Python学习第二十七天
yield关键字
yield关键字扮演着核心角色,主要用于处理异步数据流和请求调度。
主要作用
-
生成器函数:将方法转换为生成器,可以逐步产生结果而不需要一次性返回所有数据
-
异步处理:支持Scrapy的异步架构,提高爬取效率
-
请求调度:用于发起新的请求或传递处理后的数据
使用场景
| 使用场景 | 代码示例 | 说明 |
|---|---|---|
| 发起新请求 | yield scrapy.Request(url, callback=self.parse_detail) | 用于生成新的请求,Scrapy 会自动调度并下载,完成后调用指定的回调函数。 |
| 返回提取的数据 | yield {"title": response.css("h1::text").get()} | 返回字典或 Item 对象,数据会进入 Item Pipeline 进行处理和存储。 |
| 处理分页 | yield response.follow(next_page, callback=self.parse) | 跟踪下一页链接,常用于分页爬取。 |
| 多个结果逐条返回 | python<br>for product in products:<br> yield {"name": product.css(...)}<br> | 在循环中逐个 yield 结果,避免内存占用过高,适合大量数据的情况。 |
| 结合请求和数据 | python<br>yield scrapy.Request(url1, callback=...)<br>yield {"data": ...}<br> | 同一个解析方法可以混合 yield 请求和数据,Scrapy 会分别处理。 |
| 委托生成器 | yield from self.parse_other(response) | (Python 3.3+)将生成操作委托给另一个生成器函数,通常用于模块化代码。 |
为什么不使用return
-
内存效率:yield逐个返回结果,避免一次性加载所有数据到内存
-
异步支持:Scrapy的异步架构依赖生成器实现高效调度
-
灵活性:可以在一个方法中yield多个不同类型的对象(请求或数据)
-
管道处理:yield的Item会自动进入Item Pipeline进行处理
注意事项
-
yield的对象必须是
Request、Item、dict或None之一 -
使用
yield from可以委托给另一个生成器(在Python 3.3+) -
确保每个yield的对象都被正确处理,避免数据丢失
链接提取器
官网概念:链接提取器是从响应中提取链接的对象。
导入
from scrapy.linkextractors import LinkExtractor使用
import scrapy
import os
from ..items import TestprojectItem
from scrapy.linkextractors import LinkExtractor# 项目测试
class TestSpider(scrapy.Spider):def __init__(self):self.linkExtractor = LinkExtractor()name = "test"# 或者直接卸载头部的strt_url中 一样的 为什么知道这个方法 查看父类的spider 集成了 所以使用子类会自动覆盖父类相同方法# 路劲注意 file:///是本地文件开头 如果是绝对路径自己直接写即可 如果是相对路径使用下面的即可def start_requests(self):# 获取当前目录的绝对路径current_dir = os.path.dirname(os.path.abspath(__file__))file_path = os.path.join(current_dir, 'test.html')# 替换反斜杠为正斜杠,并添加 file:/// 前缀file_url = 'file:///' + file_path.replace('\\', '/')yield scrapy.Request(url=file_url, callback=self.parse)def parse(self, response):# 链接提取器for link in self.linkExtractor.extract_links(response):print("testLink:",link)print("testLink 获取属性:",link.__getattribute__("url"))return itemFeed 导出
官网概念:在实现scraper时,最经常需要的功能之一是能够正确地存储被抓取的数据,这通常意味着用被抓取的数据(通常称为“导出提要”)生成一个“导出文件”,供其他系统使用。
支持多种导出格式:
-
JSON (
json) -
JSON Lines (
jsonlines) -
CSV (
csv) -
XML (
xml) -
Pickle (
pickle) -
Marshal (
marshal)
导入
settings中设置
# 每2条记录保存一个文件分批导出测试 FEED_EXPORT_BATCH_ITEM_COUNT = 2# 全局导出的编码格式 FEED_EXPORT_ENCODING = 'utf-8' # 同时导出JSON和CSV FEEDS = {'output/test_links_batch_%(batch_id)d.json': {'format': 'json','encoding': 'utf8','indent': 4,'fields': ['title', 'url'], # 指定导出的字段'overwrite': True # 覆盖已存在的文件},'output/test_links_batch_%(batch_id)d.csv': {'format': 'csv', # 格式'encoding': 'utf8', # 编码'fields': ['title', 'url'], # 指定字段顺序'overwrite': True # 覆盖已存在的文件} }
使用
# feed 导出测试
for link in response.css('a'):# yield 挨个处理任务yield {'url': link.attrib.get('href', '').strip(),'title': link.css('::text').get('').strip()
}常用方法
需要时查询即可,不用都练习、上面的能解决很多问题、分批次用的比较多吧。
基础配置参数
| 参数名 | 类型 | 默认值 | 描述 | 示例 |
|---|---|---|---|---|
FEED_URI | 字符串 | None | 导出文件的URI路径 | 'file:///tmp/export.json' |
FEED_FORMAT | 字符串 | None | 导出格式(json, jsonlines, csv, xml等) | 'json' |
FEED_STORAGES | 字典 | 内置存储 | 自定义存储后端 | {'s3': 'myproject.storage.S3Storage'} |
FEED_STORAGE_PARAMS | 字典 | {} | 存储后端的参数 | {'access_key': 'xxx', 'secret_key': 'xxx'} |
FEED_EXPORTERS | 字典 | 内置导出器 | 自定义导出器 | {'myformat': 'myproject.exporters.MyExporter'} |
FEED_EXPORT_FIELDS | 列表 | None | 指定导出的字段及顺序 | ['title', 'price', 'url'] |
FEED_EXPORT_ENCODING | 字符串 | 'utf-8' | 导出文件的编码 | 'gbk' |
FEED_EXPORT_INDENT | 整数 | 0 | JSON导出的缩进(0表示紧凑格式) | 4 |
高级配置参数
| 参数名 | 类型 | 默认值 | 描述 | 示例 |
|---|---|---|---|---|
FEED_STORE_EMPTY | 布尔 | False | 是否存储空结果 | True |
FEED_APPEND | 布尔 | False | 是否追加到现有文件 | True |
FEED_OVERWRITE | 布尔 | True | 是否覆盖现有文件 | False |
FEED_EXPORT_BATCH_ITEM_COUNT | 整数 | None | 分批导出时的每批数量 | 1000 |
FEED_EXPORTER_PARAMS | 字典 | {} | 导出器的额外参数 | {'ensure_ascii': False} |
存储后端特定参数
本地文件系统
| 参数名 | 描述 | 示例 |
|---|---|---|
file:// 前缀 | 本地文件路径 | 'file:///path/to/export.json' |
FTP
| 参数名 | 描述 | 示例 |
|---|---|---|
ftp:// 前缀 | FTP服务器路径 | 'ftp://user:pass@ftp.example.com/path/to/export.json' |
FEED_STORAGE_FTP_ACTIVE | 使用主动模式 | True |
S3
| 参数名 | 描述 | 示例 |
|---|---|---|
s3:// 前缀 | S3路径 | 's3://bucket/path/to/export.json' |
AWS_ACCESS_KEY_ID | AWS访问密钥 | |
AWS_SECRET_ACCESS_KEY | AWS秘密密钥 | |
FEED_STORAGE_S3_ACL | 设置ACL权限 | 'private' |
命令行参数
| 参数 | 描述 | 示例 |
|---|---|---|
-o FILE | 快捷导出文件 | -o items.json |
-O FILE | 覆盖导出文件 | -O items.json |
-t FORMAT | 指定导出格式 | -t csv |
请求与响应
官网概念:通常, Request 对象在spider中生成并在系统中传递,直到它们到达下载程序,下载程序执行请求并返回 Response 返回发出请求的spider的对象。在Scrapy中,scrapy.http.Request和scrapy.Request实际上是同一个类,但它们的导入方式不同。(功能完全相同且使用scrapy.request更常见,以下不用练习做个记录使用查询即可)
使用
from scrapy.http import Request# 简单GET请求
request = Request(url='http://example.com')# 带回调的请求
request = Request(url='http://example.com/products',callback=self.parse_products,meta={'page': 1},headers={'Referer': 'http://example.com'}
)构造参数详解
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
url | str | 必填 | 请求的URL |
callback | callable | None | 响应处理函数 |
method | str | 'GET' | HTTP方法 |
headers | dict | None | 请求头 |
body | bytes/str | None | 请求体 |
cookies | dict/list | None | Cookies |
meta | dict | None | 请求元数据 |
encoding | str | 'utf-8' | 编码 |
priority | int | 0 | 优先级(0-1000) |
dont_filter | bool | False | 是否跳过去重 |
errback | callable | None | 错误处理函数 |
flags | list | None | 请求标志 |
cb_kwargs | dict | None | 回调函数的额外参数 |
常用方法和属性
核心属性
| 属性 | 类型 | 描述 | 示例 |
|---|---|---|---|
url | str | 请求的URL | 'http://example.com' |
method | str | HTTP方法(GET/POST等) | 'GET', 'POST' |
headers | dict | 请求头信息 | {'User-Agent': 'Mozilla'} |
body | bytes | 请求体内容 | b'name=value' |
meta | dict | 请求的元数据 | {'proxy': 'http://proxy:3128'} |
cookies | dict/list | 请求的Cookies | {'sessionid': '123abc'} |
encoding | str | 请求的编码 | 'utf-8' |
priority | int | 请求优先级(0-1000) | 500 |
dont_filter | bool | 是否不过滤重复请求 | True |
callback | callable | 响应回调函数 | self.parse_detail |
errback | callable | 错误回调函数 | self.error_handler |
cb_kwargs | dict | 回调函数的额外参数 | {'page': 2} |
常用方法
| 方法 | 描述 | 示例 |
|---|---|---|
replace([url, method, headers, body, cookies, meta, encoding, callback, errback, cb_kwargs, dont_filter]) | 创建并返回新Request对象(替换指定属性) | new_request = request.replace(url=new_url) |
copy() | 创建Request的浅拷贝 | req_copy = request.copy() |
__str__() | 返回请求的字符串表示 | print(request) |
特殊属性/方法
| 属性/方法 | 描述 | 示例 |
|---|---|---|
flags | 请求的标志列表 | request.flags.append('cached') |
fingerprint | 请求的唯一指纹(用于去重) | print(request.fingerprint) |
_set_url(url) | 设置URL(内部方法) | - |
_set_body(body) | 设置请求体(内部方法) | - |
元数据(meta)常用键
| meta键 | 描述 | 示例 |
|---|---|---|
dont_redirect | 禁止重定向 | meta={'dont_redirect': True} |
handle_httpstatus_list | 处理非常规状态码 | meta={'handle_httpstatus_list': [404, 500]} |
dont_retry | 禁止重试 | meta={'dont_retry': True} |
download_timeout | 下载超时(秒) | meta={'download_timeout': 60} |
proxy | 使用代理 | meta={'proxy': 'http://proxy:3128'} |
depth | 请求深度 | meta={'depth': 3} |
item | 传递Item对象 | meta={'item': item} |
代码路径:pythonPractice: python学习内容练习-代码
相关文章:

Python学习第二十七天
yield关键字 yield关键字扮演着核心角色,主要用于处理异步数据流和请求调度。 主要作用 生成器函数:将方法转换为生成器,可以逐步产生结果而不需要一次性返回所有数据 异步处理:支持Scrapy的异步架构,提高爬取效率 …...

Docker Compose 启动jar包项目
参考文章安装Docker和Docker Compose 点击跳转 配置 创建一个文件夹存放项目例如mydata mkdir /mydata上传jar包 假设我的jar包名称为goudan.jar 编写dockerfile文件 vim app-dockerfile按键盘上的i进行编辑 # 使用jdk8 FROM openjdk:8-jre# 设置时区 上海 ENV TZAsia/Sh…...

pytorch中dataloader自定义数据集
前言 在深度学习中我们需要使用自己的数据集做训练,因此需要将自定义的数据和标签加载到pytorch里面的dataloader里,也就是自实现一个dataloader。 数据集处理 以花卉识别项目为例,我们分别做出图片的训练集和测试集,训练集的标…...
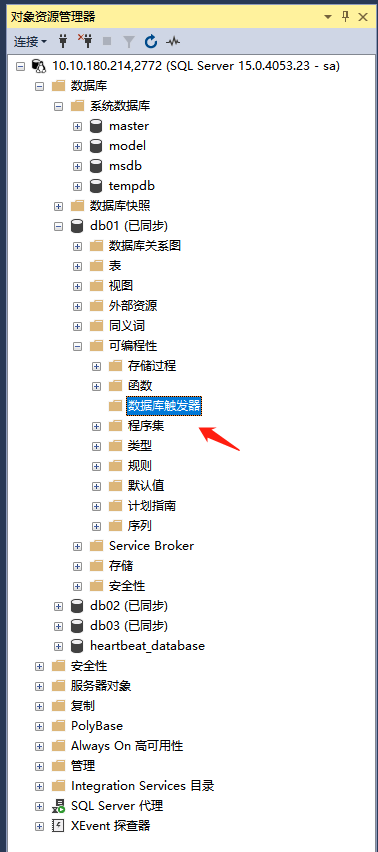
SQL Server:触发器
在 SQL Server Management Studio (SSMS) 中查看数据库触发器的方法如下: 方法一:通过对象资源管理器 连接到 SQL Server 打开 SSMS,连接到目标数据库所在的服务器。 定位到数据库 在左侧的 对象资源管理器 中,展开目标数据库&a…...

标题:利用 Rork 打造定制旅游计划应用程序:一步到位的指南
引言: 在数字化时代,旅游计划应用程序已经成为旅行者不可或缺的工具。但开发一个定制的旅游应用可能需要耗费大量时间与精力。好消息是,Rork 提供了一种快捷且智能的解决方案,让你能轻松实现创意。以下是使用 Rork 创建一个定制旅…...
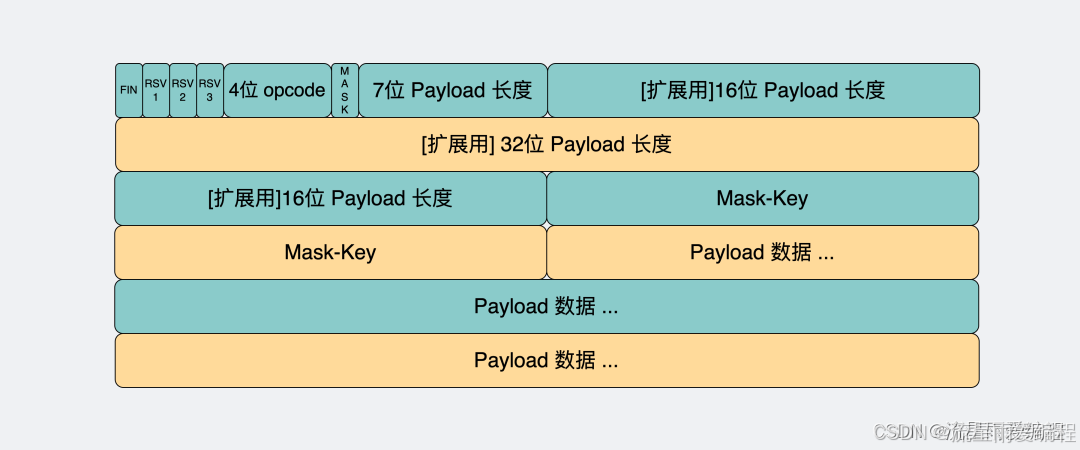
WebSocket原理详解(二)
WebSocket原理详解(一)-CSDN博客 目录 1.WebSocket协议的帧数据详解 1.1.帧结构 1.2.生成数据帧 2.WebSocket协议控制帧结构详解 2.1.关闭帧 2.2.ping帧 2.3.pong帧 3.WebSocket心跳机制 1.WebSocket协议的帧数据详解 1.1.帧结构 WebSocket客户端与服务器通信的最小单…...

计算声音信号波形的谐波
计算声音信号波形的谐波 1、效果 2、定义 在振动分析中,谐波通常指的是信号中频率是基频整数倍的成分。基频是振动的主要频率,而谐波可能由机械系统中的非线性因素引起。 3、流程 1. 信号生成:生成或加载振动信号数据(模拟或实际数据)。 2. 预处理:预处理数据,如去噪…...
RepoReporter 仿照`TortoiseSVN`项目监视器,能够同时支持SVN和Git仓库
RepoReporter 项目地址 RepoReporter 一个仓库监视器,仿照TortoiseSVN项目监视器,能够同时支持SVN和Git仓库。 工作和学习会用到很多的仓库,每天都要花费大量的时间在频繁切换文件夹来查看日志上。 Git 的 GUI 工具琳琅满目,Git…...

C++多线程的性能优化
高效线程池设计与工作窃取算法实现解析 1. 引言 现代多核处理器环境下,线程池技术是提高程序并发性能的重要手段。本文解析一个采用工作窃取(Work Stealing)算法的高效线程池实现,通过详细代码分析和性能测试展示其优势。 2. 线程池核心设计 2.1 类结…...
TS中的类)
【TS学习】(19)TS中的类
在 TypeScript 中,类(Class) 是面向对象编程的核心结构,用于封装数据和行为。TypeScript 的类继承了 JavaScript 的类特性,并增加了类型系统和高级功能的支持(如访问修饰符、存取器和装饰器)。 …...

UI设计系统:如何构建一套高效的设计规范?
UI设计系统:如何构建一套高效的设计规范? 1. 色彩系统的建立与应用 色彩系统是设计系统的基础之一,它不仅影响界面的整体美感,还对用户体验有着深远的影响。首先,设计师需要定义主色调、辅助色和强调色,并…...

深度学习--softmax回归
回归可以用于预测多少的问题,预测房屋出售价格,棒球队可能获胜的的常数或者患者住院的天数。 事实上,我们也对分类问题感兴趣,不是问 多少,而是问哪一个 1 某个电子邮件是否属于垃圾邮件 2 某个用户可能注册还是不注册…...

【计算机网络】记录一次校园网无法上网的解决方法
问题现象 环境:实训室教室内时间:近期突然出现 (推测是学校在施工,部分设备可能出现问题)症状: 连接校园网 SWXY-WIFI 后: 连接速度极慢偶发无 IP 分配(DHCP 失败)即使分…...

Java关于抽象类和抽象方法
引入抽象: 在之前把不同类中的共有成员变量和成员方法提取到父类中叫做继承。然后对于成员方法在不同子类中有不同的内容,对这些方法重新书写叫做重写;不过如果有的子类没有用继承的方法,用别的名字对这个方法命名的话࿰…...
第二十一章:Python-Plotly库实现数据动态可视化
Plotly是一个强大的Python可视化库,支持创建高质量的静态、动态和交互式图表。它特别擅长于绘制三维图形,能够直观地展示复杂的数据关系。本文将介绍如何使用Plotly库实现函数的二维和三维可视化,并提供一些优美的三维函数示例。资源绑定附上…...
(动态规划))
LeetCode 热题 100_打家劫舍(83_198_中等_C++)(动态规划)
LeetCode 热题 100_打家劫舍(83_198) 题目描述:输入输出样例:题解:解题思路:思路一(动态规划(一维dp数组)):思路二(动态规划ÿ…...

C语言复习--assert断言
assert.h 头⽂件定义了宏 assert() ,⽤于在运⾏时确保程序符合指定条件,如果不符合,就报错终止运行。这个宏常常被称为“断⾔”。 assert(p ! NULL); 代码在程序运⾏到这⼀⾏语句时,验证变量 p 是否等于 NULL 。如果确实不等于 NU…...
)
嵌入式软件设计规范框架(MISRA-C 2012增强版)
以下是一份基于MISRA-C的嵌入式软件设计规范(完整技术文档框架),包含编码规范、安全设计原则和工程实践要求: 嵌入式软件设计规范(MISRA-C 2012增强版) 一、编码基础规范 1.1 文件组织 头文件保护 /* 示…...

系统思考反馈
最近交付的都是一些持续性的项目,越来越感觉到,系统思考和第五项修炼不只是简单的一门课程,它们能真正融入到我们的日常工作和业务中,帮助我们用更清晰的思维方式解决复杂问题,推动团队协作,激发创新。 特…...

【C++】vector常用方法总结
📝前言: 在C中string常用方法总结中我们讲述了string的常见用法,vector中许多接口与string类似,作者水平有限,所以这篇文章我们主要通过读vector官方文档的方式来学习vector中一些较为常见的重要用法。 🎬个…...

Burpsuite 伪造 IP
可以用于绕过 IP 封禁检测,用来暴力、绕过配额限制。 也可以用来做 ff98sha 出的校赛题,要求用 129 个 /8 网段的 IP 地址访问同一个 domain 插件 - IPRotate 原理:利用云服务商的反向代理服务。把反向代理的域名指向到目标 ip 即可。 http…...

12.小节
1.认识 QLabel 类,能够在界面上显示字符串. 通过 setText 来设置的.参数 QString (Qt 中把 C 里的很多容器类, 进行了重新封装.历史原因) c叫法容器类,java叫法集合类 2.内存泄露,文件资源泄露 3.对象树。Qt 中通过对象树,来统一的释放界面的…...

大模型专题10 —LangGraph高级教程:构建支持网页搜索+人工干预的可追溯对话系统
在本教程中,我们将使用 LangGraph 构建一个支持聊天机器人,该机器人能够: ✅ 通过搜索网络回答常见问题 ✅ 在多次调用之间保持对话状态 ✅ 将复杂查询路由给人工进行审核 ✅ 使用自定义状态来控制其行为 ✅ 进行回溯并探索替代的对话路径 我们将从一个基础的聊天机器人开…...

2025年数智化电商产业带发展研究报告260+份汇总解读|附PDF下载
原文链接:https://tecdat.cn/?p41286 在数字技术与实体经济深度融合的当下,数智化产业带正成为经济发展的关键引擎。 从云南鲜花产业带的直播热销到深圳3C数码的智能转型,数智化正重塑产业格局。2023年数字经济规模突破53.9万亿元ÿ…...
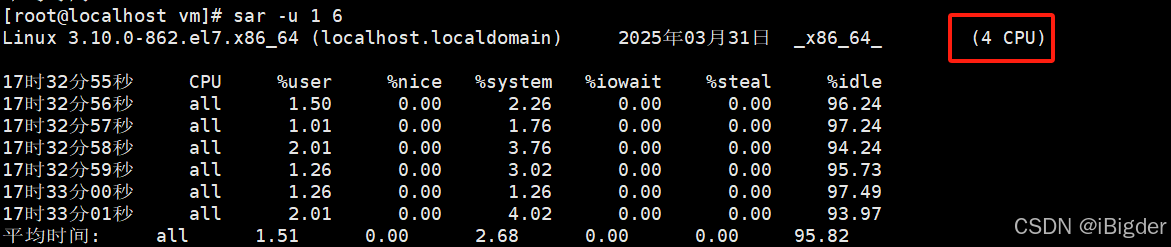
Linux中常用服务器监测命令(性能测试监控服务器实用指令)
1.查看进程 ps -ef|grep 进程名以下指令需要先安装:sysstat,安装指令: yum install sysstat2.查看CPU使用情况(间隔1s打印一个,打印6次) sar -u 1 63.#查看内存使用(间隔1s打印一个,打印6次) sar -r 1 6...

SQL:CASE WHEN使用详解
文章目录 1. 数据转换与映射2. 动态条件筛选3. 多条件分组统计4. 数据排名与分级5. 处理空值与默认值6. 动态排序 CASE WHEN 语句在 SQL 中是一个非常强大且灵活的工具,除了常规的条件判断外,还有很多巧妙的用法,以下为你详细总结:…...

linux内核`fixmap`和`memblock`有什么不同?
Linux内核中的fixmap和memblock是两个不同层次的内存管理机制,分别用于不同的场景和阶段。以下是它们的核心区别和联系: 功能与作用 memblock 物理内存管理: memblock是内核启动早期的物理内存分配器,在伙伴系统(Budd…...

基于 GEE 的区域降水数据可视化:从数据处理到等值线绘制
目录 1 引言 2 代码功能概述 3 代码详细解析 3.1 几何对象处理与地图显示 3.2 加载 CHIRPS 降水数据 3.3 筛选不同时间段的降水数据 3.4 绘制降水时间序列图 3.5 计算并可视化短期和长期降水总量 3.6 绘制降水等值线图 4 总结 5 完整代码 6 运行结果 1 引言 在气象…...
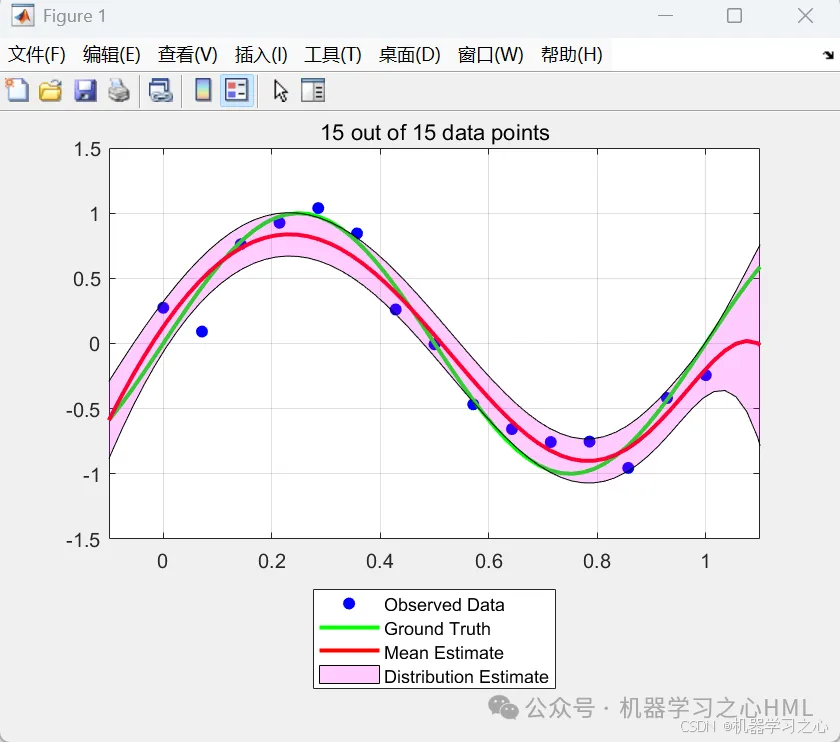
曲线拟合 | Matlab基于贝叶斯多项式的曲线拟合
效果一览 代码功能 代码功能简述 目标:实现贝叶斯多项式曲线拟合,动态展示随着数据点逐步增加,模型后验分布的更新过程。 核心步骤: 数据生成:在区间[0,1]生成带噪声的正弦曲线作为训练数据。 参数设置:…...
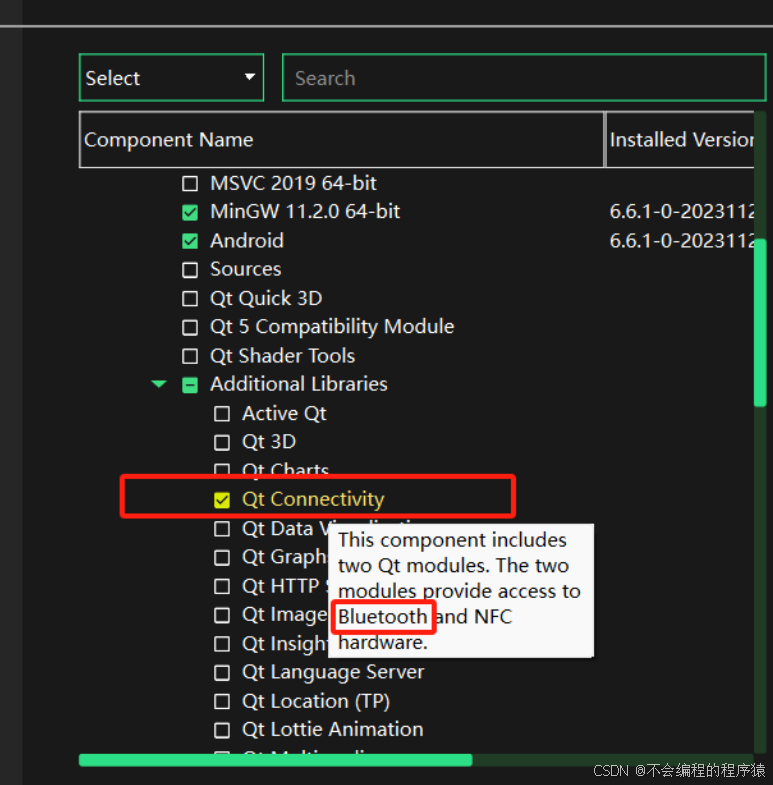
Qt6调试项目找不到Bluetooth Component蓝牙组件
错误如图所示 Failed to find required Qt component "Bluetooth" 解决方法:搜索打开Qt maintenance tool 工具 打开后,找到这个Qt Connectivity,勾选上就能解决该错误...