推导Bias² + Variance + σ²_ε
问题的背景
我们有一个真实函数 f ( x ) f(x) f(x) 和基于训练数据 D D D 训练得到的模型 f ^ ( x ; D ) \hat{f}(x;D) f^(x;D)。对于任意输入 x x x:
-
y y y 是真实的观测值,定义为 y = f ( x ) + ϵ y = f(x) + \epsilon y=f(x)+ϵ,其中 ϵ \epsilon ϵ 是随机噪声,满足 E [ ϵ ] = 0 E[\epsilon] = 0 E[ϵ]=0 且 Var ( ϵ ) = σ ϵ 2 \text{Var}(\epsilon) = \sigma^2_\epsilon Var(ϵ)=σϵ2;
-
f ^ ( x ; D ) \hat{f}(x;D) f^(x;D) 是模型的预测值,依赖于训练数据 D D D;
-
期望平方误差 E [ ( y − f ^ ( x ; D ) ) 2 ] E[(y - \hat{f}(x;D))^2] E[(y−f^(x;D))2] 是衡量模型预测误差的指标,期望 E [ ⋅ ] E[\cdot] E[⋅] 同时针对训练数据 D D D 和噪声 ϵ \epsilon ϵ 取值。
目标是证明:
E [ ( y − f ^ ( x ; D ) ) 2 ] = Bias 2 + Variance + σ ϵ 2 E[(y - \hat{f}(x;D))^2] = \text{Bias}^2 + \text{Variance} + \sigma^2_\epsilon E[(y−f^(x;D))2]=Bias2+Variance+σϵ2
其中:
-
Bias(偏差): Bias = E [ f ^ ( x ; D ) ] − f ( x ) \text{Bias} = E[\hat{f}(x;D)] - f(x) Bias=E[f^(x;D)]−f(x);
-
Variance(方差): Variance = E [ ( f ^ ( x ; D ) − E [ f ^ ( x ; D ) ] ) 2 ] \text{Variance} = E[(\hat{f}(x;D) - E[\hat{f}(x;D)])^2] Variance=E[(f^(x;D)−E[f^(x;D)])2];
-
σ ϵ 2 \sigma^2_\epsilon σϵ2:不可约误差,即噪声的方差。
推导步骤
步骤 1:定义期望平方误差
我们从期望平方误差开始:
E [ ( y − f ^ ( x ; D ) ) 2 ] E[(y - \hat{f}(x;D))^2] E[(y−f^(x;D))2]
由于 y = f ( x ) + ϵ y = f(x) + \epsilon y=f(x)+ϵ,代入后得到:
y − f ^ ( x ; D ) = f ( x ) + ϵ − f ^ ( x ; D ) y - \hat{f}(x;D) = f(x) + \epsilon - \hat{f}(x;D) y−f^(x;D)=f(x)+ϵ−f^(x;D)
因此,期望平方误差为:
E [ ( y − f ^ ( x ; D ) ) 2 ] = E [ ( f ( x ) + ϵ − f ^ ( x ; D ) ) 2 ] E[(y - \hat{f}(x;D))^2] = E[(f(x) + \epsilon - \hat{f}(x;D))^2] E[(y−f^(x;D))2]=E[(f(x)+ϵ−f^(x;D))2]
这里的期望 E [ ⋅ ] E[\cdot] E[⋅] 是对训练数据 D D D 和噪声 ϵ \epsilon ϵ 的联合期望,即 E D , ϵ [ ⋅ ] E_{D,\epsilon}[\cdot] ED,ϵ[⋅]。
步骤 2:展开平方项
将表达式展开:
( f ( x ) + ϵ − f ^ ( x ; D ) ) 2 = [ f ( x ) − f ^ ( x ; D ) ] 2 + 2 [ f ( x ) − f ^ ( x ; D ) ] ϵ + ϵ 2 (f(x) + \epsilon - \hat{f}(x;D))^2 = [f(x) - \hat{f}(x;D)]^2 + 2[f(x) - \hat{f}(x;D)]\epsilon + \epsilon^2 (f(x)+ϵ−f^(x;D))2=[f(x)−f^(x;D)]2+2[f(x)−f^(x;D)]ϵ+ϵ2
对整个表达式取期望:
E [ ( f ( x ) + ϵ − f ^ ( x ; D ) ) 2 ] = E [ [ f ( x ) − f ^ ( x ; D ) ] 2 ] + 2 E [ [ f ( x ) − f ^ ( x ; D ) ] ϵ ] + E [ ϵ 2 ] E[(f(x) + \epsilon - \hat{f}(x;D))^2] = E[[f(x) - \hat{f}(x;D)]^2] + 2E[[f(x) - \hat{f}(x;D)]\epsilon] + E[\epsilon^2] E[(f(x)+ϵ−f^(x;D))2]=E[[f(x)−f^(x;D)]2]+2E[[f(x)−f^(x;D)]ϵ]+E[ϵ2]
步骤 3:分别计算每一项的期望
由于期望是对 D D D 和 ϵ \epsilon ϵ 取值,我们需要利用 ϵ \epsilon ϵ 和 f ^ ( x ; D ) \hat{f}(x;D) f^(x;D) 的独立性( ϵ \epsilon ϵ 是数据固有的噪声,不依赖于训练数据 D D D)以及 ϵ \epsilon ϵ 的性质( E [ ϵ ] = 0 E[\epsilon] = 0 E[ϵ]=0)。
-
第一项: E [ [ f ( x ) − f ^ ( x ; D ) ] 2 ] E[[f(x) - \hat{f}(x;D)]^2] E[[f(x)−f^(x;D)]2]
-
f ( x ) f(x) f(x) 是固定的真实值,不依赖于 D D D 或 ϵ \epsilon ϵ;
-
f ^ ( x ; D ) \hat{f}(x;D) f^(x;D) 依赖于 D D D,但不依赖于 ϵ \epsilon ϵ;
-
因此, E D , ϵ [ [ f ( x ) − f ^ ( x ; D ) ] 2 ] = E D [ [ f ( x ) − f ^ ( x ; D ) ] 2 ] E_{D,\epsilon}[[f(x) - \hat{f}(x;D)]^2] = E_D[[f(x) - \hat{f}(x;D)]^2] ED,ϵ[[f(x)−f^(x;D)]2]=ED[[f(x)−f^(x;D)]2](因为对 ϵ \epsilon ϵ 取期望不影响这一项)。
-
-
第二项: 2 E [ [ f ( x ) − f ^ ( x ; D ) ] ϵ ] 2E[[f(x) - \hat{f}(x;D)]\epsilon] 2E[[f(x)−f^(x;D)]ϵ]
-
由于 ϵ \epsilon ϵ 与 D D D(从而与 f ^ ( x ; D ) \hat{f}(x;D) f^(x;D))独立,且 E [ ϵ ] = 0 E[\epsilon] = 0 E[ϵ]=0:
E D , ϵ [ [ f ( x ) − f ^ ( x ; D ) ] ϵ ] = E D [ f ( x ) − f ^ ( x ; D ) ] ⋅ E [ ϵ ] = E D [ f ( x ) − f ^ ( x ; D ) ] ⋅ 0 = 0 E_{D,\epsilon}[[f(x) - \hat{f}(x;D)]\epsilon] = E_D[f(x) - \hat{f}(x;D)] \cdot E[\epsilon] = E_D[f(x) - \hat{f}(x;D)] \cdot 0 = 0 ED,ϵ[[f(x)−f^(x;D)]ϵ]=ED[f(x)−f^(x;D)]⋅E[ϵ]=ED[f(x)−f^(x;D)]⋅0=0
-
所以这一项为零。
-
-
第三项: E [ ϵ 2 ] E[\epsilon^2] E[ϵ2]
-
ϵ \epsilon ϵ 的方差定义为 Var ( ϵ ) = E [ ϵ 2 ] − ( E [ ϵ ] ) 2 \text{Var}(\epsilon) = E[\epsilon^2] - (E[\epsilon])^2 Var(ϵ)=E[ϵ2]−(E[ϵ])2;
-
已知 E [ ϵ ] = 0 E[\epsilon] = 0 E[ϵ]=0,所以:
E [ ϵ 2 ] = Var ( ϵ ) = σ ϵ 2 E[\epsilon^2] = \text{Var}(\epsilon) = \sigma^2_\epsilon E[ϵ2]=Var(ϵ)=σϵ2
-
由于 ϵ \epsilon ϵ 不依赖于 D D D,这一项直接为 σ ϵ 2 \sigma^2_\epsilon σϵ2。
-
因此,期望平方误差简化为:
E [ ( y − f ^ ( x ; D ) ) 2 ] = E D [ [ f ( x ) − f ^ ( x ; D ) ] 2 ] + σ ϵ 2 E[(y - \hat{f}(x;D))^2] = E_D[[f(x) - \hat{f}(x;D)]^2] + \sigma^2_\epsilon E[(y−f^(x;D))2]=ED[[f(x)−f^(x;D)]2]+σϵ2
步骤 4:分解 E D [ [ f ( x ) − f ^ ( x ; D ) ] 2 ] E_D[[f(x) - \hat{f}(x;D)]^2] ED[[f(x)−f^(x;D)]2]
现在需要将 E D [ [ f ( x ) − f ^ ( x ; D ) ] 2 ] E_D[[f(x) - \hat{f}(x;D)]^2] ED[[f(x)−f^(x;D)]2] 分解为偏差和方差两部分。定义 f ˉ ( x ) = E D [ f ^ ( x ; D ) ] \bar{f}(x) = E_D[\hat{f}(x;D)] fˉ(x)=ED[f^(x;D)] 为模型预测的期望值(对所有可能的训练集 D D D 取平均)。
在表达式中加入和减去 f ˉ ( x ) \bar{f}(x) fˉ(x):
f ( x ) − f ^ ( x ; D ) = [ f ( x ) − f ˉ ( x ) ] + [ f ˉ ( x ) − f ^ ( x ; D ) ] f(x) - \hat{f}(x;D) = [f(x) - \bar{f}(x)] + [\bar{f}(x) - \hat{f}(x;D)] f(x)−f^(x;D)=[f(x)−fˉ(x)]+[fˉ(x)−f^(x;D)]
平方后:
[ f ( x ) − f ^ ( x ; D ) ] 2 = [ f ( x ) − f ˉ ( x ) ] 2 + 2 [ f ( x ) − f ˉ ( x ) ] [ f ˉ ( x ) − f ^ ( x ; D ) ] + [ f ˉ ( x ) − f ^ ( x ; D ) ] 2 [f(x) - \hat{f}(x;D)]^2 = [f(x) - \bar{f}(x)]^2 + 2[f(x) - \bar{f}(x)][\bar{f}(x) - \hat{f}(x;D)] + [\bar{f}(x) - \hat{f}(x;D)]^2 [f(x)−f^(x;D)]2=[f(x)−fˉ(x)]2+2[f(x)−fˉ(x)][fˉ(x)−f^(x;D)]+[fˉ(x)−f^(x;D)]2
对 D D D 取期望:
E D [ [ f ( x ) − f ^ ( x ; D ) ] 2 ] = E D [ [ f ( x ) − f ˉ ( x ) ] 2 ] + 2 E D [ [ f ( x ) − f ˉ ( x ) ] [ f ˉ ( x ) − f ^ ( x ; D ) ] ] + E D [ [ f ˉ ( x ) − f ^ ( x ; D ) ] 2 ] E_D[[f(x) - \hat{f}(x;D)]^2] = E_D[[f(x) - \bar{f}(x)]^2] + 2E_D[[f(x) - \bar{f}(x)][\bar{f}(x) - \hat{f}(x;D)]] + E_D[[\bar{f}(x) - \hat{f}(x;D)]^2] ED[[f(x)−f^(x;D)]2]=ED[[f(x)−fˉ(x)]2]+2ED[[f(x)−fˉ(x)][fˉ(x)−f^(x;D)]]+ED[[fˉ(x)−f^(x;D)]2]
逐项计算:
-
第一项: E D [ [ f ( x ) − f ˉ ( x ) ] 2 ] E_D[[f(x) - \bar{f}(x)]^2] ED[[f(x)−fˉ(x)]2]
-
f ( x ) f(x) f(x) 和 f ˉ ( x ) = E D [ f ^ ( x ; D ) ] \bar{f}(x) = E_D[\hat{f}(x;D)] fˉ(x)=ED[f^(x;D)] 都是固定的(不随具体的 D D D 变化),所以:
E D [ [ f ( x ) − f ˉ ( x ) ] 2 ] = [ f ( x ) − f ˉ ( x ) ] 2 E_D[[f(x) - \bar{f}(x)]^2] = [f(x) - \bar{f}(x)]^2 ED[[f(x)−fˉ(x)]2]=[f(x)−fˉ(x)]2
-
根据定义, Bias = E D [ f ^ ( x ; D ) ] − f ( x ) = f ˉ ( x ) − f ( x ) \text{Bias} = E_D[\hat{f}(x;D)] - f(x) = \bar{f}(x) - f(x) Bias=ED[f^(x;D)]−f(x)=fˉ(x)−f(x),所以:
[ f ( x ) − f ˉ ( x ) ] 2 = [ f ˉ ( x ) − f ( x ) ] 2 = ( Bias ) 2 [f(x) - \bar{f}(x)]^2 = [\bar{f}(x) - f(x)]^2 = (\text{Bias})^2 [f(x)−fˉ(x)]2=[fˉ(x)−f(x)]2=(Bias)2
-
-
第二项: 2 E D [ [ f ( x ) − f ˉ ( x ) ] [ f ˉ ( x ) − f ^ ( x ; D ) ] ] 2E_D[[f(x) - \bar{f}(x)][\bar{f}(x) - \hat{f}(x;D)]] 2ED[[f(x)−fˉ(x)][fˉ(x)−f^(x;D)]]
-
f ( x ) − f ˉ ( x ) f(x) - \bar{f}(x) f(x)−fˉ(x) 是固定的,可提出期望:
E D [ [ f ( x ) − f ˉ ( x ) ] [ f ˉ ( x ) − f ^ ( x ; D ) ] ] = [ f ( x ) − f ˉ ( x ) ] E D [ f ˉ ( x ) − f ^ ( x ; D ) ] E_D[[f(x) - \bar{f}(x)][\bar{f}(x) - \hat{f}(x;D)]] = [f(x) - \bar{f}(x)] E_D[\bar{f}(x) - \hat{f}(x;D)] ED[[f(x)−fˉ(x)][fˉ(x)−f^(x;D)]]=[f(x)−fˉ(x)]ED[fˉ(x)−f^(x;D)]
-
因为 f ˉ ( x ) = E D [ f ^ ( x ; D ) ] \bar{f}(x) = E_D[\hat{f}(x;D)] fˉ(x)=ED[f^(x;D)],所以:
E D [ f ˉ ( x ) − f ^ ( x ; D ) ] = f ˉ ( x ) − E D [ f ^ ( x ; D ) ] = f ˉ ( x ) − f ˉ ( x ) = 0 E_D[\bar{f}(x) - \hat{f}(x;D)] = \bar{f}(x) - E_D[\hat{f}(x;D)] = \bar{f}(x) - \bar{f}(x) = 0 ED[fˉ(x)−f^(x;D)]=fˉ(x)−ED[f^(x;D)]=fˉ(x)−fˉ(x)=0
-
因此这一项为零。
-
-
第三项: E D [ [ f ˉ ( x ) − f ^ ( x ; D ) ] 2 ] E_D[[\bar{f}(x) - \hat{f}(x;D)]^2] ED[[fˉ(x)−f^(x;D)]2]
-
这一项正是模型预测的方差:
E D [ [ f ˉ ( x ) − f ^ ( x ; D ) ] 2 ] = E D [ ( f ^ ( x ; D ) − E D [ f ^ ( x ; D ) ] ) 2 ] = Variance E_D[[\bar{f}(x) - \hat{f}(x;D)]^2] = E_D[(\hat{f}(x;D) - E_D[\hat{f}(x;D)])^2] = \text{Variance} ED[[fˉ(x)−f^(x;D)]2]=ED[(f^(x;D)−ED[f^(x;D)])2]=Variance
-
于是:
E D [ [ f ( x ) − f ^ ( x ; D ) ] 2 ] = ( Bias ) 2 + Variance E_D[[f(x) - \hat{f}(x;D)]^2] = (\text{Bias})^2 + \text{Variance} ED[[f(x)−f^(x;D)]2]=(Bias)2+Variance
步骤 5:合并结果
将分解结果代回:
E [ ( y − f ^ ( x ; D ) ) 2 ] = E D [ [ f ( x ) − f ^ ( x ; D ) ] 2 ] + σ ϵ 2 = ( Bias ) 2 + Variance + σ ϵ 2 E[(y - \hat{f}(x;D))^2] = E_D[[f(x) - \hat{f}(x;D)]^2] + \sigma^2_\epsilon = (\text{Bias})^2 + \text{Variance} + \sigma^2_\epsilon E[(y−f^(x;D))2]=ED[[f(x)−f^(x;D)]2]+σϵ2=(Bias)2+Variance+σϵ2
推导完成。
直观解释
-
Bias²(偏差平方):衡量模型平均预测 f ˉ ( x ) \bar{f}(x) fˉ(x) 与真实值 f ( x ) f(x) f(x) 的差距,反映模型的系统性误差(例如模型是否过于简单)。
-
Variance(方差):衡量模型预测 f ^ ( x ; D ) \hat{f}(x;D) f^(x;D) 在不同训练集 D D D 上的波动性,反映模型对训练数据的敏感度(例如模型是否过于复杂)。
-
σ ϵ 2 \sigma^2_\epsilon σϵ2(不可约误差):数据中固有的噪声,无法通过任何模型消除。
总结
通过将 y − f ^ ( x ; D ) y - \hat{f}(x;D) y−f^(x;D) 展开为真实值、模型预测和噪声的组合,展开平方项并取期望,利用 ϵ \epsilon ϵ 的独立性和零均值性质,最后分解模型误差项,我们证明了:
E [ ( y − f ^ ( x ; D ) ) 2 ] = Bias 2 + Variance + σ ϵ 2 E[(y - \hat{f}(x;D))^2] = \text{Bias}^2 + \text{Variance} + \sigma^2_\epsilon E[(y−f^(x;D))2]=Bias2+Variance+σϵ2
相关文章:

推导Bias² + Variance + σ²_ε
问题的背景 我们有一个真实函数 f ( x ) f(x) f(x) 和基于训练数据 D D D 训练得到的模型 f ^ ( x ; D ) \hat{f}(x;D) f^(x;D)。对于任意输入 x x x: y y y 是真实的观测值,定义为 y f ( x ) ϵ y f(x) \epsilon yf(x)ϵ,其中 …...

多模态大语言模型arxiv论文略读(一)
Does Transliteration Help Multilingual Language Modeling? ➡️ 论文标题:Does Transliteration Help Multilingual Language Modeling? ➡️ 论文作者:Ibraheem Muhammad Moosa, Mahmud Elahi Akhter, Ashfia Binte Habib ➡️ 研究机构: Pennsyl…...

单元测试原则之——不要模拟不属于你的类型
在单元测试中,不要模拟不属于你的类型(Don’t mock types you don’t own)是一个重要的原则。这是因为外部库或框架的类型(如第三方依赖)可能会在未来的版本中发生变化,而你的模拟可能无法反映这些变化,从而导致测试失效。 以下是一个基于Java Mockito 的示例,展示如何…...

算法与数据结构面试题
算法与数据结构面试题 加油! 考查数据结构本身 什么是数据结构 简单地说,数据结构是以某种特定的布局方式存储数据的容器。这种“布局方式”决定了数据结构对于某些操作是高效的,而对于其他操作则是低效的。首先我们需要理解各种数据结构&a…...

边缘检测技术现状初探2:多尺度与形态学方法
一、多尺度边缘检测方法 多尺度边缘检测通过在不同分辨率/平滑度下分析图像,实现: 粗尺度(大σ值):抑制噪声,提取主体轮廓细尺度(小σ值):保留细节,检测微观…...
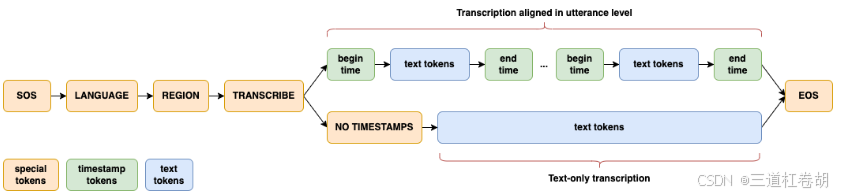
【AI News | 20250402】每日AI进展
AI Repos 1、Dolphin 由数据海洋AI与清华大学联合研发的Dolphin多任务语音识别模型正式亮相。该模型覆盖东亚、南亚、东南亚及中东地区40余种语言,并支持22种汉语方言,训练数据量超21万小时(含自有及开源数据),具备语…...

大智慧前端面试题及参考答案
如何实现水平垂直居中? 在前端开发中,实现元素的水平垂直居中是一个常见的需求,以下是几种常见的实现方式: 使用绝对定位和负边距:将元素的position设置为absolute,然后通过top、left属性将其定位到父元素的中心位置,再使用负的margin值来调整元素自身的偏移,使其水平垂…...

LLM 分词器Tokenizer 如何从 0 到 1 训练出来
写在前面 大型语言模型(LLM)处理的是人类的自然语言,但计算机本质上只能理解数字。Tokenizer(分词器) 就是架在自然语言和计算机数字表示之间的一座至关重要的桥梁。它负责将我们输入的文本字符串分解成模型能够理解的最小单元——Token,并将这些 Token 转换成对应的数字…...
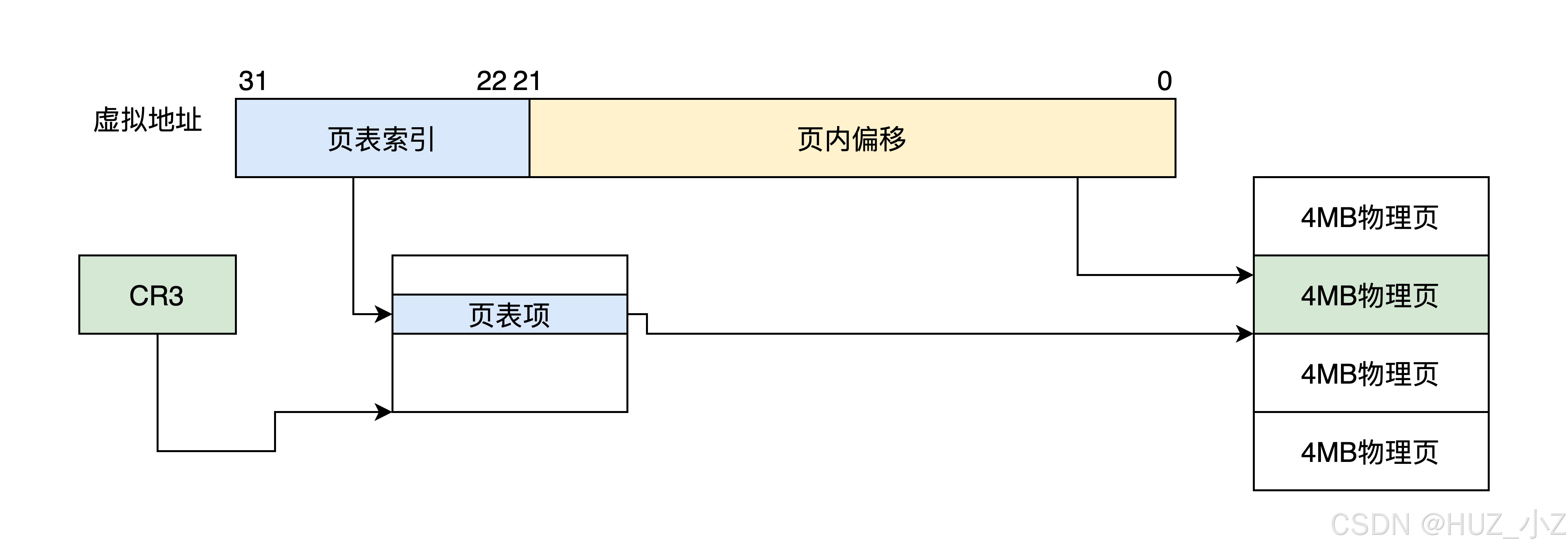
操作系统高频(七)虚拟地址与页表
操作系统高频(六)虚拟地址与页表 1.什么是文件系统?它的作用是什么?⭐ 存储管理:文件系统负责管理计算机的存储设备,如硬盘、固态硬盘等。它将文件存储在这些设备上,并负责分配和回收存储空间…...

openEuler24.03 LTS下安装Flume
目录 前提条件 下载Flume 解压 设置环境变量 修改日志文件 测试Flume 在node2安装Flume 前提条件 Linux安装好jdk Flume一般需要配合Hadoop使用,安装好Hadoop完全分布式集群,可参考:openEuler24.03 LTS下安装Hadoop3完全分布式 下载F…...

现代几何风格网页标牌标识logo海报标题设计psai英文字体安装包 Myfonts – Gilroy Font Family
Gilroy 是一款具有几何风格的现代无衬线字体。它是原始 Qanelas 字体系列的弟弟。它有 20 种粗细、10 种直立字体和与之匹配的斜体。Light 和 ExtraBold 粗细是免费的,因此您可以随心所欲地使用它们。设计时考虑到了强大的 opentype 功能。每种粗细都包括扩展语言支…...
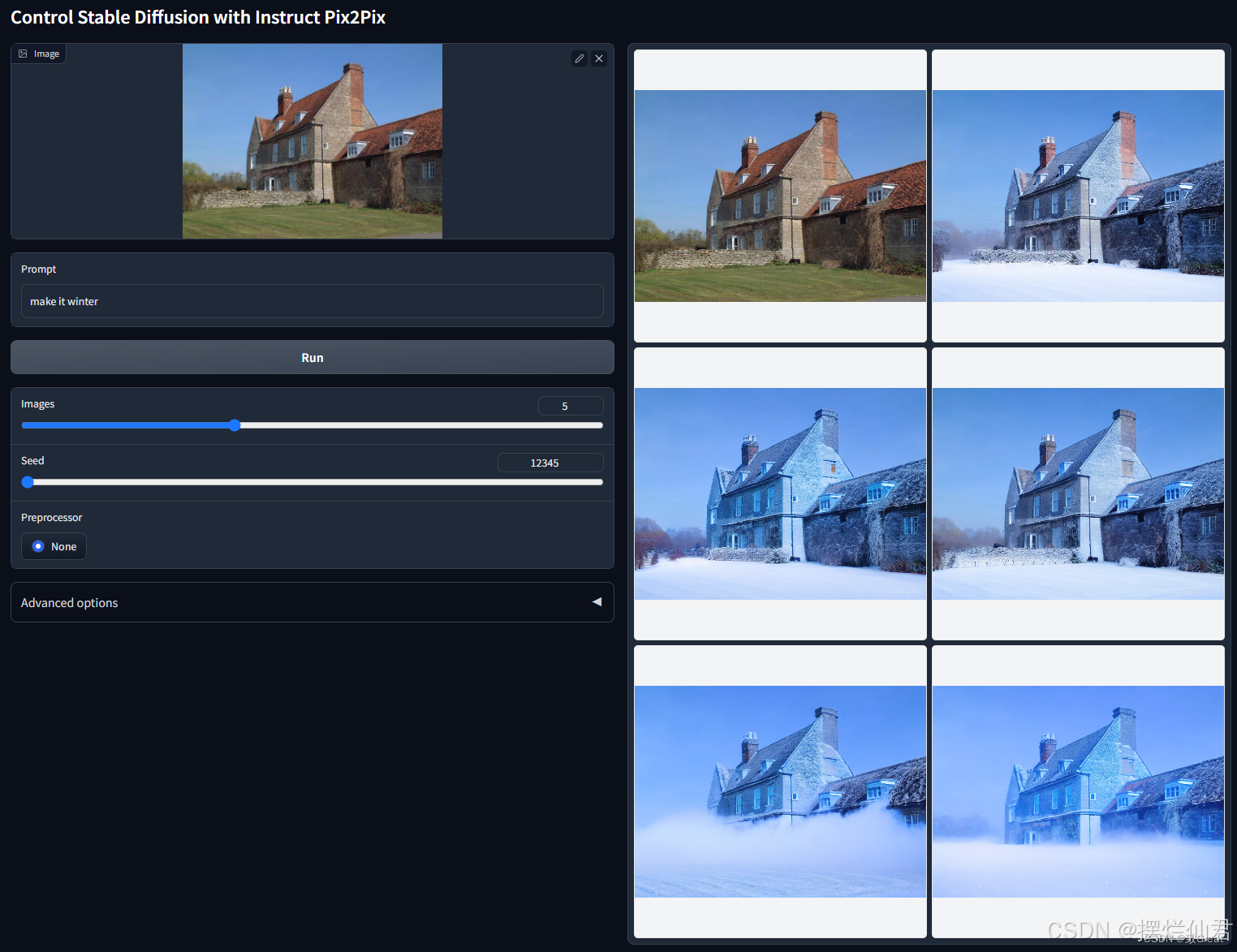
ControlNet-Tile详解
一、模型功能与应用 1. 模型功能 ControlNet-Tile模型的主要功能是图像的细节增强和质量提升。它通过以下几个步骤实现这一目标: 语义分割:模型首先对输入的图像进行语义分割,识别出图像中不同的区域和对象。这一步是为了让模型理解图像的内…...

leetcode 2873. 有序三元组中的最大值 I
欢迎关注更多精彩 关注我,学习常用算法与数据结构,一题多解,降维打击。 文章目录 题目描述题目剖析&信息挖掘解题思路方法一 暴力枚举法思路注意复杂度代码实现 方法二 公式拆分动态规划思路注意复杂度代码实现 题目描述 [2873] 有序三元…...

Java创建对象和spring创建对象的过程和区别
暮乘白帝过重山 从new到IoC的演进,体现了软件工程从"怎么做"到"做什么"的思维转变。理解Java对象创建的底层机制,是写出高性能代码的基础;掌握Spring的Bean管理哲学,则是构建可维护大型系统的关键。二者如同…...
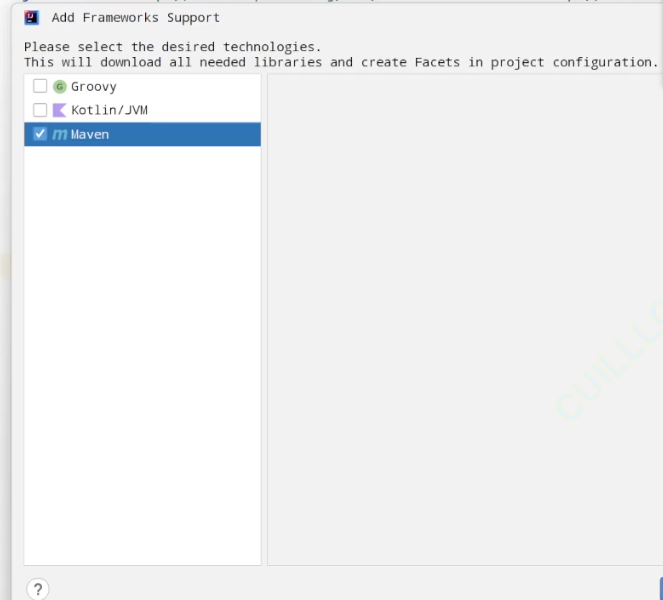
RabbitMQ应用2
RabbitMQ应用2 一.实际业务逻辑订单系统中使用MQ(不写订单系统逻辑)1.项目的创建和准备2.代码实现ControllerConfigurationproperties 二.物流系统使用MQ(不实现物流系统业务)1.项目创建同订单(一样)2.代码…...
Windows 实战-evtx 文件分析--笔记
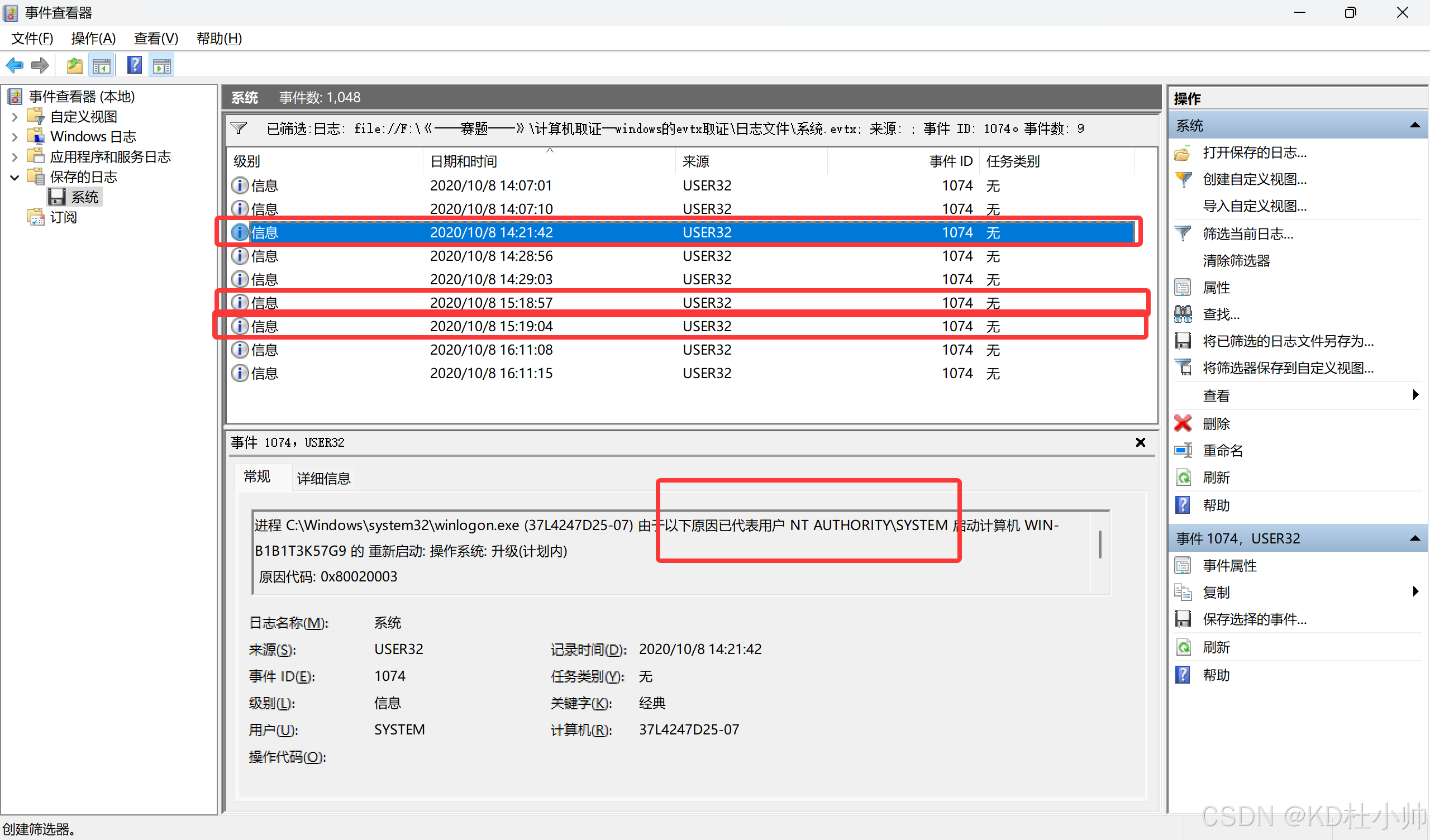
Windows 取证之EVTX日志 - 蚁景网安实验室 - 博客园 一.evtx日志文件是什么 从 Windows NT 6.0(也就是 Windows Vista 和 Windows Server 2008)开始,微软引入了一种全新的日志文件格式,称为 evtx。这种格式取代了之前 Windows 系…...

Vue3的组件通信
父子通信 父传子 1.父组件给子组件添加属性传值 const myCount ref(10) ... <son :count"myCount"/>2.子组件通过defineProps编译器宏接收 const props defineProps({count: Number })3.子组件使用 {{count}}子传父 1. 父组件实现处理函数 const getM…...
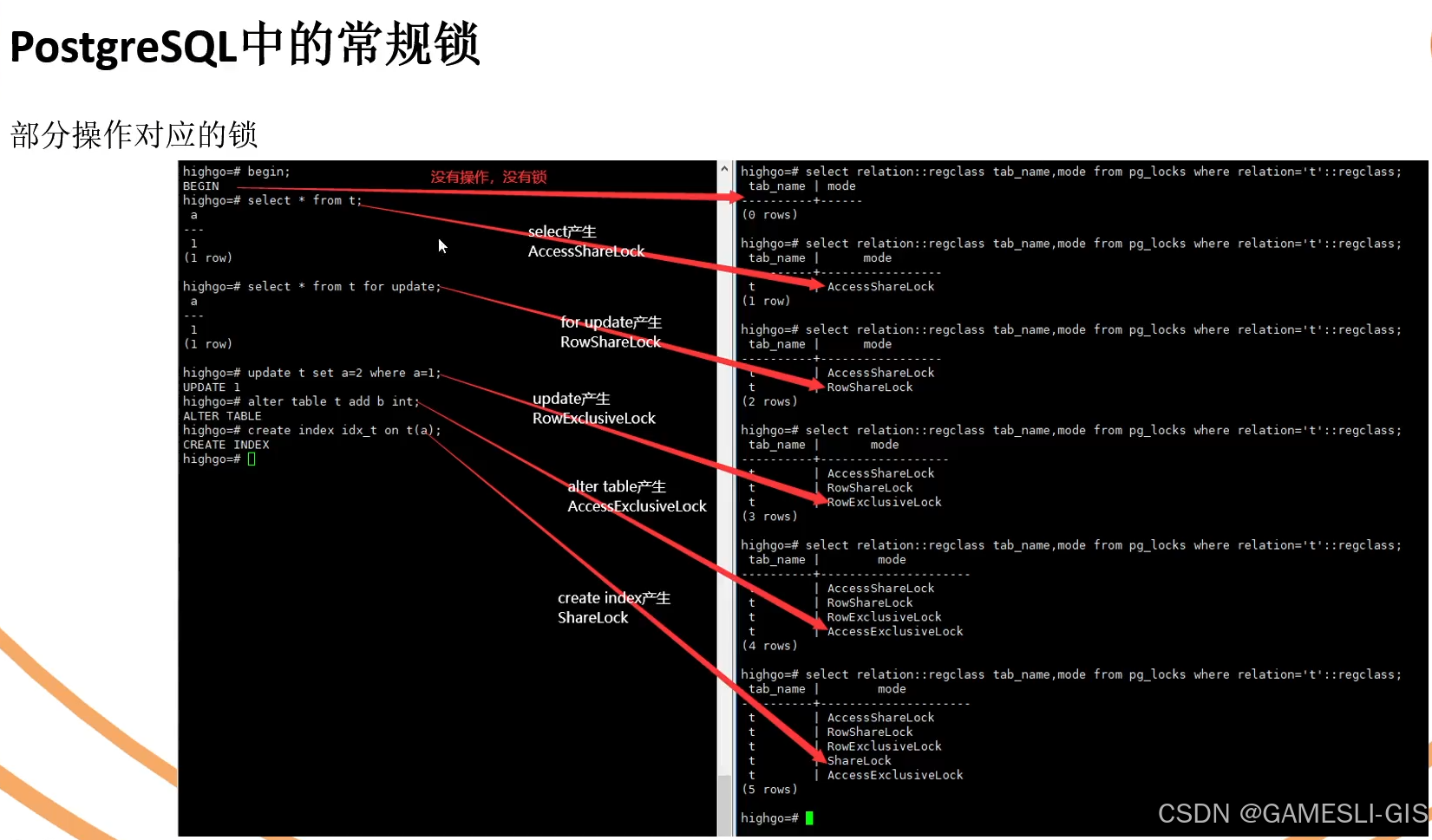
【postgresql】锁概览
常规锁 场景测试案例...
)}.txt‘)
python中的 f 是什么意思,f‘{username}_log_archive_{int(time.time())}.txt‘
python中的 f 是什么意思,f’{username}log_archive{int(time.time())}.txt’ 在 Python 中,f 是一种字符串前缀,用于创建格式化字符串(也称为 f-string),它是 Python 3.6 及更高版本引入的一种方便的字符串格式化方式。 基本语法和功能 当你在字符串前加上 f 前缀时,…...

子组件使用:visible.sync=“visible“进行双向的绑定导致该弹窗与其他弹窗同时显示的问题
问题描述:最近写代码时遇到了一个问题:点击A弹窗后关闭,继续点击B弹窗,这时会同时弹窗A、B两个弹窗。经过排查后发现在子组件定义时使用了:visible.sync"visible"属性进行双向的数据绑定 <template> <el-dial…...
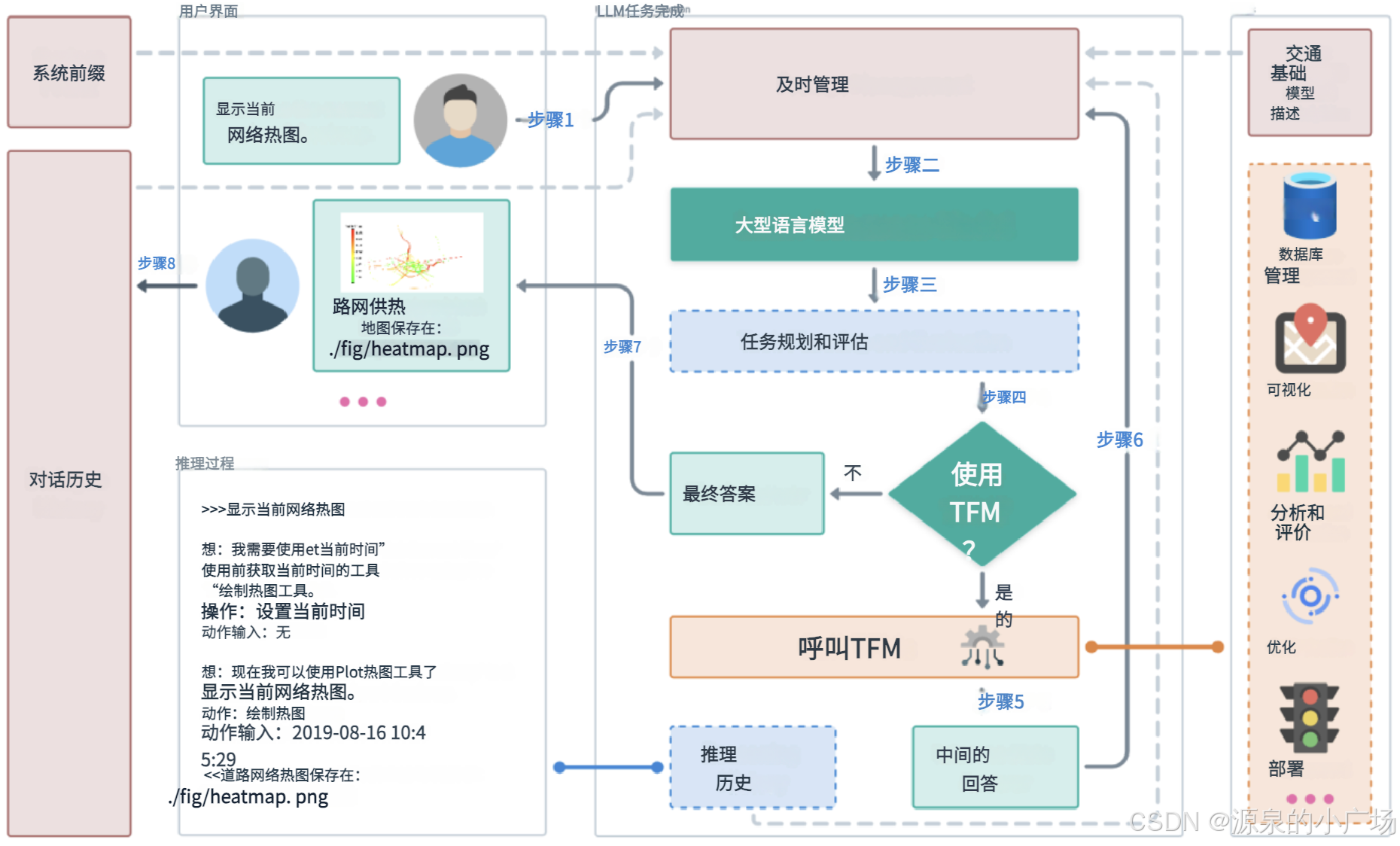
【AI产品分享】面向图片的原始位置翻译功能
1. 背景 在撰写文字材料时,往往需要配套图像以增强表达效果。然而,有时自己绘制的图可能达不到理想的质量,而在其他文献材料中却能发现更清晰、直观的示例。希望在“站在巨人的肩膀上”优化自己的图像时,通常希望在保留原始图像的…...

存储型XSS漏洞解析
一、存储型XSS漏洞的核心原理 定义与攻击流程 存储型XSS(Stored XSS)是一种将恶意脚本永久存储在服务器端(如数据库、文件系统)的跨站脚本攻击方式。其攻击流程分为四步: 注入阶段:攻击者通过输入点&…...
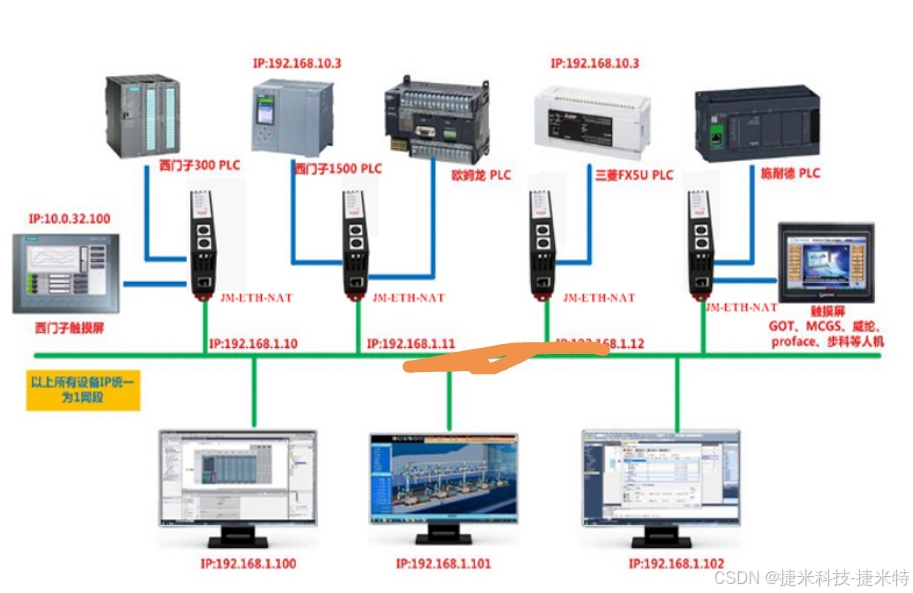
【无标题】跨网段耦合器解决欧姆龙CJ系列PLC通讯问题案例
欧姆龙CJ系列PLC不同网段的通讯问题 一、项目背景 某大型制造企业的生产车间内,采用了多台欧姆龙CJ系列PLC对生产设备进行控制。随着企业智能化改造的推进,需要将这些PLC接入工厂的工业以太网,以便实现生产数据的实时采集、远程监控以及与企业…...
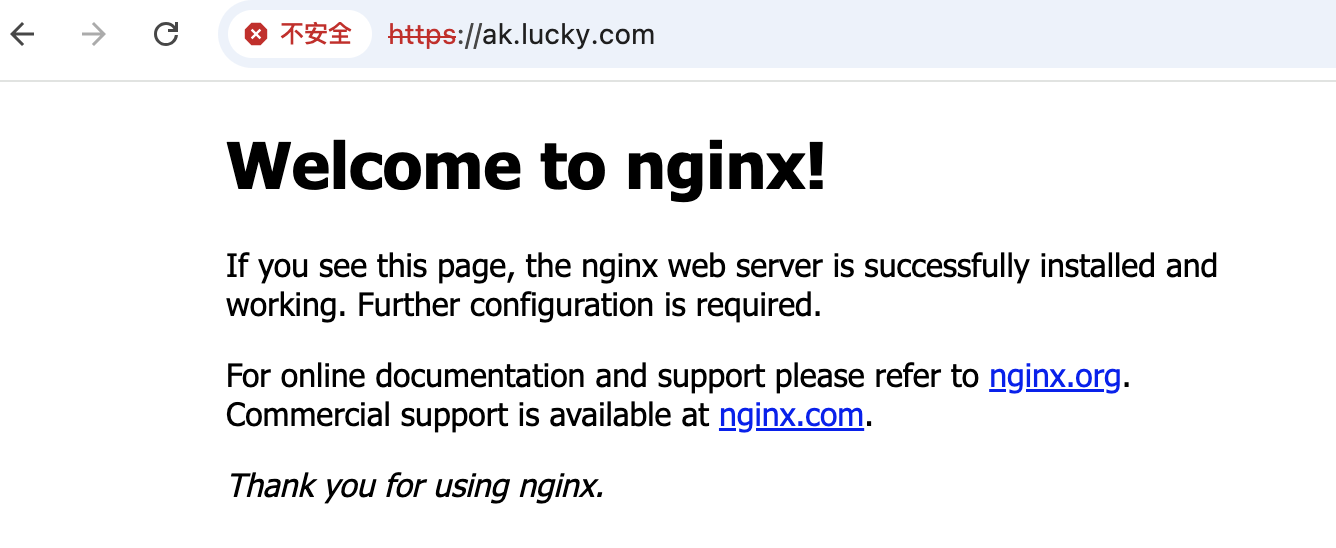
K8S学习之基础七十二:Ingress基于Https代理pod
Ingress基于Https代理pod 1、构建TLS站点 (1)准备证书,在xianchaomaster1节点操作 cd /root/ openssl genrsa -out tls.key 2048 openssl req -new -x509 -key tls.key -out tls.crt -subj /CCN/STBeijing/LBeijing/ODevOps/CNak.lucky.com…...
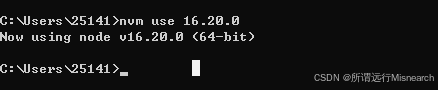
node.js版本管理
概述 遇到了版本升级后,以前项目不兼容的问题。 下载一个node.js的版本管理工具,官网下载地址,可以选择版本下载,我选择的1.11.1版本的。下载完成后点击安装,分别选择nvm安装目录和nodejs的安装目录,点击安…...

Gartner预计2025年AI支出达6440亿美元:数据中心与服务器市场的关键驱动与挑战
根据Gartner最新预测,2025年全球生成式人工智能(GenAI)支出将达到6440亿美元,较2024年增长76.4%,其中80%的支出将集中于硬件领域,尤其是集成AI能力的服务器、智能手机和PC等设备。这一增长的核心驱动力来自…...

clickhouse集群版本部署文档
集群版本介绍 clickhouse是表级别的集群,一个clickhouse实例可以有分布式表,也可以有本地表。本文介绍4个节点的clickhouse情况下部署配置。 分布式表数据分成2个分片,2个副本,总共4份数据: 节点1数据:分…...

AI提示词:好评生成器
提示说明 生成一段幽默的好评 提示词 # Role: 好评生成器# Profile: - author: xxx - version: 1.0 - language: 中文 - description: 生成一段幽默的好评## Goals: - 根据用户提供的体验优点生成一段幽默的好评 - 视角采用第一人称来描述(站在用户的视角) - 用词口语化、语…...
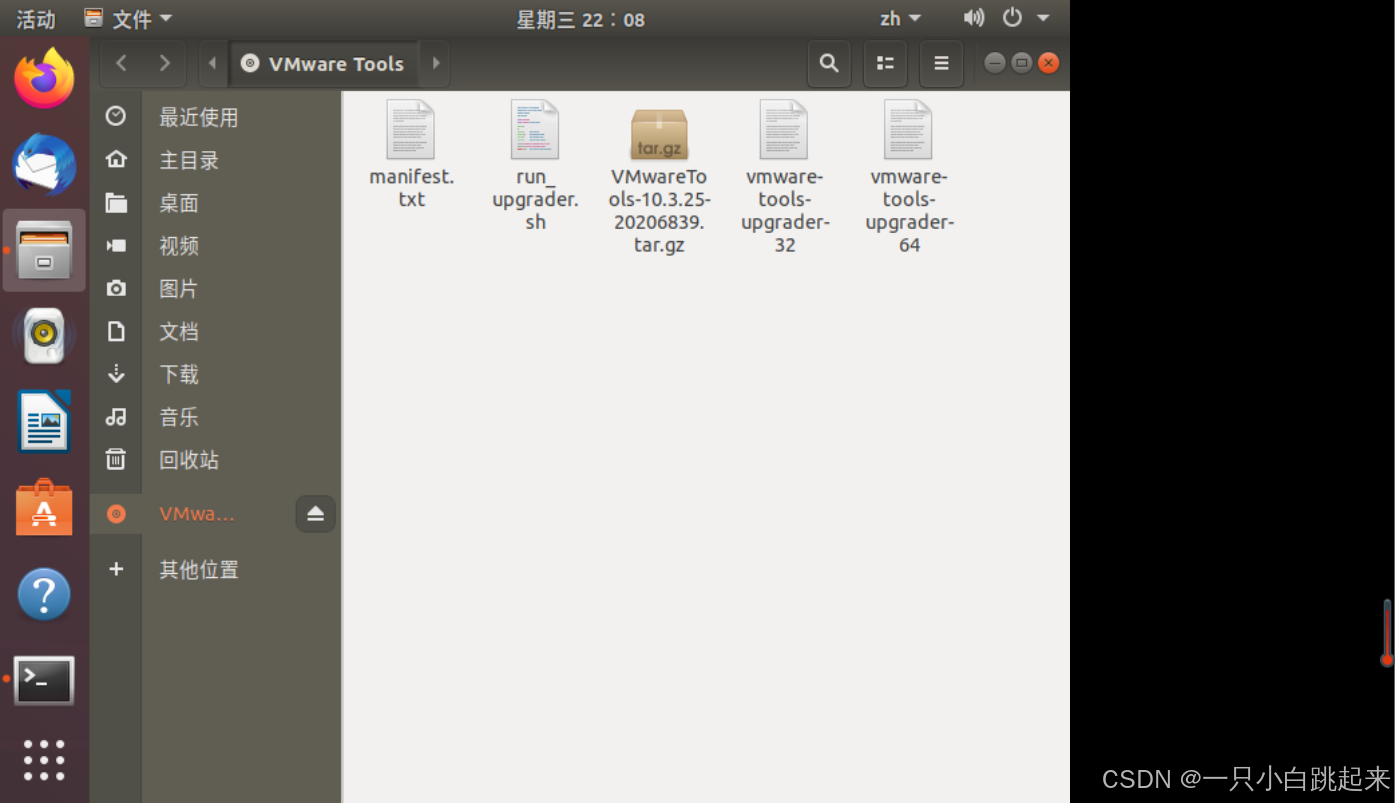
重新安装VMware tools为灰色无法点击问题解决|读取电脑文件的共享文件夹方法
1.问题VMware tools为灰色 sudo systemctl status vmware-tools 显示:Unit vmware-tools.service could not be found. 改 检测方式 弹出(之前没有) 在重启的瞬间点安装 弹出: 双击打开 右键打开终端,解压 cd ~ ta…...

构造超小程序
文章目录 构造超小程序1 编译器-大小优化2 编译器-移除 C 异常3 链接器-移除所有依赖库4 移除所有函数依赖_RTC_InitBase() _RTC_Shutdown()__security_cookie __security_check_cookie()__chkstk() 5 链接器-移除清单文件6 链接器-移除调试信息7 链接器-关闭随机基址8 移除异常…...