深度学习Note.5(机器学习.6)
1.Runner类
一个任务应用机器学习方法流程:
数据集构建
模型构建
损失函数定义
优化器
模型训练
模型评价
模型预测
所以根据以上,我们把机器学习模型基本要素封装成一个Runner类(加上模型保存、模型加载等功能。)
Runner类的成员函数定义如下:
- __init__函数:实例化Runner类时默认调用,需要传入模型、损失函数、优化器和评价指标等;
- train函数:完成模型训练,指定模型训练需要的训练集和验证集;
- evaluate函数:通过对训练好的模型进行评价,在验证集或测试集上查看模型训练效果;
- predict函数:选取一条数据对训练好的模型进行预测;
- save_model函数:模型在训练过程和训练结束后需要进行保存;
- load_model函数:调用加载之前保存的模型。
class Runner(object):def __init__(self, model, optimizer, loss_fn, metric):self.model = model # 模型self.optimizer = optimizer # 优化器self.loss_fn = loss_fn # 损失函数 self.metric = metric # 评估指标# 模型训练def train(self, train_dataset, dev_dataset=None, **kwargs):pass# 模型评价def evaluate(self, data_set, **kwargs):pass# 模型预测def predict(self, x, **kwargs):pass# 模型保存def save_model(self, save_path):pass# 模型加载def load_model(self, model_path):pass1.2Runner类流程
①初始化:传入模型、损失函数、优化器和评价指标
②训练:基于训练集调用train()函数训练模型,基于验证集通过evaluate()函数验证模型。通过save_model()函数保存模型
③评价:基于测试集通过evaluate()函数得到指标性能。
④预测:给定样本,通过predict()函数得到该样本标签

2.案例:波士顿房价预测
波士顿房价预测基于线性回归模型和Runner类实现
2.1数据处理
2.1.1构建
开源库pandas导入。
import pandas as pd # 开源数据分析和操作工具# 利用pandas加载波士顿房价的数据集
data=pd.read_csv("/home/aistudio/work/boston_house_prices.csv")
# 预览前5行数据
data.head()2.1.2数据集划分
训练集 和 测试集。
import paddlepaddle.seed(10)# 划分训练集和测试集
def train_test_split(X, y, train_percent=0.8):n = len(X)shuffled_indices = paddle.randperm(n) # 返回一个数值在0到n-1、随机排列的1-D Tensortrain_set_size = int(n*train_percent)train_indices = shuffled_indices[:train_set_size]test_indices = shuffled_indices[train_set_size:]X = X.valuesy = y.valuesX_train=X[train_indices]y_train = y[train_indices]X_test = X[test_indices]y_test = y[test_indices]return X_train, X_test, y_train, y_test X = data.drop(['MEDV'], axis=1)
y = data['MEDV']X_train, X_test, y_train, y_test = train_test_split(X,y)# X_train每一行是个样本,shape[N,D]2.1.3特征化工程
避免数据之间的可比性:对特征数据进行归一化处理,将数据缩放到[0, 1]区间
import paddleX_train = paddle.to_tensor(X_train,dtype='float32')
X_test = paddle.to_tensor(X_test,dtype='float32')
y_train = paddle.to_tensor(y_train,dtype='float32')
y_test = paddle.to_tensor(y_test,dtype='float32')X_min = paddle.min(X_train,axis=0)
X_max = paddle.max(X_train,axis=0)X_train = (X_train-X_min)/(X_max-X_min)X_test = (X_test-X_min)/(X_max-X_min)# 训练集构造
train_dataset=(X_train,y_train)
# 测试集构造
test_dataset=(X_test,y_test)2.2模型构建
rom nndl.op import Linear# 模型实例化
input_size = 12
model=Linear(input_size)2.3完善Runner类
测试集上使用MSE对模型性能进行评估。本案例利用飞桨框架提供的MSELoss API实现
import paddle
import os
from nndl.opitimizer import optimizer_lsmclass Runner(object):def __init__(self, model, optimizer, loss_fn, metric):# 优化器和损失函数为None,不再关注# 模型self.model=model# 评估指标self.metric = metric# 优化器self.optimizer = optimizerdef train(self,dataset,reg_lambda,model_dir):X,y = datasetself.optimizer(self.model,X,y,reg_lambda)# 保存模型self.save_model(model_dir)def evaluate(self, dataset, **kwargs):X,y = datasety_pred = self.model(X)result = self.metric(y_pred, y)return resultdef predict(self, X, **kwargs):return self.model(X)def save_model(self, model_dir):if not os.path.exists(model_dir):os.makedirs(model_dir)params_saved_path = os.path.join(model_dir,'params.pdtensor')paddle.save(model.params,params_saved_path)def load_model(self, model_dir):params_saved_path = os.path.join(model_dir,'params.pdtensor')self.model.params=paddle.load(params_saved_path)optimizer = optimizer_lsm# 实例化Runner
runner = Runner(model, optimizer=optimizer,loss_fn=None, metric=mse_loss)2.4模型训练
组装完成Runner之后,我们将开始进行模型训练、评估和测试
# 模型保存文件夹
saved_dir = '/home/aistudio/work/models'# 启动训练
runner.train(train_dataset,reg_lambda=0,model_dir=saved_dir)columns_list = data.columns.to_list()
weights = runner.model.params['w'].tolist()
b = runner.model.params['b'].item()for i in range(len(weights)):print(columns_list[i],"weight:",weights[i])print("b:",b)2.5模型测试
加载训练好的模型参数,在测试集上得到模型的MSE指标
# 加载模型权重
runner.load_model(saved_dir)mse = runner.evaluate(test_dataset)
print('MSE:', mse.item())2.6模型预测
load_model函数加载保存好的模型,使用predict进行模型预测
runner.load_model(saved_dir)
pred = runner.predict(X_test[:1])
print("真实房价:",y_test[:1].item())
print("预测的房价:",pred.item())真实房价: 33.099998474121094 预测的房价: 33.04654312133789
相关文章:
深度学习Note.5(机器学习.6)
1.Runner类 一个任务应用机器学习方法流程: 数据集构建 模型构建 损失函数定义 优化器 模型训练 模型评价 模型预测 所以根据以上,我们把机器学习模型基本要素封装成一个Runner类(加上模型保存、模型加载等功能。) Runne…...
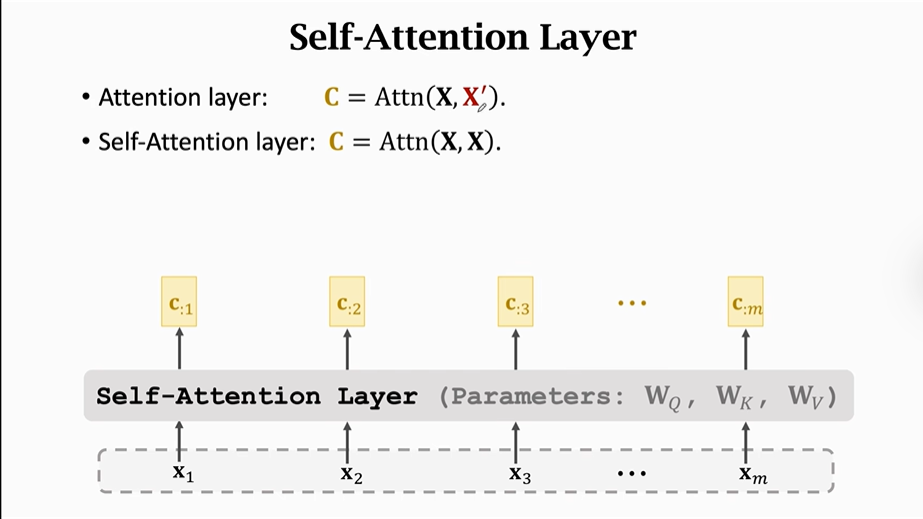
从零开始设计Transformer模型(1/2)——剥离RNN,保留Attention
声明: 本文基于哔站博主【Shusenwang】的视频课程【RNN模型及NLP应用】,结合自身的理解所作,旨在帮助大家了解学习NLP自然语言处理基础知识。配合着视频课程学习效果更佳。 材料来源:【Shusenwang】的视频课程【RNN模型及NLP应用…...

Uniapp 持续出现 Invalid Host/Origin header 解决方法
目录 前言1. 问题所示2. 原理分析前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 爬虫神器,无代码爬取,就来:bright.cn 1. 问题所示 执行代码的时候,源源不断,一直持续出现这个 Invalid Host/Origin header [WDS]...
【 <二> 丹方改良:Spring 时代的 JavaWeb】之 Spring Boot 中的缓存技术:使用 Redis 提升性能
<前文回顾> 点击此处查看 合集 https://blog.csdn.net/foyodesigner/category_12907601.html?fromshareblogcolumn&sharetypeblogcolumn&sharerId12907601&sharereferPC&sharesourceFoyoDesigner&sharefromfrom_link <今日更新> 一、开篇整…...

音视频 YUV格式详解
前言 本文介绍YUV色彩模型,YUV的分类和常见格式。 RGB色彩模型 在RGB颜色空间中,任意色光F都可以使用R、G、B三色不同的分量混合相加而成即: F = R + G + B.。即我们熟悉的三原色模型。 RGB色彩空间根据每个分量在计算机中占用的存储字节数可以分为以下几种类型,字节数…...
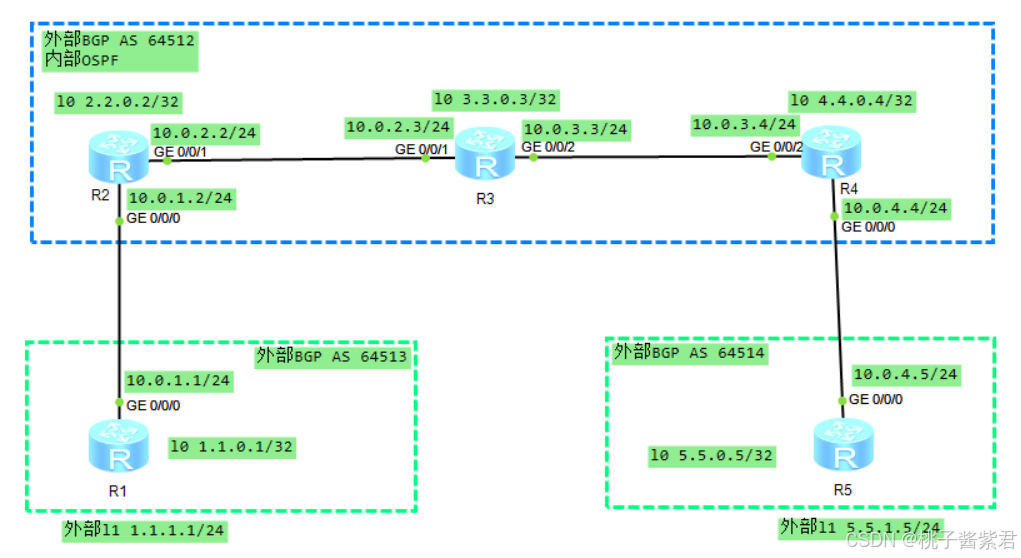
华为配置篇-BGP实验
BGP 一、简述二、常用命令总结三、实验 一、简述 IBGP 水平分割:从一个 IBGP 对等体学到的路由,不会再通告给其他的 IBGP 对等体。在一个 AS 内部,路由器之间通过 IBGP 交换路由信息。如果没有水平分割机制,当多个路由器之间形成…...

一个服务器算分布式吗,分布式需要几个服务器
一个服务器不构成分布式系统。分布式系统的核心在于多台独立的计算机(服务器)协同工作,通过通信网络共享资源、共同完成任务。以下是对问题的详细分析: 1. 单台服务器 ≠ 分布式 单台服务器的架构是集中式的,所有功能…...

vue element-ui 工程创建
vue element-ui 工程创建 按照步骤 : https://blog.csdn.net/wowocpp/article/details/146590400 创建工程 vue create demo3 cd demo3 npm run serve 在demo3 目录里面 执行如下命令 npm install element-ui -S 然后查看 package.json main.js 添加代码&…...

unity点击button后不松开通过拖拽显示模型松开后模型实例化
using System.Collections; using UnityEngine; using UnityEngine.EventSystems; using UnityEngine.UI;[RequireComponent(typeof(Button))] // 确保脚本挂在Button上 public class DragButtonSpawner : MonoBehaviour, IPointerDownHandler, IDragHandler, IPointerUpHandle…...

arco design框架中的树形表格使用中的缓存问题
目录 1.问题 2.解决方案 1.问题 arco design框架中的树形表格使用中的缓存问题,使用了树形表格的load-more懒加载 点击展开按钮后,点击关闭,再次点击展开按钮时,没有调用查询接口,而是使用了缓存的数据。 2.解决方…...

《AI大模型应知应会100篇》第2篇:大模型核心术语解析:参数、Token、推理与训练
第2篇:大模型核心术语解析:参数、Token、推理与训练 摘要 本文将用通俗易懂的语言拆解大模型领域的四大核心概念:参数、Token、训练与推理。通过案例对比、代码实战和成本计算,帮助读者快速掌握这些术语的底层逻辑与实际应用价值…...

【28BYJ-48】STM32同时驱动4个步进电机,支持调速与正反转
资料下载:待更新。。。。 先驱动起来再说,干中学!!! 1、实现功能 STM32同时驱动4个步进电机,支持单独调速与正反转控制 需要资源:16个任意IO口1ms定时器中断 目录 资料下载:待更…...

手动实现一个迷你Llama:使用SentencePiece实现自己的tokenizer
自己训练一个tokenizertokenizer需要的模块SentencePiece 库tokenizer类中的初始化函数tokenizer类中的encode函数tokenizer类中的decode函数完整代码训练函数数据分片临时文件SentencePiece 训练参数 自己训练一个tokenizer tokenizer需要的模块 encode: 将句子转换为tokend…...

【超详细】讲解Ubuntu上如何配置分区方案
Ubuntu 的分区方案 一、通用分区方案(200G为例) EFI系统分区(仅UEFI启动模式需要,) 大小:512MB–1GB类型:主分区(FAT32格式)挂载点:/boot/efi说明࿱…...
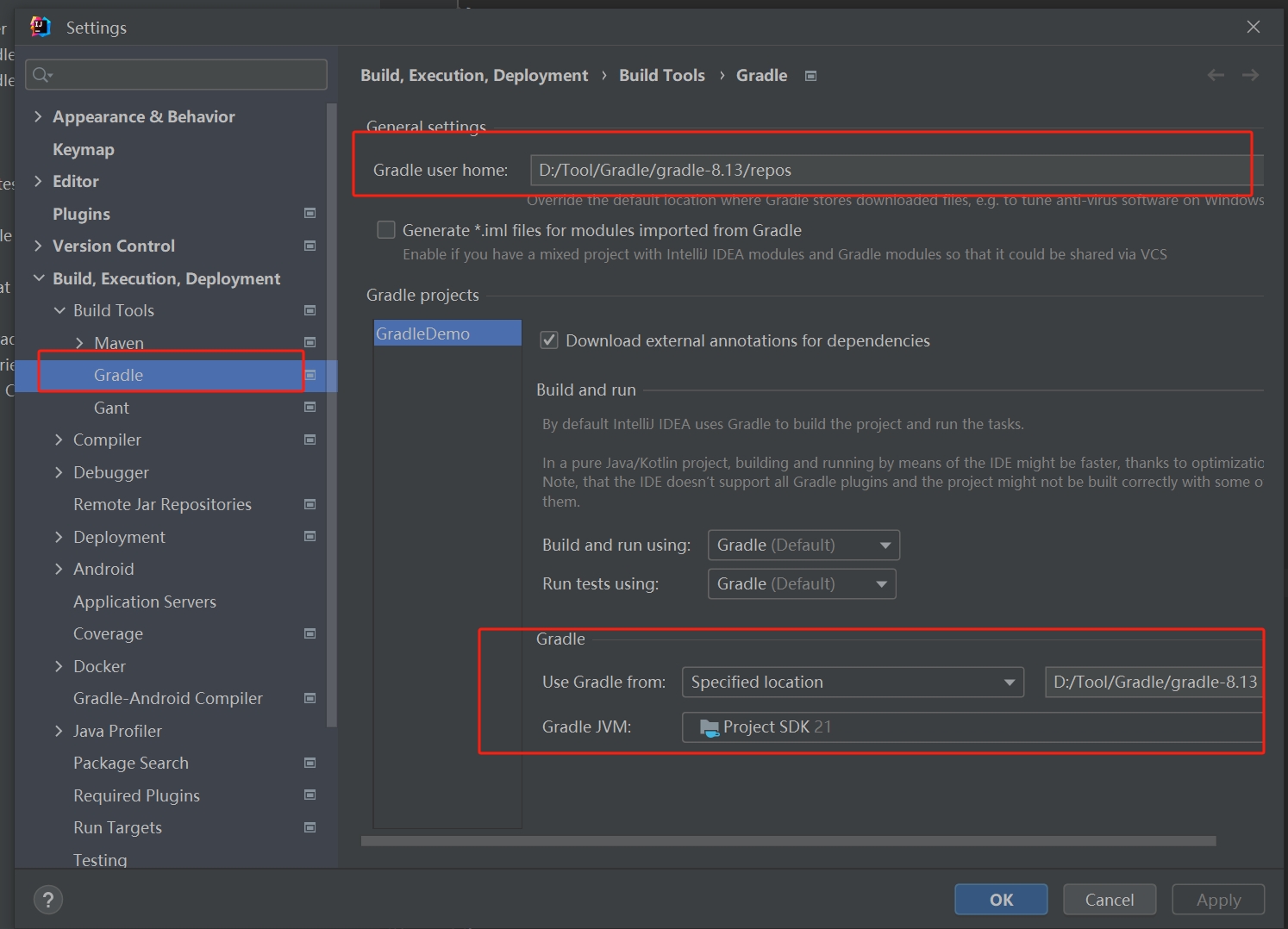
Gradle-基础
一.安装 1. 2.配置环境变量 GRADLE_HOME D:\gradle\gradle-5.6.4 GRADLE_USER_HOME D:\gradle\localRepository 3.下载源配置 安装目录下的init.d文件夹里创建一个init.gradle文件,下载顺序从上到下,内容࿱…...
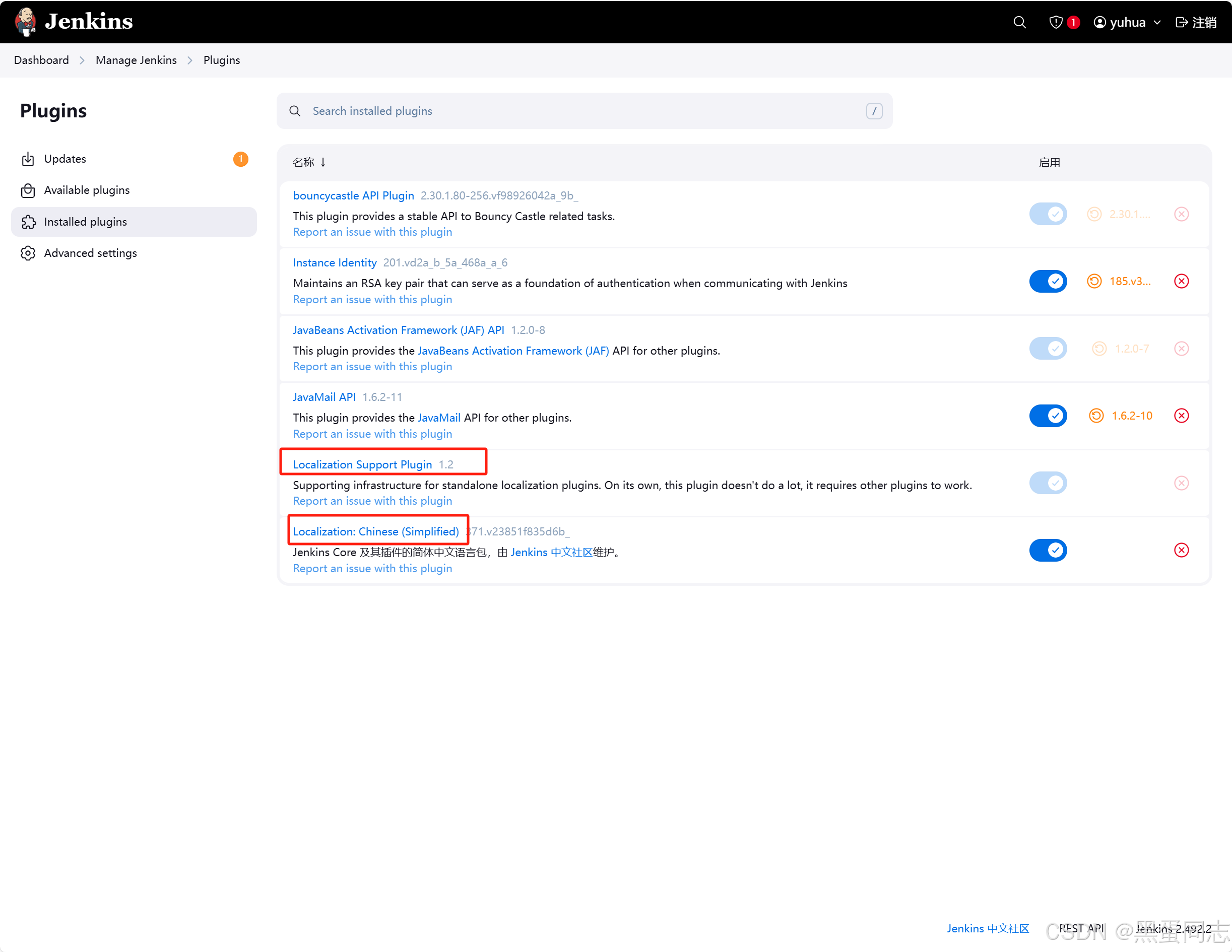
Anolis系统下安装Jenkins
1.安装java、maven yum install -y java-17-openjdk-devel maven git wget 2.配置环境变量 1.查看java和maven所在目录 [rootlocalhost ~]# which java /usr/bin/java [rootlocalhost bin]# ll /usr/bin/java lrwxrwxrwx 1 root root 22 4月 1 17:20 /usr/bin/java ->…...

Python网络爬虫:从入门到实践
目录 什么是网络爬虫? 网络爬虫的工作原理 常用Python爬虫库 编写爬虫的步骤 实战示例 注意事项与道德规范 未来趋势 1. 什么是网络爬虫? 网络爬虫(Web Crawler)是一种自动化程序,通过模拟人类浏览行为&#x…...
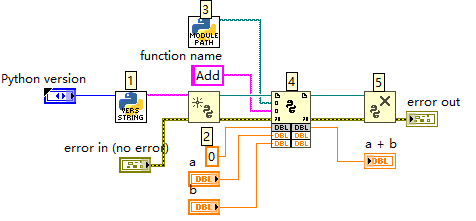
LabVIEW 调用 Python 函数
此程序是 LabVIEW 调用 Python 函数实现双精度数相加的典型示例。通过 LabVIEW 搭建交互框架,借助 “Open Python Session” 创建 Python 代码运行环境,定位 Python 模块路径后调用 “Add” 函数,最终实现数据处理并关闭会话。整个流程展现了…...

视频分析设备平台EasyCVR视频结构化AI智能分析:筑牢校园阳光考场远程监控网
一、背景分析 近年来,学校考试的舞弊现象屡禁不止,严重破坏考试的公平性,不仅损害广大考生的切身利益,也在社会上造成恶劣的影响。为有效制止舞弊行为,收集确凿的舞弊证据,在考场部署一套可靠的视频监控…...
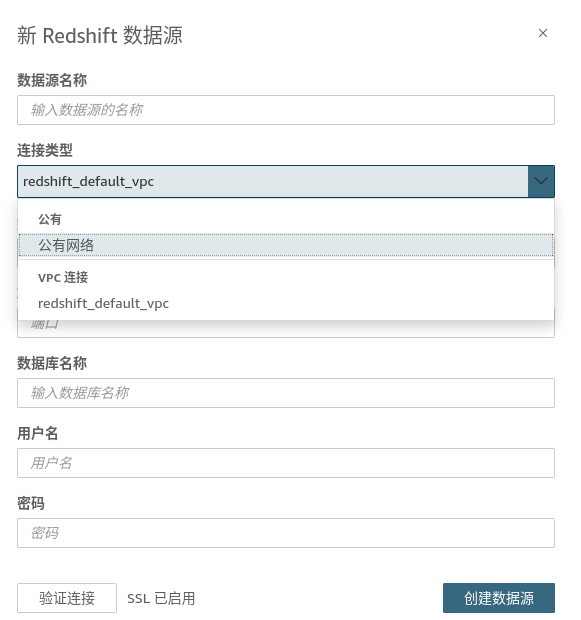
AWS用Glue读取S3文件上传数据到Redshift,再导出到Quicksight完整版,含VPC配置
1. 项目背景 AWS的官方文档,关于Glue和Vpc配置部分已经比较旧了,按照官方文档配置的流程始终跑不通,花了一番时间和波折后,才终于完整的跑通了。 在数据分析和商业智能(BI)领域,我们常需要将存…...

Qt WebSockets使用
Qt WebSockets 是 Qt 官方提供的 WebSocket 协议 实现库,支持全双工通信(客户端/服务端),适用于实时交互应用(如聊天、游戏、实时数据监控)。 1. 核心功能 完整的 WebSocket 协议支持 符合 RFC 6455 标准,支持 ws:// 和 wss://(加密)。 自动处理握手、帧拆分、Ping/…...

Docker学习--容器生命周期管理相关命令--start/stop/restart命令
docker start 命令作用: 启动一个或多个已经创建的容器。 语法: docker start [参数] CONTAINER [CONTAINER…](要操作的容器的名称,可以同时操作多个) 参数解释: -a:附加到容器的标准输入输出…...

dom操作笔记、xml和document等
文章目录 mybatis dom部分 dom(Document Object Model文档对象模型)。 xml和html都属于dom,每天都会用到,一直以为很简单,直到有一天,操作mybatis的xml时候惨不忍睹,被上了一课,做个笔记整理下吧。 xml和ht…...
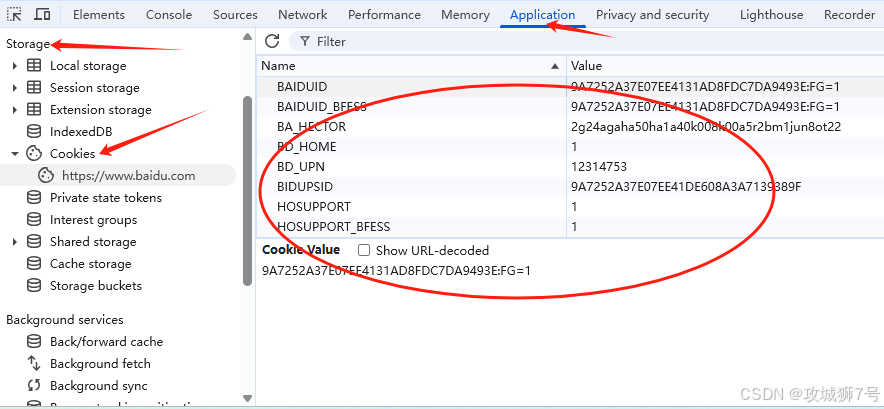
Python爬虫第3节-会话、Cookies及代理的基本原理
目录 一、会话和Cookies 1.1 静态网页和动态网页 1.2 无状态HTTP 1.3 常见误区 二、代理的基本原理 2.1 基本原理 2.2 代理的作用 2.3 爬虫代理 2.4 代理分类 2.5 常见代理设置 一、会话和Cookies 大家在浏览网站过程中,肯定经常遇到需要登录的场景。有些…...
OkHttpHttpClient
学习链接 okhttp github okhttp官方使用文档 SpringBoot 整合okHttp okhttp3用法 Java中常用的HTTP客户端库:OkHttp和HttpClient(包含请求示例代码) 深入浅出 OkHttp 源码解析及应用实践 httpcomponents-client github apache httpclie…...

android设备出厂前 按键测试 快速实现-屏蔽Home,Power等键
android整机测试,需要测试按键。 一般的键好按,好测试。如:音量加 ,音量- 。 但是,有些按键就不好测了。譬如:电源键(Power),Home键,Menu键,Bac…...

Spring Boot3使用Spring AI通过Ollama集成deepseek
文章目录 项目地址版本信息集成步骤 项目地址 DeepSeekSpringAI实战AI家庭医生应用 版本信息 版本Spring Boot3.4.4JDK21spring-ai1.0.0-M6ollama0.6.3LLMdeepseek:14b 集成步骤 引入依赖 <dependency><groupId>org.springframework.ai</groupId><a…...

c++柔性数组、友元、类模版
目录 1、柔性数组: 2、友元函数: 3、静态成员 注意事项 面试题:c/c static的作用? C语言: C: 为什么可以创建出 objx 4、对象与对象之间的关系 5、类模版 1、柔性数组: #define _CRT_SECURE_NO_WARNINGS #…...

win10 快速搭建 lnmp+swoole 环境 ,部署laravel6 与 swoole框架laravel-s项目1
参考文献 1.dnmp环境 https://github.com/yeszao/dnmp 2.laravel6.0文档 https://learnku.com/docs/laravel/6.x 3.laravels 文档 https://github.com/hhxsv5/laravel-s/blob/master/README-CN.md 安装前准备 1.确认已经安装且配置好docker,能在cmd 中运行 docker …...

【Kafka基础】基础概念解析与消息队列对比
1 Kafka 是什么? Kafka是一个 分布式流处理平台,主要用于 高吞吐量、低延迟的实时数据流处理,最初由LinkedIn开发。 核心特点: 高吞吐量:支持每秒百万级消息处理持久化存储:消息可持久化到磁盘,…...