QwQ-32B-GGUF模型部署
由于硬件只有两张4090卡,但是领导还想要满血版32b的性能,那就只能部署GGUF版。据说QwQ-32B比Deepseek-R1-32b要更牛逼一些,所以就选择部署QwQ-32B-GGUF,根据最终的测试--针对长文本(3-5M大小)的理解,QwQ-32B-GGUF确实要比Deepseek-R1-32b-GGUF好一些。
这里说一下QwQ-32B-GGUF与原版QwQ-32B的区别:
1. 文件格式与存储优化
-
QwQ-32B 是阿里官方发布的原始模型,通常以 PyTorch 权重文件(如
.bin或.safetensors)形式存储,需依赖深度学习框架(如 Hugging Face Transformers)加载 。 -
QwQ-32B-GGUF 是 QwQ-32B 经过 GGUF 格式转换后的版本,采用二进制存储,优化了数据结构与内存映射(mmap),显著提升加载速度和内存效率,特别适合本地部署
-
优势:
-
单文件部署,无需额外依赖库;
-
支持量化(如 4-bit Q4_K_M),显存需求低至 8GB;
-
通过 llama.cpp 或 Ollama 直接运行,无需复杂配置。
-
-
2. 部署场景与硬件要求
-
QwQ-32B
-
适用场景:研究级开发、全精度推理、微调训练;
-
硬件要求:需较高显存的 GPU(如 24GB 显存的 RTX 3090/4090)或云端算力;
-
部署方式:通过 Transformers 库或 vLLM 框架启动服务 。
-
-
QwQ-32B-GGUF
-
适用场景:消费级硬件本地部署、边缘计算、低资源推理;
-
硬件要求:支持量化后单卡(如 RTX 3060)甚至 CPU 运行;
-
部署方式:通过 llama.cpp、LM Studio 或 Ollama 一键启动,适合无编程经验的用户 。
-
3. 性能与功能差异
-
推理速度 GGUF 版本因内存映射和量化技术,推理速度更快(30-40 tokens/秒),而原版在全精度下延迟较高 。
-
功能完整性
-
原版 QwQ-32B 支持完整微调和工具集成(如代码执行、Agent 能力);
-
GGUF 版本因格式限制,通常仅支持推理任务,无法直接微调。
-
-
量化灵活性 GGUF 提供多级量化(如 2-bit/4-bit/8-bit),用户可平衡速度与精度;原版需自行实现量化 。
--------------------------------------------------------------------------------------------------------------------------------
以上内容是来自deepseek的回答,下面进入主题如何基于两张4090部署QwQ-32B-GGUF。
一、下载模型
1、下载目录
GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/Qwen/QwQ-32B-GGUF.gitGIT_LFS_SKIP_SMUDGE=1 这是环境变量设置,用于指示 Git LFS 跳过自动下载大文件(即“smudge”阶段)。此时大文件会被替换为轻量级指针文件(约 1KB),而非实际内容。因为该地址下有很多量化的版本。
2、下载指定文件
nohup git lfs pull --include="qwq-32b-q8_*" > lfs_pull.log 2>&1 &下载q8_0量化版本,并设置后台下载
3、合并模型文件
下载完之后,发现是由多个文件分片组成的,需要合并为一个文件,可使用如下命令:
./llama-gguf-split --merge qwq-32b-q8_0-00001-of-00009.gguf qwq-32b-q8_0.gguf这里使用的官方推荐的llama-gguf-split命令进行合并,只需指定第一个分片即可。
二、启动模型
经过各种参数调试,最终使用如下命令,上传并理解5M左右的长文本,不会包显存溢出异常
numactl --cpunodebind=0 --membind=0 ./bin/llama-server -m /data/servers/QwQ-32B-GGUF/qwq-32b-q8_0.gguf --ctx-size 16000 --n-gpu-layers 99 --tensor-split 24,24 --batch-size 128 --no-mmap --mlock --parallel 1 --host 0.0.0.0 --port 8000 --temp 0.3 --top-k 38 --repeat-penalty 1.2 --mirostat 2 --mirostat-lr 0.1 --flash-attn 以下是该命令中关键参数的详细解析,结合 NUMA 绑定、大模型推理优化及服务器配置三方面进行说明:
一、NUMA 绑定优化
-
numactl --cpunodebind=0 --membind=0-
作用:将进程的 CPU 和内存绑定到 NUMA 节点 0,避免跨节点访问内存导致的延迟。
-
适用场景:多核服务器中,若模型推理对内存带宽敏感(如大模型),绑定到同一 NUMA 节点可提升性能 10%~30%。
-
二、模型加载与GPU卸载
-
-m /data/servers/QwQ-32B-GGUF/qwq-32b-q8_0.gguf-
作用:指定 GGUF 格式的量化模型路径。
q8_0表示 8 位整数量化,平衡精度与显存占用。
-
-
--n-gpu-layers 99-
作用:将模型的前 99 层卸载到 GPU 计算,剩余层使用 CPU 推理。数值越大,GPU 显存占用越高。
-
-
--tensor-split 24,24-
作用:在多 GPU 环境下按比例分配张量。此处表示两块 GPU 各分配 24GB 显存。
-
三、内存与性能优化
-
--ctx-size 16000-
作用:设置上下文窗口大小为 16000 tokens。适用于长文本推理,但需更多显存(每 1000 tokens 约需 1GB)。
-
-
--batch-size 128-
作用:批量处理 128 个 tokens,提升吞吐量。过大可能导致 OOM,需根据显存调整。
-
-
--no-mmap --mlock-
作用:禁用内存映射,强制锁定模型到物理内存,避免换出到磁盘。
-
四、服务器与推理参数
-
--host 0.0.0.0 --port 8000-
作用:监听所有 IP 的 8000 端口,允许外部访问服务。
-
-
--temp 0.3 --top-k 38-
作用:
-
--temp 0.3:降低生成随机性(值越小越确定,如问答任务); -
--top-k 38:仅从概率最高的 38 个候选词中采样,避免低质量输出。
-
-
-
--mirostat 2 --mirostat-lr 0.1-
作用:启用 Mirostat 2.0 算法,动态调整生成多样性,
lr为学习率,控制调整幅度。
-
-
--flash-attn-
作用:启用 Flash Attention 优化,加速注意力计算,降低显存占用 20%~40%。
-
三、调用
1、非流式调用
curl -X POST "http://192.168.1.50:8000/v1/chat/completions" \-H "Content-Type: application/json" \-d '{"messages": [{"role": "user", "content": "中国的首都是哪里?"}],"model": "/data/servers/QwQ-32B-GGUF/qwq-32b-q8_0.gguf","temperature": 0.7}' 2、流式调用
curl -X POST "http://192.168.1.50:8000/v1/chat/completions" \-H "Content-Type: application/json" \-d '{"stream": true,"messages": [{"role": "user", "content": "中国的首都是哪里?"}],"model": "/data/servers/QwQ-32B-GGUF/qwq-32b-q8_0.gguf","temperature": 0.7}'OK,大功告成!
相关文章:

QwQ-32B-GGUF模型部署
由于硬件只有两张4090卡,但是领导还想要满血版32b的性能,那就只能部署GGUF版。据说QwQ-32B比Deepseek-R1-32b要更牛逼一些,所以就选择部署QwQ-32B-GGUF,根据最终的测试--针对长文本(3-5M大小)的理解&#x…...

实操自动生成接口自动化测试用例
这期抽出来的问题是关于如何使用Eolinker自动生成接口自动化测试用例,也就是将API文档变更同步到测试用例,下面是流程的示例解析。 导入并关联API文档和自动化测试用例 首先是登陆Eolinker,可以直接在线使用。 进入流程测试用例详情页&am…...

Python数据类型-dict
Python数据类型-dict 字典是Python中一种非常强大且常用的数据类型,它使用键-值对(key-value)的形式存储数据。 1. 字典的基本特性 无序集合:字典中的元素没有顺序概念可变(mutable):可以动态添加、修改和删除元素键必须唯一且不可变&…...

0301-组件基础-react-仿低代码平台项目
文章目录 1 组件基础2 组件props3 React开发者工具结语 1 组件基础 React中一切都是组件,组件是React的基础。 组件就是一个UI片段拥有独立的逻辑和显示组件可大可小,可嵌套 组件的价值和意义: 组件嵌套来组织UI结构,和HTML一…...

18-背景渐变与阴影(CSS3)
知识目标 理解背景渐变的概念和作用掌握背景渐变样式属性的语法与使用理解阴影效果的原理和应用场景掌握阴影样式属性的语法与使用 1. 背景渐变 1.1 线性渐变 运用CSS3中的“background-image:linear-gradient(参数值);”样式可以实现线性渐变效果。 …...

分享一个Drools规则引擎微服务Docker部署
通常我们都是把Drools作为嵌入式使用,但在微服务泛滥时代,还在老套的嵌入式显然不符合微服务架构要求,本文分享一个把Drools作为微服务独立部署的方案。 本方案基于Drools引擎微服务,提供REST接口。 1、可以动态部署Drools规则2…...

PHP开发者2025生存指南
PHP,这个曾经被戏称为“世界上最好的语言”的脚本语言,依旧在网络世界占据着重要的地位。然而,技术发展日新月异,面向2025年,PHP开发者要想保持竞争力甚至实现职业生涯的飞跃,需要不断学习和提升自身技能。…...
UE5学习记录part12
第15节: treasure 154 treasure: spawn pickups from breakables treasure是items的子类 基于c的treasure生成蓝图类 155 spawning actors: spawning treasure pickups 设置treasure的碰撞 蓝图实现 156 spawning actors from c : spawning our treas…...

鸿蒙开发03样式相关介绍(一)
文章目录 前言一、样式语法1.1 样式属性1.2 枚举值 二、样式单位三、图片资源3.1 本地资源3.2 内置资源3.3 媒体资源3.4 在线资源3.5 字体图标3.6 媒体资源 前言 ArkTS以声明方式组合和扩展组件来描述应用程序的UI,同时还提供了基本的属性、事件和子组件配置方法&a…...

一周掌握Flutter开发--9. 与原生交互(上)
文章目录 9. 与原生交互核心场景9.1 调用平台功能:MethodChannel9.1.1 Flutter 端实现9.1.2 Android 端实现9.1.3 iOS 端实现9.1.4 使用场景 9.2 使用社区插件9.2.1 常用插件9.2.2 插件的优势 总结 9. 与原生交互 Flutter 提供了强大的跨平台开发能力,但…...
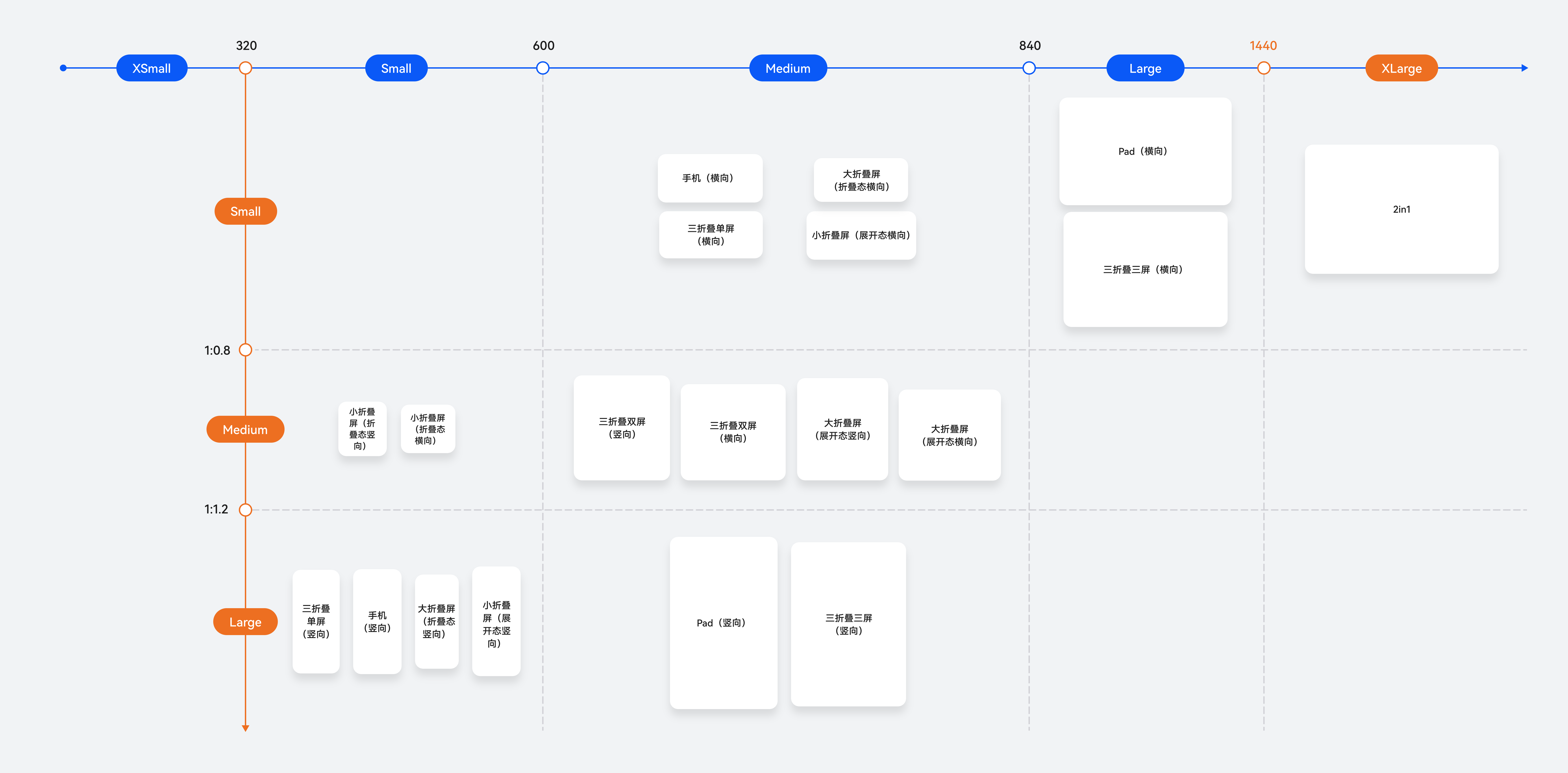
鸿蒙阔折叠Pura X外屏开发适配
首先看下鸿蒙中断点分类 内外屏开合规则 Pura X开合连续规则: 外屏切换到内屏,界面可以直接接续。内屏(锁屏或非锁屏状态)切换到外屏,默认都显示为锁屏的亮屏状态。用户解锁后:对于应用已适配外屏的情况下,应用界面可以接续到外屏。折叠外屏显示展开内屏显示折叠状态…...
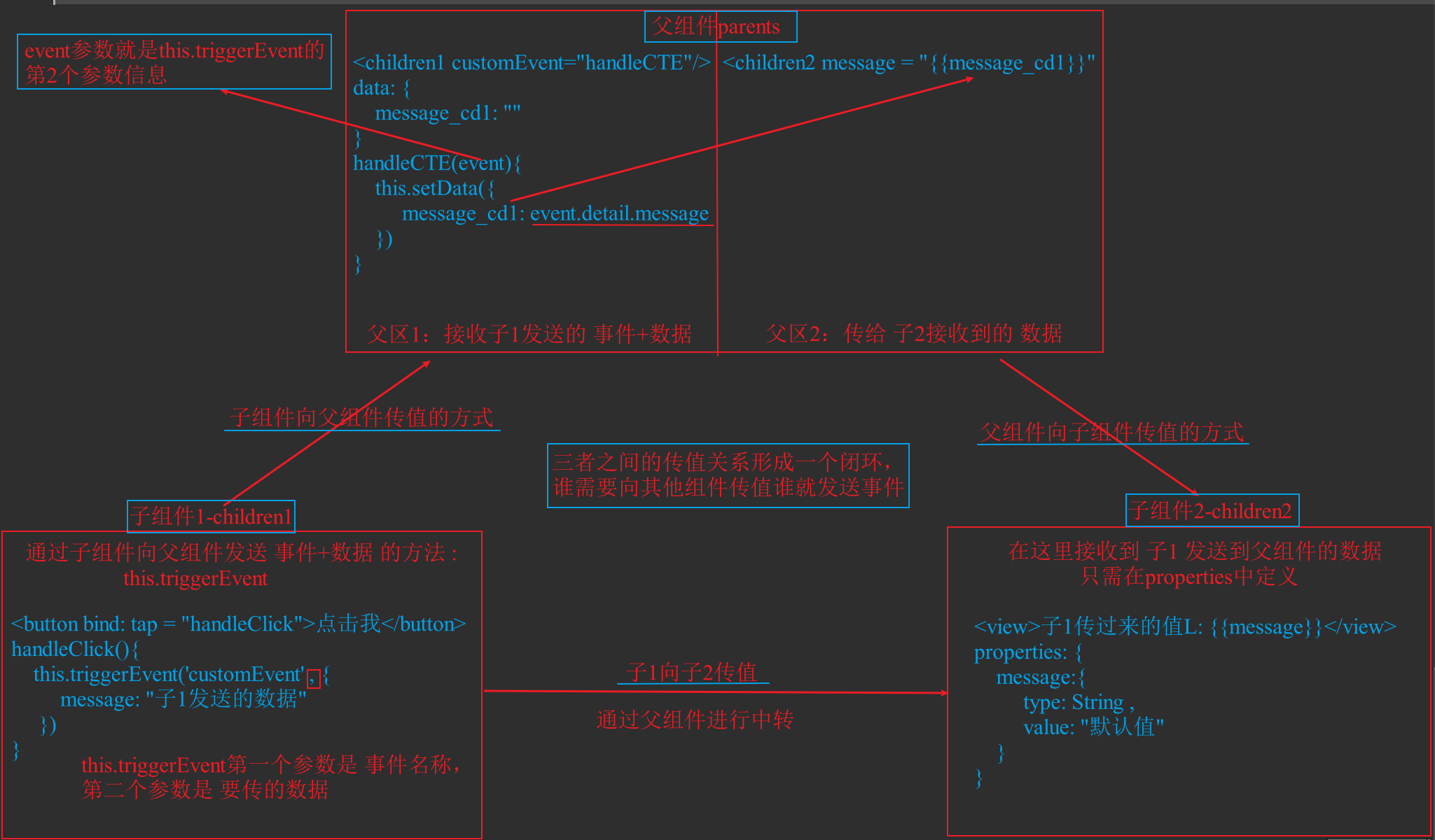
小程序中跨页面组件共享数据的实现方法与对比
小程序中跨页面/组件共享数据的实现方法与对比 在小程序开发中,实现不同页面或组件之间的数据共享是常见需求。以下是几种主要实现方式的详细总结与对比分析: 一、常用数据共享方法 全局变量(getApp())、本地缓存(w…...

Java 大视界 -- 基于 Java 的大数据分布式计算在基因测序数据分析中的性能优化(161)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

go游戏后端开发21:处理nats消息
处理 NATS 订阅的消息 在 WebSocket 的管理模块中,我们之前已经处理了一些消息。这些消息通过 NATS 订阅过来,我们需要对这些消息进行进一步的处理。一旦消息到达,我们需要执行相应的操作,并将结果发送回去,包括之前的…...

4.1-python操作wrod/pdf 文件
1.读取word文件 首先安装软件包 pip3 install python-docx from docx import Documentimport os path os.path.join(os.getcwd(),你的文档名字.docx)# 加载文档 doc Document(path)# 遍历数据 for p in doc.paragraphs:print(p.text)# 遍历文档中所有表格 for t in doc.t…...

Android 应用程序包的 adb 命令
查看所有已安装应用的包名 命令:adb shell pm list packages说明:该命令会列出设备上所有已安装应用的包名。可以通过管道符|结合grep命令来过滤特定的包名,例如adb shell pm list packages | grep com.pm,这将只显示包名中包含co…...

DeepSeek-R1 模型现已在亚马逊云科技上提供
2025年3月10日更新—DeepSeek-R1现已作为完全托管的无服务器模型在Amazon Bedrock上提供。 2025年2月5日更新—DeepSeek-R1 Distill Llama 和 Qwen模型现已在Amazon Bedrock Marketplace和Amazon SageMaker JumpStart中提供。 在最近的Amazon re:Invent大会上,亚马…...
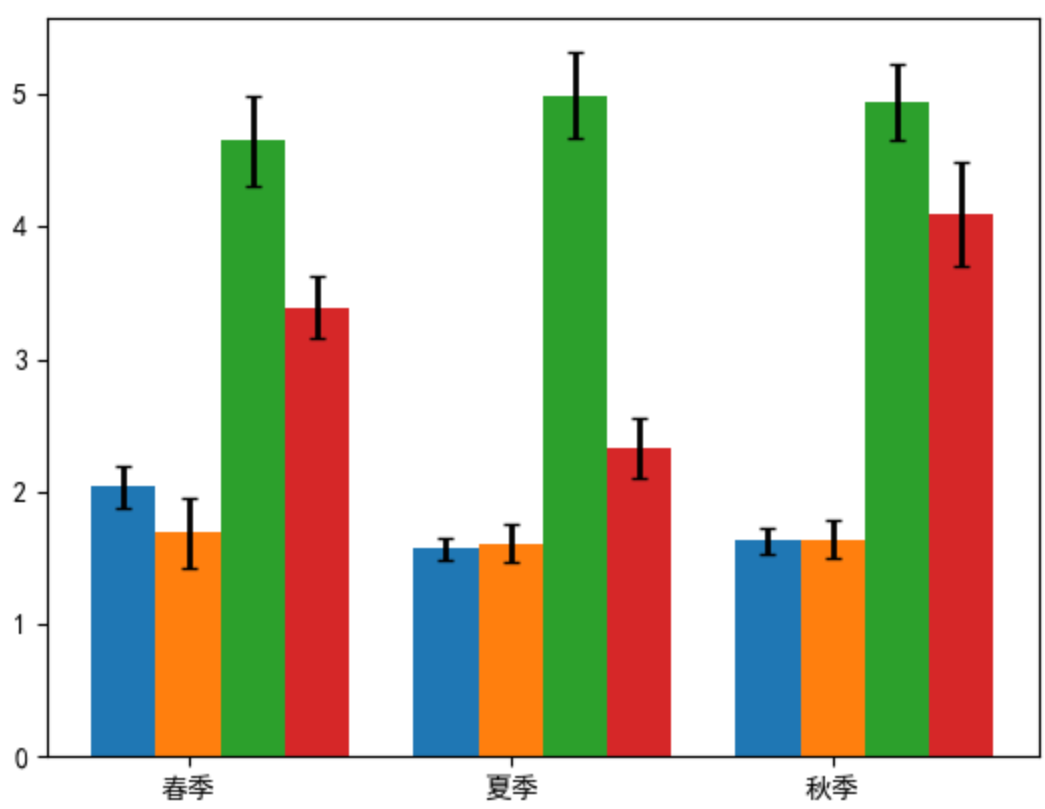
Python数据可视化-第2章-使用matplotlib绘制简单图表
环境 开发工具 VSCode库的版本 numpy1.26.4 matplotlib3.10.1 ipympl0.9.7教材 本书为《Python数据可视化》一书的配套内容,本章为第2章 使用matplotlib绘制简单图表 本文主要介绍了折线图、柱形图或堆积柱形图、条形图或堆积条形图、堆积面积图、直方图、饼图或…...
)
TDengine 快速上手:安装部署与基础 SQL 实践(二)
三、生产环境优化方案 3.1 性能调优策略 在生产环境中,TDengine 的性能优化是确保系统高效稳定运行的关键。以下是一些有效的性能调优策略。 连接池是提升数据库连接管理效率的重要工具,它允许应用程序重复使用现有的数据库连接,而不是每次…...

金融级密码管理器——密码泄露监控与自动熔断
目录 金融级密码管理器 —— 密码泄露监控与自动熔断一、模块概述与设计背景1.1 背景与挑战1.2 设计目标二、系统架构设计2.1 系统架构图(Mermaid示意图)三、关键技术与安全算法3.1 密码泄露监控3.2 自动熔断机制3.3 安全日志记录3.4 数据可视化与状态统计四、GUI与Dash仪表盘…...

mysql 主从搭建步骤
主库: 开启log-bin参数,log-bin 参数修改需要重启服务器 --You can change the server_id value dynamically by issuing a statement like this:SET GLOBAL server_id 2;--to enable binary logging using a log file name prefix of mysql-bin, and c…...

Redis 02
今天是2025/04/01 20:13 day 16 总路线请移步主页Java大纲相关文章 今天进行Redis 3,4,5 个模块的归纳 首先是Redis的相关内容概括的思维导图 3. 持久化机制(深度解析) 3.1 RDB(快照) 核心机制: 触发条件ÿ…...
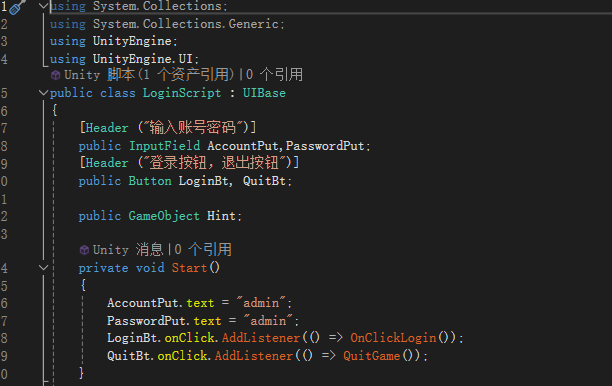
unity UI管理器
using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEngine.Events;// UI界面基类 public abstract class UIBase : MonoBehaviour {[Header("UI Settings")]public bool keepInStack true; // 是否保留在界面栈中public …...
)
PyTorch深度学习框架60天进阶学习计划-第29天:自监督学习-问题解答(一)
PyTorch深度学习框架60天进阶学习计划-第29天:自监督学习-问题解答(一) 问题: 关于自监督的目标检测模型,怎么联动yolo。 一、 如何与YOLOv7联动? 步骤概述 确定自监督模块的接入位置 在YOLOv7的主干网络…...

GIT 撤销上次推送
注意:在执行下述操作之前先备份现有工作进度,如果不慎未保存,在代码编辑器中正在修改的文件下,使用CtrlZ 撤销试试 撤销推送的方法 情况 1:您刚刚推送到远程仓库 如果您的推送操作刚刚完成,并且没有其他…...
STRUCTBERT:将语言结构融入预训练以提升深度语言理解
【摘要】最近,预训练语言模型BERT(及其经过稳健优化的版本RoBERTa)在自然语言理解(NLU)领域引起了广泛关注,并在情感分类、自然语言推理、语义文本相似度和问答等各种NLU任务中达到了最先进的准确率。受到E…...
——Webpack 6调优、模块联邦升级、Tree Shaking突破)
【万字总结】前端全方位性能优化指南(八)——Webpack 6调优、模块联邦升级、Tree Shaking突破
构建工具深度优化——从机械配置到智能工程革命 当Webpack配置项突破2000行、Node进程内存耗尽告警时,传统构建优化已触及工具链的物理极限:Babel转译耗时占比超60%、跨项目模块复用催生冗余构建、Tree Shaking误删关键代码引发线上事故……构建流程正从「工程问题」演变为「…...
)
单例模式(懒汉模式/饿汉模式)
相关概念参考:【C】C 单例模式总结(5种单例实现方法)_单例模式c实现-CSDN博客 #include<iostream>class LazySingle{ public:static LazySingle& getInstance(){static LazySingle instance;return instance;}void hello(){std::c…...

16-CSS3新增选择器
知识目标 掌握属性选择器的使用掌握关系选择器的使用掌握结构化伪类选择器的使用掌握伪元素选择器的使用 如何减少文档内class属性和id属性的定义,使文档变得更加简洁? 可以通过属性选择器、关系选择器、结构化伪类选择器、伪元素选择器。 1. 属性选择…...

C语言pthread库的线程休眠和唤醒的案例
一、代码如下 #include<stdio.h> #include<pthread.h> // 定义独占锁 pthread_mutex_t mutex; // 定义条件信号对象 pthread_cond_t condition; // 初始化函数 void init(){ int code pthread_mutex_init(&mutex, NULL); printf("共享锁初…...