飞桨PP系列新成员PP-DocLayout开源,版面检测加速大模型数据构建,超百页文档图像一秒搞定
背景介绍
文档版面区域检测技术通过精准识别并定位文档中的标题、文本块、表格等元素及其空间布局关系,为后续文本分析构建结构化上下文,是文档图像智能处理流程的核心前置环节。随着大语言模型、文档多模态及RAG(检索增强生成)等技术快速发展,高质量结构化数据已成为模型训练与文档知识库构建的关键需求。基于版面检测模型定位识别文档图像的布局,结合如文本识别、公式识别、表格识别及信息抽取等下游任务,能够为大模型产出丰富的结构化训练数据,增强大模型的公式理解、表格解析以及对文档层次结构的理解能力。
然而,当前版面检测模型在满足构建 AI 数据的需求时仍面临诸多挑战:其一,多样化文档适用性不足,现有算法多聚焦于论文类文档,对杂志、报纸、研报等复杂版式的检测效果有限,难以获取类型丰富的大模型训练数据;其二,复杂版面结构识别能力有限,类别定义不全面(如行间/行内公式未单独定义),需额外模型辅助识别,导致处理效率降低与模型管理复杂化;其三,实时性能不足,难以满足大模型对海量训练数据的快速获取的需要。
为此,飞桨团队推出PP-DocLayout版面区域检测模型,支持中英文论文、研报、试卷、书籍、报纸、杂志等多种文档类型的23类版面区域的高精度识别与定位,显著提升大模型获取训练数据的多样性与高质量,同时满足大模型海量数据构建的高效率需求,基于 PaddleX 高性能推理引擎,轻量级模型在 CPU 上每秒可处理约69个文档图像页面,T4 GPU上每秒可处理高达123个文档图像页面,大幅超越现有开源方案。
一、效果速览
论文





报纸或杂志






研报





试卷、书籍或笔记





合同或条款





二、算法解读
针对版面检测任务,PP-DocLayout 系列支持 23 个常见版面布局类别,包含文档标题、段落标题、文本、页码、摘要、目录、参考文献、脚注、页眉、页脚、算法、公式、公式编号、图像、图像标题、表格、表格标题、图表、图表标题、印章、页眉图像、页脚图像和侧栏文本。这些类别覆盖全面,涵盖了多样化文档中常见的版面元素;类别结构层次清晰,通过识别文档标题、摘要、段落标题和正文等元素,可以更好地解析文档的语义层次和逻辑关系;同时包含公式、印章、表格、图表等高价值信息的结构化数据,允许更精准的进一步数据处理和分析;增加细粒度的页眉图像、页脚图像、侧栏文本等细小元素类别,利于下游版面恢复任务提高文档版面布局顺序预测的质量。
PP-DocLayout 系列提供了三个不同尺度的模型,以满足不同场景的需求:
- 高精度模型:PP-DocLayout-L,基于飞桨自研高精度检测模型 RT-DETR-L 训练得到,其在精度上达到了90.4 mAP@0.5,相对上一版本精度提升 15% 以上,尤其适合需要高精度的任务场景;在效率上也有所保障,基于 PaddleX 的高性能推理,高精度 PP-DocLayout-L 模型在 T4 GPU 上每个页面端到端推理耗时 13.4 ms。
- 精度和效率均衡模型:PP-DocLayout-M,基于飞桨自研精度-效率均衡的检测模型 PP-PicoDet-M 训练得到,适合精度效率兼顾要求的任务,其在精度上达到了75.2 mAP@0.5,基于 PaddleX 的高性能推理模式,PP-DocLayout-M 高精度模型能够在 T4 GPU 上每个页面端到端推理耗时 12.7ms。
- 高效率模型:PP-DocLayout-S,基于飞桨自研高效率检测模型 PP-PicoDet-S 训练得到,以提升推理速度和降低模型大小为目标,适合于资源受限的环境和实时应用场景。基于 PaddleX 的高性能推理模式,高效率模型在 T4 GPU上能够能实现毫米级别预测,单页面处理耗时约 8.1ms,CPU上能够实现单页面耗时 14.5ms。

注:以上精度指标的评估集是 PaddleX 自建的版面区域检测数据集,包含中英文论文、杂志、合同、书本、试卷和研报等常见的 500 张文档类型图片。GPU 推理耗时基于 NVIDIA Tesla T4 机器,CPU 推理速度基于 Intel® Xeon® Gold 6271C CPU @ 2.60GHz,线程数为 8,精度类型为 FP32。
PP-DocLayout 在数据和算法层面均做了优化:
- 在数据层面,采用了基于主动学习的数据轮动方法,筛选较难的样本和类别,获取大量人工矫正标签的高质量多类型文档的版面检测模型训练数据。
- 算法层面:
1)更优的泛化能力:PP-DocLayout-L 的骨干网络采用了蒸馏技术,骨干网络基于大模型蒸馏得到,大幅增强模型泛化性能。通过知识蒸馏技术,可以将一个大规模、复杂的“教师”模型的知识传递给一个相对较小的“学生”模型。在这里,我们将基于大规模文档数据训练得到的 GOT-OCR2.0 模型的视觉编码器作为“教师”模型,而将飞桨自研的高精度骨干网络 PP-HGNetV2-B4 作为“学生”模型。我们收集了大量多种类型的约 50 万文档图像数据,并利用 L2 损失函数,将大模型的输出作为目标,指导小模型的学习。这样,小模型能够更好的支持复杂下游任务,如版面区域检测。在版面区域检测任务中,PP-DocLayout-L 的训练使用经过知识蒸馏的 PP-HGNetV2-B4 作为预训练模型,从而能够更快速地收敛,并提升精度和泛化能力。

骨干网络知识蒸馏

2)优化伪标签质量的半监督学习:PP-DocLayout-M/S 采用了半监督学习技术,基于 PP-DocLayout-L 生成伪标签,在伪标签生成过程中,根据每个类别得分分布制定最佳阈值获取较高质量伪标签,优化标签质量。基于真实人工标注和伪标签数据,训练 PP-DocLayout-M 和 PP-DocLayout-S 模型,增强模型精度。

3)灵活易用后处理:支持每个类别的动态阈值调整,可根据数据优化漏检和误检情况;支持重叠框过滤,可过滤多余的检测框;可自由扩张框边长,便于输入正确完整布局到下游任务;可选框的合并模式,支持输出外边框,内框和所有框,适用于不同的下游任务需求。
三、使用方法
安装
安装PaddlePaddle
# cpu
python -m pip install paddlepaddle==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/# gpu,该命令仅适用于 CUDA 版本为 11.8 的机器环境
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/# gpu,该命令仅适用于 CUDA 版本为 12.3 的机器环境
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/
安装PaddleX Wheel包
pip install https://paddle-model-ecology.bj.bcebos.com/paddlex/whl/paddlex-3.0.0rc0-py3-none-any.whl
快速体验
PaddleX 提供了简单易用的 Python API,只需几行代码即可体验模型预测效果,可以下载测试图片,方便大家快速体验效果:
图片下载地址:
https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/layout.jpg
from paddlex import create_modelmodel = create_model(model_name="PP-DocLayout-L")
output = model.predict("layout.jpg", batch_size=1, layout_nms=True)for res in output:res.print()res.save_to_img(save_path="./output/")res.save_to_json(save_path="./output/res.json")
上述代码中:
- 首先使用模型名称调用 create_model() 方法实例化对象;
- 然后使用 predict() 方法进行预测,对于预测结果支持 print() 方法进行打印,save_to_img() 方法进行可视化并保存为图片以及 save_to_json() 方法保存预测的结构化输出。
下图1为测试图像,2图为 PP-DocLayout-L 模型版面检测结果。

此外,调用模型的 predict() 方法进行推理预测时,predict() 方法参数支持传入版面模型后处理参数和是否开启高性能推理:
- threshold: 动态阈值调整,支持传入浮点数或自定义各个类别的阈值字典,为每个类别设定专属的检测得分阈值。这意味着您可以根据自己的数据,灵活调节漏检或误检的情况,确保每一次检测更加精准;
- layout_nms : 重叠框过滤,布尔类型,用于指定是否使用NMS(非极大值抑制)过滤重叠框,启用该功能,可以自动筛选最优的检测结果,消除多余干扰框;
- layout_unclip_ratio: 可调框边长,不再局限于固定的框大小,通过调整检测框的缩放倍数,在保持中心点不变的情况下,自由扩展或收缩框边长,便于输出正确完整的版面区域内容;
- layout_merge_bboxes_mode: 框合并模式,模型输出的检测框的合并处理模式,可选“large”保留外框,“small”保留内框,不设置默认保留所有框。例如一个图表区域中含有多个子图,如果选择“large”模式,则保留一个图表最大框,便于整体的图表区域理解和对版面图表位置区域的恢复,如果选择“small”则保留子图多个框,便于对子图进行一一理解或处理。在下游任务中无论是想突出整体,还是聚焦细节,都能轻松实现。
- use_hpip:是否启用高性能推理来优化您模型的推理过程,进一步提升效率。
二次开发
如果对模型效果满意,可以直接对产线进行高性能推理/服务化部署/端侧部署,如果在您的场景中,效果还有进一步优化空间,您也可以使用 PaddleX 进行便捷高效的二次开发,使用自己场景的数据对模型微调训练获得更优的精度。基于 PaddleX 便捷的二次开发能力,使用统一命令即可完成数据校验、模型训练与评估推理,无需了解深度学习的底层原理,按要求准备好场景数据,简单运行命令即可完成模型迭代,此处展示版面区域检测模型二次开发流程:
python main.py -c paddlex/configs/modules/layout_detection/PP-DocLayout-L.yaml \-o Global.mode=train \-o Global.dataset_dir=./dataset/layout_det_examples
上述命令中:main.py 为模型开发统一入口文件;-c 用于指定模型配置文件的参数,模型配置文件 PP-DocLayout-L.yaml 中包含了模型的信息,如模型名、学习率、批次大小等,其中 mode 支持指定数据校验(dataset_check)、训练(train)、评估(evaluate)、模型导出(export)和推理(predict)。更多参数也可以继续在命令中追加参数设置或可通过修改.yaml配置文件中的具体字段来进行设置。
其余更详细的使用方法及产线部署、自定义数据集相关的内容,请参考PaddleX官方教程文档:
版面区域检测模块使用教程
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-rc/docs/module_usage/tutorials/ocr_modules/layout_detection.md
精彩课程
为了帮助您迅速且深入地了解版面区域检测全流程解决方案,百度研发工程师精心打造视频精讲课程,为您深度解析本次技术升级。此外,我们还将开设针对版面区域检测产线的产业场景实战营,配套详细教程文档,手把手带您体验从数据准备、数据校验、模型训练、性能优化到模型部署的完整开发流程。机会难得,立即点击链接报名:https://www.wjx.top/vm/eArkGEn.aspx?udsid=730670

相关文章:
飞桨PP系列新成员PP-DocLayout开源,版面检测加速大模型数据构建,超百页文档图像一秒搞定
背景介绍 文档版面区域检测技术通过精准识别并定位文档中的标题、文本块、表格等元素及其空间布局关系,为后续文本分析构建结构化上下文,是文档图像智能处理流程的核心前置环节。随着大语言模型、文档多模态及RAG(检索增强生成)等…...

Java 锁机制详解:用“厕所门”和“防盗门”轻松理解多线程同步
Java 锁机制详解:用“厕所门”和“防盗门”轻松理解多线程同步 目录 锁的作用synchronized 关键字ReentrantLockReadWriteLockStampedLock避免死锁的诀窍总结与对比 锁的作用 生活中的例子:公共厕所一次只能进一人,门上的“有人/无人”标志…...

关于修改 vue Element admin、若依, 等后台管理系统模板的一些全局样式问题:
关于修改 vue Element admin、若依, 等后台管理系统模板的一些全局样式问题: 1、修改左侧菜单和顶部(菜单)的背景色、把背景色改为炫酷的背景图。 1)上传图片 src/assets/images/menu-icon.png、 src/assets/images/…...

并发多线程八股
并发多线程 1.Java里面的线程和操作系统的线程一样吗?2.Java的线程安全在三个方面体现:3.保证数据一致性的方案4.线程创建的方式1)Thread类2)Runnable接口3)Callable接口和FutureTask4)线程池(e…...

飞速(FS)HPC无损组网:驱动AI高性能计算网络转型升级
案例亮点 部署低功耗、高密度飞速(FS)以太网交换机,紧凑机身设计节省70%机房空间,冗余电源和智能风扇确保系统高可用性,有效优化散热和降低能耗。 支持25G/40G/100G多速率自适应交换架构,构建超低时延企业…...

Nest.js学习路径
作为前端开发工程师,系统学习Nest.js可以从以下步骤入手,结合其模块化架构、依赖注入和TypeScript特性,逐步掌握核心功能。以下是结合多个资源的综合学习路径: 1. 环境搭建与项目初始化 安装CLI工具 使用Nest.js官方CLI快速生成项…...

git 常用操作整理
一.git 的概念 Git 是一个分布式版本控制系统,用于跟踪文件的更改历史,帮助开发者管理代码的版本。以下是关于 Git 的一些基本概念: 1. 仓库(Repository) - **本地仓库**:在你的计算机上存储的项目文件及…...

JAVA数据库增删改查
格式 Main.java(测试类) package com.example;import com.example.dao.UserDao; import com.example.model.User;public class Main {public static void main(String[] args) {UserDao userDao new UserDao();// 测试添加用户System.out.println(" 添加用户 ");Us…...

上海某海外视频平台Android高级工程师视频一面
问的问题比较细,有很多小细节在里面,平时真不一定会注意到,做一个备忘: 1.Object类里面有哪些方法? Object 类是 Java 中所有类的根类,它定义了一些基本方法,供所有类继承和重写1. 常用方法 1…...

前后端数据序列化:从数组到字符串的旅程(附优化指南)
🌐 前后端数据序列化:从数组到字符串的旅程(附优化指南) 📜 背景:为何需要序列化? 在前后端分离架构中,复杂数据类型(如数组、对象)的传输常需序列化为字符…...

idea报错:程序包不存在
这里的程序包是我们项目里自己写的,idea却报错不存在。 解决方法: 参考这位大佬的方法,OK。...

【TVM教程】使用 TVMC Micro 执行微模型
Apache TVM是一个深度的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 →https://tvm.hyper.ai/ 作者:Andrew Reusch, Mehrdad Hessar 本教程介绍如何用 C runtime 自动调优模型。 安装 microTVM Python 依赖项…...

spring boot 整合redis
1.在pom文件中添加spring-boot-starter-data-redis依赖启动器 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency> 2.编写三个实体类 RedisHash("p…...

进程间信号
进程间信号 信号的认识信号的产生进程对信号的处理机制普通信号的处理机制实时信号的处理机制 信号集操作函数信号的捕捉 信号的认识 信号的概念: 信号是一种软件中断,它用于通知进程一个异步事件的发生。 这些事件可能来自系统内部(如硬…...

2011-2019年各省地方财政国债还本付息支出数据
2011-2019年各省地方财政国债还本付息支出数据 1、时间:2007-2019年 2、来源:国家统计局、统计年鉴 3、指标:行政区划代码、地区、年份、地方财政粮油物资储备管理等事务 4、范围:31省 5、指标说明:地方财政的国债…...

2025华为软件精英挑战赛2600w思路分享
这里写自定义目录标题 得分展示对象定义请求价值计算时间同步删除操作完整思路 得分展示 对象定义 // 将一个磁盘划分为多个基于标签聚合的区块 class Block{ public:int tag 0; // 区块标签int start_pos;int end_pos;int id;int use_size 0;int v;// 为区块确定范围Bloc…...

WEB安全-CTF中的PHP反序列化漏洞
什么是序列化? 简单来说序列化是将数组或对象转换成字符串的过程,这样的好处是利于对象存储与传输,在PHP中,序列化函数是serialize(),反序列化是unserialize() 无类序列化 无类序列化顾名思义就是不包含class的序列…...

【论文阅读】Co2l: Contrastive continual learning
原文链接:[2106.14413] Co$^2$L: Contrastive Continual Learning 阅读本文前,需要对持续学习的基本概念以及面临的问题有大致了解,可参考综述: Wang L, Zhang X, Su H, et al. A comprehensive survey of continual learning: …...

OpenMCU(五):STM32F103时钟树初始化分析
概述 本文主要描述了STM32F103初始化过程系统时钟的初始化,主要描述了系统时钟的初始化,AHB总线时钟,APB总线时钟等的初始化。 硬件板卡3d图 时钟树 STM32F103的时钟树,如下所示: 时钟源选择 从STM32F103的时钟树框图,我们可以…...

ISIS报文
IS-IS 报文 目录 IS-IS 报文 一、报文类型与功能 二、报文结构解析 三、核心功能特性 四、典型应用场景 五、抓包数据分析 六、总结 IS-IS(中间系统到中间系统)协议报文是用于链路状态路由协议中网络设备间交换路由信息的关键载体,其设…...
 的实现与协议栈交互源码解析)
【Android】BluetoothSocket.connect () 的实现与协议栈交互源码解析
本文以 Android 蓝牙框架中的BluetoothSocket.connect()方法为切入点,深入剖析 Android 设备与远程蓝牙设备建立连接的全流程。从 Java 层的 API 调用出发,逐步追踪至 JNI 层的接口转发,最终进入 Buedroid 协议栈(RFCOMM/L2CAP 层),揭示蓝牙连接的核心机制。重点解析了权…...

首屏加载时间优化解决
🤖 作者简介:水煮白菜王(juejin/csdn同名) ,一位前端劝退师 👻 👀 文章专栏: 高德AMap专栏 ,记录一下平时学习在博客写作中记录,总结出的一些开发技巧✍。 感…...

RabbitMQ--延迟队列事务消息分发
目录 1.延迟队列 1.1应用场景 1.2利用TTL死信队列模拟延迟队列存在的问题 1.3延迟队列插件 1.4常见面试题 2.事务 2.1配置事务管理器 3.消息分发 3.1概念 3.2应用场景 3.2.1限流 3.2.2负载均衡 1.延迟队列 延迟队列(Delayed Queue),即消息被发送以后, 并…...

Linux服务器组建与管理
#!/bin/bash #判断是否是root用户if [ "$USER" ! "root" ]; then echo "不是root用户,无法进行安装操作" exit 1 fi#关闭防火墙systemctl stop firewalld && systemctl disable firewalld && echo "防火墙已经关…...
:DSP与外部平台对接的关键要点解析)
程序化广告行业(48/89):DSP与外部平台对接的关键要点解析
程序化广告行业(48/89):DSP与外部平台对接的关键要点解析 大家好!在之前的博客中,我们逐步深入了解了程序化广告行业的诸多知识。一直以来,我都希望能和大家一起在这个领域探索,不断进步&#…...

设计模式 Day 2:工厂方法模式(Factory Method Pattern)详解
继 Day 1 学习了单例模式之后,今天我们继续深入对象创建型设计模式——工厂方法模式(Factory Method)。工厂方法模式为对象创建提供了更大的灵活性和扩展性,是实际开发中使用频率极高的一种设计模式。 一方面,我们将简…...
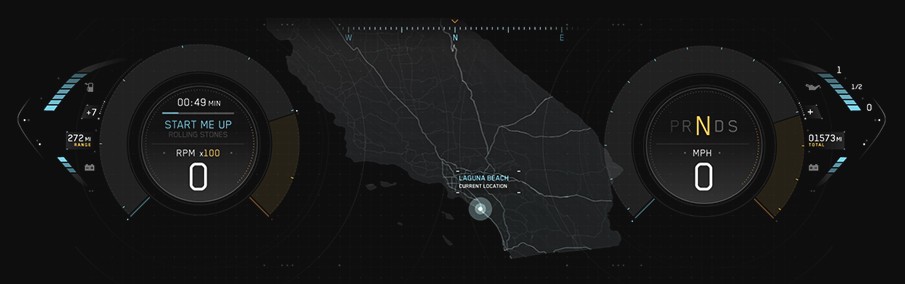
自动驾驶浪潮下,HMI 设计如何保障安全与便捷?
自动驾驶系统与 HMI 设计的关联性 自动驾驶系统涵盖了一系列复杂的传感器技术、算法以及执行机构。从激光雷达、摄像头等环境感知传感器,到用于处理海量数据的人工智能算法,再到控制车辆行驶的动力与转向执行系统,各部分协同工作,…...
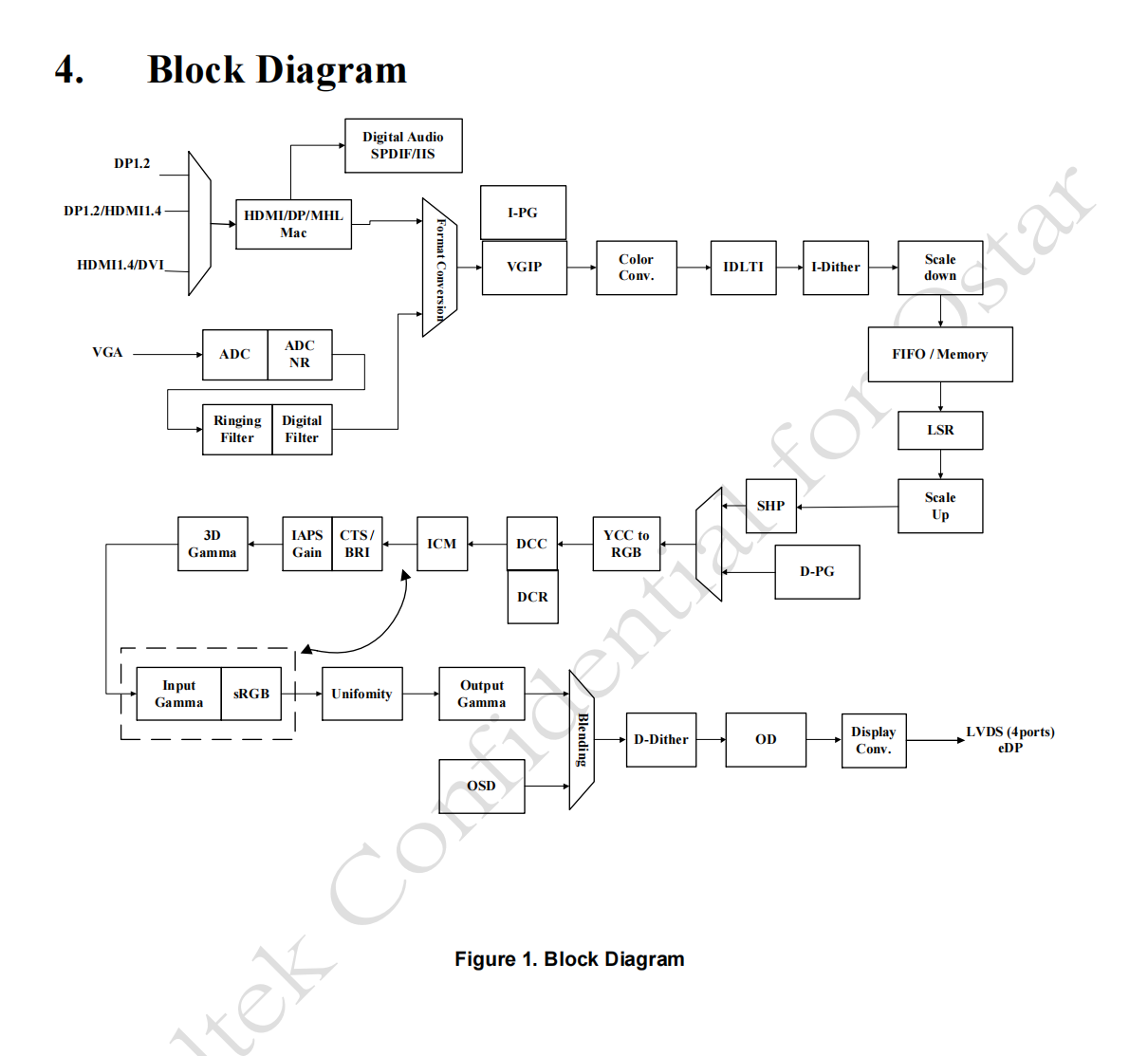
瑞昱RTD2556QR显示器驱动芯片
一、概述 RTD2556QR芯片是由Realtek公司精心研发的一款高性能显示驱动芯片,专为满足现代显示设备对高分辨率、多功能接口及稳定性能的需求而设计。该芯片凭借其卓越的技术特性和广泛的应用领域,在显示驱动市场中占据重要地位。它集成了多种先进的功能模…...

复合缩放EfficientNet原理详解
1. 为什么复合缩放更高效? (1)单维度缩放的瓶颈 增加深度(层数): 更深的网络可以学习更复杂特征,但容易导致梯度消失/爆炸问题,且计算量随深度线性增长。 问题:深层网络…...

线程等待与唤醒的几种方法与注意事项
写在前面:无论是调用哪种等待和唤醒的方法,都必须是当前线程所持有的对象,否则会导致 java.lang.IllegalMonitorStateException 等并发安全问题。 以三个线程循环打印 XYZ 为例。 一、方法 1.1 Object 对象锁 可以通过 synchronized 对方…...