LlamaIndex实现RAG增强:融合检索(Fusion Retrieval)与混合检索(Hybrid Search)
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀

RAG Hybrid Search与Fusion Retrieval的技术对比及工作流程图:
Hybrid Search (混合搜索)
- 定义:结合关键词检索和向量检索的搜索方法
- 特点:同时利用传统BM25算法(精确匹配)和神经网络嵌入(语义匹配)
- 示例:
Elasticsearch + 向量数据库的联合查询
Fusion Retrieval (融合检索)
- 定义:对多种检索结果进行加权融合的算法
- 特点:通过线性加权/学习排序(Rank Fusion)整合不同检索系统的结果
- 示例:
Reciprocal Rank Fusion (RRF)算法
核心区别对比
| 维度 | RAG Hybrid Search | Fusion Retrieval |
|---|---|---|
| 目标 | 通过混合检索策略提升召回率 | 通过多路结果融合提升准确率 |
| 工作阶段 | 检索阶段(预处理层) | 后处理阶段(结果层) |
| 技术实现 | 同时执行关键词+向量检索,合并结果 | 多路独立检索后加权/重排序 |
| 计算开销 | 较高(并行执行两种检索) | 中等(依赖独立检索系统的输出) |
| 典型应用 | 开放域问答、知识密集型任务 | 多模态检索、跨语言检索 |
工作流程图
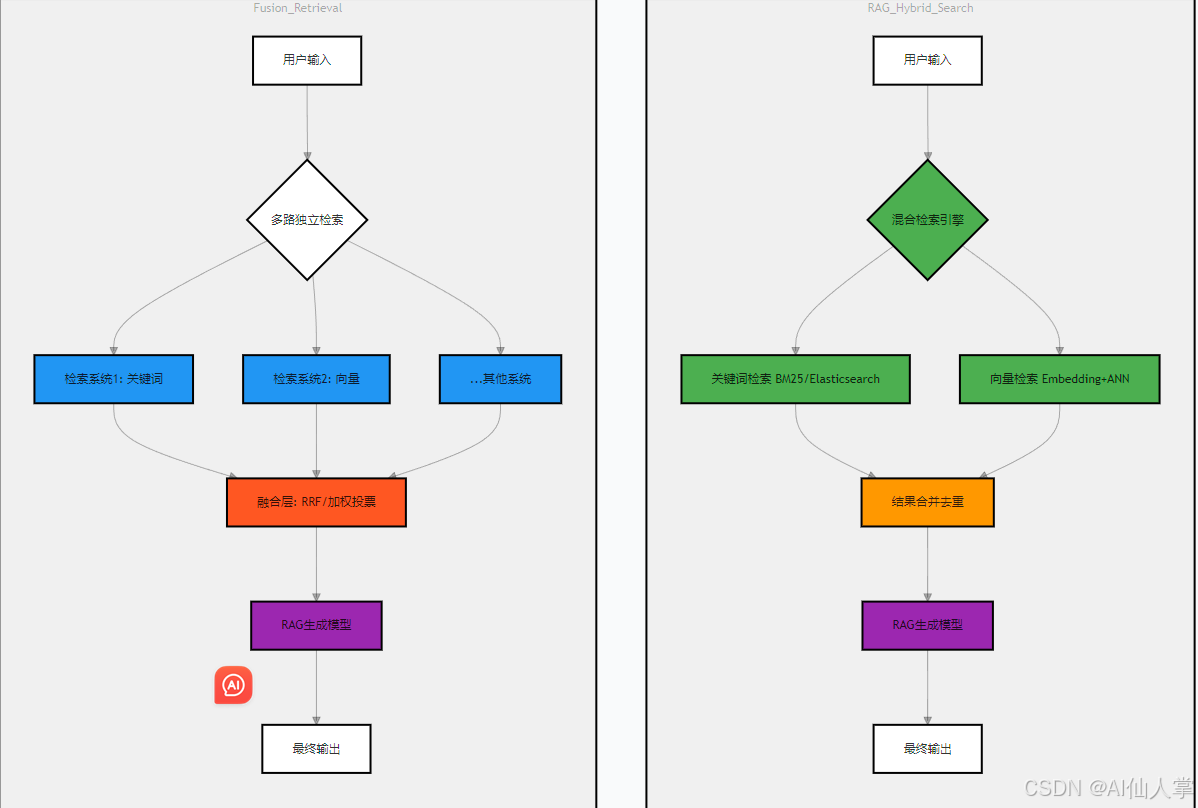
关键差异解析
-
架构层级差异
- Hybrid Search在检索阶段完成多策略整合(如BM25+向量),降低生成模型噪声
- Fusion Retrieval在检索完成后进行结果融合(如RRF算法),强调异构系统互补性
-
性能权衡
- Hybrid需维护双索引,但减少冗余计算(如ColBERT的混合压缩)
- Fusion支持异步检索(可并行化),但融合算法复杂度高(如RECIPROAL RANK FUSION)
-
适用场景
- Hybrid适合单一数据源下的多角度语义覆盖
- Fusion适合跨系统/跨模态检索(如文本+图像联合检索)
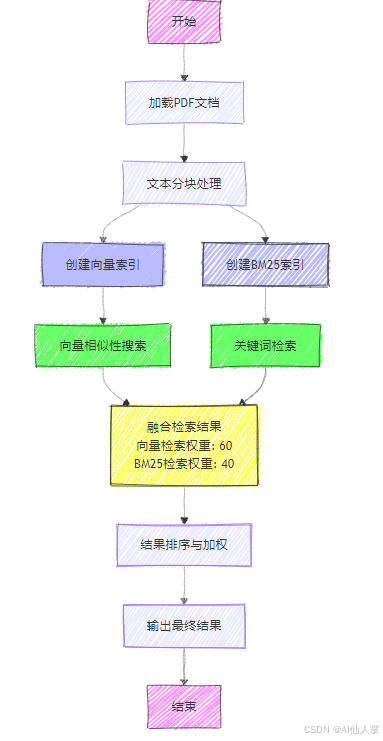
基于LlamaIndex实现RAG融合检索Fusion Retrieval
本代码实现了一个融合检索系统,将基于向量的相似性搜索与基于关键词的BM25检索相结合。该方法旨在综合两种技术的优势,提升文档检索的整体质量和相关性。
动机
传统检索方法通常依赖语义理解(基于向量)或关键词匹配(BM25)。每种方法都有其优缺点。融合检索通过结合这两种方法,构建更强大、更精确的检索系统,能够有效处理更广泛的查询场景。
核心组件
- PDF文档处理与文本分块
- 使用FAISS和OpenAI嵌入创建向量存储
- 构建基于关键词的BM25索引
- 融合BM25和向量搜索结果以优化检索效果
方法细节
文档预处理
- 加载PDF文档并使用SentenceSplitter进行分块
- 通过替换
\t为空格和清理换行符来净化文本块(针对特定格式问题)
向量存储创建
- 使用OpenAI嵌入生成文本块的向量表示
- 基于这些嵌入创建FAISS向量存储,实现高效的相似性搜索
BM25索引创建
- 使用与向量存储相同的文本块创建BM25索引
- 实现与基于向量方法并行的关键词检索
查询混合检索
在创建两种索引后,查询混合检索将它们结合起来,实现混合检索


方法优势
- 提升检索质量:结合语义搜索和关键词匹配,系统能同时捕捉概念相似性和精确关键词匹配
- 灵活调整:通过
retriever_weights参数可调节向量搜索与关键词搜索的权重平衡 - 鲁棒性强:组合方法能有效处理更广泛的查询场景,弥补单一方法的不足
- 高度可定制:系统可轻松适配不同的向量存储或关键词检索方法
结论
融合检索代表了文档搜索的强大方法,结合了语义理解和关键词匹配的优势。通过同时利用基于向量和BM25的检索方法,它为信息检索任务提供了更全面、灵活的解决方案。这种方法在需要兼顾概念相似性和关键词相关性的领域具有广泛应用潜力,如学术研究、法律文档搜索或通用搜索引擎。
导入库
import os
import sys
from dotenv import load_dotenv
from typing import List
from llama_index.core import Settings
from llama_index.core.readers import SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.schema import BaseNode, TransformComponent
from llama_index.vector_stores.faiss import FaissVectorStore
from llama_index.core import VectorStoreIndex
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.legacy.retrievers.bm25_retriever import BM25Retriever
from llama_index.core.retrievers import QueryFusionRetriever
import faisssys.path.append(os.path.abspath(os.path.join(os.getcwd(), '..'))) # 将父目录添加到路径中(适用于笔记本环境)
# 从.env文件加载环境变量
load_dotenv()# 设置OpenAI API密钥环境变量
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')# Llamaindex全局设置(LLM和嵌入模型)
EMBED_DIMENSION=512
Settings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=EMBED_DIMENSION)
读取文档
path = "../data/"
reader = SimpleDirectoryReader(input_dir=path, required_exts=['.pdf'])
documents = reader.load_data()
print(documents[0])
创建向量存储
# 创建FAISS向量存储用于保存嵌入
fais_index = faiss.IndexFlatL2(EMBED_DIMENSION)
vector_store = FaissVectorStore(faiss_index=fais_index)
文本清理转换
class TextCleaner(TransformComponent):"""在数据摄取管道中使用的转换组件用于清理文本中的杂乱内容"""def __call__(self, nodes, **kwargs) -> List[BaseNode]:for node in nodes:node.text = node.text.replace('\t', ' ') # 将制表符替换为空格node.text = node.text.replace(' \n', ' ') # 将段落分隔符替换为空格return nodes
数据摄取管道
# 管道实例化,包含:
# 节点解析器、自定义转换器、向量存储和文档
pipeline = IngestionPipeline(transformations=[SentenceSplitter(),TextCleaner()],vector_store=vector_store,documents=documents
)# 运行管道获取节点
nodes = pipeline.run()
检索器
BM25检索器
bm25_retriever = BM25Retriever.from_defaults(nodes=nodes,similarity_top_k=2,
)
向量检索器
index = VectorStoreIndex(nodes)
vector_retriever = index.as_retriever(similarity_top_k=2)
融合两种检索器
retriever = QueryFusionRetriever(retrievers=[vector_retriever,bm25_retriever],retriever_weights=[0.6, # 向量检索器权重0.4 # BM25检索器权重],num_queries=1, mode='dist_based_score',use_async=False
)
关于参数:
num_queries:查询混合检索器不仅能组合检索器,还能从给定查询生成多个问题。此参数控制传递给检索器的查询总数。设置为1时禁用查询生成,最终检索器仅使用初始查询。mode:此参数有4种选项:- reciprocal_rerank:应用互逆排序(由于缺乏标准化,不适合此类应用,因为不同检索器返回的分数范围不同)
- relative_score:基于所有节点中的最小和最大分数应用MinMax缩放,将分数缩放到0到1之间,最后根据
retriever_weights进行加权min\_score = min(scores) \\ max\_score = max(scores) - dist_based_score:与
relative_score的唯一区别在于MinMax缩放基于分数的均值和标准差,缩放和加权方式相同min\_score = mean\_score - 3 * std\_dev \\ max\_score = mean\_score + 3 * std\_dev - simple:此方法简单取每个块的最大分数
使用案例示例
# 查询
query = "气候变化对环境有哪些影响?"# 执行混合检索
response = retriever.retrieve(query)
打印最终检索节点及分数
for node in response:print(f"节点分数:{node.score:.2}")print(f"节点内容:{node.text}")print("-"*100)
基于LlamaIndex实现RAG混合检索
混合检索(Hybrid Search)结合了 关键词检索(如BM25) 和 向量相似度检索(如稠密向量),通过两者的互补性提升召回准确性。
- BM25 处理精确关键词匹配,适合直接相关查询;
- 向量检索 捕捉语义相似性,处理模糊或隐含的语义需求。

2. LlamaIndex实现混合检索的步骤
步骤1:安装依赖与数据准备
pip install llama-index
pip install llama-index[milvus] # 若使用Milvus作为向量数据库
步骤2:构建索引
- BM25索引(关键词检索):基于文本内容的关键词匹配。
- 向量索引(稠密向量检索):将文本编码为向量并存储到数据库(如Weaviate、Milvus)。
from llama_index import GPTSimpleVectorIndex, SimpleDirectoryReader
from llama_index.retrievers import VectorIndexRetriever, BM25Retriever# 加载数据
documents = SimpleDirectoryReader('data/').load_data()# 创建BM25索引(默认)
bm25_index = GPTSimpleVectorIndex(documents) # 实际BM25索引需配置参数# 创建向量索引(需配置向量数据库)
vector_index = GPTSimpleVectorIndex(documents,service_context=service_context # 需配置Embedding模型
)
步骤3:配置混合检索器
LlamaIndex通过 HybridRetriever 或自定义逻辑组合两种检索结果:
from llama_index.retrievers import HybridRetriever# 初始化两个单独的检索器
vector_retriever = VectorIndexRetriever(vector_index)
bm25_retriever = BM25Retriever(bm25_index)# 创建混合检索器(可调整alpha参数权重)
hybrid_retriever = HybridRetriever(vector_retriever=vector_retriever,bm25_retriever=bm25_retriever,alpha=0.5 # 权重参数,调整向量与BM25的贡献比例
)
步骤4:执行混合检索
query = "在发现高血压显著降低的研究中,使用了哪些测量血压的方法?"
results = hybrid_retriever.retrieve(query)
3. 关键参数与调优
**(1) Alpha值调优
- 作用:控制向量检索和BM25检索的权重比例。
- 推荐实践:
- 通过实验确定最优值(如
alpha=0.2或0.6)。 - 使用LlamaIndex的评估模块(如MRR、命中率)进行量化优化。
- 通过实验确定最优值(如
**(2) 索引配置
- BM25优化:调整分块策略(如语义分块提升召回质量)。
- 向量索引优化:
- 选择合适的Embedding模型(如
text-embedding-ada-002); - 确保向量数据库支持混合查询(如Milvus 2.4+版本)。
- 选择合适的Embedding模型(如
4. 实现注意事项
- 数据库兼容性:
- 混合检索需要底层数据库支持联合查询(如Milvus 2.4+)。
- 性能权衡:
- 混合检索可能增加计算开销,需平衡召回率与效率。
- 重排器(Reranker):
- 可添加重排器(如
RerankRetriever)对混合结果进一步排序,提升相关性。
- 可添加重排器(如
5. 参考案例与资源
- BM25+向量的两路召回实现:
参考中LlamaIndex的HybridFusionRetrieverPack或自定义检索器配置。 - Alpha调优实验:
IBM研究指出,混合检索在单/多文档场景中均表现更优,尤其当alpha=0.2/0.6时。
相关文章:
LlamaIndex实现RAG增强:融合检索(Fusion Retrieval)与混合检索(Hybrid Search)
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...
)
递归(实践版)
这篇博客我不会写太多细节,我只做一件事,那就是教你如何写好一个递归. 二叉树的后序遍历 public void dfs(TreeNode root){if(rootnull)return;dfs(root.left);dfs(root.right);System.out.println(root.val); } 归并排序 public void merge(int[] nums,int left,int right)…...

JavaScript instanceof 运算符全解析
JavaScript instanceof 运算符全解析 核心语义: 判断一个对象(object)是否属于某个构造函数(constructor)或类的实例,基于原型链(prototype chain)实现类型检测。 一、JavaScript 中的基础用法 1. 语法结构 object instanceof constructor 返回值:布尔值(true/fal…...

蓝桥杯冲刺:一维前缀和
系列文章目录 蓝桥杯系列:一维前缀和 文章目录 系列文章目录前言一、暴力的写法:二、一维前缀和的模板: 具体实现: 三、具体例题:求和 1.题目参考:2.以下是具体代码实现: 总结 前言 上次我介绍…...
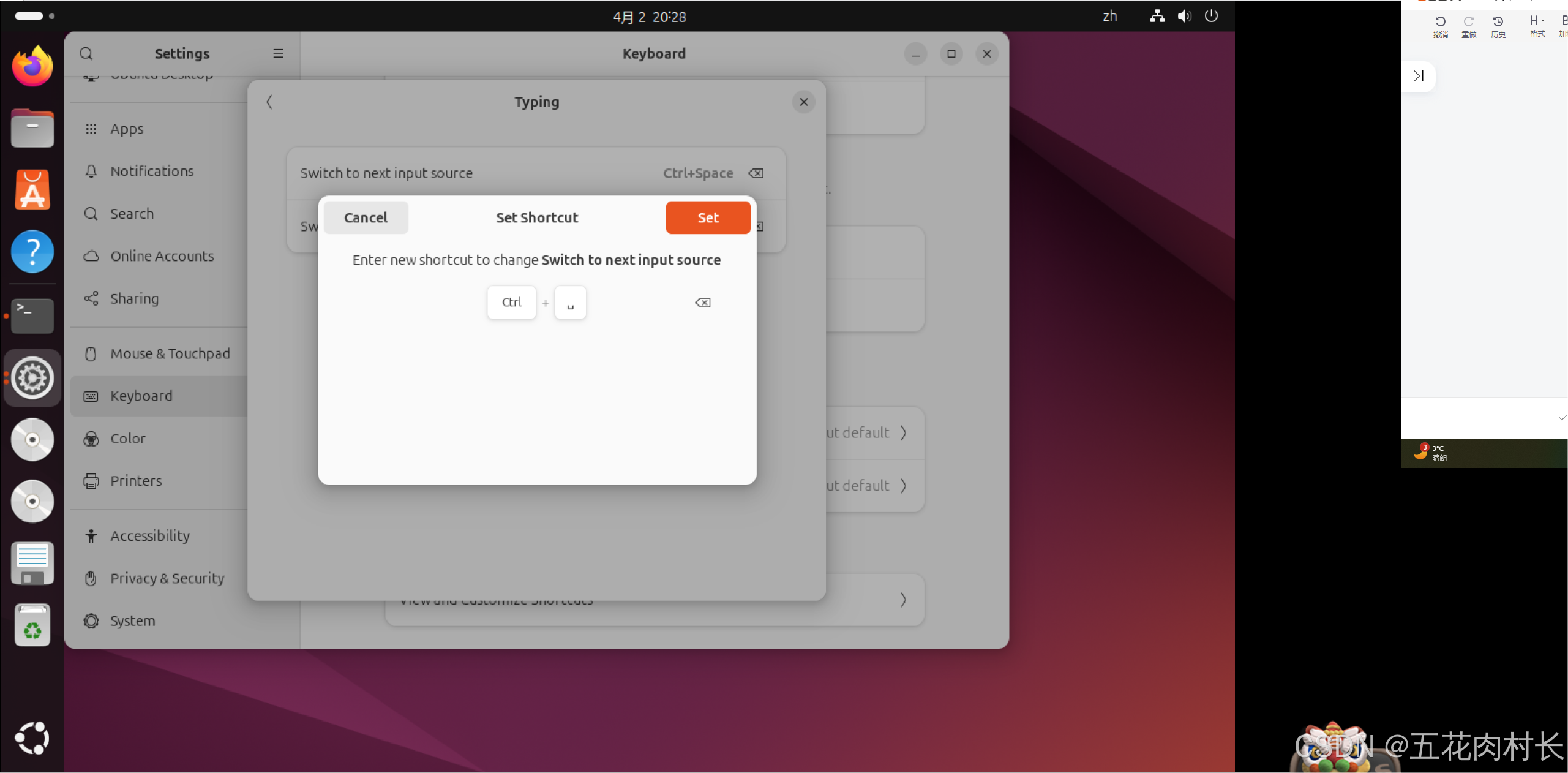
Ubuntu24.04-中文输入法的切换
Ubuntu24.04在安装后自带中文全拼输入法。。 根据官方的说明,需使用 shift super 空格 切换输入法,但在之前使用windows或者ubuntu的早些版本,多使用 Ctrl 空格 的方式切换输入法,本文就介绍如何进行输入法快捷键切换的配置&a…...

技术回顾day3
1.获取文件信息、获取视频信息 走的都是同一个方法:baseController里面的getFile。 在getFile方法里面进行判断文件的类型,判断是不是m3u8类型或者ts类型做一些额外的处理。 获取信息底层就是读取文件,然后写入response的OutputStream ou…...

埃文科技企业AI大模型一体机——昇腾体系+DeepSeek+RAG一站式解决方案
面对企业级市场海量数据资产与复杂业务场景深度耦合的刚需,埃文科技重磅推出基于华为昇腾算力DeepSeek大模型的企业一体机产品,提供DeepSeek多版本大模型一体机选择,为企业提供本地昇腾算力DeepSeek大模型RAG知识库的一体化解决方案ÿ…...

SAP-ABAP:ABAP `LEAVE LIST-PROCESSING` 深度解析
ABAP LEAVE LIST-PROCESSING 深度解析 核心机制 模式切换(Dialog → List) 中断屏幕流 强制终止当前Dialog程序的PBO/PAI处理,脱离屏幕序列控制(如事务码SE38执行的程序)。触发报表事件 激活类报表程序的事件链:INITIALIZATION → AT SELECTION-SCREEN → START-OF-SEL…...
JavaWeb开发基础知识-Servlet终极入门指南(曼波萌新版)
(✪▽✪)曼波~~~~!欢迎来到Servlet新手村!准备好开启Web开发的奇妙冒险了吗?让曼波用最有趣的方式带你飞~ 🚀 🌈 第①章 什么是Servlet? // 本质就是一个Java类! public class HelloServlet e…...

游戏引擎学习第198天
回顾并为今天的内容设定 今天我们有一些代码需要处理。昨天我们进行了一些调试界面的整合工作,之前我们做了一些临时的、粗糙的操作,将一些东西读进来并放到调试界面中。今天,我们并不打算进行大规模的工作,更多的是对之前的代码…...

Walrus 基金会启动 RFP 计划,推动生态发展
Walrus 基金会正式推出 Walrus RFP 提案申请计划,为推动和支持 Walrus 生态的项目提供资金支持。该计划旨在助力构建符合协议使命的解决方案,解锁去中心化和可编程存储的潜力。 无论项目是开发新工具、探索集成,还是提出创新用例,…...

智能配电箱:重塑未来电力管理的核心枢纽
哇塞!智能配电箱可是未来电力管理的超级核心枢纽呀,正以超燃的态势引领着电力行业迈向智能化变革的新征程呢!它在众多方面所展现出的独特优势和那广阔无垠的应用前景,简直太令人激动啦!下面就来瞧瞧智能配电箱在重塑未…...

透过 /proc 看见内核:Linux 虚拟文件系统与 systemd 初始化初探
当我们在终端中输入 ps、top、cat /proc/cpuinfo 等命令时,是否思考过这些信息来自哪里?为什么无需启动任何守护进程,就能实时读取系统负载、内存占用,甚至内核版本?这一切的答案,都藏在 Linux 系统中的一个…...

深入理解DRAM刷新机制:异步刷新为何无需扣除刷新时间?
引言 在计算机组成原理和存储器系统的学习中,DRAM(动态随机存取存储器)的刷新机制是一个关键问题。许多同学在学习时会遇到一个疑问: “为什么异步刷新的刷新信号周期可以直接用 总时间/行数 计算(如 2ms/3262.5μs&a…...
用DrissionPage升级维基百科爬虫:更简洁高效的数据抓取方案
一、原方案痛点分析 原代码使用urllibBeautifulSoup组合存在以下问题: 动态内容缺失:无法获取JavaScript渲染后的页面内容 反爬能力弱:基础请求头易被识别为爬虫 代码冗余:需要单独处理SSL证书验证 扩展性差:难以应…...

C++STL——容器-vector(含部分模拟实现,即地层实现原理)(含迭代器失效问题)
目录 容器——vector 1.构造 模拟实现 2.迭代器 模拟实现: 编辑 3.容量 模拟实现: 4.元素的访问 模拟实现 5.元素的增删查改 迭代器失效问题: 思考问题 【注】:这里的模拟实现所写的参数以及返回值,都是…...

严重BUG修复及部分体验问题优化
随着Deepseek APIPython 测试用例一键生成与导出 V1.0.6的试用不断深入,会出现程序异常崩溃的问题。经群友定位,紧急修复了bug,并适当优化部分体验性问题。针对生成的测试用例xlsx文档,可以再次选中该xlsx给大模型进行推理生成新的…...

黑马 C++ 学习笔记
课程链接:黑马 C 文章目录 C 基础语法指针空指针和野指针 const 修饰指针 C 核心编程程序的内存分区模型程序运行前程序运行后new 操作符 引用引用的基本使用引用的注意事项引用作函数参数引用作函数返回值引用的本质常量引用 函数的提高函数默认参数函数默认参数函…...
Elasticsearch 证书问题解决
报错信息 javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested targetat org.elasticsearch.client.RestClient. extractAndWrapCause(R…...

I²C总线高级特性与故障处理分析
IC总线高级特性与故障处理深度分析 目录 1. IC基础回顾 1.1 IC通信基本原理1.2 IC总线时序与协议1.3 寻址方式与读写操作 2. IC高级特性 2.1 多主机模式2.2 时钟同步与伸展2.3 高速模式与Fast-mode Plus2.4 10位寻址扩展 3. IC总线故障与锁死 3.1 断电锁死原理3.2 总线挂起与…...

山东大学《多核平台下的并行计算》实验笔记
每年的题目都不一样,学弟学妹参考参考就行。 一、搭建linux环境 主播用的ssh+虚拟机,目前用着最顺手的 二、安装并行编程软件 MPI(Message Passing Interface),由其字面意思也可些许看出,是一个信息传递接口。可以理解为是一种独立于语言的信息传递标准。而OpenMPI和MP…...
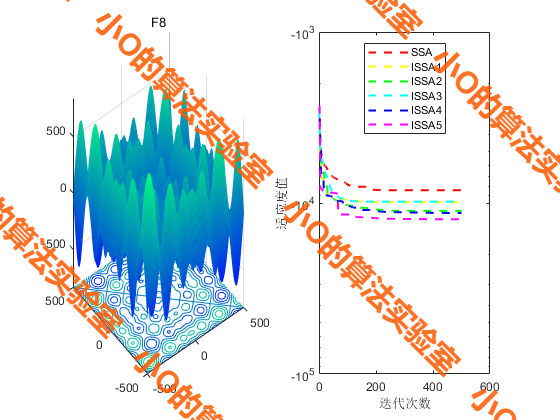
2023年CIE SCI1区TOP:序列融合麻雀搜索算法ISSA,深度解析+性能实测
目录 1.摘要2.麻雀搜索算法SSA原理3.改进策略3.结果展示4.参考文献5.代码获取 1.摘要 麻雀搜索算法(SSA)是一种基于麻雀觅食和防捕行为的群体智能算法。然而,基本SSA在迭代过程中,种群多样性逐渐降低,容易陷入局部最优…...

elasticsearch 如果按照日期进行筛选
如果你需要按照日期进行筛选,你可以使用 Elasticsearch 的范围查询来实现。以下是一个示例代码,演示如何在 Java 中进行日期范围查询: import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticse…...

SpringBoot条件装配注解
SpringBoot条件装配注解 Spring Boot 提供了一系列条件装配注解,用于控制 Bean 的创建和装配过程。以下是一些常用的条件装配注解及其详细介绍: ConditionalOnClass 作用:当类路径中存在指定的类时,才会创建该 Bean。 示例&#…...
配置晟腾910b的PyTorch torch_npu环境
1.【新教程】华为昇腾NPU的pytorch环境搭建 - Lukea - 博客园 1、新建conda环境。 conda create -n pytorch python3.102、在新建好的conda环境中,安装基础的依赖。 pip install attrs cython numpy1.24.0 decorator sympy cffi pyyaml pathlib2 psutil protobuf…...
 [第291~300题](持续更新))
算法刷题记录——LeetCode篇(3.10) [第291~300题](持续更新)
更新时间:2025-04-02 算法题解目录汇总:算法刷题记录——题解目录汇总技术博客总目录:计算机技术系列博客——目录页 优先整理热门100及面试150,不定期持续更新,欢迎关注! 295. 数据流的中位数 中位数是…...

conda 激活环境vscode的Bash窗口
多份conda环境注意事项,当时安装了两个conda环境,miniconda和conda,导致环境总是冲突矛盾。初始化时需要更加注意。 $ C:/Users/a_hal/miniconda3/Scripts/conda.exe init bash能够显示用哪里的conda环境命令执行。 然后直接conda activate…...

网线和跳线
文章目录 一、网线二、跳线三、区别对比一句话总结 一、网线 网线(网路线): 它是一种用来连接网络设备的线,比如: 把 电脑连到交换机把 路由器连到光猫把 交换机和交换机连接起来 它的本质是:传输网络信…...
火山 RTC 引擎 2 ----APPKEY
前篇文章:火山RTC引擎 --一次失望的体验 那个DEMO可以编译运行了,但是功能不能用, 一用就崩溃。 主要原因还是没有APPKEY 一、火山引擎 APPKEY 管理 1、登录后台 账号登录-火山引擎欢迎登录火山引擎,火山引擎是字节跳动旗下的云…...

Linux中进程与计划任务
目录 一.进程 1.进程相关概念 2.进程的特征 3.进程相关的命令 3.1 ps命令 3.2 top命令 3.3 pgrep命令 3.4 pstree命令进程树 3.5 kill命令 二.计划任务 1.一次性任务 2.周期性任务crontab 三.本章涉及面试题 1.运维需要关注服务器的系统性能及如何查看 一.进程 1…...