MySQL篇(一):慢查询定位及索引、B树相关知识详解
MySQL篇(一):慢查询定位及索引、B树相关知识详解
- MySQL篇(一):慢查询定位及索引、B树相关知识详解
- 一、MySQL中慢查询的定位
- (一)慢查询日志的开启
- (二)慢查询日志内容分析
- (三)慢查询分析工具
- (四)慢查询的常见原因
- 二、索引
- (一)索引的定义
- (二)索引的作用
- (三)索引的创建方式
- (四)索引的类型
- (五)索引的底层数据结构
- 三、B树和B+树的区别
- (一)节点数据存储
- (二)查询过程
- (三)范围查询支持
- (四)插入和删除操作
- (五)应用场景
MySQL篇(一):慢查询定位及索引、B树相关知识详解
一、MySQL中慢查询的定位
(一)慢查询日志的开启
在MySQL中,慢查询日志是定位慢查询的重要工具。
- 通过配置文件开启
- 编辑MySQL的配置文件(通常是
my.cnf或my.ini)。找到或添加以下配置:
[mysqld] slow_query_log = 1 slow_query_log_file = /var/lib/mysql/your_mysql_server_name-slow.log long_query_time = 2- 这里
slow_query_log = 1表示开启慢查询日志;slow_query_log_file指定慢查询日志文件的路径和名称;long_query_time = 2表示查询执行时间超过2秒的语句会被记录到慢查询日志中。修改配置文件后,需要重启MySQL服务使配置生效。
- 编辑MySQL的配置文件(通常是
- 动态开启(无需重启服务)
- 可以通过SQL语句动态开启慢查询日志:
SET GLOBAL slow_query_log = 'ON'; SET GLOBAL long_query_time = 2;- 这种方式设置的参数,在MySQL服务重启后会失效。如果需要永久生效,还是建议修改配置文件。
(二)慢查询日志内容分析
慢查询日志记录了慢查询的详细信息,包括查询执行时间、查询语句、使用的数据库等。例如,慢查询日志中的一条记录可能如下:
# Time: 230915 15:30:45
# User@Host: root[root] @ localhost []
# Thread_id: 10 Schema: test QC_hit: No
# Query_time: 3.500000 Lock_time: 0.000000 Rows_sent: 10 Rows_examined: 1000
SET timestamp=1694700645;
SELECT * FROM user WHERE age > 30;
- Time:记录查询发生的时间。
- User@Host:执行查询的用户和主机信息。
- Query_time:查询执行的时间,单位是秒。
- Rows_examined:查询过程中扫描的行数,这个值越大,通常说明查询效率越低。
- 查询语句:具体的SQL查询语句。
(三)慢查询分析工具
- mysqldumpslow工具
mysqldumpslow是MySQL自带的慢查询分析工具。例如,要查看慢查询日志中执行时间最长的10条查询:
mysqldumpslow -s t -t 10 /var/lib/mysql/your_mysql_server_name-slow.log-s t表示按照查询时间排序,-t 10表示只显示前10条记录。- 还可以通过其他参数进行更复杂的分析,比如按照扫描行数排序:
mysqldumpslow -s r -t 10 /var/lib/mysql/your_mysql_server_name-slow.log-s r表示按照扫描行数排序。
- pt-query-digest工具(Percona Toolkit的一部分)
pt-query-digest功能更强大,它可以对慢查询日志进行更深入的分析,生成详细的报告。首先需要安装Percona Toolkit:- 在Ubuntu系统上:
sudo apt-get install percona-toolkit- 使用
pt-query-digest分析慢查询日志:
pt-query-digest /var/lib/mysql/your_mysql_server_name-slow.log- 它会输出查询的摘要信息,包括查询执行时间分布、查询模式、最耗时的查询等。例如,会显示类似以下的内容:
# Profile # Rank Query ID Response time Calls Rows Rows examine # ==== ================== ============== ====== ====== =========== # 1 0x1234567890abcdef 10.000000 1 10 1000 SELECT * FROM user WHERE age > 30;
(四)慢查询的常见原因
- 缺少索引
- 如果查询语句没有使用合适的索引,MySQL可能需要全表扫描。例如:
SELECT * FROM order WHERE customer_name = 'John';- 如果
customer_name字段没有索引,当order表数据量很大时,查询会非常慢。此时可以为customer_name字段创建索引:
CREATE INDEX idx_customer_name ON order (customer_name); - 复杂的查询逻辑
- 包含大量的JOIN、子查询、聚合函数等复杂逻辑的查询可能会很慢。例如:
SELECT u.name, SUM(o.amount) FROM user u JOIN order o ON u.id = o.user_id GROUP BY u.name;- 如果
user表和order表数据量都很大,且没有合适的索引,这个查询可能会很慢。可以优化JOIN条件,为关联字段创建索引,如为user.id和order.user_id创建索引。
- 锁等待
- 在事务环境下,长时间的锁等待也会导致查询变慢。例如,一个事务对某条记录加锁后,另一个查询需要等待锁释放。可以通过查看MySQL的锁状态相关视图(如
INFORMATION_SCHEMA.INNODB_LOCKS)来分析锁等待问题。
- 在事务环境下,长时间的锁等待也会导致查询变慢。例如,一个事务对某条记录加锁后,另一个查询需要等待锁释放。可以通过查看MySQL的锁状态相关视图(如
二、索引
(一)索引的定义
索引是一种数据结构,用于快速查找数据库表中的记录。它就像一本书的目录,通过索引可以快速定位到需要的数据,而不需要遍历整个表。在MySQL中,索引存储在磁盘上(InnoDB引擎也会将常用索引加载到内存中),不同的存储引擎支持的索引类型有所不同。
(二)索引的作用
- 提高查询效率
- 最主要的作用是加快查询速度。例如,在有索引的情况下,查询语句
SELECT * FROM product WHERE price > 100;可以通过索引快速定位到价格大于100的产品记录,而不是全表扫描。
- 最主要的作用是加快查询速度。例如,在有索引的情况下,查询语句
- 保证数据的唯一性
- 唯一索引可以确保表中某一列或几列的组合值是唯一的。例如,为
user表的email字段创建唯一索引:
CREATE UNIQUE INDEX idx_email ON user (email);- 这样就可以保证
email字段的值在表中是唯一的,避免重复数据。
- 唯一索引可以确保表中某一列或几列的组合值是唯一的。例如,为
- 支持JOIN操作
- 在JOIN操作中,索引可以加快表与表之间的关联速度。当两个表通过关联字段进行JOIN时,如果关联字段有索引,MySQL可以更高效地匹配记录。
(三)索引的创建方式
- 创建表时创建索引
- 在创建表的SQL语句中直接定义索引。例如:
CREATE TABLE student (id INT PRIMARY KEY,name VARCHAR(50),age INT,INDEX idx_age (age) );- 这里
PRIMARY KEY创建了主键索引,同时INDEX idx_age (age)创建了一个普通的age字段索引。
- 使用CREATE INDEX语句创建索引
- 对于已经存在的表,可以使用
CREATE INDEX语句创建索引。例如:
CREATE INDEX idx_name ON student (name);- 这会为
student表的name字段创建一个索引。
- 对于已经存在的表,可以使用
- 使用ALTER TABLE语句创建索引
- 也可以通过
ALTER TABLE语句为表添加索引。例如:
ALTER TABLE student ADD INDEX idx_age_name (age, name);- 这创建了一个组合索引,包含
age和name两个字段。
- 也可以通过
(四)索引的类型
- 普通索引(INDEX)
- 最基本的索引类型,没有任何限制。可以加速查询,但是不保证数据的唯一性。例如:
CREATE INDEX idx_city ON address (city); - 唯一索引(UNIQUE INDEX)
- 保证索引列的值是唯一的。如前面提到的为
email字段创建唯一索引。
CREATE UNIQUE INDEX idx_unique_email ON user (email); - 保证索引列的值是唯一的。如前面提到的为
- 主键索引(PRIMARY KEY)
- 是一种特殊的唯一索引,用于标识表中的唯一记录。每个表只能有一个主键索引。在创建表时定义主键:
CREATE TABLE product (id INT PRIMARY KEY,product_name VARCHAR(100) ); - 组合索引(复合索引)
- 由多个字段组成的索引。例如,为
order表的order_date和customer_id创建组合索引:
CREATE INDEX idx_order_date_customer_id ON order (order_date, customer_id);- 使用组合索引时,需要注意索引的顺序。查询条件中使用索引字段的顺序要与创建索引时的顺序一致(遵循最左匹配原则),才能有效使用索引。
- 由多个字段组成的索引。例如,为
- 全文索引(FULLTEXT INDEX)
- 主要用于全文搜索,在MySQL中,InnoDB和MyISAM存储引擎都支持全文索引。例如,为
article表的content字段创建全文索引:
CREATE FULLTEXT INDEX idx_content ON article (content);- 然后可以使用
MATCH AGAINST语句进行全文搜索:
SELECT * FROM article WHERE MATCH(content) AGAINST('keyword' IN NATURAL LANGUAGE MODE); - 主要用于全文搜索,在MySQL中,InnoDB和MyISAM存储引擎都支持全文索引。例如,为
(五)索引的底层数据结构
- 哈希表(Hash)
- 哈希索引通过哈希函数将索引值映射到哈希表中。它的优点是查询效率高,等值查询速度快。但是,哈希索引不支持范围查询,并且在数据量较大时可能会出现哈希冲突。MySQL中Memory存储引擎支持哈希索引。例如:
- 创建Memory表并使用哈希索引:
CREATE TABLE test_hash (id INT,value VARCHAR(50),INDEX USING HASH (id) ) ENGINE = MEMORY; - B树和B+树
- B树
- B树是一种自平衡的树结构,它的每个节点可以包含多个键值对和子节点。B树的特点是能够在相对较少的磁盘I/O操作下完成查询。在B树中,每个节点中的键值是有序排列的,并且子节点的键值范围也与父节点的键值相关。例如,在一个存储整数的B树中,父节点的某个键值会作为左右子节点键值范围的分界点。
- 当进行查询时,从根节点开始,根据键值与节点中键值的比较,决定进入哪个子节点,直到找到目标键值或确定目标键值不存在。
- B+树
- B+树是B树的一种变形。与B树相比,B+树有以下特点:
- 节点数据:B+树的非叶子节点只存储键值,不存储数据记录,数据记录都存储在叶子节点中。而B树的非叶子节点既存储键值,也可能存储数据记录。
- 查询方式:B+树的查询必须到叶子节点才能找到数据记录,而B树在非叶子节点找到键值时就可能找到数据记录。
- 范围查询:B+树的叶子节点之间通过指针连接,形成一个有序的链表,这使得范围查询非常高效。例如,查询
WHERE age BETWEEN 20 AND 30,在B+树上可以通过叶子节点的链表快速遍历范围内的记录。而B树在进行范围查询时相对复杂。
- 在MySQL的InnoDB存储引擎中,索引主要使用B+树结构。例如,聚簇索引(通常是主键索引)的叶子节点存储了完整的数据记录,而辅助索引(普通索引、唯一索引等)的叶子节点存储的是主键值,通过主键值再去聚簇索引中查找完整的数据记录。
- B+树是B树的一种变形。与B树相比,B+树有以下特点:
- B树
三、B树和B+树的区别
(一)节点数据存储
- B树
- B树的非叶子节点既存储键值,也可能存储数据记录。这意味着在B树中,找到某个键值时,可能在非叶子节点就已经找到对应的数据记录,不需要一直遍历到叶子节点。例如,在一个小型的B树中,根节点可能包含多个键值和少量的数据记录,当查询的键值正好在根节点时,就可以直接获取数据。
- B+树
- B+树的非叶子节点只存储键值,不存储数据记录。数据记录全部存储在叶子节点中。这样做的好处是,非叶子节点可以存储更多的键值,从而减少树的高度,降低磁盘I/O操作次数。例如,在一个大型的B+树中,非叶子节点专注于存储键值,形成更高效的索引结构,而叶子节点存储数据记录,并且通过指针连接,方便范围查询。
(二)查询过程
- B树
- 进行查询时,从根节点开始,比较键值与节点中的键值,决定进入哪个子节点。如果在非叶子节点找到目标键值,就可以直接获取数据记录,不需要继续遍历到叶子节点。这种查询方式在某些情况下可能会更快地获取数据,但也可能因为非叶子节点存储数据记录而导致节点空间利用不够高效。
- B+树
- 查询必须从根节点开始,一直遍历到叶子节点才能找到数据记录。虽然看起来查询路径可能更长,但由于B+树的非叶子节点存储更多键值,树的高度相对较低,整体的磁盘I/O次数可能更少。而且,B+树的叶子节点形成有序链表,对于范围查询和排序操作非常有利。
(三)范围查询支持
- B树
- B树对范围查询的支持相对较弱。因为B树的非叶子节点可能存储数据记录,且叶子节点之间没有直接的指针连接,在进行范围查询时,需要不断地回溯和遍历不同的子树,操作比较复杂,效率较低。
- B+树
- B+树的叶子节点通过指针连接成一个有序的链表,这使得范围查询非常高效。例如,查询
WHERE salary BETWEEN 5000 AND 10000,在B+树上,只需要找到第一个满足条件的叶子节点,然后沿着链表依次遍历,就可以获取所有满足条件的记录,大大提高了范围查询的效率。
- B+树的叶子节点通过指针连接成一个有序的链表,这使得范围查询非常高效。例如,查询
(四)插入和删除操作
- B树
- B树在插入和删除操作时,需要维护树的平衡,操作相对复杂。当插入或删除一个键值时,可能会导致节点的分裂或合并,需要调整多个节点的键值和子节点关系。
- B+树
- B+树的插入和删除操作也需要维护树的平衡,但由于其结构特点,相对B树来说,操作可能更规则一些。例如,在插入操作中,B+树主要在叶子节点进行插入,非叶子节点的调整相对有规律;在删除操作中,也可以通过叶子节点的链表关系和非叶子节点的键值调整,更有效地维护树的平衡。
(五)应用场景
- B树
- 由于B树在某些特定场景下,非叶子节点存储数据记录可能会有一定优势,例如在一些小型数据库系统或对数据存储密度有特殊要求的场景中可能会使用B树。但总体来说,B树在数据库索引中的应用不如B+树广泛。
- B+树
- B+树非常适合用于数据库索引,尤其是在像MySQL的InnoDB存储引擎中。它的结构特点使得查询效率高,特别是对于范围查询和排序操作,能够很好地满足数据库的各种查询需求。无论是普通的单表查询,还是多表JOIN操作,B+树索引都能发挥重要作用。
通过以上对MySQL慢查询定位、索引以及B树和B+树区别的详细介绍,希望能帮助读者深入理解相关知识,在实际的数据库开发和优化中更好地应用这些内容。
相关文章:
:慢查询定位及索引、B树相关知识详解)
MySQL篇(一):慢查询定位及索引、B树相关知识详解
MySQL篇(一):慢查询定位及索引、B树相关知识详解 MySQL篇(一):慢查询定位及索引、B树相关知识详解一、MySQL中慢查询的定位(一)慢查询日志的开启(二)慢查询日…...

【清华大学】DeepSeek政务应用场景与解决方案
目录 一、政务数字化转型三阶段演进二、人工智能政务应用场景四大方向 三、技术方案核心技术 四、解决方案案例1. 公文写作2. 合同协议智能审查3. 行政执法4. 就业指导 五、风险及对策六、落地大四步法七、未来发展展望AI职业替代逻辑空间智能与具身智能人机共生 一、政务数字化…...
4.2 单相机引导机器人放料-仅考虑角度变化
【案例说明】 本案例产品在托盘中,角度变化不大(<15度);抓取没有问题,只是放的穴位只能容许3度的角度偏差,因此需要测量产品的角度。 思路是:机器人抓料后、去固定拍照位拍照(找到与标准照片的角度偏差),机器人在放料的位置上多旋转这个角度偏差,把产品放进去。 …...

洛谷题单1-P5704 【深基2.例6】字母转换-python-流程图重构
题目描述 输入一个小写字母,输出其对应的大写字母。例如输入 q[回车] 时,会输出 Q。 输入格式 无 输出格式 无 输入输出样例 输入 q输出 Q方式-upper() 代码 class Solution:staticmethoddef oi_input():"""从标准输入读取数据…...

论文阅读笔记:Denoising Diffusion Implicit Models (3)
0、快速访问 论文阅读笔记:Denoising Diffusion Implicit Models (1) 论文阅读笔记:Denoising Diffusion Implicit Models (2) 论文阅读笔记:Denoising Diffusion Implicit Models (…...

Git(八)如何在同一台电脑登录两个Git
目录 一、理解 SSH 密钥机制二、具体实现步骤1.删除GIT全局配置2.生成多个 SSH 密钥3.添加公钥到 Git 账户4.配置 SSH config 文件5.测试SSH key是否生效6.下载代码 三、Git仓库级别配置四、HTTPS方式的多账号管理 引言: 在日常开发中,我们经常会遇到需要…...

FPGA学习-基于 DE2-115 板的 Verilog 分秒计数器设计与按键功能实现
一、核心功能设计 按键暂停/继续:通过KEY1控制计时状态 按键消抖处理:20ms消抖周期消除机械抖动 硬件资源分配:符合DE2-115开发板引脚规范 二、核心模块实现详解 1. 顶层模块(counter) module counter(input CL…...
如何改电脑网络ip地址:一步步指导
有时我们需要更改电脑的网络IP地址以满足特定的网络需求。本文将为您提供一份详细的步骤指南,帮助您轻松完成电脑网络IP地址的更改。以下是更改计算机IP地址的分步指南,适用于常见的操作系统: 一、更换内网ip Windows 系统(Win10…...

PyTorch 分布式训练(Distributed Data Parallel, DDP)简介
PyTorch 分布式训练(Distributed Data Parallel, DDP) 一、DDP 核心概念 torch.nn.parallel.DistributedDataParallel 1. DDP 是什么? Distributed Data Parallel (DDP) 是 PyTorch 提供的分布式训练接口,DistributedDataPara…...

prism WPF 消息的订阅或发布
prism WPF 消息的订阅或发布 EventMessage using Prism.Events; using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;namespace Cjh.PrismWpf {/// <summary>/// 事件消息/// </summary>publ…...

【Unity】记录TMPro使用过程踩的一些坑
1、打包到webgl无法输入中文,编辑器模式可以,但是webgl不行,试过网上的脚本,还是不行 解决方法:暂时没找到 2、针对字体asset是中文时,overflow的效果模式处理奇怪,它会出现除了overflow模式以…...

计算机视觉初步(环境搭建)
1.anaconda 建议安装在D盘,官网正常安装即可,一般可以安装windows版本 安装成功后,可以在电脑应用里找到: 2.创建虚拟环境 打开anaconda prompt, 可以用conda env list 查看现有的环境,一般打开默认bas…...

【go】异常处理panic和recover
panic 和 recover 当然能触发程序宕机退出的,也可以是我们自己,比如经过检查判断,当前环境无法达到我们程序进行的预期条件时(比如一个服务指定监听端口被其他程序占用),可以手动触发 panic,让…...

Sentinel[超详细讲解]-3
主要讲解🚀 - 基于QPS/并发数的流量控制 1、流控规则 流量控制(Flow Control)用于限制某个资源的访问频率,防止系统被瞬时的流量高峰冲垮。流量控制规则可以针对不同的资源进行配置,例如接口、方法、类等。 流量规则的…...

【云原生】Kubernetes CEL 速查表
以下是一份 Kubernetes CEL 速查表(Cheat Sheet),涵盖了常见的语法、宏、标准函数和一些在 Kubernetes 中常见的使用示例。可在编写或调试 CEL 表达式时用作快速参考。 1. 基础概念 概念说明语言特点无副作用、逐渐类型化(Gradua…...
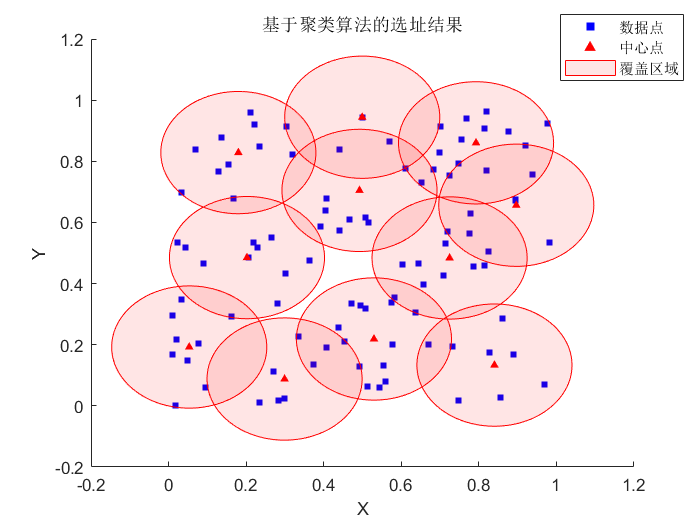
基于聚类与引力斥力优化的选址算法
在众多实际场景中,诸如消防设施选址、基站布局规划以及充电桩站点部署等,都面临着如何利用最少的资源,实现对所有目标对象全面覆盖的难题。为有效解决这类问题,本文提出一种全新的组合算法模型 —— 基于聚类与引力斥力优化的选址…...

深入剖析雪花算法:分布式ID生成的核心方案
深入剖析雪花算法:分布式ID生成的核心方案 深入剖析雪花算法:分布式ID生成的核心方案一、雪花算法(Snowflake)概述二、雪花算法核心组成1. 64位二进制结构2. 时间戳起始点 三、工作原理与代码实现1. 生成逻辑2. Java代码示例3. 代…...

RK3568 pinctrl内容讲解
文章目录 一、pinctrl的概念`pinctrl` 的作用设备树中的 `pinctrl` 节点典型的 `pinctrl` 节点结构例子`pinctrl` 的重要性总结二、RK3568的pinctrl讲解1. `pinctrl` 节点2. `gpio0` 至 `gpio4` 子节点每个 `gpioX` 子节点的结构和作用3. `gpio1` 到 `gpio4` 子节点总结1. `aco…...

主流Web3公链的核心区别对比
以下是当前主流Web3公链的核心区别对比表,涵盖技术架构、性能、生态等关键维度: 特性以太坊 (Ethereum)SolanaBNB ChainPolygonAvalanche共识机制PoS(信标链分片)PoH(历史证明) PoSPoSA(权益证…...

Mac 电脑移动硬盘无法识别的解决方法
在使用 Mac 电脑的过程中,不少用户都遇到过移动硬盘没有正常推出,导致无法识别的问题。这不仅影响了数据的传输,还可能让人担心硬盘内数据的安全。今天,我们就来详细探讨一下针对这一问题的解决方法。 当发现移动硬盘无法识别时&…...

LeetCode Hot100 刷题笔记(4)—— 二叉树、图论
目录 一、二叉树 1. 二叉树的深度遍历(DFS:前序、中序、后序遍历) 2. 二叉树的最大深度 3. 翻转二叉树 4. 对称二叉树 5. 二叉树的直径 6. 二叉树的层序遍历 7. 将有序数组转换为二叉搜索树 8. 验证二叉搜索树 9. 二叉搜索树中第 K 小的元素 …...

安全框架SpringSecurity入门
安全框架 Spring Security 入门 Spring Security 是一个强大的安全框架,广泛用于保护基于 Spring 的应用程序。它提供了全面的安全服务,包括认证、授权、攻击防护等。下面我将为你详细介绍 Spring Security 的主要知识点,帮助你更好地理解和…...

c# 虚函数、接口、抽象区别和应用场景
文章目录 定义和语法实现要求继承和使用场景总结访问修饰符设计目的性能扩展性在 C# 里,虚函数、接口和抽象函数都能助力实现多态性,不过它们的定义、使用场景和特点存在差异,下面为你详细剖析: 定义和语法 虚函数:虚函数在基类里定义,使用 virtual 关键字,且有默认的实…...

MySQL Online DDL 技术深度解析
在MySQL数据库管理体系中,数据定义语言(DDL)和数据操作语言(DML)构成了数据库交互的基础。 DDL用于定义数据库对象,如数据库、表、列、索引等,相关命令包括CREATE、ALTER、DROP;DML则…...

【计算机视觉】YOLO语义分割
一、语义分割简介 1. 定义 语义分割(Semantic Segmentation)是计算机视觉中的一项任务,其目标是对图像中的每一个像素赋予一个类别标签。与目标检测只给出目标的边界框不同,语义分割能够在像素级别上区分不同类别,从…...

【SpringBoot + MyBatis + MySQL + Thymeleaf 的使用】
目录: 一:创建项目二:修改目录三:添加配置四:创建数据表五:创建实体类六:创建数据接口七:编写xml文件八:单元测试九:编写服务层十:编写控制层十一…...

git 按行切割 csv文件
# 进入Git Bash环境 # 基础用法(不保留标题行): split -l 1000 input.csv output_part_# 增强版(保留标题行): header$(head -n1 input.csv) # 提取标题 tail -n 2 input.csv | split -l 5000000 - --filt…...
在ensp进行OSPF+RIP+静态网络架构配置
一、实验目的 1.Ospf与RIP的双向引入路由消息 2.Ospf引入静态路由信息 二、实验要求 需求: 路由器可以互相ping通 实验设备: 路由器router7台 使用ensp搭建实验坏境,结构如图所示 三、实验内容 1.配置R1、R2、R3路由器使用Ospf动态路由…...

Qt实现HTTP GET/POST/PUT/DELETE请求
引言 在现代应用程序开发中,HTTP请求是与服务器交互的核心方式。Qt作为跨平台的C框架,提供了强大的网络模块(QNetworkAccessManager),支持GET、POST、PUT、DELETE等HTTP方法。本文将手把手教你如何用Qt实现这些请求&a…...

从零开始开发HarmonyOS应用并上架
开发环境搭建(1-2天) 硬件准备 操作系统:Windows 10 64位 或 macOS 10.13 内存:8GB以上(推荐16GB) 硬盘:至少10GB可用空间 软件安装 下载 DevEco Studio 3.1(官网:…...