【NLP 面经 5】
难以承受的东西只会让我在下一次更平静的面对
—— 25.4.2
一、NER任务,CRF模型改进
命名实体识别(NER)任务中,你使用基于条件随机场(CRF)的模型,然而模型在识别嵌套实体和重叠实体时效果不佳,并且在处理长文本时性能显著下降。请从模型结构、特征表示和训练优化这三个方面分析可能的原因,并提出相应的改进措施。
模型结构方面
- 原因:
- CRF 局限性:传统 CRF 模型假设标签之间的依赖关系是一阶马尔可夫链,即每个标签只依赖于前一个标签。这种简单的依赖假设在处理嵌套实体和重叠实体时,难以捕捉到复杂的标签关系。例如,当一个实体嵌套在另一个实体内部时,仅考虑一阶依赖无法充分利用实体间的层次结构信息。
- 缺乏层次建模:CRF 模型没有显式地对文本的层次结构进行建模。对于长文本,文本通常具有词、短语、句子等不同层次结构,而简单的 CRF 结构难以有效整合不同层次的信息,导致在长文本中性能下降。
- 改进措施:
- 改进 CRF 结构:引入高阶 CRF,放宽标签之间的依赖假设,使其能捕捉到多个相邻标签之间的关系。例如,二阶 CRF 可以考虑当前标签依赖于前两个标签,这样能更好地处理嵌套实体和重叠实体的复杂标签序列。
- 结合层次化模型:在 CRF 模型前添加层次化的编码结构,如使用递归神经网络(RNN)或卷积神经网络(CNN)对文本进行多层次特征提取。例如,先使用 RNN 对词序列进行编码,捕捉词级别的上下文信息,再通过池化操作得到句子级别的表示,最后将这些多层次特征输入到 CRF 模型中,以提升对长文本的处理能力。
特征表示方面
- 原因:
- 特征单一:如果仅使用词本身的特征(如词向量),可能无法充分表示文本中实体的复杂语义。在识别嵌套和重叠实体时,缺乏能体现实体间关系和层次的特征。例如,对于 “苹果公司发布的 iPhone 手机”,仅靠词向量难以区分 “苹果公司” 和 “iPhone 手机” 之间的嵌套关系。
- 长文本特征丢失:在处理长文本时,简单的特征提取方法可能会丢失远距离的上下文信息。例如,在长文档中,开头部分的信息可能对识别结尾处的实体至关重要,但传统特征提取方法可能无法有效保留和利用这些远距离信息。
- 改进措施:
- 丰富特征集:除词向量外,添加句法特征(如依存句法关系)、语义角色标注特征等。句法特征可以帮助捕捉词与词之间的结构关系,有助于识别嵌套和重叠实体。例如,通过依存关系可以明确 “发布” 这个动作的施事者是 “苹果公司”,受事者是 “iPhone 手机”。同时,利用命名实体类别特征,将已识别出的实体类别信息作为新特征,辅助识别其他相关实体。
- 增强上下文特征:使用基于注意力机制的特征提取方法,如自注意力机制。自注意力机制可以动态地计算每个位置与其他位置之间的关联程度,从而有效捕捉长文本中的远距离上下文信息。例如,在处理长新闻文章时,自注意力机制能让模型关注到文章不同部分与当前识别实体相关的信息,提升长文本中实体识别的准确性。
训练优化方面
- 原因:
- 标注噪声影响:训练数据中的标注错误或噪声会误导模型学习,尤其在处理嵌套和重叠实体时,错误标注可能导致模型对复杂实体关系的学习出现偏差。在长文本中,标注错误可能更难发现和修正,对模型性能影响更大。
- 参数调优不足:CRF 模型有多个参数(如转移矩阵参数、发射矩阵参数),如果这些参数没有得到合理的调优,模型可能无法充分学习到数据中的模式,导致在识别复杂实体和处理长文本时性能不佳。
- 改进措施:
- 数据清洗与增强:对训练数据进行严格的清洗,通过人工复查或使用自动化工具检测和修正标注错误。同时,进行数据增强,如对含有嵌套和重叠实体的样本进行复制和小幅度修改(如同义词替换),增加模型对复杂实体关系的学习机会。对于长文本,可通过数据增强增加长文本样本数量,让模型更好地适应长文本环境。
- 优化参数调优:使用交叉验证和网格搜索、随机搜索等方法对 CRF 模型的参数进行调优。例如,通过在验证集上测试不同的转移矩阵和发射矩阵参数组合,选择能使模型在验证集上性能最佳的参数配置。同时,可以尝试使用更高级的优化算法(如 Adam、Adagrad 等)来加速模型收敛,确保模型能学习到最优的参数。
二、机器阅读理解任务中,预训练模型改进
机器阅读理解任务中,你训练了一个基于预训练语言模型(如 BERT)的模型。但在实际应用中,发现模型对于需要复杂推理和多跳阅读的问题回答准确率较低,并且在处理领域特定文本时泛化能力较差。请从模型架构调整、数据处理优化和训练策略改进这三个方面,分析可能的原因并提出改进措施。
模型架构调整方面
- 原因:
- 预训练模型局限性:虽然 BERT 等预训练语言模型在通用语言理解上表现出色,但它们的架构并非专门为复杂推理和多跳阅读设计。标准的 Transformer 架构在处理多步推理和长距离依赖时存在一定局限,难以在多个文本段落间建立复杂的逻辑联系。
- 缺乏推理模块:模型中没有显式的推理模块来处理需要复杂推理的问题。对于多跳阅读,需要模型能够在不同信息片段间进行综合分析和推导,而预训练模型的简单架构无法很好地支持这种复杂操作。
- 领域适应性不足:预训练模型是在大规模通用语料上训练的,其架构可能无法充分捕捉领域特定文本的独特结构和语义特点,导致在领域特定任务中泛化能力差。
- 改进措施:
- 增强推理能力架构:在模型中引入专门的推理模块,例如基于图神经网络(GNN)的推理层。对于多跳阅读问题,将文本中的实体和句子作为节点,它们之间的语义关系作为边构建图,利用 GNN 在图结构上进行推理,从而更好地处理多步推理和长距离依赖问题。
- 多跳阅读架构优化:设计一种层次化的阅读架构,对于多跳问题,模型可以分阶段处理文本信息。例如,第一阶段定位与问题相关的初步信息,第二阶段基于第一阶段的结果进一步挖掘深层信息,通过这种逐步深入的方式提升多跳阅读能力。
- 领域适配架构调整:针对领域特定文本,在预训练模型基础上添加领域适配层。例如,对于医学领域文本,可以添加医学知识图谱嵌入层,将医学知识融入模型架构,使其更好地适应领域特定的语言模式和语义理解。
数据处理优化方面
- 原因:
- 数据多样性不足:训练数据集中简单问题占比较大,缺乏足够多的复杂推理和多跳阅读问题样本,导致模型对这类问题的学习不充分。同时,领域特定数据量少且缺乏多样性,使得模型难以掌握领域特定的语言表达和知识。
- 数据标注不准确:对于复杂推理和多跳阅读问题,标注难度较大,可能存在标注不准确或不一致的情况。这会误导模型学习,尤其在处理需要精确逻辑推导的问题时,错误标注会严重影响模型性能。在领域特定数据标注中,由于领域知识的专业性,也容易出现标注错误。
- 数据预处理不当:在处理领域特定文本时,通用的预处理方法可能无法有效提取领域相关特征。例如,医学文本中的专业术语和特殊句式,若预处理过程中未进行针对性处理,会导致模型无法充分利用这些信息,影响泛化能力。
- 改进措施:
- 扩充数据多样性:收集更多复杂推理和多跳阅读的问题样本,可从专业竞赛数据集、学术文献等来源获取。对于领域特定数据,增加数据收集渠道,如领域内的专业论坛、报告等,丰富领域数据的多样性。同时,利用数据增强技术,对现有复杂问题和领域特定数据进行变换,生成更多训练样本。
- 提升标注质量:建立严格的标注流程,采用多轮标注和交叉验证的方式,确保标注的准确性和一致性。对于复杂推理问题,邀请领域专家参与标注或对标注结果进行审核。在领域特定数据标注中,加强标注人员的领域知识培训,提高标注质量。
- 优化预处理策略:针对领域特定文本,设计专门的预处理方法。例如,在医学文本预处理中,利用医学词典进行术语识别和规范化处理,对特殊句式进行句法分析和转换,以便模型更好地理解和利用领域特定信息。
训练策略改进方面
- 原因:
- 单任务训练局限:模型采用单一的机器阅读理解任务进行训练,没有充分利用其他相关任务的知识来辅助复杂推理和领域适应性学习。单一任务训练难以让模型学习到更广泛的语言知识和推理技巧。
- 缺乏对抗训练:在训练过程中没有引入对抗训练机制,模型容易受到噪声和对抗样本的影响,尤其是在面对复杂推理和领域特定文本中的噪声数据时,模型的鲁棒性较差。
- 训练目标单一:仅使用传统的问答准确率等单一指标作为训练目标,无法全面衡量模型在复杂推理和领域适应性方面的能力,导致模型优化方向不够全面。
- 改进措施:
- 多任务学习:引入多任务学习策略,除了机器阅读理解任务外,同时训练模型进行相关任务,如文本蕴含、知识图谱补全等。通过多任务学习,模型可以从不同任务中学习到更丰富的语言知识和推理技巧,提升复杂推理能力。在领域特定场景下,结合领域内的其他相关任务,如医学文本中的疾病分类任务,帮助模型更好地适应领域知识。
- 对抗训练:在训练过程中加入对抗训练机制,例如生成对抗网络(GAN)或对抗样本训练。通过对抗训练,模型可以学习到如何抵御噪声和对抗样本的干扰,提高在复杂推理和领域特定文本中的鲁棒性。例如,在训练过程中,生成一些针对复杂推理问题的对抗样本,让模型学习如何正确回答这些具有挑战性的问题。
- 多目标优化:采用多目标优化方法,除了传统的问答准确率外,增加与复杂推理和领域适应性相关的指标作为训练目标,如推理步骤的准确性、领域特定知识的覆盖率等。通过优化多个目标,引导模型在复杂推理和领域适应性方面全面提升性能。
三、文本摘要任务中,Seq2Seq模型改进优化
文本摘要任务中,你使用基于序列到序列(Seq2Seq)模型,并结合注意力机制。然而,生成的摘要存在信息遗漏、重复以及可读性差的问题。请从模型架构、训练数据和生成策略这三个角度,分析产生这些问题的可能原因,并提出相应的改进措施。
模型架构方面
- 原因:
- 编码器 - 解码器结构局限:基本的 Seq2Seq 模型由编码器和解码器组成,编码器将输入文本压缩成固定长度的向量表示,在处理长文本时,这种固定长度的表示可能无法完整保留所有重要信息,导致生成摘要时信息遗漏。
- 注意力机制不足:虽然引入了注意力机制,但可能注意力的计算方式不够完善。例如,简单的注意力机制可能无法准确聚焦到文本中最关键的信息,使得在生成摘要时错过重要内容。此外,注意力机制可能没有充分考虑文本的语义结构,导致生成的摘要逻辑不连贯,可读性差。同时,注意力机制在处理长序列时,可能会出现梯度消失或爆炸问题,影响模型性能。
- 缺乏层次化建模:文本通常具有词、句子、段落等不同层次结构,而模型可能没有对这些层次结构进行有效建模。在生成摘要时,无法区分不同层次信息的重要性,导致信息选择不当,出现信息遗漏或重复的情况。
- 改进措施:
- 改进编码器 - 解码器结构:采用变分自编码器(VAE)或基于 Transformer 的编码器 - 解码器结构。VAE 可以通过引入潜在变量,更灵活地对输入文本进行编码,保留更多信息。基于 Transformer 的结构能够利用自注意力机制更好地处理长序列,避免信息丢失。例如,将输入文本通过多层 Transformer 编码器进行编码,再由 Transformer 解码器生成摘要。
- 优化注意力机制:使用更复杂的注意力机制,如多头注意力机制的变体,增加注意力头的数量或改进注意力分数的计算方式,使其能更准确地捕捉文本中的关键信息。结合位置编码和句法信息来计算注意力权重,以更好地考虑文本的语义结构,增强摘要的逻辑性和可读性。同时,采用层归一化(Layer Normalization)等技术来解决长序列中注意力机制的梯度问题。
- 构建层次化模型:在模型中添加层次化的编码结构,如在词向量层之上,使用卷积神经网络(CNN)或递归神经网络(RNN)对句子进行编码,再通过池化操作得到段落级别的表示。在生成摘要时,根据不同层次的表示来选择和组织信息,优先保留高层级结构中的重要信息,减少信息遗漏和重复。
训练数据方面
- 原因:
- 数据规模和多样性不足:训练数据量较少,模型学习到的语言模式和信息有限,无法涵盖各种文本类型和主题的特点,导致生成的摘要缺乏多样性,容易遗漏重要信息。同时,数据集中不同主题、领域的数据分布不均衡,模型在生成特定主题或领域的摘要时表现较差。
- 数据标注质量问题:摘要标注可能存在主观性和不一致性,不同标注者对同一文本生成的摘要可能存在差异。这种标注的不准确性会误导模型学习,使得生成的摘要出现信息错误、重复或逻辑混乱等问题。
- 缺乏上下文信息:训练数据可能仅包含文本和对应的摘要,没有提供额外的上下文信息,如文本的来源、相关背景知识等。模型在生成摘要时,由于缺乏这些信息,可能无法准确理解文本含义,导致信息遗漏或生成的摘要可读性差。
- 改进措施:
- 扩充数据规模和多样性:收集更多的训练数据,包括不同领域、主题和风格的文本及其摘要。可以从多种来源获取数据,如新闻文章、学术论文、小说等。对数据进行合理的预处理和清洗,确保数据质量。同时,采用数据增强技术,如对文本进行同义词替换、句子重组等操作,增加数据的多样性。
- 提高标注质量:制定明确的摘要标注准则,对标注者进行培训,确保标注的一致性和准确性。采用多轮标注和交叉验证的方式,对标注结果进行审核和修正。可以引入自动评估指标(如 ROUGE 等)辅助标注过程,提高标注质量。
- 添加上下文信息:在训练数据中加入相关的上下文信息,如文本的来源信息、相关的知识图谱或背景知识等。模型在训练过程中可以利用这些额外信息更好地理解文本,从而生成更准确、完整和可读性强的摘要。例如,对于新闻文本,可以添加事件的背景信息和相关报道链接等。
生成策略方面
- 原因:
- 贪心搜索局限:如果采用贪心搜索策略生成摘要,每次只选择概率最高的词,容易陷入局部最优解,导致生成的摘要缺乏多样性,可能会遗漏重要信息,并且可能出现重复内容。因为贪心搜索没有考虑到后续词的选择对整体摘要的影响,只关注当前步骤的最优选择。
- 缺乏摘要结构规划:生成策略没有对摘要的结构进行有效的规划,只是按照顺序逐词生成,没有考虑到摘要应具有的开头、中间和结尾等结构特点,导致生成的摘要逻辑不连贯,可读性差。
- 未考虑语义连贯性:在生成过程中,没有充分考虑生成的词与前文的语义连贯性,使得生成的摘要在语义上出现跳跃或不连贯的情况。例如,生成的相邻句子之间缺乏逻辑联系,影响摘要的整体质量。
- 改进措施:
- 采用束搜索或其他优化策略:用束搜索代替贪心搜索,在每一步生成时保留多个概率较高的候选词(束宽决定候选词数量)。通过综合考虑后续生成步骤,从多个候选路径中选择最优摘要,避免陷入局部最优,提高摘要的多样性和准确性,减少信息遗漏和重复。此外,还可以考虑使用强化学习等方法来优化生成策略,根据生成摘要的质量反馈来调整生成过程。
- 引入摘要结构规划:在生成摘要之前,先对输入文本进行分析,确定摘要的大致结构,如开头部分可以概括文本的主题,中间部分提取关键信息,结尾部分进行总结或给出结论。可以使用基于规则或机器学习的方法来进行结构规划,例如,通过对大量高质量摘要的统计分析,学习不同类型文本摘要的结构模式,然后应用到生成过程中。
- 增强语义连贯性:在生成过程中,利用语言模型的概率分布和语义理解能力,结合注意力机制,确保生成的词与前文在语义上连贯。例如,在计算生成下一个词的概率时,不仅考虑当前词的概率,还考虑该词与前文的语义相关性,通过调整概率分布来生成更连贯的摘要。可以使用预训练的语言模型(如 GPT 系列)来评估生成文本的语义连贯性,并在生成过程中进行优化。
四、 代码题:单词拼接
给定一个字符串列表
words,找出所有可以由列表中其他单词拼接而成的单词。示例 1:
words = ["cat","cats","catsdogcats","dog","dogcatsdog","hippopotamuses","rat","ratcatdogcat"] # 输出: ["catsdogcats", "dogcatsdog", "ratcatdogcat"] # 解释: "catsdogcats" 可以由 "cats", "dog" 和 "cats" 拼接而成; # "dogcatsdog" 可以由 "dog", "cats" 和 "dog" 拼接而成; # "ratcatdogcat" 可以由 "rat", "cat", "dog" 和 "cat" 拼接而成。请实现以下函数:
def findAllConcatenatedWordsInADict(words):# 在此处编写你的代码pass
方法一 暴力遍历求解
算法与思路
对于给定列表 words 中的每个单词 word,尝试将其分割为两个或多个子串。
检查这些子串是否都在单词列表 words 中。如果所有子串都在列表中,那么该单词就是由其他单词拼接而成的。
def findAllConcatenatedWordsInADict(words):res = []word_set = set(words)for word in words:length = len(word)# 从单词的第一个字符开始,尝试将单词分割为前缀和剩余部分。i 表示前缀的长度。for i in range(1, length):# 在 i 的基础上,进一步分割剩余部分为后缀和再剩余部分。j 表示后缀结束的位置。for j in range(i + 1, length + 1):pre = word[:i]suf = word[i:j]rest = word[j:]if pre in word_set and suf in word_set:res.append(word)breakif word in res:breakreturn res方法二 字典树辅助
思路与算法
字典树(Trie)辅助:可以构建一个字典树来存储所有单词,这样在查找某个单词是否能由其他单词拼接而成时,可以高效地进行前缀匹配。
动态规划:对于每个单词,使用动态规划的方法判断它是否能由字典树中的其他单词拼接而成。定义一个布尔数组 dp,dp[i] 表示从单词开头到位置 i 的子串是否能由其他单词拼接而成。通过遍历单词的所有子串,并在字典树中查询子串是否存在,来更新 dp 数组。如果 dp[len(word)] 为 True,则该单词满足要求。
class TrieNode:def __init__(self):self.children = {}self.is_end_of_word = FalseClass Trie:def __init__(self, word):self.root = TrieNode()def insert(self, word)node = self.rootfor char in word:if char not in node.children:node.children[char] = TrieNode()node = node.children[char]node.is_end_of_word = Truedef search(self, word):node = self.rootfor char in word:if char not in node.children:return Falsenode = node.children[char]return node.is_end_of_worddef findAllConcatenatedWordsInADict(words):res = []word_set = set(words)trie = Trie()for word in words:trie.insert(word)def can_form(word):dp = [False] * (len(word) + 1)dp[0] = Truefor i in range(1, len(word) + 1)for j in range(i):if dp[j] and trie.search(word[j:i]):dp[i] = Truebreakreturn dp[-1]for word in words:if can_form(word):res.append(word)return res相关文章:

【NLP 面经 5】
难以承受的东西只会让我在下一次更平静的面对 —— 25.4.2 一、NER任务,CRF模型改进 命名实体识别(NER)任务中,你使用基于条件随机场(CRF)的模型,然而模型在识别嵌套实体和重叠实体时效果不佳&a…...

鸿蒙NEXT小游戏开发:猜小球
1. 引言 “猜小球”是一个经典的益智游戏,通常由一名表演者和多名参与者共同完成。表演者会将一个小球放在一个杯子下面,然后将三个杯子快速地交换位置,参与者则需要猜出最终哪个杯子下面有小球。本文将介绍如何使用HarmonyOS NEXT技术&…...

[NCTF2019]Fake XML cookbook [XXE注入]
题目源代码 function doLogin(){var username $("#username").val();var password $("#password").val();if(username "" || password ""){alert("Please enter the username and password!");return;}var data "…...

Android 防抖和节流
文章目录 Android 防抖和节流概述工具类使用源码下载 Android 防抖和节流 概述 防抖(Debounce): 防抖是指在事件被触发后,等待一段时间,如果在这段时间内没有再触发事件,才执行处理函数。如果在这段时间内…...

安徽京准:NTP时间同步服务器操作使用说明
安徽京准:NTP时间同步服务器操作使用说明 3.1 连接天线 天线连接到“ANT”口。 3.2 连接电源 将220V电源线连到AC220V座上或将电源适配器(7.5V~12V)接到DC口上。也可以同时接上,提高供电可靠性。 3.3 LAN网口 网线连接到NTP…...
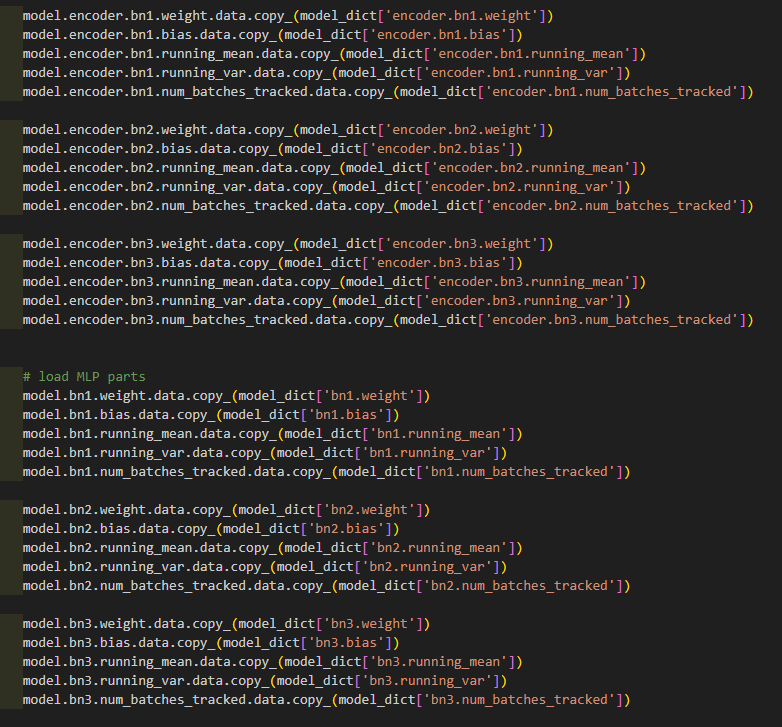
【学习记录】pytorch载入模型的部分参数
需要从PointNet网络框架中提取encoder部分的参数,然后赋予自己的模型。因此,需要从一个已有的.pth文件读取部分参数,加载到自定义模型上面。做了一些尝试,记录如下。 关于模型保存与载入 torch.save(): 使用Python的pickle实用程…...

Ubuntu Wayland启动腾讯会议并实现原生屏幕共享
Intro 众所周知,长期以来,由于腾讯会议项目组的尸位素餐、极度不作为,在Wayland成为Ubuntu 24.04 LTS的默认窗口环境下,仍然选择摆烂,甚至还“贴心”地在启动脚本下增加检测Wayland退出的代码;并且即使使用…...

写Prompt的技巧和基本原则
一.基本原则 1.一定要描述清晰你需要大模型做的事情,不要模棱两可 2.告诉大模型需要它做什么,不需要做什么 改写前: 请帮我推荐一些电影 改写后: 请帮我推荐2025年新出的10部评分比较高的喜剧电影,不要问我个人喜好等其他问题ÿ…...

前端Material-UI面试题及参考答案
目录 Material-UI 的设计理念与 Material Design 规范的关系是什么? 如何通过 npm/yarn/pnpm 安装 Material-UI 的核心依赖? Material-UI 的默认主题系统如何实现全局样式管理? 如何在项目中配置自定义字体和颜色方案? 什么是 emotion 和 styled-components,它们在 Ma…...
)
29、web前端开发之CSS3(六)
13. 多列布局(Multi-column Layout) 多列布局(Multi-column Layout)是一种通过CSS实现的布局方式,允许将内容组织成多列,类似于报纸或杂志的排版方式。这种布局方法能够有效地利用页面空间,提升…...

Go 语言语法精讲:从 Java 开发者的视角全面掌握
《Go 语言语法精讲:从 Java 开发者的视角全面掌握》 一、引言1.1 为什么选择 Go?1.2 适合 Java 开发者的原因1.3 本文目标 二、Go 语言环境搭建2.1 安装 Go2.2 推荐 IDE2.3 第一个 Go 程序 三、Go 语言基础语法3.1 变量与常量3.1.1 声明变量3.1.2 常量定…...
)
MySQL 复制与主从架构(Master-Slave)
MySQL 复制与主从架构(Master-Slave) MySQL 复制与主从架构是数据库高可用和负载均衡的重要手段。通过复制数据到多个从服务器,既可以实现数据冗余备份,又能分担查询压力,提升系统整体性能与容错能力。本文将详细介绍…...

水下成像机理分析
一般情况下, 水下环境泛指浸入到人工水体 (如水库、人工湖等)或自然水体(如海洋、河流、湖 泊、含水层等)中的区域。在水下环境中所拍摄 的图像由于普遍受到光照、波长、水中悬浮颗粒物 等因素的影响,导致生成的水下图像出现模糊、退 化、偏色等现象,图像…...

腾讯云智测试开发面经
1、投递时间线 2.20投递简历,3.11第一轮面试,3.30第二轮面试,4.4第三轮面试,4.10第四轮面试,4.11offer意向书 2、第一轮面试 第一轮面试技术面,面试官是导师,面试时长40多分钟 1)自我介绍 2)数组和列表的区别 3)了解哪些数据库 4)进程和线程的区别 5)了解哪…...

JVM类加载器详解
文章目录 1.类与类加载器2.类加载器加载规则3.JVM 中内置的三个重要类加载器为什么 获取到 ClassLoader 为null就是 BootstrapClassLoader 加载的呢? 4.自定义类加载器什么时候需要自定义类加载器代码示例 5.双亲委派模式类与类加载器双亲委派模型双亲委派模型的执行…...

@ComponentScan注解详解:Spring组件扫描的核心机制
ComponentScan注解详解:Spring组件扫描的核心机制 一、ComponentScan注解概述 ComponentScan是Spring框架中的一个核心注解,用于自动扫描和注册指定包及其子包下的Spring组件。它是Spring实现依赖注入和自动装配的基础机制之一。 Retention(Retention…...

rust Send Sync 以及对象安全和对象不安全
开头:菜鸟小明的疑惑 小明: “李哥,我最近学 Rust,感觉它超级严谨,啥 Send、Sync、对象安全、静态分发、动态分发的,我都搞晕了!为啥 Rust 要设计得这么复杂啊?” 小李࿰…...

从一到无穷大 #44:AWS Glue: Data integration + Catalog
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 引言Glue的历史,设计原则与挑战Serverless ETL 功能设计Glue StudioGlue …...

【Redis】如何处理缓存穿透、击穿、雪崩
Redis 缓存穿透、击穿和雪崩是高并发场景下的典型问题,以下是详细解决方案和最佳实践: 一、缓存穿透(Cache Penetration) 问题:恶意请求不存在的数据(如不存在的ID),绕过缓存直接访…...

区块链技术如何重塑金融衍生品市场?
区块链技术如何重塑金融衍生品市场? 金融衍生品市场一直是全球金融体系的重要组成部分,其复杂性和风险性让许多投资者望而却步。然而,随着区块链技术的兴起,这一领域正在经历一场深刻的变革。区块链以其去中心化、透明和不可篡改…...
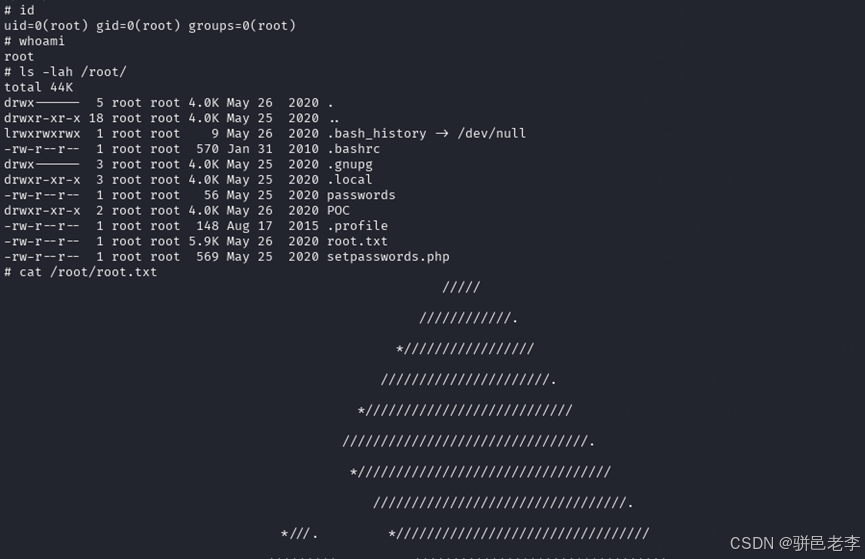
实战打靶集锦-35-GitRoot
文章目录 1. 主机发现2. 端口扫描3. 服务枚举4. 服务探查5. 系统提权6. 写在最后 靶机地址:https://download.vulnhub.com/gitroot/GitRoot.ova 1. 主机发现 目前只知道目标靶机在192.168.56.xx网段,通过如下的命令,看看这个网段上在线的主机…...

Vue3 + Element Plus + AntV X6 实现拖拽树组件
Vue3 Element Plus AntV X6 实现拖拽树组件 介绍 在本篇文章中,我们将介绍如何使用 Vue 3 和 Element Plus 结合 antv/x6 实现树形结构的拖拽功能。用户可以将树节点拖拽到图形区域,自动创建相应的节点。我们将会通过简单的示例来一步步讲解实现过程…...

从零开始跑通3DGS教程:介绍
写在前面 本文内容 本文所属《从零开始跑通3DGS教程》系列文章,将实现从原始图像(有序、无序)数据开始,经过处理(视频抽帧成有序),SFM,3DGS训练、编辑、渲染等步骤,完整地呈现从原始图像到新视角合成的全部流程&#x…...

聊聊Spring AI的Chat Model
序 本文主要研究一下Spring AI的Chat Model Model spring-ai-core/src/main/java/org/springframework/ai/model/Model.java public interface Model<TReq extends ModelRequest<?>, TRes extends ModelResponse<?>> {/*** Executes a method call to …...

将mysql配置成服务的方法
第一步:配置环境变量 1)新建MYSQL_HOME变量,并配置:C:\Program Files\MySQL\MySQL Server 5.6 MYSQL_HOME:C:\Program Files\MySQL\MySQL Server 5.6 2)编辑path系统变量,将%MYSQL_HOME%\bin添加到path变量后。配置path环境变量…...
 存储引擎:ASTORE 与 USTORE 详细对比)
GaussDB(for PostgreSQL) 存储引擎:ASTORE 与 USTORE 详细对比
GaussDB(for PostgreSQL) 存储引擎:ASTORE 与 USTORE 详细对比 1. 背景说明 GaussDB(for PostgreSQL) 是华为基于 PostgreSQL 开发的企业级分布式数据库,其存储引擎分为 ASTORE 和 USTORE 两种类型,分别针对不同场景优化。 2. 核心对比 (1)…...

英语口语 -- 常用 1368 词汇
英语口语 -- 常用 1368 词汇 介绍常用单词List1 (96 个)时间类气候类自然类植物类动物类昆虫类其他生物地点类 List2 (95 个)机构类声音类食品类餐饮类蔬菜类水果类食材类饮料类营养类疾病类房屋类家具类服装类首饰类化妆品类 Lis…...

SpringBoot+Vue 中 WebSocket 的使用
WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议,它使得客户端和服务器之间可以进行实时数据传输,打破了传统 HTTP 协议请求 - 响应模式的限制。 下面我会展示在 SpringBoot Vue 中,使用WebSocket进行前后端通信。 后端 1、引入 j…...
关于依赖注入框架VContainer DIIOC 的学习记录
文章目录 前言一、VContainer核心概念1.DI(Dependency Injection(依赖注入))2.scope(域,作用域) 二、练习例子1.Hello,World!步骤一,编写一个底类。HelloWorldService步骤二,编写使用低类的类。GamePresenter步骤三&am…...

LRU缓存是什么
LRU缓存是什么 LRU(Least Recently Used)即最近最少使用,是一种缓存淘汰策略。在缓存空间有限的情况下,当新的数据需要存入缓存,而缓存已满时,LRU 策略会优先淘汰最近最少使用的数据,以此保证缓存中存储的是最近最常使用的数据。 LRU缓存的工作原理 LRU 缓存的核心思…...