NLP语言模型训练里的特殊向量
1. CLS 向量和 DEC 向量的区别及训练方式
(1) CLS 向量与 DEC 向量是否都是特殊 token?
CLS 向量([CLS] token)和 DEC 向量(Decoder Input token)都是特殊的 token,但它们出现在不同类型的 NLP 模型中,并承担不同的功能。
-
CLS 向量([CLS] token)
- 主要出现在 BERT 类的双向 Transformer 编码器模型中,比如 BERT、RoBERTa、ALBERT 等。
- 用于表示整个输入序列的全局信息,常用于分类任务(如情感分析、文本匹配)。
- 具体机制:
- 在 BERT 预训练阶段,[CLS] token 被加在输入文本的最前面。
- 经过 Transformer 编码层后,输出的 CLS 向量聚合了整个文本的信息,最终送入分类头进行任务训练。
- 例如,在情感分类任务中,CLS 向量会经过全连接层和 softmax 变换,输出正负类别概率。
-
DEC 向量(Decoder Input token)
- 主要出现在 Encoder-Decoder 结构的模型中,比如 Transformer(用于机器翻译)、T5(用于文本生成)等。
- 充当解码器的初始输入,通常由
<bos>(begin-of-sequence) 或者<s>(start token)表示。 - 具体机制:
- 训练时,Decoder 需要一个起始 token(例如
<bos>),然后依赖 Encoder 的输出和已生成的部分自回归地预测下一个 token。 - 生成过程中,每个时间步的 DEC 向量都会影响下一个 token 的生成。
- 训练时,Decoder 需要一个起始 token(例如
(2) CLS 向量和 DEC 向量如何初始化?
-
CLS 向量初始化:
在 BERT 预训练时,[CLS] token 的初始向量与普通词向量一样,随机初始化,并在训练过程中通过梯度下降不断优化。 -
DEC 向量初始化:
在 Transformer 类模型中,DEC token 也通常是随机初始化的,但是不同的模型可能采用不同的方法:- 在 T5 这种预训练模型中,Decoder 的输入采用的是预训练时学习到的
<s>token 。 - 在机器翻译任务中,Decoder 可能使用源语言的
<bos>作为起点。
- 在 T5 这种预训练模型中,Decoder 的输入采用的是预训练时学习到的
(3) CLS 向量和 DEC 向量如何参与训练?
-
CLS 向量的训练方式:
- 在 BERT 预训练任务(如 Masked Language Model 和 Next Sentence Prediction)中,CLS 向量是计算句子级别任务损失的关键部分。
- 在下游任务中(如文本分类),CLS 向量会经过额外的线性层,用于预测类别标签。
-
DEC 向量的训练方式:
- 参与自回归训练,即在训练时,Decoder 只能够看到之前的词,而预测当前时间步的目标词(Teacher Forcing 机制)。
- 目标是最大化正确序列的似然,使得 DEC 向量能够学习如何有效指导解码器生成合理的输出。
(4) CLS 向量和 DEC 向量本质上是否相同?
从数学本质上看,它们都是高维向量(embedding),但在模型设计上:
- CLS 向量用于编码文本全局语义,属于 Encoder 端的产物。
- DEC 向量用于自回归地指导序列生成,属于 Decoder 端的输入。
- 区别主要体现在训练方式、任务目标和语义作用上。
2. 分类损失(如交叉熵) vs. 语言模型损失(如负对数似然)
这两种损失都用于 NLP 任务,但应用场景不同。
(1) 分类损失(Cross Entropy, CE)
-
适用任务: 用于文本分类、命名实体识别(NER)、情感分析等任务。
-
计算方式:
- 先计算模型输出的类别概率分布:
p i = softmax ( z i ) p_i = \text{softmax}(z_i) pi=softmax(zi) - 再计算真实类别 ( y ) 与预测类别 ( p ) 之间的交叉熵:
L = − ∑ i y i log p i L = -\sum_{i} y_i \log p_i L=−i∑yilogpi
- 先计算模型输出的类别概率分布:
-
特点:
- 仅在整个输入上计算一个类别概率,而不涉及逐 token 预测。
(2) 语言模型损失(Negative Log Likelihood, NLL)
-
适用任务: 用于文本生成、机器翻译、问答任务(如 GPT、T5)。
-
计算方式:
- 语言模型在训练时,目标是最大化正确序列的似然概率,其损失形式为:
L = − ∑ t log p ( y t ∣ y < t , x ) L = -\sum_{t} \log p(y_t | y_{<t}, x) L=−t∑logp(yt∣y<t,x) - 这里,( y_t ) 是第 ( t ) 个时间步的目标词,( y_{<t} ) 代表已生成的部分,( x ) 是输入序列(如果是 Encoder-Decoder)。
- 语言模型在训练时,目标是最大化正确序列的似然概率,其损失形式为:
-
特点:
- 逐 token 计算损失,关注序列的生成概率。
- 在自回归(Auto-regressive)任务中,每个 token 预测结果依赖前面已生成的部分。
(3) 两者的主要区别
| 分类损失(CE) | 语言模型损失(NLL) | |
|---|---|---|
| 任务类型 | 句子级别任务(分类) | 逐 token 预测任务(生成) |
| 计算方式 | 计算整个文本的类别概率 | 计算每个 token 的预测概率 |
| 是否自回归 | 否 | 是 |
3. 自回归(Autoregressive, AR)
(1) 自回归的定义
自回归(Autoregressive)是一种序列建模方法,当前时间步的预测依赖于过去的输出。
(2) 为什么叫“自回归”?
- “回归” 这个术语在统计学中表示根据历史数据预测未来值。
- “自” 指的是模型的输入来自于自己之前的预测。
- 因此,自回归 = “使用自身过去的信息来预测未来”。
(3) NLP 中的自回归模型
-
GPT(Generative Pre-trained Transformer)
-
在第 ( t ) 个时间步,只能看到 ( y_1, y_2, \ldots, y_{t-1} ) 这些前面的 token,不能看到未来的信息。
-
预测方式:
p ( y t ∣ y < t ) p(y_t | y_{<t}) p(yt∣y<t) -
依赖“过去的输出”来预测下一个词,典型的自回归结构。
-
-
BERT 不是自回归模型
- BERT 是 双向 Transformer,训练时可以看到整个输入,因此它不是自回归模型。
(4) 自回归的应用
- 语言模型(GPT、XLNet)
- 机器翻译(Transformer Decoder)
- 语音生成(WaveNet)
总结
-
CLS 向量和 DEC 向量本质上都是向量,但用途不同:
- CLS 向量用于文本分类、全局表征;
- DEC 向量用于解码器输入,引导文本生成。
-
分类损失 vs. 语言模型损失:
- 交叉熵用于整体分类;
- 负对数似然用于逐 token 预测。
-
自回归(Auto-regressive)是指依赖自身过去输出进行预测,GPT 等生成模型采用这一机制。
在 NLP 任务中,<s> 和 <bos> 都是 特殊 token,但它们的使用方式略有不同,取决于具体的模型和任务。
1. <s>(Start-of-Sequence Token)
<s> 代表 序列的起始 token,在不同的模型中用途不同:
-
在 T5 模型(Text-to-Text Transfer Transformer)中:
T5是一个 Encoder-Decoder 结构的 Transformer,所有任务都被转换成文本生成任务。- 在 T5 的 Decoder 中,解码输入(Decoder Input)以
<s>作为起始 token,然后逐步生成后续 token。 - 训练时:
输入 (Encoder Input) = "Translate English to French: I love NLP" 目标输出 (Decoder Target) = "<s> J'aime le NLP </s>" - 预测时:
<s>提供解码起点,模型基于 Encoder 的输出和<s>生成下一个 token。
-
在 BART(Bidirectional and Auto-Regressive Transformer)模型中:
BART也是 Encoder-Decoder 结构,用于文本填充、摘要等任务。<s>用于标识句子开始,在BART预训练阶段,模型可能会恢复丢失的<s>token。
-
在一些 NLP 任务中:
<s>也可以作为整个句子或段落的起点,类似于[CLS](BERT 中用于分类任务的 token)。
2. <bos>(Beginning-of-Sequence Token)
<bos> 代表 序列的开始,用于 自回归(Auto-regressive)解码:
-
在机器翻译(MT)任务中:
Transformer结构的 Decoder 需要一个起始 token,通常用<bos>作为 Decoder 的输入。- 例如:
源语言输入 (Encoder Input): "I love NLP" 目标输出 (Decoder Target): "<bos> J'aime le NLP <eos>" - 在训练时,Decoder 会在
<bos>之后一个个预测目标语言的 token,直到遇到<eos>(end-of-sequence)。
-
在 GPT 这样的自回归模型中:
GPT主要用于文本生成任务,如对话、摘要。<bos>告诉模型“文本从这里开始”,然后 GPT 依次预测下一个 token。
3. <s> 和 <bos> 的区别
| Token | 常见用途 | 典型模型 |
|---|---|---|
<s> (Start-of-Sequence) | 句子/段落的起点,用于 Encoder-Decoder 任务 | T5、BART |
<bos> (Beginning-of-Sequence) | 自回归生成的起始 token,特别用于解码 | GPT、Transformer Decoder |
- 如果是 Encoder-Decoder 结构(如 T5、BART),一般使用
<s>作为起始 token。 - 如果是 仅 Decoder 结构(如 GPT),则使用
<bos>作为文本生成的起始 token。
相关文章:

NLP语言模型训练里的特殊向量
1. CLS 向量和 DEC 向量的区别及训练方式 (1) CLS 向量与 DEC 向量是否都是特殊 token? CLS 向量([CLS] token)和 DEC 向量(Decoder Input token)都是特殊的 token,但它们出现在不同类型的 NLP 模型中&am…...
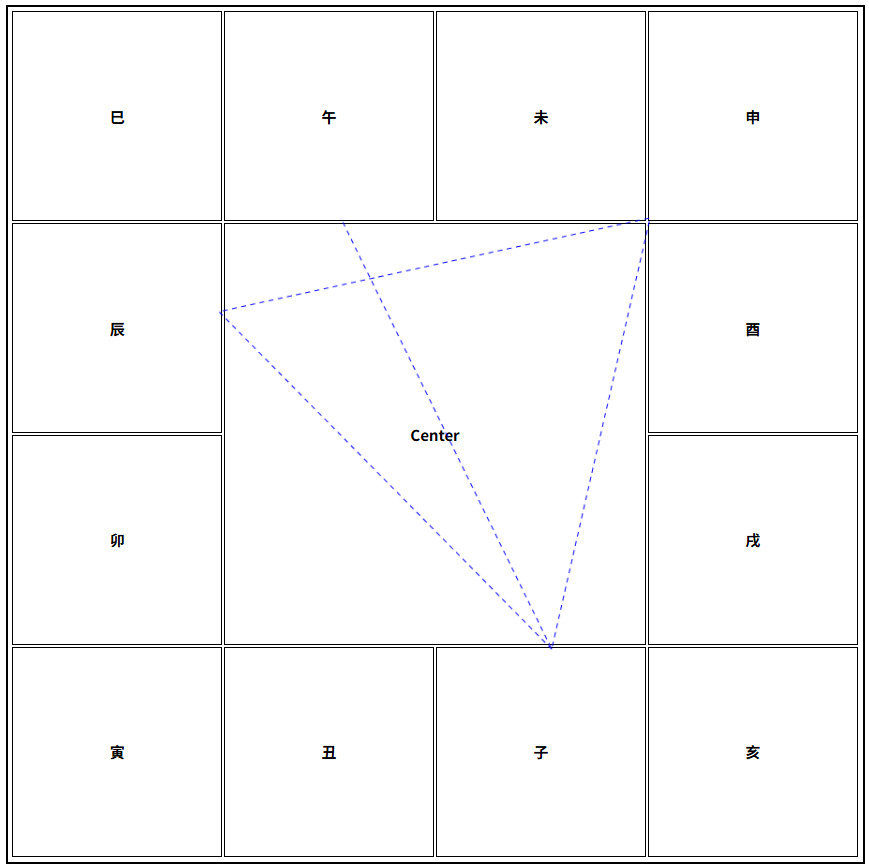
利用Canvas在紫微斗数命盘上画出三方四正
许多紫微斗数排盘程序都会在命盘上画出三方四正的指示线,便于观察命盘。本文用Canvas在一个模拟命盘上画出三方四正指示线。 模拟命盘并画出“子”宫三方四正的HTML文件如下: <!doctype html> <html lang"en"> <head><…...
传统汽车 HMI 设计 VS 新能源汽车 HMI 设计,有何不同?
一、设计理念与目标的差异 传统汽车HMI设计的核心目标是辅助驾驶,强调功能的简洁性和操作的便捷性。其设计侧重于提供基础的车辆信息(如车速、转速、油量等),并确保驾驶员在操作时能够快速获取关键信息。相比之下,新能…...

【JavaWeb】前端基础
JavaWeb 前端三大件:HTML(主要用于网页主体结构的搭建),CSS(页面美化),JavaScript(主要用于页面元素的动态代理) 1. HTML 1.1 html概述 HTML:Hyper Text …...

SpringMVC组件解析
SpringMVC的执行流程 ① 用户发送请求至前端控制器DispatcherServlet。 ② DispatcherServlet收到请求调用HandlerMapping处理器映射器 ③ 处理器映射器找到具体的处理器(可以根据xm|配置、注解进行査找),生成处理器对象及处理器 拦截器(如果有则生成)一…...

使用 Provider 和 GetX 实现 Flutter 局部刷新的几个示例
1. 使用 Provider 实现局部刷新 示例 1:ChangeNotifier Consumer 通过 ChangeNotifier 和 Consumer 实现局部刷新。 import package:flutter/material.dart; import package:provider/provider.dart;void main() {runApp(ChangeNotifierProvider(create: (_) &g…...

数据结构C语言练习(两个栈实现队列)
一、引言 在数据结构的学习中,我们经常会遇到一些有趣的问题,比如如何用一种数据结构去实现另一种数据结构的功能。本文将深入探讨 “用栈实现队列” 这一经典问题,详细解析解题思路、代码实现以及每个函数的作用,帮助读者更好地…...

Java 基础-28- 多态 — 多态下的类型转换问题
在 Java 中,多态(Polymorphism)是面向对象编程的核心概念之一。多态允许不同类型的对象通过相同的方法接口进行操作,而实际调用的行为取决于对象的实际类型。虽然多态提供了极大的灵活性,但在多态的使用过程中…...
nextjs使用02
并行路由 同一个页面,放多个路由,, 目录前面加,layout中可以当作插槽引入 import React from "react";function layout({children,notifications,user}:{children:React.ReactNode,notifications:React.ReactNode,user:React.Re…...

第2.6节 iOS生成全量和增量报告
2.6.1 简介 在采集了覆盖率数据后,就需要生成对应需求的全量和增量覆盖率报告,以便对测试进行查漏补缺。IOS系统有两种开发语言,所以生成报告的方式也不相同,下面就分别介绍一下Object C和Swift语言如何生成覆盖率报告。 2.6.2 O…...
应用分享 | AWG技术突破:操控钻石氮空位色心,开启量子计算新篇章!
利用AWG操作钻石中的氮空位色彩中心 金刚石中的颜色中心是晶格中的缺陷,其中碳原子被不同种类的原子取代,而相邻的晶格位点则是空的。由于色心具有明亮的单光子发射和光学可触及的自旋,因此有望成为未来量子信息处理和量子网络的固态量子发射…...

前端开发学习路线完整指南
前端开发学习路线完整指南 前端开发是一个不断发展的领域,涉及多个技术栈。本文将为你提供一条系统的前端学习路线,帮助你从零基础到熟练掌握前端开发技能。 1. 前置知识 在学习前端之前,了解一些基础知识会对你的学习过程有很大帮助。 计…...

linux服务器专题2------vim编辑器如何设置显示行号
在 Vim 编辑器中,可以通过以下步骤来显示行号: 临时显示行号 打开 Vim 编辑器,输入如下命令: :set number这将临时启用行号显示。关闭 Vim 后,行号设置将丢失。 永久显示行号 如果希望在每次启动 Vim 时都显示行号…...

Jmeter触发脚本备份
JMeter 在以下情况会触发脚本备份: 手动保存测试计划时:如果测试计划有未保存的修改,当用户手动保存测试计划(脚本)时,JMeter 都会自动将当前脚本备份到${JMETER_HOME}/backups文件夹下。 关闭 JMeter 时…...

【视觉与语言模型参数解耦】为什么?方案?
一些无编码器的MLLMs统一架构如Fuyu,直接在LLM内处理原始像素,消除了对外部视觉模型的依赖。但是面临视觉与语言模态冲突的挑战,导致训练不稳定和灾难性遗忘等问题。解决方案则是通过参数解耦方法解决模态冲突。 在多模态大语言模型…...
重建二叉树(C++)
目录 1 问题描述 1.1 示例1 1.2 示例2 1.3 示例3 2 解题思路 3 代码实现 4 代码解析 4.1 初始化 4.2 递归部分 4.3 主逻辑 5 总结 1 问题描述 给定节点数为 n 的二叉树的前序遍历和中序遍历结果,请重建出该二叉树并返回它的头结点。 例如输入前序遍历序…...

VLAN、QinQ、VXLAN的区别
1、技术本质与封装方式 技术OSI层级封装原理标识位长度拓展性VLAN数据链路层L2在以太网帧头插入802.1Q Tag(单层VLAN标签)12位(4094个)有限,仅支持单一网络域内隔离QinQ数据链路层L2在原始VLAN标签外再封装一层802.1Q…...

保姆级教程:synchronized 同步方法 vs 同步代码块,看完彻底懂锁!
一、同步方法(锁住整个方法) 1. 代码示例 public class Counter {private int count 0;// 同步方法:锁住整个方法public synchronized void add() {count;}// 同步方法:锁住整个方法public synchronized void subtract() {coun…...

10乱码问题的解释(1)
在计算机中,一个汉字,占几个字节? 针对这个问题,只要你回答出一个具体的数字,就一定是错的!! 前提条件: 当前中文编码使用的是哪种方式(字符集) 计算机存的其实是二进制数字~~ 英文字母,怎么表示的?? ASCII 码表~~ 规定了每个字符,都有一个对应的数字来表示~~ 只是表示英文,…...

短视频文案--钓鱼女和滑板女
短视频文案 第一个文案: 1标题:风萧萧兮易水寒,美女钓鱼兮不复还 2内容: 我站在池边的微风中,再也看不到曾经快乐的少女了。 风很凉,凉得心不知前往何处。 水很清,清得深知这里没鱼群。 芦苇…...

算法设计学习3
实验目的及要求: 1.加强对结构体的应用。 2.熟悉字符计数排序。 实验设备环境: 1.微型计算机 2.DEV C(或其他编译软件) 实验步骤: 任务:要求使用自定义函数来实现 输入一段文本,统计每个字符出现的次数,按…...

nginx的自动跳转https
mkdir /usr/local/nginx/certs/ 创建一个目录 然后用openssl生成证书 编辑nginx的配置文件 自动跳转成功 做一个优化,如果访问的时候后面加了其他的uri也一起自动跳转了...

python-leetcode 62.搜索插入位置
题目: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置 方法一:二分查找 假设题意是在排序数组中寻找是否存在一个目标值,则可以…...

2. ollama下载及安装deepseek模型
ollamam 1. ollama2. ollama常用命令3. Windows配置Ollama与DeepSeek自定义目录环境3.1 自定义安装3.3 添加到系统变量 1. ollama 官网地址 下载地址 测试安装 deepseek模型下载地址 根据电脑性能下载对应版本 2. ollama常用命令 # 运行模型 ollama run 模型 # 查看模型…...

deepseek使用记录26——思维混乱背后的理论泡沫与骗局
一 后现代主义哲学自20世纪60年代兴起以来,其理论形态和社会影响一直备受争议。支持者认为它是对现代性弊病的批判和解构,而反对者则将其视为一种脱离现实的“工业化学术生产”,甚至是一场哲学骗局。结合相关文献和案例,可从以下角…...
)
服务器入门操作1(深度学习)
服务器相关 基本命令 查看GPU状态: 查看GPU信息查看CPU信息查看系统版本号 nvidia-smi lscpu lsb_release -a清屏: clearanaconda相关: 查看环境列表激活虚拟环境退出虚拟环境跳转至目录跳转至上一级目录 conda env list conda activa…...
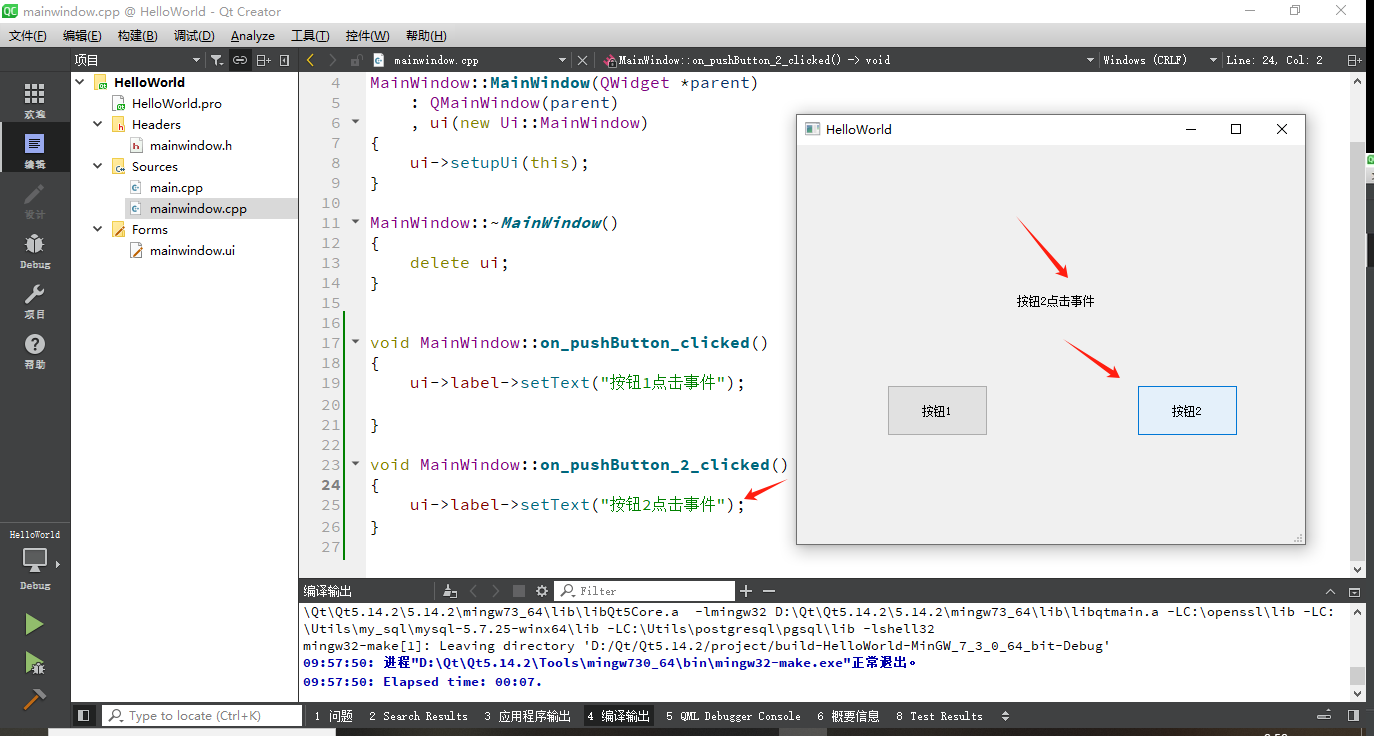
Qt基本框架(1)
本篇主要介绍Qt的基本框架,并实现简单的按钮事件 本文部分ppt、视频截图原链接:[萌马工作室的个人空间-萌马工作室个人主页-哔哩哔哩视频] 1. Qt基本框架介绍 Qt基本框架主要分为两部分:Qt实例对象和Qt窗口。Qt实例对象负责初始化Qt运行时…...

Buzz1.2.0视频语音转成TXT、SRT、VTT工具
buzz0.9.0.exe下载 https://download.csdn.net/download/u011000529/90551347 特征 导入音频和视频文件并导出文本到 TXT、SRT 和 VTT从您计算机的麦克风转录和翻译成文本(资源密集型且可能不是实时的,Demo)支持Whisper、 Whisper.cpp、Fast…...

动手学深度学习:AlexNet
前言 从这个模型开始,我的数据集主阵地就将从装甲板转移到手语视频数据集,模型开始变得更加复杂,数据集当然也要更复杂啦,我将记录在这个过程中遇到的问题和解决后续。 数据读取 由于是视频数据集,我采取的方法是将…...
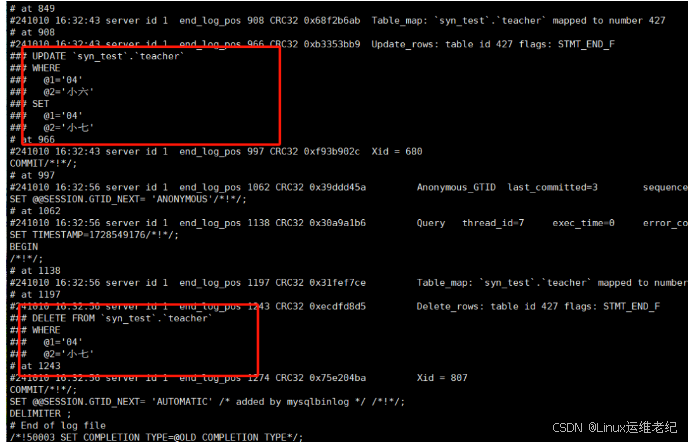
MySql之binlog与数据恢复(Binlog and Data Recovery in MySQL)
MySql之binlog与数据恢复 什么是binlog binlog我们一般叫做归档日志,他是mysql服务器层的日志,跟存储引擎无关,他记录的是所有DDL和DML的语句,不包含查询语句,binlog是一种逻辑日志,他记录的是sql语句的原…...