高并发内存池(一):项目介绍和Thread Cache实现
前言:本文将要介绍的高并发内存池,它的原型是Google的⼀个开源项⽬tcmalloc,全称Thread-Caching Malloc,近一个月我将以学习为目的来模拟实现一个精简版的高并发内存池,并对核心技术分块进行精细剖析,分享在专栏《高并发内存池》里,期待小伙伴们的热情支持与关注!
项目专栏:高并发内存池_敲上瘾的博客-CSDN博客
一、项目介绍
该篇文章将要介绍的⾼并发的内存池,它的原型是google的⼀个开源项⽬tcmalloc,全称Thread-Caching Malloc,即线程缓存的malloc,实现了⾼效的多线程内存管理,⽤于替代系统的内存分配相关的函数(malloc、free)。
在多线程环境下进行内存申请本质上属于对公共资源的访问,高并发场景下对内存分配锁的竞争会异常激烈,这将严重拖慢程序运行效率。此外,频繁的系统级内存申请不仅会产生额外开销,还可能引发内存碎片问题。传统的malloc内存分配机制由于这些固有缺陷,已难以满足现代高性能开发中对内存管理效率的需求。
而tcmalloc在高并发场景下是如何高效、安全的分配和释放内存呢?它的设计核心如下:
- 减少锁竞争:传统内存分配器使用全局锁保护内存管理结构,高并发下锁竞争严重。高并发内存池通过以下方式降低锁冲突:
- 线程本地缓存(Thread Local Storage, TLS):每个线程维护独立的内存缓存,大部分分配/释放操作在本地完成,无需加锁。
- 分层设计:将内存管理分为线程本地缓存、中央共享缓存和全局堆,逐层解耦。
- 内存预分配:预先分配大块内存(如分页或固定大小的块),减少频繁的系统调用(如
brk或mmap)。 - 内存分类管理:
- 按大小划分:小对象(如<64KB)、中对象和大对象采用不同分配策略。
- 对齐与碎片优化:固定大小的内存块减少内存碎片。
concurrent memory pool主要由以下3个部分构成:

thread cache:
线程缓存是每个线程独有的,⽤于⼩于256KB的内存的分配,线程从这⾥申请内存不需要加锁,每个线程独享⼀个cache,这也是该并发线程池⾼效的地⽅。
central cache:
中⼼缓存是所有线程所共享,thread cache是按需从central cache中获取的对象。central cache合适的时机回收thread cache中的对象,避免⼀个线程占⽤了太多的内存,⽽其他线程的内存吃紧,达到内存分配在多个线程中均衡调度的⽬的。central cache是存在竞争的,所以从这⾥取内存对象是需要加锁,⾸先这⾥⽤的是桶锁,其次只有thread cache的没有内存对象时才会找central cache,所以这⾥竞争不会很激烈。
page cache:
⻚缓存是在central cache缓存上⾯的⼀层缓存,存储的内存是以⻚为单位存储及分配的,central cache没有内存对象时,从page cache分配出⼀定数量的page,并切割成定⻓⼤⼩的⼩块内存,分配给central cache。当⼀个span的⼏个跨度⻚的对象都回收以后,page cache会回收central cache满⾜条件的span对象,并且合并相邻的⻚,组成更⼤的⻚,缓解内存碎⽚的问题。
二、Thread Cache实现
Thread Cache实现有些类似定长内存池,大家有兴趣可以阅读一下:
定长内存池原理及实现-CSDN博客
但是定长内存池有一个缺点,即它每次申请的空间只能是固定的,它的核心原理是:
先向系统申请一大块空间,然后当我们再需要申请内存时就从这块空间上获取,我们把空间用完后不用急着释放回系统,而是把它用一个自由链表连接起来,进行二次利用。也就是说我们再次申请空间时直接到自由链表上找,如果没有再去大空间上找,如果还不够再去向系统申请。
但我们希望从开辟的内存池申请的空间不是固定的,它可以是4字节、10字节、50字节,500字节等等。申请多少字节不是关键的问题,因为字节大小本来就是可以随意申请的,问题在于这些空间被弃用后,我们如何把它们管理起来并进行二次利用。
定长内存池使用一个自由链表来维护弃用的空间,那么我们用多个自由链表来维护不同的字节大小空间,需要多少字节就到指定的自由链表去找不就行了吗?答案是:是的!
为了高效的找到相应的自由链表,我们可以做一个哈希表。如下:

需要注意几个问题:
- 不能直接一个任意字节就做一个对应自由链表,这样数组的开销太大了,需要引入对齐机制,比如我们需要5字节,6字节,8字节等都统一申请8字节,如果需要9字节,15字节等都统一申请16字节。当然这是会造成一定的内存浪费的,像这样因为对齐带来的内存浪费把它称为内碎片。
- 因为要做成自由链表所以为了保证在任何环境下都能存下一个指针的大小,最少的对齐数必须是8 byte。
- 因为对齐会产生内碎片,所以对齐数的选取是很重要的,如果我们就以8的倍数来选定对齐数,它需要开辟的数组大小是256*1024/8=32768,这未免有些太大,我们可以根据字节大小采用不同分配策略。
为突出该哈希表的性质,下文就称它为自由链表桶。
1.框架设计
首先用一个common.h文件来写一些需要用到的公共的类,比如自由链表的封装,对齐数的计算 和 哈希表下标映射的计算也封装成类放在里面。如下:

FreeList:
- Push:把用完的内存插入链表中。
- Pop:从链表中取出内存。
- Empty:判断该自由链表中是否有节点,以便判断是否需要到central cache中取内存。
- _list_head:储存自由链表的头。
SizeClass:
- RoundUp:计算对齐数和对齐后实际需要申请的空间大小。
- Index:计数自由链表桶中对应的下标。
这里把它写成静态成员函数是为方便在没有类对象情况下对函数的直接调用,因为现在并没有成员变量所以没必要实例化出对象。
可以把它做为内联函数,减少函数栈帧的开辟。
创建ConcurrentAlloc.h,在这个文件里提供一些直接能让用户使用的类和接口。我们封装一个ConcurrentAlloc类,如下:

- ConAlloc:用来给让用户申请内存。
- ConFree:用来让用户释放内存。
接下来就是创建ThreadCache.h文件,来声明一些在thread cache这一层需要用到的类方法等。如下:

- Allocate:在自由链表桶里面申请空间。
- Deallocate:把不用的空间放到自由链表桶。
- FetchFromCentralCache:当自由链表里没有空间时到Central Cache这一层获取,该函数在该篇文章不进行实现,请期待下一篇文章的讲解。
- _freelists[ ]:自由链表桶。
2.自由链表封装
Push实现
Push功能是把不用的空间放到自由链表中,因为头插效率比较高时间复杂度为O(1),我们直接把它头插到自由链表中。接下来就是头插操作:
把这块需要插入到链表的空间记为obj,首先把_list_head值储存到obj空间的前4/8字节,因为并不确定用户用的是32位系统还是64位系统,所以可以用这样一个操作来解决:
*(void **)obj = _list_head;
然后让obj成为新的头,即_list_head = obj,如下:
void Push(void *obj)
{*(void **)obj = _list_head;_list_head = obj;
}Pop实现
Pop是从自由链表中获取到内存,我们直接取头节点即可,如下:
void *Pop()
{void *obj = _list_head;_list_head = *(void **)obj;return obj;
}- void *obj = _list_head:取到头指针,并保存到obj中。
- _list_head = *(void **)obj:把_list_head更新为头节点指向的下一个节点,也可写为 _list_head = *(void**)_list_head;
Empty实现
直接返回 _list_head == nullptr即可
3.对齐数计算和下映射计算
在这里做这样一个规则把内存浪费率控制在10%左右:
| [1,128] | 8byte对齐 | _freelist[0,16) |
| [128+1,1024] | 16byte对齐 | _freelist[16,72) |
| [1024+1,8*1024] | 128byte对齐 | _freelist[72,128) |
| [8*1024+1,64*1024] | 1024byte对齐 | _freelist[128,184) |
| [64*1024+1,256*1024] | 8*1024byte对齐 | _freelist[184,208) |
浪费率:
(浪费的字节数 / 对齐后的字节数)*100%
[1,128] 区间对齐数为8byte,所以最大的浪费数为7byte,而区间内的前8个字节对齐后申请的内存是8,所以浪费率 = (7/8)*100%87.50%
同理各个区间的浪费率为:
| [1,128] | (7/8)*100% |
| [128+1,1024] | (15/16*9)*100% |
| [1024+1,8*1024] | (127/128*9)*100% |
| [8*1024+1,64*1024] | (1023/1024*9)*100% |
| [64*1024+1,256*1024] | ( (8*1024-1) / (8*1024*9) )*100% |
虽然[1,128]区间浪费率有点高但实际浪费的并不多,无伤大雅。
对齐后字节大小计算
接下来就是计算对齐数,也就是让用户任意扔一个数字过来,需要通过对齐规则计算它实际开辟的空间。在RoundUp中实现。
我们可以用 if else 把数据分开处理,如下:
static inline int RoundUp(size_t bytes)
{if (bytes <= 128)return _RoundUp(bytes, 8);else if (bytes <= 1024)return _RoundUp(bytes, 16);else if (bytes <= 8 * 1024)return _RoundUp(bytes, 128);else if (bytes <= 64 * 1024)return _RoundUp(bytes, 1024);else if (bytes <= 256 * 1024)return _RoundUp(bytes, 8 * 1024);else{assert(false);return 1;}
}_RoundUp函数实现也很简单,如果这个数本身就对齐直接返回即可,如果不是再做简单的处理,如下:
int _RoundUp(size_t size, size_t alignNum)
{if (size % alignNum == 0)return size;elsereturn (size / alignNum + 1) * alignNum;
}但是代码中又是取模,又是除,效率还略逊一筹,可以考虑把它改成位运算,即:
static inline int _RoundUp(size_t bytes, size_t alignNum)
{return (bytes + alignNum - 1) & ~(alignNum - 1);
}- bytes + (alignNum - 1):把这个过程也当成为运算,作用是把bytes中不足下一个alignNum倍数的部分补上。
- &~(alignNum - 1):再把补过头的部分消去。
这里大家可以带进去数值来理一理。
下标映射计算
接下来是实现Index,假设我们已经知道用户要申请的空间大小(size)和对齐数是2的多少次方(align_shift),那么可以做这样的计算:
static inline int _Index(size_t bytes, size_t align_shift)
{return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}1左移align_shift位得到对齐数,再减1,加上bytes,作用是把bytes中不足下一个alignNum倍数的部分补上。然后右移align_shift相当于除以对齐数,最后再减去1因为数组下标是从0开始的。
以上计算出来的只是这个对齐后的字节数 对于相应 对齐数 在数组上起始位置的相对位置,还需要加上前面对齐占用的数组元素个数才能得到正确的下标。即:
static inline int _Index(size_t bytes, size_t align_shift)
{return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
static inline int Index(size_t bytes)
{// 每个区间有多少个链static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128)return _Index(bytes, 3);else if (bytes <= 1024)return _Index(bytes, 4)+group_array[0];else if (bytes <= 8 * 1024)return _Index(bytes, 7)+group_array[0]+group_array[1];else if (bytes <= 64 * 1024)return _Index(bytes, 10)+group_array[0]+group_array[1]+group_array[2];else if (bytes <= 256 * 1024)return _Index(bytes, 13)+group_array[0]+group_array[1]+group_array[2]+group_array[3];else{assert(false);return 1;}
}回顾上文框架,以上我们相当于完成了common.h文件,接下来处理ThreadCache和ConcurrentAlloc的封装就简单多了。
刚才我们设计了对齐数,接下来就可以确定自由链表桶的大小了,即208(从对齐规则表里得到)。我们可以把208做成一个全局的 static const size_t 类型 或者 宏定义。
单独创建一个ThreadCache.cpp文件用来做接口的实现:
#include "ThreadCache.h"
void* ThreadCache::Allocate(size_t bytes)
{//得到对齐后的字节数int objSize = SizeClass::RoundUp(bytes);//得到自由链表桶的下标映射int intex = SizeClass::Index(bytes);//先去链表桶里面申请内存,如果没有到CentralCache中获取if(!_freelists[intex].Empty())return _freelists[intex].Pop();elsereturn FetchFromCentralCache(objSize,intex);
}
void ThreadCache::Deallocate(void* obj,size_t bytes)
{int intex = SizeClass::Index(bytes);_freelists[intex].Push(obj);
}
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{//... ...return nullptr;
}我们希望每个线程都有自己独立的Thread Cache对象,但又不想让用户在线程内自己申请。那么可以直接把它定义为全局变量 并在前面加上static thread_local关键字,让各自线程在自己的线程局部储存内都申请一份Thread Cache对象,而不是共享。
所以在ThreadCache.h文件中定义:
static thread_local ThreadCache* pTLSThreadCache = nullptr;
ConcurrentAlloc封装如下:
#pragma once
#include "Common.h"
#include "ThreadCache.h"
class ConcurrentAlloc
{
public:static void* ConAlloc(size_t size){if(pTLSThreadCache == nullptr)pTLSThreadCache = new ThreadCache;return pTLSThreadCache->Allocate(size);}static void ConFree(void* ptr,size_t size){assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr,size);}
};三、源码
1.Common.h
#pragma once
#include <iostream>
#include <assert.h>
#include <thread>
using namespace std;
class FreeList
{
public:void Push(void *obj){*(void **)obj = _list_head;_list_head = obj;}void *Pop(){void *obj = _list_head;_list_head = *(void **)obj;return obj;}bool Empty(){return _list_head == nullptr;}private:void *_list_head = nullptr;
};
class SizeClass
{// 整体控制在最多10%左右的内碎片浪费// [1,128] 8byte对齐 freelist[0,16)// [128+1,1024] 16byte对齐 freelist[16,72)// [1024+1,8*1024] 128byte对齐 freelist[72,128)// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184)// [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)
public:static inline int _RoundUp(size_t bytes, size_t alignNum){return (bytes + alignNum - 1) & ~(alignNum - 1);}static inline int RoundUp(size_t bytes){if (bytes <= 128)return _RoundUp(bytes, 8);else if (bytes <= 1024)return _RoundUp(bytes, 16);else if (bytes <= 8 * 1024)return _RoundUp(bytes, 128);else if (bytes <= 64 * 1024)return _RoundUp(bytes, 1024);else if (bytes <= 256 * 1024)return _RoundUp(bytes, 8 * 1024);else{assert(false);return 1;}}static inline int _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}static inline int Index(size_t bytes){static int group_array[4] = {16, 56, 56, 56};if (bytes <= 128)return _Index(bytes, 3);else if (bytes <= 1024)return _Index(bytes, 4) + group_array[0];else if (bytes <= 8 * 1024)return _Index(bytes, 7) + group_array[0] + group_array[1];else if (bytes <= 64 * 1024)return _Index(bytes, 10) + group_array[0] + group_array[1] + group_array[2];else if (bytes <= 256 * 1024)return _Index(bytes, 13) + group_array[0] + group_array[1] + group_array[2] + group_array[3];else{assert(false);return 1;}}private:
};2.ConcurrentAlloc.h
#pragma once
#include "Common.h"
#include "ThreadCache.h"
class ConcurrentAlloc
{
public:static void* ConAlloc(size_t size){pTLSThreadCache = new ThreadCache;return pTLSThreadCache->Allocate(size);}static void ConFree(void* ptr,size_t size){assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr,size);}
};3.ThreadCache.h
#pragma once
#include "Common.h"
static int const FREE_LIST_SIZE = 208;
class ThreadCache
{
public://从Thread Cache中申请void* Allocate(size_t bytes);void Deallocate(void* obj,size_t bytes);//CentralCache中申请void* FetchFromCentralCache(size_t index, size_t size);
private:FreeList _freelists[FREE_LIST_SIZE];
};
static thread_local ThreadCache* pTLSThreadCache = nullptr;3.ThreadCache.cpp
#include "ThreadCache.h"
void* ThreadCache::Allocate(size_t bytes)
{int objSize = SizeClass::RoundUp(bytes);int intex = SizeClass::Index(bytes);if(!_freelists[intex].Empty())return _freelists[intex].Pop();elsereturn FetchFromCentralCache(objSize,intex);
}
void ThreadCache::Deallocate(void* obj,size_t bytes)
{int intex = SizeClass::Index(bytes);_freelists[intex].Push(obj);
}
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{//... ...return nullptr;
}5.UnitTest.cpp
#include "ConcurrentAlloc.h"
void Alloc1()
{for(int i=0;i<5;i++)ConcurrentAlloc::ConAlloc(7);
}
void Alloc2()
{for(int i=0;i<5;i++)ConcurrentAlloc::ConAlloc(8);
}
int main()
{thread t1(Alloc1);thread t2(Alloc2);t1.join();t2.join();return 0;
}相关文章:
高并发内存池(一):项目介绍和Thread Cache实现
前言:本文将要介绍的高并发内存池,它的原型是Google的⼀个开源项⽬tcmalloc,全称Thread-Caching Malloc,近一个月我将以学习为目的来模拟实现一个精简版的高并发内存池,并对核心技术分块进行精细剖析,分享在…...
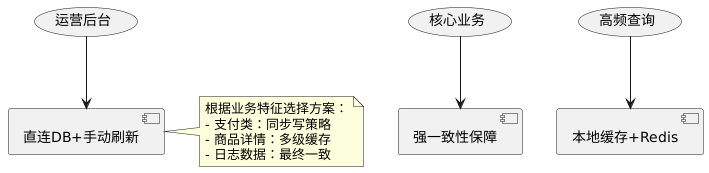
MySQL与Redis数据一致性保障方案详解
前言 在现代分布式系统中,MySQL和Redis的结合使用非常普遍。MySQL作为关系型数据库负责持久化存储,而Redis则作为高性能缓存层提升系统的响应速度。然而,在这种架构下,如何保证MySQL与Redis之间的数据一致性是一个重要的挑战。本…...

“钉耙编程”2025春季联赛(2)题解(更新中)
1001 学位运算导致的 1002 学历史导致的 // Problem: 学历史导致的 // Contest: HDOJ // URL: https://acm.hdu.edu.cn/contest/problem?cid1151&pid1002 // Memory Limit: 524288 MB // Time Limit: 1000 ms // // Powered by CP Editor (https://cpeditor.org)#include …...

C#高级:启动、中止一个指定路径的exe程序
一、启动一个exe class Program {static void Main(string[] args){string exePath "D:\测试\Test.exe";// 修改为你要运行的exe路径StartProcess(exePath);}private static bool StartProcess(string exePath){// 创建一个 ProcessStartInfo 对象来配置进程启动参…...

【NumPy】1. 前言安装
0.前言 需要具备[[Python]]基础 定义: NumPy 通常与 [[SciPy]](Scientific Python)和 [[Matplotlib]](绘图库)一起使用, 这种组合广泛用于替代 [[MatLab]],是一个强大的科学计算环境,有助于我…...
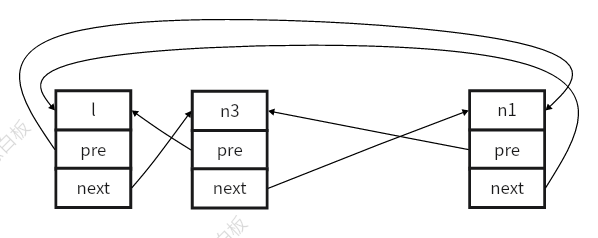
双向链表的理解
背景 代码中经常会出现双向链表,对于双向链表的插入和删除有对应的API函数接口,但直观的图表更容易理解,所以本文会对rt-thread内核代码中提供的双向链表的一些API函数操作进行绘图,方便后续随时查看。 代码块 rt-thread中提供…...
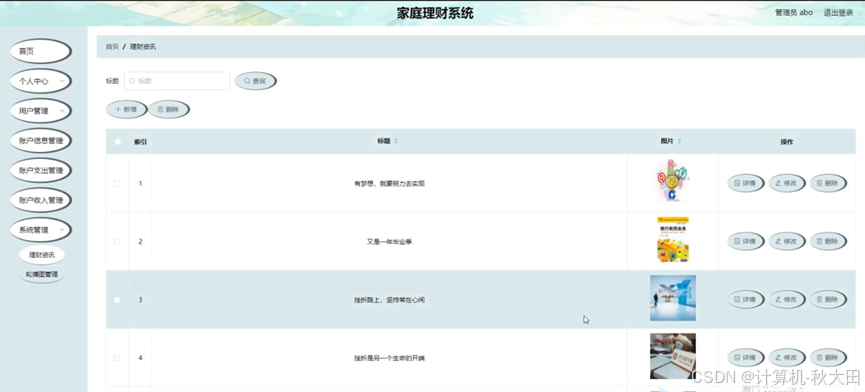
基于Spring Boot的家庭理财系统app的设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

【测试】每日3道面试题 3/31
长期更新,建议关注收藏点赞。 单元测试策略有哪些,主要内容。 白盒测试黑盒测试基于异常和边界的测试 主要内容:测试用例设计、执行、结果分析、自动化beta测试和alpha测试主要区别 主要区别:测试环境测试者 alphabeta时间先后测…...

Go 语言常见错误
代码及工程组织 1、意外的变量隐藏 示例代码: package mainimport ("fmt" )var FunTester "全局变量 FunTester"func main() {FunTester : "局部变量 FunTester"fmt.Println(FunTester) }func showGlobal() {fmt.Println(FunTest…...

216. 组合总和 III 回溯
目录 问题描述 解决思路 关键点 代码实现 代码解析 1. 初始化结果和路径 2. 深度优先搜索(DFS) 3. 遍历候选数字 4. 递归与回溯 示例分析 复杂度与优化 回溯算法三部曲 1. 路径选择:记录当前路径 2. 递归探索:进入下…...

【Python 算法】动态规划
本博客笔记内容来源于灵神,视频链接如下:https://www.bilibili.com/video/BV16Y411v7Y6?vd_source7414087e971fef9431117e44d8ba61a7&spm_id_from333.788.player.switch 01背包 计算了f[i1],f[i]就没用了,相当于每时每刻只有…...

nginx的自定义错误页面
正常访问一个不存在的页面是会报404这个错误 我们可以自定义错误页面 error_page 404 /40x.html 然后调用location 最后创建文件 写入你想写的内容 最后实验成功 注意在nginx的配置文件里,注意在加分号 在写完配置时...

制作service列表并打印出来
制作service列表并打印出来 在Linux中,服务(Service)是指常驻在内存中的进程,这些进程通常监听某个端口,等待其他程序的请求。服务也被称为守护进程(Daemon),它们提供了系统所需的各…...

UML 4+1 视图:搭建软件架构的 “万能拼图”
UML 41 视图是一种全面描述软件架构的方法,以下为你详细介绍各个视图: 1.逻辑视图(Logical View) 概述:逻辑视图主要用于展现系统的功能架构,它聚焦于系统提供的功能以及这些功能的逻辑组织方式ÿ…...
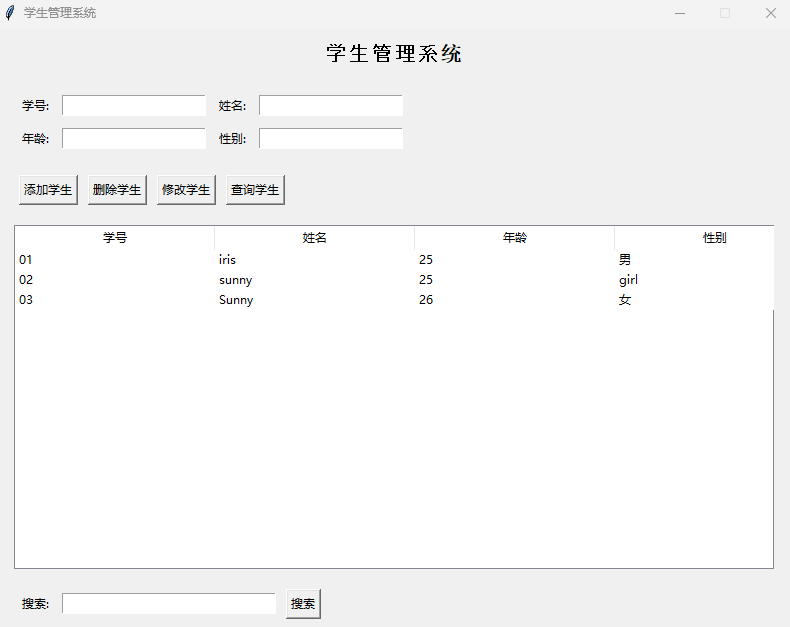
tkinter 库(设计图形界面系统)
几何管理的应用 # tkinter 库 是Python的标准GUI库,提供了创建图形用户界面的功能。 tkinter是一个跨平台的GUI库,支持Windows、macOS和Linux等操作系统。它是Python的标准库之一,无需额外安装。 #tkinter.Entry 是 Tkinter 的输入框控件类&…...

WordPress汉主题
WordPress汉主题wphan.com(以下简称WP汉主题)是一个专注于WordPress中文主题与插件开发的专业团队。该团队致力于为中文用户提供高质量的WordPress主题和插件资源,帮助用户轻松创建专业且吸引人的网站。 WP汉主题提供多种功能丰富的WordPress主题,涵盖博…...
在线文档协作工具选型必看:14款产品对比
本文将深入对比14款在线文档协作工具:PingCode; 2. Worktile; 3. 语雀; 4. 金山文档; 5. WPS云文档; 6. Google Docs; 7. 轻雀文档; 8. Microsoft 365 Online; 9. 明道云文档等。 在数字化办公日益普及的今天,企业对高效协同的需求不断升级,在…...

分布式计算Ray框架面试题及参考答案
目录 简述 Ray 的架构设计核心组件及其协作流程 全局控制存储(GCS)在 Ray 中的作用是什么?如何实现高可用性? 对比 Ray 的任务(Task)与 Actor 模型,说明各自适用场景 解释 Ray 的 Object Store 如何实现跨节点数据共享与零拷贝传输 Ray 的分布式调度器如何实现毫秒级…...
Java虚拟机JVM知识点(持续更新)
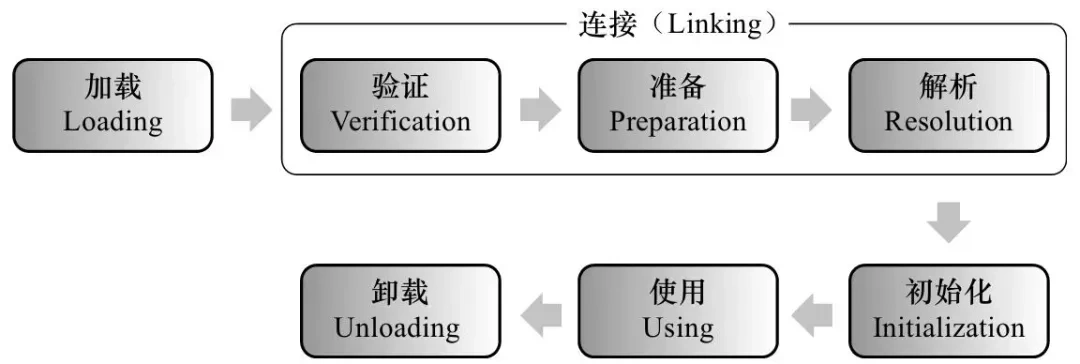
JVM内存模型 介绍下内存模型 根据JDK8的规范,我们的JVM内存模型可以拆分为:程序计数器、Java虚拟机栈、堆、元空间、本地方法栈,还有一部分叫直接内存,属于操作系统的本地内存,也是可以直接操作的。 详细解释一下 程…...

【计算机网络】HTTP与HTTPS
文章目录 1. HTTP定义2. HTTP交互3. HTTP报文格式3.1 抓包工具-fiddler3.2 抓包操作3.3 报文格式3.3.1 请求报文3.3.2 响应报文 4. URL5. 请求头中的方法6. GET和POST的区别7. HTTP报头7.1 Host7.2 Content_Length7.3 Content_Type7.4 User-Agent(UA)7.5 Referer7.6 Cookie 8 状…...

数据结构:树的5种存储方案详解(C语言完整实现)
数据结构中的树结构常用来存储逻辑关系为 "一对多" 的数据。树结构可以细分为两类,分别是二叉树和非二叉树(普通树),存储它们的方案是不一样的: 二叉树的存储方案有 2 种,既可以用顺序表存储二叉…...

【蓝桥杯】 枚举和模拟练习题
系列文章目录 蓝桥杯例题 枚举和模拟 文章目录 系列文章目录前言一、好数: 题目参考:核心思想:代码实现: 二、艺术与篮球: 题目参考:核心思想:代码实现: 总结 前言 今天距离蓝桥杯还有13天&…...

WebGL图形编程实战【3】:矩阵操控 × 从二维到三维的跨越
上一篇文章:WebGL图形编程实战【2】:动态着色 纹理贴图技术揭秘 仓库地址:github…、gitee… 矩阵操控 矩阵变换 回到前面关于平移缩放、旋转的例子当中,我们是通过改变传递进去的xy的值来改变的。 在进行基础变换的时候&…...

如何把数据从SQLite迁移到PostgreSQL
## 如何把数据从SQLite迁移到PostgreSQL 文章目录 1、DB-Engines 中的SQLite 和 PostgreSQL2、SQLite安装和测试2.1、编译安装SQLite2.2、数据测试 3、Postgresql安装和测试3.1、编译安装postgresql3.2、测试 4、pgloader安装5、数据迁移和验证5.1、准备参数文件5.2、数据迁移…...

Qt使用QGraphicsView绘制线路图————附带详细实现代码
文章目录 0 效果1 核心1.1 简单示例1.1.1 解读 1.2 创建用户交互1.2.1 完整示例 1.3 创建图形元1.3.1 绘制直线1.3.2 绘制贝塞尔曲线1.3.3 绘制图片 1.4 移动的小车 2 使用自定义视图类参考 0 效果 视图中包含线路、道岔、信号灯、火车。 下图为站点信号灯: 下图…...

【系统性偏见:AI照出的文明暗伤与生存悖论】
系统性偏见:AI照出的文明暗伤与生存悖论 第一层:偏见如何从数据中“遗传” 当某科技公司用十年招聘数据训练AI筛选简历时,系统悄然学会:提到"女性工程师协会"的简历,获得面试的概率自动下降37%——这相当于…...

【Linux】调试器——gdb使用
目录 一、预备知识 二、常用指令 三、调试技巧 (一)监视变量的变化指令 watch (二)更改指定变量的值 set var 正文 一、预备知识 程序的发布形式有两种,debug和release模式,Linux gcc/g出来的二进制…...

【数据分享】2000—2024年我国乡镇的逐年归一化植被指数(NDVI)数据(年最大值/Shp/Excel格式)
之前我们分享过2000-2024年我国逐年的归一化植被指数(NDVI)栅格数据,该逐年数据是取的当年月归一化植被指数(NDVI)的年最大值!另外,我们基于此年度栅格数据按照行政区划取平均值,得到…...
Shell 不神秘:拆解 Linux 命令行的逻辑与效率
初始shell shell的概述 什么是shell 本质 shell本质是脚本文件:完成批处理。 比如 有一个文件 中十个文件,这十个文件中每个文件又有是个子文件,由人来处理,很麻烦,但如果写一个脚本文件,让脚本来替我…...

win 远程 ubuntu 服务器 安装图形界面
远程结果:无法使用docker环境使用此方法 注意要写IP和:数字 在 ubuntu 服务器上安装如下: # 安装 sudo apt-get install tightvncserver # 卸载 sudo apt purge tightvncserver sudo apt autoremove#安装缺失的字体包: sudo apt update s…...