【强化学习】近端策略优化算法(PPO)的理解
本篇博客参考自上海大学刘树林老师的课程。B站课程链接:https://www.bilibili.com/video/BV17t4geUEvQ/?spm_id_from=333.337.search-card.all.click&vd_source=74af336a587568c23a499122c8ffbbee
文章目录
- 传统策略梯度训练面临的问题
- 其他方法的改进
- TRPO算法的贡献
- PPO算法对TRPO的改进
- PPO算法流程
传统策略梯度训练面临的问题

其他方法的改进
TRPO算法的贡献
传统方法容易出现策略网络不稳定的问题,基于这个问题,TRPO算法把两次策略 π \pi π的差异设置到一个很小的邻域内。简单说就是“小步、稳走、达到最优策略”。

下图展示了该优化方法的基本思想。目标函数是 J ( θ ) J(\theta) J(θ),该函数当前的参数是 θ n o w \theta_{now} θnow,该函数很难处理,具体参数/曲线也未知。在 θ n o w \theta_{now} θnow的邻域中,找一条更容易处理的、简单的曲线 L ( θ ∣ θ n o w ) L(\theta|\theta_{now}) L(θ∣θnow)。函数 L ( θ ∣ θ n o w ) L(\theta|\theta_{now}) L(θ∣θnow)和函数 J ( θ ) J(\theta) J(θ)是不一样的,但是在邻域 θ n o w \theta_{now} θnow内,函数 L ( θ ∣ θ n o w ) L(\theta|\theta_{now}) L(θ∣θnow)是可以逼近函数 J ( θ ) J(\theta) J(θ)的。这个阈就被称作置信阈。在这个置信阈中,求曲线 L ( θ ∣ θ n o w ) L(\theta|\theta_{now}) L(θ∣θnow)的最大值,把这个最大值对应的新参数 θ n o w \theta_{now} θnow作为下一个点继续求解。然后再求近似、求最大值…… TRPO借助了这个思想。

下式就是策略梯度定理, A π ( S , A ) A_{\pi}(S,A) Aπ(S,A)是优势函数。关键要解决两个问题:(1)要使得训练前后的两个策略可控;(2)旧策略收集的数据能够被策略网络多次应用以提升策略训练效果。
解决问题(1):对训练前后的两个策略施加约束;
解决问题(2):使用离轨策略。

下图展示了TRPO是如何解决这两个问题的。
(1)把原先的同轨策略改造成离轨策略。把现有的策略 π o l d \pi_{old} πold作为一个旧策略,让旧策略去取数据/和环境互动,把训练的策略 π n e w \pi_{new} πnew作为一个新策略。所以现在即有两个策略网络。把旧策略取到的数据 A π o l d ( S , A ) A_{\pi_{old}}(S,A) Aπold(S,A)来训练新策略,得到新策略的网络参数 θ n e w \theta_{new} θnew。
(2)增加置信阈。利用KL散度进行约束。KL散度是衡量两个概率分布差异的非对称性指标。在信任域策略优化(TRPO)中,使用KL散度限制策略更新的幅度,确保新策略与旧策略的差异不超过阈值 δ \delta δ。

PPO算法对TRPO的改进
用KL散度的目的是使得新策略和旧策略比较接近,但这样做比较麻烦。干脆取一个很小的 ϵ \epsilon ϵ,把新旧策略的比值控制在 [ 1 − ϵ , 1 + ϵ ] [1-\epsilon,1+\epsilon] [1−ϵ,1+ϵ]之间。当比值超过上边界/下边界的时候,强行让比值等于对应的上下边界值。

PPO算法流程

第一模块:采集数据
第1步:将当前策略网络参数作为旧策略网络参数 θ o l d \theta_{old} θold。
第2步:将初始状态 s 0 s_0 s0输入旧网络策略中,由于状态s和动作a均连续,策略网络采用随机高斯策略框架,策略网络的输出为动作a所服从正态分布的均值 μ o l d \mu_{old} μold和标准差 σ o l d \sigma_{old} σold,由此可以得到高斯分布策略函数 π o l d ( a ∣ s , θ o l d ) \pi_{old}(a|s,\theta_{old}) πold(a∣s,θold),然后抽样选择动作: a 0 a_0 a0~ π o l d ( ⋅ ∣ s 0 , θ o l d ) \pi_{old}(·|s_0,\theta_{old}) πold(⋅∣s0,θold),并与环境产生交互,环境给出相应的奖励 r 1 r_1 r1,同时状态更新为 s 1 s_1 s1,上述过程就产生了一个四元组 ( s 0 , a 0 , r 1 , s 1 ) (s_0,a_0,r_1,s_1) (s0,a0,r1,s1)。继续以上循环,可以得到多个四元组 ( s 0 , a 0 , r 1 , s 1 ) (s_0,a_0,r_1,s_1) (s0,a0,r1,s1), ( s 1 , a 1 , r 2 , s 2 ) (s_1,a_1,r_2,s_2) (s1,a1,r2,s2),…,将其储存在经验记忆库中,供训练使用。
第二模块:计算状态价值函数和优势函数
第1步:从经验记忆库中按照时序依次取出四元组 ( s 0 , a 0 , r 1 , s 1 ) (s_0,a_0,r_1,s_1) (s0,a0,r1,s1), ( s 1 , a 1 , r 2 , s 2 ) (s_1,a_1,r_2,s_2) (s1,a1,r2,s2),…,将其依次输入价值网络中,计算
q 0 = V ( s 0 ; w ) 和 q 1 = V ( s 1 ; w ) , . . . q_0 = V(s_0;w) 和 q_1 = V(s_1;w),... q0=V(s0;w)和q1=V(s1;w),...
第2步:计算TD目标
y 0 = r 1 + γ q 1 y_0=r_1+\gamma q_1 y0=r1+γq1
第3步:计算TD误差
δ 0 = q 0 − y 0 \delta_0=q_0-y_0 δ0=q0−y0
第4步:计算优势函数 A t A_t At。优势函数 A t A_t At的引入是为了减小策略梯度中产生的方差,为了达到更好的效果,PPO-Clip算法采用了广义优势估计(GAE)近似优势函数 A t A_t At。
如下图所示,A2C方法用的是下图中的 A t ( 1 ) A_t^{(1)} At(1)进行计算的,这样计算的偏差比较大。 A t ( k ) A_t^{(k)} At(k)类似于蒙特卡洛方法,但它的问题则是方差比较大。为了弥补两个方法的不足,干脆将 A t ( 1 ) A_t^{(1)} At(1)到 A t ( k ) A_t^{(k)} At(k)都算出来,分别求单步时序差分、两步、三步,…,再做平滑,这样就能弥补方差和偏差大的问题。这就是一种广义优势函数。

下图是广义优势估计的定义。这种再次加权,相当于对偏差和方差做出了平衡,这个效果比单用一个优势函数的效果要好得多。

第三模块:更新评估网络
第1步:计算评估网络(价值网络)的损失函数。这里用均方误差MSE(Mean Squared Error,MSE)来定义评估网络的损失函数,公式表示为针对任意时间步 t t t 时刻的预测值 V ( s t ; w ) V(s_t; w) V(st;w)与目标值 r t + 1 + γ V ( s t + 1 ; w ) r_{t+1}+ \gamma V(s_{t+1};w) rt+1+γV(st+1;w) 之间的差异。
L ( w ) = { V ( s t ; w ) − [ r t + 1 + γ V ( S t + 1 ; w ) ] } 2 L(w)= \{V(s_t; w)- [r_{t+1} + \gamma V(S_{t+1}; w)]\}^2 L(w)={V(st;w)−[rt+1+γV(St+1;w)]}2
第2步:针对任意时间步时刻,计算损失函数梯度。
∇ w L ( w ) = 2 { V ( s t ; w ) − [ r t + 1 + γ V ( s t + 1 ; w ) ] } ∇ w V ( s t ; w ) = 2 δ t ∇ w V ( s t ; w ) \nabla_wL(w)=2\{V(s_t;w)-[r_{t+1} + \gamma V(s_{t+1};w)]\} \nabla_w V(s_t; w) = 2 \delta_t \nabla_w V(s_t;w) ∇wL(w)=2{V(st;w)−[rt+1+γV(st+1;w)]}∇wV(st;w)=2δt∇wV(st;w)
第3步:针对任意时间步t时刻,更新评估网络。
w ← w − 2 α δ t ∇ w ( s t ; w ) w←w-2\alpha \delta_t \nabla_w(s_t;w) w←w−2αδt∇w(st;w)
还可以采用小批量更新方法。
第四模块:更新策略网络
第1步:针对所有四元组 ( s , a , r , s ) (s,a,r,s) (s,a,r,s)中的 s s s、 a a a,分别由动作 a a a概率分布的均值 μ o l d \mu_{old} μold和标准差 σ o l d \sigma_{old} σold构造高斯分布旧策略函数(动作概率密度函数) π o l d ( a ∣ s , θ o l d ) \pi_{old}(a|s,\theta_{old}) πold(a∣s,θold),并计算自然对数 l o g π o l d ( a ∣ s , θ o l d ) log \pi_{old}(a|s,\theta_{old}) logπold(a∣s,θold)。
第2步:针对本模块第1步计算出的每个 l o g π o l d ( a ∣ s , θ o l d ) log\pi_{old}(a|s,\theta_{old}) logπold(a∣s,θold),依次单独训练当前网络。
(a)在每次训练中,将四元组 ( s t , a t , r t + 1 , s t + 1 ) (s_t,a_t,r_{t+1},s_{t+1}) (st,at,rt+1,st+1)中的 s t s_t st输入当前策略网络中由动作 a a a,概率分布的均值 μ n e w \mu_{new} μnew和标准差 σ o l d \sigma_{old} σold构造高斯分布新策略函数(动作概率密度函数) π n e w ( a t ∣ s t , θ n e w ) \pi_{new}(a_t|s_t, \theta_{new}) πnew(at∣st,θnew),并计算自然对数 l o g π n e w ( a t ∣ s t , θ n e w ) log\pi_{new}(a_t | s_t,\theta_{new}) logπnew(at∣st,θnew)。

相关文章:
【强化学习】近端策略优化算法(PPO)的理解
本篇博客参考自上海大学刘树林老师的课程。B站课程链接:https://www.bilibili.com/video/BV17t4geUEvQ/?spm_id_from333.337.search-card.all.click&vd_source74af336a587568c23a499122c8ffbbee 文章目录 传统策略梯度训练面临的问题其他方法的改进TRPO算法的贡…...

Java基础 3.30
1.结合练习 /*随机生成10个整数(1-100的范围)保存到数组,并倒序打印以及求平均值、求最大值和最大值的下标,并查找里面是否有8 */ public class ArrayHomework02 {public static void main(String[] args) {int arr[] new int[10];for (int i 0; i &l…...
5.好事多磨 -- TCP网络连接Ⅱ
前言 第4章节通过回声服务示例讲解了TCP服务器端/客户端的实现方法。但这仅是从编程角度的学习,我们尚未详细讨论TCP的工作原理。因此,将详细讲解TCP中必要的理论知识,还将给出第4章节客户端问题的解决方案。 一、回声客户端完美实现 第4章…...

【零基础入门unity游戏开发——2D篇】SpriteMask精灵遮罩组件
考虑到每个人基础可能不一样,且并不是所有人都有同时做2D、3D开发的需求,所以我把 【零基础入门unity游戏开发】 分为成了C#篇、unity通用篇、unity3D篇、unity2D篇。 【C#篇】:主要讲解C#的基础语法,包括变量、数据类型、运算符、…...

Java 枚举类 Key-Value 映射的几种实现方式及最佳实践
Java 枚举类 Key-Value 映射的几种实现方式及最佳实践 前言 在 Java 开发中,枚举(Enum)是一种特殊的类,它能够定义一组固定的常量。在实际应用中,我们经常需要为枚举常量添加额外的属性,并实现 key-value 的映射关系。本文将详细…...

JVM 每个区域分别存储什么数据?
JVM(Java Virtual Machine)的运行时数据区(Runtime Data Areas)被划分为几个不同的区域,每个区域都有其特定的用途和存储的数据类型。以下是 JVM 各个区域存储数据的详细说明: 1. 程序计数器 (Program Cou…...

chromem-go + ollama + bge-m3 进行文档向量嵌入和查询
Ollama 安装 https://ollama.com/download Ollama 运行嵌入模型 bge-m3:latest ollama run bge-m3:latestchromem-go 文档嵌入和查询 package mainimport ("context""fmt""runtime""github.com/philippgille/chromem-go" )func ma…...

PyTorch中卷积层torch.nn.Conv2d
在 PyTorch 中,卷积层主要由 torch.nn.Conv1d、torch.nn.Conv2d 和 torch.nn.Conv3d 实现,分别对应一维、二维和三维卷积操作。以下是详细说明: 1. 二维卷积 (Conv2d) - 最常用 import torch.nn as nn# 基本参数 conv nn.Conv2d(in_channe…...
GO语言学习(16)Gin后端框架
目录 ☀️前言 1.什么是前端?什么是后端?🌀 2.Gin框架介绍 🌷 3.Gin框架的基本使用 -Hello,World例子🌷 🌿入门示例 - Hello,World 💻补充(一些常用的网…...

RAG 在 AI 助手、法律分析、医学 NLP 领域的实战案例
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索和生成模型的技术,广泛应用于 AI 助手、法律分析、医学 NLP 等领域。 以下是具体的实战案例和技术实现。 1. AI 助手中的 RAG 应用 案例 1:企业…...

大模型-提示词(Prompt)技巧
1、什么是提示词? 提示词(Prompt)是用户发送给大语言模型的问题、指令或请求,用来明确地告诉模型用户想要解决的问题或完成的任务,是大语言模型理解用户需求并据此生成相关、准确回答或内容的基础。对于大语言模型来说…...

RNN模型与NLP应用——(9/9)Self-Attention(自注意力机制)
声明: 本文基于哔站博主【Shusenwang】的视频课程【RNN模型及NLP应用】,结合自身的理解所作,旨在帮助大家了解学习NLP自然语言处理基础知识。配合着视频课程学习效果更佳。 材料来源:【Shusenwang】的视频课程【RNN模型及NLP应用…...

硬件与软件的边界-从单片机到linux的问答详解
硬件与软件的边界——从单片机到 Linux 设备驱动的问答详解 在嵌入式开发和操作系统领域,经常会有人问: “如果一个设备里没有任何代码,硬件是不是依然会工作?例如,数据收发、寄存器数据存储、甚至中断触发ÿ…...

5.实现 Channel 类,Reactor 模式初步形成
目录 由联合体epoll_data引出类Channel 结构体epoll_data_t Channel类 Channel类的使用 Epoll类的改变 由联合体epoll_data引出类Channel 在之前使用epoll时,有使用到一个结构体epoll_event // 这是联合体,多个变量共用同一块内存 typedef union…...
深度剖析:U盘打不开难题与应对之策
一、引言 在数字化办公与数据存储的浪潮中,U盘凭借其小巧便携、大容量存储等优势,成为了人们日常数据传输与备份的得力助手。然而,当我们急需调用U盘中的关键数据时,却常常遭遇U盘打不开的棘手状况。U盘打不开不仅会影响工作进度&…...

洛谷题单3-P5721 【深基4.例6】数字直角三角形-python-流程图重构
题目描述 给出 n n n,请输出一个直角边长度是 n n n 的数字直角三角形。所有数字都是 2 2 2 位组成的,如果没有 2 2 2 位则加上前导 0 0 0。 输入格式 输入一个正整数 n n n。 输出格式 输出如题目要求的数字直角三角形。 输入输出样例 输入…...

一起学大语言模型-通过ollama搭建本地大语言模型服务
文章目录 Ollama的github地址链接安装下载需求配置更改安装目录安装更改下载的模型存储位置Ollama一些目录说明日志目录 运行一个模型测试下测试下更改服务监听地址和端口号 Ollama的github地址链接 https://github.com/ollama/ollama 安装 下载 mac安装包下载地址࿱…...

AllData数据中台商业版发布版本1.2.9相关白皮书发布
文章末尾网盘链接获取白皮书,本资源通过星球社群不定时更新,加入星球后,请联系市场同事获取相关知识星球社群信息。 一、总体介绍 主要介绍了AllData商业版产品的整体情况,包括产品定位、核心优势、灵活性和扩展性等,已有150个客户使用,社区发展良好。同时,详细解析了…...

uni-app 框架 调用蓝牙,获取 iBeacon 定位信标的数据,实现室内定位场景
背景:最近需要对接了一个 叫 iBeacon 定位信标 硬件设备,这个设备主要的作用是,在信号不好的地方,或者室内实现定位,准确的找到某个东西。就比如 地下停车场,商城里,我们想知道这个停车场的某个…...

leetcode-热题100(3)
leetcode-74-搜索二维矩阵 矩阵最后一列升序排序,在最后一列中查找第一个大于等于target的元素 然后在该元素所在行进行二分查找 bool searchMatrix(int** matrix, int matrixSize, int* matrixColSize, int target) {int n matrixSize;int m matrixColSize[0];in…...

汇编学习结语
一天之内挑战计划太乐观了, 不过还好,这次我总共用了三天完成了系列汇编指令的学习,有的指令也深入进行了验证,输出了系列文章,收获颇多。 接下来我将开启一个专栏,用于记录学习OllyDbg的使用。 OllyDbg使用…...

C++ I/O 流通俗指南
1. std::ostream 是什么? 定义:std::ostream 是 C 标准库中的输出流类,负责将数据输出到各种目标(如屏幕、文件、网络等)。你可以把 std::ostream 想象成一根“数据水管”: 数据从 C 代码流进 std::ostrea…...
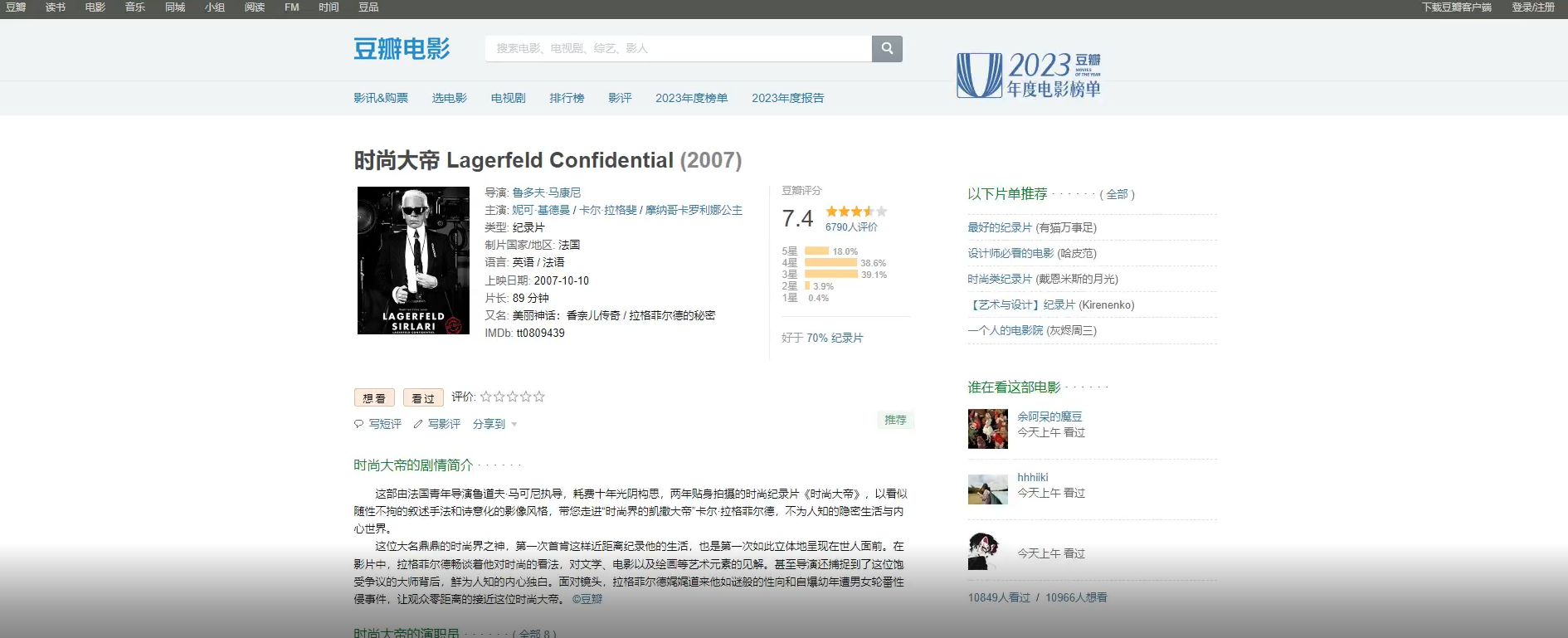
基于python的电影数据分析及可视化系统
一、项目背景 随着电影行业的快速发展,电影数据日益丰富,如何有效地分析和可视化这些数据成为行业内的一个重要课题。本系统旨在利用Python编程语言,结合数据分析与可视化技术,为电影行业从业者、研究者及爱好者提供一个便捷的电…...

【NLP 面经 5】
难以承受的东西只会让我在下一次更平静的面对 —— 25.4.2 一、NER任务,CRF模型改进 命名实体识别(NER)任务中,你使用基于条件随机场(CRF)的模型,然而模型在识别嵌套实体和重叠实体时效果不佳&a…...

鸿蒙NEXT小游戏开发:猜小球
1. 引言 “猜小球”是一个经典的益智游戏,通常由一名表演者和多名参与者共同完成。表演者会将一个小球放在一个杯子下面,然后将三个杯子快速地交换位置,参与者则需要猜出最终哪个杯子下面有小球。本文将介绍如何使用HarmonyOS NEXT技术&…...

[NCTF2019]Fake XML cookbook [XXE注入]
题目源代码 function doLogin(){var username $("#username").val();var password $("#password").val();if(username "" || password ""){alert("Please enter the username and password!");return;}var data "…...

Android 防抖和节流
文章目录 Android 防抖和节流概述工具类使用源码下载 Android 防抖和节流 概述 防抖(Debounce): 防抖是指在事件被触发后,等待一段时间,如果在这段时间内没有再触发事件,才执行处理函数。如果在这段时间内…...

安徽京准:NTP时间同步服务器操作使用说明
安徽京准:NTP时间同步服务器操作使用说明 3.1 连接天线 天线连接到“ANT”口。 3.2 连接电源 将220V电源线连到AC220V座上或将电源适配器(7.5V~12V)接到DC口上。也可以同时接上,提高供电可靠性。 3.3 LAN网口 网线连接到NTP…...
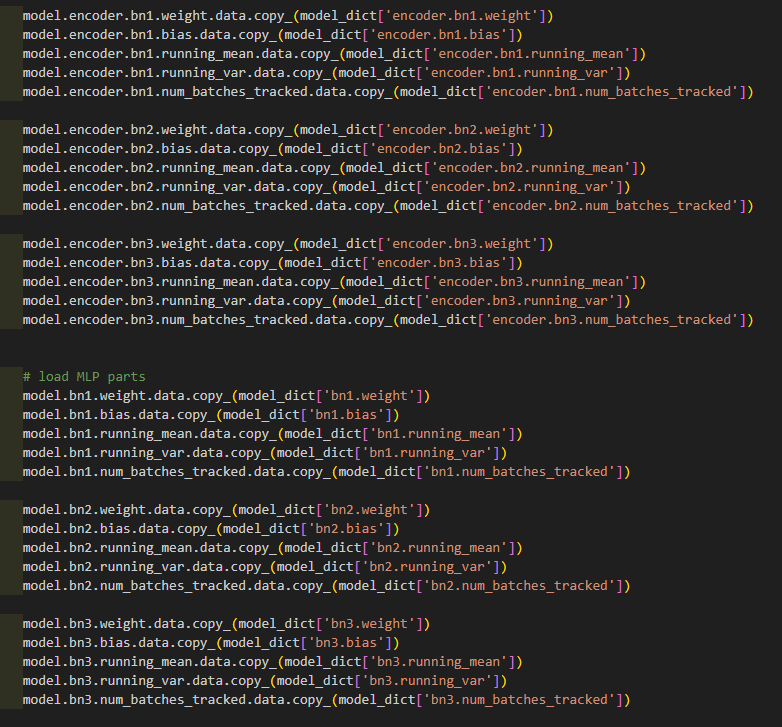
【学习记录】pytorch载入模型的部分参数
需要从PointNet网络框架中提取encoder部分的参数,然后赋予自己的模型。因此,需要从一个已有的.pth文件读取部分参数,加载到自定义模型上面。做了一些尝试,记录如下。 关于模型保存与载入 torch.save(): 使用Python的pickle实用程…...

Ubuntu Wayland启动腾讯会议并实现原生屏幕共享
Intro 众所周知,长期以来,由于腾讯会议项目组的尸位素餐、极度不作为,在Wayland成为Ubuntu 24.04 LTS的默认窗口环境下,仍然选择摆烂,甚至还“贴心”地在启动脚本下增加检测Wayland退出的代码;并且即使使用…...