动手学深度学习:AlexNet
前言
从这个模型开始,我的数据集主阵地就将从装甲板转移到手语视频数据集,模型开始变得更加复杂,数据集当然也要更复杂啦,我将记录在这个过程中遇到的问题和解决后续。
数据读取
由于是视频数据集,我采取的方法是将每一帧读取进来,灰度处理成单通道(个人认为彩色并没有什么信息,同时也是减少通道数量),再将前几帧数据集堆叠成多通道,实现对于视频的处理。
import cv2
import os
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
import random
import torch
import time
import warnings
# warnings.filterwarnings("ignore")
root='/home/chen/Dataset/NMFs-CSL/jpg_video'
labels=os.listdir(root)[:10]
labels

videos_path=[]
for label in labels:for filename in os.listdir(os.path.join(root,label)):if not filename.endswith(".mp4"):videos_path.append(os.path.join(root,label,filename))
videos_path
def train_test_split(data_path,train=0.8):train_data_path=[]test_data_path=[]num_len=len(data_path)indices=list(range(num_len))random.seed(0)random.shuffle(indices)train_num=int(num_len*train)for i in indices[:train_num]:train_data_path.append(data_path[i])for i in indices[train_num:]:test_data_path.append(data_path[i])return train_data_path,test_data_path
train_data_path,test_data_path=train_test_split(videos_path)
len(train_data_path),len(test_data_path)
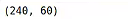
堆叠多帧成多通道
def stack_frames(frames, num_frames):"""将多个连续帧堆叠成一个高维输入。Args:frames: 帧序列 (list of tensors)num_frames: 堆叠的帧数Returns:stacked_frame: 堆叠后的高维输入"""stacked_frame = torch.cat(frames[:num_frames], dim=0) # 堆叠成一个高维输入
# print(stacked_frame.shape)return stacked_frame
train_data=[]
test_data=[]
train_label=[]
test_label=[]
frames_len=4
for video in train_data_path:frames=[]for i in os.listdir(video):frame=cv2.cvtColor(cv2.resize(cv2.imread(os.path.join(video,i)),(224,224)),cv2.COLOR_BGR2GRAY)frame=torch.tensor(frame,dtype=torch.float32)frame=frame.unsqueeze(0)normalize = transforms.Normalize(mean=[0.5], std=[0.5])frame=normalize(frame)frames.append(frame)print(len(frames))train_label.append(video.split('/')[6])train_data.append(stack_frames(frames,frames_len))
for video in test_data_path:frames=[]for i in os.listdir(video):frame=cv2.cvtColor(cv2.resize(cv2.imread(os.path.join(video,i)),(224,224)),cv2.COLOR_BGR2GRAY)frame=torch.tensor(frame,dtype=torch.float32)frame=frame.unsqueeze(0)normalize = transforms.Normalize(mean=[0.5], std=[0.5])frame=normalize(frame)frames.append(frame)
# select=len(frames)//2test_label.append(video.split('/')[6])test_data.append(stack_frames(frames,frames_len))
train_labels = [labels.index(item) for item in train_label if item in labels]
test_labels = [labels.index(item) for item in test_label if item in labels]
train_labels,test_labels

batch_size=16
class MyDatasets(Dataset):def __init__(self,data,labels,size=None):self.data=dataself.labels=labelsself.size=sizeself.end_time=time.time()def __len__(self):return len(self.data)def __getitem__(self,index):img=self.data[index]label=torch.tensor(self.labels[index],dtype=torch.long)
# print(img.shape)
# print(time.time()-self.end_time)return img,label
def load_data(train_data,train_labels,test_data,test_labels,batch_size,size=None):train=MyDatasets(train_data,train_labels)test=MyDatasets(test_data,test_labels)return DataLoader(train,batch_size,shuffle=True,num_workers=8),DataLoader(test,batch_size,shuffle=True,num_workers=8)
train_iter,test_iter=load_data(train_data,train_labels,test_data,test_labels,batch_size)
for x,y in train_iter:print(x.shape)break
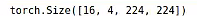
模型
import torch.nn as nn
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device

也是todesk了一台有显卡的电脑,速度嘎嘎快。虽然但是第一次cuda,遇到好几个报错,什么模型在cuda上,数据没放cuda上,还有结果acc什么的要matplotlib要放在cpu上。
# 输入图像为224*224*64
net=nn.Sequential(
nn.Conv2d(frames_len,96,kernel_size=11,stride=4,padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(96,256,kernel_size=5,padding=2),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(256,384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(384,384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(384,256,kernel_size=3,padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Flatten(),
nn.Linear(6400,4096),nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096,4096),
nn.Dropout(p=0.5),
nn.Linear(4096,len(labels))).to(device)
def init_weight(m):if type(m)==nn.Linear or type(m)==nn.Conv2d:nn.init.xavier_uniform_(m.weight)
net.apply(init_weight)

loss_fn=nn.CrossEntropyLoss()
optimer=torch.optim.SGD(net.parameters(),lr=0.0001)#0.001会导致loss为nan
# 初始化最小测试损失
best_test_loss = float('inf')
best_model_path = './models/AlexNet1.pt'
调参了这么些个模型最大体会就是轮次调大一点,那样就只需要调小轮次再训练,而不是一直调大,并且很多时候跑多轮了才会发现一些关键问题,不要看开始不行就停下来!!看完结果再决定。
epochs_num=300
train_len=len(train_iter.dataset)
all_acc=[]
all_loss=[]
test_all_acc=[]
shape=None
for epoch in range(epochs_num):acc=0loss=0for x,y in train_iter:x=x.to(device)y=y.to(device)hat_y=net(x)l=loss_fn(hat_y,y)loss+=loptimer.zero_grad()l.backward()optimer.step()acc+=(hat_y.argmax(1)==y).sum()all_acc.append((acc/train_len).cpu().numpy())all_loss.append(loss.detach().cpu().numpy())
# print(all_loss)test_acc=0test_loss=0test_len=len(test_iter.dataset)with torch.no_grad():for x,y in test_iter:x=x.to(device)y=y.to(device)shape=x.shapehat_y=net(x)test_loss+=loss_fn(hat_y,y)test_acc+=(hat_y.argmax(1)==y).sum()test_all_acc.append((test_acc/test_len).cpu().numpy())print(f'{epoch}的test的acc{test_acc/test_len}')# 保存测试损失最小的模型if test_loss < best_test_loss:best_test_loss = test_loss
# torch.save(net, best_model_path)dummy_input = torch.randn(shape)
# torch.onnx.export(net, dummy_input, "./models/LeNet6.onnx", opset_version=11)print(f'Saved better model with Test Loss: {best_test_loss:.4f}')

可视化
import matplotlib.pyplot as plt
损失函数可视化
plt.plot(range(1,epochs_num+1),all_loss,'.-',label='train_loss')
plt.text(epochs_num, all_loss[-1], f'{all_loss[-1]:.4f}', fontsize=12, verticalalignment='bottom')
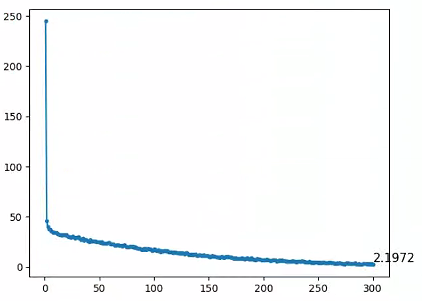
准确率可视化
plt.plot(range(1,epochs_num+1),all_acc,'-',label='train_acc')
plt.text(epochs_num, all_acc[-1], f'{all_acc[-1]:.4f}', fontsize=12, verticalalignment='bottom')
plt.plot(range(1,epochs_num+1),test_all_acc,'-.',label='test_acc')
plt.legend()

看上去似乎效果还可以,实际上我认为完全没有学习我想要它学习的内容。
bug
1.正确率一直很低且相同
解决方法:我查看了整体思路,实在没有头绪,打印了train的loss,惊然发现loss为nan,于是默默将学习率调到很低,终于acc开始有了变化。
2.loss下降,但train和test正确率疯狂在震荡且无提升
解决方法:由于准确率在随机的那个值附近徘徊,判断是没有学习到东西,调高学习率之后,train的acc疯狂上升,test的acc轻微上升。
3.train的acc很高,但test的acc很低
解决方法:发现在调低batch和帧数之后,train疯狂上升到98%,test也有所上升,结论模型根本没有在识别视频手语,而是在做图片的分类,我个人感觉是对于这个模型本身就不存在时序性导致的。
总结
后面学的一些模型可能在这个数据集上效果还是不会好吧,先拿这个数据集做练习着,看train的acc就知道我模型应该没写错哈哈,还是有在拟合图片的。
相关文章:
动手学深度学习:AlexNet
前言 从这个模型开始,我的数据集主阵地就将从装甲板转移到手语视频数据集,模型开始变得更加复杂,数据集当然也要更复杂啦,我将记录在这个过程中遇到的问题和解决后续。 数据读取 由于是视频数据集,我采取的方法是将…...
MySql之binlog与数据恢复(Binlog and Data Recovery in MySQL)
MySql之binlog与数据恢复 什么是binlog binlog我们一般叫做归档日志,他是mysql服务器层的日志,跟存储引擎无关,他记录的是所有DDL和DML的语句,不包含查询语句,binlog是一种逻辑日志,他记录的是sql语句的原…...

JDK1.8和Maven、Git安装教程自用成功
一.JDK安装 JRK:java运行环境 JDK:java语言的软件开发工具包;JDK里包含了java开发工具,也包含了JRE 1.下载JDK1.8并安装 Java Downloads | Oracle 进入官网后往下翻,找到JAVA8; 然后选择对应的版本&am…...
数据采集助力AI大模型训练
引言使用抓取浏览器采集ebay商品页面选购亮数据AI训练数据总结 引言 AI技术在今天已经是我们工作生活中不可或缺的工具,很多小伙伴也在致力于训练AI模型。高质量的数据是训练强大AI模型的核心驱动力,无论是自然语言处理、计算机视觉还是推荐系统…...

WPF中viewmodel单例模式
1、单例模式介绍 单例模式是一种创建型设计模式,确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。它常用于需要全局唯一访问点的场景,如配置管理、日志记录、数据库连接等。 2、WPF 中 ViewModel 的单例实现 在 WPF 中&#…...

Rust 为什么不适合开发 GUI
前言 在当今科技蓬勃发展的时代,Rust 编程语言正崭露头角,逐步为世界上诸多重要基础设施提供动力支持。从存储海量信息到应用于 Linux 内核,Rust 展现出强大的实力。然而,当涉及构建 GUI(图形用户界面)时&…...
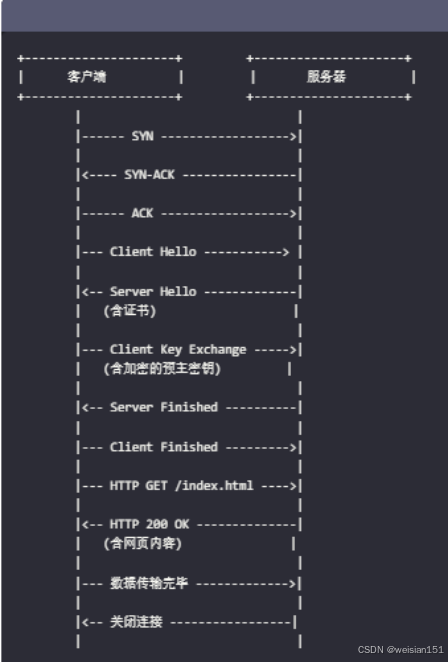
消息队列篇--通信协议篇--理解HTTP、TLS和TCP如何协同工作
前面介绍了HTTP/HTTPS,SSL/TLS以及TCP和UDP,这些在网络传输上分别有着自己的作用。为了深入理解下这些概念,本篇重点介绍下HTTP、TLS 和 TCP是如何协同工作的?我们从底层到上层逐步分析每个协议的作用及其相互关系。这些协议共同协…...

代码随想录算法训练营第三十四天 | 62.不同路径 63.不同路径II 343.整数拆分
62.不同路径 题目链接:62. 不同路径 - 力扣(LeetCode) 文章讲解:代码随想录 视频讲解:动态规划中如何初始化很重要!| LeetCode:62.不同路径_哔哩哔哩_bilibili 思路:机器人位于一…...

2023第十四届蓝桥杯大赛软件赛省赛C/C++ 大学 B 组(真题题解)(C++/Java题解)
记录刷题的过程、感悟、题解。 希望能帮到,那些与我一同前行的,来自远方的朋友😉 大纲: 1、日期统计-(解析)-暴力dfs(😉蓝桥专属 2、01串的熵-(解析)-不要chu…...
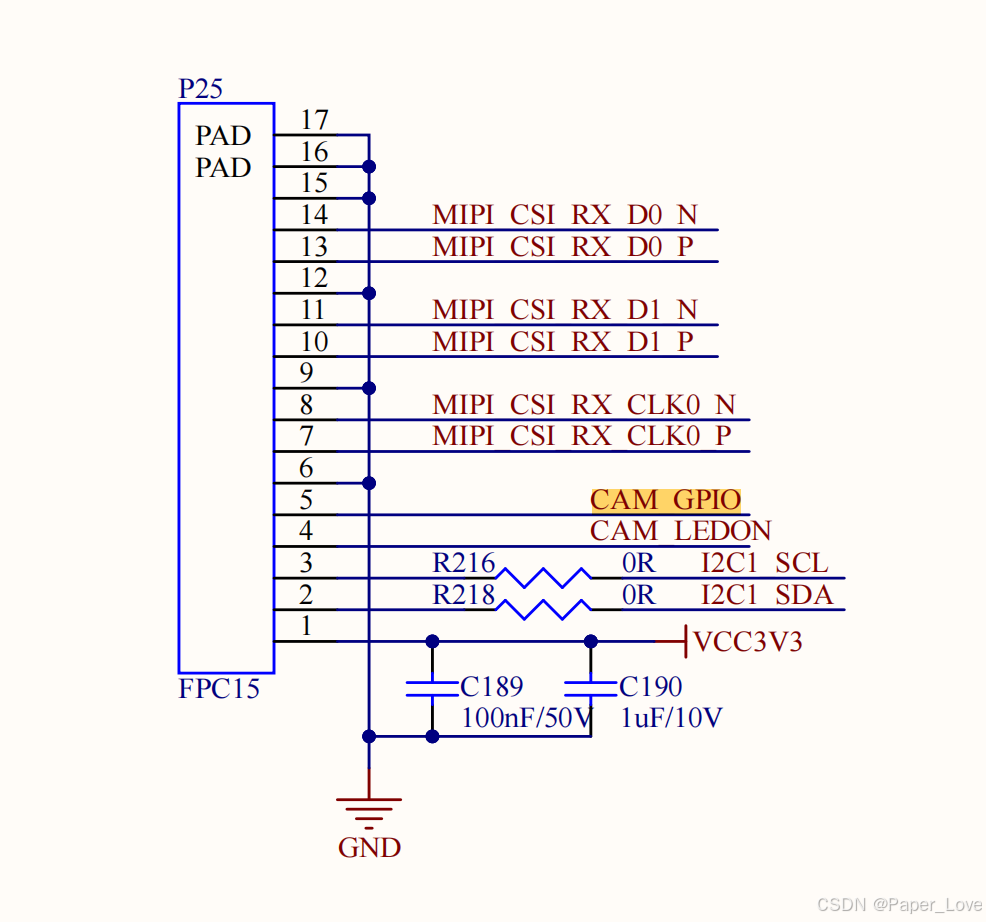
RK3568-适配ov5647摄像头
硬件原理图 CAM_GPIO是摄像头电源控制引脚,连接芯片GPIO4_C2 CAM_LEDON是摄像头led灯控制引脚,连接芯片GPIO4_C3编写设备树 / {ext_cam_clk: external-camera-clock {compatible = "fixed-clock";clock-frequency = <25000000>;clock-output-names = "…...

Java的设计模式详解
摘要:设计模式是软件工程中解决常见问题的经典方案。本文结合Java语言特性,深入解析常用设计模式的核心思想、实现方式及实际应用场景,帮助开发者提升代码质量和可维护性。 一、设计模式概述 1.1 什么是设计模式? 设计模式&…...

实战篇Redis
黑马程序员的Redis的笔记(后面补一下图片) 【黑马程序员Redis入门到实战教程,深度透析redis底层原理redis分布式锁企业解决方案黑马点评实战项目】https://www.bilibili.com/video/BV1cr4y1671t?p72&vd_source001f1c33a895eb5ed820b9a4…...

化学方程式配平 第33次CCF-CSP计算机软件能力认证
很经典的大模拟题目 但是还不算难 大模拟题最需要注意的就是细节 写代码一定要考虑全面 并且要细心多debug 多打断点STL库的熟练使用 istringstream真的处理字符串非常好用 注意解耦合思想 这样改代码debug更加清晰 https://www.acwing.com/problem/content/5724/ #includ…...

Java基础-25-继承-方法重写-子类构造器的特点-构造器this的调用
在面向对象编程中,继承是实现代码复用和扩展的重要机制。通过继承,子类可以继承父类的属性和方法,并且可以通过方法重写来改变或扩展父类的行为。此外,构造器在对象初始化过程中扮演了重要角色,尤其是在子类构造器中如…...

nvidia 各 GPU 架构匹配的 CUDA arch 和 CUDA gencode
使用 NVCC 进行编译 cuda c(.cu)时,arch 标志 (-arch) 指定了 CUDA 文件将为其编译的 NVIDIA GPU 架构的名称。 Gencodes (-gencode) 允许更多的 PTX 代,并且可以针对不同的架构重复多次。 NVIDIA 架构名称的列表,以及它们具有的计算能力&am…...

沉浸式体验测评|AI Ville:我在Web3小镇“生活”了一周
最近,我在朋友的推荐下,体验了 aivillebot 的项目。起初,我只是抱着试试看的心态,心想这不就是个 Web3 版的《星露谷物语》吗? 但是一周下来,我发现这个虚拟小镇也没那么简单——里面的居民不是目前端游或链…...

TTL 值 | 在 IP 协议、ping 工具及 DNS 解析中的作用
注:本文为 “TTL” 相关文章合辑。 未整理去重。 如有内容异常,请看原文。 TTL 值的意义 2007-10-18 11:33:17 TTL 是 IP 协议包中的一个值,用于标识网络路由器是否应丢弃在网络中停留时间过长的数据包。数据包可能因多种原因在一定时间内…...
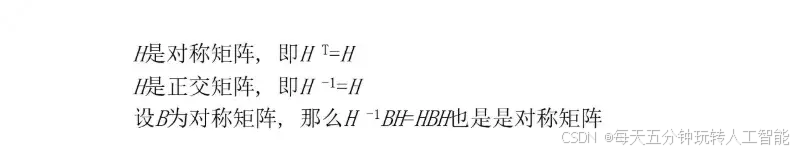
人工智能之数学基础:初等反射阵
本文重点 在线性代数中,初等反射阵(Householder矩阵)作为一类特殊的正交矩阵,在矩阵变换、特征值计算及几何变换等领域具有广泛应用。其简洁的构造方式和丰富的数学性质,使其成为数值分析和几何处理中的重要工具。 什么是初等反射阵(豪斯霍尔德变换) I为单位矩阵,wwT…...

4.1 代码随想录第三十二天打卡
准备:完全背包理论基础-二维DP数组 1.完全背包就是同一物品可以往里多次装 2.这里先遍历背包 或物品都可以 3.dp[i][j] 表示从下标为[0-i]的物品,每个物品可以取无限次,放进容量为j的背包,价值总和最大是多少 518.零钱兑换II (1)题目描述…...
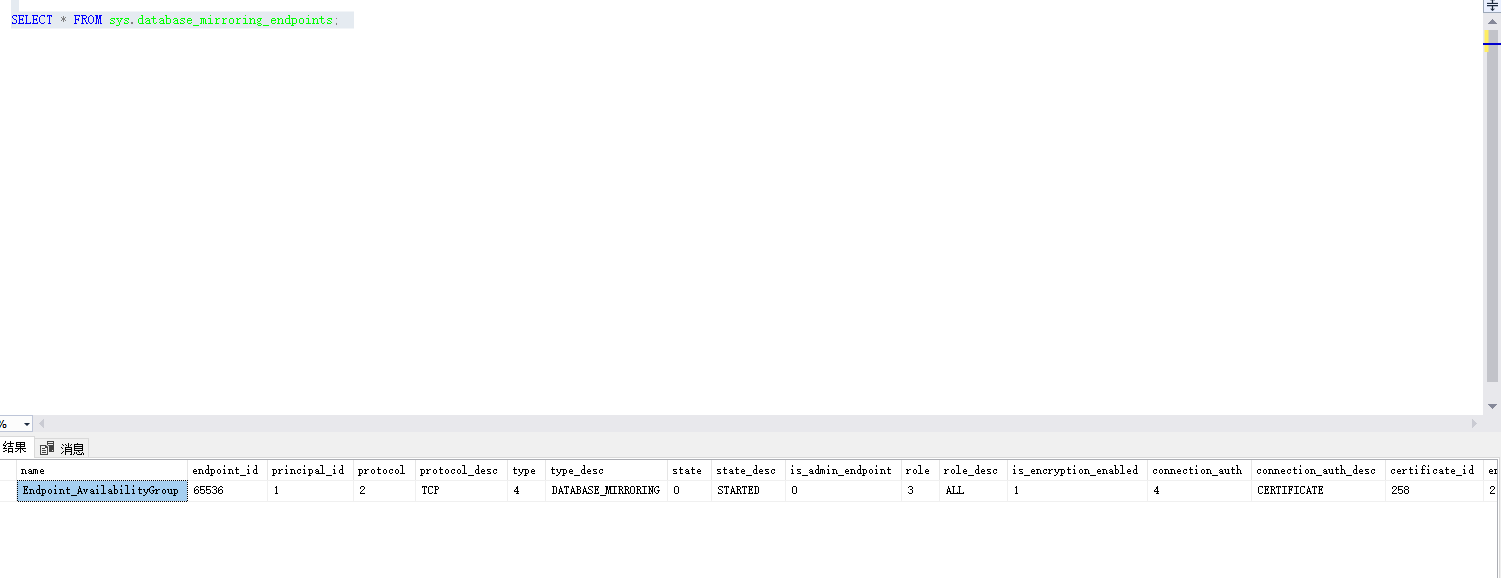
SQL Server:数据库镜像端点检查
目录标题 **1. 端点的作用****2. 检查的主要内容****(1)端点是否存在****(2)端点状态****(3)协议与端口****(4)权限配置** **3. 操作步骤(示例)****ÿ…...

【区块链安全 | 第九篇】基于Heimdall设计的智能合约反编译项目
文章目录 背景目的安装1、安装 Rust2、克隆 heimdall-dec3、编译 heimdall-dec4、运行 heimdall-dec 使用说明1、访问 Web 界面2、输入合约信息3、查看反编译结果 实战演示1、解析普通合约2、解析代理合约 背景 在区块链安全研究中,智能合约的审计和分析至关重要。…...

【Easylive】TokenUserInfoDto中@JsonIgnoreProperties和 Serializable 接口作用
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 这段代码定义了一个名为 TokenUserInfoDto 的 DTO(数据传输对象),用于封装用户令牌信息。以下是对 JsonIgnoreProperties 和 Serializable 接口作用的详…...
k8s EmptyDir(空目录)详解
1. 定义与特性 emptyDir 是 Kubernetes 中一种临时存储卷类型,其生命周期与 Pod 完全绑定。当 Pod 被创建时,emptyDir 会在节点上生成一个空目录;当 Pod 被删除时,该目录及其数据会被永久清除。它主要用于同一 Pod 内多个容器间的…...
)
毕业设计:实现一个基于Python、Flask和OpenCV的人脸打卡Web系统(六)
毕业设计:实现一个基于Python、Flask和OpenCV的人脸打卡Web系统(六) Flask Flask是一个使用 Python 编写的轻量级 Web 应用框架。其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 。Flask使用 BSD 授权。 Flask也被称为 “microframework” ,因为它使用简单的核心,…...

洛谷题单2-P5717 【深基3.习8】三角形分类-python-流程图重构
题目描述 给出三条线段 a , b , c a,b,c a,b,c 的长度,均是不大于 10000 10000 10000 的正整数。打算把这三条线段拼成一个三角形,它可以是什么三角形呢? 如果三条线段不能组成一个三角形,输出Not triangle;如果是…...
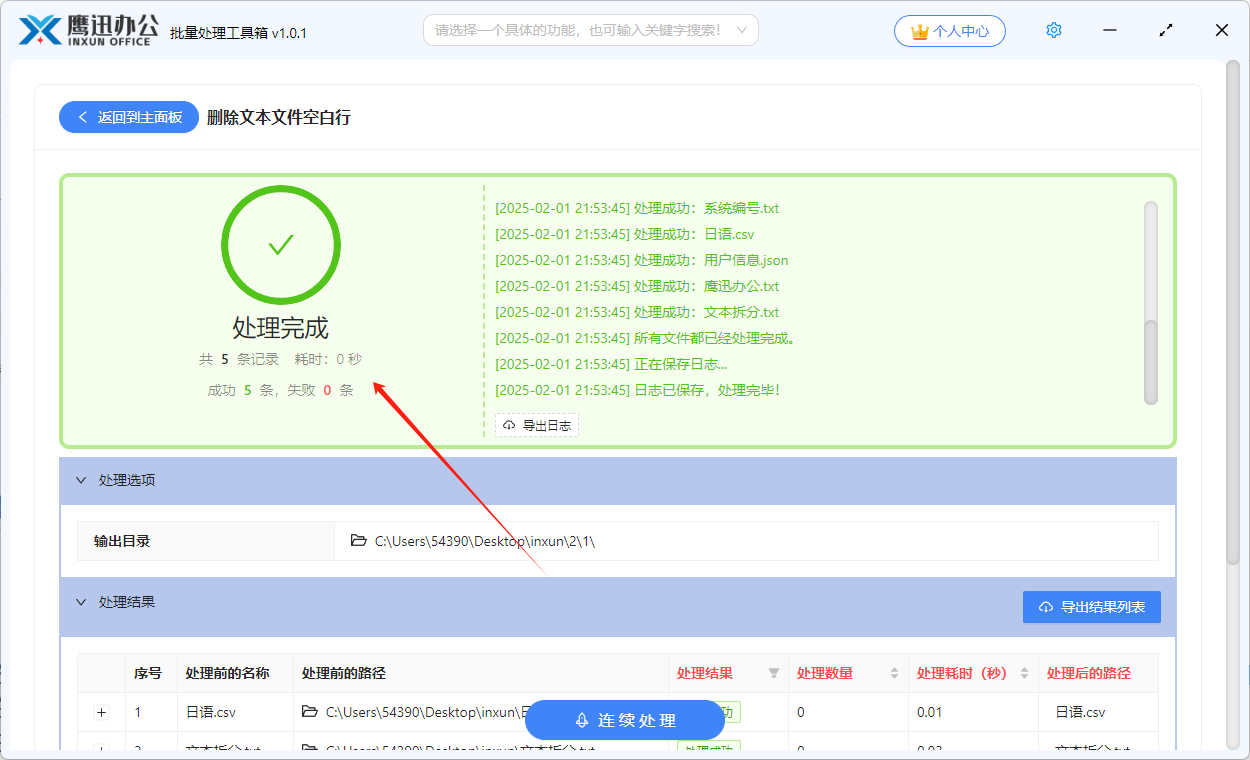
批量删除 txt/html/json/xml/csv 等文本文件空白行
我们常常会遇到需要删除 txt 文本文件中空白行的情况,如果文本文件较大,行数较多的时候,有些空白行不容易人工识别,这使得删除文本文件空白行变得非常繁琐,我们需要先找到空白的行,然后才能进行删除操作。尤…...
 和 tinyint 有什么区别)
MySQL数据库中,tinyint(1) 和 tinyint 有什么区别
TINYINT(1) 和 TINYINT 的区别 在 MySQL 中,TINYINT(1) 和 TINYINT 本质上是相同的数据类型,但 TINYINT(1) 中的 (1) 实际上不会影响存储大小或取值范围。 1. TINYINT 及其取值范围 TINYINT 是 MySQL 中最小的整数类型,占用 1 个字节 (8 bi…...

android databinding使用教程
Android DataBinding 是一种可以将 UI 组件与数据源绑定的框架,能够减少 findViewById 的使用,并提高代码的可维护性。下面是 DataBinding 的完整使用教程: 1. 启用 DataBinding 在 build.gradle(Module 级别)中启用 …...

【FreeRtos】任务调度器可以被挂起吗?
1. 省流回答 FreeRTOS的任务调度器可以被挂起(Suspend)。 通过调用API函数 vTaskSuspendAll(),可以临时禁止任务调度器的运行,此时系统将不再进行任务切换(包括抢占式调度和时间片轮转),但中断…...

ES5内容之String接口
注意:slice、substr、substring 都接受一个或两个参数,第一个参数指定字符串的开始位置,第二个参数表示子字符串到哪里结束,slice 和 substring 的第二个参数指定的是子字符串的最后一个字符后面的位置,substr 第二个参…...