【diffusers 进阶(十五)】dataset 工具,Parquet和Arrow 数据文件格式,load dataset 方法
系列文章目录
- 【diffusers 极速入门(一)】pipeline 实际调用的是什么? call 方法!
- 【diffusers 极速入门(二)】如何得到扩散去噪的中间结果?Pipeline callbacks 管道回调函数
- 【diffusers极速入门(三)】生成的图像尺寸与 UNet 和 VAE 之间的关系
- 【diffusers极速入门(四)】EMA 操作是什么?
- 【diffusers极速入门(五)】扩散模型中的 Scheduler(noise_scheduler)的作用是什么?
- 【diffusers极速入门(六)】缓存梯度和自动放缩学习率以及代码详解
- 【diffusers极速入门(七)】Classifier-Free Guidance (CFG)直观理解以及对应代码
- 【diffusers极速入门(八)】GPU 显存节省(减少内存使用)技巧总结
- 【diffusers极速入门(九)】GPU 显存节省(减少内存使用)代码总结
- 【diffusers极速入门(十)】Flux-pipe 推理,完美利用任何显存大小,GPU显存节省终极方案(附代码)
- 【diffusers 进阶(十一)】Lora 具体是怎么加入模型的(推理代码篇上)OminiControl
- 【diffusers 进阶(十二)】Lora 具体是怎么加入模型的(推理代码篇下)OminiControl
- 【diffusers 进阶(十三)】AdaLayerNormZero 与 AdaLayerNormZeroSingle 代码详细分析
- 【diffusers 进阶(十四)】权重读取,查看 Lora 具体加在哪里和 Rank ‘秩’ 是多少?以 OminiControl 为例
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系列文章目录
- load_dataset
- Parquet
- Arrow
- 二者详细对比
- 1.核心特性对比
- 2.应用场景差异
- 3.性能对比
- 4. Hugging Face生态中的使用
- 5. 选择建议
load_dataset
Parquet
Parquet文件采用列式存储格式,与CSV等行式文件不同。由于效率更高且查询响应更快,大型数据集通常存储为Parquet格式。
加载Parquet文件:
from datasets import load_dataset
dataset = load_dataset("parquet", data_files={'train': 'train.parquet', 'test': 'test.parquet'})
通过HTTP加载远程Parquet文件:
base_url = "https://huggingface.co/datasets/wikimedia/wikipedia/resolve/main/20231101.ab/"
data_files = {"train": base_url + "train-00000-of-00001.parquet"}
wiki = load_dataset("parquet", data_files=data_files, split="train")
Arrow
Arrow文件采用内存列式存储格式,与CSV等行式格式和未压缩的Parquet格式不同。
加载Arrow文件:
from datasets import load_dataset
dataset = load_dataset("arrow", data_files={'train': 'train.arrow', 'test': 'test.arrow'})
通过HTTP加载远程Arrow文件:
base_url = "https://huggingface.co/datasets/croissantllm/croissant_dataset/resolve/main/english_660B_11/"
data_files = {"train": base_url + "train/data-00000-of-00080.arrow"}
wiki = load_dataset("arrow", data_files=data_files, split="train")
总结:
- 文件格式特点:
- Parquet:磁盘列式存储,适合大规模数据存储和高效查询
- Arrow:内存列式存储,适合快速内存处理(需注意内存容量限制)
- 加载方式:
- 本地文件:指定data_files参数(支持多文件拆分)
- 远程文件:直接传入HTTP/HTTPS URL
- 通用接口:统一使用datasets.load_dataset(),通过格式参数区分
- 应用场景:
- Parquet:数据仓库、离线分析、大规模数据存储
- Arrow:内存计算、实时处理、跨进程数据传递
- 技术优势:
- 列式存储:提升分析查询效率,降低I/O开销
- 压缩优化:Parquet支持多种压缩算法
- 类型保留:保持原始数据类型(如日期、嵌套结构)
- 元数据管理:自动读取文件元信息
二者详细对比
以下是Parquet和Arrow两种数据格式的详细对比分析:
1.核心特性对比
| 特性 | Parquet | Arrow |
|---|---|---|
| 存储介质 | 磁盘存储(适合持久化存储) | 内存存储(适合内存计算与跨进程传输) |
| 存储结构 | 列式存储,支持分块与压缩 | 列式存储,内存友好型二进制格式 |
| 压缩方式 | 支持Snappy、Gzip、Brotli等压缩算法 | 不压缩(需结合Parquet或其他压缩层) |
| 数据类型 | 支持复杂类型(嵌套结构、日期等) | 支持更广泛的数据类型(如字典、列表等) |
| 元数据管理 | 自动记录统计信息(如最小值、最大值) | 包含完整的Schema定义和内存布局信息 |
2.应用场景差异
Parquet:
- 离线分析:适合数据仓库、日志分析等需要频繁查询特定列的场景。
- 大规模数据存储:通过列式压缩减少存储空间,支持高效的查询过滤。
- 跨平台兼容性:与Spark、Pandas等工具深度集成,便于多框架处理。
Arrow:
- 内存计算:在内存密集型任务(如机器学习预处理)中提供快速访问。
- 实时处理:支持零拷贝数据传输,适合微服务间高效通信。
- 跨语言支持:通过Arrow Flight协议实现不同语言间的数据共享。
3.性能对比
| 场景 | Parquet | Arrow |
|---|---|---|
| 磁盘读取 | 高(列式存储减少I/O量) | 不适用(需配合Parquet) |
| 内存访问 | 低(需加载到内存后处理) | 极高(直接内存访问) |
| 压缩效率 | 高(可选压缩算法) | 无(需结合其他格式) |
| 序列化速度 | 较慢(需解析文件结构) | 极快(内存直接序列化) |
4. Hugging Face生态中的使用
- 分布式加载:
# Parquet分布式分片 dataset = load_dataset("parquet", data_files="s3://bucket/*.parquet", split="train")# Arrow内存共享 dataset = load_dataset("arrow", data_files="local/*.arrow", split="train") - 类型保留:
- Parquet:自动推断日期、嵌套结构等复杂类型。
- Arrow:精确保留原始数据类型(如Python的datetime对象)。
- 性能优化:
- 使用
dataset.set_format("arrow")将数据转为Arrow格式以加速内存操作。
- 使用
5. 选择建议
- 选Parquet:当需要持久化存储、跨工具协作或处理PB级数据时。
- 选Arrow:当需要内存快速处理、实时分析或跨语言数据传递时。
- 组合使用:将数据存储为Parquet,加载到内存后转为Arrow格式进行计算。
相关文章:
】dataset 工具,Parquet和Arrow 数据文件格式,load dataset 方法)
【diffusers 进阶(十五)】dataset 工具,Parquet和Arrow 数据文件格式,load dataset 方法
系列文章目录 【diffusers 极速入门(一)】pipeline 实际调用的是什么? call 方法!【diffusers 极速入门(二)】如何得到扩散去噪的中间结果?Pipeline callbacks 管道回调函数【diffusers极速入门࿰…...
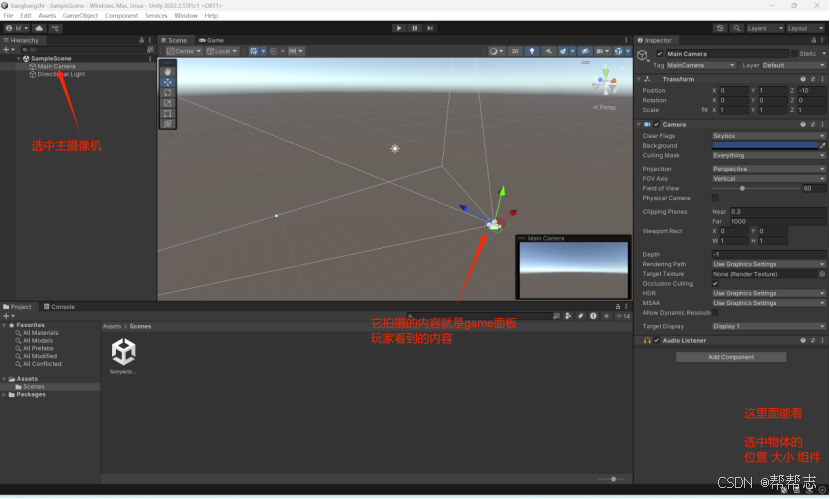
unity各个面板说明
游戏开发,unity各个面板说明 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是Python基础语法。前后每一小节的内容是存在的有:学习and理解的关联性,希望对您有用~ unity简介-unity基础…...

游戏引擎学习第199天
回顾并发现我们可能破坏了某些东西 目前,我们的调试 UI 运行得相对顺利,可以创建可修改的调试变量,也可以插入分析器(profiler)等特殊视图组件,并进行一些交互操作。然而,在上一次结束时&#…...

Linux红帽:RHCSA认证知识讲解(十)使用 tar创建归档和压缩文件
Linux红帽:RHCSA认证知识讲解(十)使用 tar创建归档和压缩文件 前言一、归档与压缩的基本概念1.1 归档与压缩的区别 二、使用tar创建归档文件2.1 tar命令格式2.2 示例操作 三、使用tar进行压缩3.2 命令格式3.3 示例操作 前言 在红帽 Linux 系…...
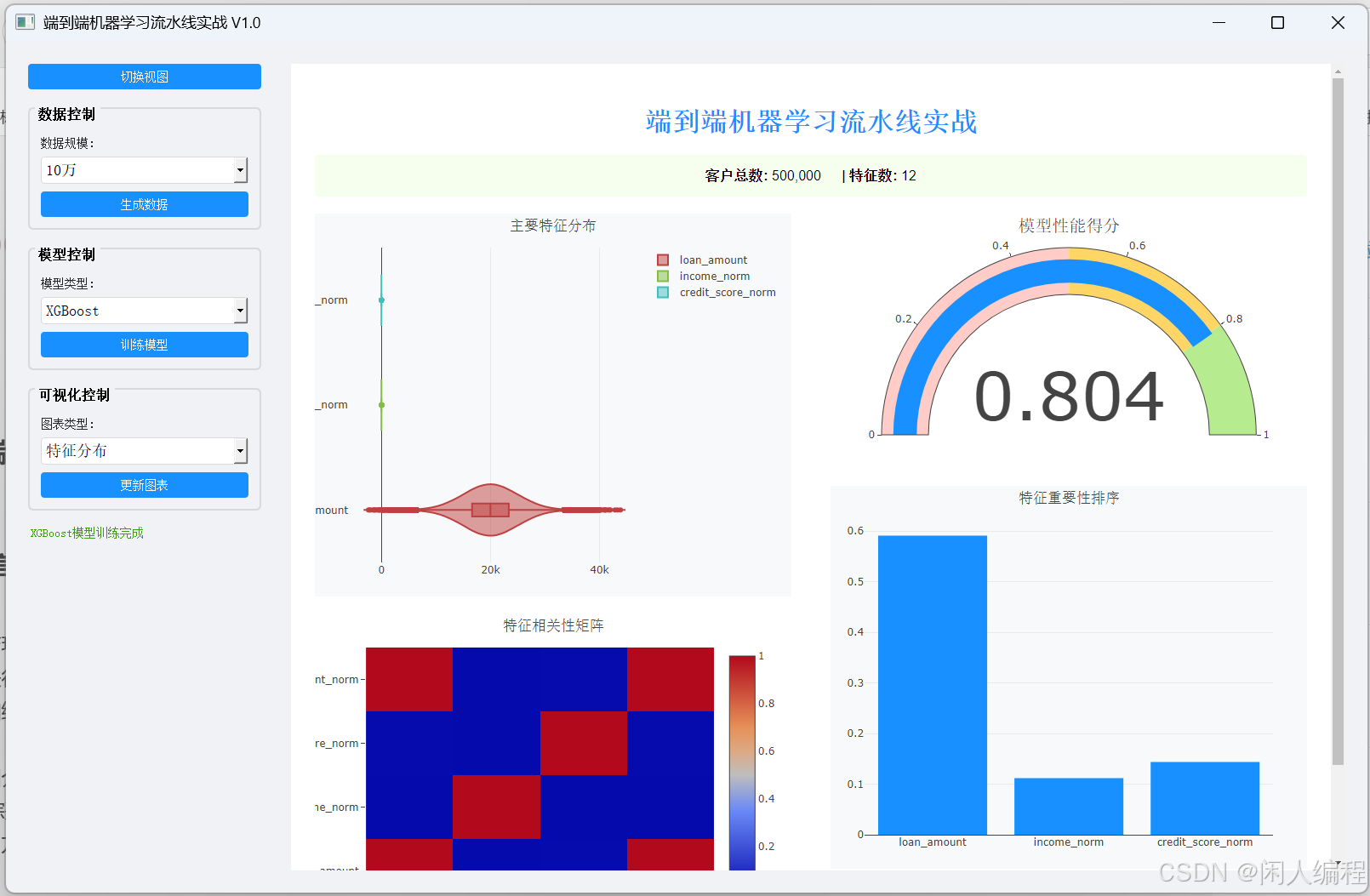
端到端机器学习流水线(MLflow跟踪实验)
目录 端到端机器学习流水线(MLflow跟踪实验)1. 引言2. 项目背景与意义2.1 端到端机器学习流水线的重要性2.2 MLflow的作用2.3 工业级数据处理需求3. 数据集生成与介绍3.1 数据集构成3.2 数据生成方法4. 机器学习流水线与MLflow跟踪4.1 端到端机器学习流水线4.2 MLflow跟踪实验…...

相平面案例分析爱情故事
动态系统的分析可以分为三个步骤:第一步描述系统,通过语言来描述系统的特性,第一步描述系统,即通过语言来描述系统的特性;第二步数学分析,即使用数学工具对系统进行量化解析;第三步结果与讨论&a…...

《2024年全球DDoS攻击态势分析》
从攻击态势来看,2024年DDoS攻击频次继续呈增长趋势,2024年同步增加1.3倍;超大规模攻击激增,超800Gbps同比增长3.1倍,累计高达771次,且互联网史上最大带宽和最大包速率攻击均被刷新;瞬时泛洪攻击…...

RTC实时时钟M41T11M6F国产替代FRTC4111S
由NYFEA徕飞公司制造的FRTC4111S是一种低功耗的串行实时时钟(RTC),国产直接替代ST的M41T11M6F,其具有56字节的NVRAM,32.768 kHz振荡器(由外部晶体控制)和RAM的前8字节用于时钟/日历功能并以二进制编码十进制(BCD)格式配置。地址和数据通过两行双向总线串…...
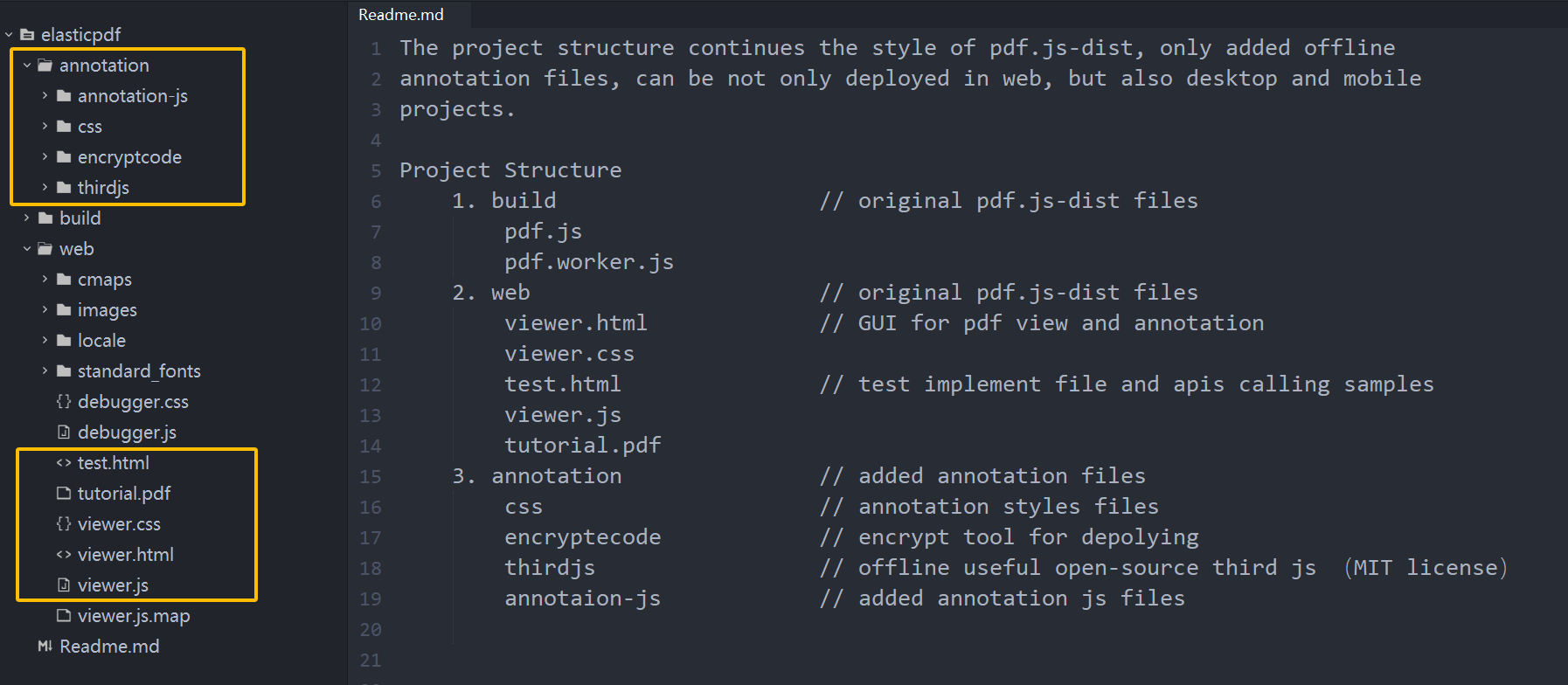
Uni-app PDF Annotation plugin library online API examples
This article introduces the online version of the ElasticPDF API tutorial for the PDF annotation plug-in library in Uni-app projects. The API includes ① Export edited PDF data; ② Export annotations json data; ③ Reload old annotations; ④ Change files; ⑤…...

SpringKafka消息发布:KafkaTemplate与事务支持
文章目录 引言一、KafkaTemplate基础二、消息序列化三、事务支持机制四、错误处理与重试五、性能优化总结 引言 在现代分布式系统架构中,Apache Kafka作为高吞吐量的消息系统,被广泛应用于事件驱动应用开发。Spring Kafka为Java开发者提供了与Kafka交互…...

进行性核上性麻痹护理指南,助患者安稳生活
生活细致照料 安全保障:进行性核上性麻痹患者易出现平衡障碍、步态不稳,居家环境需格外留意安全。移除地面障碍物,保持通道畅通,在卫生间、走廊安装扶手,防止患者摔倒受伤。 饮食协助:患者常伴有吞咽困难&…...
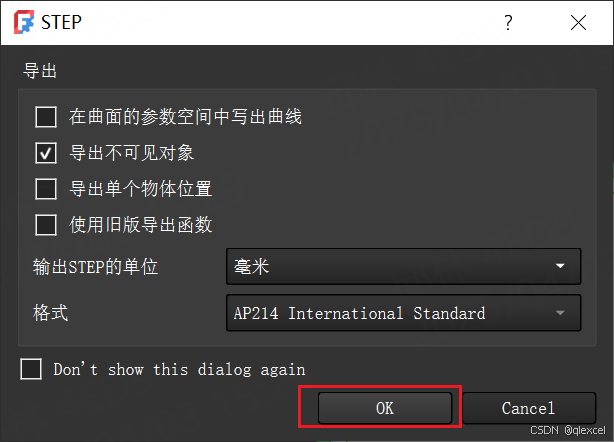
提取嘉立创3D封装
嘉立创上元器件基本都有3D封装,当用AD或其他软件画PCB时,需要用到的3D封装可以从嘉立创EDA中提取。 首先新建工程,然后放置要提取3D封装的器件 导出-》3D文件 因为导出的文件中包含器件的3D封装和PCB板,需要把PCB板删除才能使用…...

工作记录 2017-03-24
工作记录 2017-03-24 序号 工作 相关人员 1 修改了邮件上的问题。 更新RD服务器。 郝 更新的问题 1、修改了New User时 init的保存。 2、文件的查询加了ID。 3、加了 patient insurance secondary 4、修改了payment detail的处理。 识别引擎监控 Ps (iCDA LOG :剔除…...
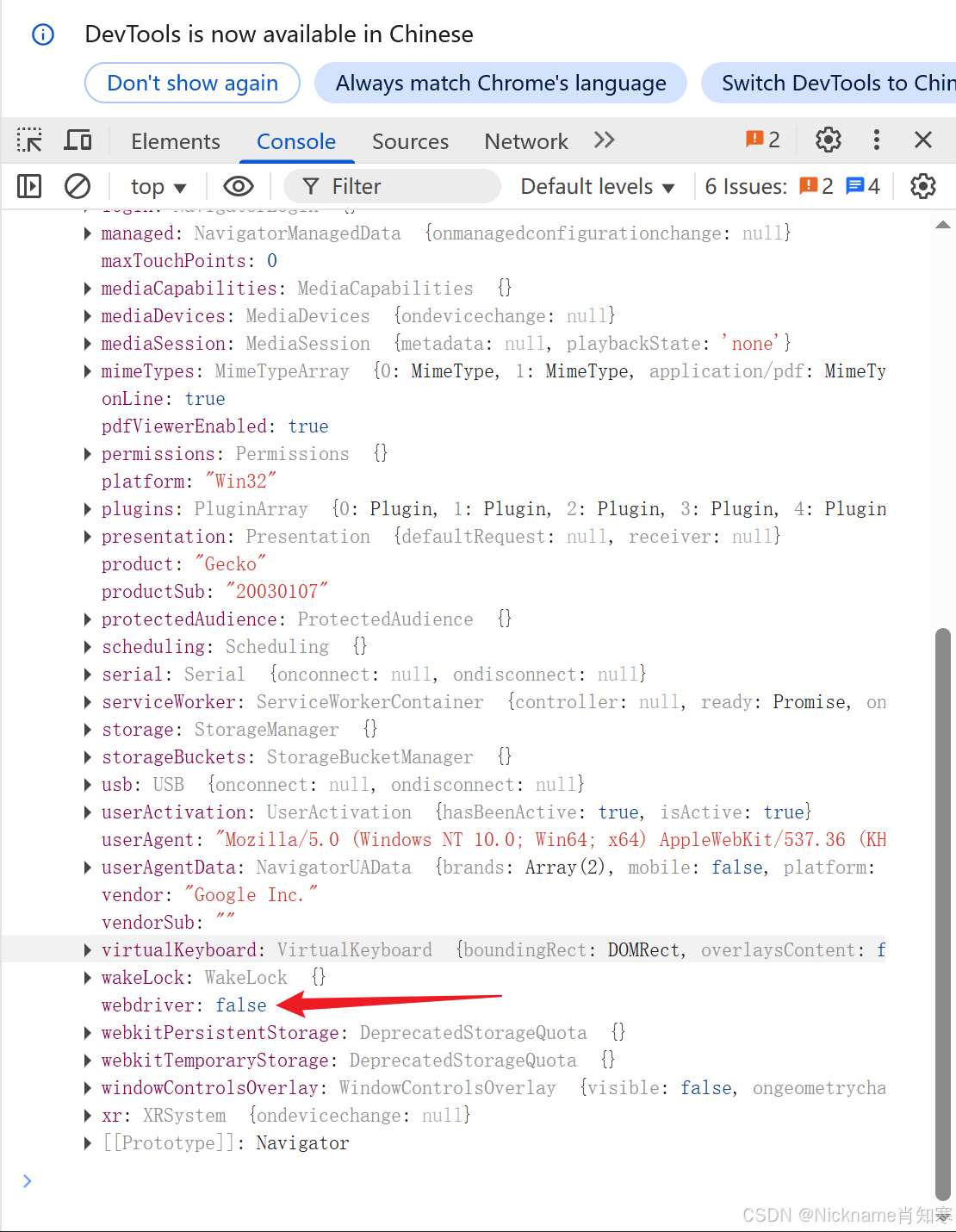
chromium魔改——修改 navigator.webdriver 检测
chromium源码官网 https://source.chromium.org/chromium/chromium/src 说下修改的chromium源码思路: 首先在修改源码过检测之前,我们要知道它是怎么检测的,找到他通过哪个JS的API来做的检测,只有知道了如何检测,我们…...

Qt 信号量使用方法
Qt 信号量使用方法 QSemaphore 类 常用函数介绍 函数名称函数功能QSemaphore()构造并初始化对象acquire()尝试获取n个资源,如果没有那么多资源,线程将阻塞直到有n个资源可用available()返回当前信号量可用的资源个数,这个数永远不可能为负…...

训练或微调以生成新组合结构
能通过训练或者微调,产生其它没有的组合的结构,比如有化学组成和空年组,想要生成指定化学成分指定空间组的结构,以下是针对需求的详细分析与实现思路,同时给出相应的 Python 代码示例。 1. 训练或微调以生成新组合结构…...

【通俗易懂说模型】生成对抗网络·GAN
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀《深度学习理论直觉三十讲》_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目…...
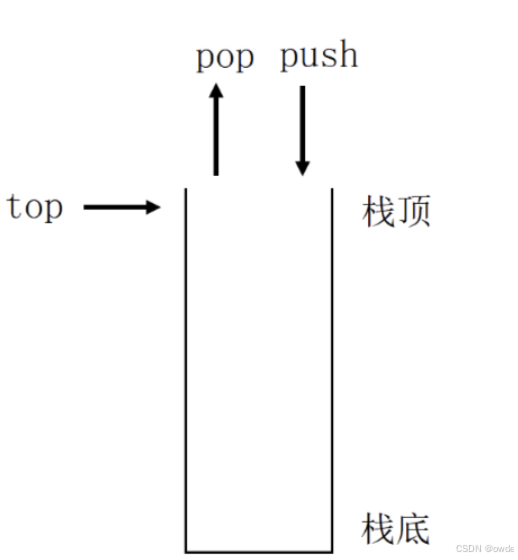
容器适配器-stack栈
C标准库不只是包含了顺序容器,还包含一些为满足特殊需求而设计的容器,它们提供简单的接口。 这些容器可被归类为容器适配器(container adapter),它们是改造别的标准顺序容器,使之满足特殊需求的新容器。 适配器:也称配置器,把一…...

7-6 混合类型数据格式化输入
本题要求编写程序,顺序读入浮点数1、整数、字符、浮点数2,再按照字符、整数、浮点数1、浮点数2的顺序输出。 输入格式: 输入在一行中顺序给出浮点数1、整数、字符、浮点数2,其间以1个空格分隔。 输出格式: 在一行中…...
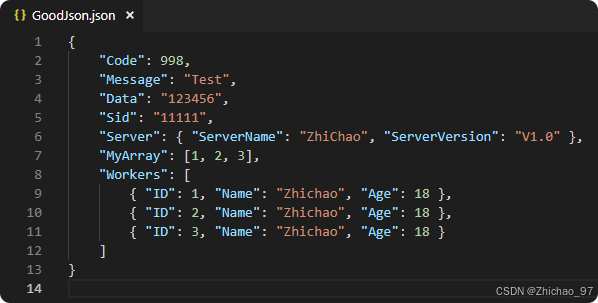
【UE5 C++课程系列笔记】31——创建Json并保存为文件
目录 方式一(不推荐) 方式二(推荐) 一、生成普通Json对象 二、对象嵌套对象 三、对象嵌套数组 四、对象嵌套数组再嵌套对象 方式一(不推荐) 如下代码实现了把JSON字符串保存到文件中 #include &qu…...
Photoshop 2025 Mac中文 Ps图像编辑软件
Photoshop 2025 Mac中文 Ps图像编辑软件 文章目录 Photoshop 2025 Mac中文 Ps图像编辑软件一、介绍二、效果三、下载 一、介绍 Adobe Photoshop 2025 Mac版集成了多种强大的图像编辑、处理和创作功能。①强化了Adobe Sensei AI的应用,通过智能抠图、自动修复、图像…...

linux文件上传下载lrzsz
lrzsz 是一个在 Linux 系统中用于通过串行端口(如 ZMODEM、XMODEM、YMODEM 等协议)进行文件上传和下载的工具集。它通常用于在终端环境中通过串口或 SSH 连接传输文件。 安装 lrzsz 在大多数 Linux 发行版中,你可以使用包管理器来安装 lrzsz。 Debian/Ubuntu: sudo apt-ge…...

MySQL超全笔记
1、初识SQL 什么是数据库 数据库 ( DataBase , 简称DB ) 概念 : 长期存放在计算机内,有组织,可共享的大量数据的集合,是一个数据 “仓库” 作用 : 保存,并能安全管理数据(如:增删改查等),减少冗余… 数据库总览 : 关系型数据库 ( SQL ) MySQL , Oracle , SQL Server , SQ…...

使用Redis构架你自己的私有大模型
使用Redis构架你自己的私有大模型--楼兰 Redis你通常用来做什么?缓存?分布式锁?数据过滤器?不够不够,这远远不够。之前给大家分享过基于Redis Stack提供的一系列插件,完全可以把Redis作为一个类似于Elastic Search的JSON数据库使用。不光可以存储并操作JSON格式的数据…...

2.4路径问题专题:LeeCode 931.下降路径最小和
动态规划解决最小下降路径和问题 1. 题目链接 LeetCode 931. 最小下降路径和 2. 题目描述 给定一个 n x n 的整数矩阵 matrix,找到一条从第一行到最后一行的下降路径,使得路径上的数字和最小。下降路径可以从第一行的任意元素出发,每一步…...

从内核到应用层:Linux缓冲机制与语言缓冲区的协同解析
系列文章目录 文章目录 系列文章目录前言一、缓冲区1.1 示例11.2 缓冲区的概念 二、缓冲区刷新方案三、缓冲区的作用及存储 前言 上篇我们介绍了,文件的重定向操作以及文件描述符的概念,今天我们再来学习一个和文件相关的知识-----------用户缓冲区。 在…...
【AI News | 20250403】每日AI进展
AI Repos 1、llm-server-docs 项目提供了一份基于Debian系统的本地语言模型服务器搭建指南,适用于Linux初学者。教程涵盖驱动安装、GPU功耗设置、自动登录配置及开机自启脚本部署等关键步骤,支持Ollama/vLLM等多种OpenAI兼容方案。方案设计强调四大原则…...
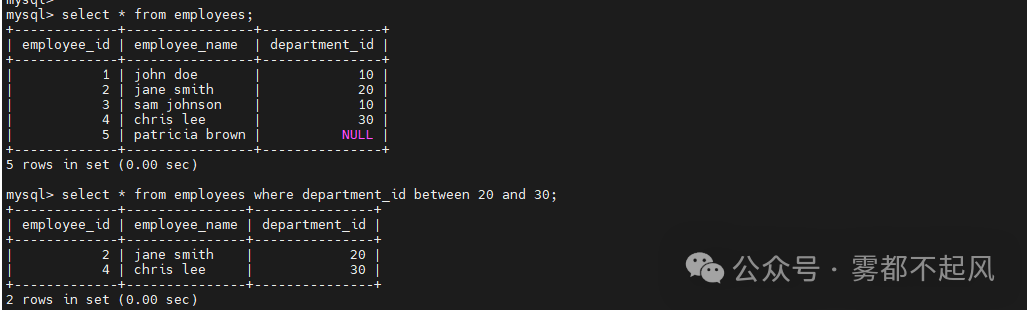
深入理解SQL中的<>运算符:不等于的灵活运用
在SQL的世界里,数据的筛选与查询是最常见的操作之一。在编写查询语句时,比较运算符是我们不可忽视的工具,其中,<> 运算符作为 不等于 的代表,起着至关重要的作用。它不仅能够帮助我们筛选出符合特定条件的数据&a…...
)
单网卡上绑定多个虚拟IP(AI回答)
单网卡绑定多个虚拟IP的实现方法 一、Linux系统配置方案 1. 手动绑定少量IP地址(适用于CentOS/RHEL) 步骤1:进入网络配置目录 cd /etc/sysconfig/network-scripts/步骤2:复制并重命名网卡配置文件 cp ifcfg-eth0 i…...
数据清洗的具体内容
(一)ETL介绍 “ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较…...