蓝耘平台API深度剖析:如何高效实现AI应用联动
目录
一、蓝耘平台简介
1.1 蓝耘通义大模型
1.2 蓝耘云计算资源
1.3 蓝耘API与微服务
二、 蓝耘平台应用联动场景
2.1 数据采集与预处理联动
2.2 模型推理与后端服务联动
2.3 跨平台联动
三、蓝耘平台注册+体验功能
3.1 注册
3.2 体验蓝耘MaaS平台如何使用海螺AI生成视频
3.3 如何调用Maas平台阿里QwQ?
四、蓝耘平台API调用示例
4.1 配置与初始化
4.2 数据上传与模型推理
4.3 数据格式和模型输入要求
五、总结
正文开始——
一、蓝耘平台简介
蓝耘平台不仅支持传统的AI模型训练和推理,还提供了自动化工具链来简化AI应用的部署过程。它可以为用户提供一站式的AI服务,帮助从数据处理、模型训练到推理应用的全生命周期管理。具体来说,蓝耘平台包含以下核心组件:
1.1 蓝耘通义大模型
蓝耘通义大模型是平台的核心之一,支持自然语言处理(NLP)、计算机视觉(CV)、语音识别等多个AI任务。通过该模型,用户可以快速进行模型训练和推理,简化了AI模型开发的复杂度。
1.2 蓝耘云计算资源
平台提供的云计算资源涵盖CPU、GPU、FPGA等多种硬件加速支持,可以为用户提供强大的计算能力,尤其在训练大型深度学习模型时,能够极大提高效率。
1.3 蓝耘API与微服务
蓝耘平台提供了完整的API接口,使得不同模块和服务之间可以通过API进行无缝集成。通过RESTful API,用户可以轻松调用AI模型进行推理,获取预测结果并进行后续的数据处理。
二、 蓝耘平台应用联动场景
在实际应用中,蓝耘平台的应用联动场景非常丰富,能够支持各种不同类型的AI任务和服务之间的协作。以下是一些常见的应用联动场景,涵盖了从数据采集、推理到后端服务应用的多种实现方式。
2.1 数据采集与预处理联动
在很多AI应用中,数据的采集与预处理是基础且重要的一环。例如,图像识别、文本分析、语音处理等任务通常都需要在输入数据上进行一定的预处理。蓝耘平台不仅支持数据上传,还提供强大的数据预处理工具,帮助用户将原始数据转化为符合模型输入要求的格式。
场景示例:
假设我们正在处理一个图像分类任务,用户需要上传图像文件,然后进行预处理,包括裁剪、缩放、归一化等操作,再将图像传递给模型进行推理。
数据采集与预处理的联动流程:
- 图像上传:用户通过接口上传图像。
- 数据预处理:在上传后,图像首先通过预处理函数进行裁剪、缩放、去噪等操作。
- 推理请求:预处理后的图像数据传递给AI模型进行推理,获取分类结果。
代码实现
假设我们上传的图像需要进行缩放和裁剪预处理,以下是一个完整的代码示例:
import requests
from PIL import Image
import io# 蓝耘平台API的基础URL
API_URL = "https://blueyun.aliyuncs.com/ai/inference"# 模型ID
model_id = "your_model_id"
headers = {"Authorization": "Bearer your-access-token"}# 图像预处理:缩放和裁剪
def preprocess_image(image_path):# 打开图像文件image = Image.open(image_path)# 缩放图像至指定大小(例如:256x256)image = image.resize((256, 256))# 可选择裁剪图像,如果需要特定的区域# image = image.crop((left, top, right, bottom))# 将图像转换为字节流,以便发送给APIimg_byte_array = io.BytesIO()image.save(img_byte_array, format='JPEG')img_byte_array = img_byte_array.getvalue()return img_byte_array# 上传图像并进行推理
def upload_and_infer(image_path):# 进行图像预处理preprocessed_image = preprocess_image(image_path)# 调用蓝耘API进行推理response = requests.post(API_URL, headers=headers, files={'file': preprocessed_image}, data={'model_id': model_id})if response.status_code == 200:result = response.json()return resultelse:raise Exception(f"Error during inference: {response.status_code}")# 调用函数进行图像分类推理
result = upload_and_infer("path_to_your_image.jpg")
print("推理结果:", result)
在这个例子中,我们通过PIL库对上传的图像进行预处理,包括缩放到指定大小,然后将其转换为字节流格式,通过API进行推理。这样一来,用户上传的图像就能符合模型的输入要求。
2.2 模型推理与后端服务联动
在一些应用中,AI模型的推理结果往往需要与后端服务进行联动。后端服务可能是一个数据库、业务逻辑系统,或者其他的API接口,推理结果需要进一步处理或提供更多的数据支持。例如,智能客服系统在处理用户输入时,需要先通过NLP模型识别用户意图,再根据业务逻辑给出响应。
场景示例:
假设我们正在开发一个智能客服系统,用户通过文本输入问题,系统首先使用NLP模型识别意图,接着调用后端的业务逻辑服务获取相关信息,再返回给用户。
模型推理与后端服务联动的流程:
- 文本输入:用户通过接口输入问题文本。
- NLP推理:系统通过蓝耘平台的NLP模型分析用户意图。
- 调用后端API:根据用户的意图,调用后端服务(例如查询订单状态、获取天气信息等)。
- 生成响应:系统将后端服务的数据与NLP模型的推理结果结合,生成最终的回复。
代码实现
以下是一个示例,展示如何在文本分类模型推理后,结合后端API(例如查询天气信息)生成响应:
import requests# 蓝耘平台的NLP API URL
NLP_API_URL = "https://blueyun.aliyuncs.com/nlp/intent"
headers = {"Authorization": "Bearer your-access-token"}# 后端天气查询API
WEATHER_API_URL = "https://api.weather.com/v3/wx/conditions/current"# 进行NLP推理
def nlp_inference(user_input):data = {"text": user_input}response = requests.post(NLP_API_URL, headers=headers, json=data)if response.status_code == 200:return response.json()else:raise Exception("Error during NLP inference")# 根据NLP解析结果调用后端API(例如查询天气)
def query_weather(location):params = {"city": location, "apiKey": "your-weather-api-key"}response = requests.get(WEATHER_API_URL, params=params)if response.status_code == 200:return response.json()else:raise Exception("Error during weather query")# 主函数:将NLP推理与后端服务联动
def handle_user_query(user_input):nlp_result = nlp_inference(user_input)print(f"NLP解析结果: {nlp_result}")# 如果用户查询的是天气信息if "天气" in nlp_result['intent']:location = nlp_result['location']weather_data = query_weather(location)return f"当前{location}的天气是:{weather_data['temperature']}°C,{weather_data['description']}。"else:return "抱歉,我无法理解您的问题。"# 示例调用
user_input = "北京今天的天气如何?"
response = handle_user_query(user_input)
print("系统回复:", response)2.3 跨平台联动
在一些复杂的应用中,蓝耘平台不仅需要与内部系统联动,还需要与外部平台进行协同。例如,企业的CRM系统、ERP系统或者第三方数据服务可能需要与蓝耘平台的AI模型进行联动,以便自动化处理大量数据,提升业务效率。
场景示例:
例如,企业利用蓝耘平台的AI能力,结合自身的CRM系统,自动分析客户的行为数据,为销售人员提供个性化的客户管理建议。
跨平台联动的流程:
- 数据采集:从企业的CRM系统或其他外部系统中采集数据。
- AI推理:将采集的数据传输至蓝耘平台进行AI分析,例如客户行为预测。
- 返回分析结果:将分析结果返回企业内部系统,为决策提供支持。
代码实现
以下是跨平台联动的代码示例:
import requests# 假设这是从企业内部系统采集的数据
crm_data = {"customer_id": 12345, "purchase_history": [10, 25, 45]}# 蓝耘平台API进行客户行为预测
AI_PREDICTION_API = "https://blueyun.aliyuncs.com/ai/predict"# 进行客户行为预测
def predict_customer_behavior(customer_data):response = requests.post(AI_PREDICTION_API, json=customer_data, headers={"Authorization": "Bearer your-access-token"})if response.status_code == 200:return response.json()else:raise Exception("Error during AI prediction")# 调用预测API并返回结果
prediction = predict_customer_behavior(crm_data)
print("客户行为预测结果:", prediction)在此代码示例中,我们通过CRM系统的接口收集客户的购买历史数据,然后将其传递给蓝耘平台进行AI推理。根据推理结果,企业可以调整营销策略,提高客户管理效率。
三、蓝耘平台注册+体验功能
3.1 注册
可以点击链接进行注册操作【https://cloud.lanyun.net//#/registerPage?promoterCode=0131】

3.2 体验蓝耘MaaS平台如何使用海螺AI生成视频




3.3 如何调用Maas平台阿里QwQ?




#include <iostream>
#include <cstdlib> // 用于随机数函数
#include <ctime> // 用于随机数种子
using namespace std;// 交换两个元素
void swap(int* a, int* b) {int temp = *a;*a = *b;*b = temp;
}// 随机选择主元的分区函数(Lomuto 分区方案)
int randomizedPartition(int arr[], int low, int high) {// 1. 随机选择主元位置(降低有序数组的最坏时间复杂度)int pivotIndex = low + rand() % (high - low + 1); // 随机选择 [low, high] 区间的一个索引swap(arr[pivotIndex], arr[high]); // 将随机选择的主元与最后一个元素交换int pivot = arr[high]; // 现在以最后一个元素作为主元int i = low - 1; // 标记小于等于主元的区域右边界// 2. 遍历数组,将小于等于主元的元素移动到左侧for (int j = low; j < high; j++) {if (arr[j] <= pivot) { // 允许等于主元的元素也移动到左侧(避免无限递归)i++;swap(arr[i], arr[j]);}}// 3. 将主元放到最终位置swap(arr[i + 1], arr[high]);return i + 1; // 返回主元的位置
}// 快速排序递归实现(使用随机主元)
void quickSort(int arr[], int low, int high) {if (low < high) {int pi = randomizedPartition(arr, low, high); // 获取分区后的主元位置quickSort(arr, low, pi - 1); // 递归排序左半部分quickSort(arr, pi + 1, high); // 递归排序右半部分}
}// 测试代码
int main() {// 初始化随机数种子(使每次运行结果不同)srand(time(0));int arr[] = {5, 1, 9, 2, 7, 3, 8, 4, 6};int n = sizeof(arr) / sizeof(arr[0]);cout << "原始数组: ";for (int x : arr) cout << x << " ";cout << endl;quickSort(arr, 0, n - 1);cout << "排序后的数组: ";for (int x : arr) cout << x << " ";cout << endl;return 0;
}四、蓝耘平台API调用示例
在蓝耘平台上,API调用是进行应用联动的核心方式之一。通过API,开发者可以实现与平台服务的交互,比如上传数据、调用AI模型进行推理、获取结果等。在这一部分,我们将深入讲解如何使用蓝耘平台的API进行调用,涵盖初始化、数据上传、模型推理、异常处理等内容,并提供多个示例代码。
4.1 配置与初始化
在开始调用蓝耘平台的API之前,我们需要进行一些基本的配置与初始化操作。这些步骤包括获取API访问的凭证(如access_token或API Key)、设置API请求头、指定模型ID等。
蓝耘平台的API一般采用基于HTTP请求的方式,支持GET、POST等请求方法。在初始化时,最重要的操作是设置API Key或Token,确保所有请求都可以通过认证。
示例:API初始化
import requests# 蓝耘平台API基础URL
BASE_URL = "https://blueyun.aliyuncs.com/"# 设置API访问凭证
API_KEY = 'your_api_key'
API_SECRET = 'your_api_secret'
ACCESS_TOKEN = 'your_access_token'# 设置请求头部
headers = {'Authorization': f'Bearer {ACCESS_TOKEN}','Content-Type': 'application/json'
}在这个例子中,我们初始化了API的基础URL和请求头。为了保证API调用的安全性,我们使用了Bearer token方式进行身份验证。如果您使用的是API Key和API Secret,您可以按照平台文档中的方式进行签名和加密。
4.2 数据上传与模型推理
在蓝耘平台上,上传数据并请求推理结果是最常见的操作之一。例如,对于图像分类任务,我们通常需要将图像上传至平台进行处理。上传的数据可以通过POST请求进行传输,图像数据一般需要转换成二进制格式。推理请求可以将图像数据与其他必要的参数一起传递给API。
示例:上传图像并进行推理
from PIL import Image
import io
import requests# 蓝耘平台推理API URL
INFERENCE_URL = f"{BASE_URL}/ai/inference"# 图像上传和预处理
def preprocess_image(image_path):# 打开图像文件并进行预处理image = Image.open(image_path)image = image.resize((256, 256)) # 假设模型要求256x256的输入图像# 将图像转换为二进制格式img_byte_array = io.BytesIO()image.save(img_byte_array, format='JPEG')img_byte_array = img_byte_array.getvalue()return img_byte_array# 调用API进行推理
def infer_with_image(image_path):# 进行图像预处理preprocessed_image = preprocess_image(image_path)# 构建推理请求response = requests.post(INFERENCE_URL,headers=headers,files={'file': preprocessed_image},data={'model_id': 'your_model_id'})if response.status_code == 200:return response.json()else:raise Exception(f"Error during inference: {response.status_code}")# 示例:上传图像进行推理
image_path = "path_to_your_image.jpg"
result = infer_with_image(image_path)
print("推理结果:", result)在这个例子中,我们使用Python的PIL库处理图像,并将其转换为二进制格式以便上传。接着,我们通过蓝耘平台的推理API调用模型进行图像分类,最终输出推理结果。这个代码展示了如何从上传图像到获取结果的完整流程。
4.3 数据格式和模型输入要求
在进行API调用时,数据格式和模型的输入要求至关重要。不同的模型可能会有不同的数据格式要求。例如,图像分类模型通常要求输入图像为特定大小(如224x224或256x256),并且可能需要进行归一化处理;而NLP模型则要求输入为文本数据,可能需要进行分词和编码。
图像分类模型的输入要求
大多数图像分类任务要求输入图像为固定尺寸的RGB图像。如果您的图像尺寸与模型的输入要求不一致,您需要进行缩放和裁剪。此外,图像一般还需要归一化处理,即将像素值缩放到[0, 1]的范围内。
from PIL import Image
import numpy as npdef preprocess_image_for_model(image_path):# 打开图像并缩放到224x224image = Image.open(image_path)image = image.resize((224, 224))# 转换为RGB格式image = image.convert('RGB')# 将图像转换为NumPy数组image_array = np.array(image)# 归一化处理(假设模型要求输入值在0到1之间)image_array = image_array / 255.0return image_array五、总结
通过本文的详细介绍,我们深入了解了如何使用蓝耘平台的API进行各种操作,包括数据上传、模型推理、异常处理和批量推理。无论是在处理图像数据、文本数据,还是在实际应用中进行大规模的AI推理,蓝耘平台提供的强大功能和API接口都能帮助开发者快速实现智能应用。
在实际开发过程中,合理使用API,优化数据处理和推理流程,可以大大提升系统的响应速度和处理效率。同时,良好的异常处理和错误管理机制,能够确保系统在遇到问题时能够稳定运行,避免崩溃或性能下降。希望通过本文的示例代码,您能够更好地理解如何在蓝耘平台上实现高效、灵活的AI应用开发。
完——
相关文章:
蓝耘平台API深度剖析:如何高效实现AI应用联动
目录 一、蓝耘平台简介 1.1 蓝耘通义大模型 1.2 蓝耘云计算资源 1.3 蓝耘API与微服务 二、 蓝耘平台应用联动场景 2.1 数据采集与预处理联动 2.2 模型推理与后端服务联动 2.3 跨平台联动 三、蓝耘平台注册体验功能 3.1 注册 3.2 体验蓝耘MaaS平台如何使用海螺AI生成视频…...

缓存 “三剑客”
缓存 “三剑客” 问题 如何保证 Redis 缓存和数据库的一致性? 1. 缓存穿透 缓存穿透是指请求一个不存在的数据,缓存层和数据库层都没有这个数据,这种请求会穿透缓存直接到数据库进行查询 解决方案: 1.1 缓存空值或特殊值 查一…...

ComfyUi教程之阿里的万象2.1视频模型
ComfyUi教程之阿里的万象2.1视频模型 官网Wan 2.1 特点 一、本地安装1.1克隆仓库1.2 安装依赖(1.3)下载模型(1.4)CUDA和CUDNN 二、 使用体验(2.1)官方例子(2.2)执行过程(…...

⭐算法OJ⭐ 戳气球【动态规划】Burst Balloons
问题描述 LeetCode 312. 戳气球(Burst Balloons) 给定 n 个气球,编号从 0 到 n-1,每个气球上标有一个数字 nums[i]。戳破气球 i 可以获得 nums[left] * nums[i] * nums[right] 的硬币(left 和 right 是 i 的相邻气球&…...

Leetcode 寻找两个正序数组的中位数
💯 完全正确!!你这段话可以直接当作这道题的**“思路总览”模板答案**了,结构清晰、逻辑严谨、几乎没有遗漏任何关键点👏 不过我可以帮你稍微精炼一下语言,使它在保留你原本意思的基础上更具表达力和条理性…...
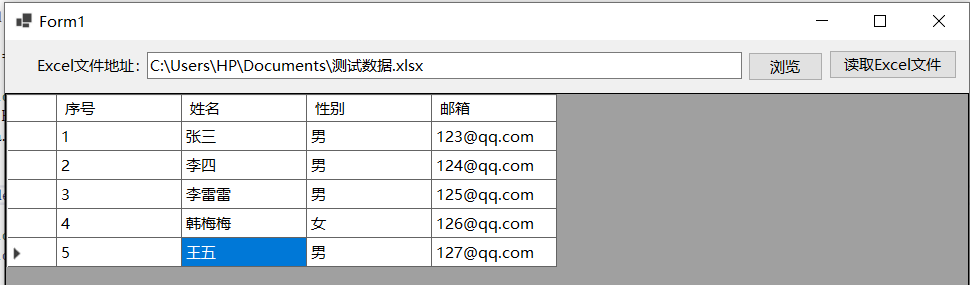
C#测试Excel开源组件ExcelDataReader
使用微软的com组件Microsoft.office.Interop.Excel读写Excel文件虽然可用,但是列多、行多的时候速度很慢,之前测试过Sylvan.Data.Excel包的用法,如果只是读取Excel文件内容的话,还可以使用ExcelDataReader包,后者是C#开…...

手机零售行业的 AI 破局与创新降本实践 | OceanBase DB大咖说
OceanBase《DB 大咖说》第 20 期,我们邀请了九机与九讯云的技术总负责人,李远军,为我们分享手机零售企业如何借力分布式数据库OceanBase,赋能 AI 场景,并通过简化架构实现成本管控上的突破与创新。 李远军于2016年加入…...

SQL Server 动态构建 SQL 语句学习指南
在 SQL Server 中,动态构建 SQL 语句应用于各种场景,包括动态表名、列名,动态 WHERE 条件,以及动态分页、排序等。本文将详细计划如何在 SQL Server 中最佳实现动态 SQL 语句构建。 一、动态 SQL 的应用场景 动态表名或列名动态…...

Ceph与Bacula运维实战:数据迁移与备份配置优化指南
#作者:猎人 文章目录 1ceph数据迁移&&bacula配置调整1.1ceph数据迁移&&bacula配置调整1.2在备份服务器的ceph-client上mount cephfs文件系统1.2.1迁移数据1.2.2调整bacula-sd配置 1ceph数据迁移&&bacula配置调整 1.1ceph数据迁移&&am…...

Spring Boot分布式项目重试实战:九种失效场景与正确打开方式
在分布式系统架构中,网络抖动、服务瞬时过载、数据库死锁等临时性故障时有发生。本文将通过真实项目案例,深入讲解Spring Boot项目中如何正确实施重试机制,避免因简单粗暴的重试引发雪崩效应。 以下是使用Mermaid语法绘制的重试架构图和决策…...

Android OTA升级中SettingsProvider数据库升级的深度解析与完美解决方案
一、问题场景:OTA升级引发的系统属性"失效"之谜 在某Android 12.0系统定制项目中,我们遭遇了一个棘手问题:当通过OTA升级新增/修改SettingsProvider系统属性后,必须恢复出厂设置才能生效。这不仅导致用户数据丢失风险&…...

[Html]overflow: auto 失效原因,flex 1却未设置min-height overflow的几个属性以及应用场景
一、overflow: auto 失效原因分析 1. 未设置固定高度或宽度 • 当容器未定义具体尺寸时,浏览器无法判断内容是否溢出,导致滚动条不生效。需为容器添加 height 或 width 属性(如 height: 300px)。 • 示例: css .cont…...
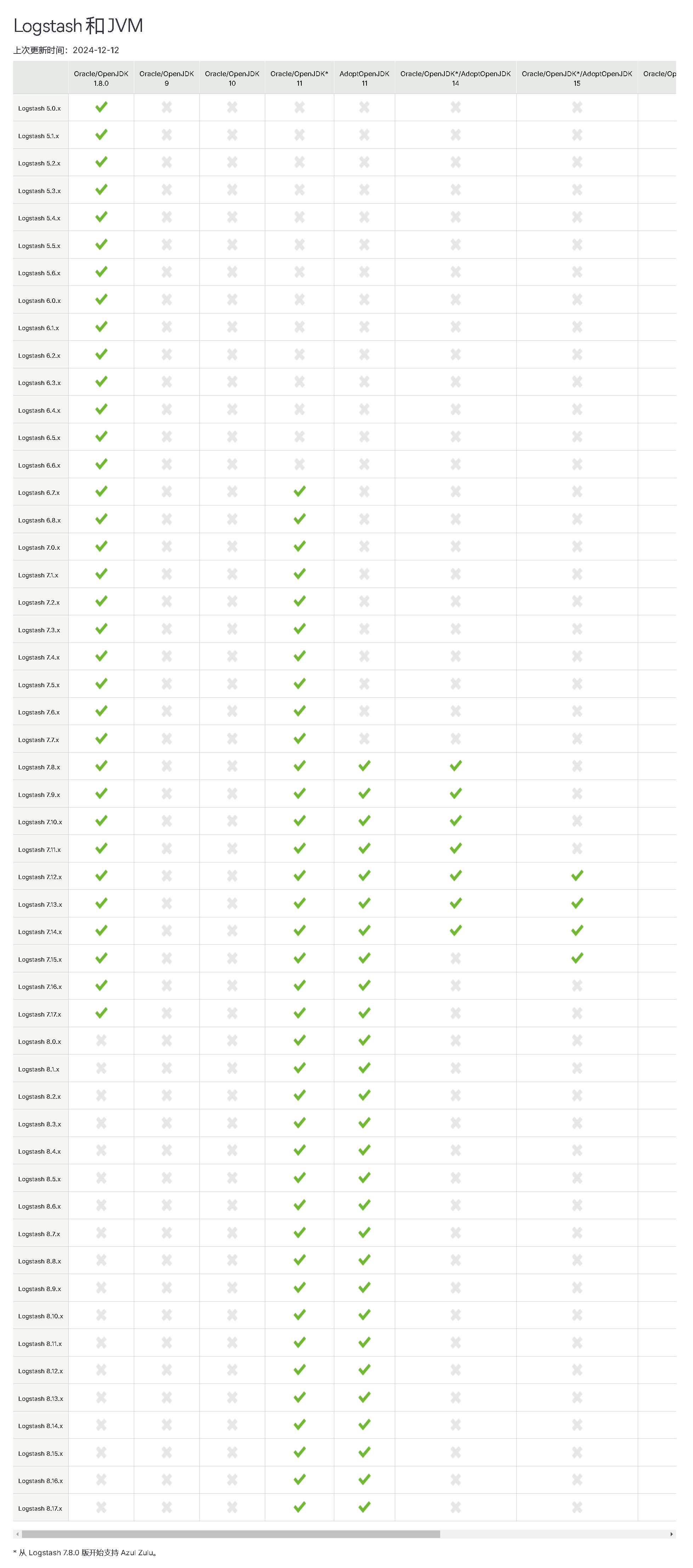
SpringBoot整合LogStash,LogStash采集服务器日志
LogStash 1. 下载 版本支持兼容表https://www.elastic.co/cn/support/matrix 版本: 7.16.x 的最后一个版本 https://www.elastic.co/downloads/past-releases/logstash-7-16-3 需要提前安装好jdk1.8和ES, 此处不在演示 2. 安装 tar -xvf logstash-7.16.3-linux-x86_64.tar.gz…...

LLM - 推理大语言模型 DeepSeek-R1 论文简读
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/146840732 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 DeepSeek-R1 通过强化学习,显著提升大语言模型推理能力,使用特殊的训…...

目前市场上,好用的校招系统是哪个?
在数字化浪潮的推动下,校园招聘已从传统的“海投简历线下宣讲”模式全面转向智能化、数据化。面对每年数百万应届生的激烈竞争,企业如何在短时间内精准筛选人才、优化招聘流程、降低人力成本?答案或许藏在AI驱动的校招管理系统中。而在这场技…...

Oracle logminer详解
Oracle LogMiner 是 Oracle 数据库提供的一个内置工具,用于分析和挖掘数据库的在线重做日志文件(Online Redo Log Files)和归档日志文件(Archive Log Files)。通过 LogMiner,用户可以查看数据库的历史操…...
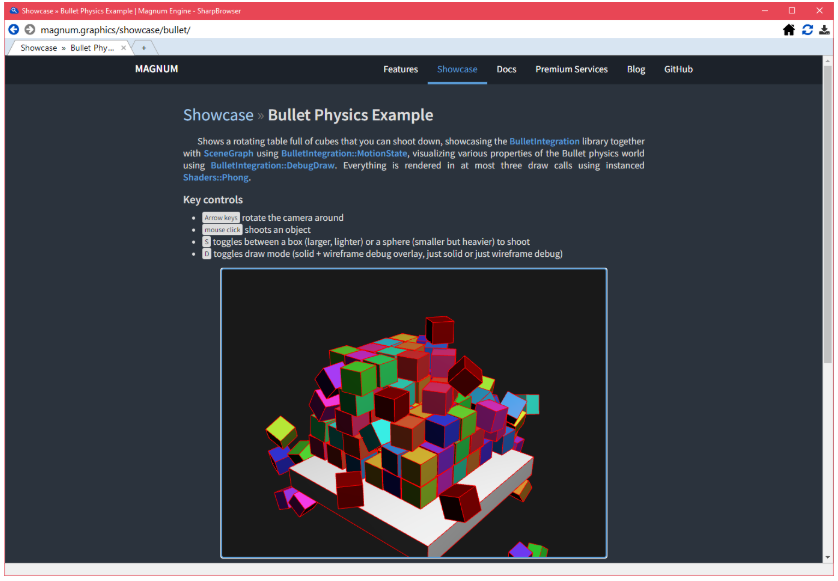
SharpBrowser:用C#打造超快的个性化开源浏览器!
推荐一个基于.Net 8 和 CefSharp开发的开源浏览器。 01 项目简介 SharpBrowser 是一个用 C# 和 CefSharp 开发的全功能网页浏览器。它声称是最快的开源 C# 网页浏览器,渲染网页的速度比谷歌浏览器还快,因为其使用轻量级的 CEF 渲染器。 经过比较所有可…...

【企业级Web应用中的文件下载处理:从S3预签名URL到压缩状态管理】
企业级Web应用中的文件下载处理:从S3预签名URL到压缩状态管理 1. 引言:一个看似简单的下载功能背后 在开发企业级Web应用时,文件下载功能看似简单,却常常隐藏着诸多技术挑战。近期,我们在一个xx申报系统项目中&#…...

【新模型速递】PAI一键云上零门槛部署DeepSeek-V3-0324、Qwen2.5-VL-32B
DeepSeek近期推出了“DeepSeek-V3-0324”版本,据测试在数学推理和前端开发方面的表现已优于 Claude 3.5 和 Claude 3.7 Sonnet。 阿里也推出了多模态大模型Qwen2.5-VL的新版本--“Qwen2.5-VL-32B-Instruct”,32B参数量实现72B级性能,通杀图文…...
现代C++的关键性概念: 如何利用多维数组的指针安全地遍历所有元素)
[原创](Modern C++)现代C++的关键性概念: 如何利用多维数组的指针安全地遍历所有元素
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、C …...
)
flask开发中设置Flask SQLAlchemy 的 db.Column 只存储非负整数(即 0 或正整数)
如果你想控制一个 Flask SQLAlchemy 的 db.Column 只存储非负整数(即 0 或正整数),你可以在模型中使用验证来确保这一点。一种常见的方法是使用模型的 validate 方法或者在执行插入或更新操作时进行检查。 以下是实现这一目标的几种方法&…...

【Elasticsearch基础】基本核心概念介绍
Elasticsearch作为当前最流行的分布式搜索和分析引擎,其强大的功能背后是一套精心设计的核心概念体系。本文将深入解析Elasticsearch的五大核心概念,帮助开发者构建坚实的技术基础,并为高效使用ES提供理论支撑。 1 索引(Index&…...

Github 热点项目 awesome-mcp-servers MCP 服务器合集,3分钟实现AI模型自由操控万物!
【今日推荐】超强AI工具库"awesome-mcp-servers"星数破万! ① 百宝箱式服务模块:AI能直接操作浏览器、读文件、连数据库,比如让AI助手自动整理Excel表格,三分钟搞定全天报表; ② 跨领域实战利器:…...

SpringMVC 拦截器(Interceptor)
一.拦截器 假设有这么一个场景,一个系统需要用户登录才能进入,在检验完用户的信息后对页面进行了跳转。但是如果我们直接输入跳转的url,可以绕过用户信息校验(用户登录),直接进入系统。 因此我们引入了使…...

【NLP】16. NLP推理方法重点回顾 -- 52道多选题
Which of the following problems are commonly solved using sequence tagging? A) Named Entity Recognition (NER) B) Part-of-Speech (POS) Tagging C) Word Embedding Training D) Syntactic Dependency Parsing 序列标注是一种 NLP 任务,常用于 命名实体…...

Redisson分布式锁深度解析:原理与实现机制
Redisson作为Redis Java客户端中的分布式解决方案佼佼者,其分布式锁实现被广泛应用于生产环境。以下从底层设计到源码实现进行全面剖析。 一、核心架构设计 1. 整体架构图 graph LRA[客户端] --> B[RLock接口]B --> C[RedissonLock]C --> D[Redis命令执…...

Linux 系统调用实现机制详解
Linux 系统调用实现机制详解 —— fork()、execve()、waitpid() 内核层面的秘密 在 Linux 内核中,fork()、execve() 和 waitpid() 是构建多任务操作系统的三大基石,它们涉及进程控制、内存管理、文件系统等多个子系统。本文将带你一探它们在 内核层面的…...

责任链模式_行为型_GOF23
责任链模式 责任链模式(Chain of Responsibility Pattern)是一种行为型设计模式,核心思想是将多个处理请求的对象连成一条链,请求沿链传递直到被处理。它像现实中的“多级审批流程”——请假或报销时,申请会逐级提交给…...

03-SpringBoot3入门-配置文件(自定义配置及读取)
1、自定义配置 # 自定义配置 zbj:user:username: rootpassword: 123456# 自定义集合gfs:- a- b- c2、读取 1)User类 package com.sgu.pojo;import lombok.Data; import org.springframework.boot.context.properties.ConfigurationProperties; import org.spring…...

学习记录-软件测试基础
一、软件测试分类 1.按阶段:单元测试(一般开发自测)、集成测试、系统测试、验收测试 2.按代码可见度测试:黑盒测试、灰盒测试、白盒测试 3.其他:冒烟测试(冒烟测试主要是在开发提测后进行,主要是测试主流…...