孤码长征:破译PCL自定义点云注册机制源码迷局——踩坑实录与架构解构
在之前一个博客《一文搞懂PCL中自定义点云类型的构建与函数使用》中,清晰地介绍了在PCL中点云的定义与注册方法。我的一个读者很好奇其内部注册的原理以及机制,再加上最近工作中跟猛男开发自定义点云存储的工作,借着这些需求,我也详细得对PCL相关的源码进行了整理与理解。
在正式开始之前,我们对点云注册的需求进行归类整理,进而引出点云注册都是实现哪些功能。点云注册的目的就是让我们在进行数据处理时,对一些常用的功能进行自动重载,减少代码冗余。值得注意的是,PCL中几乎所有的函数和class都是template类型的,目的就是支持各种点云的复用。

首先,我们将点云处理功能分为两类:
- 字段有感功能。字段有感,表示一个功能只会利用固定某些字段,比如我们对点云聚类时只关注字段xyz。如果自定义的点云类型没有所需字段,那么编译就会不通过。此外,在进行函数处理时,不可避免对点云进行进行基本运算操作,即对字段的加减乘除是无感的,引出点云注册必须要实现的功能:点云的加减乘除运算的重载。
- 字段无感功能。字段无感功能一般存在于数据IO(比如pcd点云的读写),点云拷贝(点云类型A拷贝到点云类型B上)。这些功能不会特意对指定字段进行特别的处理,每个字段处理的方式都是类似的。因此,基于这些,字段无感功能需要实现以下几点功能:
- 字段名称。数据类型是字符串,判断两个点云是否有相同字段名可用。
- 字段偏移量。用于拷贝数据使用,offset表示字段在这个数据类型的起点,结合字段字节大小,调用memcpy可以完成字段的拷贝。
- 字段数据类型。同上,数据拷贝需要。
- 字段列表。记录这个点云的字段列表,然后遍历每个字段完成操作
接下来,就按照理解顺序,逐步的对注册过程进行理解。
一 相关Boost宏定义介绍
下面这些宏是在点云注册中用到的宏,这里先对其进行介绍,在阅读时可以先跳过,后面遇到相关宏再来翻看这个即可。
- BOOST_PP_CAT。该宏在展开参数后将其连接起来,定义在
<boost/preprocessor/cat.hpp>。用法为BOOST_PP_CAT(a, b),其中a和b为待拼接的操作数。一个例子:
BOOST_PP_CAT(x, BOOST_PP_CAT(y, z)) // 展开为:xyz
- BOOST_PP_SEQ_FOR_EACH 。该宏会对一个序列的每个元素调用一个宏,定义在
<boost/preprocessor/seq/for_each.hpp>。用法为BOOST_PP_SEQ_FOR_EACH(macro, data, seq),其中macro一个宏,其参数必须为(r, data, elem)。elem就是seq序列的一个元素。data辅助参数,会传递到macro中。seq需要展开的序列。如果seq是(a)(b)(c),则会展开为以下序列macro(r, data, a) macro(r, data, b) macro(r, data, c),其中r只是个循环计数,操作中基本不会使用这个,关于r的内容可以参考这个博客《使用BOOST_PP_SEQ_FOR_EACH宏处理序列》。
#define SEQ (w)(x)(y)(z)
#define MACRO(r, data, elem) BOOST_PP_CAT(elem, data)
BOOST_PP_SEQ_FOR_EACH(MACRO, _, SEQ) // 展开为w_ x_ y_ z_
- BOOST_PP_TUPLE_ELEM 。该宏目的是提取一个tuple操作数的某个数,定义在
<boost/preprocessor/tuple/elem.hpp>。用法有两种BOOST_PP_TUPLE_ELEM(i, tuple),BOOST_PP_TUPLE_ELEM(size, i, tuple)。size表示这个tuple的个数。i提取tuple中的某个元素,有效使用范围是0~size-1。tuple待提取的操作数。
#define TUPLE (a, b, c, d)
BOOST_PP_TUPLE_ELEM(0, TUPLE) // 展开后结果为: a
BOOST_PP_TUPLE_ELEM(3, TUPLE) // 展开后结果为:d
- BOOST_PP_SEQ_TRANSFORM。该宏目的是对预处理序列(Preprocessor Sequence)中的每个元素进行转换,定义在
<boost/preprocessor/seq/transform.hpp>。用法BOOST_PP_SEQ_TRANSFORM(TRANSFORM_MACRO, DATA, SEQ),参数说明:TRANSFORM_MACRO: 自定义的转换宏,需接受(r, data, elem)参数。DATA: 传递给TRANSFORM_MACRO的额外数据(可为空)。SEQ: 输入的预处理序列,格式如 (a)(b)©。
#define SEQ (1)(3)(2)(5)
#define OP(s, data, elem) BOOST_PP_DEC(elem)
BOOST_PP_SEQ_TRANSFORM(OP, 3, SEQ) // expands to (0)(2)(1)(4)
- BOOST_PP_SEQ_ENUM。该宏目的是对序列(Preprocessor Sequence)中的每个元素用
,进行连接,定义在<boost/preprocessor/seq/enum.hpp>。用法BOOST_PP_SEQ_ENUM(SEQ)。
#include <boost/preprocessor/seq/enum.hpp>
#define SEQ (B)(O)(O)(S)(T)
BOOST_PP_SEQ_ENUM(SEQ) // expands to B, O, O, S, T
二 剖析点云注册机制
为了方便各位理解宏相关的操作,我们定义个简单的点云类型_PointXYZIT,其中包含xyz,intensity和一个自定义字段time。
struct EIGEN_ALIGN16 _PointXYZIT
{PCL_ADD_POINT4D; // XYZ [16 bytes]PCL_ADD_INTENSITY;double time;
};
其对应的点云注册操作如下:
POINT_CLOUD_REGISTER_POINT_STRUCT (_PointXYZIT,(float, x, x)(float, y, y)(float, z, z)(float, intensity, intensity)(double, time, time)
)
对应POINT_CLOUD_REGISTER_POINT_STRUCT的定义如下,这里name就是_PointXYZIT,fseq就是(float, x, x)(float, y, y)(float, z, z)(float, intensity, intensity)(double, time, time)。
#define POINT_CLOUD_REGISTER_POINT_STRUCT(name, fseq) \POINT_CLOUD_REGISTER_POINT_STRUCT_I(name, \BOOST_PP_CAT(POINT_CLOUD_REGISTER_POINT_STRUCT_X fseq, 0))
其中:
POINT_CLOUD_REGISTER_POINT_STRUCT_I:注册每个字段的名称(string),数据类型,偏移量,以及重载该点云的基本加减乘除运算。BOOST_PP_CAT(POINT_CLOUD_REGISTER_POINT_STRUCT_X fseq, 0)):对fseq进行后处理,比如将(float, x, x)变成((float, x, x))
注:宏定义操作目的是构造一个代码块,与我们正常开发函数的方式有点类似,但切记宏定义是代码块,实际编译时候会展开,所以宏这个输入没有什么数据类型的概念。
基于上述内容,引出下面几个更细节的问题:
- 注册序列预处理。()()序列是如何转为(())(())
- 点云注册宏
POINT_CLOUD_REGISTER_POINT_STRUCT做了啥。 - 自定义点云的保存与加载是如何实现的。
- 点云处理算法是如何适配自定义点云的。
2.1 注册序列预处理
注册序列预处理,是展开BOOST_PP_CAT(POINT_CLOUD_REGISTER_POINT_STRUCT_X fseq, 0),前面已说这里的目的是将(float, x, x)变成((float, x, x))。关联的宏定义如下:
#define POINT_CLOUD_REGISTER_POINT_STRUCT_X(type, name, tag) \((type, name, tag)) POINT_CLOUD_REGISTER_POINT_STRUCT_Y
#define POINT_CLOUD_REGISTER_POINT_STRUCT_Y(type, name, tag) \((type, name, tag)) POINT_CLOUD_REGISTER_POINT_STRUCT_X
#define POINT_CLOUD_REGISTER_POINT_STRUCT_X0
#define POINT_CLOUD_REGISTER_POINT_STRUCT_Y0
这里用了一个非常巧的技巧,递归展开。BOOST_PP_CAT最后面跟了一个参数0,那么最后展开的结果是一定调用了POINT_CLOUD_REGISTER_POINT_STRUCT_X0或者POINT_CLOUD_REGISTER_POINT_STRUCT_Y0中的一个,进而避免了无限循环展开。详细展开流程如下,已展开代码用绿色表示,处理的代码用红色表示。
① 展开POINT_CLOUD_REGISTER_POINT_STRUCT_X fseq:
- POINT_CLOUD_REGISTER_POINT_STRUCT_X(float, x, x)(float, y, y)(float, z, z)(float, intensity, intensity)(double, time, time)
- ((float, x, x))POINT_CLOUD_REGISTER_POINT_STRUCT_Y(float, y, y)(float, z, z)(float, intensity, intensity)(double, time, time)
- ((float, x, x))((float, y, y))POINT_CLOUD_REGISTER_POINT_STRUCT_X(float, z, z)(float, intensity, intensity)(double, time, time)
- 以此类推得到
((float, x, x))((float, y, y))((float, z, z))((float, intensity, intensity))((double, time, time))POINT_CLOUD_REGISTER_POINT_STRUCT_Y
② 拼接BOOST_PP_CAT。BOOST_PP_CAT已在第一章节介绍,这里BOOST_PP_CAT第二个参数是0,会基于上一个展开的结果,会将0拼接在POINT_CLOUD_REGISTER_POINT_STRUCT_Y后面得到POINT_CLOUD_REGISTER_POINT_STRUCT_Y0,而这个的宏定义就是空的,避免了无限递归。
③ 最终展开结果:((float, x, x))((float, y, y))((float, z, z))((float, intensity, intensity))((double, time, time))
2.2 为自定义字段构造推断器和常用运算符
注册器的核心就是POINT_CLOUD_REGISTER_POINT_STRUCT_I,其中name就是_PointXYZIT,fseq就是((float, x, x))...((double, time, time)),代码实现具体细节如下:
#define POINT_CLOUD_REGISTER_POINT_STRUCT_I(name, seq) \namespace pcl \{ \namespace fields \{ \BOOST_PP_SEQ_FOR_EACH(POINT_CLOUD_REGISTER_FIELD_TAG, name, seq) \} \namespace traits \{ \BOOST_PP_SEQ_FOR_EACH(POINT_CLOUD_REGISTER_FIELD_NAME, name, seq) \BOOST_PP_SEQ_FOR_EACH(POINT_CLOUD_REGISTER_FIELD_OFFSET, name, seq) \BOOST_PP_SEQ_FOR_EACH(POINT_CLOUD_REGISTER_FIELD_DATATYPE, name, seq) \POINT_CLOUD_REGISTER_POINT_FIELD_LIST(name, POINT_CLOUD_EXTRACT_TAGS(seq)) \} \namespace common \{/*common部分就是点云的加减乘除相关运算的重载,单独放在子节里面*/} \}
为了更容易理解,我将按照common,fields,traits的顺序进行源码解读。
2.2.1 [common] 注册基本运算符
基本运算包含:
- 加法部分:两点相加
pt1+pt2,自加运算pt1+=pt2,以及点和一个常数(float)的加法pt1+k, pt1+=k。 - 减法部分:两点相减
pt1-pt2,自减运算pt1-=pt2,以及点和一个常数(float)的减法pt1-k, pt1-=k。 - 乘除法:点云乘除法只有一个数乘/除,即
pt1 *= k, pt2 = pt1 * k, pt2 = k * pt1,pt1 /= k, pt2 = pt1 / k, pt2 = k / pt1。
关键注意:目前点云的加减乘除是正常理解的运算方法,如果有label这种标签属性,还是要慎用这些基本运算。而且对于数乘/除来说,对应的常数只是浮点数,所以整数如果处理之后,会存在精度损失的风险。
(1) 重载点云加法运算
相关代码如下,一个加法运算需要构造5种重载形式,但核心只需要解决点云和点云的加法,点云和一个数的加法。
inline const name& \ // pt1 += pt2
operator+= (name& lhs, const name& rhs) \
{ \BOOST_PP_SEQ_FOR_EACH(PCL_PLUSEQ_POINT_TAG, _, seq) \return (lhs); \
} \
inline const name& \ // pt1 += k
operator+= (name& p, const float& scalar) \
{ \BOOST_PP_SEQ_FOR_EACH(PCL_PLUSEQSC_POINT_TAG, _, seq) \return (p); \
} \
inline const name operator+ (const name& lhs, const name& rhs) \ // pt3 = pt1 + pt2
{ name result = lhs; result += rhs; return (result); } \
inline const name operator+ (const float& scalar, const name& p) \ // pt2 = k + pt1
{ name result = p; result += scalar; return (result); } \
inline const name operator+ (const name& p, const float& scalar) \ // pt2 = pt1 + k
{ name result = p; result += scalar; return (result); } \
以第一个重载函数inline const name& operator+= (name& lhs, const name& rhs)来理解,这里的name就是_PointXYZIT。BOOST_PP_SEQ_FOR_EACH(PCL_PLUSEQ_POINT_TAG, _, seq)会对seq,也就是((float, x, x))...((double, time, time))中的每个元素,来调用宏PCL_PLUSEQ_POINT_TAG。
#define PCL_PLUSEQ_POINT_TAG(r, data, elem) \pcl::traits::plus (lhs.BOOST_PP_TUPLE_ELEM(3, 1, elem), \ // 提取elem的第2个元素,即xrhs.BOOST_PP_TUPLE_ELEM(3, 1, elem));
以第一个元素(float, x, x)为例,代码展开后为pcl::traits::plus(lhs.x, rhs.x);,这样被BOOST_PP_SEQ_FOR_EACH遍历每个元素后,则可以得到这个自定义点云的每个元素的加法形式,其他运算符重载方式类似。
inline const name& operator+= (_PointXYZIT& lhs, const _PointXYZIT& rhs)
{pcl::traits::plus(lhs.x, rhs.x);pcl::traits::plus(lhs.y, rhs.y);pcl::traits::plus(lhs.z, rhs.z);pcl::traits::plus(lhs.intensity, rhs.intensity);pcl::traits::plus(lhs.time, rhs.time);return (lhs);
}
// 如果数据类型T不是个矩阵,则套用正常的加法
template<typename T> inline
std::enable_if_t<!std::is_array<T>::value> plus (T &l, const T &r)
{l += r;
}// 如果数据类型T是矩阵,则遍历每个元素进行加法处理
// 根据数据类型来估计这个矩阵的大小
// remove_const_t的目的:假如T是const double,则把其中的const移除掉
template<typename T> inline
std::enable_if_t<std::is_array<T>::value> plus (std::remove_const_t<T> &l, const T &r)
{// 把一个数组中的数组类型部分移除掉,只保留元素类型。// 如:int a[12]; 其中a的类型=int[12]; 即去除[12],只保留元素类型 int。using type = std::remove_all_extents_t<T>;constexpr std::uint32_t count = sizeof(T) / sizeof(type);for (std::uint32_t i = 0; i < count; ++i)l[i] += r[i];
}
这里我们发现注册器还支持数组类型的注册,确实如此。

同样地,对于PCL_PLUSEQSC_POINT_TAG,以第一个元素(float, x, x)为例,代码展开后为pcl::traits::plusscalar(lhs.x, scalar);原理与上面的加法类似。
#define PCL_PLUSEQSC_POINT_TAG(r, data, elem) \pcl::traits::plusscalar (p.BOOST_PP_TUPLE_ELEM(3, 1, elem), \scalar);template<typename T1, typename T2> inline
std::enable_if_t<!std::is_array<T1>::value> plusscalar (T1 &p, const T2 &scalar)
{p += scalar;
}template<typename T1, typename T2> inline
std::enable_if_t<std::is_array<T1>::value> plusscalar (T1 &p, const T2 &scalar)
{using type = std::remove_all_extents_t<T1>;constexpr std::uint32_t count = sizeof(T1) / sizeof(type);for (std::uint32_t i = 0; i < count; ++i)p[i] += scalar;
}(2) 重载点云减法运算
相关代码如下,一个减法运算需要构造5种重载形式,需要处理的内容基本与加法无益。这里就不进行重复说明了。
inline const name& \ // pt1 -= pt2
operator-= (name& lhs, const name& rhs) \
{ \BOOST_PP_SEQ_FOR_EACH(PCL_MINUSEQ_POINT_TAG, _, seq) \return (lhs); \
} \
inline const name& \ // pt1 -= k
operator-= (name& p, const float& scalar) \
{ \BOOST_PP_SEQ_FOR_EACH(PCL_MINUSEQSC_POINT_TAG, _, seq) \return (p); \
} \
inline const name operator- (const name& lhs, const name& rhs) \ // pt3 = pt1 - pt2
{ name result = lhs; result -= rhs; return (result); } \
inline const name operator- (const float& scalar, const name& p) \ // pt2 = pt1 - k
{ name result = p; result *= -1.0f; result += scalar; return (result); } \
inline const name operator- (const name& p, const float& scalar) \ // pt2 = k - pt1
{ name result = p; result -= scalar; return (result); } \
(3) 重载点云乘除法运算
对于乘除法来说,就只有一个数乘了,这里用法基本与前面相似,没有新的技巧需要介绍。
- 乘除法:点云乘除法只有一个数乘/除,即
pt1 *= k, pt2 = pt1 * k, pt2 = k * pt1,pt1 /= k, pt2 = pt1 / k, pt2 = k / pt1。
inline const name& \ // pt1 *= k
operator*= (name& p, const float& scalar) \
{ \BOOST_PP_SEQ_FOR_EACH(PCL_MULEQSC_POINT_TAG, _, seq) \return (p); \
} \
inline const name operator* (const float& scalar, const name& p) \ // pt2 = k * pt1
{ name result = p; result *= scalar; return (result); } \
inline const name operator* (const name& p, const float& scalar) \ // pt2 = pt1 * k
{ name result = p; result *= scalar; return (result); } \
inline const name& \ // pt1 /= k
operator/= (name& p, const float& scalar) \
{ \BOOST_PP_SEQ_FOR_EACH(PCL_DIVEQSC_POINT_TAG, _, seq) \return (p); \
} \
inline const name operator/ (const float& scalar, const name& p_in) \ // pt2 = k / pt1
{ name p = p_in; BOOST_PP_SEQ_FOR_EACH(PCL_DIVEQSC2_POINT_TAG, _, seq) \return (p); } \
inline const name operator/ (const name& p, const float& scalar) \ // pt2 = pt1 / k
{ name result = p; result /= scalar; return (result); } \
2.2.2 [field] 注册字段域
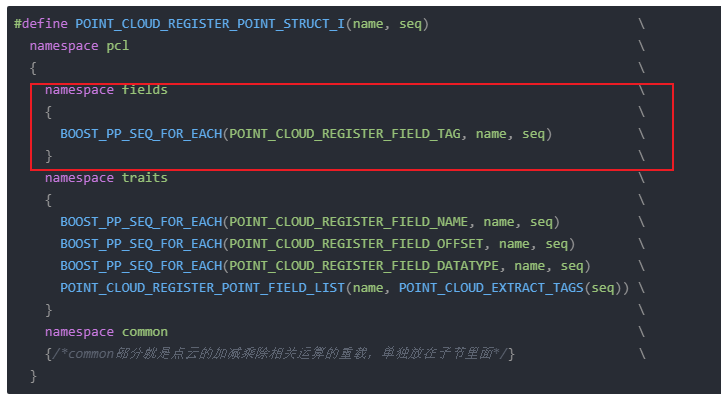
字段域注册代码只有BOOST_PP_SEQ_FOR_EACH(POINT_CLOUD_REGISTER_FIELD_TAG, name, seq),对应的宏定义为:
#define POINT_CLOUD_REGISTER_FIELD_TAG(r, name, elem) \struct BOOST_PP_TUPLE_ELEM(3, 2, elem); \
对于前面的例子_PointXYZIT,这里展开后结果就是struct x; struct y; struct z; struct intensity; struct time; 然而我们是无法找到struct x;等属性的相关内容的具体定义,因此这里我们引出PCL的一个非常巧的一个定义方式:不完全类型。
不完全类型指“函数之外、类型的大小不能被确定的类型”,只能以有限方式使用。在这里,你就理解为一个tag,我们永远不会实例化这个。
这个tag在构造类模板中起到了非常大的一个作用,比如我们可以为点云添加一个字段的名称(简化模式),这样在使用时候就可以通过name<_PointXYZIT, pcl::fields::x>::value来得到指定字段对应的字符串名称(“x”),pcl::fields::x对应的是前面展开的struct x;,而且在注册fields时候完全不用担心重定义问题,因为这个只是个声明,没有任何实质内容。真的是一个非常巧妙的一种设计模式,好喜欢!!!下面的template class仅是个示例,下节细说。
// 这里的value记录的就是字段对应的字符串形式,即
// name<_PointXYZIT, pcl::fields::x>::value = "x"
// name<_PointXYZIT, pcl::fields::intensity>::value = "intensity"
template<class PointT, typename Tag>
struct name
{ static const char value[];
};
到这里肯定有个疑问,这里用宏定义来定义一个唯一的struct是否可以,当然可以。但这种编程模式,属于C++编程技术中的萃取技术(Traits)。萃取技术(Traits)是模板元编程的一个核心概念,用于在编译时提供类型相关的信息。用template比用宏定义更加清晰,也更加容易维护。
2.2.3 [traits] 注册各种字段详细属性
Traits 是一种编程技术,特别适用于 C++ 这样的泛型编程语言。它的核心思想是在编译时收集和封装关于特定类型的各种属性或行为信息,这些信息对于编写泛型代码至关重要,但通常不会直接体现在类型本身的声明中。在编写泛型代码时(比如使用模板),经常会遇到这样的情况:
- 需要根据类型的不同特性(如是否为指针、是否支持某种运算符、是否有特定的成员函数等)来选择不同的实现路径。
- 想要提供一套通用的接口,使其能够适应不同类型的特殊要求,如容器类可能需要知道其元素类型的大小以便高效分配内存。
- 希望在编译阶段就能够发现某些类型不满足特定条件(如不支持某个操作)导致的错误,而不是等到运行时出错。
Traits 技术就是为了满足这些需求而诞生的,它提供了一种机制,使得编译器可以根据类型特质而非类型本身来做出编译时决策,生成最合适的代码。《C++ 的 traits 技术到底是什么? - 星河灿烂梦中寻的回答》
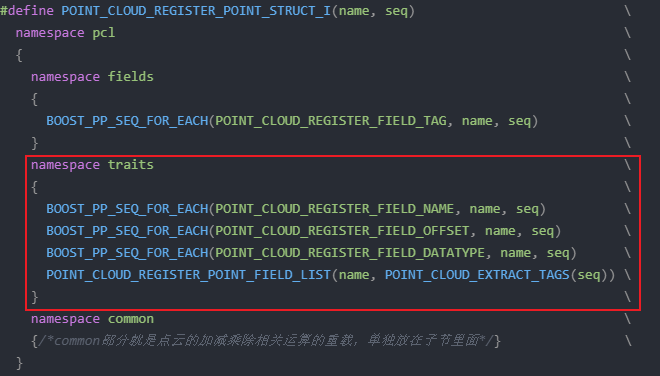
在理解前面的内容之后,我们开始正式理解PCL中的注册原理。注册主要需要记录以下信息:字段名称、字段大小、字段类型、添加列表。
(1) 点云字段名的注册
由BOOST_PP_SEQ_FOR_EACH(POINT_CLOUD_REGISTER_FIELD_NAME, name, seq)完成,其中关键宏定义POINT_CLOUD_REGISTER_FIELD_NAME如下:
// templat中用了dummy,这个字段没有意义,只是为了保证这个class可以定义在hpp中,
// 否则认为没有参数,无法直接初始化value的值,编译期抛出错误
#define POINT_CLOUD_REGISTER_FIELD_NAME(r, point, elem) \template<int dummy> \struct name<point, pcl::fields::BOOST_PP_TUPLE_ELEM(3, 2, elem), dummy> \{ \static const char value[]; \}; \\template<int dummy> \const char name<point, \pcl::fields::BOOST_PP_TUPLE_ELEM(3, 2, elem), \dummy>::value[] = \BOOST_PP_STRINGIZE(BOOST_PP_TUPLE_ELEM(3, 2, elem)); \ // 记录字段的名称
原理很简单,声明一个模板struct,其中Point和对应的字段fields作为个Tag,然后初始化value为字段的字符串形式。注意到这里用了一个template name,并对这个name进行了class template 特化处理,原型如下。
// 这里的POD目前可以理解为POD<PointT>::type等价于PointT,具体用法后面说。
template<class PointT, typename Tag, int dummy = 0>
struct name : name<typename POD<PointT>::type, Tag, dummy>
{// 特化时需要指定value// static const char value[];// 剔除编译器的无限循环,只要这个tag没有被特化,就直接抛出错误BOOST_MPL_ASSERT_MSG((!std::is_same<PointT, typename POD<PointT>::type>::value),POINT_TYPE_NOT_PROPERLY_REGISTERED, (PointT&));
};
从点云注册的角度去理解特化,就是每个点的字段都必须对name进行特化,即必须构造struct name<point, pcl::fields::BOOST_PP_TUPLE_ELEM(3, 2, elem), dummy>,这样在调用时调用的是特化后的数据。否则调用的是原型的类模板,并在编译期抛出错误,以提示开发者需要处理这个字段。(更详细的特化技术可以参考博客:C++ 模板特化与偏特化)
(2) 点云字段偏移量的注册
由BOOST_PP_SEQ_FOR_EACH(POINT_CLOUD_REGISTER_FIELD_OFFSET, name, seq)完成,其中关键宏定义POINT_CLOUD_REGISTER_FIELD_OFFSET如下,整体定义思路及方式与name相似。
template<class PointT, typename Tag>
struct offset : offset<typename POD<PointT>::type, Tag>
{BOOST_MPL_ASSERT_MSG((!std::is_same<PointT, typename POD<PointT>::type>::value),POINT_TYPE_NOT_PROPERLY_REGISTERED, (PointT&));
};// 记录字段偏移量
#define POINT_CLOUD_REGISTER_FIELD_OFFSET(r, name, elem) \template<> struct offset<name, pcl::fields::BOOST_PP_TUPLE_ELEM(3, 2, elem)> \{ \static const std::size_t value = offsetof(name, BOOST_PP_TUPLE_ELEM(3, 1, elem)); \};
其中offsetof是个宏定义,定义在#include <cstddef>中,传入Class名和变量名即可确定当前变量的偏移。原型很简单:
// 通过将结构体首地址虚拟为0来计算成员偏移量
// 该宏在预处理阶段展开,不产生任何运行时开销。偏移量计算结果由编译器根据结构体内存布局直接生成
// 这里仅限制常见的C语言类型(POD),包含数组。其他非POD,比如vector类型就不能这样用了
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE*)0)->MEMBER)
// (TYPE*)0:将0强制转换为TYPE类型的指针,虚拟一个起始地址为0的结构体实例
// &((TYPE*)0)->MEMBER:获取成员MEMBER的地址。由于结构体首地址为0,该地址的数值即等于成员的字节偏移量
// (size_t):将偏移量转换为无符号整型,确保跨平台兼容性
(3) 点云字段数据类型的注册
由BOOST_PP_SEQ_FOR_EACH(POINT_CLOUD_REGISTER_FIELD_DATATYPE, name, seq)完成,其中关键宏定义POINT_CLOUD_REGISTER_FIELD_DATATYPE如下:
template<class PointT, typename Tag>
struct datatype : datatype<typename POD<PointT>::type, Tag>
{BOOST_MPL_ASSERT_MSG((!std::is_same<PointT, typename POD<PointT>::type>::value),POINT_TYPE_NOT_PROPERLY_REGISTERED, (PointT&));
};// 利用name确定数据类型,数据类型的enum,以及数据类型大小
// 注:这里pcl::fields::BOOST_PP_TUPLE_ELEM(3, 2, elem)我认为应该是BOOST_PP_TUPLE_ELEM(3, 1, elem)
// 但由于注册时变量和name一样,所以这种问题没有触发
#define POINT_CLOUD_REGISTER_FIELD_DATATYPE(r, name, elem) \template<> struct datatype<name, pcl::fields::BOOST_PP_TUPLE_ELEM(3, 2, elem)> \{ \using type = boost::mpl::identity<BOOST_PP_TUPLE_ELEM(3, 0, elem)>::type; \using decomposed = decomposeArray<type>; \static const std::uint8_t value = asEnum<decomposed::type>::value; \static const std::uint32_t size = decomposed::value; \};
datatype中有三个关键变量:
type:数据类型,比如float, int,float[32]等。boost::mpl::identity是个模板,输入是什么类型,输出是什么类型,主要用于延迟推导。value:每个元素的数据类型,每种数据类型映射到了一个uint8上,这样可以在运行时动态的对点云进行拷贝赋值等无感操作。
template<typename T> struct asEnum {};
template<> struct asEnum<std::int8_t> { static const std::uint8_t value = detail::PointFieldTypes::INT8; };
template<> struct asEnum<std::uint8_t> { static const std::uint8_t value = detail::PointFieldTypes::UINT8; };
template<> struct asEnum<std::int16_t> { static const std::uint8_t value = detail::PointFieldTypes::INT16; };
template<> struct asEnum<std::uint16_t> { static const std::uint8_t value = detail::PointFieldTypes::UINT16; };
template<> struct asEnum<std::int32_t> { static const std::uint8_t value = detail::PointFieldTypes::INT32; };
template<> struct asEnum<std::uint32_t> { static const std::uint8_t value = detail::PointFieldTypes::UINT32; };
template<> struct asEnum<float> { static const std::uint8_t value = detail::PointFieldTypes::FLOAT32; };
template<> struct asEnum<double> { static const std::uint8_t value = detail::PointFieldTypes::FLOAT64; };
size:返回元素个数,如果注册类型是数组,则这里是元素个数。否则就是1。
元素类型和元素个数利用下面这个template进行推断
template<typename T> struct decomposeArray
{// 单数据:float->float; 数组:float[]->floatusing type = std::remove_all_extents_t<T>; // 单数据: sizeof(float) / sizeof(float) = 1;// 数组:sizeof(float[8]) / sizeof(float) = 8;static const std::uint32_t value = sizeof (T) / sizeof (type);
};
(4) 构造点云字段列表
相关代码为POINT_CLOUD_REGISTER_POINT_FIELD_LIST(name, POINT_CLOUD_EXTRACT_TAGS(seq))。
先看展开seq的部分,这里的目的是提取字段的内容,比如((float, x, x))((float, y, y))就变更为(pcl::fields::x)(pcl::fields::y)
// 我依然认为这里应该是BOOST_PP_TUPLE_ELEM(3, 1, elem)
#define POINT_CLOUD_TAG_OP(s, data, elem) pcl::fields::BOOST_PP_TUPLE_ELEM(3, 2, elem)
#define POINT_CLOUD_EXTRACT_TAGS(seq) BOOST_PP_SEQ_TRANSFORM(POINT_CLOUD_TAG_OP, _, seq)
注册这个点云的属性列表,就是增加个vector数据类型,承载所有的字段
template<typename PointT>
struct fieldList : fieldList<typename POD<PointT>::type>
{BOOST_MPL_ASSERT_MSG((!std::is_same<PointT, typename POD<PointT>::type>::value),POINT_TYPE_NOT_PROPERLY_REGISTERED, (PointT&));
};#define POINT_CLOUD_REGISTER_POINT_FIELD_LIST(name, seq) \template<> struct fieldList<name> \{ \using type = boost::mpl::vector<BOOST_PP_SEQ_ENUM(seq)>; \};// 展开后,_PointXYZIT对应内容为
template<> struct fieldList<_PointXYZIT>
{using type = boost::mpl::vector<pcl::fields::x,pcl::fields::y,pcl::fields::z,pcl::fields::intensity,pcl::fields::time>
}
定义了这个之后,就可以利用for_each_type<typename traits::fieldList<PointT>::type> (mapper);对每个字段进行遍历,或者利用boost::mpl::contains判断是否包含指定字段了。
- 对于遍历:可以利用offset和name,直接动态memcpy, write, read对每个字段进行处理,无须关心字段具体内容。
- 对于判断:算法处理时,可以利用contains判断是否存在指定字段,可以在编译期直接报错。
2.3 注册自定义点类型包装器
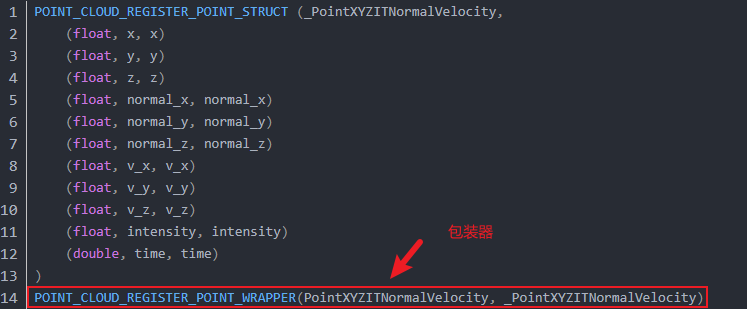
注册自定义点类型包装器的宏,其核心用途是扩展或适配现有点类型的访问接口,使其与 PCL 内部算法兼容。其定义如下:
#define POINT_CLOUD_REGISTER_POINT_WRAPPER(wrapper, pod) \BOOST_MPL_ASSERT_MSG(sizeof(wrapper) == sizeof(pod), POINT_WRAPPER_AND_POD_TYPES_HAVE_DIFFERENT_SIZES, (wrapper&, pod&)); \namespace pcl { \namespace traits { \template<> struct POD<wrapper> { using type = pod; }; \} \}
我们在定义好点云时候,还会再派生一个class,增加构造方式,以及std::cout打印点云信息。从定义中,也可以发现,派生的class,不能再定义新的字段。
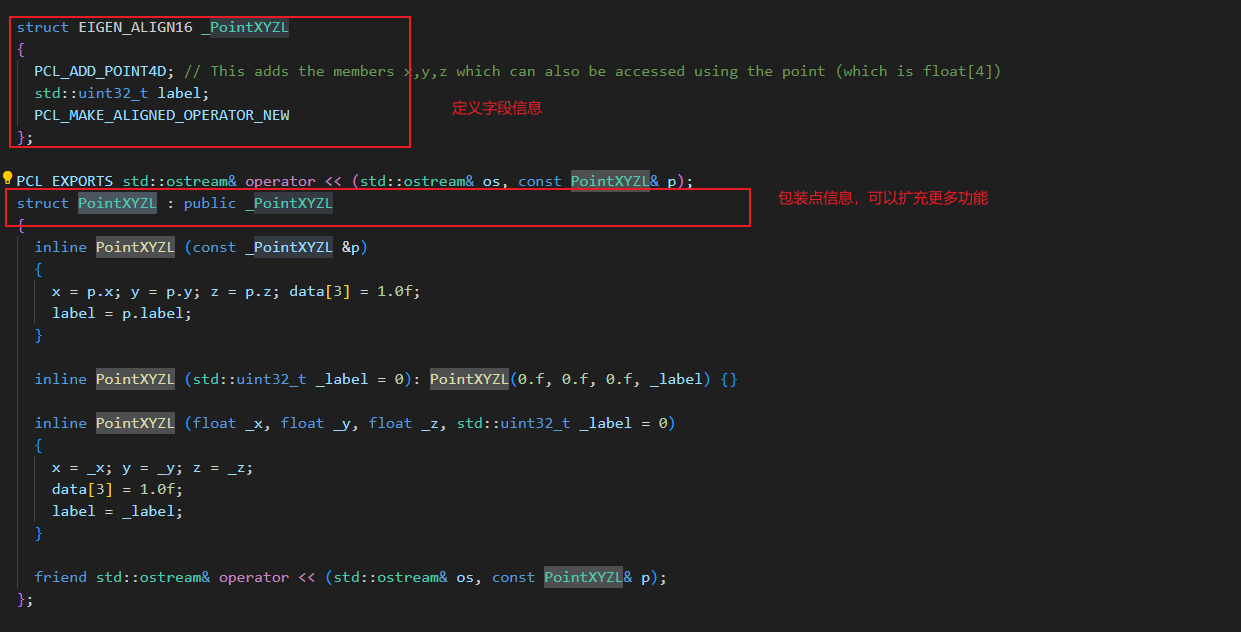
包装器template<> struct POD<wrapper> { using type = pod; };的定义,就是说明派生class的字段操作方式同原始数据结构,即PointXYZL的字段操作方式同_PointXYZL。这里不理解可以先mark下,后面带着例子去理解。
三 点云无感操作函数解析
对于自定义点云来说,无感操作函数,也就是完全不关心有什么字段,只需要遍历已存在的字段列表,完成数据拷贝IO等操作,涉及到拷贝核心就是memcpy,size大小,offset,数据类型(type和实际内容互转)。经典常用的无感函数有3钟:
// 自定义点云保存
template <typename PointT> int
writeBinaryCompressed (const std::string &file_name, const pcl::PointCloud<PointT> &cloud)
{PCDWriter w;return (w.writeBinaryCompressed<PointT>(file_name, cloud));
}// 自定义点云加载
template<typename PointT> inline int
loadPCDFile (const std::string &file_name, pcl::PointCloud<PointT> &cloud)
{pcl::PCDReader p;return (p.read (file_name, cloud));
}// 点云A到点云B的拷贝
template <typename PointInT, typename PointOutT> void
copyPointCloud (const pcl::PointCloud<PointInT> &cloud_in, pcl::PointCloud<PointOutT> &cloud_out);
3.1 字段操作
在正式介绍相关内容之前,还需要理解一些前置函数,比如操作字段相关。
3.1.1 将任意点云的所有字段统一为同一个Struct
pcl中构造了一个结构体PCLPointField来存放一个字段的所有内容,定义函数getFields来将任意一种点云类型转换成std::vector<pcl::PCLPointField>(有一种万象归一的感觉👀),每个字段的转换方式定义在FieldAdder中。
先介绍可承载“万点类型”的数据结构:
// 定义在common\include\pcl\PCLPointField.h
struct PCLPointField
{std::string name; // 字段的字符串名称uindex_t offset = 0; // 字段偏移量std::uint8_t datatype = 0; // 数据类型,uindex_t count = 0; // 元素个数// 还有一些无关函数,跟本节内容无关,省略掉了
}; // struct PCLPointField
PCL中定义了一个函数pcl::for_each_type,通过调用转换器的operator()函数来对每个字段完成数据转换,因此对应的转换器细节如下:
template<typename PointT>
struct FieldAdder
{// 传入vector的引用,记录fields的指针。FieldAdder (std::vector<pcl::PCLPointField>& fields) : fields_ (fields) {};// 运算符重载,U表示字段对应的tag,就是在点云注册时定义的template<typename U> void operator() (){pcl::PCLPointField f;// 这里传递的就是注册时确定的值f.name = traits::name<PointT, U>::value;f.offset = traits::offset<PointT, U>::value;f.datatype = traits::datatype<PointT, U>::value;f.count = traits::datatype<PointT, U>::size;fields_.push_back (f);}std::vector<pcl::PCLPointField>& fields_;
};最终定义了下述函数,实现所有字段的转换
template <typename PointT> std::vector<pcl::PCLPointField>
getFields ()
{std::vector<pcl::PCLPointField> fields;// Get the fields listpcl::for_each_type<typename pcl::traits::fieldList<PointT>::type>(pcl::detail::FieldAdder<PointT>(fields));return fields;
}
3.1.2 提取两个点云字段的交集
定义前要,每个字段列表的定义如下:
#define POINT_CLOUD_REGISTER_POINT_FIELD_LIST(name, seq) \template<> struct fieldList<name> \{ \using type = boost::mpl::vector<BOOST_PP_SEQ_ENUM(seq)>; \};
提取两个vector seq1, seq2交集的思路如下:
- 判断seq1中的每个字段是否在seq2中。
boost::mpl::contains<Sequence2, boost::mpl::_1>,这里boost::mpl::_1就是个占位符,在后续操作中被调用时动态接收参数。 - 移除不包含的字段。
- 利用
boost::mpl::not_将contains结果取反,即若seq1中的一个字段key1不在seq2中,则为true。 - 移除字段,
boost::mpl::remove_if移除seq1中不在seq2的字段。
- 利用
template <typename Sequence1, typename Sequence2>struct intersect { using type = typename boost::mpl::remove_if<Sequence1, boost::mpl::not_<boost::mpl::contains<Sequence2, boost::mpl::_1> > >::type; };
3.1.3 判断某个自定义类型是否包含指定字段
在设计算法时,想在编译期预先检查是否包含所需字段,则可以参考common\include\pcl\impl\point_types.hpp中的类模板has_all_fields进行判断。
// 是否含有指定字段,如果有则has_field::value = true
template <typename PointT, typename Field>
struct has_field : boost::mpl::contains<typename pcl::traits::fieldList<PointT>::type, // PointT的全量字段列表Field // 待判断字段>::type
{ };// 指定的字段列表是否都在PointT中,如果都在则has_all_fields::value = true
template <typename PointT, typename Field>
struct has_all_fields : boost::mpl::fold<Field, // boost::mpl::vectorboost::mpl::bool_<true>,boost::mpl::and_<boost::mpl::_1,has_field<PointT, boost::mpl::_2> > >::type
{ };
如果想判断是否存在xyz字段,则可以定义
template <typename PointT>
struct has_xyz : has_all_fields<PointT, boost::mpl::vector<pcl::fields::x,pcl::fields::y,pcl::fields::z> >
{ };// 若值为true则表示xyz字段在PointT中
template <typename PointT>
constexpr auto has_xyz_v = has_xyz<PointT>::value;
3.2 保存点云
点云保存以PCD为例,保存后的PCD内容如下,包含数据头和编码数据两个部分。

关于数据头保存定义在函数generateHeader中,详见io\include\pcl\io\impl\pcd_io.hpp,这里仅介绍跟自定义点云相关内容。
template <typename PointT> std::string
pcl::PCDWriter::generateHeader (const pcl::PointCloud<PointT> &cloud, const int nr_points)
{std::ostringstream oss;oss.imbue (std::locale::classic ());oss << "# .PCD v0.7 - Point Cloud Data file format""\nVERSION 0.7""\nFIELDS";// 获取点云的所有字段信息const std::vector<pcl::PCLPointField> fields = pcl::getFields<PointT>();std::stringstream field_names, field_types, field_sizes, field_counts;for (const auto &field : fields){// PCLPointCloud2中定义的某种字段,跟本博客内容暂时无关,暂不考虑if (field.name == "_") continue;// 保存字段名称field_names << " " << field.name; // 根据数据类型,获取保存字段对应的字节数,field_sizes << " " << pcl::getFieldSize (field.datatype);// 根据数据类型,获取保存时数据类型的名称,比如I/U/F等if ("rgb" == field.name)field_types << " " << "U";elsefield_types << " " << pcl::getFieldType (field.datatype);// 记录当前字段的元素个数(字段类型为array情况)int count = std::abs (static_cast<int> (field.count));if (count == 0) count = 1; // check for 0 counts (coming from older converter code)field_counts << " " << count;}oss << field_names.str ();oss << "\nSIZE" << field_sizes.str () << "\nTYPE" << field_types.str () << "\nCOUNT" << field_counts.str ();// 记录点云个数等信息(跟自定义点无关了,这里可以跳过)if (nr_points != std::numeric_limits<int>::max ())oss << "\nWIDTH " << nr_points << "\nHEIGHT " << 1 << "\n";elseoss << "\nWIDTH " << cloud.width << "\nHEIGHT " << cloud.height << "\n";oss << "VIEWPOINT " << cloud.sensor_origin_[0] << " " << cloud.sensor_origin_[1] << " " << cloud.sensor_origin_[2] << " " << cloud.sensor_orientation_.w () << " " << cloud.sensor_orientation_.x () << " " << cloud.sensor_orientation_.y () << " " << cloud.sensor_orientation_.z () << "\n";if (nr_points != std::numeric_limits<int>::max ())oss << "POINTS " << nr_points << "\n";elseoss << "POINTS " << cloud.size () << "\n";return (oss.str ());
}
上述介绍了怎么遍历字段来获取字节、名称等信息,下面这里正式介绍怎么保存点云各个字段的数据。
template <typename PointT> int
pcl::PCDWriter::writeBinaryCompressed (const std::string &file_name, const pcl::PointCloud<PointT> &cloud)
{// 生成PCD文件头std::ostringstream oss;oss << generateHeader<PointT> (cloud) << "DATA binary_compressed\n";oss.flush ();int data_idx = static_cast<int> (oss.tellp ());// 打开文件,准备保存int fd = io::raw_open (file_name.c_str (), O_RDWR | O_CREAT | O_TRUNC, S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);boost::interprocess::file_lock file_lock;setLockingPermissions(file_name, file_lock);// auto fields = pcl::getFields<PointT> (); // 存放待处理的字段std::size_t fsize = 0; // 记录一个点的字节数std::size_t data_size = 0; // 记录整个点云字节数,即num * fsizestd::size_t nri = 0; std::vector<int> fields_sizes (fields.size ()); // 每个字段,整个点云的字节数for (const auto &field : fields){if (field.name == "_")continue;fields_sizes[nri] = field.count * pcl::getFieldSize (field.datatype);fsize += fields_sizes[nri];fields[nri] = field;++nri;}fields_sizes.resize (nri);fields.resize (nri);data_size = cloud.size () * fsize;// 分配需要保存的数据内存,我这里选择的是有压缩的保存方式,因此需要将所有字节存放在一起进行无损压缩char *only_valid_data = static_cast<char*> (malloc (data_size));// 保存方式是将字段合并在一起保存,比如字段内容是xyz,则将点云的x放一起保存,再将y放一起保存。std::vector<char*> pters (fields.size ()); // 各个字段的数据指针std::size_t toff = 0;for (std::size_t i = 0; i < pters.size (); ++i){pters[i] = &only_valid_data[toff];toff += static_cast<std::size_t>(fields_sizes[i]) * cloud.size();}// 遍历所有的点的所有字段,将数据存放在对应指针下for (const auto& point: cloud){for (std::size_t j = 0; j < fields.size (); ++j){// 利用offset确定字段首地址,利用field_size确定需要拷贝的字节数memcpy (pters[j], reinterpret_cast<const char*> (&point) + fields[j].offset, fields_sizes[j]);// 将指针向后移,移动后即为下个点对应字段的保存地址pters[j] += fields_sizes[j];}}/*后面与字段操作无关,这里不进行详解了*/char* temp_buf = static_cast<char*> (malloc (static_cast<std::size_t> (static_cast<float> (data_size) * 1.5f + 8.0f)));unsigned int compressed_size = pcl::lzfCompress (only_valid_data, static_cast<std::uint32_t> (data_size), &temp_buf[8], static_cast<std::uint32_t> (static_cast<float>(data_size) * 1.5f));unsigned int compressed_final_size = 0;// Was the compression successful?if (compressed_size){char *header = &temp_buf[0];memcpy (&header[0], &compressed_size, sizeof (unsigned int));memcpy (&header[4], &data_size, sizeof (unsigned int));data_size = compressed_size + 8;compressed_final_size = static_cast<std::uint32_t> (data_size) + data_idx;}else{resetLockingPermissions (file_name, file_lock);throw pcl::IOException ("[pcl::PCDWriter::writeBinaryCompressed] Error during compression!");return (-1);}// Prepare the map// Allocate disk space for the entire file to prevent bus errors.if (io::raw_fallocate (fd, compressed_final_size) != 0) { /*省略异常处理*/ }char *map = static_cast<char*> (::mmap (nullptr, compressed_final_size, PROT_WRITE, MAP_SHARED, fd, 0));if (map == reinterpret_cast<char*> (-1)) //MAP_FAILED) { /*省略异常处理*/ }// Copy the headermemcpy (&map[0], oss.str ().c_str (), data_idx);// Copy the compressed datamemcpy (&map[data_idx], temp_buf, data_size);// Unmap the pages of memoryif (::munmap (map, (compressed_final_size)) == -1) { /*省略异常处理*/ }// Close fileio::raw_close (fd);resetLockingPermissions (file_name, file_lock);free (only_valid_data);free (temp_buf);return (0);
}
3.2 加载点云
点云读取时,是先将数据读取到PCLPointCloud2(全量点云),然后再通过fromPCLPointCloud2将读取到的点云转换为目标点云,点云加载时允许存在字段的丢失,比如保存时点云类型为PointXYZI,加载时可以指定为PointXYZ。
template<typename PointT> int
read (const std::string &file_name, pcl::PointCloud<PointT> &cloud, const int offset = 0)
{pcl::PCLPointCloud2 blob;int pcd_version;int res = read (file_name, blob, cloud.sensor_origin_, cloud.sensor_orientation_,pcd_version, offset);// If no error, convert the dataif (res == 0)pcl::fromPCLPointCloud2 (blob, cloud);return (res);
}
保存时按照每个点的每个字段进行保存,那么读取时同样是按照每个字段进行读取,相关代码在io\src\pcd_io.cpp,这里仅摘出读取部分的代码以便理解:
/* 假设这里我们已经读取完文件头,并且完成相关字段信息的构建,相关变量
std::vector<pcl::PCLPointField> fields;
std::vector<int> fields_sizes; // 每个字段,整个点云的字节数
*/// 构造每个字段的数据指针起始地址
std::vector<char*> pters (fields.size ());
std::size_t toff = 0;
for (std::size_t i = 0; i < pters.size (); ++i)
{pters[i] = &buf[toff];toff += fields_sizes[i] * cloud.width * cloud.height;
}
// Copy it to the cloud
for (uindex_t i = 0; i < cloud.width * cloud.height; ++i)
{for (std::size_t j = 0; j < pters.size (); ++j){// 利用offset确定字段首地址,利用field_size确定需要拷贝的字节数// 利用memcpy将保存的数据地址,复制到点云对应位置上memcpy (&cloud.data[i * fsize + fields[j].offset], pters[j], fields_sizes[j]);// Increment the pointerpters[j] += fields_sizes[j];}
}
3.3 点云拷贝
点云拷贝,主要是将点云类型A,转换为点云数据类型B,核心的功能就是需要将有共同字段的数据拷贝过去,相关代码在common\include\pcl\common\impl\io.hpp,这里对其中一个最简单的函数进行详解
template <typename PointInT, typename PointOutT> void
copyPointCloud (const pcl::PointCloud<PointInT> &cloud_in, pcl::PointCloud<PointOutT> &cloud_out)
{// 拷贝点云基本信息,跟自定义点无关,并分配内存空间cloud_out.header = cloud_in.header;cloud_out.width = cloud_in.width;cloud_out.height = cloud_in.height;cloud_out.is_dense = cloud_in.is_dense;cloud_out.sensor_orientation_ = cloud_in.sensor_orientation_;cloud_out.sensor_origin_ = cloud_in.sensor_origin_;cloud_out.resize (cloud_in.size ());if (cloud_in.empty ())return;// 如果两种点云数据类型一样,直接对点云进行深拷贝if (isSamePointType<PointInT, PointOutT> ())memcpy (&cloud_out[0], &cloud_in[0], cloud_in.size () * sizeof (PointInT));else// 点云类型不一致,只能一个点一个点的处理了for (std::size_t i = 0; i < cloud_in.size (); ++i)copyPoint (cloud_in[i], cloud_out[i]);
}
自定义点的拷贝copyPoint 的主函数定义在common\include\pcl\common\impl\copy_point.hpp中。
template <typename PointInT, typename PointOutT> void
copyPoint (const PointInT& point_in, PointOutT& point_out)
{detail::CopyPointHelper<PointInT, PointOutT> copy;copy (point_in, point_out);
}
值得注意的是,CopyPointHelper也是个类模板,跟3.1中介绍的FieldAdder的使用方式相似,PCL中针对有无rgb/rgba字段的点进行可不同的拷贝处理,这里介绍大多数字段的拷贝方式。
// 计算两个点云的字段交集,intersect原理参考3.1
using FieldListInT = typename pcl::traits::fieldList<PointInT>::type;
using FieldListOutT = typename pcl::traits::fieldList<PointOutT>::type;
using FieldList = typename pcl::intersect<FieldListInT, FieldListOutT>::type;// 遍历每个字段进行拷贝
pcl::for_each_type <FieldList> (pcl::NdConcatenateFunctor <PointInT, PointOutT> (point_in, point_out));
字段拷贝器NdConcatenateFunctor,定义在common\include\pcl\common\concatenate.h:
template<typename PointInT, typename PointOutT>
struct NdConcatenateFunctor
{using PodIn = typename traits::POD<PointInT>::type;using PodOut = typename traits::POD<PointOutT>::type;NdConcatenateFunctor (const PointInT &p1, PointOutT &p2): p1_ (reinterpret_cast<const PodIn&> (p1)), p2_ (reinterpret_cast<PodOut&> (p2)) { }template<typename Key> inline void operator () (){// 提取字段的数据类型,如果数据类型不同直接抛出错误using InT = typename pcl::traits::datatype<PointInT, Key>::type;using OutT = typename pcl::traits::datatype<PointOutT, Key>::type;BOOST_MPL_ASSERT_MSG ((std::is_same<InT, OutT>::value),POINT_IN_AND_POINT_OUT_HAVE_DIFFERENT_TYPES_FOR_FIELD,(Key, PointInT&, InT, PointOutT&, OutT));// 利用offset,和字段的sizeof,利用memcpy直接拷贝memcpy (reinterpret_cast<std::uint8_t*>(&p2_) + pcl::traits::offset<PointOutT, Key>::value,reinterpret_cast<const std::uint8_t*>(&p1_) + pcl::traits::offset<PointInT, Key>::value,sizeof (InT));}private:const PodIn &p1_;PodOut &p2_;
};
四 小结
从24年9月份就准备开始彻底理解这个注册原理,用业余时间断断续续花了7个月才把这个吃透(真的太烧脑了😭)。点云注册机制是PCL的核心,吃透了这个,后面去理解点云处理算法会轻松很多。
PCL中的注册器以及各种traits都很深奥,需要花费较多时间去理解。PCL中默认的注册方式有些潜在的约束,用户是无法感知的,而且注册器中有些小小的bug,比如注册字段时,字符串和name都是一致的,因此没有触发。还有对于特殊的类别,如果想在点云中记录label等信息,在进行点云的基本运算时,很容易出现问题。
PCL注册机制对个人的项目开发有很大的启发意义,我在自己的工作中模仿PCL的方式实现了挺多功能,解决新类型注册的封装、代码复用等等。当然,模仿的也仅仅是其冰山一角,代码结构设计还需要不断地在实际应用中不断尝试。
相关文章:
孤码长征:破译PCL自定义点云注册机制源码迷局——踩坑实录与架构解构
在之前一个博客《一文搞懂PCL中自定义点云类型的构建与函数使用》中,清晰地介绍了在PCL中点云的定义与注册方法。我的一个读者很好奇其内部注册的原理以及机制,再加上最近工作中跟猛男开发自定义点云存储的工作,借着这些需求,我也…...

【SQL】MySQL基础2——视图,存储过程,游标,约束,触发器
文章目录 1. 视图2. 存储过程2.1 创建存储过程2.2 执行存储过程 3. 游标4. 约束4.1 主键约束4.2 外键约束4.3 唯一约束4.4 检查约束 5. 触发器 1. 视图 视图是虚拟的表,它是动态检索的部分。使用视图的原因:避免重复的SQL语句;使用表的部分而…...

Centos 7 搭建 jumpserver 堡垒机
jumpserver 的介绍 1、JumpServer 是完全开源的堡垒机, 使用 GNU GPL v2.0 开源协议, 是符合4A 的专业运维审计系统 1)身份验证 / Authentication 2)授权控制 / Authorization 3)账号管理 / Accounting 4)安全审计 / Auditing 2、JumpServer 使用 Python / Django 进行开…...

封装了一个优雅的iOS全屏侧滑返回工具
思路 添加一个全屏返回手势,UIPangesturerecognizer, 1 手势开始 在手势开始响应的时候,将navigationController的delegate代理设置为工具类,在工具类中执行代理方法,- (nullable id )navigationController:(UINavigationControll…...

HCIP-6 DHCP
HCIP-6 DHCP DHCP(Dynamic Host Configuration Protocol,动态主机配置协议) 手工配置网络参数存在的问题 灵活性差 容易出错 IP地址资源利用率低 工作量大 人员素质要求高 DHCP服务器按照如下次序为客户端选择IP地址: ①DHCP服务器的数…...
用于实现并查集(也称为不相交集合)数据结构类cv::detail::DisjointSets)
OpenCV图像拼接(8)用于实现并查集(也称为不相交集合)数据结构类cv::detail::DisjointSets
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::detail::DisjointSets 类是OpenCV库中用于实现不相交集合(也称为并查集)数据结构的类。该数据结构常用于处理动态连接…...

opencv图像处理之指纹验证
一、简介 在当今数字化时代,生物识别技术作为一种安全、便捷的身份验证方式,正广泛应用于各个领域。指纹识别作为生物识别技术中的佼佼者,因其独特性和稳定性,成为了众多应用场景的首选。今天,我们就来深入探讨如何利…...

记一道CTF题—PHP双MD5加密+”SALT“弱碰撞绕过
通过分析源代码并找到绕过限制的方法,从而获取到flag! 部分源码: <?php $name_POST[username]; $passencode(_POST[password]); $admin_user "admin"; $admin_pw get_hash("0e260265122865008095838959784793");…...

Text2SQL推理类大模型本地部署的解决方案
大家好,我是herosunly。985院校硕士毕业,现担任算法工程师一职,获得CSDN博客之星第一名,热衷于大模型算法的研究与应用。曾担任百度千帆大模型比赛、BPAA算法大赛评委,编写微软OpenAI考试认证指导手册。曾获得多项AI顶级比赛的Top名次,其中包括阿里云、科大讯飞比赛第一名…...

机器学习的一百个概念(3)上采样
前言 本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见[《机器学习的一百个概念》 ima 知识库 知识库广场搜索&…...

Electron应用生命周期全解析:从启动到退出的精准掌控
一、Electron生命周期的核心特征 1.1 双进程架构的生命周期差异 Electron应用的生命周期管理具有明显的双进程特征: 主进程生命周期:贯穿应用启动到退出的完整周期渲染进程生命周期:与浏览器标签页相似但具备扩展能力进程间联动周期&#…...

AI渗透测试:网络安全的“黑魔法”还是“白魔法”?
引言:AI渗透测试,安全圈的“新魔法师” 想象一下,你是个网络安全新手,手里攥着一堆工具,正准备硬着头皮上阵。这时,AI蹦出来,拍着胸脯说:“别慌,我3秒扫完漏洞࿰…...

分秒计数器设计
一、在VsCode中写代码 目录 一、在VsCode中写代码 二、在Quartus中创建工程与仿真 1、建立工程项目文件md_counter 2、打开项目文件,创建三个目录 3、打开文件trl,创建md_counter.v文件 4、打开文件tb,创建md_counter_tb.v文件 5、用VsCod…...

Flink介绍——发展历史
引入 我们整个大数据处理里面的计算模式主要可以分为以下四种: 批量计算(batch computing) MapReduce Hive Spark Flink pig流式计算(stream computing) Storm SparkStreaming/StructuredStreaming Flink Samza交互计…...

12. STL的原理
目录 1. 容器、迭代器、算法 什么是迭代器? 迭代器的作用? 迭代器的类型? 迭代器失效 迭代器的实现细节: 2. 适配器 什么是适配器? 适配器种类: 3. 仿函数 什么是仿函数? 仿函数与算法和容器的…...

OSPFv3 的 LSA 详解
一、复习: OSPFv3 运行于 IPv6 协议上,所以是基于链路,而不是基于网段,它实现了拓扑和网络的分离。另外,支持一个链路上多个进程;支持泛洪范围标记和泛洪不识别的报文(ospfv2 的行为是丢弃&…...

python 原型链污染学习
复现SU的时候遇到一道python原型链污染的题,借此机会学一下参考: 【原型链污染】Python与Jshttps://blog.abdulrah33m.com/prototype-pollution-in-python/pydash原型链污染 文章目录 基础知识对父类的污染命令执行对子类的污染pydash原型链污染打污染的…...
)
Windows 图形显示驱动开发-WDDM 2.4功能-GPU 半虚拟化(十一)
注册表设置 GPU虚拟化标志 GpuVirtualizationFlags 注册表项用于设置半虚拟化 GPU 的行为。 密钥位于: DWORD HKLM\System\CurrentControlSet\Control\GraphicsDrivers\GpuVirtualizationFlags 定义了以下位: 位描述0x1 为所有硬件适配器强制设置…...

入栈操作-出栈操作
入栈操作 其 入栈操作 汇编代码流程解析如下: 出栈操作 其 出栈操作 汇编代码流程解析如下:...

C++ 多态:面向对象编程的核心概念(一)
文章目录 引言1. 多态的概念2. 多态的定义和实现2.1 实现多态的条件2.2 虚函数2.3 虚函数的重写/覆盖2.4 虚函数重写的一些其他问题2.5 override 和 final 关键字2.6 重载/重写/隐藏的对比 3. 纯虚函数和抽象类 引言 多态是面向对象编程的三大特性之一(封装、继承、…...

传统策略梯度方法的弊端与PPO的改进:稳定性与样本效率的提升
为什么传统策略梯度方法(如REINFORCE算法)在训练过程中存在不稳定性和样本效率低下的问题 1. 传统策略梯度方法的基本公式 传统策略梯度方法的目标是最大化累积奖励的期望值。具体来说,优化目标可以表示为: max θ J ( θ )…...

我的机器学习学习之路
学习python的初衷 • hi,今天给朋友们分享一下我是怎么从0基础开始学习机器学习的。 • 我是2023年9月开始下定决心要学python的,目的有两个,一是为了提升自己的技能和价值,二是将所学的知识应用到工作中去,提升工作…...

Spring Boot 的自动装配
Spring Boot 的自动装配(Auto Configuration)是其核心特性之一,通过智能化的条件判断和配置加载机制,极大简化了传统 Spring 应用的配置复杂度。其原理和实现过程可概括为以下几个关键点: 一、核心触发机制:…...

Python数据可视化-第3章-图表辅助元素的定制
教材 本书为《Python数据可视化》一书的配套内容,本章为第3章-图表辅助元素的定制 本章主要介绍了图表辅助元素的定制,包括认识常用的辅助元素、设置坐标轴的标签、设置刻度范围和刻度标签、添加标题和图例、显示网格、添加参考线和参考区域、添加注释文…...

`git commit --amend` 详解:修改提交记录的正确方式
文章目录 git commit --amend 详解:修改提交记录的正确方式1. 修改提交信息2. 补充遗漏的文件3. 结合 --amend 进行交互式修改4. 已推送提交的修改总结 git commit --amend 详解:修改提交记录的正确方式 git commit --amend 用于修改最近一次的提交&…...

Linux系统下C语言fork函数使用案例
一、fork函数的作用 生成一个子进程,异步执行某个任务; 二、子进程的作用 1、子进程能复制一份父进程的变量、函数; 2、子进程可以和父进程同时并发执行; 函数语法: pid_t fork() 说明:调用后返回一个进程…...

springboot实现异步导入Excel的注意点
springboot实现异步导入Excel 需求前言异步导入面临的问题实现异步如何导入大Excel文件避免OOM?异步操作后,如何通知导入结果?如何加快导入效率?将导入结果通知给用户后,如何避免重复通知? 优化点完结撒花&…...

Linux练习——有关硬盘、联网、软件包的管理
1、将你的虚拟机的网卡模式设置为nat模式,给虚拟机网卡配置三个主机位分别为100、200、168的ip地址 #使用nmtui打开文本图形界面配置网络 [rootrhcsa0306 ~]# nmtui #使用命令激活名为 ens160 的 NetworkManager 网络连接 [rootrhcsa0306 ~]# nmcli c up ens160 #通…...

论文阅读:GS-Blur: A 3D Scene-Based Dataset for Realistic Image Deblurring
今天介绍一篇 2024 NeurIPS 的文章,是关于真实世界去模糊任务的数据集构建的工作,论文作者来自韩国首尔大学 Abstract 要训练去模糊网络,拥有一个包含成对模糊图像和清晰图像的合适数据集至关重要。现有的数据集收集模糊图像的方式主要有两…...

经典动态规划问题:爬楼梯的多种解法详解
引言 今天我们要解决一个经典的算法问题——爬楼梯问题。这个问题看似简单,但蕴含了多种解法,从递归到动态规划,再到组合数学,每种方法都有其独特的思路和优化方式。本文将详细讲解四种解法,并通过代码和图解帮助大家…...