npu踩坑记录
之前使用qwen系列模型在ascend 910a卡进行了一些生成任务, 贴出踩坑过程也许对遇到类似问题的同学有帮助: )
目录
千问 qwq32环境配置
代码部署
生成内容清洗
已生成内容清洗
生成过程优化
Failed to initialize the HCCP process问题
assistant 的历史回答丢失
推理执行失败
千问 qwq32环境配置
该模型为慢思考模型,思考过程可能没用,思考结果有用
创建开发环境使用qwq-32b镜像
根据训练作业可以找到模型位置, 启动代码
代码部署
更换模型千问 qwq32
生成内容清洗
content末尾的<|im_end|>处理
进行字符串处理
原先的处理代码:
| cleaned_text = generated_text1.strip().replace("```markdown", "").replace("```", "") |
现在通过正则匹配保留</think>之后, <|im_end|>之前的文字:
| import re def clean_text(generated_text1): # 先去掉不需要的 markdown 标记 cleaned_text = generated_text1.strip().replace("```markdown", "").replace("```", "")
# 使用正则匹配 </think> 之后,<|im_end|> 之前的内容 match = re.search(r'</think>(.*?)<\|im_end\|>', cleaned_text, re.DOTALL)
if match: return match.group(1).strip() # 提取内容并去除前后空格 else: return "" # 如果没有匹配,返回空字符串 # 测试样例 generated_text1 = """ Hello, this is some text. </think> ```markdown This is the part we want to keep. ```<|im_end|> More text here. """ cleaned_text = clean_text(generated_text1) print(cleaned_text) |
已生成内容清洗
对已经生成的数据使用clean_text进行清洗.
遍历文件夹中所有文件:
| import os def read_all_files(folder_path): """ 读取指定文件夹内所有文件的内容并依次输出 :param folder_path: 文件夹路径 """ if not os.path.isdir(folder_path): print("错误:提供的路径不是一个有效的文件夹") return # 遍历文件夹中的所有文件 for filename in os.listdir(folder_path): file_path = os.path.join(folder_path, filename) # 仅处理普通文件(跳过文件夹) if os.path.isfile(file_path): try: with open(file_path, 'r', encoding='utf-8') as f: content = f.read() print(f"===== 文件: {filename} =====") print(content) print("\n") except Exception as e: print(f"无法读取文件 {filename}: {e}") # 指定要读取的文件夹路径 folder_path = "your_folder_path_here" read_all_files(folder_path) |
生成过程优化
生成中间结果知识点保留
分为outlines generation和contents generation, outlines generation保存生成的知识点, contents generation读取生成的知识点
Failed to initialize the HCCP process问题
Warmup拉不起来时候会报错:
| EJ0001: [PID: 2369411] 2025-03-24-19:23:56.333.074 Failed to initialize the HCCP process. Reason: Maybe the last training process is running. Solution: Wait for 10s after killing the last training process and try again. |
参考:
https://llamafactory.readthedocs.io/zh-cn/latest/advanced/npu.html
https://github.com/hiyouga/LLaMA-Factory/issues/3839
| 解决Failed to initialize the HCCP process问题 local_rank = int(os.environ["LOCAL_RANK"]) torch_npu.npu.set_device(local_rank) |
pkill -9 python
杀掉device侧所有进程,等待10s后重新启动训练。
这些方法都用上,看到显存使用量终于降下来了,过了下再启动就好了
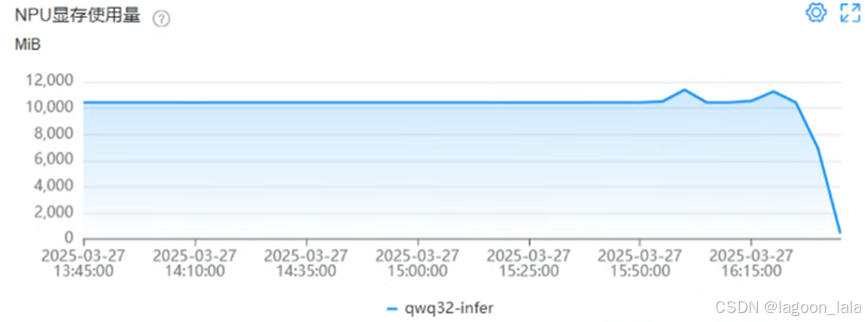
assistant 的历史回答丢失
现在成功读取后发现, 将知识点放入模板再输入模型进行推理的时候这些知识点消失了.
在使用qwen系列大模型qwq32B进行多轮对话时, 'role'为'assistent'的内容不包含在apply_chat_template后的text中, 解决这个问题
| messages=[ {'role': 'assistent', 'content': outline}, {'role': 'user', 'content': prompt1} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) |
qwq32B的主页为https://huggingface.co/Qwen/QwQ-32B
该代码使用ascend的is_chat_model模式运行, 是否会导致apply_chat_template()自动忽略 assistant 的历史回答
当 is_chat_model=True 时:
- apply_chat_template() 可能会自动忽略 assistant 的历史回答,因为 Qwen 的 apply_chat_template 可能会:
- 仅格式化 user 提供的 messages,而 不会 把 assistant 的历史回答包含进去。
- 这就可能导致 assistant 的内容丢失,需要手动补全历史对话。
搜索关键词:
tokenizer.apply_chat_template
qwen
templates-for-chat-models:
https://huggingface.co/docs/transformers/main/chat_templating?template=Zephyr#templates-for-chat-models
模型可能具有几个不同的模板,用于不同的用例。例如,模型可能具有用于常规聊天,工具使用和rag的模板。
When there are multiple templates, the chat template is a dictionary. Each key corresponds to the name of a template. apply_chat_template handles multiple templates based on their name. It looks for a template named default in most cases and if it can’t find one, it raises an error.当有多个模板时,聊天模板是字典。每个键对应于模板的名称。 apply_chat_template根据其名称处理多个模板。在大多数情况下,它寻找一个名为default的模板
To access templates with other names, pass the template name to the chat_template parameter in apply_chat_template. For example, if you’re using a RAG template then set chat_template="rag".要使用其他名称访问模板,请将模板名称传递到chat_template <b1>> </b1>中的参数。例如,如果您使用的是rag模板,则设置chat_template="rag"。
设置模板:
| tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}" |
查看和编辑模板:
https://huggingface.co/docs/transformers/main/chat_templating_writing
| template = tokenizer.chat_template template = template.replace("SYS", "SYSTEM") # Change the system token tokenizer.chat_template = template # Set the new template |
The template is saved in the tokenizer_config.json file. Upload it to the Hub with push_to_hub() so you can reuse it later and make sure everyone is using the right template for your model.模板保存在tokenizer_config.json文件中。
通过设置chat_template属性添加聊天模板,并使用apply_chat_template()对其进行测试。如果它按预期工作,则可以使用push_to_hub()上传到hub上,以便您稍后重复使用并确保每个人都使用正确的模板为模型。
| tokenizer.push_to_hub("model_name") |
下载tokenizer_config.json
这是qwen的模板与role为assistant相关部分:
| "chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- '' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" and not message.tool_calls %}\n {%- set content = message.content.split('</think>')[-1].lstrip('\\n') %}\n {{- '<|im_start|>' + message.role + '\\n' + content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {%- set content = message.content.split('</think>')[-1].lstrip('\\n') %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n<think>\\n' }}\n{%- endif %}\n", |
模板的含义
模板中与 assistant 角色相关的部分主要负责将模型过去生成的回答(以及可能的工具调用信息)以特定格式纳入对话上下文,以便后续生成时参考。具体来说,有两个分支:
- 纯回答的情况(无工具调用):
当消息的 role 为 "assistant" 且没有 tool_calls 时,模板会对 message.content 做如下处理:- 它会先用 message.content.split('</think>')[-1] 取出最后一个 </think> 标签后的内容,并去除开头的换行符(lstrip('\n')),这通常表示模型的“思考”部分已经结束,只保留最终的回答文本。
- 然后,这段回答会被包裹在 <|im_start|>assistant\n ... <|im_end|>\n 标签之间,从而作为完整的 assistant 消息嵌入整个对话历史中。
- 包含工具调用的情况:
当 assistant 消息中存在 tool_calls 时(即模型在回答过程中调用了外部函数),模板会进行如下操作:- 同样先提取出回答部分(分割后取最后部分并去除前导换行),并输出 <|im_start|>assistant 后跟上这部分内容(如果存在)。
- 接着,对 message.tool_calls 进行循环处理。对于每个工具调用(如果 tool_call.function 定义了,则取其内容),模板会生成一个块:
- 该块以 <tool_call> 开始,内部以 JSON 格式输出调用的函数名("name")和参数("arguments",使用 tojson 转换),最后以 </tool_call> 结束。
- 最终,再以 <|im_end|>\n 结束整个 assistant 消息的输出。
此外,在所有消息处理完后,如果设置了 add_generation_prompt,模板会追加 <|im_start|>assistant\n<think>\n
因此尝试在开头加入think结束的token, 看是否能获取到内容
加入后还是没有, debug发现他们把关键词拼错了, assistant拼成assistent了
修改后可以正常保留历史回复并进行生成
推理执行失败
推理输入包含知识点后推理执行失败
他们的推理外异常捕获没有输出异常信息, 不利于调试, 因此增加打印异常信息
优化报错日志方便debug,参考:
https://www.cnblogs.com/klchang/p/4635040.htmle
| except: except Exception as e: # print(catalog data) log info(ENV.rank, f'generate content error: repr(e)}') logging.error(f'{'{catalog data} \n generate content error') |
打印错误信息如下:
| ValueError('req: 0 out of memory, need block:144 is more than free generate content error: block 136') |
出现这个问题一般是参数max_input_length不够大, (输入长度2048不够)调大参数后启动推理成功
相关文章:
npu踩坑记录
之前使用qwen系列模型在ascend 910a卡进行了一些生成任务, 贴出踩坑过程也许对遇到类似问题的同学有帮助: ) 目录 千问 qwq32环境配置 代码部署 生成内容清洗 已生成内容清洗 生成过程优化 Failed to initialize the HCCP process问题 assistant 的历史回答丢失 推理执…...

Linux信号——信号的产生(1)
注:信号vs信号量:两者没有任何关系! 信号是什么? Linux系统提供的,让用户(进程)给其他进程发送异步信息的一种方式。 进程看待信号的方式: 1.信号在没有发生的时候,进…...

【机器学习】——机器学习思考总结
摘要 这篇文章深入探讨了机器学习中的数据相关问题,重点分析了神经网络(DNN)的学习机制,包括层级特征提取、非线性激活函数、反向传播和梯度下降等关键机制。同时,文章还讨论了数据集大小的标准、机器学习训练数据量的…...

html处理Base文件流
处理步骤 从服务返回的字符串中提取文件流数据,可能是Base64或二进制。将数据转换为Blob对象。创建对象URL。创建<a>元素,设置href和download属性。触发点击事件以下载文件。删除缓存数据 代码 // 假设这是从服务返回的Base64字符串(…...

力扣每日一题:2712——使所有字符相等的最小成本
使所有字符相等的最小成本 题目示例示例1示例2 题解这些话乍一看可能看不懂,但是多读两遍就明白了。很神奇的解法,像魔术一样。 题目 给你一个下标从 0 开始、长度为 n 的二进制字符串 s ,你可以对其执行两种操作: 选中一个下标…...
:深入了解QMfcApp)
在MFC中使用Qt(六):深入了解QMfcApp
前言 此前系列文章回顾: 在MFC中使用Qt(一):玩腻了MFC,试试在MFC中使用Qt!(手动配置编译Qt) 在MFC中使用Qt(二):实现Qt文件的自动编译流程 在M…...

JMeter进行分布式压测
从机: 1、确认防火墙是否关闭; 2、打开网络设置,关闭多余端口;(避免远程访问不到) 3、打开JMeter/bin 目录底下的jmeter.properties; remove_hosts设置当前访问地址,192.XXXXX&…...

Python实现音频数字水印方法
数字水印技术可以将隐藏信息嵌入到音频文件中而不明显影响音频质量。下面我将介绍几种在Python中实现音频数字水印的方法。 方法一:LSB (最低有效位) 水印 import numpy as np from scipy.io import wavfile def embed_watermark_lsb(audio_path, watermark, ou…...
快速入手-基于Django-rest-framework的第三方认证插件(SimpleJWT)权限认证扩展返回用户等其他信息(十一)
1、修改serializer.py,增加自定义类 # 自定义用户登录token等返回信息 class MyTokenObtainPair(TokenObtainPairView): def post(self, request, *args, **kwargs): serializer self.get_serializer(datarequest.data) try: serializer.is_valid(raise_exceptio…...

关于IP免实名的那些事
IP技术已成为个人与企业保护隐私、提升网络效率的重要工具。其核心原理是通过中介服务器转发用户请求,隐藏真实IP地址,从而实现匿名访问、突破地域限制等目标。而“免实名”代理IP的出现,进一步简化了使用流程,用户无需提交身份信…...

【SQL性能优化】预编译SQL:从注入防御到性能飞跃
🔥 开篇:直面SQL的"阿喀琉斯之踵" 假设你正在开发电商系统🛒,当用户搜索商品时: -- 普通SQL拼接(危险!) String sql "SELECT * FROM products WHERE name "…...

Spring容器从启动到关闭的注解使用顺序及说明
Spring容器从启动到关闭的注解使用顺序及说明 1. 容器启动阶段 注解:Configuration、ComponentScan 作用: Configuration:标记配置类,声明Spring应用上下文的配置源。ComponentScan:扫描指定包下的组件(B…...

UVM概念面试题100问
1-10:UVM概述 Q1: 什么是UVM? A1: UVM是Universal Verification Methodology的缩写,它是由Accellera标准化的一种用于IC验证的方法学。它提供了一个基类库(BCL),包含通用工具如组件层次结构、事务级模型(TLM)和配置数据库等,使用户能够创建结构化、可重用的验证环境。 Q2:…...

SQL Server从安装到入门一文掌握应用能力。
本篇文章主要讲解,SQL Server的安装教程及入门使用的基础知识,通过本篇文章你可以快速掌握SQL Server的建库、建表、增加、查询、删除、修改等基本数据库操作能力。 作者:任聪聪 日期:2025年3月31日 一、SQL Server 介绍: SQL Server 是微软旗下的一款主流且优质的数据库…...

力扣HOT100之矩阵:54. 螺旋矩阵
这道题之前在代码随想录里刷过类似的,还有印象,我就按照当初代码随想录的思路做了一下,结果怎么都做不对,因为按照代码随想录的边界条件设置,当行数和列数都为奇数时,最后一个元素无法被添加到数组中&#…...

5.1 WPF路由事件以及文本样式
一、路由事件 WPF中存在一种路由事件(routed event),该事件将发送到包含该控件所在层次的所有控件,如果不希望继续向更高的方向传递,只要设置e.Handled true即可。 这种从本控件-->父控件->父的父控件的事件&am…...

Python数据可视化-第1章-数据可视化与matplotlib
环境 开发工具 VSCode库的版本 numpy1.26.4 matplotlib3.10.1 ipympl0.9.7教材 本书为《Python数据可视化》一书的配套内容,本章为第1章 数据可视化与matplotlib 本文主要介绍了什么是数据集可视化,数据可视化的目的,常见的数据可视化方式…...

Flutter敏感词过滤实战:基于AC自动机的高效解决方案
Flutter敏感词过滤实战:基于AC自动机的高效解决方案 在社交、直播、论坛等UGC场景中,敏感词过滤是保障平台安全的关键防线。本文将深入解析基于AC自动机的Flutter敏感词过滤实现方案,通过原理剖析实战代码性能对比,带你打造毫秒级…...

20250331-vue-组件事件1触发与监听事件
触发与监听事件 1 在组件的模板表达式中,可以直接使用 $emit 方法触发自定义事件(例如:在 v-on 的处理函数中): 子组件代码 <template><button click"$emit(someEvent)">点击</button> </template><…...

Odoo/OpenERP 和 psql 命令行的快速参考总结
Odoo/OpenERP 和 psql 命令行的快速参考总结 psql 命令行选项 选项意义-a从脚本中响应所有输入-A取消表数据输出的对齐模式-c <查询>仅运行一个简单的查询,然后退出-d <数据库名>指定连接的数据库名(默认为当前登录用户名)-e回显…...
Vue中使用antd-table组件时,树形表格展开配置不生效-defaultExpandedRowKeys-默认展开配置不生效
defaultExpandedRowKeys属性 defaultExpandAllRows这个属性仅仅是用来设置默认值的,只在第一次渲染的时候起作用,后续再去改变,无法实现响应式 解决方案一 a-table表格添加key属性,当每次获取值时,动态改变key,以达到重新渲染的效果 <a-table:key="tableKey"…...

VRRP交换机三层架构综合实验
题目要求: 1,内网Ip地址使用172.16.0.0/16分配 说明可以划分多个子网,图中有2个VLAN,可以根据VLAN划分 2,sw1和SW2之间互为备份 互为备份通常通过VRRP(虚拟路由冗余协议)来实现。VRRP会在两个…...
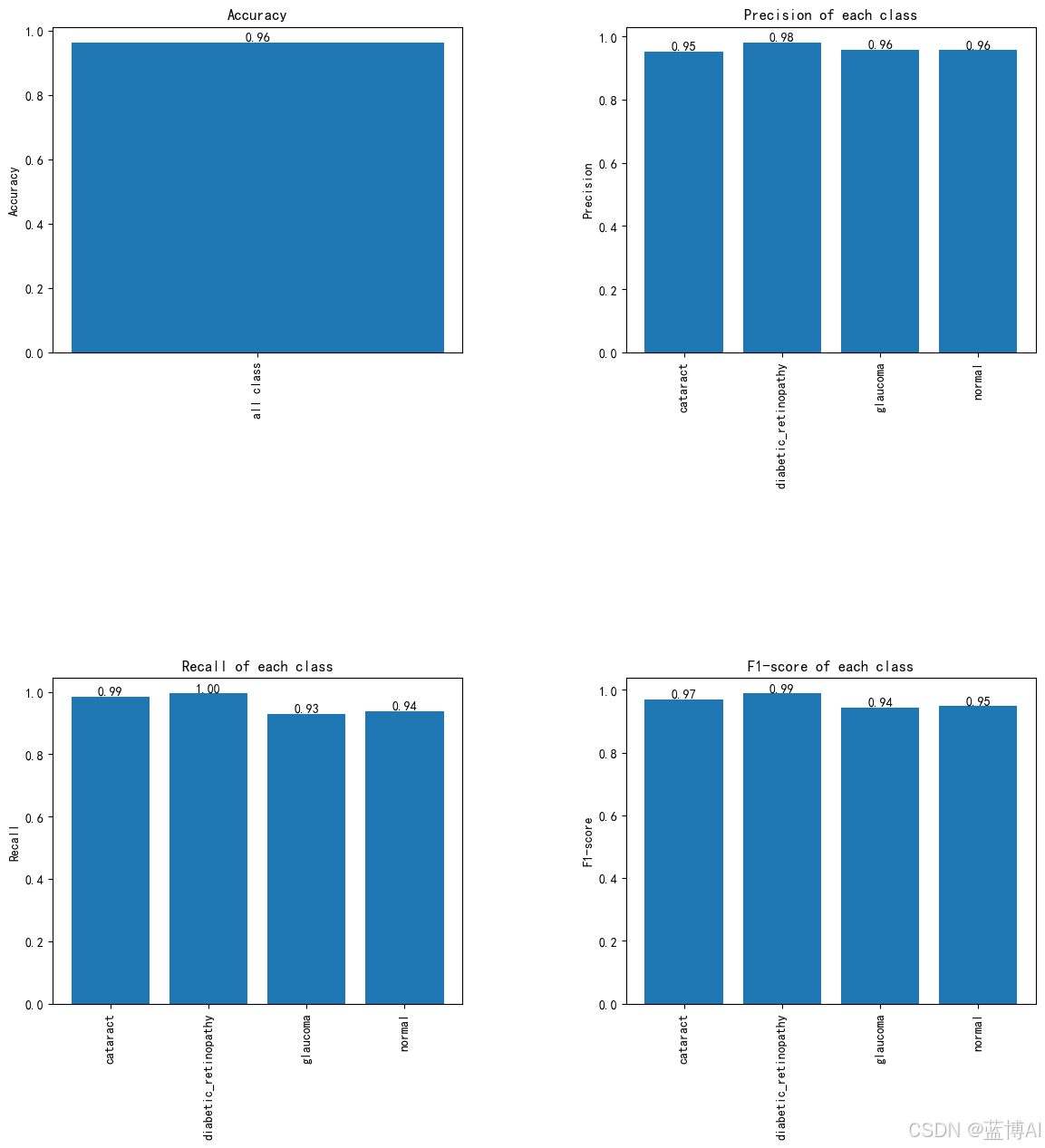
基于卷积神经网络的眼疾识别系统,resnet50,efficentnet(pytorch框架,python代码)
更多图像分类、图像识别、目标检测、图像分割等项目可从主页查看 功能演示: 眼疾识别系统resnet50,efficentnet,卷积神经网络(pytorch框架,python代码)_哔哩哔哩_bilibili (一)简介…...

基于srpingboot智慧校园管理服务平台的设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论…...
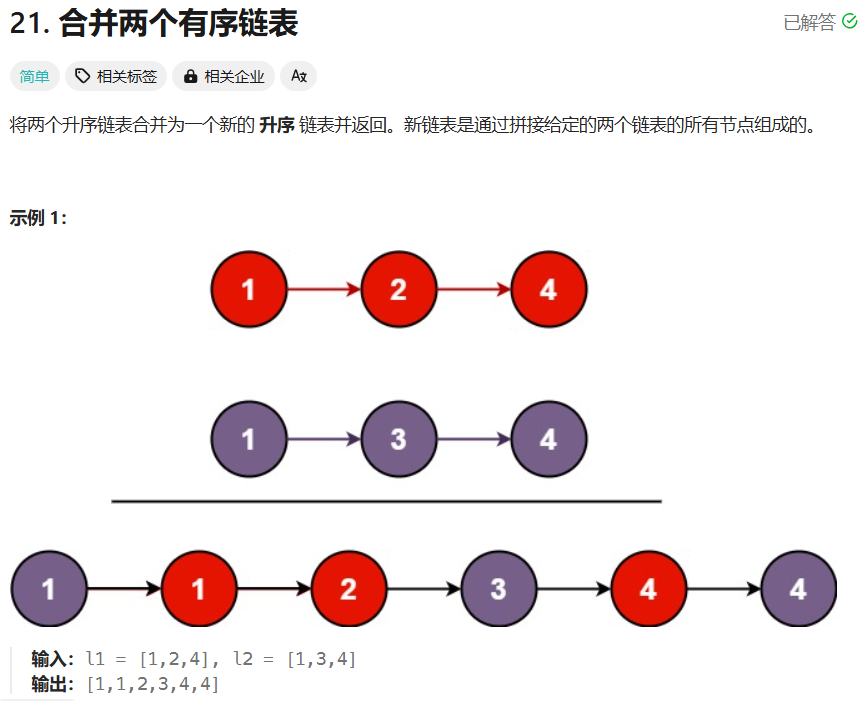
【力扣hot100题】(026)合并两个有序链表
可以创建一个新链表记录答案: /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *…...

TCP网络编程与多进程并发实践
一、引言 在网络编程中,TCP(传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。而多进程并发则是一种提高服务器处理能力的有效手段,允许服务器同时处理多个客户端的请求。本文将详细介绍如何使用 TCP 协议进…...
)
【前端】一文掌握 Vue 3 指令用法(vue3 备忘清单)
文章目录 入门介绍创建应用应用实例通过 CDN 使用 Vue使用 ES 模块构建版本模板语法文本插值原始 HTMLAttribute 绑定布尔型 Attribute动态绑定多个值使用 JavaScript 表达式仅支持表达式(例子都是无效)调用函数指令 Directives参数 Arguments绑定事件动态参数动态的事件名称修…...
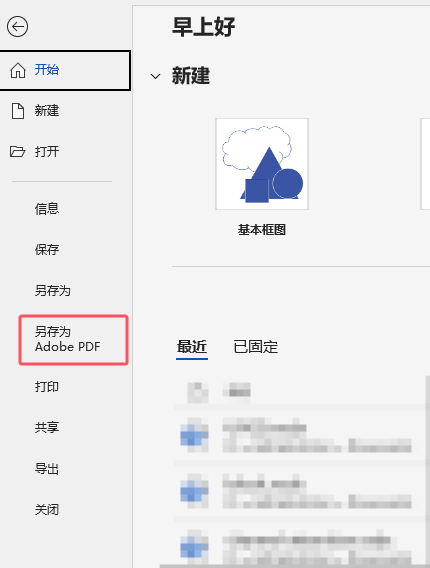
visio导出pdf公式变形
情况描述导出为pdf后,mathtype写的公式就变形了 但是导出为png和jpg就是正常 解决方法就是 需要下载一个Adobe Acrobat...

【学习笔记】计算机网络(六)
第6章应用层 文章目录 第6章应用层6.1 域名系统DNS6.1.1 域名系统概述6.1.2 互联网的域名结构6.1.3 域名服务器域名服务器的分区管理DNS 域名服务器的层次结构域名服务器的可靠性域名解析过程-两种查询方式DNS 高速缓存机制 6.2 文件传送协议6.2.1 FTP 概述6.2.2 FTP 的基本工作…...

做一个多级动态表单,可以保存数据和回显数据
<template> <div class"two"> <button class"save" click"saveBtn">保存数据</button> <button class"sd" click"showBtn">回显数据</button> <div class"all" click&quo…...