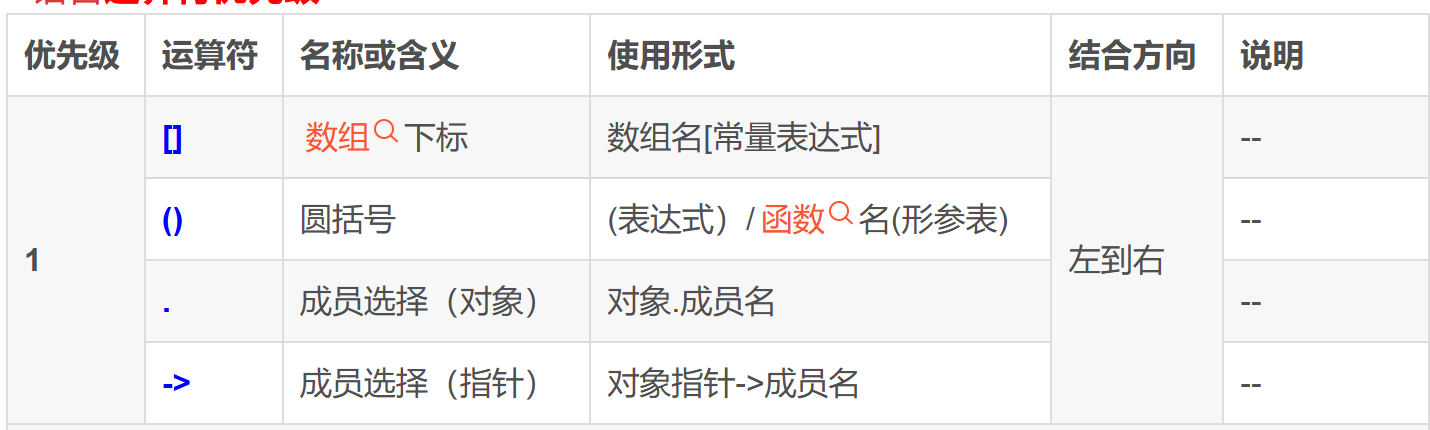
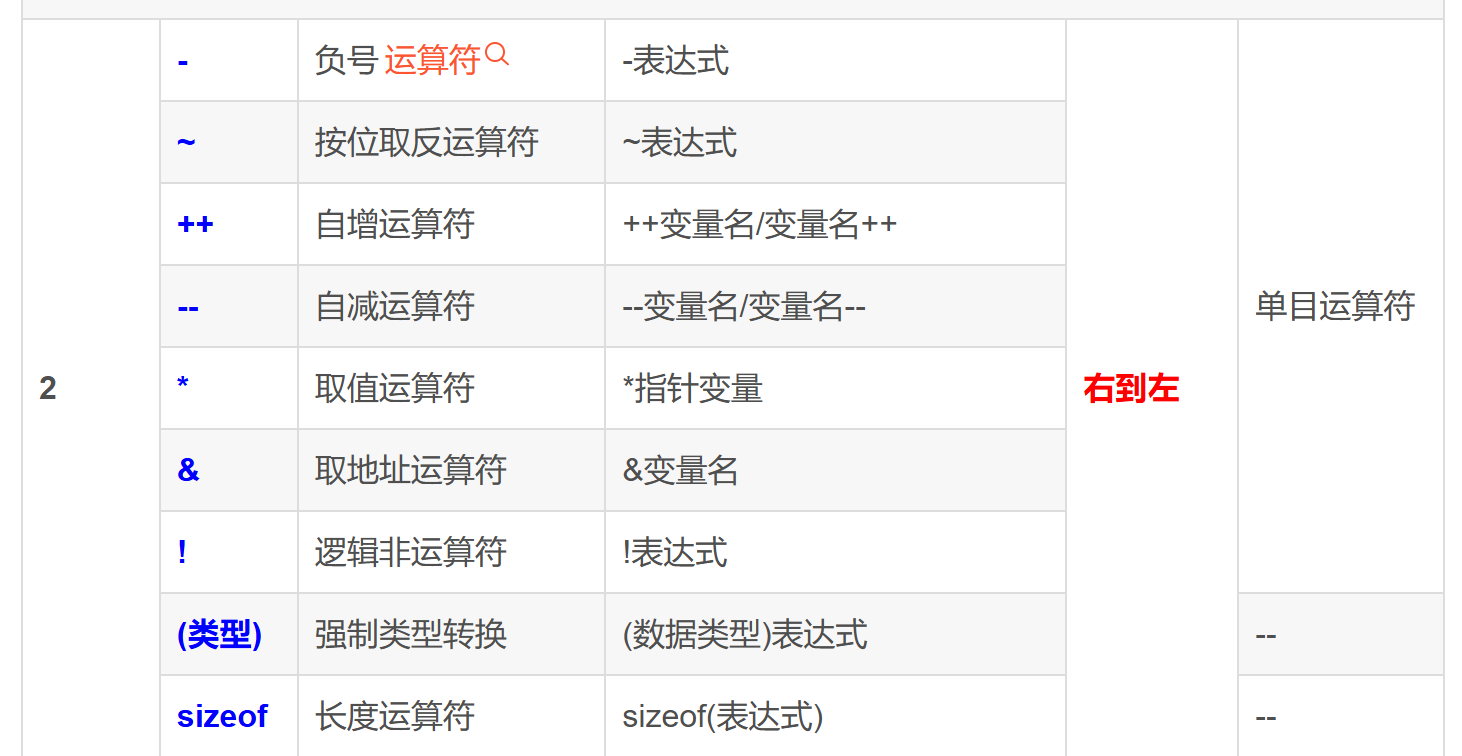
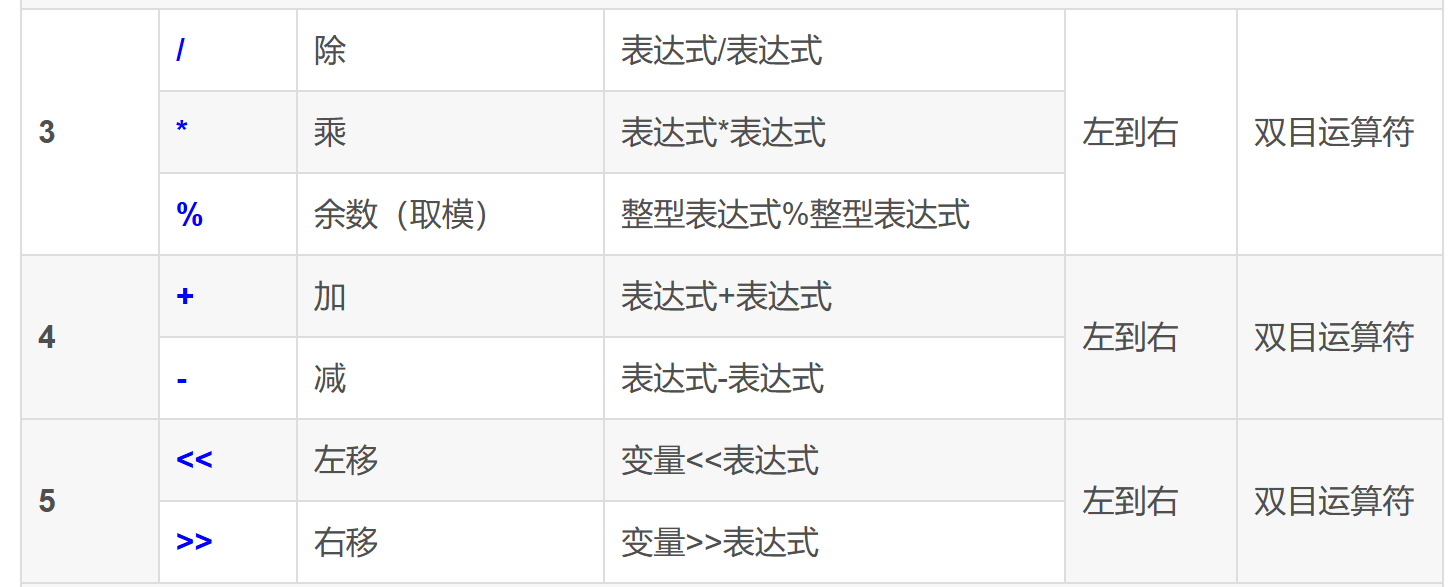
深入理解指针5
sizeof和strlen的对比
sizeof的功能
**sizeof是**** 操作符****,用来**** 计算****变量或类型或数组所占**** 内存空间大小****,**** 单位是字节,****他不管内存里是什么数据**int main()
{printf("%zd\n", sizeof(char));printf("%zd\n", sizeof(signed char));printf("%zd\n", sizeof(unsigned char));printf("%zd\n", sizeof(unsigned int));printf("%zd\n", sizeof(signed int));printf("%zd\n", sizeof(int));printf("%zd\n", sizeof(short));printf("%zd\n", sizeof(long));printf("%zd\n", sizeof(float));int a = 10;printf("%zd\n", sizeof a);int arr[] = { 1,2,3,4 };printf("%zd\n", sizeof arr); //sizeof如果是统计变量或数组大小,括号就可以省略,如果是统计类型大小,括号就不可以省略return 0;
}
分析:
1.i是一个整型变量,i+20后还是一个整型变量,int类型占4个字节,而short类型占2个字节,所以当你把一个int类型的值赋值给short类型,他肯定放不下,
放不下就会发生截断,但是不管s变量里面最终放的是什么,这个表达式其实是不会执行的,i也不会被重新赋值,编译器之关心s变量是什么类型,
2.当sizeof操作数为表达式的时候,是不会计算表达式的值,有也只是摆设,我们都知道一个.c的文件要执行,必须要变成.exe可执行文件才行
要经过编译和链接两个部分,在编译器编译的时候,计算大小的时候其实是根据类型计算的,就直接将sizeof(s=i+20),转换成sizeof(s),那s是short类型
在内存中占两个字节,
3.那为什么sizeof操作数为表达式的时候,就不计算表达式的值呢?
表达式是由操作数和操作符(运算符)组成的式子,能计算出一个值,比如a[3],[]是下标运算符,a是操作数,表示数组名,3也是一个操作数,是一个常量。
表达式有两个属性,一个是值属性,一个是类型属性,当表达式得不到结果的时候,sizeof就会计算他的类型
总结:
- sizeof是操作符计算的所占内存大小,单位是字节,不关心内存中存放什么数据
- sizeof操作符的操作数如果是表达式,不会计算表达式的值,编译器会转换成计算类型的大小
- 当sizeof计算变量或数组大小时,括号可以省略,但是计算类型的时候,大小不能省略
- sizeof的返回类型,是size_t类型,它对应的格式是%zd
strlen的功能
** strlen是函数,使⽤需要包含头⽂件 **`**int main()
{int str[] = { 1,2,3,4,5,6,7 };printf("%zd\n", strlen(str));//结果是1,为什么是1呢?调试观察内存窗口的时候会//1后面就是00,而00就是\0return 0;
}
int main()
{char arr[] = {'a','b','c','d','e'}; //字符数组存的都是字符,所以arr数组内存里没有\0,就会越界访问,一直遇到\0为止char arr2[] = "hello"; //字符数组里存的是字符串,字符串末尾有隐藏的\0printf("%zd\n", strlen(arr));printf("%zd\n", strlen(arr2));return 0;
}
总结:
- strlen是库函数,使用是需要包含头文件
**<font style="color:#117CEE;"><string.h></font>**,统计\0之前的字符串的长度,特别关心内存里有没有\0,因为只有遇到\0才会停止统计 - size_t strlen ( const char * str ), 他的返回类型也是size_t的类型,对应的格式也是%zd,他的参数是cha*类型的指针
数组和指针练习题
除了下面的两个例子外,你见到的任何数组名都是表示数组首元素的地址- sizeof(数组名)——数组名单独放在sizeof里表示计算的是整个数组的大小,而不是计算首元素地址的大小
- &数组名——表示取出整个数组的地址,
int main()
{int a[] = { 1,2,3,4 };printf("%zd\n", sizeof(a));//16,因为他取出的是整个数组的大小printf("%zd\n", sizeof(a + 0));//a并没有单独放在sizeof里,所以他表示的是数组名,数据名就是//首元素的地址,是地址,就是4或8个字节printf("%zd\n", sizeof(*a));//4,a并没有单独放在sizeof里,所以他表示的是数组名,//首元素的地址解引用得到的就是首元素1,*a=a[0]printf("%zd\n", sizeof(a + 1));//a并没有单独放在sizeof里,所以他表示的是数组名,地址+1//因为是整型数组,所以跳过一个字节,指针指向第二个元素的地址,还是地址,是地址就是4或8个字节printf("%zd\n", sizeof(a[1]));//a[1]表示第二个元素,计算第二个元素的大小,因为是int类型,所以是四个字节printf("%zd\n", sizeof(&a));//&a取出整个数组的地址,数组地址也是地址,是地址就是4或8个字节printf("%zd\n", sizeof(*&a));//这个题可以从两个角度分析,&a取地址,那么*&a就是将地址解引用,那他他们就抵消了,所以 sizeof(*&a)=sizeof(a),就是计算整整个数组的大小//另一个角度就是: &a取出来的是一个数组的地址,将数组的地址存放起来用数组指针,int(*p)[4]=&a, //声明了一个数组指针 p,它指向一个包含 4 个 int 类型元素的数组。&arr 是取数组 arr 的地址,将其赋值给 p,此时 p 指向了 arr 这个数组//对指针 p 解引用,即* p,根据指针解引用的原理,得到的是指针所指向的对象,在这里 p指向一个数组,所以* p就代表了这个数组,//它和直接使用数组名 arr 效果类似//sizeof 是一个操作符,它返回操作数在内存中占用的字节数。因为 *p 代表整个数组,那谁能代表整个数组呢,不就是数组名吗// 所以 sizeof(*ptr) 计算的就是这个包含 5 个 int 元素的数组在内存中所占的字节数。printf("%zd\n", sizeof(&a + 1));//&a得到是数组的地址,而数组的地址其实就是首元素的地址,而数组地址+1是跳过一个数组,//所以&a+1指向的其实是下一个数组的地址,但还是地址,是地址,就是4或者8个字节printf("%zd\n", sizeof(&a[0]));//他的意思是说取出首元素的地址,只要是地址就是4或者8个字节printf("%zd\n", sizeof(&a[0] + 1));//首元素的地址+1,指向第二个元素的地址,那不还是地址吗,是地址就是4或8个字节return 0;
}int main()
{int a[3][4] = { 0 };printf("%d\n", sizeof(a));//数组名a单独放在sizeof里,计算的是整个数组的大小,数组里一共有12个元素,每个元素的类型都是4个字节,所以是48个字节//结果是48printf("%d\n", sizeof(a[0][0]));//a[0][0]表示数组的第一行第一列个元素,也就是0,这个元素的类型是int类型,所以占4个字节printf("%d\n", sizeof(a[0]));//a[0]=*(a+0),那a是数组名,即二维数组首元素的地址,二维数组首元素是第一行,也就是第一行的地址,第一行的地址解引用得到是第一行的数组名//而数组名又表示数组首元素的地址,所以a[0]其实表示是第一行的数组名,数组名单独放在sizeof里,就不是代表数组首元素的地址了,而是计算//第一行数组的大小,第一行数组有4个元素,每一个元素都是int,一个int4个字节,所以是16个字节printf("%d\n", sizeof(a[0] + 1));//a[0]是第一行的数组名,数组名没有单独放在sizeof里,所以表示第一行数组首元素的地址,是int*类型,int*类型指针+1,跳过一个整型元素//所以a[0]+1表示第一行第二列的元素的地址,还是地址//是地址大小就是4或8个字节printf("%d\n", sizeof(*(a[0] + 1)));//a[0]+1表示的是第一行第二列元素的地址,那解引用后就得到第一行第二列这个元素,是int类型的,所以是4个字节//结果是4个字节printf("%d\n", sizeof(a + 1));//a是数组名,数组名没有单独放在sizeof里,所以表示的是第一行,也就是第一个一维数组的地址,a+1表示第二行的地址,是地址大小就是4或8个字节printf("%d\n", sizeof(*(a + 1)));//a+1是第二行的地址,是一个数组指针类型,数组指针解引用得到的就是的第二行的数组名,数组名单独放在sizeof里表示计算第二行数组的大小//他等同于sizeof(a[1]),因为*(a+1)=a[1]//结果是16字节printf("%d\n", sizeof(&a[0] + 1));//a[0]是第一行的数组名,数组名前面加上&,表示取出第一行数组的地址,数组地址+1跳过一个数组,所以&a[0] + 1表示第二行的地址//是地址大小就是4或8个字节,他的写法等价于a+1printf("%d\n", sizeof(*(&a[0] + 1)));//&a[0] + 1表示第二行的地址,然后解引用,一个数组指针解引用得到的是数组名,所以*(&a[0] + 1))表示的是第二行的数组名,即统计第二行数组元素//的大小,结果是16个字节,他的写法其实就等价于sizeof(a[1])printf("%d\n", sizeof(*a));//a在这里没有单独放在sizeof里,也没有加上&,就表示数组首元素的地址,也就是第一行的地址//第一行的地址解引用后,就得到第一行的数组名,数组名单独放在sizeof里,表示计算第一行数组元素的大小//结果是16个字节printf("%d\n", sizeof(a[3]));//a[3]表示第四行的数组名,数组名单独放在sizeof里,就是计算第四行数组元素的大小,但是这个数组只有3行,第4行属于越界访问了//但是对于sizeof来说,sizeof并不关心这个数组元素是不是真的存在,他只关心a[3]的数据类型,因为sizeof 是一个编译时操作符,它的作用是在编译阶段// 计算某个数据类型或者变量所占的内存字节数。它不会在运行时去访问实际的内存地址,只是根据数据类型的定义来进行计算。//从类型上来说,他和a[0],a[1],a[1]一样,都是包含4个int类型的元素的一维数组//结果是16个字节return 0;
}int main()
{char arr[] = { 'a','b','c','d','e' };printf("%d\n", sizeof(arr));//数组名单独放在sizeof里,表示计算整个数组的大小,一共有5个元素,每个元素是char类型,//结果是5个字节printf("%d\n", sizeof(arr + 0));//arr没有单独放在sizeof里,所以表示的数组一维数组首元素的地址,是地址大小就是4或8字节printf("%d\n", sizeof(*arr));//首元素的地址解引用就得到首元素,是一个char类型的,所以是1个字节printf("%d\n", sizeof(arr[1]));//arr+1表示第二个元素,数组元素类型都是相同的,char类型的,所以是1个字节printf("%d\n", sizeof(&arr));//数组名前加上地址表示取出数组的地址,是地址,大小就是4或8个字节printf("%d\n", sizeof(&arr + 1));//&arr+1,数组的地址+1,跳过一个数组,指向下一个数组的地址,还是地址,是地址大小就是4或8个字节printf("%d\n", sizeof(&arr[0] + 1));//取出第一个元素的地址,是char*类型的,+1,跳过一个字节,指向第二个元素的地址,是地址大小就是4或8个字节
return 0;
}
int main()
{char arr[] = { 'a','b','c','d','e'};printf("%zd\n", strlen(arr));//arr是数组首元素的地址,从首元素这个地址开始向后, 统计\0 之前字符串中字符的个数,一直找到\0为止,但是这个数组内存中//并没有存入\0,所以当把整个数组的字符都统计完了,还会往后继续统计,直到遇到\0,所以最后的结果是随机值printf("%zd\n", strlen(arr + 0));//首元素地址+0还是首元素地址,那么strlen统计的时候从首元素地址开始统计,和上面的一样,可能会存在越界查找//直到遇到\0,所以最终的打印结果还是随机值printf("%zd\n", strlen(*arr));//arr是数组首元素的地址,地址解引用后就得到首元素,所以得到字符a,字符a所对应的acsii码值是97,但是因为strlen的参数是一个//char *类型的指针,存放的是地址,所以他就会把97当成地址访问,但是97这个地址不是你随便想访问就能访问的,所以会报错,提示你非法访问printf("%zd\n", strlen(arr[1]));//arr[1]表示第二个字符,即b,而b的ASCII码值是98,同样的,会把98当成地址访问,最后会报错,提示非法访问printf("%zd\n", strlen(&arr));//&arr表示数组的地址,数组的地址是数组指针类型,也就是char (*p)[6],但是strlen函数的参数是char*类型的,所以编译器//就会把数组指针类型转换成char*类型的,但是值不发生变化,然后数组的地址其实是首元素的地址,从他开始统计的//时候,找到\0才结束,所以最后的结果也是随机值printf("%zd\n", strlen(&arr + 1));//&arr是数组的地址,数组地址+1,指向下一个数组的地址,就从下一个数组的首元素地址开始统计,直到遇到\0,所以最后也是随机值printf("%zd\n", strlen(&arr[0] + 1));//&arr[0]是首元素地址,首元素地址+1,指针指向第二个元素的地址,从第二个元素的地址开始往后统计,直到遇到\0//所以最后的结果也是一个随机值return 0;
}
int main()
{char arr[] = "abcedf"; //内存里有\0printf("%zd\n", strlen(arr));//结果是6,strlen函数统计\0之前的字符个数printf("%zd\n", strlen(arr + 0));//结果是6//printf("%zd\n", strlen(*arr));//*arr是字符a,strlen的参数是char*类型指针,a的ascii吗值是97,会把97当成一个地址,属于非法访问//printf("%zd\n", strlen(arr[1]));//得到的是字符b,字符b的ascii码值是98,同理他也会把98当成地址访问,属于非法访问printf("%zd\n", strlen(&arr));//取出数组的地址,从数组的地址也就是首元素的地址开始往后统计,直到遇到\0//结果是6printf("%zd\n", strlen(&arr + 1));//数组地址+1,指向下一个数组的地址,那从下一个数组的地址开始往后统计,你也不知道什么时候,会遇到\0//随机值printf("%zd\n", strlen(&arr[0] + 1));//取出第一个元素的地址,然后+1,指向第二个元素的地址,从第二个元素的地址开始往后统计,//结果是5return 0;
}
int main()
{char arr[] = "abcdef";//内存有\0printf("%zd字节\n", sizeof(arr));//数组名单独放在sizeof里,表示计算整个数组的大小,//结果是7个字节printf("%zd字节\n", sizeof(arr + 0));//注意这题,不是计算整个数组的大小,因为arr不是单独放在sizeof里,所以这里表示数组首元素的地址//arr+0还是arr,是地址,所以结果是4或8个字节printf("%zd字节\n", sizeof(*arr));//*arr表示首元素,也就是字符a,a是一个char类型,占一个字节//结果是1个字节printf("%zd字节\n", sizeof(arr[1]));//arr[1]表示字符b,b是一个char类型的,占1个字节printf("%zd字节\n", sizeof(&arr));//取出数组的地址,是地址,大小就是4或8个字节printf("%zd字节\n", sizeof(&arr + 1));//&arr+1表示下一个数组的地址,还是地址,是地址,大小就是4或8个字节printf("%zd字节\n", sizeof(&arr[0] + 1));//%arr[0]表示取出数组首元素的地址,+1,指向第二个元素的地址//是地址大小就是4或8个字节return 0;
}
int main()
{char* p = "abcdef"; //定义一个字符指针,指针指向的对象为字符,存放的其实是常量字符串字符a的地址printf("%d\n", sizeof(p)); //p是一个指针变量,指针变量就是用来存放地址的啊,那是地址就占内存4或8个字节,// 计算的是指针 p 本身所占用的内存大小printf("%d\n", sizeof(p + 1));//p是char*类型的指针,char*类型的指针+1,跳过一个字节,p存放的是a的地址,又因为数组在内存中是连续存放的//所以p+1指向b的地址,是地址,大小就是4或8个字节printf("%d\n", sizeof(*p));//p是存的a的地址,解引用,就得到字符a,字符a是char类型的,在内存中占一个字节//结果为1printf("%d\n", sizeof(p[0]));//p[0]=*(p+0),p存放a的地址,+0,没有变化,解引用就得到p指向的对象,也就是字符a//a是char类型,在内存中占1个字节printf("%d\n", sizeof(&p));//p是一个指针变量,是变量就要向内存申请空间,所以p也有自己的地址//&p取出来的就是p的地址,是地址大小就是4或8个字节,存放一级指针变量的地址,称为二级指针,printf("%d\n", sizeof(&p + 1));//结果是4或8个字节printf("%d\n", sizeof(&p[0] + 1));//&p[0]=&(*(p+0)),p存的是首元素的地址,首元素的地址解引用后得到字符a,&a,取出来的地址是char*类型// 因为是char*类型,所以指针+1跳过一个字节,指向b,还是char*类型的指针//是指针,也就是地址,大小就为4或8个字节return 0;
}
**<font style="color:#DF2A3F;">关于printf("%d\n", sizeof(&p + 1))这句代码的解析如下:</font>**
如果是p+1,因为p是一个char*类型的指针,所以p+1跳过一个字节
而对于&p+1,&p是char**类型。
在指针加减运算时,指针+n,移动的字节数其实是n*该指针指向的类型大小。
因为&p是char**类型,他所指向是char*,这里就涉及到之前学过的知识,指针变量的大小,不管你是什么指针,char*,char**,long*,指针变量的大小都是一样的,如果是32位的系统就是4个字节,如果是64位的就是8个字节
所以&p+1移动4个字节,&p+1仍然是一个char**类型的指针,既然 是指针,大小就是4或8个字节。
```c int main() { printf("%d\n", sizeof(char**)); printf("%d\n", sizeof(char*)); printf("%d\n", sizeof(char**)); printf("%d\n", sizeof(int**)); printf("%d\n", sizeof(int***)); printf("%d\n", sizeof(long*));
return 0;
}
```c
int main()
{char* p = "abcdef"; //定义字符指针p,存放的其实是字符a的地址printf("%d\n", strlen(p)); //strlen函数遇到\0才会停止//从字符a的地址开始往后统计,因为是abcdef是常量字符串,所以末尾会有隐藏的\0,//结果是6printf("%d\n", strlen(p + 1));//p是char*类型的指针,所以+1后跳过一个字符,1个字节,指向b,//从b的地址开始往后统计,直到遇到\0,结果是5/rintf("%d\n", strlen(*p));//p是字符a的地址,解引用后就得到字符a,字符a的ascii码值是97,但是因为strlen函数的参数是const char * str ,是一个char*类型的指针//所以他就会把97当成地址,但是这个地址不是你想访问就能访问的,属于非法访问printf("%d\n", strlen(p[0]));//p[0]等于*(p+0),也就是得到的还是字符a,同理还是会把97当成地址,属于非法访问printf("%d\n", strlen(&p));//&p,取出的是指针变量p的地址,从指针变量p的地址开始往后统计,你也不知道什么时候会遇到\0//随机值printf("%d\n", strlen(&p + 1));//&p取出来的是指针变量p在内存区域的起始地址,是一个char**类型的,+1后跳过4个字节,从&p+1这个地址开始往后统计,你也不知道什么//时候会遇到\0,所以打印的结果是一个随机值printf("%d\n", strlen(&p[0] + 1));//因为&p[0]得到的其实还是字符a的地址,是一个char*类型的,+1后跳过一个字节,指向字符b,从b的地址开始往后统计//结果是5//指针变量p自身的地址printf("指针变量 p 自身的内存地址(&p): %p\n", &p);//指针变量p中存储的地址,也就是字符'a'的地址printf("指针变量 p 中存储的地址(p): %p\n", p);//字符串首字符'a'的地址printf("字符串首字符 'a' 的地址: %p\n", (void*)&("abcdef"[0]));return 0;
}指针运算笔试题
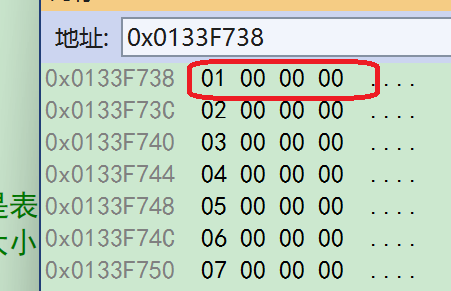
```c int main() { //结果是2和5 int a[5] = { 1, 2, 3, 4, 5 }; int* ptr = (int*)(&a + 1); //&a取出的是数组的地址,数组地址+1,跳过一个数组,得到的指针是数组指针类型,然后强制类型转换成int* //因为ptr是一个int*类型的指针,所以-1,跳过一个整型,4个字节,指向5,解引用就得到5 printf("%d,%d", *(a + 1), *(ptr - 1)); //a表示数组首元素地址,是int*类型的指针,+1后跳过一个整型,也就是4个字节,指向2,解引用就得到2 return 0; }
---```c
//在X86环境下
//假设结构体的⼤⼩是20个字节
//程序输出的结构是啥?
struct Test
{int Num;char* pcName;short sDate;char cha[2];short sBa[4];
}*p = (struct Test*)0x100000; //定义一个结构体类型的指针,指针指向的对象是结构体int main()
{printf("%p\n", p + 0x1); //0x开头表示十六进制,0x1就是1,所以这个式子就是p+1//那指针+1跳过多少个字节呢?因为p是一个结构体指针,所以p+1跳过了一个结构体,// 这里题目说了结构体是20个字节,所以p+1跳过了20个字节// p+1=0x100000+20,注意不能这样写,20是十进制,要转成十六进制,20对应的十六进制为14// 所以结果为0x100014printf("%p\n", (unsigned long)p + 0x1);//注意这题也有个坑,p不是指针类型了,他强制转换成了无符号整型,那这里p+1就是0x100001printf("%p\n", (unsigned int*)p + 0x1);//这里p是一个无符号整型指针,无符号整型是4个字节,所以p+1跳过4个字节//所以结果是0x100004return 0;
}
//下面的代码要改成x64的环境才能运行
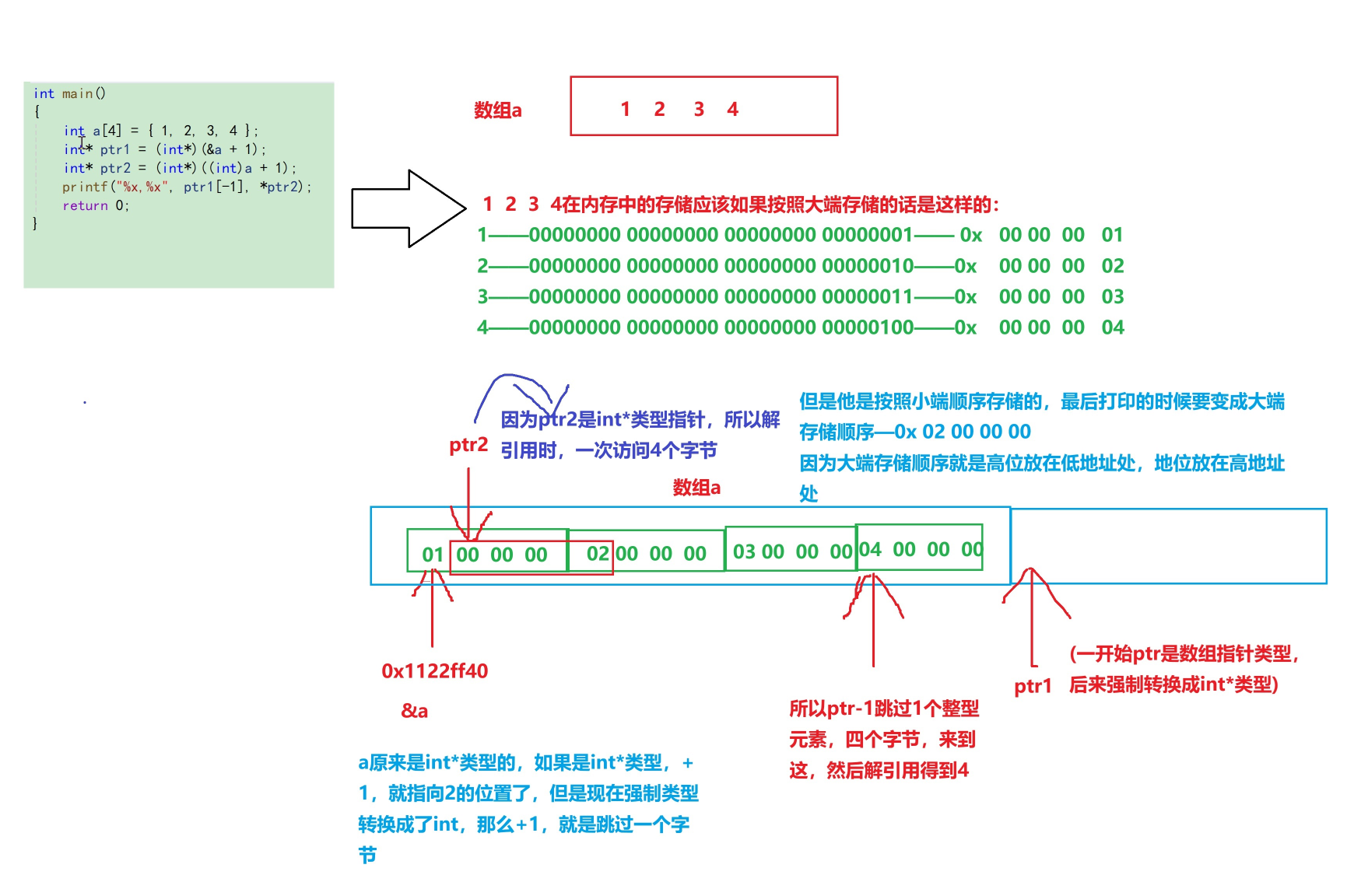
int main()
{int a[4] = { 1, 2, 3, 4 };int* ptr1 = (int*)(&a + 1);//&a取出数组的地址,然后+1,跳过一个数组,指针指向下一个数组的地址,数组地址是数组指针类型,但是把他强制类型转换成了int*,ptr1是一个int*类型指针//那么ptr-1,就是跳过一个整型元素,指向元素为4的地址,然后解引用,得到的是4//ptr[-1]其实就等于*(ptr+(-1)),也就是 * (ptr-1),十进制4转成十六进制4还是4int* ptr2 = (int*)((int)a + 1);//只有指针才讨论是跳过一个字节还是4个字节,整型数据+1就是+1//a表示数组首元素地址,是int*类型,但是强制类型转换成了int,如果是int*类型,那加1是跳过4个字节,但是现在强制类型转化//int* ptr2 = (int*)((long long )a + 1);//这样写就可以在x64的环境下运行,因为long long是8个字节printf("%x,%x", ptr1[-1], *ptr2);//%X表示以十六进制形式打印//打印结果是4 和 2000000return 0;
}
问题出在int* ptr2 = (int*)((int)a + 1)这个代码中,因为是x64的环境,指针变量的大小为8个字节,
假设a的地址是0x1122334455667788,把他强制类型转化int,因为int是四个字节,所以就会发生截断,
截断后就变成了:0x 55667788,那这个地址就不对了,那这个地址+1就不知道是谁的空间了,属于非法访问
非要强制类型转换就转换成long long这个类型,因为long long是8个字节
注意!不要被这题的陷阱迷惑了,他是用的圆括号,而不是花括号,这是一个逗号表达式,
逗号表达式按照从左到右的顺序依次计算,整个表达式的值是最后一个表达式的值。
int main()
{int a[3][2] = { (0, 1), (2, 3), (4, 5) };//他其实是这样的:int a[3][2] = { 1, 3, 5 };//第一行:1,3//第二行:5,0//第三行:0,0int* p;p = a[0];//a[0]是第一行的数组名,他会隐式转换成第一行首元素的地址,printf("%d", p[0]);//p[0] = *(p+0),第一行首元素地址解引用就得到1,也就是第一行第一个元素return 0;
}
逗号表达式就是由逗号运算符将多个子表达式连接,这题的(0, 1)中0和1都是常量,常量也是一种表达式
按照从左到右的顺序依次计算这些子表达式,最终整个逗号表达式的值是最后一个子表达式的值。
```c 逗号表达式会依次计算每个子表达式,并且最终会返回最后一个子表达式的值。这个值可以被赋值给其他变量或者用于其他表达式的计算。 变量定义语句中的逗号并不涉及求值后返回结果的操作。它只是告知编译器为多个变量分配内存并初始化。每个变量初始化后的值会分别存储在对应的变量内存空间中, 不存在一个统一的 “表达式结果”变量定义语句中的逗号不是运算符,不存在优先级和结合性的概念。它只是语法规定的分隔符,用于区分不同变量的定义。
逗号表达式中的逗号是运算符,它的优先级是所有运算符中最低的。结合性是从左到右,也就是按照从左到右的顺序依次计算各个子表达式。
所以在使用逗号表达式时,通常需要用括号来明确运算顺序,避免因优先级问题导致意外结果。
int main()
{
int a = 1, b = 2, c = 3;//变量定义语句中的逗号不属于逗号表达式,这里的逗号的作用是定义多个同类型的变量int x = 1, y = 2;
int z = x + 1, y + 2; // 这里由于逗号运算符优先级低,会先计算 x + 1 并赋值给 z,y + 2 不会影响结果
int z = (x + 1, y + 2); // 这里使用括号明确是逗号表达式,z 的值为 y + 2 的结果int a = 1, b = 2, c = 3;
int result;
result = (a = a + 1, b = b + 2, c = c + 3);//result 被赋值为逗号表达式最后一个子表达式 c = c + 3 的值,程序输出时会显示 result 等于更新后 c 的值。
printf("a = %d, b = %d, c = %d, result = %d\n", a, b, c, result);
return 0;
}
---```cint main()
{int a[5][5];//定义一个二维数组,该数组有5行5列int(*p)[4];//定义一个指针p,该指针指向1个包含4个int类型一维数组p = a;//将二维数组首元素的地址,也就是第一行的地址赋值给p,虽然a和p都是地址//但是他们的类型是不同的,a是一个指向5个int类型元素的一维数组指针,int(*)[5]//而p是一个指向4个int类型元素的一维数组指针,int(*)[4]printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);////%p:用于以十六进制的形式输出指针的值,这里输出的是 -4 的十六进制表示。// 在大多数系统中,int 类型是 32 位的,-4 的补码表示为 0xFFFFFFFC。return 0;
}
&p[4][2]:
由于p是一个指向包含4个int类型的元素的一维数组指针,所以p[4]会让指针p向后移动4个包含4个int元素的一维数组的距离,可以把p[4]理解成*(p+4),a[4]=*(a+4),a[4]会让指针a向后移动4个包含5个int元素的一维数组的距离
指针减指针的结果是两个指针之间相差的元素的个数,这里&p[4][2]-&a[4][2]得到的是负数,因为&p[4][2]的地址靠前,要小一些,
最终的打印结果为-4,-4是他的原码的十进制形式,他存储在内存中是要以补码的形式
-4原码:10000000000000000000000000000100
-4反码:11111111111111111111111111111011
-4补码:1111 1111 1111 1111 1111 1111 1111 1110
地址:fffffffc(4个1为一个f)
如果是要打印地址的话,不用转成原码,直接打印补码,因为地址是16进制,所以要将二进制的补码转成十六进制
int main()
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int* ptr1 = (int*)(&aa + 1);//&aa得到是数组的地址,数组地址+1,跳过一个数组int* ptr2 = (int*)(*(aa + 1));//aa+1得到是第二行的地址,行地址解引用得到的是该行首元素的地址printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));//打印结果为10,5//ptr1和ptr2都是int*类型的指针,减1时,就跳过一个整形元素return 0;
}
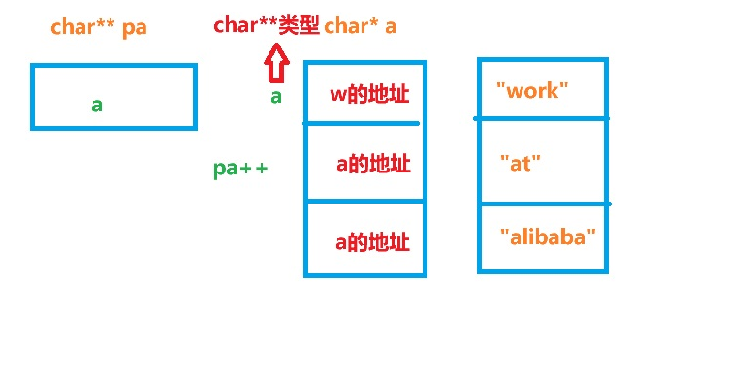
int main()
{char* a[] = { "work","at","alibaba" };//定义一个字符指针数组//下标为0的元素存放的是常量字符串"work"中'w'的地址//下标为1的元素存放的是'a'的地址串"at"中'a'的地址//下标为2的元素存放的是'a'的地址串"alibaba"中'a'的地址char** pa = a;//a表示数组首元素的地址,是char**类型pa++;printf("%s\n", *pa);//pa++后,然后解引用得到的是at"中'a'的地址//打印结果为atreturn 0;
}
int main()
{char* c[] = { "ENTER","NEW","POINT","FIRST" };//定义了一个字符指针数组//分别存放字符'E','N','p','F'的地址char** cp[] = { c + 3,c + 2,c + 1,c };char*** cpp = cp;printf("%s\n", **++cpp); //打印"POINT"printf("%s\n", *-- * ++cpp + 3); //打印"ER"//++和--和*的优先级是相同的,都是右结合,从右往左,他们的优先级都高于+号//在优先级相同的时候,运算顺序由结合方向决定,//第一步:++cpp 第二步:* ++cpp 第三步:-- * ++cpp 第四步:*-- * ++cpp 第五步:+3printf("%s\n", *cpp[-2] + 3); //打印"ST"//[]的优先级高于*,先执行cpp[-2],然后再解引用//cpp[-2]=*(cpp-2)//*cpp[-2] + 3 =*( *(cpp-2)) + 3printf("%s\n", cpp[-1][-1] + 1); //打印"EW"//cpp[-1][-1]其实就等于*(*(cpp-1)-1)//cpp-1后,然后解引用,拿到的是c+2这个地址,c+2这个地址再减1,得到的是c+1这个地址,c+1这个地址解引用,得到的是N的地址,然后再+1,得到的是E的地址return 0;
}
上面这个题产生的疑问以及解答:
1.cp是数组名,那不是数组首元素的地址吗,那cpp+1后,cp指向的地址会不会发生改变吗?因为cpp不是等于cp吗
解答:
cp是一个数组,类型为char [4],即包含4个char类型元素的数组。在c语言里,数组名表示首元素的地址,他是一个常量地址,在程序运行期间
是不能被修改的,cp所指向的地址不会因为其他指针的操作而改变
- char ** 类型的指针执行 +1 操作时,指针会在内存中向后移动一个 char * 类型对象,对吗?
解答:
是的。指针运算和指针所指向的类型有关,在C语言中,指针加上一个整数时,实际移动的字节数是n * sizeof(指针所指向的类型)
相关文章:
深入理解指针5
sizeof和strlen的对比 sizeof的功能 **sizeof是**** 操作符****,用来**** 计算****变量或类型或数组所占**** 内存空间大小****,**** 单位是字节,****他不管内存里是什么数据** int main() {printf("%zd\n", sizeof(char));p…...

一文详解QT环境搭建:Windows使用CLion配置QT开发环境
在当今的软件开发领域,跨平台应用的需求日益增长,Qt作为一款流行的C图形用户界面库,因其强大的功能和易用性而备受开发者青睐。与此同时,CLion作为一款专为C/C打造的强大IDE,提供了丰富的特性和高效的编码体验。本文将…...

NE 综合实验3:基于 IP 配置、链路聚合、VLAN 管理、路由协议及安全认证的企业网络互联与外网访问技术实现(H3C)
综合实验3 实验拓扑 设备名称接口IP地址R1Ser_1/0与Ser_2/0做捆绑MP202.100.1.1/24G0/0202.100.2.1/24R2Ser_1/0与Ser_2/0做捆绑MP202.100.1.2/24G0/0172.16.2.1/24G0/1172.16.1.1/24G0/2172.16.5.1/24R3G5/0202.100.2.2/24G0/0172.16.2.2/24G0/1172.16.3.1/24G0/2172.16.7.1/…...
:机器学习中的“真相”基准)
Ground Truth(真实标注数据):机器学习中的“真相”基准
Ground Truth:机器学习中的“真相”基准 文章目录 Ground Truth:机器学习中的“真相”基准引言什么是Ground Truth?Ground Truth的重要性1. 模型训练的基础2. 模型评估的标准3. 模型改进的指导 获取Ground Truth的方法1. 人工标注2. 众包标注…...

双重token自动续期解决方案
Token自动续期实现方案详解 Token自动续期是提升用户体验和保障系统安全的关键机制,其核心在于无感刷新和安全可控。以下从原理、实现方案、安全措施和最佳实践四个维度展开说明: 一、核心原理:双Token机制 Token自动续期通常采用 Access …...

我与数学建模之启程
下面的时间线就是从我的大二上开始 9月开学就迎来了本科阶段最重要的数学建模竞赛——国赛,这个比赛一般是在9月的第二周开始。 2021年国赛是我第一次参加国赛,在报名前我还在纠结队友,后来经学长推荐找了另外两个学长。其实第一次国赛没啥…...
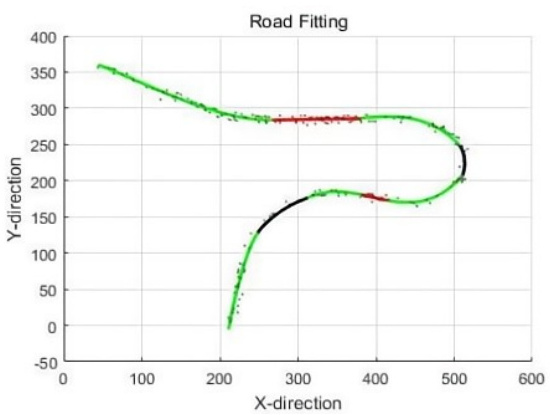
多段圆弧拟合离散点实现切线连续
使用多段圆弧来拟合一个由离散点组成的曲线,并且保证切线连续。也就是说,生成的每一段圆弧之间在连接点处必须有一阶导数连续,也就是切线方向相同。 点集分割 确保每个段的终点是下一段的起点,相邻段共享连接点,避免连接点位于数…...

烧结银:解锁金刚石超强散热潜力
烧结银:解锁金刚石超强散热潜力 在材料科学与热管理领域,金刚石凭借超高的热导率,被誉为 “散热之王”,然而,受限于其特殊的性质,金刚石在实际应用中难以充分发挥散热优势。而烧结银AS9335的出现&#x…...

【蓝桥杯】第十四届C++B组省赛
⭐️个人主页:小羊 ⭐️所属专栏:蓝桥杯 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 试题A:日期统计试题B:01串的熵试题C:冶炼金属试题D:飞机降落试题E:接…...

企业级海外网络专线行业应用案例及服务商推荐
在全球化业务快速发展的今天,传统网络技术已难以满足企业需求。越来越多企业开始选择新型海外专线解决方案,其中基于SD-WAN技术的企业级海外网络专线备受关注。这类服务不仅能保障跨国数据传输,还能根据业务需求灵活调整网络配置。接下来我们…...

阿里云服务器安装docker以及mysql数据库
(1) 官方下载路径 官方下载地址: Index of linux/static/stable/x86_64/阿里云镜像地址: https://mirrors.aliyun.com/docker-ce/下载最新的 Docker 二进制文件:wget https://download.docker.com/linux/static/stable/x86_64/docker-20.10.23.tgz登录到阿里云服务…...
)
力扣经典算法篇-5-多数元素(哈希统计,排序,摩尔投票法)
题干: 给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 1: 输入:nums [3,2,3] 输出&…...

axios介绍以及配置
Axios 是一个基于 Promise 的 HTTP 客户端,用于浏览器和 Node.js 环境中进行 HTTP 请求。 一、特点与基本用法 1.特点 浏览器兼容性好:能在多种现代浏览器中使用,包括 Chrome、Firefox、Safari 等。支持 Promise API:基于 Prom…...

深入解析:HarmonyOS Design设计语言的核心理念
深入解析:HarmonyOS Design设计语言的核心理念 在当今数字化迅速发展的时代,用户对操作系统的体验要求越来越高。华为的HarmonyOS(鸿蒙操作系统)应运而生,旨在为用户提供全场景、全设备的智慧体验。其背后的设计语言—…...

大数据技术之Scala:特性、应用与生态系统
摘要 Scala 作为一门融合面向对象编程与函数式编程范式的编程语言,在大数据领域展现出独特优势。本文深入探讨 Scala 的核心特性,如函数式编程特性、类型系统以及与 Java 的兼容性等。同时,阐述其在大数据处理框架(如 Apache Spa…...
:竞价指标剖析与流量对接要点)
程序化广告行业(47/89):竞价指标剖析与流量对接要点
程序化广告行业(47/89):竞价指标剖析与流量对接要点 大家好!一直以来,我都希望能和大家一同深入探索程序化广告行业的奥秘,这也是我持续撰写这一系列博客的动力。今天,咱们接着来剖析程序化广告…...

dfs记忆化搜索刷题 + 总结
文章目录 记忆化搜索 vs 动态规划斐波那契数题解代码 不同路径题解代码 最长递增子序列题解代码 猜数字大小II题解代码 矩阵中的最长递增路径题解代码 总结 记忆化搜索 vs 动态规划 1. 记忆化搜索:有完全相同的问题/数据保存起来,带有备忘录的递归 2.记忆…...

vue2 全局封装axios统一管理api
在vue项目中,经常会使用到axios来与后台进行数据交互,axios丰富的api满足我们基本的需求。但是对于项目而言,每次都需要对异常进行捕获或者处理的话,代码会很繁重冗余。我们需要将其公共部分封装起来,比如异常处理&…...

大模型有哪些算法
大模型(Large-scale Models)通常指参数量大、架构复杂、在特定任务或领域表现出色的深度学习模型。这些模型的算法核心往往基于Transformer 架构及其变体,同时结合了大规模数据、硬件加速和优化技巧。以下是当前主流大模型及其核心算法的分类…...

【Linux】进程的详讲(中上)
目录 📖1.什么是进程? 📖2.自己写一个进程 📖3.操作系统与内存的关系 📖4.PCB(操作系统对进程的管理) 📖5.真正进程的组成 📖6.形成进程的过程 📖7、Linux环境下的进程知识 7.1 task_s…...

Python Cookbook-4.17 字典的并集与交集
任务 给定两个字典,需要找到两个字典都包含的键(交集),或者同时属于两个字典的键(并集)。 解决方案 有时,尤其是在Python2.3中,你会发现对字典的使用完全是对集合的一种具体化的体现。在这个要求中,只需要考虑键&am…...
优选算法的巧思之径:模拟专题
专栏:算法的魔法世界 个人主页:手握风云 目录 一、模拟 二、例题讲解 2.1. 替换所有的问号 2.2. 提莫攻击 2.3. Z字形变换 2.4. 外观数列 2.5. 数青蛙 一、模拟 模拟算法说简单点就是照葫芦画瓢,现在草稿纸上模拟一遍算法过程…...

【云服务器】在Linux CentOS 7上快速搭建我的世界 Minecraft 服务器搭建,并实现远程联机,详细教程
【云服务器】在Linux CentOS 7上快速搭建我的世界 Minecraft 服务器搭建,详细详细教程 一、 服务器介绍二、下载 Minecraft 服务端三、安装 JDK 21四、搭建服务器五、本地测试连接六、添加服务,并设置开机自启动 前言: 推荐使用云服务器部署&…...

文本分析(非结构化数据挖掘)——特征词选择(基于TF-IDF权值)
TF-IDF是一种用于信息检索和文本挖掘的常用加权算法,用于评估一个词在文档或语料库中的重要程度。它结合了词频(TF)和逆文档频率(IDF)两个指标,能够有效过滤掉常见词(如“的”、“是”等&#x…...

【JavaSE】小练习 —— 图书管理系统
【JavaSE】JavaSE小练习 —— 图书管理系统 一、系统功能二、涉及的知识点三、业务逻辑四、代码实现4.1 book 包4.2 user 包4.3 Main 类4.4 完善管理员菜单和普通用户菜单4.5 接着4.4的管理员菜单和普通用户菜单,进行操作选择(1查找图书、2借阅图书.....…...

命令模式介绍及应用案例
命令模式介绍 命令模式(Command Pattern) 是一种行为设计模式,它将请求封装为一个对象,从而使你可以用不同的请求对客户进行参数化,并且支持请求的排队、记录日志、撤销操作等功能。命令模式的核心思想是将“请求”封…...

多线程(多线程案例)(续~)
目录 一、单例模式 1. 饿汉模式 2. 懒汉模式 二、阻塞队列 1. 阻塞队列是什么 2. 生产者消费者模型 3. 标准库中的阻塞队列 4. 自实现阻塞队列 三、定时器 1. 定时器是什么 2. 标准库中的定时器 欢迎观看我滴上一篇关于 多线程的博客呀,直达地址…...

python笔记之函数
函数初探 python在要写出函数很简单,通过关键字def即可写出,简单示例如下 def add(a, b):return ab 以上即可以定义出一个简单的函数:接收两个变量a和b,返回a和b相加的结果,当然这么说也不全对,原因就是…...

合合信息大模型加速器2.0实测:当AI开始“读心术“与“考古“
凌晨三点的编辑部,我盯着屏幕上密密麻麻的财务报表和如天书般的专利图纸,感觉咖啡因正在大脑中上演"黑凤凰"式崩溃。这时,合合信息的AI助手突然开口:"您需要的是自动关联32个数据表,还是让模型直接生成…...

一个判断A股交易状态的python脚本
最近在做股票数据相关的项目,需要用到判断某一天某个时刻A股的状态,比如休市,收盘,交易中等,发动脑筋想了一下,这个其实还是比较简单的,这里我把实现方法分享给大家。 思路 当天是否休市 对于某…...