖励=-2
完整代码:
import pygame
import time
import random
import numpy as np
import os
from datetime import datetime# 定义迷宫环境
class MazeEnv:def __init__(self):self.maze = [['.', '.', '.', '#', '.', '.', '.', '#'],['.', '#', '.', '.', '.', '#', '.', '.'],['.', '#', '.', '#', '.', '#', '.', '#'],['.', '.', '.', '#', '.', '.', '.', '.'],['#', '.', '.', '#', '.', '#', '.', '.'],['.', '#', '.', '.', '.', '#', '.', '#'],['.', '#', '.', '#', '.', '.', '.', '.'],['.', '.', '.', '#', '.', '#', 'G', '#']]self.maze = np.array(self.maze)self.start = (0, 0)self.goal = (7, 6)self.current_state = self.startself.actions = [(0, 1), (0, -1), (1, 0), (-1, 0)] # 右, 左, 下, 上self.action_names = ["Right", "Left", "Down", "Up"]def reset(self):self.current_state = self.startreturn self.current_statedef step(self, action):next_state = (self.current_state[0] + action[0], self.current_state[1] + action[1])if (next_state[0] < 0 or next_state[0] >= self.maze.shape[0] ornext_state[1] < 0 or next_state[1] >= self.maze.shape[1] orself.maze[next_state] == '#'):next_state = self.current_state # 如果碰到墙,保持原位置reward = -1 # 每一步的默认奖励done = Falseif next_state == self.goal:reward = 10 # 到达目标的奖励done = Trueself.current_state = next_statereturn next_state, reward, donedef get_maze_size(self):return self.maze.shapedef is_wall(self, position):return self.maze[position] == '#'def is_goal(self, position):return position == self.goal# 定义Q-Learning智能体
class QLearningAgent:def __init__(self, env, learning_rate=0.1, discount_factor=0.9, epsilon=0.1):self.env = envself.q_table = {}self.learning_rate = learning_rateself.discount_factor = discount_factorself.epsilon = epsilonself.log_file = Noneself.q_update_info = {} # 存储Q值更新过程的信息self.optimal_path = [] # 存储当前最优路径def get_action(self, state):if random.uniform(0, 1) < self.epsilon:action_index = random.randint(0, len(self.env.actions) - 1)return self.env.actions[action_index], "Explore", action_index # 探索else:q_values = [self.get_q_value(state, action) for action in self.env.actions]max_q_index = np.argmax(q_values)return self.env.actions[max_q_index], "Exploit", max_q_index # 利用def get_q_value(self, state, action):key = (state, action)return self.q_table.get(key, 0.0)def update_q_table(self, state, action, reward, next_state):old_q = self.get_q_value(state, action)max_next_q = max([self.get_q_value(next_state, a) for a in self.env.actions])new_q = old_q + self.learning_rate * (reward + self.discount_factor * max_next_q - old_q)self.q_table[(state, action)] = new_q# 记录Q值更新过程action_index = self.env.actions.index(action)update_info = {"old_q": old_q,"reward": reward,"max_next_q": max_next_q,"new_q": new_q,"formula": f"Q(s,a) = {old_q:.2f} + {self.learning_rate} * ({reward} + {self.discount_factor} * {max_next_q:.2f} - {old_q:.2f})"}self.q_update_info = update_info# 记录日志if self.log_file:self.log_file.write(f"状态: {state}, 动作: {self.env.action_names[action_index]}, 旧Q值: {old_q:.4f}, 奖励: {reward}, 下一状态最大Q值: {max_next_q:.4f}, 新Q值: {new_q:.4f}\n")self.log_file.write(f"计算公式: {update_info['formula']}\n\n")# 更新最优路径self.update_optimal_path()def update_optimal_path(self):"""计算从起点到终点的当前最优路径"""path = []state = self.env.startmax_steps = 100 # 防止无限循环step_count = 0while state != self.env.goal and step_count < max_steps:path.append(state)q_values = [self.get_q_value(state, action) for action in self.env.actions]action = self.env.actions[np.argmax(q_values)]next_state = (state[0] + action[0], state[1] + action[1])# 检查是否为有效移动if (next_state[0] < 0 or next_state[0] >= self.env.maze.shape[0] ornext_state[1] < 0 or next_state[1] >= self.env.maze.shape[1] orself.env.maze[next_state] == '#'):break # 如果路径无法继续,则停止state = next_statestep_count += 1# 如果达到目标,添加目标if state == self.env.goal:path.append(state)self.optimal_path = path# 记录最优路径到日志if self.log_file and len(path) > 0:self.log_file.write(f"当前最优路径: {path}\n\n")def start_logging(self):# 创建logs目录(如果不存在)os.makedirs("logs", exist_ok=True)# 创建带时间戳的日志文件timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")log_path = f"logs/q_learning_{timestamp}.txt"self.log_file = open(log_path, "w", encoding="utf-8")self.log_file.write(f"Q-Learning 训练日志 - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")self.log_file.write(f"学习率: {self.learning_rate}, 折扣因子: {self.discount_factor}, 探索率: {self.epsilon}\n\n")return log_pathdef close_logging(self):if self.log_file:self.log_file.close()def train(self, num_episodes=1000, visualize=False):log_path = self.start_logging()print(f"训练日志将保存至: {log_path}")# 创建pygame窗口(如果需要可视化)pygame_handler = Noneif visualize:pygame_handler = PygameHandler(self.env, self)for episode in range(num_episodes):state = self.env.reset()done = Falsetotal_reward = 0steps = 0if self.log_file:self.log_file.write(f"\n===== 回合 {episode+1} =====\n")while not done:action, action_type, action_index = self.get_action(state)next_state, reward, done = self.env.step(action)self.update_q_table(state, action, reward, next_state)total_reward += rewardsteps += 1state = next_state# 可视化当前步骤(如果需要)if visualize and (episode % 100 == 0):if pygame_handler and not pygame_handler.update(state, action_info=(action, action_type, action_index), episode=episode, steps=steps):# 如果用户关闭窗口,停止训练print("训练被用户中止")self.close_logging()return# 记录每个回合的摘要if self.log_file:self.log_file.write(f"回合 {episode+1} 完成: 步数={steps}, 总奖励={total_reward}\n\n")if episode % 100 == 0:print(f"回合 {episode+1}/{num_episodes}, 步数: {steps}, 总奖励: {total_reward}")self.close_logging()# 关闭pygame窗口if pygame_handler:pygame_handler.close()def test(self, visualize=True):state = self.env.reset()done = Falsepath = [state]# 开始测试日志os.makedirs("logs", exist_ok=True)timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")test_log_path = f"logs/q_learning_test_{timestamp}.txt"# 创建pygame窗口(如果需要可视化)pygame_handler = Noneif visualize:pygame_handler = PygameHandler(self.env, self, is_testing=True)with open(test_log_path, "w", encoding="utf-8") as test_log:test_log.write(f"Q-Learning 测试日志 - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n\n")step = 0while not done:q_values = [self.get_q_value(state, action) for action in self.env.actions]action_index = np.argmax(q_values)action = self.env.actions[action_index]test_log.write(f"步骤 {step+1}:\n")test_log.write(f" 当前状态: {state}\n")test_log.write(f" 选择动作: {self.env.action_names[action_index]} {action}\n")test_log.write(f" Q值: {q_values}\n")next_state, reward, done = self.env.step(action)# 更新Q值显示信息(仅用于可视化)self.q_update_info = {"old_q": self.get_q_value(state, action),"reward": reward,"max_next_q": max([self.get_q_value(next_state, a) for a in self.env.actions]) if not done else 0,"new_q": self.get_q_value(state, action),"formula": "No Q-value update during testing"}# 可视化当前步骤if visualize and pygame_handler:action_info = (action, "Testing", action_index)if not pygame_handler.update(state, action_info=action_info, episode="Testing", steps=step+1, wait_for_key=True):print("测试被用户中止")breakstate = next_statepath.append(state)step += 1test_log.write(f" 新状态: {state}, 奖励: {reward}, 完成: {done}\n\n")test_log.write(f"测试完成! 总步数: {step}\n")test_log.write(f"路径: {path}\n")# 关闭pygame窗口if pygame_handler:pygame_handler.close()print(f"测试日志已保存至: {test_log_path}")print(f"路径: {path}")# Pygame处理类
class PygameHandler:def __init__(self, env, agent, is_testing=False):self.env = envself.agent = agentself.is_testing = is_testing# 初始化pygamepygame.init()# 设置窗口尺寸和参数rows, cols = env.get_maze_size()self.CELL_SIZE = 90 # 单元格大小self.INFO_PANEL_WIDTH = 500 # 右侧信息面板宽度self.screen_width = cols * self.CELL_SIZE + self.INFO_PANEL_WIDTHself.screen_height = rows * self.CELL_SIZE + 100 # 额外空间用于显示信息# 创建窗口self.screen = pygame.display.set_mode((self.screen_width, self.screen_height))pygame.display.set_caption("Q-Learning Maze Visualization")self.clock = pygame.time.Clock()# 定义颜色self.WHITE = (255, 255, 255)self.BLACK = (0, 0, 0)self.GREEN = (0, 255, 0)self.RED = (255, 0, 0)self.BLUE = (0, 0, 255)self.LIGHT_BLUE = (100, 100, 255)self.YELLOW = (255, 255, 0)self.GRAY = (200, 200, 200)self.PURPLE = (180, 0, 180)# 加载字体self.title_font = pygame.font.SysFont(None, 30)self.font = pygame.font.SysFont(None, 24)self.small_font = pygame.font.SysFont(None, 20)# FPS设置self.fps = 36 if not is_testing else 20 # 训练时速度提高5倍,测试时保持适中def draw_maze(self):rows, cols = self.env.get_maze_size()for i in range(rows):for j in range(cols):rect = pygame.Rect(j * self.CELL_SIZE, i * self.CELL_SIZE, self.CELL_SIZE, self.CELL_SIZE)if self.env.is_wall((i, j)):pygame.draw.rect(self.screen, self.BLACK, rect)elif self.env.is_goal((i, j)):pygame.draw.rect(self.screen, self.GREEN, rect)elif (i, j) in self.agent.optimal_path:# 标记最优路径pygame.draw.rect(self.screen, self.YELLOW, rect)else:pygame.draw.rect(self.screen, self.WHITE, rect)pygame.draw.rect(self.screen, self.GRAY, rect, 1) # 绘制网格线# 显示Q值q_values = {action: self.agent.get_q_value((i, j), action) for action in self.env.actions}for idx, (action, q) in enumerate(zip(self.env.actions, q_values.values())):action_index = self.env.actions.index(action)action_name = self.env.action_names[action_index]q_text = f"{action_name}: {q:.2f}"text_surface = self.small_font.render(q_text, True, self.BLACK)self.screen.blit(text_surface, (j * self.CELL_SIZE + 5, i * self.CELL_SIZE + idx * 20 + 10))def draw_agent(self, position):x, y = positioncenter = (y * self.CELL_SIZE + self.CELL_SIZE // 2, x * self.CELL_SIZE + self.CELL_SIZE // 2)pygame.draw.circle(self.screen, self.RED, center, self.CELL_SIZE // 4)def draw_optimal_path(self):if len(self.agent.optimal_path) > 1:for i in range(len(self.agent.optimal_path) - 1):start_pos = self.agent.optimal_path[i]end_pos = self.agent.optimal_path[i + 1]start_center = (start_pos[1] * self.CELL_SIZE + self.CELL_SIZE // 2, start_pos[0] * self.CELL_SIZE + self.CELL_SIZE // 2)end_center = (end_pos[1] * self.CELL_SIZE + self.CELL_SIZE // 2, end_pos[0] * self.CELL_SIZE + self.CELL_SIZE // 2)pygame.draw.line(self.screen, self.PURPLE, start_center, end_center, 5)def draw_info_panel(self, state, action_info):rows, cols = self.env.get_maze_size()# 绘制右侧信息面板背景info_rect = pygame.Rect(cols * self.CELL_SIZE, 0, self.INFO_PANEL_WIDTH, rows * self.CELL_SIZE)pygame.draw.rect(self.screen, self.LIGHT_BLUE, info_rect)# 标题title_surface = self.title_font.render("Q-Learning Real-time Information", True, self.BLACK)self.screen.blit(title_surface, (cols * self.CELL_SIZE + 20, 20))# 当前状态和动作信息y_offset = 70if action_info:action, action_type, action_index = action_infostate_text = f"Current state: {state}"action_text = f"Selected action: {self.env.action_names[action_index]} {'⟶' if action == (0, 1) else '⟵' if action == (0, -1) else '⟲' if action == (1, 0) else '⟱'}"type_text = f"Decision type: {action_type}"state_surface = self.font.render(state_text, True, self.BLACK)action_surface = self.font.render(action_text, True, self.BLACK)type_surface = self.font.render(type_text, True, self.BLACK)self.screen.blit(state_surface, (cols * self.CELL_SIZE + 20, y_offset))self.screen.blit(action_surface, (cols * self.CELL_SIZE + 20, y_offset + 30))self.screen.blit(type_surface, (cols * self.CELL_SIZE + 20, y_offset + 60))y_offset += 100# Q值更新信息if self.agent.q_update_info:update_title = self.font.render("Q-value Update Process:", True, self.BLACK)self.screen.blit(update_title, (cols * self.CELL_SIZE + 20, y_offset))info = self.agent.q_update_infolines = [f"Old Q-value: {info['old_q']:.4f}",f"Reward: {info['reward']}",f"Max next Q-value: {info['max_next_q']:.4f}",f"New Q-value: {info['new_q']:.4f}","","Calculation Formula:",f"Q(s,a) = Q(s,a) + α[R + γ·max Q(s',a') - Q(s,a)]",f"{info['formula']}"]for i, line in enumerate(lines):line_surface = self.small_font.render(line, True, self.BLACK)self.screen.blit(line_surface, (cols * self.CELL_SIZE + 30, y_offset + 30 + i * 25))y_offset += 250# 绘制最优路径信息if self.agent.optimal_path:path_title = self.font.render("Current Optimal Path:", True, self.BLACK)self.screen.blit(path_title, (cols * self.CELL_SIZE + 20, y_offset))path_text = ", ".join([f"({x},{y})" for x, y in self.agent.optimal_path])path_lines = [path_text[i:i+40] for i in range(0, len(path_text), 40)] # 分行显示for i, line in enumerate(path_lines):line_surface = self.small_font.render(line, True, self.BLACK)self.screen.blit(line_surface, (cols * self.CELL_SIZE + 30, y_offset + 30 + i * 25))def draw_bottom_info(self, episode, steps):rows, cols = self.env.get_maze_size()info_rect = pygame.Rect(0, rows * self.CELL_SIZE, self.screen_width, 100)pygame.draw.rect(self.screen, self.GRAY, info_rect)episode_text = f"Episode: {episode}"steps_text = f"Steps: {steps}"instructions_text = "Press Q to quit"episode_surface = self.font.render(episode_text, True, self.BLACK)steps_surface = self.font.render(steps_text, True, self.BLACK)instructions_surface = self.font.render(instructions_text, True, self.BLACK)self.screen.blit(episode_surface, (20, rows * self.CELL_SIZE + 20))self.screen.blit(steps_surface, (20, rows * self.CELL_SIZE + 50))self.screen.blit(instructions_surface, (self.screen_width - 300, rows * self.CELL_SIZE + 35))def update(self, state, action_info=None, episode=0, steps=0, wait_for_key=False):"""更新显示并处理事件,返回是否继续运行"""# 处理事件for event in pygame.event.get():if event.type == pygame.QUIT or (event.type == pygame.KEYDOWN and event.key == pygame.K_q):return False# 清屏并绘制self.screen.fill(self.WHITE)self.draw_maze()self.draw_optimal_path()self.draw_agent(state)self.draw_info_panel(state, action_info)self.draw_bottom_info(episode, steps)# 更新显示pygame.display.flip()# 如果是测试模式且需要等待按键if wait_for_key and self.is_testing:waiting = Truewhile waiting:for event in pygame.event.get():if event.type == pygame.QUIT or (event.type == pygame.KEYDOWN and event.key == pygame.K_q):return Falseelif event.type == pygame.KEYDOWN:waiting = Falsepygame.event.pump() # 防止窗口无响应self.clock.tick(30)else:# 控制帧率self.clock.tick(self.fps)# 处理事件,防止窗口无响应pygame.event.pump()return Truedef close(self):"""关闭pygame"""pygame.quit()# 程序入口
if __name__ == "__main__":# 创建环境和智能体env = MazeEnv()agent = QLearningAgent(env)# 训练和测试agent.train(num_episodes=1000, visualize=True)agent.test(visualize=True)
相关文章:
《Python实战进阶》No37: 强化学习入门加餐版3 之 Q-Learning算法可视化升级
连续第4篇文章写Q-Learning算法及可视化 Q-Learning强化学习算法在迷宫寻路中的应用 引言 强化学习是机器学习的一个重要分支,其核心理念是通过与环境的交互来学习最优策略。在上三篇文章中,《Python实战进阶》No37: 强化学习入门:Q-Learn…...
)
1.两数之和(Java)
1. 题目描述 LeetCode 1. 两数之和(Two Sum) 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那两个整数,并返回它们的索引。 示例 1: 输入:nums [2,7,11,15], target 9 …...

漏洞挖掘---灵当CRM客户管理系统getOrderList SQL注入漏洞
一、灵当CRM 灵当CRM是上海灵当信息科技有限公司旗下产品,适用于中小型企业。它功能丰富,涵盖销售、服务、财务等管理功能,具有性价比高、简洁易用、可定制、部署灵活等特点,能助力企业提升经营效益和客户满意度。 二、FOFA-Sear…...

Java高频面试之集合-20
hello啊,各位观众姥爷们!!!本baby今天来报道了!哈哈哈哈哈嗝🐶 面试官:讲讲 HashSet 的底层实现? HashSet 是 Java 集合框架中用于存储唯一元素的高效数据结构,其底层实…...

sort命令:排序
sort:默认首位排序 参数: -n:按整个数字排序 -r:降序 -u:去重 [rootrobin ~]# sort -n aa.txt #按数字排序(正序) [rootrobin ~]# sort -nr aa.txt #降序 [rootrobin ~]# sort -…...

Javaweb后端 AOP快速入门 AOP核心概念 AOP执行流程
AOP是对特定方法编程,把共用都用的方法提取出来,统一维护 AOP基础 AOP快速入门 对原始方法无影响 AOP核心概念 连接点,是原始方法,被控制范围内的原始方法 通知,AOP类里面写的公共的方法 切入点,实际被AO…...
deepseek ai 输入法
一、简介 使用java开发一个安卓输入法接入deepseek实现ai聊天,代码已开源。 二、视频演示 deepseek输入法_哔哩哔哩_bilibili 三、开源地址 https://github.com/deepseek/inputmethed 四、技术细节 CustomInputMethodService.java 输入法服务类 MainActivity.…...

Rust 所有权与引用
目录 Rust 所有权原则变量所有权变量作用范围深拷贝 Rust 的引用示例可变引用不可变引用可变引用和不可变引用不能同时存在悬垂引用 Rust 所有权原则 Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者一个值同时只能被一个变量所拥有,或者说一…...

探究 CSS 如何在HTML中工作
2025/3/28 向全栈工程师迈进! 一、CSS的作用 简单一句话——美化网页 <p>Lets use:<span>Cascading</span><span>Style</span><span>Sheets</span> </p> 对于如上代码来说,其显示效果如下࿱…...
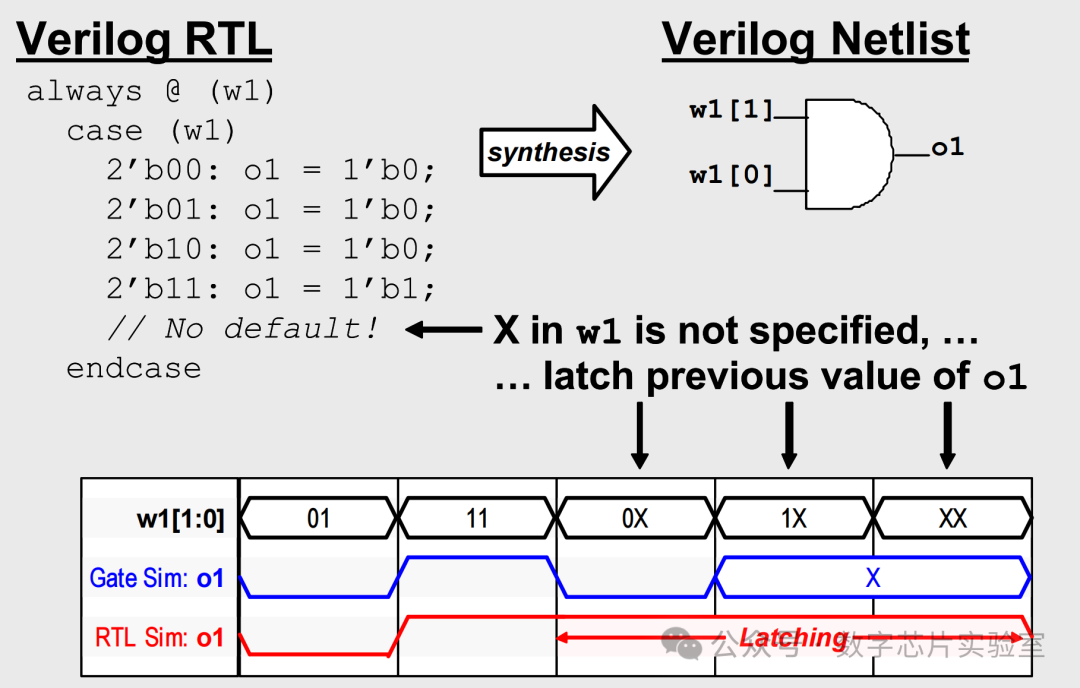
Verilog中X态的危险:仿真漏掉的bug
由于Verilog中X态的微妙语义,RTL仿真可能PASS,而网表仿真却会fail。 目前进行的网表仿真越来越少,这个问题尤其严重,主要是网表仿真比RTL仿真慢得多,因此对整个回归测试而言成本效益不高。 上面的例子中,用…...

使用 uv 管理 Python 项目
介绍 首先, uv 工具是使用 rust 开发出来的, 速度要比传统的 pip, pipx 等一众包管理工具要快不少. 另外, 除了包管理之外, uv 还提供了脚手架的功能, 使用体验和前端开发使用过的 vue-cli 很相似, 可以帮助我们自动初始化项目, 创建好一个空的包含必要文件结构的文件夹. 此外…...

【操作系统】软中断vs硬中断
在操作系统中,中断(Interrupt) 是 CPU 响应外部事件的重要机制,分为 硬中断(Hardware Interrupt) 和 软中断(Software Interrupt)。它们的核心区别在于 触发方式 和 处理机制。 1. 硬…...

《C++11:通过thread类编写C++多线程程序》
关于多线程的概念与理解,可以先了解Linux下的底层线程。当对底层线程有了一定程度理解以后,再学习语言级别的多线程编程就轻而易举了。 【Linux】多线程 -> 从线程概念到线程控制 【Linux】多线程 -> 线程互斥与死锁 语言级别的…...

19-dfs-排列数字(基础)
题目 来源 842. 排列数字 - AcWing题库 思路 由于相对简单,是dfs的模板题,具体思路详见代码 代码 #include<bits/stdc.h> using namespace std; const int N10; int state[N],path[N];//是否使用过,当前位置 int n; void dfs(int …...
32.代码题
接着上集...... 派对:超时了,总该受到惩罚吧? 洛西:至于吗?就0.1秒! 晴/宇:十分应该。 洛西:我..................... 没办法,洛西只能按照要求去抓R了。 1.P1102 …...

nacos 3.x Java SDK 使用详解
Nacos 3.x Java SDK 使用详解 Nacos 3.x 是云原生服务治理的重要升级版本,其 Java SDK 在性能、协议和扩展性上均有显著优化。 一、环境要求与依赖配置 基础环境 JDK 版本:需使用 JDK 17(Nacos 3.x 已放弃对 JDK 8 的支持)。Spri…...

SPI-NRF24L01
模块介绍 NRF24L01是NORDIC公司生产的一款无线通信芯片,采用FSK调制,内部集成NORDIC自己的Enhanced Short Burst 协议,可以实现点对点或者1对6 的无线通信,通信速率最高可以达到2Mbps. NRF24L01采用SPI通信。 ①MOSI 主器件数据输出…...

python黑科技:无痛修改第三方库源码
需求不符合 很多时候,我们下载的 第三方库 是不会有需求不满足的情况,但也有极少的情况,第三方库 没有兼顾到需求,导致开发者无法实现相关功能。 如何通过一些操作将 第三方库 源码进行修改,是我们将要遇到的一个难点…...
一区严选!挑战5天一篇脂质体组学 DAY1-5
Day 1! 前期已经成功挑战了很多期NHANES啦!打算来试试孟德尔随机化领域~ 随着孟德尔随机化研究的普及,现在孟德尔发文的难度越来越高,简单的双样本想被接收更是难上加难,那么如何破除这个困境,这次我打算…...
)
【JavaScript】合体期功法——DOM(二)
目录 DOM事件监听案例关闭广告随机点名 事件监听版本事件类型 DOM 事件监听 事件:编程时系统内发生的动作或事情,例如用户在网页上单击一个按钮 事件监听:让程序检测是否产生事件,一旦事件触发,立即调用函数做出响应…...

23种设计模式中的中介者模式
定义了一个中介对象来封装一系列对象之间的交互。中介者使各对象直接不再显示地相互引用,从而使其松散耦合,且可以独立地改变它们之间的交互。 通过引入一个中介者对象,来协调和封装多个对象之间的交互,从而降低他们之间的耦合度。…...

量子计算:开启未来计算的新纪元
一、引言 在当今数字化时代,计算技术的飞速发展深刻地改变了我们的生活和工作方式。从传统的电子计算机到如今的高性能超级计算机,人类在计算能力上取得了巨大的进步。然而,随着科技的不断推进,我们面临着越来越多的复杂问题&…...

Docker 的实质作用是什么
Docker 的实质作用是什么 目录 Docker 的实质作用是什么**1. Docker 的实质作用****2. 为什么使用 Docker?****(1)解决环境一致性问题****(2)提升资源利用率****(3)简化部署与扩展****(4)加速开发与协作****3. 举例说明****总结**Docker 的实质是容器化平台,核心作用…...

Assembly语言的装饰器
Assembly语言的装饰器:灵活高效的代码复用 引言 在软件开发中,代码复用和模块化是两个至关重要的概念。它们不仅使得代码的维护变得更为简单,而且能极大提升开发效率。在高级语言中,装饰器是一种非常受欢迎的设计模式࿰…...

VITA 模型解读,实时交互式多模态大模型的 pioneering 之作
写在前面:实时交互llm 今天回顾一下多模态模型VITA,当时的背景是OpenAI 的 GPT-4o 惊艳亮相,然而,当我们将目光投向开源社区时,却发现能与之匹敌的模型寥寥无几。当时开源多模态大模型(MLLM),大多在以下一个或多个方面存在局限: 模态支持不全:大多聚焦于文本和图像,…...

自学-408-《计算机网络》(总结速览)
文章目录 第一章 计算机网络概述1. 计算机网络的定义2. 计算机网络的基本功能3. 计算机网络的分类4. 计算机网络的层次结构5. 计算机网络的协议6. 计算机网络的组成部分7. 计算机网络的应用8. 互联网的概念 物理层的主要功能第二章 数据链路层和局域网1. 数据链路层的功能2. 局…...

AF3 FeaturePipeline类解读
AlphaFold3 feature_pipeline 模块 FeaturePipeline 类是一个封装类,通过调用函数np_example_to_features 实现整个数据处理流程。 源代码: def np_to_tensor_dict(np_example: Mapping[str, np.ndarray],features: Sequence[str], ) -> TensorDict:"""C…...

【质量管理】纠正、纠正措施和预防的区别与解决问题的四重境界
“质量的定义就是符合要求”,我们在文章【质量管理】人们对于质量的五个错误观念-CSDN博客中提到过,这也是质量大师克劳士比所说的。“质量的系统就是预防”,防止出现产品不良而造成的质量损失。 质量问题的解决可以从微观和宏观两个方面来考…...

Java面试黄金宝典24
1. 什么是跳表 定义 跳表(Skip List)是一种随机化的数据结构,它基于有序链表发展而来,通过在每个节点中维护多个指向其他节点的指针,以多层链表的形式组织数据。其核心思想是在链表基础上增加额外层次,每…...
)
Windows 11系统下Kafka的详细安装与启动指南(JDK 1.8)
1. 安装前准备 在Windows 11系统中安装Kafka之前,需要确保满足以下条件: 1.1 系统要求 Windows 11操作系统(64位)至少4GB内存(建议8GB或更高)至少5GB可用磁盘空间管理员权限1.2 所需工具 浏览器(用于下载软件)解压工具(如7-Zip、WinRAR,Windows 11自带的解压功能也…...