ComplexE的代码注释
目录
- dataloader.py
- model.py
- run.py
先安装软件,配置环境,搞了一周。再看代码写注释搞了一周。中间隔了一周。再安装环境跑代码又一周。最后结果是没结果。自己电脑内存带不动。还不想配电脑,又不会用GPU服务器。哭死哭死。心态崩了。直接发吧。代码主要就三个py文件
论文笔记
数据集下载地址先下载,数据集大概4G+,用程序下载感觉有点慢
官方代码地址
因为python版本问题,将代码中三个 lambda: 进行修改,源代码注释掉了。
dataloader.py
#!/usr/bin/python3
# __future__ 模块实际上是为了解决向后兼容性问题而设计的,使得开发者可以在旧版本的Python环境中使用新版本的语言特性
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function# 导入Python中的一个非常强大的数值计算库——NumPy,并为其指定一个别名np
import numpy as np
# 导入PyTorch库,它是一个开源的机器学习框架
import torch# 从PyTorch的 torch.utils.data 模块中导入 Dataset 类。Dataset 是一个用于表示数据集的抽象类
from torch.utils.data import Dataset# 创建一个自定义数据集类的开始,该类继承自 PyTorch 的 Dataset 类
class TrainDataset(Dataset):# 函数初始化def __init__(self, triples, nentity, nrelation, negative_sample_size, mode, count, true_head, true_tail):self.len = len(triples['head']) # 三元组的个数self.triples = triples # 将所有数据存入triples 中self.nentity = nentity # 存储所有实体(头、尾节点)self.nrelation = nrelation # 存储所有关系self.negative_sample_size = negative_sample_size # 设置负样本的数量self.mode = mode # 工作模式训练、验证、测试)self.count = count # 计算数量self.true_head = true_head # 存储每个关系下的真实头实体集合self.true_tail = true_tail # 存储每个关系下的真实尾实体集合# 返回三元组个数def __len__(self):return self.len# 该方法允许你通过索引访问数据集中的元素。具体来说,这个实现是从一个三元组数据集中获取特定索引处的样本,并为它生成负样本和子采样权重def __getitem__(self, idx):# 将指定位置 idx 的头属性、关系、尾属性装入到 正样本:positive_sample 中head, relation, tail = self.triples['head'][idx], self.triples['relation'][idx], self.triples['tail'][idx]positive_sample = [head, relation, tail]# 子采样权重:subsampling_weight,先计算相应 头实体与关系+尾实体与反向关系 的数量# torch.Tensor()函数注重张量的维度,不同维度之间不可计算,使用应用平方根倒数变换计算权重subsampling_weight = self.count[(head, relation)] + self.count[(tail, -relation-1)]subsampling_weight = torch.sqrt(1 / torch.Tensor([subsampling_weight]))# torch.randint(low, high, size)函数抽取随机整数,从 low(包含)到 high(不包含),并生成指定大小 size 的张量# self.negative_sample_size,,中“,”表示这是一个元组,不可删除# self.negative_sample_size是生成的负样本数量# torch.LongTensor(positive_sample)函数生成一个长度为positive_sample的一维向量negative_sample = torch.randint(0, self.nentity, (self.negative_sample_size,)) # 负样本positive_sample = torch.LongTensor(positive_sample) # 正样本# 返回 正样本、负样本、子采样权重、标识样本(训练、验证、测试)return positive_sample, negative_sample, subsampling_weight, self.mode# 将数据转化为一种合适的模型输入格式,自动调用该函数处理批次数据,一般搭配别的函数使用@staticmethod # 静态方法def collate_fn(data):positive_sample = torch.stack([_[0] for _ in data], dim=0) # 提取其中第一个元素(正样本)negative_sample = torch.stack([_[1] for _ in data], dim=0) # 提取其中第二个元素(负样本)subsample_weight = torch.cat([_[2] for _ in data], dim=0) # 提取其中第三个元素(权重)mode = data[0][3] # 提取第四个样本-模式(训练、验证、测试)# 返回 正样本、负样本、子采样权重、标识样本(训练、验证、测试)return positive_sample, negative_sample, subsample_weight, mode# 从 PyTorch 的 torch.utils.data.Dataset 继承而来
class TestDataset(Dataset):# 初始化def __init__(self, triples, args, mode, random_sampling):self.len = len(triples['head']) # 计算三元组个数self.triples = triples # 将数据存入triples中self.nentity = args.nentity # 存储所有实体(头、尾节点)self.nrelation = args.nrelation # 存储关系self.mode = mode # 模式(训练、验证、测试)self.random_sampling = random_sampling # 是否随机采样if random_sampling: # 随机采样self.neg_size = args.neg_size_eval_train # 随机采样数量# 返回三元组个数def __len__(self):return self.lendef __getitem__(self, idx):# 获取头实体、关系和尾实体并形成正样本head, relation, tail = self.triples['head'][idx], self.triples['relation'][idx], self.triples['tail'][idx]positive_sample = torch.LongTensor((head, relation, tail))# 选择破坏头实体或尾实体来生成负样本if self.mode == 'head-batch': # 破坏头节点if not self.random_sampling: # 不随机采样,使用提前准备的数据negative_sample = torch.cat([torch.LongTensor([head]), torch.from_numpy(self.triples['head_neg'][idx])])else: # 随机采样negative_sample = torch.cat([torch.LongTensor([head]), torch.randint(0, self.nentity, size=(self.neg_size,))])elif self.mode == 'tail-batch': # 破坏尾节点if not self.random_sampling: # 不随机采样,使用提前准备的数据negative_sample = torch.cat([torch.LongTensor([tail]), torch.from_numpy(self.triples['tail_neg'][idx])])else: # 随机采样negative_sample = torch.cat([torch.LongTensor([tail]), torch.randint(0, self.nentity, size=(self.neg_size,))])# 返回正样本、负样本、模式return positive_sample, negative_sample, self.mode# 静态方法@staticmethod# 多个样本组合成一个批次def collate_fn(data):positive_sample = torch.stack([_[0] for _ in data], dim=0) # 正样本negative_sample = torch.stack([_[1] for _ in data], dim=0) # 负样本mode = data[0][2] # 模式# 返回正样本、负样本、模式return positive_sample, negative_sample, modeclass BidirectionalOneShotIterator(object):# 初始化def __init__(self, dataloader_head, dataloader_tail):# 用于生成破坏头节点的数据样本的数据加载器self.iterator_head = self.one_shot_iterator(dataloader_head)# 用于生成破坏尾节点的数据样本的数据加载器self.iterator_tail = self.one_shot_iterator(dataloader_tail)# 迭代的步数self.step = 0def __next__(self):# 迭代加1self.step += 1if self.step % 2 == 0: # 偶数生成破坏头节点的数据data = next(self.iterator_head)else: # 偶数生成破坏尾节点的数据data = next(self.iterator_tail)return data # 返回数据# 静态方法@staticmethoddef one_shot_iterator(dataloader):# 将PyTorch数据加载器转换为python迭代器while True: # 一直循环for data in dataloader: # 循环dataloaderyield data # 将当前批次的数据返回
model.py
#!/usr/bin/python3from __future__ import absolute_import # 启用绝对导入
from __future__ import division # 改变除法运算符 / 的行为,使其总是返回浮点数结果
from __future__ import print_function # 将 print 语句改为函数形式import logging # 用于输出程序运行时的信息(如调试信息、警告、错误等)import numpy as np # 导入 numpy 库用于计算矩阵,并将其命名为 npimport torch # 构建和训练深度学习模型
import torch.nn as nn # 神经网络模块,并将其命名为 nn
import torch.nn.functional as F # 导入 PyTorch 的函数式 API,并将其命名为 Fimport datetime # 日期和时间的高级操作
import time # 处理时间戳、延时、性能测量等任务from torch.utils.data import DataLoader # 常用于训练深度学习模型时批量处理数据
from dataloader import TestDataset # 用于加载测试数据,并提供特定的预处理逻辑
from collections import defaultdict # 允许为不存在的键提供默认值from ogb.linkproppred import Evaluator # 用于评估图机器学习模型的标准基准库# 典型的深度学习模型类,用于知识图谱嵌入
class KGEModel(nn.Module):# 初始化def __init__(self, model_name, nentity, nrelation, hidden_dim, gamma, evaluator,double_entity_embedding=False, double_relation_embedding=False,triple_relation_embedding=False, quad_relation_embedding=False):# 四个布尔标志,控制是否用双倍、三倍或四倍的关系/实体嵌入super(KGEModel, self).__init__() # 初始化模型的基本结构self.model_name = model_name # 模型名称self.nentity = nentity # 实体数量(头、尾节点)self.nrelation = nrelation # 关系的数量self.hidden_dim = hidden_dim # 嵌入维度self.epsilon = 2.0 # 固定值,用于某些模型计算self.gamma = nn.Parameter( # 将张量包装为模型参数torch.Tensor([gamma]), # 创建包含 gamma 值的张量requires_grad=False # 表示该参数不用通过梯度更新)# 定义一个不可训练的参数 embedding_range ,用于控制嵌入向量的取值范围# self.gamma.item(): 提取gamma张量的标量值# (self.gamma.item() + self.epsilon) / hidden_dim: 计算嵌入范围的值。避免梯度小时或者爆炸# torch.Tensor([...]): 将计算结果包装为张量self.embedding_range = nn.Parameter( # 将张量定义为模型的参数torch.Tensor([(self.gamma.item() + self.epsilon) / hidden_dim]),requires_grad=False # 但不允许通过梯度更新,成为一个超参数)# 三元表达式,根据 double_entity_embedding 动态设置实体嵌入的维度self.entity_dim = hidden_dim *2 if double_entity_embedding else hidden_dim# 设置不同的嵌入的维度if double_relation_embedding:self.relation_dim = hidden_dim*2elif triple_relation_embedding:self.relation_dim = hidden_dim*3elif quad_relation_embedding:self.relation_dim = hidden_dim*4else:self.relation_dim = hidden_dimself.entity_embedding = nn.Parameter(torch.zeros(nentity, self.entity_dim))nn.init.uniform_(tensor=self.entity_embedding,a=-self.embedding_range.item(),b=self.embedding_range.item())# 定义一个可训练的参数,表示所有实体的嵌入向量# nn.Parameter(...)将张量包装为模型的可训练参数# torch.zeros(nentity, self.entity_dim):创建一个形状为(nentity, self.entity_dim)的零张量# nentity: 实体的数量、self.entity_dim: 每个实体的嵌入维度self.relation_embedding = nn.Parameter(torch.zeros(nrelation, self.relation_dim))nn.init.uniform_( # 将张量的值初始化均匀分布tensor=self.relation_embedding, # 指定要初始化的张量a=-self.embedding_range.item(), # 均匀分布的下界(最小值)b=self.embedding_range.item() # 均匀分布的上界(最大值))# 检查模型是否在支持的模型列表中。如果不在列表中,则抛出一个异常#在“前进”功能中添加新模型时,不要忘记修改此行if model_name not in ['TransE', 'DistMult', 'ComplEx', 'RotatE', 'PairRE', 'RotatEv2', 'CompoundE']:raise ValueError('model %s not supported' % model_name)# 判断模型名称与模型参数是否匹配if model_name == 'RotatE' and (not double_entity_embedding or double_relation_embedding):raise ValueError('RotatE should use --double_entity_embedding')# 判断模型名称与模型参数是否匹配if model_name == 'ComplEx' and (not double_entity_embedding or not double_relation_embedding):raise ValueError('ComplEx should use --double_entity_embedding and --double_relation_embedding')# 判断模型名称与模型参数是否匹配if model_name == 'PairRE' and (not double_relation_embedding):raise ValueError('PairRE should use --double_relation_embedding')# 判断模型名称与模型参数是否匹配if model_name == 'CompoundE' and (not triple_relation_embedding):raise ValueError('CompoundE should use --triple_relation_embedding')self.evaluator = evaluator # 用于评估模型在特定任务上的性能# 用于计算一批三元组的得分,sample 样本,默认是正样本def forward(self, sample, mode='single'):# 计算一批三元组得分的正向函数。# 在“单一”模式下,样本是一批三重样本。# 在“破坏头节点”或“破坏尾节点”模式下,样品由两部分组成。# 第一部分通常是正样本。# 第二部分是负样本中的实体。# 因为负样本和正样本通常共享两个元素# 在他们的三重((头,关系)或(关系,尾))。# 正样本if mode == 'single':batch_size, negative_sample_size = sample.size(0), 1 # 样本数量,负样本大小head = torch.index_select(self.entity_embedding, # 从嵌入矩阵中选择指定行dim=0, # 按行选择index=sample[:,0] # 选择三元组中第一个实体).unsqueeze(1) # 在维度1上增加一个新维度,(batch_size, entity_dim)变为(batch_size, 1, entity_dim)relation = torch.index_select(self.relation_embedding, # 从嵌入矩阵中选择指定行dim=0, # 按行选择index=sample[:,1] # 选择三元组中第二个实体).unsqueeze(1) # 在维度1上增加一个新维度变为(batch_size, 1, entity_dim)tail = torch.index_select(self.entity_embedding, # 从嵌入矩阵中选择指定行dim=0, # 按行选择index=sample[:,2] # 选择三元组中第三个实体).unsqueeze(1) # 在维度1上增加一个新维度变为(batch_size, 1, entity_dim)# 破坏头节点elif mode == 'head-batch':tail_part, head_part = sample # 分出正、负样本部分batch_size, negative_sample_size = head_part.size(0), head_part.size(1) # 正负样本数量head = torch.index_select(self.entity_embedding, # 从矩阵中选择指定行dim=0, # 按行选择index=head_part.view(-1) # 将 head_part 展平为一维张量,包含所有负样本的头实体索引).view(batch_size, negative_sample_size, -1) # 将展平后的结果重新调整为形状(batch_size, negative_sample_size, entity_dim)relation = torch.index_select(self.relation_embedding, # 从矩阵中选择指定行dim=0, # 按行选择index=tail_part[:, 1] # 选择三元组中第二个实体).unsqueeze(1) # 在维度1上增加一个新维度变为(batch_size, 1, relation_dim)tail = torch.index_select(self.entity_embedding, # 从矩阵中选择指定行dim=0, # 按行选择index=tail_part[:, 2] # 选择三元组中第三个实体).unsqueeze(1) # 在维度1上增加一个新维度变为(batch_size, 1, relation_dim)# 破坏尾节点elif mode == 'tail-batch':head_part, tail_part = sample # 分出正、负样本部分batch_size, negative_sample_size = tail_part.size(0), tail_part.size(1) # 正负样本数量head = torch.index_select(self.entity_embedding, # 从矩阵中选择指定行dim=0, # 按行选择index=head_part[:, 0] # 选择三元组中第一个实体).unsqueeze(1) # 变为 (batch_size, 1, entity_dim)relation = torch.index_select(self.relation_embedding, # 从矩阵中选择指定行dim=0, # 按行选择index=head_part[:, 1] # 选择三元组中第二个实体).unsqueeze(1) # 变为 (batch_size, 1, entity_dim)tail = torch.index_select(self.entity_embedding, # 从矩阵中选择指定行dim=0, # 按行选择index=tail_part.view(-1) # 将 tail_part 展平为一维张量,包含所有负样本的尾实体索引).view(batch_size, negative_sample_size, -1) # 调整为(batch_size, negative_sample_size, entity_dim)# 如果不是上面的模式,报错else:raise ValueError('mode %s not supported' % mode)model_func = { # 模型'TransE': self.TransE, # 平移的距离模型'DistMult': self.DistMult, # 双线性模型'ComplEx': self.ComplEx, # 复数空间的双线性模型'RotatE': self.RotatE, # 旋转操作的模型'PairRE': self.PairRE, # 成对关系表示的模型'RotatEv2': self.RotatEv2, # RotatE的升级版本,论文中好像没看到?作者说代码是参考了PairRE'CompoundE': self.CompoundE # 新模型}if self.model_name in model_func: # 如果模型在程序中score = model_func[self.model_name](head, relation, tail, mode) # 计算得分else:raise ValueError('model %s not supported' % self.model_name) # 报错return score # 返回得分# TransE得分函数def TransE(self, head, relation, tail, mode):if mode == 'head-batch': # 破坏头的三元组,两种形式相同但是意义不同。score = head + (relation - tail)else: # 但是结果好像是相同的,搞不懂(无奈)score = (head + relation) - tail# 计算最终得分。self.gamma.item()超参数。p=1, dim=2,L1 范数,沿着第 2 维度进行,相当于每个三元组进行计算score = self.gamma.item() - torch.norm(score, p=1, dim=2)return score# DistMult得分函数def DistMult(self, head, relation, tail, mode):if mode == 'head-batch':score = head * (relation * tail) # 同上else:score = (head * relation) * tailscore = score.sum(dim = 2)return score# ComplEx得分函数,得分函数自己去AI上找,就是简单的转化,不想写def ComplEx(self, head, relation, tail, mode):re_head, im_head = torch.chunk(head, 2, dim=2)re_relation, im_relation = torch.chunk(relation, 2, dim=2)re_tail, im_tail = torch.chunk(tail, 2, dim=2)if mode == 'head-batch':re_score = re_relation * re_tail + im_relation * im_tailim_score = re_relation * im_tail - im_relation * re_tailscore = re_head * re_score + im_head * im_scoreelse:re_score = re_head * re_relation - im_head * im_relationim_score = re_head * im_relation + im_head * re_relationscore = re_score * re_tail + im_score * im_tailscore = score.sum(dim = 2)return score# RotatE得分函数,得分函数自己去AI上找,就是简单的转化,不想写def RotatE(self, head, relation, tail, mode):pi = 3.14159265358979323846re_head, im_head = torch.chunk(head, 2, dim=2)re_tail, im_tail = torch.chunk(tail, 2, dim=2)#Make phases of relations uniformly distributed in [-pi, pi]phase_relation = relation/(self.embedding_range.item()/pi)re_relation = torch.cos(phase_relation)im_relation = torch.sin(phase_relation)if mode == 'head-batch':re_score = re_relation * re_tail + im_relation * im_tailim_score = re_relation * im_tail - im_relation * re_tailre_score = re_score - re_headim_score = im_score - im_headelse:re_score = re_head * re_relation - im_head * im_relationim_score = re_head * im_relation + im_head * re_relationre_score = re_score - re_tailim_score = im_score - im_tailscore = torch.stack([re_score, im_score], dim = 0)score = score.norm(dim = 0)score = self.gamma.item() - score.sum(dim = 2)return score# RotatEv2得分函数,得分函数自己去AI上找,就是简单的转化,不想写def RotatEv2(self, head, relation, tail, mode, r_norm=None):pi = 3.14159265358979323846re_head, im_head = torch.chunk(head, 2, dim=2)re_tail, im_tail = torch.chunk(tail, 2, dim=2)#Make phases of relations uniformly distributed in [-pi, pi]phase_relation = relation/(self.embedding_range.item()/pi)re_relation = torch.cos(phase_relation)im_relation = torch.sin(phase_relation)re_relation_head, re_relation_tail = torch.chunk(re_relation, 2, dim=2)im_relation_head, im_relation_tail = torch.chunk(im_relation, 2, dim=2)re_score_head = re_head * re_relation_head - im_head * im_relation_headim_score_head = re_head * im_relation_head + im_head * re_relation_headre_score_tail = re_tail * re_relation_tail - im_tail * im_relation_tailim_score_tail = re_tail * im_relation_tail + im_tail * re_relation_tailre_score = re_score_head - re_score_tailim_score = im_score_head - im_score_tailscore = torch.stack([re_score, im_score], dim = 0)score = score.norm(dim = 0)score = self.gamma.item() - score.sum(dim = 2)return score# PairRE得分函数,得分函数自己去AI上找,就是简单的转化,不想写def PairRE(self, head, relation, tail, mode):re_head, re_tail = torch.chunk(relation, 2, dim=2)head = F.normalize(head, 2, -1)tail = F.normalize(tail, 2, -1)score = head * re_head - tail * re_tailscore = self.gamma.item() - torch.norm(score, p=1, dim=2)return score# CompoundE得分函数,这个可以好好看def CompoundE(self, head, relation, tail, mode):tail_scale, tail_translate, theta = torch.chunk(relation, 3, dim=2) # 缩放、平移向量、旋转向量theta, _ = torch.chunk(theta, 2, dim=2)head = F.normalize(head, 2, -1)tail = F.normalize(tail, 2, -1) # 模长为1pi = 3.14159265358979323846 # Πtheta = theta/(self.embedding_range.item()/pi) # 将旋转角度 theta 标准化到[−π,π] 范围内。re_rotation = torch.cos(theta)im_rotation = torch.sin(theta) # 计算旋转的相关信息re_rotation = re_rotation.unsqueeze(-1)im_rotation = im_rotation.unsqueeze(-1) # 增加一个维度,方便后续的计算tail = tail.view((tail.shape[0], tail.shape[1], -1, 2)) # 将尾节点分为两部份,实部、虚部tail_r = torch.cat((re_rotation * tail[:, :, :, 0:1], im_rotation * tail[:, :, :, 0:1]), dim=-1)tail_r += torch.cat((-im_rotation * tail[:, :, :, 1:], re_rotation * tail[:, :, :, 1:]), dim=-1) # 对实部虚部进行旋转tail_r = tail_r.view((tail_r.shape[0], tail_r.shape[1], -1)) # 两个部分重新组成一个部分tail_r += tail_translate # 平移tail_r *= tail_scale # 缩放score = head - tail_r # 计算得分 得分=头节点-尾阶段 (各种计算) 关系score = self.gamma.item() - torch.norm(score, p=1, dim=2) # 计算每个三元组得分return score# 静态方法,结合了正样本和负样本的损失计算、正则化项(如果启用),并通过反向传播更新模型参数@staticmethoddef train_step(model, optimizer, train_iterator, args):# 执行一次训练步骤,应用反向传播算法,并返回损失值model.train() # 训练模式optimizer.zero_grad() # 每次训练步骤开始时,清空优化器中累积的梯度,以避免梯度叠加positive_sample, negative_sample, subsampling_weight, mode = next(train_iterator) # 获取一批数据,包括正样本、负样本、子采样权重和当前模式# 如果配置中启用了GPU,则将数据移动到GPU上,以加速计算if args.cuda:positive_sample = positive_sample.cuda()negative_sample = negative_sample.cuda()subsampling_weight = subsampling_weight.cuda()negative_score = model((positive_sample, negative_sample), mode=mode) # 计算负样本的得分if args.negative_adversarial_sampling: # 启用对抗负采样# 不将采样权重应用于反向传播negative_score = (F.softmax(negative_score * args.adversarial_temperature, dim = 1).detach()* F.logsigmoid(-negative_score)).sum(dim = 1)else: # 直接计算负样本的平均损失negative_score = F.logsigmoid(-negative_score).mean(dim = 1)positive_score = model(positive_sample) # 计算正样本的得分positive_score = F.logsigmoid(positive_score).squeeze(dim = 1) # 转换为概率值if args.uni_weight: # 如果启用了均匀权重,直接计算正负样本的平均损失positive_sample_loss = - positive_score.mean()negative_sample_loss = - negative_score.mean()else: # 否则,根据子采样权重计算加权损失positive_sample_loss = - (subsampling_weight * positive_score).sum()/subsampling_weight.sum()negative_sample_loss = - (subsampling_weight * negative_score).sum()/subsampling_weight.sum()loss = (positive_sample_loss + negative_sample_loss)/2 # 正样本损失和负样本损失取平均作为总损失# 判断是否正则化if args.regularization != 0.0:# 对ComplEx和DistMult使用L3正则化:L3,立方后求和再开立方regularization = args.regularization * (model.entity_embedding.norm(p = 3)**3 +model.relation_embedding.norm(p = 3).norm(p = 3)**3)loss = loss + regularizationregularization_log = {'regularization': regularization.item()} # 启用了正则化,记录正则化项的值else:regularization_log = {} # 如果未启用正则化,则返回空字典loss.backward() # 计算损失的梯度optimizer.step() # 更新模型参数# 将正样本损失、负样本损失、总损失以及正则化项(如果有)记录到日志中。因为配置不支持**操作,所以修改了 log 代码# 初始化 log 字典log = {}# 将 regularization_log 的内容添加到 log 中log.update(regularization_log)# 添加其他字段log['positive_sample_loss'] = positive_sample_loss.item()log['negative_sample_loss'] = negative_sample_loss.item()log['loss'] = loss.item()return log# 静态方法,在测试集或验证集上评估知识图谱嵌入模型的性能@staticmethoddef test_step(model, test_triples, args, random_sampling=False):# 在测试或有效数据集上评估模型# 模型设置为评估模式model.eval()# 准备数据加载器进行评估test_dataloader_head = DataLoader(TestDataset( # 测试数据集test_triples, # 三元组数据args, # 超参数和配置的对象'head-batch', # 模式为破坏头节点random_sampling # 是否使用随机采样生成负样本),batch_size=args.test_batch_size, # 样本数量num_workers=max(1, args.cpu_num//2), # 最多一半的 CPU 核心数collate_fn=TestDataset.collate_fn # 多个样本组合成一个批次)test_dataloader_tail = DataLoader(TestDataset( # 测试数据集test_triples, # 三元组数据args, # 超参数和配置的对象'tail-batch', # 模式为破坏尾节点random_sampling # 是否使用随机采样生成负样本),batch_size=args.test_batch_size, # 样本数量num_workers=max(1, args.cpu_num//2), # 最多一半的 CPU 核心数collate_fn=TestDataset.collate_fn # 多个样本组合成一个批次)test_dataset_list = [test_dataloader_head, test_dataloader_tail] # 两个数据加载器组合成一个列表,方便后续统一处理test_logs = defaultdict(list) # 存储每个批次的评估结果step = 0total_steps = sum([len(dataset) for dataset in test_dataset_list]) # 计算总的迭代次数with torch.no_grad(): # 使用 torch.no_grad() 上下文管理器,禁用梯度计算,减少内存消耗并加速推理过程t1 = datetime.datetime.now().microsecondt3 = time.mktime(datetime.datetime.now().timetuple()) # 计算开始时间(高精度)for test_dataset in test_dataset_list:for positive_sample, negative_sample, mode in test_dataset:if args.cuda: # 如果启用了 GPU,将数据转移到 GPU 上进行计算positive_sample = positive_sample.cuda()negative_sample = negative_sample.cuda()batch_size = positive_sample.size(0)score = model((positive_sample, negative_sample), mode) # 计算每个样本的得分batch_results = model.evaluator.eval({'y_pred_pos': score[:, 0],'y_pred_neg': score[:, 1:]})for metric in batch_results:test_logs[metric].append(batch_results[metric])if step % args.test_log_steps == 0: # 每隔一定步数,打印当前进度logging.info('Evaluating the model... (%d/%d)' % (step, total_steps))step += 1t2 = datetime.datetime.now().microsecondt4 = time.mktime(datetime.datetime.now().timetuple()) # 计算结束时间(高精度)strTime = 'funtion time use:%dms' % ((t4 - t3) * 1000 + (t2 - t1) / 1000) # 计算运行时间print (strTime) # 输出运行时间metrics = {} # 创建一个空字典,用于存储最终的评估指标for metric in test_logs: # 遍历所有键(即评估指标名称),并计算每个指标的平均值metrics[metric] = torch.cat(test_logs[metric]).mean().item()return metrics
run.py
#!/usr/bin/python3from __future__ import absolute_import # Python 2 和 Python 3 的兼容性声明
from __future__ import division # Python 2 和 Python 3 的兼容性声明
from __future__ import print_function # Python 2 和 Python 3 的兼容性声明import argparse # 用于解析命令行参数
import json # 处理 JSON 格式的数据
import logging # 记录日志信息
import os # 操作系统交互
import random # 生成随机数import numpy as np # 多维数组操作
import torch # 深度学习框架from torch.utils.data import DataLoader # 导入加载数据的工具from model import KGEModel # 导入文件from dataloader import TrainDataset # 导入文件
from dataloader import BidirectionalOneShotIterator # 导入文件from ogb.linkproppred import LinkPropPredDataset, Evaluator # 加载链接预测任务数据集的类和评估链接预测任务性能的工具
from collections import defaultdict # 一种字典的扩展,允许为不存在的键提供默认值
from tqdm import tqdm # 显示进度条的工具
import time # 时间相关的功能
from tensorboardX import SummaryWriter # 记录训练过程日志的工具
import os.path as osp # 路径操作相关的功能# 定义一个全局函数来替代 lambda
def default_value():return 4
# 解析命令行参数,定义相关参数的默认值
def parse_args(args=None):parser = argparse.ArgumentParser(description='Training and Testing Knowledge Graph Embedding Models',usage='train.py [<args>] [-h | --help]')parser.add_argument('--cuda', action='store_true', help='use GPU') # 定义是否用GPUparser.add_argument('--do_train', action='store_true') # 是否执行训练任务parser.add_argument('--do_valid', action='store_true') # 是否执行验证任务parser.add_argument('--do_test', action='store_true') # 是否执行测试任务parser.add_argument('--evaluate_train', action='store_true', help='Evaluate on training data') # 在训练数据上进行评估parser.add_argument('--dataset', type=str, default='ogbl-wikikg2', help='dataset name, default to wikikg') # 用于指定使用的数据集名称parser.add_argument('--model', default='TransE', type=str) # 指定使用的模型类型parser.add_argument('-de', '--double_entity_embedding', action='store_true') # 是否使用双倍大小的实体嵌入向量parser.add_argument('-dr', '--double_relation_embedding', action='store_true') # 是否使用双倍大小的关系嵌入向量parser.add_argument('-tr', '--triple_relation_embedding', action='store_true') # 是否使用三倍大小的关系嵌入向量parser.add_argument('-qr', '--quad_relation_embedding', action='store_true') # 是否使用四倍大小的关系嵌入向量parser.add_argument('-n', '--negative_sample_size', default=128, type=int) # 指定负采样的样本数量parser.add_argument('-d', '--hidden_dim', default=500, type=int) # 指定嵌入向量的维度parser.add_argument('-g', '--gamma', default=12.0, type=float) # 定义模型的边缘超参数parser.add_argument('-adv', '--negative_adversarial_sampling', action='store_true') # 是否使用负采样对抗训练parser.add_argument('-a', '--adversarial_temperature', default=1.0, type=float) # 控制对抗负采样的温度parser.add_argument('-b', '--batch_size', default=1024, type=int) # 指定训练时的批量大小parser.add_argument('-r', '--regularization', default=0.0, type=float) # 指定正则化项的强度parser.add_argument('--test_batch_size', default=4, type=int, help='valid/test batch size') # 指定验证或测试时的批量大小parser.add_argument('--uni_weight', action='store_true',help='Otherwise use subsampling weighting like in word2vec') # 权重相等或者子采样权重parser.add_argument('-lr', '--learning_rate', default=0.0001, type=float) # 用于指定优化器的学习率parser.add_argument('-cpu', '--cpu_num', default=10, type=int) # 用于指定程序使用的 CPU 核心数量parser.add_argument('-init', '--init_checkpoint', default=None, type=str) # 用于指定模型初始化时的检查点文件路径parser.add_argument('-save', '--save_path', default=None, type=str) # 指定模型保存的路径parser.add_argument('--max_steps', default=100000, type=int) # 用于指定训练的最大步数parser.add_argument('--warm_up_steps', default=None, type=int) # 指定学习率预热(warm-up)的步数parser.add_argument('--save_checkpoint_steps', default=10000, type=int) # 指定每隔多少步保存一次模型检查点parser.add_argument('--valid_steps', default=10000, type=int) # 指定每隔多少步在验证集上评估一次模型性能parser.add_argument('--log_steps', default=100, type=int, help='train log every xx steps') # 指定每隔多少步记录一次训练日志parser.add_argument('--test_log_steps', default=1000, type=int, help='valid/test log every xx steps') # 指定每隔多少步记录一次验证或测试日志parser.add_argument('--nentity', type=int, default=0, help='DO NOT MANUALLY SET') # 表示知识图谱中的实体数量,不是由用户手动指定parser.add_argument('--nrelation', type=int, default=0, help='DO NOT MANUALLY SET') # 表示知识图谱中的关系数量,不是由用户手动指定parser.add_argument('--print_on_screen', action='store_true', help='log on screen or not') # 是否将日志信息直接打印到屏幕上parser.add_argument('--ntriples_eval_train', type=int, default=200000, help='number of training triples to evaluate eventually') # 指定在训练数据上进行评估时使用的三元组数量parser.add_argument('--neg_size_eval_train', type=int, default=500, help='number of negative samples when evaluating training triples') # 指定在评估训练数据时生成的负样本数量parser.add_argument('--relation_type', type=str, default='all', help='1-1, 1-n, n-1, n-n') # 指定要处理的关系类型return parser.parse_args(args) # 返回参数# 自动同步模型和数据的配置信息
def override_config(args):# 覆盖模型和数据配置with open(os.path.join(args.init_checkpoint, 'config.json'), 'r') as fjson: # 打开配置文件,只读模式argparse_dict = json.load(fjson) # 复制相关信息# 键值对逐一赋值给对象的对应属性args.dataset = argparse_dict['dataset'] # 数据集名称args.model = argparse_dict['model'] # 模型名称args.double_entity_embedding = argparse_dict['double_entity_embedding'] # 是否使用双倍实体嵌入args.double_relation_embedding = argparse_dict['double_relation_embedding'] # 是否使用双倍关系嵌入args.triple_relation_embedding = argparse_dict['triple_relation_embedding'] # 是否使用三重关系嵌入args.quad_relation_embedding = argparse_dict['quad_relation_embedding'] # 是否使用四重关系嵌入args.hidden_dim = argparse_dict['hidden_dim'] # 隐藏层维度args.test_batch_size = argparse_dict['test_batch_size'] # 测试批量大小# 用于保存模型的参数、优化器的状态以及其他相关变量
def save_model(model, optimizer, save_variable_list, args):# 保存模型和优化器的参数,# 以及一些其他变量,如step和learning_rateargparse_dict = vars(args) # 提取信息# os.path.join() 拼接路径with open(os.path.join(args.save_path, 'config.json'), 'w') as fjson:json.dump(argparse_dict, fjson) # json格式写入entity_embedding = model.entity_embedding.detach().cpu().numpy() # 提取实体嵌入np.save( # 造完整的文件路径,保存为 .npy 文件os.path.join(args.save_path, 'entity_embedding'),entity_embedding)relation_embedding = model.relation_embedding.detach().cpu().numpy() # 提取关系嵌入np.save( # 造完整的文件路径,保存为 .npy 文件os.path.join(args.save_path, 'relation_embedding'),relation_embedding)def set_logger(args):# 将日志写入检查点和控制台# 根据args.do_train的值决定日志文件的名称,是测试集还是训练集if args.do_train:log_file = os.path.join(args.save_path or args.init_checkpoint, 'train.log')else:log_file = os.path.join(args.save_path or args.init_checkpoint, 'test.log')print(log_file) # 将日志文件的路径打印到控制台,logging.basicConfig( # 配置日志记录器format='%(asctime)s %(levelname)-8s %(message)s', # 指定日志信息的格式level=logging.INFO, # 设置日志记录的最低级别datefmt='%Y-%m-%d %H:%M:%S', # 指定日期和时间的格式filename=log_file, # 指定日志文件的路径filemode='w' # 表示每次运行程序时会覆盖之前的日志文件)if args.print_on_screen: # 如果为True,将日志信息同时输出到控制台console = logging.StreamHandler() # 用于将日志信息输出到控制台console.setLevel(logging.INFO) # 设置控制台日志的最低级别为 INFOformatter = logging.Formatter('%(asctime)s %(levelname)-8s %(message)s') # 定义日志信息的输出格式console.setFormatter(formatter) # 应用到控制台日志处理器logging.getLogger('').addHandler(console) # 将 console 添加到根日志记录器中def log_metrics(mode, step, metrics, writer):# 打印评估日志for metric in metrics: # 遍历logging.info('%s %s at step %d: %f' % (mode, metric, step, metrics[metric])) # 输出格式writer.add_scalar("_".join([mode, metric]), metrics[metric], step) # 记录数据(如损失值、准确率等)def main(args):if (not args.do_train) and (not args.do_valid) and (not args.do_test) and (not args.evaluate_train): # 选择一种运行模式raise ValueError('one of train/val/test mode must be choosed.') # 否则报错if args.init_checkpoint: # 是否提供了参数(即初始化检查点路径)override_config(args) # 自动配置信息# 动态生成日志保存路径args.save_path = 'log/%s/%s/%s-%s/%s'%(args.dataset, args.model, args.hidden_dim, args.gamma, time.time()) if args.save_path == None else args.save_pathwriter = SummaryWriter(args.save_path) # 在指定路径下生成日志文件# 将日志写入检查点和控制台set_logger(args)dataset = LinkPropPredDataset(name = args.dataset) # 加载一个链接预测数据集split_dict = dataset.get_edge_split() # 获取数据集中边的划分信息(训练集、验证集、测试集)nentity = dataset.graph['num_nodes'] # 提取实体总数nrelation = int(max(dataset.graph['edge_reltype'])[0])+1 # 提取关系的总数,因为关系类型编号通常从 0 开始,因此 +1evaluator = Evaluator(name = args.dataset) # 初始化一个评估器对象args.nentity = nentity # 实体数量args.nrelation = nrelation # 关系数量logging.info('Model: %s' % args.model) # 记录模型名称logging.info('Dataset: %s' % args.dataset) # 记录数据集名称logging.info('#entity: %d' % nentity) # 记录实体数量logging.info('#relation: %d' % nrelation) # 记录关系数量train_triples = split_dict['train'] # 提取训练集logging.info('#train: %d' % len(train_triples['head'])) # 记录三元组个数valid_triples = split_dict['valid'] # 提取验证集logging.info('#valid: %d' % len(valid_triples['head'])) # 记录三元组个数test_triples = split_dict['test'] # 提取测试集logging.info('#test: %d' % len(test_triples['head'])) # 记录三元组个数logging.info('relation type %s' % args.relation_type) # 记录关系类型(1-N、N-N)test_set_file = '' # 初始化,用于后续存储测试集文件的路径if args.relation_type == '1-1': # 关系类型test_set_file = './dataset/ogbl_wikikg/wikikg_P/1-1-id.txt' # 测试集中一对一关系的原始三元组 IDtest_set_pre_processed = './dataset/ogbl_wikikg/wikikg_P/1-1.pt' # 预处理后的测试集文件elif args.relation_type == '1-n':test_set_file = './dataset/ogbl_wikikg/wikikg_P/1-n-id.txt'test_set_pre_processed = './dataset/ogbl_wikikg/wikikg_P/1-n.pt'elif args.relation_type == 'n-1':test_set_file = './dataset/ogbl_wikikg/wikikg_P/n-1-id.txt'test_set_pre_processed = './dataset/ogbl_wikikg/wikikg_P/n-1.pt'elif args.relation_type == 'n-n':test_set_file = './dataset/ogbl_wikikg/wikikg_P/n-n-id.txt'test_set_pre_processed = './dataset/ogbl_wikikg/wikikg_P/n-n.pt'if test_set_file != '': # 修改路径后if osp.exists(test_set_pre_processed): # 检查预处理文件是否存在test_triples = torch.load(test_set_pre_processed, 'rb') # 二进制加载文件,二进制高效、紧凑else:test_triples_new = {} # 初始化新的测试集test_triples_chosen = [] # 用于存储从文件中读取的三元组test_triples_new['head'] = [] # 存储头实体的列表test_triples_new['relation'] = [] # 存储关系的列表test_triples_new['tail'] = [] # 存储尾实体的列表test_triples_new['head_neg'] = [] # 存储头实体的负样本的列表test_triples_new['tail_neg'] = [] # 存储尾实体的负样本的列表f_test = open(test_set_file, "r") # 打开原始测试集文件for line in f_test: # 逐行遍历h, r, t = line.strip().split('\t') # 分离头实体-关系-尾实体h, r, t = int(h), int(r), int(t) # 用数值记录test_triples_chosen.append((h, r, t)) #记录到刚刚建立的文件中f_test.close() # 关闭文件for idx in range(len(test_triples['head'])): # 使用idx遍历三元组h, r, t = test_triples['head'][idx], test_triples['relation'][idx], test_triples['tail'][idx] # 提取h、r、tif (h, r, t) in test_triples_chosen: # 检查三元组是否是测试集的一部分test_triples_new['head'].append(h) # 添加到 test_triples_new 的相应列表test_triples_new['relation'].append(r) # 添加到 test_triples_new 的相应列表test_triples_new['tail'].append(t) # 添加到 test_triples_new 的相应列表test_triples_new['head_neg'].append(test_triples['head_neg'][idx]) # 将对应的负样本添加到文件test_triples_new['tail_neg'].append(test_triples['tail_neg'][idx]) # 将对应的负样本添加到文件print('Saving ...') # 正在保存torch.save(test_triples_new, test_set_pre_processed, pickle_protocol=4) # 将文件保存到路径中test_triples = test_triples_new # 赋值logging.info('#test: %d' % len(test_triples['head'])) # 记录测试集中三元组的数量# train_count: 记录(head, relation)和(tail, -relation - 1)的出现次数,默认值为4。搞不懂为什么是 4# train_true_head: 记录每个(relation, tail)对应的所有可能头实体。# train_true_tail: 记录每个(head, relation)对应的所有可能尾实体。# train_count, train_true_head, train_true_tail = defaultdict(lambda: 4), defaultdict(list), defaultdict(list) # 原来的代码,进行更改train_count, train_true_head, train_true_tail = defaultdict(default_value), defaultdict(list), defaultdict(list)f_train = open("train.txt", "w") # 创建文件,用于存储训练集中的三元组for i in tqdm(range(len(train_triples['head']))): # 遍历训练集中的所有三元组head, relation, tail = train_triples['head'][i], train_triples['relation'][i], train_triples['tail'][i] # 提取当前三元组的头实体、关系和尾实体train_count[(head, relation)] += 1 # 更新出现次数train_count[(tail, -relation-1)] += 1 # 更新出现次数,反向关系用于对称性建模train_true_head[(relation, tail)].append(head) # 添加头实体train_true_tail[(head, relation)].append(tail) # 添加尾实体f_train.write("\t".join([str(head), str(relation), str(tail)]) + '\n') # 转换为字符串形式,并写入文件f_train.close() # 关闭文件kge_model = KGEModel( # 创建实例model_name=args.model, # 指定嵌入模型的名称nentity=nentity, # 实体数量nrelation=nrelation, # 关系数量hidden_dim=args.hidden_dim, # 嵌入向量的隐藏维度gamma=args.gamma, # 定义评分函数中的边界值double_entity_embedding=args.double_entity_embedding, # 是否使用双倍实体嵌入double_relation_embedding=args.double_relation_embedding, # 是否使用双倍关系嵌入triple_relation_embedding=args.triple_relation_embedding, # 是否使用三重关系嵌入quad_relation_embedding=args.quad_relation_embedding, # 是否使用四重关系嵌入evaluator=evaluator # 指定评估器)logging.info('Model Parameter Configuration:') # 记录参数的配置信息for name, param in kge_model.named_parameters(): # 遍历模型的所有参数logging.info('Parameter %s: %s, require_grad = %s' % (name, str(param.size()), str(param.requires_grad))) # 记录参数名称、嵌入维度、是否需要反向更新if args.cuda: # 是否有GPUkge_model = kge_model.cuda() # GPU上运行,加速# 是否需要执行训练过程if args.do_train:# 设置训练数据加载器迭代器train_dataloader_head = DataLoader( # 创建对象TrainDataset(train_triples, nentity, nrelation, # 创建训练集args.negative_sample_size, 'head-batch', # 破坏头节点train_count, train_true_head, train_true_tail),batch_size=args.batch_size, # 样本数量shuffle=True, # 随机打乱数据num_workers=max(1, args.cpu_num//2), # 数据加载的子进程数量,两个“/”是向下取整collate_fn=TrainDataset.collate_fn # 多个样本组合成一个批次)train_dataloader_tail = DataLoader(TrainDataset(train_triples, nentity, nrelation,args.negative_sample_size, 'tail-batch', # 破坏尾节点train_count, train_true_head, train_true_tail),batch_size=args.batch_size, # 样本数量shuffle=True, # 随机打乱数据num_workers=max(1, args.cpu_num//2), # 数据加载的子进程数量,两个“/”是向下取整collate_fn=TrainDataset.collate_fn # 多个样本组合成一个批次)# 同时处理破坏头节点批次和破坏尾节点批次的训练数据train_iterator = BidirectionalOneShotIterator(train_dataloader_head, train_dataloader_tail)# 设置训练配置current_learning_rate = args.learning_rate # 学习率# optimizer = torch.optim.Adam( # 使用优化器,代码更改# filter(lambda p: p.requires_grad, kge_model.parameters()), # kge_model.parameters()返回所有参数,filter()筛选可迭代对象中的元素,lambda匿名函数# lr=current_learning_rate # 优化器的学习率# )optimizer = torch.optim.Adam([p for p in kge_model.parameters() if p.requires_grad], # 列表推导式筛选参数lr=current_learning_rate # 学习率)if args.warm_up_steps: # 定义预热阶段的长度warm_up_steps = args.warm_up_steps # 被赋值后else:warm_up_steps = args.max_steps // 2 # 刚开始# 用于恢复之前的训练状态或加载预训练模型if args.init_checkpoint:# 从检查点目录还原模型logging.info('Loading checkpoint %s...' % args.init_checkpoint) # 提示正在加载指定路径的检查点checkpoint = torch.load(os.path.join(args.init_checkpoint, 'checkpoint')) # 加载保存的检查点文件init_step = checkpoint['step'] # 提取当前训练的步数kge_model.load_state_dict(checkpoint['model_state_dict']) # 将检查点中保存的模型参数加载到当前模型if args.do_train: # 是否需要继续训练current_learning_rate = checkpoint['current_learning_rate'] # 提取当前的学习率warm_up_steps = checkpoint['warm_up_steps'] # 提取预热步数optimizer.load_state_dict(checkpoint['optimizer_state_dict']) # 将检查点中保存的优化器状态加载到当前优化器中else:logging.info('Ramdomly Initializing %s Model...' % args.model) # 随机初始化模型参数init_step = 0 # 训练的起始步数为0step = init_step # 赋值步数logging.info('Start Training...') # 提示训练即将开始logging.info('init_step = %d' % init_step) # 表示将 init_step 作为整数插入到日志信息中logging.info('negative_sample_size = %d' % args.negative_sample_size) # 输出负采样样本的数量logging.info('batch_size = %d' % args.batch_size) # 输出批量大小logging.info('hidden_dim = %d' % args.hidden_dim) # 输出隐藏层维度logging.info('gamma = %f' % args.gamma) # 输出超参数logging.info('negative_adversarial_sampling = %s' % str(args.negative_adversarial_sampling)) # 是否启用负对抗采样logging.info('learning_rate = %f' % args.learning_rate) # 输出学习率if args.negative_adversarial_sampling: # 如果启用了负对抗采样,输出对抗温度logging.info('adversarial_temperature = %f' % args.adversarial_temperature)# 设置有效的数据加载器,因为它将在培训期间进行评估if args.do_train: # 是否需要进行训练logging.info('learning_rate = %d' % current_learning_rate) # 输出当前学习率training_logs = [] # 存储训练过程中的日志信息,例如每一步的损失值、评估指标等# 训练循环for step in range(init_step, args.max_steps): # 从检查点\初始点开始训练log = kge_model.train_step(kge_model, optimizer, train_iterator, args) # 执行一次训练步骤training_logs.append(log) # 将当前训练步骤的日志信息添加到列表中# 动态调整学习率if step >= warm_up_steps: # 超过了预热步数current_learning_rate = current_learning_rate / 10 # 降低为原来的十分之一,减小学习率,从而提高模型的收敛精度logging.info('Change learning_rate to %f at step %d' % (current_learning_rate, step)) # 提示学习率已调整# optimizer = torch.optim.Adam( # 使用新的学习率重新初始化优化器,代码更改# filter(lambda p: p.requires_grad, kge_model.parameters()), # 过滤出模型中需要更新的参数# lr=current_learning_rate # 调整参数# )optimizer = torch.optim.Adam([p for p in kge_model.parameters() if p.requires_grad], # 列表推导式筛选参数lr=current_learning_rate # 学习率)warm_up_steps = warm_up_steps * 3 # 延长下一次学习率调整的触发点,避免频繁调整学习率# 定期保存模型检查点if step % args.save_checkpoint_steps == 0 and step > 0: # ~ 41 seconds/saving,约41秒/节省?满足保存检查点的条件save_variable_list = { # 用于保存与检查点相关的变量'step': step, # 训练步数'current_learning_rate': current_learning_rate, # 学习率'warm_up_steps': warm_up_steps # 预热步数}save_model(kge_model, optimizer, save_variable_list, args) # 保存模型和训练状态if step % args.log_steps == 0: # 每隔多少步记录一次指标metrics = {} # 存储计算后的平均指标for metric in training_logs[0].keys(): # 遍历所有键metrics[metric] = sum([log[metric] for log in training_logs])/len(training_logs) # 计算每个指标的平均值,并存储log_metrics('Train', step, metrics, writer) # 将计算出的指标记录到日志或可视化工具中training_logs = [] # 清空列表# 定期在验证集上评估模型性能if args.do_valid and step % args.valid_steps == 0 and step > 0: # 是否需要执行验证操作logging.info('Evaluating on Valid Dataset...') # 提示用户正在对验证集进行评估metrics = kge_model.test_step(kge_model, valid_triples, args) # 对验证集进行评估log_metrics('Valid', step, metrics, writer) # 将验证集的评估结果记录到日志或可视化工具中# 保存模型和训练状态到检查点文件中save_variable_list = {'step': step, # 训练步数'current_learning_rate': current_learning_rate, # 学习率'warm_up_steps': warm_up_steps # 预热步数}save_model(kge_model, optimizer, save_variable_list, args) # 将模型参数保存到检查点文件中# 在验证集上评估模型性能if args.do_valid: # 是否需要执行验证操作logging.info('Evaluating on Valid Dataset...') # 提示用户正在对验证集进行评估metrics = kge_model.test_step(kge_model, valid_triples, args) # 调用模型的 test_step 方法对验证集进行评估log_metrics('Valid', step, metrics, writer) # 评估结果记录到日志或可视化工具中# 在测试集上评估模型性能if args.do_test: # 是否需要执行测试操作logging.info('Evaluating on Test Dataset...') # 提示用户正在对测试集进行评估metrics = kge_model.test_step(kge_model, test_triples, args) # 模型的 test_step 方法对测试集进行评估log_metrics('Test', step, metrics, writer) # 评估结果记录到日志或可视化工具中print(metrics) # 评估结果直接打印到控制台if args.evaluate_train: # 在训练集的一个随机子集上评估模型性能,是否需要执行训练集评估操作logging.info('Evaluating on Training Dataset...') # 提示用户正在对训练集进行评估small_train_triples = {} # 存储从训练集中随机采样的小批量数据indices = np.random.choice(len(train_triples['head']), args.ntriples_eval_train, replace=False) # 从训练集中随机选择一部分数据索引for i in train_triples: # 根据随机选择的索引遍历small_train_triples[i] = train_triples[i][indices]metrics = kge_model.test_step(kge_model, small_train_triples, args, random_sampling=True) # 调用模型的 test_step 方法对随机采样的训练集子集进行评估log_metrics('Train', step, metrics, writer) # 将训练集评估结果记录到日志或可视化工具中if __name__ == '__main__':main(parse_args())相关文章:

ComplexE的代码注释
目录 dataloader.pymodel.pyrun.py 先安装软件,配置环境,搞了一周。再看代码写注释搞了一周。中间隔了一周。再安装环境跑代码又一周。最后结果是没结果。自己电脑内存带不动。还不想配电脑,又不会用GPU服务器。哭死哭死。心态崩了。直接发吧…...

vector<int> 的用法
vector<int> 是 C 标准模板库(STL)中的一个容器,用于存储动态大小的整数序列。以下是它的主要用法: 基本操作 1. 创建和初始化 #include <vector> using namespace std;vector<int> v1; // 空vector vector<int>…...

Java高级JVM知识点记录,内存结构,垃圾回收,类文件结构,类加载器
JVM是Java高级部分,深入理解程序的运行及原理,面试中也问的比较多。 JVM是Java程序运行的虚拟机环境,实现了“一次编写,到处运行”。它负责将字节码解释或编译为机器码,管理内存和资源,并提供运行时环境&a…...

名言警句1
1、嫉妒是欲望的衍生,而欲望则是成长的驱动,说到底每个人都是为了成长,为了不居人后,在成长的过程中,我们可以让欲望枝繁叶茂,但不能让嫉妒开花结果 2、人生无法奢求更多,我们有健康的身体&…...

【STL】queue
q u e u e queue queue 是一种容器适配器,设计为先进先出( F i r s t I n F i r s t O u t , F I F O First\ In\ First\ Out,\ FIFO First In First Out, FIFO)的数据结构,有两个出口,将元素推入队列的操作称为 p u …...

QXmpp入门
QXmpp 是一个基于 Qt 的 XMPP (Jabber) 协议实现库,用于开发即时通讯(IM)、聊天应用和实时协作系统。它支持客户端和服务端开发,提供完整的 XMPP 核心功能扩展。 1. 核心功能 XMPP 核心协议支持 支持 RFC 6120 (XMPP Core) 和 RFC 6121 (XMPP IM) 基础功能:认证、在线状态…...

使用cursor为代码添加注释
1. add-comments.md英文 You are tasked with adding comments to a piece of code to make it more understandable for AI systems or human developers. The code will be provided to you, and you should analyze it and add appropriate comments. To add comments to …...

20250330-傅里叶级数专题之离散时间傅里叶变换(4/6)
4. 傅里叶级数专题之离散时间傅里叶变换 20250328-傅里叶级数专题之数学基础(0/6)-CSDN博客20250330-傅里叶级数专题之傅里叶级数(1/6)-CSDN博客20250330-傅里叶级数专题之傅里叶变换(2/6)-CSDN博客20250330-傅里叶级数专题之离散傅里叶级数(3/6)-CSDN博客20250330-傅里叶级数专…...
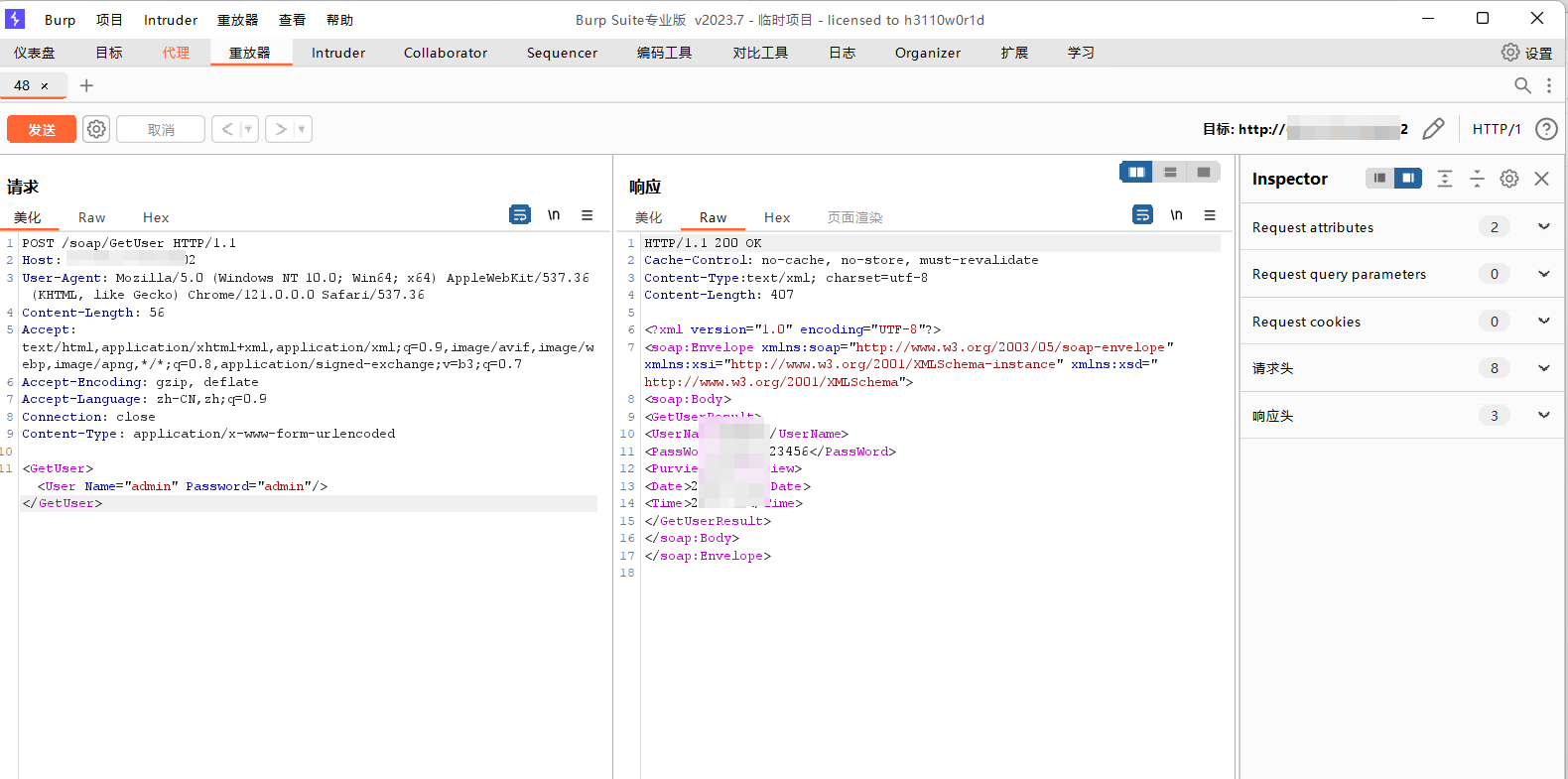
漏洞挖掘---迅饶科技X2Modbus网关-GetUser信息泄露漏洞
一、迅饶科技 X2Modbus 网关 迅饶科技 X2Modbus 网关是功能强大的协议转换利器。“X” 代表多种不同通信协议,能将近 200 种协议同时转为 Modbus RTU 和 TCP 服务器 。支持 PC、手机端等访问监控,可解决组态软件连接不常见控制设备难题,广泛…...

Java进阶——位运算
位运算直接操作二进制位,在处理底层数据、加密算法、图像处理等领域具有高效性能和效率。本文将深入探讨Java中的位运算。 本文目录 一、位运算简介1. 与运算2. 或运算异或运算取反运算左移运算右移运算无符号右移运算 二、位运算的实际应用1. 权限管理2. 交换两个变…...

golang strings包常用方法
方法名称功能描述示例strings.Join将字符串切片中的元素连接成一个字符串,使用指定的分隔符。strings.Join([]string{"hello", "world"}, " ")strings.HasPrefix检查字符串是否以指定的前缀开头。strings.HasPrefix("hello"…...

网络安全之前端学习(css篇2)
那么今天我们继续来学习css,预计这一章跟完后,下一章就是终章。然后就会开始js的学习。那么话不多说,我们开始吧。 字体属性 之前讲到了css可以改变字体属性,那么这里来详细讲一讲。 1.1字体颜色 之前讲到了对于字体改变颜色食…...

PS底纹教程
1.ctrlshiftU 去色 2.新建纯色层 颜色中性灰;转换为智能对象 3.纯色层打开滤镜(滤镜库); 素描下找到半调图案,数值调成大小5对比1; 再新建一层,素描下找到撕边,对比拉到1&#x…...

NX/UG二次开发—CAM获取加工操作的最低Z深度值的方法
网上已经有些大佬给出了解决方案,但是基本有两种,一种内部函数,另外一种就是导出程序的刀轨文件找坐标计算。使用内部函数进行操作,可以自己学习,不做解释。下面只是针对第二种进行说明,参考胡君老师的教程…...

解决pyinstaller GUI打包时无法打包图片问题
当我们的python GuI在开发时。经常会用到图片作为背景,但是在打包后再启动GUI后却发现:原先调试时好端端的背景图片竟然不翼而飞或者直接报错。这说明图片没有被pyinstaller一起打包…… 要解决这个问题很简单,就是更改图片的存储方式。 tk…...

蓝桥杯真题------R格式(高精度乘法,高精度加法)
对于高精度乘法和加法的同学可以学学这几个题 高精度乘法 高精度加法 文章目录 题意分析部分解全解 后言 题意 给出一个整数和一个浮点数,求2的整数次幂和这个浮点数相乘的结果最后四舍五入。、 分析 我们可以发现,n的范围是1000,2的1000次方非常大&am…...

Nginx — Nginx安装证书模块(配置HTTPS和TCPS)
一、安装和编译证书模块 [rootmaster nginx]# wget https://nginx.org/download/nginx-1.25.3.tar.gz [rootmaster nginx]# tar -zxvf nginx-1.25.3.tar.gz [rootmaster nginx]# cd nginx-1.25.3 [rootmaster nginx]# ./configure --prefix/usr/local/nginx --with-http_stub_…...

回调后门基础
回调后门概述 回调后门(Reverse Shell)是一种常见的攻击方式,攻击者通过受害主机主动连接到远程服务器(攻击者控制的机器),从而获得远程控制权限。 工作原理 受害者主机 运行一个恶意代码,尝…...

深度学习 Deep Learning 第13章 线性因子模型
深度学习 Deep Learning 第13章 线性因子模型 内容概要 本章深入探讨了线性因子模型,这是一类基于潜在变量的概率模型,用于描述数据的生成过程。这些模型通过简单的线性解码器和噪声项捕捉数据的复杂结构,广泛应用于信号分离、特征提取和数…...

【个人笔记】用户注册登录思路及实现 springboot+mybatis+redis
基本思路 获取验证码接口 验证码操作用了com.pig4cloud.plugin的captcha-core这个库。 AccountControl的"/checkCode"接口代码,通过ArithmeticCaptcha生成一张验证码图片,通过text()函数得到验证码的答案保存到变量code,然后把图…...
)
华为OD机试2025A卷 - 正则表达式替换(Java Python JS C++ C )
最新华为OD机试 真题目录:点击查看目录 华为OD面试真题精选:点击立即查看 题目描述 为了便于业务互交,约定一个对输入的字符串中的下划线做统一替换。 具体要求如下: 输入字符串,将其中包含的每一个下划线“_”,使用特殊字符串(^|$|[,+])替换,并输出替换后的结果…...

WPS宏开发手册——Excel常用Api
目录 系列文章4、Excel常用Api4.1、判断是否是目标工作excel4.2、获取源工作表和目标工作表的引用4.3、获取单元格的值4.4、设置单元格的值4.5、合并单元格4.6、获取源范围4.7、获取源范围行数4.8、通过源来获取单元格的值4.9、设置单元格的背景颜色4.10、设置单元格的文字颜色…...

数据库基础入门
关系型数据库 vs. 非关系型数据库SQL 基础 & ORM 框架使用一、数据库概述 数据库(Database)是 存储和管理数据 的系统,主要分为 关系型数据库(Relational Database) 和 非关系型数据库(NoSQL)。 📌 数据库的作用: ✅ 存储:持久化数据,避免数据丢失。 ✅ 管理…...

聚类(Clustering)基础知识3
文章目录 一、聚类的性能评价1、聚类性能评价(1)聚类性能评价方法: 2、参考模型 (reference model)(1)数据集:(2)聚类结果:(3)参考模型࿱…...

RK3588使用笔记:设置程序/服务开机自启
一、前言 一般将系统用作嵌入式设备时肯定要布置某些程序,这时候就需要对程序设置开机自己,否则每次都要人为启动,当有些嵌入式系统未连接显示屏或者无桌面环境去操作启动程序时,程序自启就是必须的了,本文介绍在纯li…...

Python-数据处理
第十五章 生成数据 安装Matplotlib:通过pip install matplotlib命令安装库。绘制折线图的核心语法为: import matplotlib.pyplot as plt x_values [1, 2, 3] y_values [1, 4, 9] plt.plot(x_values, y_values, linewidth2) plt.title(&quo…...

LoRA技术全解析:如何用4%参数量实现大模型高效微调
引言 在当今的人工智能领域,大型语言模型(LLM)已经成为革命性的技术。然而,这些模型通常拥有数十亿个参数,全量微调成本极高。本文将为初级开发者详细讲解LoRA(Low-Rank Adaptation)技术&#…...

职测-言语理解与表达
成语填空 成语的误用 误用①:望文生义【按成语的字面意思去理解,导致误用】 成语解释如数家珍对列举的事物或叙述的故事十分熟悉,但熟悉的对象不能是自己收藏的宝贝目无全牛比喻技术熟练到得心应手的境地登堂入室比喻学问或技艺由浅入深&a…...
)
深度学习处理文本(2)
建立词表索引 将文本拆分成词元之后,你需要将每个词元编码为数值表示。你可以用无状态的方式来执行此操作,比如将每个词元哈希编码为一个固定的二进制向量,但在实践中,你需要建立训练数据中所有单词(“词表”&…...

python实现股票数据可视化
最近在做一个涉及到股票数据清洗及预测的项目,项目中需要用到可视化股票数据这一功能,这里我与大家分享一下股票数据可视化的一些基本方法。 股票数据获取 目前,我已知的使用python来获取股票数据方式有以下三种: 爬虫获取,实现…...