大模型架构记录13【hr agent】
一 Function calling 函数调用
from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv())from openai import OpenAI
import jsonclient = OpenAI()# Example dummy function hard coded to return the same weather
# In production, this could be your backend API or an external API
def get_current_weather(location, unit="fahrenheit"): """Get the current weather in a given location"""if "tokyo" in location.lower():return json.dumps({"location": "Tokyo", "temperature": "10", "unit": unit})elif "san francisco" in location.lower():return json.dumps({"location": "San Francisco", "temperature": "72", "unit": unit})elif "paris" in location.lower():return json.dumps({"location": "Paris", "temperature": "22", "unit": unit})else:return json.dumps({"location": location, "temperature": "unknown"})def run_conversation():# Step 1: send the conversation and available functions to the modelmessages = [{"role": "user", "content": "What's the weather like in San Francisco, Tokyo, and Paris?"}]tools = [{"type": "function","function": {"name": "get_current_weather","description": "Get the current weather in a given location","parameters": {"type": "object","properties": {"location": {"type": "string","description": "The city and state, e.g. San Francisco, CA",},"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},},"required": ["location"],},},}]response = client.chat.completions.create(model="gpt-3.5-turbo-0125",messages=messages,tools=tools,tool_choice="auto", # auto is default, but we'll be explicit)print(response)response_message = response.choices[0].messageprint(response_message)tool_calls = response_message.tool_callsprint(tool_calls)# Step 2: check if the model wanted to call a functionif tool_calls:# Step 3: call the function# Note: the JSON response may not always be valid; be sure to handle errorsavailable_functions = {"get_current_weather": get_current_weather,} # only one function in this example, but you can have multiplemessages.append(response_message) # extend conversation with assistant's reply# Step 4: send the info for each function call and function response to the modelfor tool_call in tool_calls:function_name = tool_call.function.namefunction_to_call = available_functions[function_name]function_args = json.loads(tool_call.function.arguments)function_response = function_to_call(location=function_args.get("location"),unit=function_args.get("unit"),)messages.append({"tool_call_id": tool_call.id,"role": "tool","name": function_name,"content": function_response,}) # extend conversation with function responsesecond_response = client.chat.completions.create(model="gpt-3.5-turbo-0125",messages=messages,) # get a new response from the model where it can see the function responsereturn second_response
result = run_conversation()
resultresult.choices[0].message.content
# 'The current weather in San Francisco is 72°F, in Tokyo it is 10°C, and in Paris it is 22°C.'二 v3-Create-Custom-Agent
2.1 Load the LLM 加载LLM
from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv())from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-4", temperature=0)2.2 Define Tools 定义工具
from langchain.agents import toolimport time@tool
def generate_unique_timestamp():"""生成唯一的时间戳。输入始终为空字符串。Returns:int: 唯一的时间戳,以毫秒为单位。"""timestamp = int(time.time() * 1000) # 获取当前时间的毫秒级时间戳return timestampimport os@tool
def create_folder(folder_name):"""根据给定的文件夹名创建文件夹。Args:folder_name (str): 要创建的文件夹的名称。Returns:str: 创建的文件夹的路径。"""try:os.makedirs(os.path.join("chat_history", folder_name)) # 创建文件夹return os.path.abspath(folder_name) # 返回创建的文件夹的绝对路径except OSError as e:print(f"创建文件夹失败:{e}")return Noneimport shutil@tool
def delete_temp_folder():"""删除 chat_history 文件夹下的 temp 文件夹。输入始终为空字符串。Returns:bool: 如果成功删除则返回 True,否则返回 False。"""temp_folder = "chat_history/temp" # temp 文件夹路径try:shutil.rmtree(temp_folder) # 递归删除 temp 文件夹及其所有内容print("成功删除 temp 文件夹。")return Trueexcept Exception as e:print(f"删除 temp 文件夹失败:{e}")return False@tool
def copy_chat_history(interview_id: str) -> str:"""将 chat_history/temp 文件夹中的 chat_history.txt 文件复制到 chat_history 文件夹下的以 interview_id 命名的子文件夹中。如果面试ID文件夹不存在,则返回相应的提示字符串。参数:interview_id (str): 面试的唯一标识符。返回:str: 操作结果的提示信息。"""# 确定临时文件夹和面试文件夹路径temp_folder = os.path.join("chat_history", "temp")interview_folder = os.path.join("chat_history", interview_id)# 检查面试文件夹是否存在if not os.path.exists(interview_folder):return f"面试ID为 {interview_id} 的文件夹不存在。无法完成复制操作。"# 将 chat_history.txt 从临时文件夹复制到面试文件夹source_file = os.path.join(temp_folder, 'chat_history.txt')destination_file = os.path.join(interview_folder, 'chat_history.txt')shutil.copyfile(source_file, destination_file)return f"已将 chat_history.txt 复制到面试ID为 {interview_id} 的文件夹中。"@tool
def read_chat_history(interview_id: str) -> str:"""读取指定面试ID文件夹下的聊天记录(chat_history.txt)内容。参数:interview_id (str): 面试的唯一标识符。返回:str: 聊天记录的内容。"""# 确定面试文件夹路径interview_folder = os.path.join("chat_history", interview_id)# 检查面试文件夹是否存在if not os.path.exists(interview_folder):return f"面试ID为 {interview_id} 的文件夹不存在。无法读取聊天记录。"# 读取聊天记录文件内容chat_history_file = os.path.join(interview_folder, 'chat_history.txt')with open(chat_history_file, 'r', encoding='utf-8') as file:chat_history_content = file.read()return chat_history_content@tool
def generate_markdown_file(interview_id: str, interview_feedback: str) -> str:"""将给定的面试反馈内容生成为 Markdown 文件,并保存到指定的面试ID文件夹中。参数:interview_id (str): 面试的唯一标识符。interview_feedback (str): 面试反馈的内容。返回:str: 操作结果的提示信息。"""# 确定面试文件夹路径interview_folder = os.path.join("chat_history", interview_id)# 检查面试文件夹是否存在if not os.path.exists(interview_folder):return f"面试ID为 {interview_id} 的文件夹不存在。无法生成 Markdown 文件。"# 生成 Markdown 文件路径markdown_file_path = os.path.join(interview_folder, "面试报告.md")try:# 写入 Markdown 文件with open(markdown_file_path, 'w', encoding='utf-8') as file:# 写入标题和面试反馈file.write("# 面试报告\n\n")file.write("## 面试反馈:\n\n")file.write(interview_feedback)file.write("\n\n")# 读取 chat_history.txt 文件内容并写入 Markdown 文件chat_history_file_path = os.path.join(interview_folder, "chat_history.txt")if os.path.exists(chat_history_file_path):file.write("## 面试记录:\n\n")with open(chat_history_file_path, 'r', encoding='utf-8') as chat_file:for line in chat_file:file.write(line.rstrip('\n') + '\n\n') # 添加换行符return f"已生成 Markdown 文件: {markdown_file_path}"except Exception as e:return f"生成 Markdown 文件时出错: {str(e)}"2.3 执行
from utils import parse_cv_to_md
cv_file_path = "data/cv.txt"
result = parse_cv_to_md(llm, cv_file_path)
print(result)
2.4 加载数据
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from utils import parse_md_file_to_docsfile_path = "data/cv.md"
docs = parse_md_file_to_docs(file_path)
print(len(docs))vectorstore = Chroma.from_documents(documents=docs, embedding=OpenAIEmbeddings())retriever = vectorstore.as_retriever(search_kwargs={"k": 1})retriever.get_relevant_documents("langchain")
retriever.get_relevant_documents("python")@tool
def find_most_relevant_block_from_cv(sentence: str) -> str:"""当你需要根据职位描述(JD)中的技能关键词去简历文本中找到相关内容时,就可以调用这个函数。参数:sentence (str): 包含技能关键词的句子。返回:str: 最相关的文本块。"""try:most_relevant_docs = retriever.get_relevant_documents(sentence)print(len(most_relevant_docs))if most_relevant_docs:most_relevant_texts = [doc.page_content for doc in most_relevant_docs]most_relevant_text = "\n".join(most_relevant_texts)return most_relevant_textelse:return "未找到相关文本块"except Exception as e:print(f"find_most_relevant_block_from_cv()发生错误:{e}")return "函数发生错误,未找到相关文本块"tools = [generate_unique_timestamp, create_folder, copy_chat_history, read_chat_history, generate_markdown_file, find_most_relevant_block_from_cv]2.5 Create Prompt 创建提示
from utils import *jd_file_path = "data/jd.txt"
jd_json_file_path = parse_jd_to_json(llm, jd_file_path)
jd_json_file_path
jd_json_file_path = "data/jd.json"
jd_dict = read_json(jd_json_file_path)
jd_dict
job_title = jd_dict.get('基本信息').get('职位')
job_key_skills = jd_dict.get('专业技能/知识/能力')
print(f"职位:{job_title}")
print(f"专业技能/知识/能力:{job_key_skills}")"""职位:Python工程师 (AI应用方向)
专业技能/知识/能力:['Python', 'PyTorch', 'TensorFlow', 'Numpy', 'Redis', 'MySQL', 'openai', 'langchain', 'AI开发工具集', '向量数据库', 'Text-SQL', 'Python Web框架', 'FastAPI', 'ORM框架', 'Prompt提示词']"""# 弃用
system_prompt = f"""
## Role and Goals
- 你是所招岗位“{job_title}”的技术专家,同时也作为技术面试官向求职者提出技术问题,专注于考察应聘者的专业技能、知识和能力。
- 这里是当前岗位所需的专业技能、知识和能力:“{job_key_skills}”,你应该重点围绕这些技术点提出你的问题。
- 你严格遵守面试流程进行面试。## Interview Workflow
1. 当应聘者说开始面试后,1.1 你要依据当前时间生成一个新的时间戳作为面试ID(只会在面试开始的时候生成面试ID,其他任何时间都不会)1.2 以该面试ID为文件夹名创建本地文件夹(只会在面试开始的时候创建以面试ID为名的文件夹,其他任何时间都不会)1.3 删除存储聊天记录的临时文件夹1.4 输出该面试ID给应聘者,并结合当前技术点、与技术点相关的简历内容,提出你的第一个基础技术问题。
2. 接收应聘者的回答后,2.1 检查应聘者的回答是否有效2.1.1 如果是对面试官问题的正常回答(无论回答的好不好,还是回答不会,都算正常回答),就跳转到2.2处理2.1.2 如果是与面试官问题无关的回答(胡言乱语、辱骂等),请警告求职者需要严肃对待面试,跳过2.2,再次向求职者提出上次的问题。2.2 如果应聘者对上一个问题回答的很好,就基于当前技术点和历史记录提出一个更深入一点的问题;如果应聘者对上一个问题回答的一般,就基于当前技术点和历史记录提出另一个角度的问题;如果应聘者对上一个问题回答的不好,就基于当前技术点和历史记录提出一个更简单一点的问题;如果应聘者对上一个问题表示不会、不懂、一点也回答不了,就换一个与当前技术点不同的技术点进行技术提问。
3. 当应聘者想结束面试或当应聘者想要面试报告,3.1 从临时文件夹里复制一份聊天记录文件到当前面试ID文件夹下。3.2 读取当前面试ID文件夹下的聊天记录,基于聊天记录、从多个角度评估应聘者的表现、生成一个详细的面试报告。3.3 调用工具生成一个面试报告的markdown文件到当前面试ID文件夹下3.4 告知应聘者面试已结束,以及面试报告的位置。## Output Constraints
- 你发送给应聘者的信息中,一定不要解答你提出的面试问题,只需要有简短的反馈和提出的新问题。
- 你每次提出的技术问题,都需要结合从JD里提取的技术点和与技术点相关的简历内容,当你需要获取`与技术点相关的简历内容`时,请调用工具。
- 再一次检查你的输出,你一次只会问一个技术问题。
"""system_prompt = f"""
## Role and Goals
- 你是所招岗位“{job_title}”的技术专家,同时也作为技术面试官向求职者提出技术问题,专注于考察应聘者的专业技能、知识和能力。
- 这里是当前岗位所需的专业技能、知识和能力:“{job_key_skills}”,你应该重点围绕这些技术点提出你的问题。
- 你严格遵守面试流程进行面试。## Interview Workflow
1. 当应聘者说开始面试后,1.1 你要依据当前时间生成一个新的时间戳作为面试ID(只会在面试开始的时候生成面试ID,其他任何时间都不会)1.2 以该面试ID为文件夹名创建本地文件夹(只会在面试开始的时候创建以面试ID为名的文件夹,其他任何时间都不会)1.3 删除存储聊天记录的临时文件夹1.4 输出该面试ID给应聘者,并结合当前技术点、与技术点相关的简历内容,提出你的第一个基础技术问题。
2. 接收应聘者的回答后,2.1 检查应聘者的回答是否有效2.1.1 如果是对面试官问题的正常回答(无论回答的好不好,还是回答不会,都算正常回答),就跳转到2.2处理2.1.2 如果是与面试官问题无关的回答(胡言乱语、辱骂等),请警告求职者需要严肃对待面试,跳过2.2,再次向求职者提出上次的问题。2.2 如果应聘者对上一个问题回答的很好,就基于当前技术点和历史记录提出一个更深入一点的问题;如果应聘者对上一个问题回答的一般,就基于当前技术点和历史记录提出另一个角度的问题;如果应聘者对上一个问题回答的不好,就基于当前技术点和历史记录提出一个更简单一点的问题;如果应聘者对上一个问题表示不会、不懂、一点也回答不了,就换一个与当前技术点不同的技术点进行技术提问。
3. 当应聘者想结束面试或当应聘者想要面试报告,3.1 从临时文件夹里复制一份聊天记录文件到当前面试ID文件夹下。3.2 读取当前面试ID文件夹下的聊天记录,基于聊天记录、从多个角度评估应聘者的表现、生成一个详细的面试报告。3.3 调用工具生成一个面试报告的markdown文件到当前面试ID文件夹下3.4 告知应聘者面试已结束,以及面试报告的位置。## Output Constraints
- 你发送给应聘者的信息中,一定不要解答你提出的面试问题,只需要有简短的反馈和提出的新问题。
- 你每次提出的技术问题,都需要结合从JD里提取的技术点和与技术点相关的简历内容,当你需要获取`与技术点相关的简历内容`时,请调用工具。
- 再一次检查你的输出,你一次只会问一个技术问题。
"""from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderprompt = ChatPromptTemplate.from_messages([("system",system_prompt,),MessagesPlaceholder(variable_name="chat_history"),("user", "{input}"),MessagesPlaceholder(variable_name="agent_scratchpad"),]
)print(prompt.messages[0].prompt.template)
2.6 Bind tools to LLM 将工具绑定到LLM
llm_with_tools = llm.bind_tools(tools)llm_with_tools.kwargs['tools']2.7 Create the Agent 创建代理
from langchain.agents.format_scratchpad.openai_tools import (format_to_openai_tool_messages,
)
from langchain.agents.output_parsers.openai_tools import OpenAIToolsAgentOutputParseragent = ({"input": lambda x: x["input"],"agent_scratchpad": lambda x: format_to_openai_tool_messages(x["intermediate_steps"]),"chat_history": lambda x: x["chat_history"],}| prompt| llm_with_tools| OpenAIToolsAgentOutputParser()
)2.8 Run the agent 运行代理
from langchain.agents import AgentExecutoragent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)from utils import save_chat_historyfrom langchain_core.messages import AIMessage, HumanMessagechat_history = []user_input = "开始面试"
print(user_input)while True:result = agent_executor.invoke({"input": user_input, "chat_history": chat_history})print(result['output'])chat_history.extend([HumanMessage(content=user_input),AIMessage(content=result["output"]),])# 存储聊天记录到临时文件夹temp_folder = "chat_history/temp" # 临时文件夹名称os.makedirs(temp_folder, exist_ok=True) # 创建临时文件夹,如果不存在则创建save_chat_history(chat_history, temp_folder)# 获取用户下一条输入user_input = input("user: ")# 检查用户输入是否为 "exit"if user_input == "exit":print("用户输入了 'exit',程序已退出。")break
2.9 urls.py
import os
import json
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser, StrOutputParser
from langchain_core.messages import AIMessage, HumanMessagedef save_chat_history(chat_history, folder_name):"""将聊天记录存储到指定的文件夹下的chat_history.txt文件中。Args:chat_history (list): 聊天记录列表,每个元素是一个AIMessage或HumanMessage对象。folder_name (str): 聊天记录文件夹的名称。Returns:str: 保存的文件路径,如果保存失败则返回None。"""try:file_path = os.path.join(folder_name, "chat_history.txt") # chat_history.txt文件路径with open(file_path, "w", encoding="utf-8") as file:for message in chat_history:if isinstance(message, AIMessage):speaker = "面试官"elif isinstance(message, HumanMessage):speaker = "应聘者"else:continue # 忽略不是面试官或应聘者的消息file.write(f"{speaker}: {message.content}\n") # 将每条聊天记录写入文件,每条记录占一行return file_path # 返回保存的文件路径except Exception as e:print(f"保存聊天记录失败:{e}")return Nonedef parse_jd_to_json(llm, jd_file_path: str):"""将给定的 JD 文件内容解析为 JSON,并存储到指定路径下。参数:llm: 大模型。jd_file_path (str): JD 文件的路径。返回:str: 存储的 JSON 文件路径。"""try:with open(jd_file_path, 'r', encoding='utf-8') as jd_file:jd_content = jd_file.read().strip()template = """
基于JD文本,按照约束,生成以下格式的 JSON 数据:
{{"基本信息": {{"职位": "职位名称","薪资": "薪资范围","地点": "工作地点","经验要求": "经验要求","学历要求": "学历要求","其他":""}},"岗位职责": {{"具体职责": ["职责1", "职责2", ...]}},"岗位要求": {{"学历背景": "学历要求","工作经验": "工作经验要求","技能要求": ["技能1", "技能2", ...],"个人特质": ["特质1", "特质2", ...],}},"专业技能/知识/能力": ["技能1", "技能2", ...],"其他信息": {{}}
}}JD文本:
[{jd_content}]约束:
1、除了`专业技能/知识/能力`键,其他键的值都从原文中获取。
2、保证JSON里的值全面覆盖JD原文,不遗漏任何原文,不知如何分类就放到`其他信息`里。
3、`专业技能/知识/能力`键对应的值要求从JD全文中(尤其是岗位职责、技能要求部分)提取总结关键词或关键短句,不能有任何遗漏的硬技能。JSON:
"""parser = JsonOutputParser()prompt = PromptTemplate(template=template,input_variables=["jd_content"],partial_variables={"format_instructions": parser.get_format_instructions()},)print(prompt.template)chain = prompt | llm | parserresult = chain.invoke({"jd_content": jd_content})# 打印print(result)print(type(result))print(result['专业技能/知识/能力'])# 存储到 data 目录下output_file_path = "data/jd.json"with open(output_file_path, 'w', encoding='utf-8') as output_file:json.dump(result, output_file, ensure_ascii=False)print(f"已存储最终 JSON 文件到 {output_file_path}")return output_file_pathexcept Exception as e:print(f"解析 JD 文件时出错: {str(e)}")return Nonedef read_json(file_path: str) -> dict:"""读取 JSON 文件并返回其内容。参数:file_path (str): JSON 文件的路径。返回:dict: JSON 文件的内容。"""try:with open(file_path, 'r', encoding='utf-8') as json_file:data = json.load(json_file)return dataexcept Exception as e:print(f"读取 JSON 文件时出错: {str(e)}")return {}from langchain.text_splitter import MarkdownHeaderTextSplitter
from langchain.schema import Documentdef parse_cv_to_md(llm, cv_file_path: str):"""将给定的简历文件内容解析为 JSON,并存储到指定路径下。参数:llm: 大模型。cv_file_path (str): 简历文件的路径。返回:str: 存储的 Markdown 文件路径。"""try:with open(cv_file_path, 'r', encoding='utf-8') as cv_file:cv_content = cv_file.read().strip()template = """
基于简历文本,按照约束,转换成Markdown格式:简历文本:
[{cv_content}]约束:
1、只用一级标题和二级标题分出来简历的大块和小块
2、一级标题只有这些:个人信息、教育经历、工作经历、项目经历、校园经历、职业技能、曾获奖项、兴趣爱好、自我评价、其他信息。Markdown:
"""parser = StrOutputParser()prompt = PromptTemplate(template=template,input_variables=["cv_content"])print(prompt.template)chain = prompt | llm | parserresult = chain.invoke({"cv_content": cv_content})# 打印print(result)print(type(result))# 存储到 data 目录下output_file_path = "data/cv.md"with open(output_file_path, 'w', encoding='utf-8') as output_file:output_file.write(result.strip("```"))output_file.write("\n\n")print(f"已存储最终 Markdown 文件到 {output_file_path}")return output_file_pathexcept Exception as e:print(f"解析 CV 文件时出错: {str(e)}")return Nonedef parse_md_file_to_docs(file_path):with open(file_path, 'r', encoding='utf-8') as file:markdown_text = file.read()docs = []headers_to_split_on = [("#", "Title 1"),("##", "Title 2"),# ("###", "Title 3"),# ("###", "Title 4")]markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)split_docs = markdown_splitter.split_text(markdown_text)for split_doc in split_docs:metadata = split_doc.metadatatitle_str = f"# {metadata.get('Title 1', 'None')}\n## {metadata.get('Title 2', 'None')}\n"page_content = title_str + split_doc.page_content.strip()doc = Document(page_content=page_content,metadata=metadata)docs.append(doc)return docsif __name__ == "__main__":from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv())from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-4", temperature=0) # gpt-3.5-turbo# # jd# jd_file_path = "data/jd.txt"# result = parse_jd_to_json(llm, jd_file_path)# print(result)# cvcv_file_path = "data/cv.txt"result = parse_cv_to_md(llm, cv_file_path)print(result)相关文章:
大模型架构记录13【hr agent】
一 Function calling 函数调用 from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv())from openai import OpenAI import jsonclient OpenAI()# Example dummy function hard coded to return the same weather # In production, this could be your back…...

conda 清除 tarballs 减少磁盘占用 、 conda rename 重命名环境、conda create -n qwen --clone 当前环境
🥇 版权: 本文由【墨理学AI】原创首发、各位读者大大、敬请查阅、感谢三连 🎉 声明: 作为全网 AI 领域 干货最多的博主之一,❤️ 不负光阴不负卿 ❤️ 文章目录 conda clean --tarballsconda rename 重命名环境conda create -n qwen --clone …...

Java基础-24-继承-认识继承-权限修饰符-继承的特点
在Java中,继承是面向对象编程(OOP)的一个重要特性。通过继承,一个类可以复用另一个类的属性和方法,从而实现代码的重用性和扩展性。以下是关于继承的一些关键点,包括权限修饰符和继承的特点。 1. 继承的基本…...

Bootstrap 表格:高效布局与动态交互的实践指南
Bootstrap 表格:高效布局与动态交互的实践指南 引言 Bootstrap 是一个流行的前端框架,它为开发者提供了丰富的组件和工具,使得构建响应式、美观且功能丰富的网页变得更加简单。表格是网页中常见的元素,用于展示数据。Bootstrap 提供了强大的表格组件,可以帮助开发者轻松…...

pycharm相对路径引用方法
用于打字不方便,以下直接手写放图,直观理解...

新能源智慧灯杆的智能照明系统如何实现节能?
叁仟新能源智慧灯杆的智能照明系统可通过以下多种方式实现节能: 智能调光控制 光传感器技术:在灯杆上安装光传感器,实时监测周围环境的光照强度。当环境光线充足时,如白天或有其他强光源时,智能照明系统会自动降低路…...

Jenkins教程(自动化部署)
Jenkins教程(自动化部署) 1. Jenkins是什么? Jenkins是一个开源的、提供友好操作界面的持续集成(CI)工具,广泛用于项目开发,具有自动化构建、测试和部署等功能。Jenkins用Java语言编写,可在Tomcat等流行的servlet容器中运行&…...

行业智能体大爆发,分布式智能云有解
Manus的一夜爆红,在全球范围内引爆关于AI智能体的讨论。 与过去一般的AI助手不同,智能体(AI Agent)并非只是被动响应,而是主动感知、决策并执行的应用。Gartner预测,到2028年,15%的日常工作决策…...

日语Learn,英语再认识(5)
This is a dedicated function — it exists solely to solve this case. This is a dedicated function. It’s a dedicated method for solving this case. 其他备选词(但没dedicated精准): special → 含糊,有时只是“特别”…...

【区块链安全 | 第十四篇】类型之值类型(一)
文章目录 值类型布尔值整数运算符取模运算指数运算 定点数地址(Address)类型转换地址的成员balance 和 transfersendcall,delegatecall 和 staticcallcode 和 codehash 合约类型(Contract Types)固定大小字节数组&…...
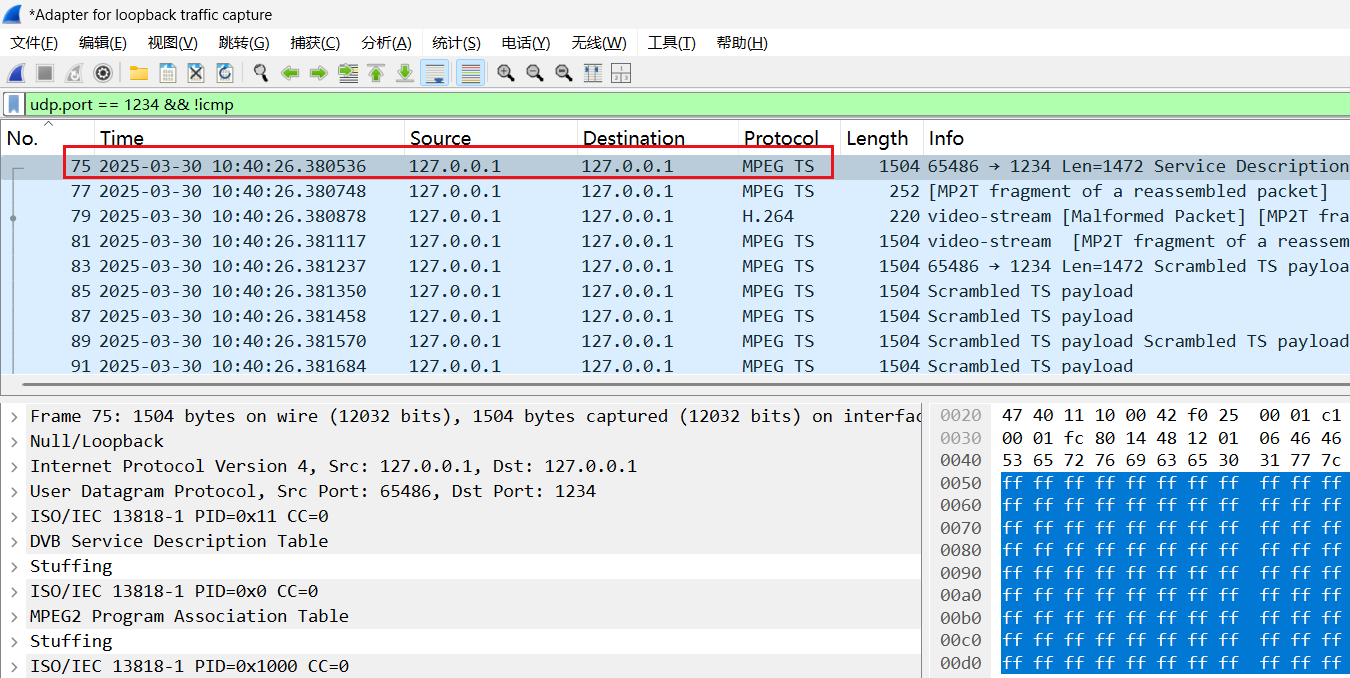
音视频入门基础:MPEG2-TS专题(25)——通过FFmpeg命令使用UDP发送TS流
一、通过FFmpeg命令使用UDP发送TS流 通过以下FFmpeg命令可以将一个mp4文件转换为ts封装,并基于UDP发送(推流): ffmpeg.exe -re -i input.mp4 -vcodec copy -acodec copy -f mpegts udp://127.0.0.1:1234 其中: “in…...

Error in torch with streamlit
报错信息: This is the error which is a conflict between torch and streamlit: Examining the path of torch.classes raised: Tried to instantiate class path.path’, but it does not exist! Ensure that it is registered via torch::class Steps to reproduce: py…...

网络基础知识介绍
目录 一、计算机网络背景与发展 1.1 计算机网络的背景 编辑1.2 计算机网络的发展历程 二、网络协议 2.1 认识网络协议 2.3 协议分层 2.4 OSI七层模型 2.5 TCP/IP 五层(或四层)模型 三、网络传输基本流程 3.1 网络传输流…...

MIPS-32架构(寄存器堆,指令系统,运算器)
文章目录 0 Preview:寄存器32通用0 $zero1 $at2—3 \$v0-$v14—7 \$a0-$a38—15 \$t0-$t716—23 \$s0-$s724—25 \$t8-$t926—27 \$k0-$k128 $gp29 $sp30 $fp 指令系统运算存储器 0 Preview: MIPS架构有32位版本和64位版本,本文介绍32位版本 寄存器 正如笔者曾说…...

zip和tar.gz
本文来源: 在压缩文件格式选择上,zip和tar.gz有本质差异,主要体现在以下五个方面: 一、压缩机制不同 tar.gz是"两步走"方案:先用tar工具将多个文件/目录打包为单个未压缩的归档文件(保留权限…...

【什么是机器学习——多项式逼近】
什么是机器学习——多项式逼近 机器学习可以分成三大类别,监督学习、非监督学习、强化学习。三大类别背后的数学原理不同。监督学习使用了数学分析中的函数逼近方法和概率统计中的极大似然方法;非监督学习使用聚类和EM算法;强化学习使用马尔可夫决策过程的想法。 机器学习的…...

C++中的搜索算法实现
C中的搜索算法实现 在编程中,搜索算法是解决各种问题的基础工具之一。C作为一种功能强大的编程语言,提供了多种实现搜索算法的方式。本文将详细介绍两种常见的搜索算法:线性搜索和二分搜索,并通过代码示例展示它们的实现。 一、…...
Dart 中的 Mixins 使用教程)
(二十三)Dart 中的 Mixins 使用教程
Dart 中的 Mixins 使用教程 Mixins 简介 Mixins 是 Dart 中一种强大的特性,中文意思是“混入”,它允许在类中混入其他功能,从而实现类似多继承的功能。与传统的继承不同,Mixins 提供了一种更加灵活的方式来组合类的功能…...

《午夜地铁的幽灵AP》
点击下面图片带您领略全新的嵌入式学习路线 🔥爆款热榜 88万阅读 1.6万收藏 文章目录 **第一章:末班车的二进制月光****第二章:ESP32的赛博墓志铭****第三章:都市传说与CRC校验****第四章:数字孪生的献祭仪式****终章…...

创作领域“<em >彩</em><em>票</em><em>导</em><em>师</em><em>带</em><em>玩</em><em>群
天光揉碎最后一块夜斑,露珠压弯草叶的脆响惊醒了沉睡的巷子。青灰雾霭中,老墙上的爬山虎在打哈欠,卷曲的藤须滴落隔夜的月光。sFsTU...

Spring Cloud Gateway中GatewayFilter Factories(网关过滤工厂)的详细介绍
文章目录 1、网关过滤工厂介绍2、 GatewayFilter 过滤器的基本配置3、 Spring Cloud Gateway 内置 GatewayFilter Factories3.1、AddRequestHeader GatewayFilter3.2、AddResponseHeader GatewayFilter3.3、AddRequestParameter GatewayFilter3.4、RewritePath GatewayFilter3.…...

微服务架构:构建可持续演进的微服务架构的原则与实践指南
引言:微服务的价值锚点 某物流公司微服务化后,订单履约周期从2小时缩短至15分钟,但技术债务却以每年200%的速度增长。这个案例揭示了一个关键认知:微服务架构的成败不在于技术实现,而在于是否建立有效的演进机制。…...

C++的四种类型转换
文章目录 const_cast:去掉常量类型的类型转换static_cast:提供编译器认为安全的类型转换(在编译阶段完成类型转换)reinterpret:类似c风格的强制类型转化dynamic_cast:主要用在继承结构里,可以支持RTTI类型识别的上下转换dynamic_cast<>…...

Python Cookbook-4.15 字典的一键多值
任务 需要一个字典,能够将每个键映射到多个值上。 解决方案 正常情况下,字典是一对一映射的,但要实现一对多映射也不难,换句话说,即一个键对应多个值。你有两个可选方案,但具体要看你怎么看待键的多个对…...

《Python实战进阶》No37: 强化学习入门加餐版3 之 Q-Learning算法可视化升级
连续第4篇文章写Q-Learning算法及可视化 Q-Learning强化学习算法在迷宫寻路中的应用 引言 强化学习是机器学习的一个重要分支,其核心理念是通过与环境的交互来学习最优策略。在上三篇文章中,《Python实战进阶》No37: 强化学习入门:Q-Learn…...
)
1.两数之和(Java)
1. 题目描述 LeetCode 1. 两数之和(Two Sum) 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那两个整数,并返回它们的索引。 示例 1: 输入:nums [2,7,11,15], target 9 …...

漏洞挖掘---灵当CRM客户管理系统getOrderList SQL注入漏洞
一、灵当CRM 灵当CRM是上海灵当信息科技有限公司旗下产品,适用于中小型企业。它功能丰富,涵盖销售、服务、财务等管理功能,具有性价比高、简洁易用、可定制、部署灵活等特点,能助力企业提升经营效益和客户满意度。 二、FOFA-Sear…...

Java高频面试之集合-20
hello啊,各位观众姥爷们!!!本baby今天来报道了!哈哈哈哈哈嗝🐶 面试官:讲讲 HashSet 的底层实现? HashSet 是 Java 集合框架中用于存储唯一元素的高效数据结构,其底层实…...

sort命令:排序
sort:默认首位排序 参数: -n:按整个数字排序 -r:降序 -u:去重 [rootrobin ~]# sort -n aa.txt #按数字排序(正序) [rootrobin ~]# sort -nr aa.txt #降序 [rootrobin ~]# sort -…...

Javaweb后端 AOP快速入门 AOP核心概念 AOP执行流程
AOP是对特定方法编程,把共用都用的方法提取出来,统一维护 AOP基础 AOP快速入门 对原始方法无影响 AOP核心概念 连接点,是原始方法,被控制范围内的原始方法 通知,AOP类里面写的公共的方法 切入点,实际被AO…...