Scikit-learn使用指南
1. Scikit-learn 简介
- 定义:
Scikit-learn(简称sklearn)是基于 Python 的开源机器学习库,提供了一系列算法和工具,用于数据挖掘、数据预处理、分类、回归、聚类、模型评估等任务。 - 特点:
- 基于 NumPy、SciPy 和 Matplotlib 开发,与科学计算库无缝集成。
- 算法接口统一,学习曲线低,适合快速实现机器学习任务。
- 包含丰富的内置数据集(如鸢尾花、葡萄酒数据集)和常用算法(如决策树、随机森林、SVM、K-means)。
- 适用场景:
- 研究与开发中的快速原型设计。
- 生产环境中需要稳定、易维护的机器学习模型。
2. 安装与环境配置
安装命令
pip install scikit-learn
注意:
- 若需特定版本(如
0.24),可指定版本:pip install scikit-learn==0.24.0 - 推荐使用 虚拟环境(如
virtualenv或conda)管理依赖,避免版本冲突。
虚拟环境示例(macOS/Linux)
# 创建虚拟环境
python -m venv ml_env
source ml_env/bin/activate # 激活环境# 安装依赖
pip install scikit-learn numpy pandas
3. 核心功能与常用模块
(1) 数据集加载
Scikit-learn 提供了多个内置数据集,直接调用即可使用:
from sklearn.datasets import load_iris, load_wine, make_classification# 加载鸢尾花数据集
iris = load_iris()
X_iris = iris.data # 特征
y_iris = iris.target # 标签# 生成合成数据(分类)
X_syn, y_syn = make_classification(n_samples=1000, n_features=20, random_state=42)
(2) 数据预处理
- 标准化/归一化:
from sklearn.preprocessing import StandardScaler, MinMaxScalerscaler = StandardScaler() X_scaled = scaler.fit_transform(X) - 缺失值处理:
from sklearn.impute import SimpleImputerimputer = SimpleImputer(strategy='mean') X_imputed = imputer.fit_transform(X)
(3) 模型训练与评估
示例:决策树分类器(鸢尾花数据集)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 加载数据
iris = load_iris()
X, y = iris.data, iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 初始化模型并训练
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)# 预测与评估
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率: {accuracy:.2f}")
(4) 超参数调优
-
网格搜索(Grid Search):
from sklearn.model_selection import GridSearchCVparam_grid = {'max_depth': [3, 5, 7], 'min_samples_split': [2, 5]} grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5) grid_search.fit(X_train, y_train) print("最佳参数:", grid_search.best_params_) -
随机搜索(Random Search):
from sklearn.model_selection import RandomizedSearchCVparam_dist = {'max_depth': [3, 5, 7], 'min_samples_split': [2, 5, 10]} random_search = RandomizedSearchCV(DecisionTreeClassifier(), param_distributions=param_dist, n_iter=10, cv=5) random_search.fit(X_train, y_train)
4. 版本更新与新特性(以0.24版本为例)
-
Halving Search(渐进式搜索):
- 适用于大规模搜索空间或训练缓慢的模型(如
HalvingGridSearchCV和HalvingRandomSearchCV)。 - 需要先启用实验功能:
from sklearn.experimental import enable_halving_search_cv from sklearn.model_selection import HalvingGridSearchCV
- 适用于大规模搜索空间或训练缓慢的模型(如
-
ICE 图(个体条件期望):
- 可视化特征与预测结果的关系,支持
plot_partial_dependency的kind='individual'参数。
- 可视化特征与预测结果的关系,支持
-
分类特征支持:
HistGradientBoostingClassifier和HistGradientBoostingRegressor新增categorical_features参数,支持分类特征的高效处理。- 示例:
from sklearn.ensemble import HistGradientBoostingClassifier model = HistGradientBoostingClassifier(categorical_features=[True, False])
5. 常见问题与解决方案
(1) 数据格式不兼容
- 问题:混合使用
H2O和Scikit-learn时需转换数据格式。 - 解决:
# H2OFrame 转 Pandas DataFrame import h2o df_pandas = h2o_frame.as_data_frame()# Pandas DataFrame 转 H2OFrame h2o_frame = h2o.H2OFrame(df_pandas)
(2) 版本冲突
- 问题:不同项目依赖不同版本的 Scikit-learn。
- 解决:使用虚拟环境隔离依赖,确保每个项目使用独立的 Python 环境。
(3) 缺失值处理
- 问题:模型训练时遇到
NaN值。 - 解决:
from sklearn.impute import SimpleImputer imputer = SimpleImputer(strategy='mean') X_imputed = imputer.fit_transform(X)
6. 推荐学习资源
- 官方文档:
Scikit-learn 官网 - 书籍:
- 《Scikit-Learn机器学习核心技术与实践》(谭贞军)
- 《Python机器学习基础教程》(Sebastian Raschka)
- 实践示例:
- 使用鸢尾花、葡萄酒等内置数据集快速上手分类任务。
- 尝试
GridSearchCV和RandomizedSearchCV进行超参数调优。
7. 代码示例:完整机器学习流程
# 完整流程:数据加载→预处理→模型训练→评估
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report# 加载数据
wine = load_wine()
X, y = wine.data, wine.target# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义Pipeline(标准化 + 随机森林)
pipeline = Pipeline([('scaler', StandardScaler()),('classifier', RandomForestClassifier(n_estimators=100))
])# 训练模型
pipeline.fit(X_train, y_train)# 评估
y_pred = pipeline.predict(X_test)
print("分类报告:\n", classification_report(y_test, y_pred))
相关文章:

Scikit-learn使用指南
1. Scikit-learn 简介 定义: Scikit-learn(简称 sklearn)是基于 Python 的开源机器学习库,提供了一系列算法和工具,用于数据挖掘、数据预处理、分类、回归、聚类、模型评估等任务。特点: 基于 NumPy、SciP…...

React AJAX:深入理解与高效实践
React AJAX:深入理解与高效实践 引言 随着Web应用的日益复杂,前端开发对数据的处理需求也越来越高。React作为目前最流行的前端框架之一,其与AJAX的结合使得数据的异步获取和处理变得更为高效和便捷。本文将深入探讨React与AJAX的关系&…...

uniapp微信小程序封装navbar组件
一、 最终效果 二、实现了功能 1、nav左侧返回icon支持自定义点击返回事件(默认返回上一步) 2、nav左侧支持既显示返回又显示返回首页icon 3、nav左侧只显示返回icon 4、nav左侧只显示返回首页icon 5、nav左侧自定义left插槽 6、nav中间支持title命名 7…...

python程序进行耗时检查
是的,line_profiler 是一个非常强大的工具,可以逐行分析代码的性能。下面是详细步骤,教你如何使用 line_profiler 来标记函数并通过 kernprof 命令运行分析。 1. 安装 line_profiler 首先需要安装 line_profiler: pip install l…...

用户模块——业务校验工具AssertUtil
AssertUtil 方法的作用 在写代码时,我们经常需要检查某些条件是否满足,比如: 用户名是否已被占用? 输入的邮箱格式是否正确? 用户是否有权限执行某个操作? 一般情况下,我们可能会这样写&am…...
系统思考与心智模式
我们的生命为什么越来越长?因为有了疫苗,有了药物。可这些是怎么来的?是因为我们发现了细菌的存在。但在很久以前,医生、助产士甚至都不洗手——不是他们不负责,而是根本不知道“细菌”这回事。那细菌是怎么被发现的&a…...

【计算机视觉】OpenCV实战项目- 抖音动态小表情
OpenCV实战项目- 抖音动态小表情 替换掉当前机器的文件位置即可运行: ‘C:/Users/baixiong/.conda/envs/python37/Lib/site-packages/cv2/data/haarcascade_frontalface_default.xml’ ‘C:/Users/baixiong/.conda/envs/python37/Lib/site-packages/cv2/data/haar…...

数据库--数据库设计
目录: 1.数据库设计和数据模型 2.概念结构设计:E-R模型 3.逻辑结构设计:从E-R图到关系设计 4.数据库规范化设计理论 5.数据库规范化设计实现 1.数据库设计和数据模型 数据库设计会影响数据库自身和上层应用的性能。 一个好的数据库设计可以提…...

[Mac]利用hexo-theme-fluid美化个人博客
接上文,使用Fluid美化个人博客 文章目录 一、安装hexo-theme-fluid安装依赖指定主题创建「关于页」效果展示 二、修改个性化配置1. 修改网站设置2.修改文章路径显示3.体验分类和标签4.左上角博客名称修改5.修改背景图片6.修改关于界面 欢迎大家参观 一、安装hexo-theme-fluid 参…...
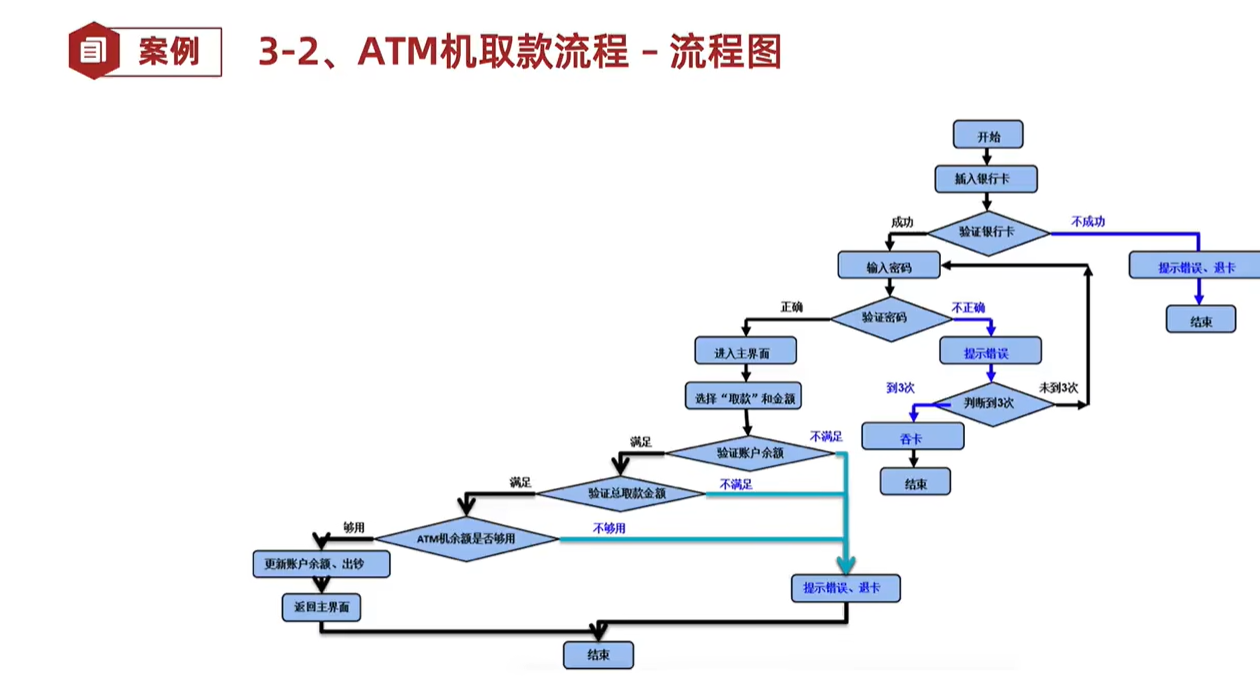
黑盒测试的场景法(能对项目业务进行设计测试点)
定义: 通过运用场景来对系统的功能点或业务流程的描述,设计用例遍历场景,验证软件系统功能的正确性从而提高测试效果的一种方法。 场景法一般包含基本流和备用流。 基本流:软件功能的正确流程,通常一个业务只存在一个基本流且基本流有一个…...

通过Anaconda Prompt激活某个虚拟环境并安装第三方库
打开 Anaconda Prompt 在Windows中,可以通过开始菜单搜索 Anaconda Prompt 来打开。(红色箭头指向的地方。) 激活虚拟环境 输入以下命令来激活您的虚拟环境(假设虚拟环境名称为 myenv): conda activate…...
详解)
SerDes(Serializer/Deserializer)详解
一、SerDes的定义与核心作用 SerDes(串行器/解串器) 是一种将 并行数据转换为高速串行数据(发送端)以及 将串行数据恢复为并行数据(接收端)的集成电路技术,用于解决高速数据传输中的时序、噪声…...

oneDNN、oneMKL 和 oneTBB 介绍及使用
1. oneDNN(Intel oneAPI Deep Neural Network Library) 简介 oneDNN 是 Intel 开源的深度学习神经网络加速库,专为 CPU 和 GPU 上的深度学习推理和训练优化。它提供高效的底层算子(如卷积、池化、矩阵乘法等)ÿ…...

目标检测的训练策略
在目标检测竞赛中,训练策略的优化是提高模型性能的关键。常用的训练策略包括数据预处理、数据增强、超参数调节、损失函数设计、正负样本采样、模型初始化和训练技巧等。以下是一些常见的训练策略: 1. 数据预处理与数据增强 数据归一化:对输…...

深入理解 YUV 颜色空间:从原理到 Android 视频渲染
在视频处理和图像渲染领域,YUV 颜色空间被广泛用于压缩和传输视频数据。然而,在实际开发过程中,很多开发者会遇到 YUV 颜色偏色 的问题,例如 画面整体偏绿。这通常与 U、V 分量的取值有关。那么,YUV 颜色是如何转换为 …...

unidbg读写跟踪还原X-Gorgon
使用版本 33.2.5 mssdk提供给 libsscronet.so 网络库的接口地址是 0x88ee0 参数签名函数调用序列 0x88ee0 -> 0x87e48 -> 0x86d60 -> 0x6B14c 0x6B14c -> 0x6Db40 -> 0x73908-> 0x7d3f0 (X-Argus) ->…...

全长约8.3公里!宁波象山港跨海大桥南中塔柱云端合龙
快科技3月31日消息,据报道,由中国交建二航局承建的宁波象山港跨海大桥顺利完成南中塔柱合龙施工,标志着这一重大交通工程取得阶段性突破。 这座连接宁波鄞州区与象山县的跨海通道全长8.3公里,其标志性的南主塔采用创新"钻石…...
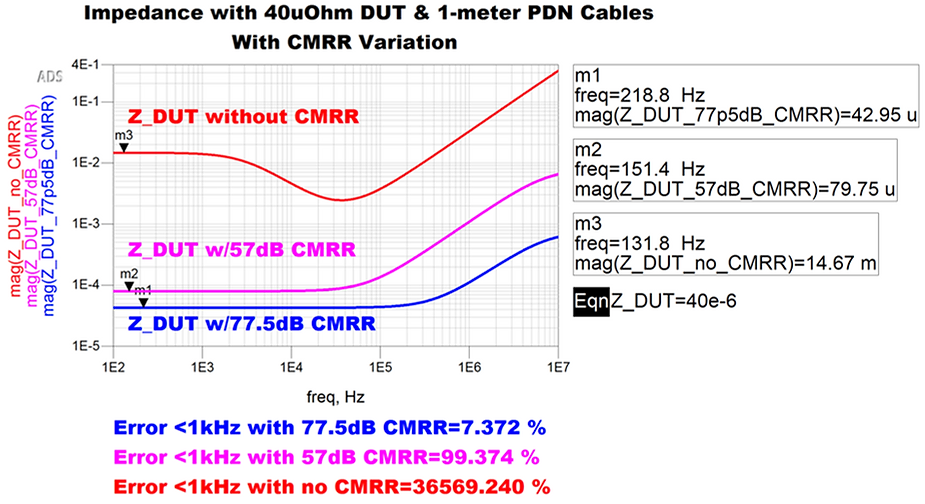
使用 2 端口探头测量 40 uOhm(2000 安培)PDN 的挑战 – 需要多少 CMRR?
部分 1 / 3 本文是 3 部分系列的第一部分: 第 2 部分 - 测量结果! 第 3 部分 - 使用另一台 VNA 的测量结果 介绍 我们大多数人都知道 2 端口测量中的接地回路。我们大多数人也都知道,我们需要引入接地回路隔离器来纠正错误。如果没有&…...

蓝桥杯——统计子矩阵
解法:二维前缀和双指针 代码: #include <iostream> using namespace std; typedef long long ll; ll prefix[505][505], a[250010]; int main() {ll n, m, k, ans 0; cin >> n >> m >> k;for(int i 1; i < n; i)for(int …...
---多实例处理)
snmp/mib采用子代理模式,编码,部署(二)---多实例处理
snmp/mib采用子代理模式,编码,部署(二)---多实例处理 0.本文针对net-snmp中mib表做处理,即单张表对应后台多个实例. 1.源代码生成 拷贝GSC-MIB-0805.txt到/usr/share/snmp/mibs(具体看自己安装目录,如果找不到,下面解…...
吾爱破解安卓逆向学习笔记(4p)
学习目标,了解安卓四大组件,activity生命周期,同时了解去除部分广告和更新提示。 广告类型 1.启动页广告 2.更新广告 3.横幅广告 安卓四大组件 组件描述Activity(活动)在应用中的一个Activity可以用来表示一个界面,意思可以…...

使用Redis实现轻量级消息队列
使用消息中间件如RabbitMQ或kafka虽然好,但也给服务器带来很大的内存开销,当系统的业务量,并发量不高时,考虑到服务器和维护成本,可考虑使用Redis实现一个轻量级的消息队列,实现事件监听的效果。下面介绍下…...

stm32第十天外部中断和NVIC讲解
一:外部中断基础知识 1.STM32外部中断框架 中断的概念:在主程序运行过程中,出现了特点的中断触发条件,使得CPU暂停当前正在运行的程序,转而去处理中断程序,处理完成后又返回原来被暂停的位置继续运行 1&…...

26考研——线性表_ 线性表的链式表示_单链表(2)
408答疑 文章目录 三、 线性表的链式表示单链表概念单链表的结构头结点 单链表上基本操作的实现单链表的初始化带头结点和不带头结点的初始化操作注意 求表长操作按序号查找结点按值查找表结点插入结点操作扩展:对某一结点进行前插操作 删除结点操作扩展:…...

MATLAB 控制系统设计与仿真 - 31
二次型最优控制 考虑到系统如果以状态空间方程的形式给出,其性能指标为: 其中F,Q,R是有设计者事先选定。线性二次最优控制问题简称LQ(Linear Quadractic)问题,就是寻找一个控制,使得系统沿着由指定初态出发的相应轨迹,其性能指标J取得最小值。 LQ问题分…...

蓝桥杯15届JAVA_A组
将所有1x1转化为2x2 即1x1的方块➗4 然后计算平方数 记得-1 2 import java.io.BufferedReader; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.io.PrintWriter;public class Main{static BufferedReader in new BufferedReader(new In…...

deepseek v3 0324实现工作流编辑器
HTML 工作流编辑器 以下是一个简单的工作流编辑器的HTML实现,包含基本的拖拽节点、连接线和可视化编辑功能: <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewp…...

【NLP 面经 3】
目录 一、Transformer与RNN对比 多头自注意力机制工作原理 相比传统 RNN 在处理长序列文本的优势 应对过拟合的改进方面 二、文本分类任务高维稀疏文本效果不佳 特征工程方面 核函数选择方面 模型参数调整方面 三、NER中,RNN模型效果不佳 模型架构方面 数据处理方面…...

20250331-智谱-沉思
背景 收到GLM沉思的消息,立马试用下。感觉真的太及时了。 (背景:为了客户的需求“AI辅助写作”实验了2款开源workflow,2款在线workflow,好几款多智能体框架后,心中无底之际。。。) 1. GLM(开启…...

Java EE(17)——网络原理——IP数据报结构IP协议解析(简述)
一.IP数据报结构 (1)版本:指明协议的版本,IPv4就是4,IPv6就是6 (2)首部长度:单位是4字节,表示IP报头的长度范围是20~60字节 (3)8位区分服务:实际上只有4位TOS有效,分别是最小延时,最…...