聚类(Clustering)基础知识3
文章目录
- 一、聚类的性能评价
- 1、聚类性能评价
- (1)聚类性能评价方法:
- 2、参考模型 (reference model)
- (1)数据集:
- (2)聚类结果:
- (3)参考模型:
- (4)标记向量:
- (5)样本对数目计算:
- (6)外部评价指标:
- 3、外部索引
- (1)Jaccard 系数 (JC)
- Fowlkes and Mallows 指数 (FMI)
- (2)Rand 指数 (Rand Index), RI
- 4、无参考模型
- (1)大部分时候只有聚类结果,没有参考模型,只能用内部评价法评估聚类的性能:
- 5、簇内相似度
- (1)平均距离:
- (2)最大距离:
- (3)簇的半径 (diameter):
- 6、簇间相似度/距离
- (1)最小距离:
- (2)类中心之间的距离:
- 7、内部评价指标
- (1)DB 指数 (DBI)
- (2)Dunn 指数 (DI)
- 8、Calinski-Harabaz Index (CHI)
- 9、轮廓指数 (Silhouette Index)
- (1)例:轮廓指数
- (2)例:根据SI选择聚类数目
- 10、聚类小结
- 11、Scikit-Learn中的聚类算法
- (1)Classes sklearn.cluster
- 12、Scikit-Learn中的聚类算法示例
- 13、采用Scikit-Learn进行聚类算法的实例
一、聚类的性能评价
1、聚类性能评价
(1)聚类性能评价方法:
聚类性能评价方法主要分为两种:
- 外部评价法 (external criterion):评估聚类结果与参考结果的相似程度。
- 内部评价法 (internal criterion):评估聚类的本质特征,无需参考结果。
2、参考模型 (reference model)
(1)数据集:
- 数据集: D = { x 1 , x 2 , . . . , x N } D = \{x_1, x_2, ..., x_N\} D={x1,x2,...,xN}
(2)聚类结果:
- 聚类结果: C = { C 1 , C 2 , . . . , C K } C = \{C_1, C_2, ..., C_K\} C={C1,C2,...,CK},其中 C k C_k Ck表示属于类别 k k k的样本的集合。
(3)参考模型:
- 参考模型: C ∗ = { C 1 ∗ , . . . , C K ∗ } C^* = \{C_1^*, ..., C_K^*\} C∗={C1∗,...,CK∗}
(4)标记向量:
- λ \lambda λ 和 λ ∗ \lambda^* λ∗ 分别为 C C C和 C ∗ C^* C∗ 的标记向量。
(5)样本对数目计算:
- a = # { ( x i , x j ) ∣ x i , x j ∈ C k ; x i , x j ∈ C l ∗ } a = \#\{(x_i, x_j) | x_i, x_j \in C_k; \ x_i, x_j \in C_l^*\} a=#{(xi,xj)∣xi,xj∈Ck; xi,xj∈Cl∗}
- 在两种聚类结果中,两个样本的所属簇相同。
- d = # { ( x i , x j ) ∣ x i ∈ C k 1 , x j ∈ C k 2 ; x i ∈ C l 1 ∗ , x j ∈ C l 2 ∗ } d = \#\{(x_i, x_j) | x_i \in C_{k1}, x_j \in C_{k2}; \ x_i \in C_{l1}^*, x_j \in C_{l2}^*\} d=#{(xi,xj)∣xi∈Ck1,xj∈Ck2; xi∈Cl1∗,xj∈Cl2∗}
- 在两种聚类结果中,两个样本的所属簇不同。
- b = # { ( x i , x j ) ∣ x i , x j ∈ C k ; x i ∈ C l 1 ∗ , x j ∈ C l 2 ∗ } b = \#\{(x_i, x_j) | x_i, x_j \in C_k; \ x_i \in C_{l1}^*, x_j \in C_{l2}^*\} b=#{(xi,xj)∣xi,xj∈Ck; xi∈Cl1∗,xj∈Cl2∗}
- c = # { ( x i , x j ) ∣ x i ∈ C k 1 , x j ∈ C k 2 ; x i , x j ∈ C l ∗ } c = \#\{(x_i, x_j) | x_i \in C_{k1}, x_j \in C_{k2}; \ x_i, x_j \in C_l^*\} c=#{(xi,xj)∣xi∈Ck1,xj∈Ck2; xi,xj∈Cl∗}
(6)外部评价指标:
利用 ( a , b , c , d ) (a, b, c, d) (a,b,c,d)定义外部评价指标:
| N ( N − 1 ) / 2 N(N-1)/2 N(N−1)/2 | 参考模型 | 相同 | 不同 |
|---|---|---|---|
| 聚类结果 | 相同 | a a a | b b b |
| 不同 | c c c | d d d |
3、外部索引
(1)Jaccard 系数 (JC)
- J C = a a + b + c JC = \frac{a}{a+b+c} JC=a+b+ca
- J C ∈ [ 0 , 1 ] JC \in [0,1] JC∈[0,1], J C ↑ JC \uparrow JC↑,一致性 ↑ \uparrow ↑
Fowlkes and Mallows 指数 (FMI)
- F M I = a a + b ⋅ a a + c FMI = \sqrt{\frac{a}{a+b} \cdot \frac{a}{a+c}} FMI=a+ba⋅a+ca
- F M I ∈ [ 0 , 1 ] FMI \in [0,1] FMI∈[0,1], F M I ↑ FMI \uparrow FMI↑,一致性 ↑ \uparrow ↑
(2)Rand 指数 (Rand Index), RI
- R I = 2 ( a + d ) N ( N − 1 ) RI = \frac{2(a+d)}{N(N-1)} RI=N(N−1)2(a+d)
- R I ∈ [ 0 , 1 ] RI \in [0,1] RI∈[0,1], R I ↑ RI \uparrow RI↑,一致性 ↑ \uparrow ↑
4、无参考模型
(1)大部分时候只有聚类结果,没有参考模型,只能用内部评价法评估聚类的性能:
- 簇内相似度越高,聚类质量越好。
- 簇间相似度越低,聚类质量越好。
5、簇内相似度
(1)平均距离:
- a v g ( C k ) = 1 ∣ C k ∣ ( ∣ C k ∣ − 1 ) ∑ x i , x j ∈ C k d i s t ( x i , x j ) avg(C_k) = \frac{1}{|C_k|(|C_k|-1)} \sum_{x_i, x_j \in C_k} dist(x_i, x_j) avg(Ck)=∣Ck∣(∣Ck∣−1)1∑xi,xj∈Ckdist(xi,xj)
- 其中 ∣ C k ∣ |C_k| ∣Ck∣表示簇 C k C_k Ck中元素的数目。
(2)最大距离:
- d i a m ( C k ) = max x i , x j ∈ C k d i s t ( x i , x j ) diam(C_k) = \max_{x_i, x_j \in C_k} dist(x_i, x_j) diam(Ck)=maxxi,xj∈Ckdist(xi,xj)
(3)簇的半径 (diameter):
- d i a m ( C k ) = 1 ∣ C k ∣ ∑ x i ∈ C k ( d i s t ( x i , μ k ) ) 2 diam(C_k) = \sqrt{\frac{1}{|C_k|} \sum_{x_i \in C_k} (dist(x_i, \mu_k))^2} diam(Ck)=∣Ck∣1∑xi∈Ck(dist(xi,μk))2
- 其中 μ k = 1 ∣ C k ∣ ∑ x i ∈ C k x i \mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i μk=∣Ck∣1∑xi∈Ckxi

- 其中 μ k = 1 ∣ C k ∣ ∑ x i ∈ C k x i \mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i μk=∣Ck∣1∑xi∈Ckxi
6、簇间相似度/距离
(1)最小距离:
- d m i n ( C k , C l ) = min x i ∈ C k , x j ∈ C l d i s t ( x i , x j ) d_{min}(C_k, C_l) = \min_{x_i \in C_k, x_j \in C_l} dist(x_i, x_j) dmin(Ck,Cl)=minxi∈Ck,xj∈Cldist(xi,xj)

(2)类中心之间的距离:
- d c e n ( C k , C l ) = d i s t ( μ k , μ l ) d_{cen}(C_k, C_l) = dist(\mu_k, \mu_l) dcen(Ck,Cl)=dist(μk,μl),
- 其中 μ k = 1 ∣ C k ∣ ∑ x i ∈ C k x i \mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i μk=∣Ck∣1∑xi∈Ckxi

- 其中 μ k = 1 ∣ C k ∣ ∑ x i ∈ C k x i \mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i μk=∣Ck∣1∑xi∈Ckxi
7、内部评价指标
(1)DB 指数 (DBI)
D B I = 1 K ∑ k = 1 K max k ≠ l a v g ( C k ) + a v g ( C l ) d c e n ( C k , C l ) DBI = \frac{1}{K} \sum_{k=1}^{K} \max_{k \neq l} \frac{avg(C_k) + avg(C_l)}{d_{cen}(C_k, C_l)} DBI=K1∑k=1Kmaxk=ldcen(Ck,Cl)avg(Ck)+avg(Cl),
簇内距离/簇间距离
D B I ↓ DBI \downarrow DBI↓,聚类质量 ↑ \uparrow ↑
(2)Dunn 指数 (DI)
D I = min 1 ≤ k < l ≤ K d m i n ( C k , C l ) max 1 ≤ k ≤ K d i a m ( C k ) DI = \min_{1 \leq k < l \leq K} \frac{d_{min}(C_k, C_l)}{\max_{1 \leq k \leq K} diam(C_k)} DI=min1≤k<l≤Kmax1≤k≤Kdiam(Ck)dmin(Ck,Cl),
最小簇间距离/最大簇的半径
D I ↑ DI \uparrow DI↑,聚类质量 ↑ \uparrow ↑
8、Calinski-Harabaz Index (CHI)
C H I = t r ( B ) t r ( W ) × N − K K − 1 CHI = \frac{tr(B)}{tr(W)} \times \frac{N - K}{K - 1} CHI=tr(W)tr(B)×K−1N−K,
C H I ↑ CHI \uparrow CHI↑,聚类质量 ↑ \uparrow ↑ 计算快
其中 W W W为簇内散度矩阵: W = ∑ k = 1 K ∑ x i ∈ C k ( x i − μ k ) ( x i − μ k ) ⊤ W = \sum_{k=1}^{K} \sum_{x_i \in C_k} (x_i - \mu_k)(x_i - \mu_k)^\top W=∑k=1K∑xi∈Ck(xi−μk)(xi−μk)⊤
其中簇中心 μ k = 1 ∣ C k ∣ ∑ x i ∈ C k x i \mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i μk=∣Ck∣1∑xi∈Ckxi
t r ( W ) = ∑ k = 1 K ∑ x i ∈ C k d i s t ( x i , μ k ) tr(W) = \sum_{k=1}^{K} \sum_{x_i \in C_k} dist(x_i, \mu_k) tr(W)=∑k=1K∑xi∈Ckdist(xi,μk),为矩阵 W W W的迹
B B B为簇间散度矩阵: B = ∑ k = 1 K ∣ C k ∣ ( μ k − μ ) ( μ k − μ ) ⊤ B = \sum_{k=1}^{K} |C_k|(\mu_k - \mu)(\mu_k - \mu)^\top B=∑k=1K∣Ck∣(μk−μ)(μk−μ)⊤
其中 μ = 1 N ∑ i = 1 N x i \mu = \frac{1}{N} \sum_{i=1}^{N} x_i μ=N1∑i=1Nxi
t r ( B ) = ∑ k = 1 K ∣ C k ∣ d i s t ( μ k , μ ) tr(B) = \sum_{k=1}^{K} |C_k|dist(\mu_k, \mu) tr(B)=∑k=1K∣Ck∣dist(μk,μ)
9、轮廓指数 (Silhouette Index)
对于其中的一个样本点 i i i,记:
- a ( i ) a(i) a(i):样本点 i i i到与其所属簇中其它点的平均距离
- d ( i , C k ) ‾ \overline{d(i, C_k)} d(i,Ck):样本点 i i i到其他簇 C k ( x i ∉ C k ) C_k (x_i \notin C_k) Ck(xi∈/Ck)内所有点的平均距离
- b ( i ) b(i) b(i):所有 d ( i , C k ) ‾ \overline{d(i, C_k)} d(i,Ck)的最小值
则样本点 i i i的轮廓宽度为: s ( i ) = b ( i ) − a ( i ) max ( a ( i ) , b ( i ) ) s(i) = \frac{b(i) - a(i)}{\max(a(i), b(i))} s(i)=max(a(i),b(i))b(i)−a(i)
s ( i ) ∈ [ − 1 , 1 ] s(i) \in [-1, 1] s(i)∈[−1,1]
S I ↑ SI \uparrow SI↑,聚类质量 ↑ \uparrow ↑
平均轮廓值为: S I = 1 N ∑ i = 1 N s ( i ) SI = \frac{1}{N} \sum_{i=1}^{N} s(i) SI=N1∑i=1Ns(i)
(1)例:轮廓指数
SI值小的点为边缘点
(2)例:根据SI选择聚类数目
2个簇轮廓分数高,但2个簇的大小不均衡
4个簇轮廓分数高,且每个簇的轮廓大小比较均衡
3个簇和5个簇比较糟糕:因为存在低于平均轮廓分数的聚类,轮廓图的大小波动很大
10、聚类小结
聚类与应用高度相关
聚类很难评估,但实际应用中很有用
聚类方法
- 基于中心的模型:如K均值聚类
- 基于连接性的模型:如层次聚类(BIRCH、CURE、CHAMELEON、GRIN)
- 基于分布的模型:基于数据点的产生分布确定模型,如高斯混合模型
- 基于密度的模型:如DBSCAN、OPTICS、DENCLUE、Mean-shift
- 基于图模型的聚类:谱聚类
- 基于网格的聚类:STING、CLIQUE
- 基于模型的聚类:SOM、基于神经网络的聚类
两个通用工具
- EM
- 图及其拉普拉斯矩阵
11、Scikit-Learn中的聚类算法
(1)Classes sklearn.cluster
| Classes | Description |
|---|---|
| cluster.AffinityPropagation(…) | Perform Affinity Propagation Clustering of data. |
| cluster.AgglomerativeClustering(…) | Agglomerative Clustering. |
| cluster.Birch(…) | Implements the BIRCH clustering algorithm. |
| cluster.DBSCAN(…) | Perform DBSCAN clustering from vector array or distance matrix. |
| cluster.FeatureAgglomeration(…) | Agglomerate features. |
| cluster.KMeans(…) | K-Means clustering. |
| cluster.MiniBatchKMeans(…) | Mini-Batch K-Means clustering. |
| cluster.MeanShift(…) | Mean shift clustering using a flat kernel. |
| cluster.OPTICS(…) | Estimate clustering structure from vector array. |
| cluster.SpectralClustering(…) | Apply clustering to a projection of the normalized Laplacian. |
| cluster.SpectralBiclustering(…) | Spectral biclustering (Kluger, 2003). |
| cluster.SpectralCoClustering(…) | Spectral Co-Clustering algorithm (Dhillon, 2001). |
Scikit-Learn 官方文档
12、Scikit-Learn中的聚类算法示例

13、采用Scikit-Learn进行聚类算法的实例
- Python Data Science Handbook
- Neptune.ai 聚类算法博客
相关文章:
聚类(Clustering)基础知识3
文章目录 一、聚类的性能评价1、聚类性能评价(1)聚类性能评价方法: 2、参考模型 (reference model)(1)数据集:(2)聚类结果:(3)参考模型࿱…...

RK3588使用笔记:设置程序/服务开机自启
一、前言 一般将系统用作嵌入式设备时肯定要布置某些程序,这时候就需要对程序设置开机自己,否则每次都要人为启动,当有些嵌入式系统未连接显示屏或者无桌面环境去操作启动程序时,程序自启就是必须的了,本文介绍在纯li…...

Python-数据处理
第十五章 生成数据 安装Matplotlib:通过pip install matplotlib命令安装库。绘制折线图的核心语法为: import matplotlib.pyplot as plt x_values [1, 2, 3] y_values [1, 4, 9] plt.plot(x_values, y_values, linewidth2) plt.title(&quo…...

LoRA技术全解析:如何用4%参数量实现大模型高效微调
引言 在当今的人工智能领域,大型语言模型(LLM)已经成为革命性的技术。然而,这些模型通常拥有数十亿个参数,全量微调成本极高。本文将为初级开发者详细讲解LoRA(Low-Rank Adaptation)技术&#…...

职测-言语理解与表达
成语填空 成语的误用 误用①:望文生义【按成语的字面意思去理解,导致误用】 成语解释如数家珍对列举的事物或叙述的故事十分熟悉,但熟悉的对象不能是自己收藏的宝贝目无全牛比喻技术熟练到得心应手的境地登堂入室比喻学问或技艺由浅入深&a…...
)
深度学习处理文本(2)
建立词表索引 将文本拆分成词元之后,你需要将每个词元编码为数值表示。你可以用无状态的方式来执行此操作,比如将每个词元哈希编码为一个固定的二进制向量,但在实践中,你需要建立训练数据中所有单词(“词表”&…...

python实现股票数据可视化
最近在做一个涉及到股票数据清洗及预测的项目,项目中需要用到可视化股票数据这一功能,这里我与大家分享一下股票数据可视化的一些基本方法。 股票数据获取 目前,我已知的使用python来获取股票数据方式有以下三种: 爬虫获取,实现…...

JavaScript DOM与元素操作
目录 DOM 树、DOM 对象、元素操作 一、DOM 树与 DOM 对象 二、获取 DOM 元素 1. 基础方法 2. 现代方法(ES6) 三、修改元素内容 四、修改元素常见属性 1. 标准属性 2. 通用方法 五、通过 style 修改样式 六、通过类名修改样式 1. className 属…...

ARM向量表
向量表作用说明RVBAR在 AArch64 中,重置向量不再是异常向量表的一部分。 有复位向量的专用配置输入引脚和寄存器。在 AArch64 中,处理器从 IMPLEMENTAION‑DEFINED 地址开始执行, 该地址由硬件输入引 脚RVBARADDR定义, 可以通过 R…...

leetcode刷题日记——除自身以外数组的乘积
[ 题目描述 ]: [ 思路 ]: 题目要求获取数组中每个元素除自己以外的各元素的乘积最简单的方法就是算出数组所有元素的乘积,然后除以自身,即可得到除自身外各元素的乘积 但要考虑到其自身为0的情况,即当期自身为0时&am…...

【信奥一本通提高篇】基础算法之贪心算法
原文 https://bbs.fmcraft.top/blog/index.php/archives/22/ 贪心算法 概述 近年来的信息学竞赛试题,经常出现求一个问题的可行解或最优解的题目。这类问题就是我们通常所说的最优化问题。贪心算法是求解这类问题的一种常用算法。在众多的算法中,贪心…...

PyQt6实例_批量下载pdf工具_批量pdf网址获取
目录 前置: 步骤: step one 安装包 step two 获取股票代码 step three 敲代码,实现 step four 网址转pdf网址 视频 前置: 1 本系列将以 “PyQt6实例_批量下载pdf工具”开头,放在 【PyQt6实例】 专栏 2 本节讲…...
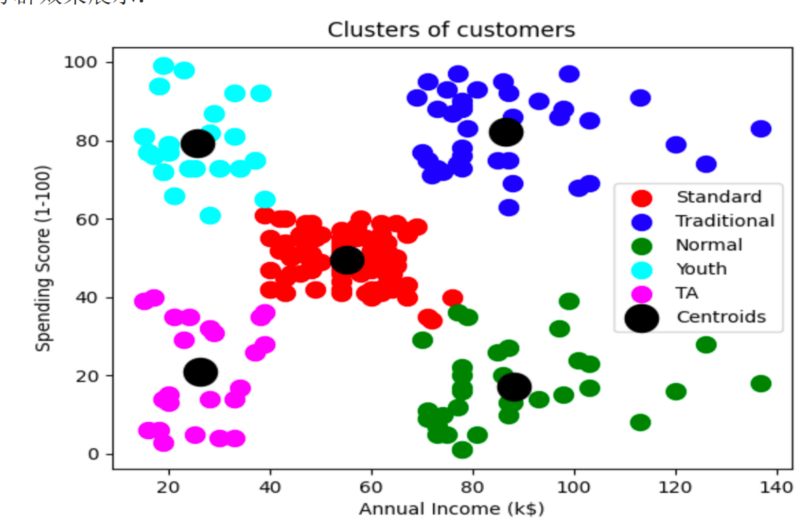
KMeans算法案例
KMeans算法案例 案例介绍 已知:客户性别、年龄、年收入、消费指数 需求:对客户进行分析,找到业务突破口,寻找黄金客户 数据集共包含顾客的数据, 数据共有 4 个特征, 数据共有 200 条。接下来,使用聚类算法对具有相似…...

IDApro直接 debug STM32 MCU
使用IDA pro 逆向分析muc 固件的时候, 难免要进行一些动态的debug,来进一步搞清楚一些内存的数据、算法等,这时候使用远程debug 的方式直接在mcu上进行debug 最合适不过了。 不过有个前提条件就是一般来说有的mcu 会被运行中的代码屏蔽 RDP、…...

六十天前端强化训练之第三十六天之E2E测试(Cypress)大师级完整指南
欢迎来到编程星辰海的博客讲解 看完可以给一个免费的三连吗,谢谢大佬! 目录 一、知识讲解 1. E2E测试核心概念 2. Cypress框架特性 3. 工作原理 4. 测试金字塔定位 二、核心代码示例:用户登录全流程测试 三、实现效果展示 四、学习要…...

创建和管理Pod
创建和管理Pod 文章目录 创建和管理Pod[toc]一、什么是Pod1.Pod 的核心定义2.Pod 的组成与结构3.Pod 的生命周期4.Pod 的使用场景5.高级特性 二、Pod与容器1. 为什么使用 Pod 作为 Kubernetes 的最小部署单元?2. 单一容器 Pod3. 多容器 Pod4. 初始化容器(…...

20250330-傅里叶级数专题之离散傅里叶变换(5/6)
5. 傅里叶级数专题之离散傅里叶变换 推荐视频: 工科生以最快的速度理解离散傅立叶变换(DFT) 哔哩哔哩 20250328-傅里叶级数专题之数学基础(0/6)-CSDN博客20250330-傅里叶级数专题之傅里叶级数(1/6)-CSDN博客20250330-傅里叶级数专题之傅里叶变换(2/6)-CSDN博客20250330-傅里叶…...

Android设计模式之代理模式
一、定义: 为其他对象提供一种代理以控制对这个对象的访问。 二、角色组成: Subject抽象主题:声明真是主题与代理的共同接口方法,可以是一个抽象类或接口。 RealSubject真实主题:定义了代理表示的真实对象,…...

《非暴力沟通》第十二章 “重获生活的热情” 总结
《非暴力沟通》第十二章 “重获生活的热情” 的核心总结: 本章将非暴力沟通的核心理念延伸至生命意义的探索,提出通过觉察与满足内心深处的需要,打破“义务性生存”的桎梏,让生活回归由衷的喜悦与创造。作者强调,当行动…...

3.29:数据结构-绪论线性表-上
一、时间复杂度 1、ADT 2、定义法计算时间复杂度:统计核心语句的总执行次数 (1)例题1,与2022年的真题对比着写 此题关键在于求和公式的转化,类型为:线性循环嵌套非线性循环 2022年那道题如果考场上实在脑…...

Java项目如何打jar包?
1.java把项目打包成jar 步骤一、IDEA -> File -> Project Structure -> Artifacts -> -> JAR -> From moduls with dependencies... -> 选择 Module 和 Main Class -> 选择 JAR files from libraries JAR files from libraries 解释 extract to the t…...

【奶茶经济学的符号暴力本质】
金字塔式七层分析框架:奶茶经济学的符号暴力本质 第一层:缺货的戏剧经济学 结论:13.7%缺货率是精密计算的神经钩 机制:喜茶新品首日仅投放86.3%门店,制造"限量焦虑"激活前额叶决策区矛盾验证: …...

Python PDF解析利器:pdfplumber | AI应用开发
Python PDF解析利器:pdfplumber全面指南 1. 简介与安装 1.1 pdfplumber概述 pdfplumber是一个Python库,专门用于从PDF文件中提取文本、表格和其他信息。相比其他PDF处理库,pdfplumber提供了更直观的API和更精确的文本定位能力。 主要特点…...

大模型架构记录13【hr agent】
一 Function calling 函数调用 from dotenv import load_dotenv, find_dotenvload_dotenv(find_dotenv())from openai import OpenAI import jsonclient OpenAI()# Example dummy function hard coded to return the same weather # In production, this could be your back…...

conda 清除 tarballs 减少磁盘占用 、 conda rename 重命名环境、conda create -n qwen --clone 当前环境
🥇 版权: 本文由【墨理学AI】原创首发、各位读者大大、敬请查阅、感谢三连 🎉 声明: 作为全网 AI 领域 干货最多的博主之一,❤️ 不负光阴不负卿 ❤️ 文章目录 conda clean --tarballsconda rename 重命名环境conda create -n qwen --clone …...

Java基础-24-继承-认识继承-权限修饰符-继承的特点
在Java中,继承是面向对象编程(OOP)的一个重要特性。通过继承,一个类可以复用另一个类的属性和方法,从而实现代码的重用性和扩展性。以下是关于继承的一些关键点,包括权限修饰符和继承的特点。 1. 继承的基本…...

Bootstrap 表格:高效布局与动态交互的实践指南
Bootstrap 表格:高效布局与动态交互的实践指南 引言 Bootstrap 是一个流行的前端框架,它为开发者提供了丰富的组件和工具,使得构建响应式、美观且功能丰富的网页变得更加简单。表格是网页中常见的元素,用于展示数据。Bootstrap 提供了强大的表格组件,可以帮助开发者轻松…...

pycharm相对路径引用方法
用于打字不方便,以下直接手写放图,直观理解...

新能源智慧灯杆的智能照明系统如何实现节能?
叁仟新能源智慧灯杆的智能照明系统可通过以下多种方式实现节能: 智能调光控制 光传感器技术:在灯杆上安装光传感器,实时监测周围环境的光照强度。当环境光线充足时,如白天或有其他强光源时,智能照明系统会自动降低路…...

Jenkins教程(自动化部署)
Jenkins教程(自动化部署) 1. Jenkins是什么? Jenkins是一个开源的、提供友好操作界面的持续集成(CI)工具,广泛用于项目开发,具有自动化构建、测试和部署等功能。Jenkins用Java语言编写,可在Tomcat等流行的servlet容器中运行&…...