DataPlatter:利用最少成本数据提升机器人操控的泛化能力
25年3月来自中科院计算所的论文“DataPlatter: Boosting Robotic Manipulation Generalization with Minimal Costly Data”。
视觉-语言-动作 (VLA) 模型在具身人工智能中的应用日益广泛,这加剧对多样化操作演示的需求。然而,数据收集的高成本往往导致所有场景的数据覆盖不足,从而限制模型的性能。大型工作空间中的空间推理阶段 (SRP) 占主导地位,导致失败的情况居多。幸运的是,这些数据可以以低成本收集,凸显利用廉价数据来提高模型性能的潜力。本文介绍 DataPlatter 方法,这是一种将训练轨迹分解为不同任务阶段的框架,并利用大量易于收集的 SRP 数据来增强 VLA 模型的泛化能力。通过分析,使用适当比例的额外 SRP 数据进行子任务特定训练可以作为机器人操作的性能催化剂,最大限度地利用昂贵的物理交互阶段 (PIP) 数据。
随着多模态大语言模型 (MLLM) 的理解和推理能力快速发展,它们在现实世界交互中的应用,即具身人工智能 (EAI),已成为研究的焦点 [4, 14, 27],而利用视觉-语言-动作 (VLA) 模型的方法是一种常见的选择 [5, 16, 47, 53]。与 MLLM 类似,训练 VLA 的空间理解和物理交互推理能力,需要大量跨各种任务的演示轨迹。尽管人们付出了大量的努力和高昂的成本来收集机器人演示,无论是在模拟 [10, 11, 30] 中还是在现实世界 [3, 35, 41] 中,但将特定智体的轨迹泛化到新智体配置仍然是一个关键挑战。因此,特定智体可用的训练数据仍然有限,远远不足以涵盖多样化的现实场景,从而限制 VLA 模型能力的提升。
为了解决这个问题,提高数据利用效率,研究人员正致力于探索跨智体训练 [6, 23, 35, 44, 47]、空间认知增强 [12, 25, 51] 和通过思维链进行任务逻辑提取 [38]。值得注意的是,最近的研究 [24, 41] 证明了一种规模化定律,它控制着操作工作空间的空间体积、训练数据的数量和 VLA 模型的泛化性能之间的关系。所有这些方法都有一个共同的前提:理解具身任务的组合性质。
大部分任务处理过程一般可以分为两个阶段:空间推理阶段(SRP)和物理交互阶段(PIP),如图所示。前一个阶段与目标无关,因为智体会探索广阔的工作空间,而不需要与目标进行任何密切交互,比如在操作前接近目标,这使得数据收集相对简单。相比之下,在后期阶段,需要根据物理定律对目标采取精确的动作,并预见到物体的反应,这对于人类或算法专家来说都是极其耗费人力的。这引发了一个核心问题:廉价的 SRP 数据能否放大稀缺的 PIP 数据的价值,从而减少数据收集所需的工作量?

目前,大多数 EAI 模型仅限于执行它们在训练期间明确遇到的任务。例如,即使一个模型被训练来捡起瓶子,它也不能将其泛化到捡起可乐罐。虽然这个问题已经通过从早期的域随机化 [13]、元学习 [8] 和数据增强 [17] 到最近在世界模型构建 [5, 27] 和空间推理 [12, 25] 方面的进展进行研究,但对分布外 (OOD) 新目标的泛化性能仍然显示出有限的提升。[5, 53] 尝试将使用互联网规模数据训练的大模型中世界知识迁移到机器人动作推理中,但来自“练习”的 OOD 目标操作经验无法从“阅读”中有效获得,而 [27, 38, 38] 则试图直接使用通用能力来指导智体的动作逻辑。 [12, 25, 51] 致力于通过理解工作空间中的空间信息来提高动作性能。Zhu [52] 通过文本-图像对将目标知识迁移到相似的物体上,但在推理过程中仍然需要辅助信息才能获得更好的性能。
本文提出一种端到端的训练方法,可以大幅度提高 OOD 目标的泛化性能。本文关键见解源于两个关键的观察结果:(1)与 PIP 相比,SRP 所需的空间理解能力表现出更高的环境可变性,因为对特定目标的操作阶段相对固定,与周围场景的关联性较小; (2) 神经网络在不同任务阶段表现出不同的注意模式,例如在 SRP 中关注目标的位置和空间占有以避免碰撞,而在 PIP 中则转移到目标占比。这些发现表明,针对子任务的训练策略可以更好地与模型的学习特性相匹配,在子任务中使用这些数据段的不同占比。
Tan [41] 和本文实验(见下表 SRP 阶段对模型性能的影响)都表明,较小的工作空间可以显著提高操作任务的成功率。这表明将操作阶段与不同的注意中心解耦,可以提高泛化性能。此外,子任务难度的这种变化,可能导致模型在更简单的小工作空间阶段过拟合,而在大工作空间阶段欠拟合,这需要每个阶段使用不同的数据量。

本文提出 DataPlatter 方法,将训练数据从不同的操作阶段中分离出来,构建一个隐式的子任务特定训练程序,并利用大量易于收集的 SRP 数据来训练此阶段,以提高 VLA 模型的性能。
如图所示,DataPlatter 根据智体与环境中物体的交互程度将机器人操作轨迹分为空间推理阶段和物理交互阶段。通过采用适当比例的两阶段数据混合,目标是实现与使用完整数据进行模型训练相当的泛化性能。这种方法有效地减少对昂贵的 PIP 数据依赖。

重点关注利用行为克隆的 VLA 模型,这是 IL 方法的一类。考虑一个机器人操作轨迹数据集 D^F = {τ_i^F},其中每个全阶段轨迹 τ_i^F = {l^i, o_1^i, a_1^i, o_2^i, · · · , a_T-1^i, o_T^i} 由任务的语言指令 l、智体在每个时间步 t 的观察 o_t^i 以及智体采取的动作 a_t^i 组成。具有参数 θ 的 VLA 模型 Ψ_θ 将任务指令和一段长度为 L 的观察历史 O_t,Li = {o_t−L+1, · · · , o_t} 作为输入,并预测智体在过去 L 个时间步和接下来的 H 个时间步中应执行的如下动作块以完成任务 A_t,L,H^i = {a_t−L+1 , · · · , a_t+H }。
通常,像 CLIP [36] 这样的视觉编码器使用图像-文本对进行预训练,以提供对齐的视觉-纹理语义,从而促进与 LLM 的无缝集成,并且通常在训练 VLA 模型期间保持冻结状态。GPT [1] 或 LLaMA [32] 等 LLM 因其强大的通用推理能力而成为模型的核心,并且通常使用适配器 [20, 26] 来集成多模态输入tokens。动作解码器通常由几个轻量级神经网络层组成,这些神经网络层解释 LLM 输出的动作 token 块并将其转换为具有物理意义的动作,例如末端执行器的 6-DoF 姿势。
模型优化的目标是尽量减少预测动作序列和演示动作序列之间的差异。
为了利用数据集中不同子任务的轨迹,首先根据末端执行器 G 和目标物体 T 之间的距离以及目标在腕部相机 C_w 中的可见性,将给定的全阶段轨迹 τ_i 分割为 SRP 和 PIP。假设场景中有一个腕部相机和一个静态相机,这是大多数数据集中的常见配置。更正式地说,对于位置 p_T 处的目标物体 T、位置 p_G 处的末端执行器 G 和在 OpenCV 框架下定义的姿势 P_C = (p_C,R_C) 处腕式摄像机 C_w,如果满足以下条件,则 PIP 开始:

一旦完成富有交互的操作阶段,PIP 就会停止,例如在拾取和放置任务中抓取目标或在开关操作任务中触发按钮之后。除 PIP 之外,轨迹的其余部分被称为 SRP。按照这样的程序,轨迹可以分为几个段 τ_iF = { τ_i,1SRP, τ_i,1PIP, τ_i,2SRP, ···}。相应地,数据集可以分为两个子数据集:DF = DSRP ∪ DPIP ,其中 DSRP = {τ_i,jSRP} 包含轨迹中的所有 SRP 段,DPIP = {τ_i,jPIP} 包含操作段。注:目标是使用大量易于收集的 SRP 数据(而不是昂贵的 PIP 数据)来训练 VLA 模型,因此在实践中,可以将独立收集的 SRP 数据集 D_ind^SRP 纳入训练中。
在 VLA 模型的训练阶段之前,分别在 D 和 D_indSRP 中采样 N_1 和 N_2 个段,并构建一个新的数据集 D^Mix 来训练模型,本文称其为 DataPlatter,即

在实践中,为了达到最佳模型能力,通常使用整个全阶段轨迹数据集 DF,即 N_1 = |DF|,并选择适当的 N_2 来提高在新场景上的泛化性能。通过这种方法,构建一个隐式的子目标特定训练,子任务数据集 DPIP 和 DSRP ∪ D_ind^SRP,提供一种灵活的方式来控制每个子任务的性能。通过改变两个子数据集之间的数据比例,可以观察任务成功率相对于 SRP 数据量的变化趋势,由此可以得出在保持 VLA 模型性能的同时节省 PIP 数据的原则。
本文使用 RoboMM [47] 作为基线,这是一个多模态 VLA 模型,利用 UVFormer [25] 以低成本的方式通过带有相机参数的 RGB 图像帮助实现空间感知。在训练过程中,将语言指令和来自静态相机和腕式相机的 RGB 图像以及它们的内和外参输入模型,并使用带有动作块的深度图像作为监督。
在 Isaac-Sim 的模拟环境中,生成一个涉及各种类别和几何形状目标物体的“物体拾取”任务数据集。对于仅 SRP 轨迹,为了在现实世界的机器人中提供可实现的管道,没有直接从模拟中读取物体信息,而是应用前面提供的检测采样方法。
数据集是在 IsaacSim 的模拟环境中收集的,该环境使用与Zheng [50] 类似的算法自动收集。每个场景都用 4 到 6 个物体随机放置在桌子上进行初始化,包括位置和方向。配备两指夹持器的 Franka-Panda 7-DoF 机械臂以随机末端执行器姿势初始化。放置在桌子前面的静态摄像机以及安装在夹持器上的腕式摄像机用于捕捉场景的 RGB 和深度观察。在收集过程中,从桌子上的物体中抽取一个目标并指定为目标,并使用预定义模板生成语言指令。在每个步骤中,都会记录夹持器的姿势、算法生成的动作目标、机器人关节信息、夹持器状态、来自摄像机的图像、任务指令以及场景中所有物体的状态信息,以供训练和重现。在生成相机图像和评估时使用光线追踪渲染器。在实验中使用的目标物体如图所示。

对于全阶段轨迹,首先在目标上采样无碰撞抓取标签,使用 Fang [7] 的方法,采用物体的碰撞模型对其进行密集标记。然后,智体使用 CuRobo [39] 执行 6-DoF 路径规划并执行生成的路径。对于仅涉及 SRP 阶段的轨迹,为了在现实世界的机器人中提供可实现的管道,没有直接从模拟器中读取目标信息。实际上,首先从静态摄像机捕获的 RGB 图像中定位目标,然后将其输入到 CNN 以检测目标边框。利用边框可以从深度图像中获取目标的平均深度,并使用摄像机的内外参计算其位置。然后在接近姿势采样阶段,只需在距离目标位置 10 厘米的范围内采样末端执行器姿势,确保夹持器朝向目标,然后使用深度图像提供的空间占用信息规划路径,最后由智体执行路径。
在轨迹生成过程中,仅 SRP 轨迹的生成速度比使用全阶段数据的轨迹快 2.5 倍,而全阶段数据的长度仅为 SRP 数据的 1.4 倍。在现实世界的数据收集中,这种差异只会更大。在实验中使用的其他数据集使用前面 PIP 开始的条件所提供的方法进行划分,其中 d_th = 0.2 m 和 α_fov = π/3。
模型在配备 8 个 Nvidia A100 GPU 的服务器上进行训练,每个 GPU 具有 80GB 的 CUDA 内存。SRP 段通常比 PIP 段长,数据集 DM⟩§ 包含的 SRP 轨迹是 PIP 轨迹的几倍。在训练期间,形成混合数据集 D^Mix,其中独立 SRP 段的比例各不相同。
为了防止 SRP 特征主导模型对操作的理解,在训练期间,PIP 轨迹 τ^PIP 被复制 [N_2/N_1] 次。使用前 10 个epochs 内零样本环境中性能最佳的检查点进行评估。
相关文章:
DataPlatter:利用最少成本数据提升机器人操控的泛化能力
25年3月来自中科院计算所的论文“DataPlatter: Boosting Robotic Manipulation Generalization with Minimal Costly Data”。 视觉-语言-动作 (VLA) 模型在具身人工智能中的应用日益广泛,这加剧对多样化操作演示的需求。然而,数据收集的高成本往往导致…...

诠视科技MR眼镜如何安装apk应用
诠视科技MR眼镜如何安装apk应用 1、使用adb工具安装1.1 adb工具下载1.2 解压adb文件1.3 使用adb安装apk1.4 常用adb命令 2、拷贝到文件夹安装 1、使用adb工具安装 1.1 adb工具下载 点击下面的链接开始下载adb工具,下载结束以后解压文件。 下载链接: https://down…...

3.31Python有关文件操作
1.复制文件 import os from shutil ipmort copy,copytreepath os.path.join(os.getcwd(),test1.txt) target_path os.path.join(os.getcwd(),test1copy)copy(path,target_path) copytree(path,target_path) 注意:test1.txt 和 test1copy 文件夹/包 都点存在 …...

搭建前端环境和后端环境
搭建前端环境 ①、安装vscode,并安装相应的插件工具 ②、安装node.js,可以选择当前版本,或者其他版本 ③、创建工作区 创建一个空文件夹,然后通过vscode工具打开,保存为后缀名为.code-workspace ④、从gitee…...

Polhemus FastScan 单摄像头3D激光扫描器
FastSCAN Cobra是Polhemus公司研制的手持激光扫描仪。与以前的产品比较,它节省了30%的费用,体积也减小了一半 ,但仍然保留了所有功能,使用和携带都更加方便。作为超小的手持激光扫描仪,FastSCAN Cobra对扫描三维物体具…...
召唤数学精灵
1.召唤数学精灵 - 蓝桥云课 问题描述 数学家们发现了两种用于召唤强大的数学精灵的仪式,这两种仪式分别被称为累加法仪式 A(n) 和累乘法仪式 B(n)。 累加法仪式 A(n) 是将从1到 n 的所有数字进行累加求和,即: A(n)12⋯n 累乘法仪式 B(n) …...

《算法:递归+记忆化搜索》
递归记忆化搜索 此文章为简单讲义,详情请移步至主播的主页算法合集: 樱茶喵的个人主页 🔴递归 一.什么是递归? 函数自己调用自己。 二.为什么要用递归? 优点: 代码简洁,可读性好 可用于某些…...

框架修改思路
一、组件引入基本样式 面包屑(使用element plus的标签页) <!-- 标签页区域 --><el-tabs v-model"activeTab" type"card" closable tab-remove"removeTab" class"top-tabs"><el-tab-pane :key&q…...
:ls)
每天学一个 Linux 命令(8):ls
大家好,欢迎来到《每天掌握一个Linux命令》系列。在这个系列中,我们将逐步学习并熟练掌握Linux命令,今天,我们要学习的命令是ls。 01 什么是ls命令 在Linux系统中,ls命令是“list”的缩写,其英文全称为“list directory contents”,即“列出目录内容”。该命令非常实用…...

2025图像处理和深度学习国际学术会议(IPDL 2025)
重要信息 官网:www.IPDL.xyz 时间:2025年4月11-13日 地点:中国-成都 简介 随着深度学习和图像处理技术的迅速发展,相关技术的应用逐渐渗透到各个行业,如医疗影像分析、自动驾驶、安防监控和智能制造等。这些应用的…...

Flutter 环境搭建、常用指令、开发细节
一、环境搭建 Flutter 插件和包管理平台:pub.devFlutter 环境安装,官方中文文档,按着官方的来就够了,没啥难度。安卓模拟器可以使用 Android Studio 自带的也可以第三方的,例如:Genymotion。配置环境变量&…...

使用uni-app框架 写电商商城前端h5静态网站模板项目-手机端-前端项目练习
以前用vue2 分享过一个电商商城前端静态网站项目-电脑端,需要的小伙伴还是很多的,最近又花了几天更新了一个 手机端的 电商商城h5项目,今天也分享一下实现方案。 对于以前写的 电商商城前端静态网站模板-电脑端,有兴趣的小伙伴 可…...

远心镜头原理
文章目录 原理特点分类应用领域 参考:B站优致谱视觉 原理 远心镜头的工作原理基于其特殊的光学设计,旨在解决普通镜头存在的视差问题。它通过将镜头的光轴与成像面垂直,并使主光线平行于光轴,从而确保在一定的物距范围内…...

centos7修复漏洞CVE-2023-38408
漏洞描述: CVE-2023-38408 是 OpenSSH 组件中的一个远程代码执行(RCE)漏洞,影响 OpenSSH 代理(ssh-agent)的安全性。该漏洞被发现于 2023 年 7 月,并被标记为 高危(CVSS 评分 7.3&a…...

Scikit-learn使用指南
1. Scikit-learn 简介 定义: Scikit-learn(简称 sklearn)是基于 Python 的开源机器学习库,提供了一系列算法和工具,用于数据挖掘、数据预处理、分类、回归、聚类、模型评估等任务。特点: 基于 NumPy、SciP…...

React AJAX:深入理解与高效实践
React AJAX:深入理解与高效实践 引言 随着Web应用的日益复杂,前端开发对数据的处理需求也越来越高。React作为目前最流行的前端框架之一,其与AJAX的结合使得数据的异步获取和处理变得更为高效和便捷。本文将深入探讨React与AJAX的关系&…...

uniapp微信小程序封装navbar组件
一、 最终效果 二、实现了功能 1、nav左侧返回icon支持自定义点击返回事件(默认返回上一步) 2、nav左侧支持既显示返回又显示返回首页icon 3、nav左侧只显示返回icon 4、nav左侧只显示返回首页icon 5、nav左侧自定义left插槽 6、nav中间支持title命名 7…...

python程序进行耗时检查
是的,line_profiler 是一个非常强大的工具,可以逐行分析代码的性能。下面是详细步骤,教你如何使用 line_profiler 来标记函数并通过 kernprof 命令运行分析。 1. 安装 line_profiler 首先需要安装 line_profiler: pip install l…...

用户模块——业务校验工具AssertUtil
AssertUtil 方法的作用 在写代码时,我们经常需要检查某些条件是否满足,比如: 用户名是否已被占用? 输入的邮箱格式是否正确? 用户是否有权限执行某个操作? 一般情况下,我们可能会这样写&am…...
系统思考与心智模式
我们的生命为什么越来越长?因为有了疫苗,有了药物。可这些是怎么来的?是因为我们发现了细菌的存在。但在很久以前,医生、助产士甚至都不洗手——不是他们不负责,而是根本不知道“细菌”这回事。那细菌是怎么被发现的&a…...

【计算机视觉】OpenCV实战项目- 抖音动态小表情
OpenCV实战项目- 抖音动态小表情 替换掉当前机器的文件位置即可运行: ‘C:/Users/baixiong/.conda/envs/python37/Lib/site-packages/cv2/data/haarcascade_frontalface_default.xml’ ‘C:/Users/baixiong/.conda/envs/python37/Lib/site-packages/cv2/data/haar…...

数据库--数据库设计
目录: 1.数据库设计和数据模型 2.概念结构设计:E-R模型 3.逻辑结构设计:从E-R图到关系设计 4.数据库规范化设计理论 5.数据库规范化设计实现 1.数据库设计和数据模型 数据库设计会影响数据库自身和上层应用的性能。 一个好的数据库设计可以提…...

[Mac]利用hexo-theme-fluid美化个人博客
接上文,使用Fluid美化个人博客 文章目录 一、安装hexo-theme-fluid安装依赖指定主题创建「关于页」效果展示 二、修改个性化配置1. 修改网站设置2.修改文章路径显示3.体验分类和标签4.左上角博客名称修改5.修改背景图片6.修改关于界面 欢迎大家参观 一、安装hexo-theme-fluid 参…...
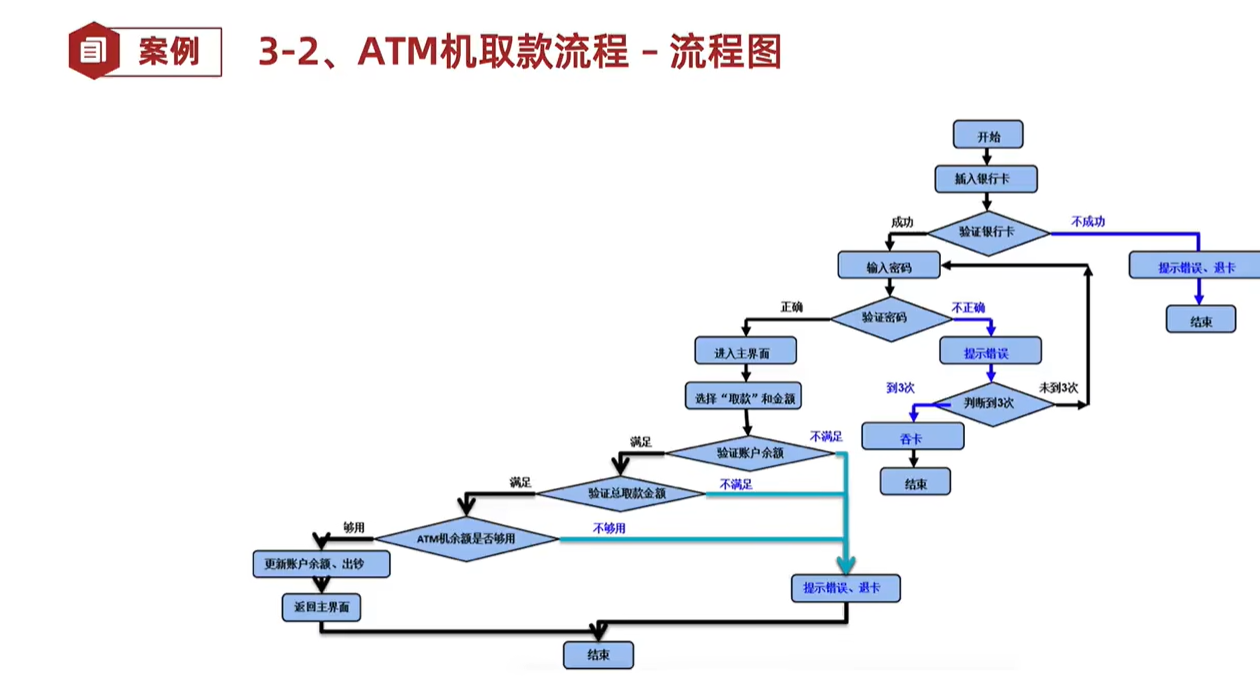
黑盒测试的场景法(能对项目业务进行设计测试点)
定义: 通过运用场景来对系统的功能点或业务流程的描述,设计用例遍历场景,验证软件系统功能的正确性从而提高测试效果的一种方法。 场景法一般包含基本流和备用流。 基本流:软件功能的正确流程,通常一个业务只存在一个基本流且基本流有一个…...

通过Anaconda Prompt激活某个虚拟环境并安装第三方库
打开 Anaconda Prompt 在Windows中,可以通过开始菜单搜索 Anaconda Prompt 来打开。(红色箭头指向的地方。) 激活虚拟环境 输入以下命令来激活您的虚拟环境(假设虚拟环境名称为 myenv): conda activate…...
详解)
SerDes(Serializer/Deserializer)详解
一、SerDes的定义与核心作用 SerDes(串行器/解串器) 是一种将 并行数据转换为高速串行数据(发送端)以及 将串行数据恢复为并行数据(接收端)的集成电路技术,用于解决高速数据传输中的时序、噪声…...

oneDNN、oneMKL 和 oneTBB 介绍及使用
1. oneDNN(Intel oneAPI Deep Neural Network Library) 简介 oneDNN 是 Intel 开源的深度学习神经网络加速库,专为 CPU 和 GPU 上的深度学习推理和训练优化。它提供高效的底层算子(如卷积、池化、矩阵乘法等)ÿ…...

目标检测的训练策略
在目标检测竞赛中,训练策略的优化是提高模型性能的关键。常用的训练策略包括数据预处理、数据增强、超参数调节、损失函数设计、正负样本采样、模型初始化和训练技巧等。以下是一些常见的训练策略: 1. 数据预处理与数据增强 数据归一化:对输…...

深入理解 YUV 颜色空间:从原理到 Android 视频渲染
在视频处理和图像渲染领域,YUV 颜色空间被广泛用于压缩和传输视频数据。然而,在实际开发过程中,很多开发者会遇到 YUV 颜色偏色 的问题,例如 画面整体偏绿。这通常与 U、V 分量的取值有关。那么,YUV 颜色是如何转换为 …...

unidbg读写跟踪还原X-Gorgon
使用版本 33.2.5 mssdk提供给 libsscronet.so 网络库的接口地址是 0x88ee0 参数签名函数调用序列 0x88ee0 -> 0x87e48 -> 0x86d60 -> 0x6B14c 0x6B14c -> 0x6Db40 -> 0x73908-> 0x7d3f0 (X-Argus) ->…...