训练或微调以生成新组合结构
能通过训练或者微调,产生其它没有的组合的结构,比如有化学组成和空年组,想要生成指定化学成分+指定空间组的结构,以下是针对需求的详细分析与实现思路,同时给出相应的 Python 代码示例。
1. 训练或微调以生成新组合结构
要生成指定化学成分与指定空间组的结构,你可以对 mattergen 模型进行微调。微调的过程一般是在预训练模型的基础上,利用包含目标组合结构的数据集进一步训练模型。
2. 生成模型中未实现的词条
对于像“过电势”这类模型未实现的词条,你可以先进行预训练,再进行微调。预训练能够让模型学习到通用的语言特征,微调则可让模型聚焦于特定的任务。
3. 预训练过程
数据集创建
你需要构建一个包含目标词条与组合结构的数据集。数据集可以是文本文件,每行代表一个样本。
预训练步骤
- 加载预训练模型:加载 mattergen 模型。
- 数据处理:把数据集转换为模型能够接受的格式。
- 训练模型:运用处理后的数据对模型进行训练。
以下是一个简单的 Python 代码示例,用于说明预训练和微调的过程:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
加载预训练模型和分词器
model_name = “your_mattergen_model_name” # 替换为实际的 mattergen 模型名称
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
数据集创建示例
data = [
“指定化学成分1 + 指定空间组1”,
“指定化学成分2 + 指定空间组2”,
“过电势相关描述1”,
“过电势相关描述2”
]
数据处理
def tokenize_function(examples):
return tokenizer(examples[“text”], padding=“max_length”, truncation=True)
tokenized_datasets = tokenize_function({“text”: data})
tokenized_datasets = {k: [v] for k, v in tokenized_datasets.items()}
训练参数设置
training_args = TrainingArguments(
output_dir=‘./results’, # 输出目录
num_train_epochs=3, # 训练轮数
per_device_train_batch_size=16, # 每个设备的训练批次大小
save_steps=10_000, # 每多少步保存一次模型
save_total_limit=2, # 最多保存的模型数量
prediction_loss_only=True,
)
训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets,
)
预训练
trainer.train()
保存预训练后的模型
model.save_pretrained(“./pretrained_model”)
tokenizer.save_pretrained(“./pretrained_model”)
微调示例
假设你有一个微调数据集 fine_tuning_data
fine_tuning_data = [
“微调数据示例1”,
“微调数据示例2”
]
fine_tuning_tokenized_datasets = tokenize_function({“text”: fine_tuning_data})
fine_tuning_tokenized_datasets = {k: [v] for k, v in fine_tuning_tokenized_datasets.items()}
微调训练器
fine_tuning_trainer = Trainer(
model=model,
args=training_args,
train_dataset=fine_tuning_tokenized_datasets,
)
微调
fine_tuning_trainer.train()
保存微调后的模型
model.save_pretrained(“./fine_tuned_model”)
tokenizer.save_pretrained(“./fine_tuned_model”)
注意事项
- 要把
your_mattergen_model_name替换成实际的 mattergen 模型名称。 - 数据集需要依据实际情况进行扩充与优化。
- 训练参数可以根据具体任务和计算资源进行调整。
相关文章:

训练或微调以生成新组合结构
能通过训练或者微调,产生其它没有的组合的结构,比如有化学组成和空年组,想要生成指定化学成分指定空间组的结构,以下是针对需求的详细分析与实现思路,同时给出相应的 Python 代码示例。 1. 训练或微调以生成新组合结构…...

【通俗易懂说模型】生成对抗网络·GAN
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀《深度学习理论直觉三十讲》_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目…...
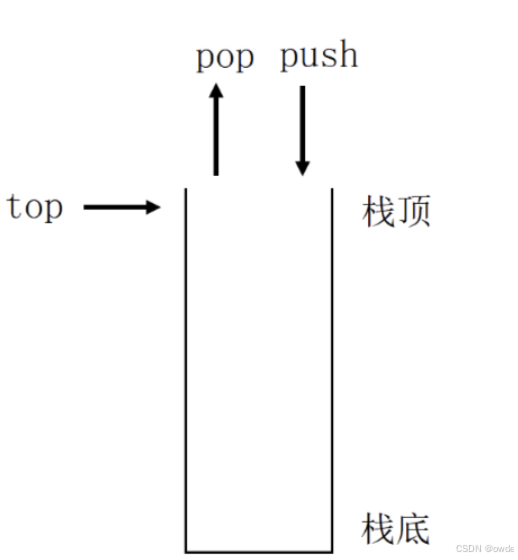
容器适配器-stack栈
C标准库不只是包含了顺序容器,还包含一些为满足特殊需求而设计的容器,它们提供简单的接口。 这些容器可被归类为容器适配器(container adapter),它们是改造别的标准顺序容器,使之满足特殊需求的新容器。 适配器:也称配置器,把一…...

7-6 混合类型数据格式化输入
本题要求编写程序,顺序读入浮点数1、整数、字符、浮点数2,再按照字符、整数、浮点数1、浮点数2的顺序输出。 输入格式: 输入在一行中顺序给出浮点数1、整数、字符、浮点数2,其间以1个空格分隔。 输出格式: 在一行中…...
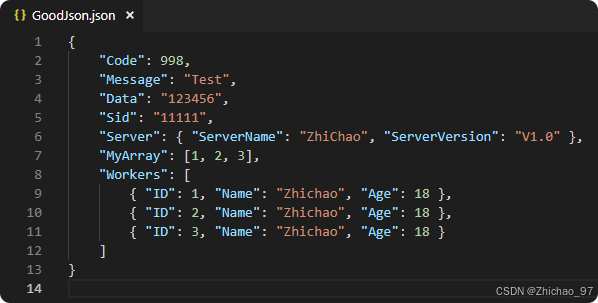
【UE5 C++课程系列笔记】31——创建Json并保存为文件
目录 方式一(不推荐) 方式二(推荐) 一、生成普通Json对象 二、对象嵌套对象 三、对象嵌套数组 四、对象嵌套数组再嵌套对象 方式一(不推荐) 如下代码实现了把JSON字符串保存到文件中 #include &qu…...
Photoshop 2025 Mac中文 Ps图像编辑软件
Photoshop 2025 Mac中文 Ps图像编辑软件 文章目录 Photoshop 2025 Mac中文 Ps图像编辑软件一、介绍二、效果三、下载 一、介绍 Adobe Photoshop 2025 Mac版集成了多种强大的图像编辑、处理和创作功能。①强化了Adobe Sensei AI的应用,通过智能抠图、自动修复、图像…...

linux文件上传下载lrzsz
lrzsz 是一个在 Linux 系统中用于通过串行端口(如 ZMODEM、XMODEM、YMODEM 等协议)进行文件上传和下载的工具集。它通常用于在终端环境中通过串口或 SSH 连接传输文件。 安装 lrzsz 在大多数 Linux 发行版中,你可以使用包管理器来安装 lrzsz。 Debian/Ubuntu: sudo apt-ge…...

MySQL超全笔记
1、初识SQL 什么是数据库 数据库 ( DataBase , 简称DB ) 概念 : 长期存放在计算机内,有组织,可共享的大量数据的集合,是一个数据 “仓库” 作用 : 保存,并能安全管理数据(如:增删改查等),减少冗余… 数据库总览 : 关系型数据库 ( SQL ) MySQL , Oracle , SQL Server , SQ…...

使用Redis构架你自己的私有大模型
使用Redis构架你自己的私有大模型--楼兰 Redis你通常用来做什么?缓存?分布式锁?数据过滤器?不够不够,这远远不够。之前给大家分享过基于Redis Stack提供的一系列插件,完全可以把Redis作为一个类似于Elastic Search的JSON数据库使用。不光可以存储并操作JSON格式的数据…...

2.4路径问题专题:LeeCode 931.下降路径最小和
动态规划解决最小下降路径和问题 1. 题目链接 LeetCode 931. 最小下降路径和 2. 题目描述 给定一个 n x n 的整数矩阵 matrix,找到一条从第一行到最后一行的下降路径,使得路径上的数字和最小。下降路径可以从第一行的任意元素出发,每一步…...

从内核到应用层:Linux缓冲机制与语言缓冲区的协同解析
系列文章目录 文章目录 系列文章目录前言一、缓冲区1.1 示例11.2 缓冲区的概念 二、缓冲区刷新方案三、缓冲区的作用及存储 前言 上篇我们介绍了,文件的重定向操作以及文件描述符的概念,今天我们再来学习一个和文件相关的知识-----------用户缓冲区。 在…...
【AI News | 20250403】每日AI进展
AI Repos 1、llm-server-docs 项目提供了一份基于Debian系统的本地语言模型服务器搭建指南,适用于Linux初学者。教程涵盖驱动安装、GPU功耗设置、自动登录配置及开机自启脚本部署等关键步骤,支持Ollama/vLLM等多种OpenAI兼容方案。方案设计强调四大原则…...
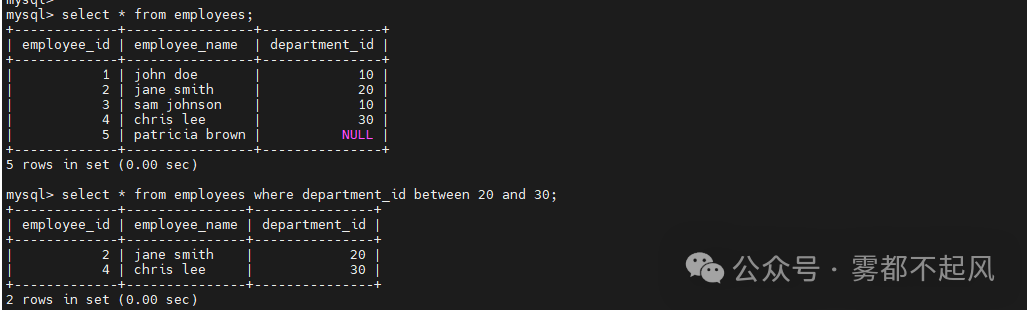
深入理解SQL中的<>运算符:不等于的灵活运用
在SQL的世界里,数据的筛选与查询是最常见的操作之一。在编写查询语句时,比较运算符是我们不可忽视的工具,其中,<> 运算符作为 不等于 的代表,起着至关重要的作用。它不仅能够帮助我们筛选出符合特定条件的数据&a…...
)
单网卡上绑定多个虚拟IP(AI回答)
单网卡绑定多个虚拟IP的实现方法 一、Linux系统配置方案 1. 手动绑定少量IP地址(适用于CentOS/RHEL) 步骤1:进入网络配置目录 cd /etc/sysconfig/network-scripts/步骤2:复制并重命名网卡配置文件 cp ifcfg-eth0 i…...
数据清洗的具体内容
(一)ETL介绍 “ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较…...
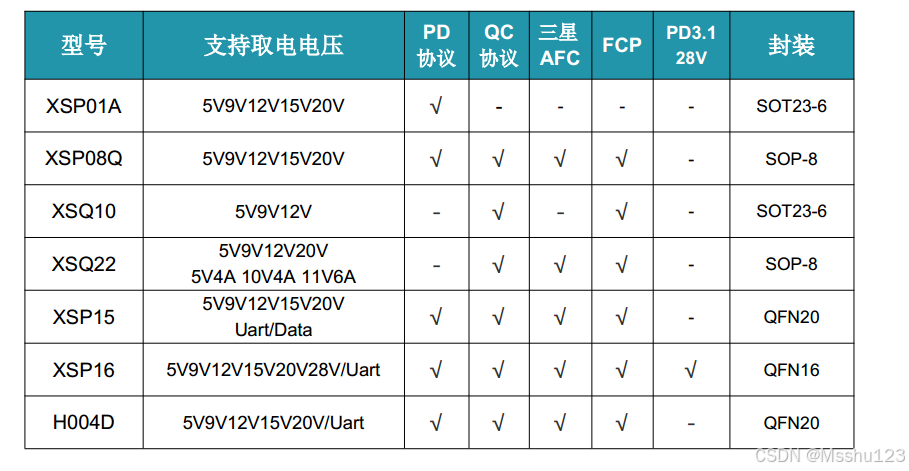
小家电等电子设备快充方案,XSP15支持全协议和支持MCU与电脑传输数据
随着USB-C的普及,市面上消费者PD充电器越来越多,如何让小家电等电子产品也能够支持PD协议快充呢?就需要加入一颗汇铭达XSP15取电协议芯片,这颗芯片不仅能支持取电,还能通过串口读取充电器支持的最大输出功率和支持外部…...

手动实现一个迷你Llama:手动实现Llama模型
进阶的 LLM Llama模型教学一、库导入二、实现 ModelArgs 参数类构建Transformer 模型参数解释 三、实现均方根归一化(RMSNorm,LayerNorm 的一种变体)层定义与原理RMSNorm 公式与 LayerNorm 的对比RMSNorm 的优点RMSNorm 的实现RMSNorm 的关键…...
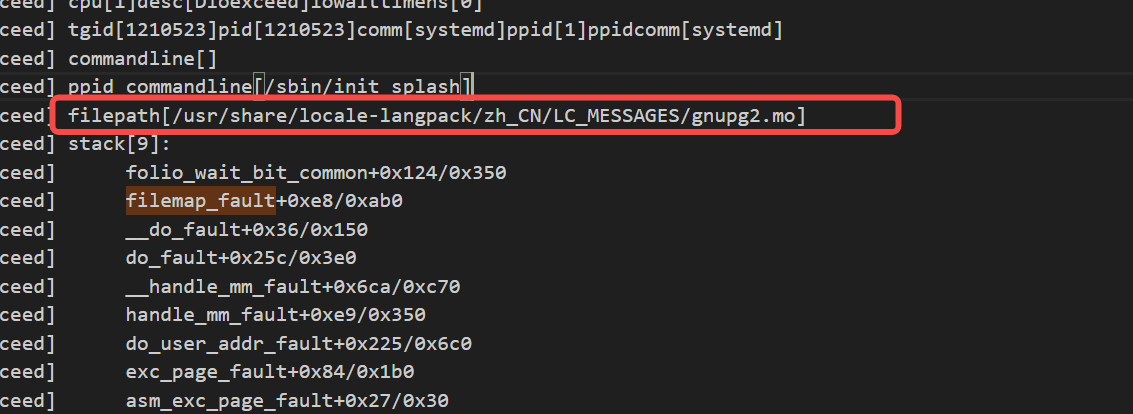
缺页异常导致的iowait打印出相关文件的绝对路径
一、背景 在之前的博客 增加等IO状态的唤醒堆栈打印及缺页异常导致iowait分析-CSDN博客 里,我们进一步优化了D状态和等IO状态的事件的堆栈打印,补充了唤醒堆栈打印,也分析了一种比较典型的缺页异常filemap_fault导致的iowait的情况。 在这篇…...
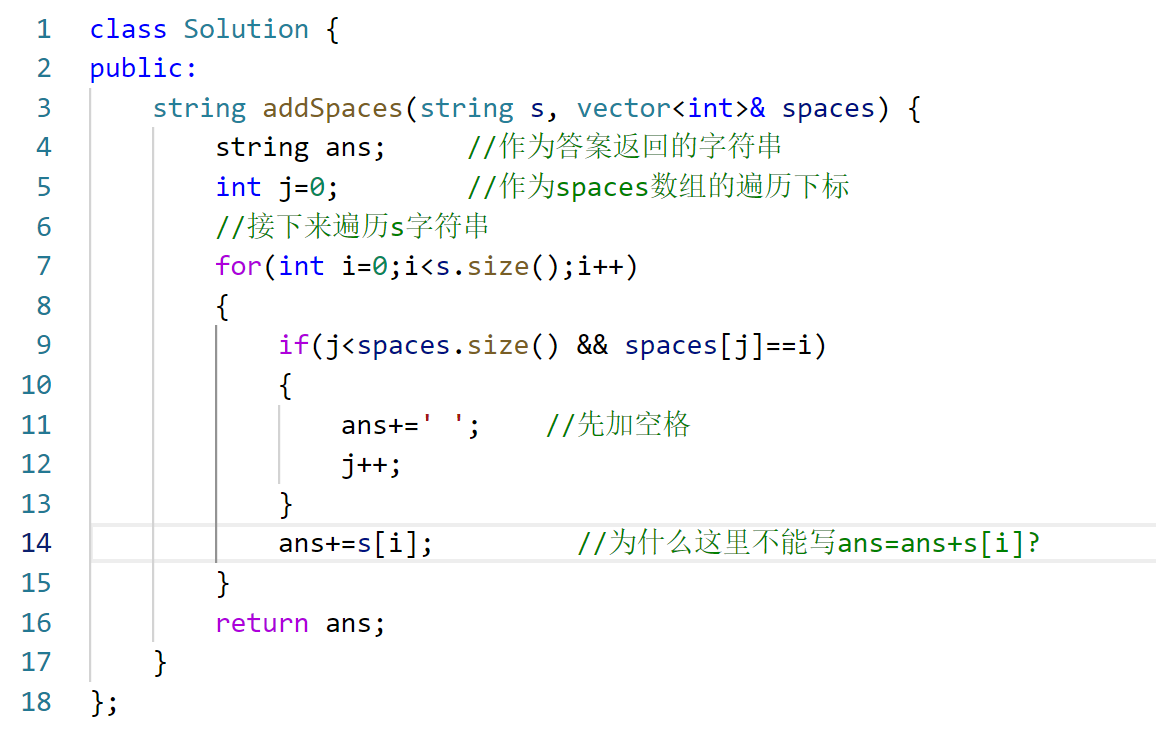
记录学习的第十七天
今天对昨天下午的洛谷蓝桥杯模拟赛和今天早上的力扣周赛进行复盘。 昨天的蓝桥杯模拟赛,硬坐了4个小时,只会做前面的三道入门题。😥而且第一道填空题竟然还算错了。其他的五道题我都没啥思路了,实在难受啊! Q1:这道题硬…...

全面解析 Mybatis 与 Mybatis-Plus:深入原理、实践案例与高级特性对比
全面解析 Mybatis 与 Mybatis-Plus:深入原理、实践案例与高级特性对比 🚀 前言一、基础介绍 ✨1. Mybatis 简介 🔍2. Mybatis-Plus 简介 ⚡ 二、核心区别与高级特性对比 🔎1. 开发模式与配置管理2. 功能丰富度与扩展性3. 自动填充…...

Ubuntu 22.04 一键部署openManus
openManus 前言 OpenManus-RL,这是一个专注于基于强化学习(RL,例如 GRPO)的方法来优化大语言模型(LLM)智能体的开源项目,由来自UIUC 和 OpenManus 的研究人员合作开发。 前提要求 安装deepseek docker方式安装 ,windows 方式安装,Linux安装方式...

lib-zo,C语言另一个协程库,dns协程化, gethostbyname
lib-zo,C语言另一个协程库,dns协程化, gethostbyname 另一个 C 协程库 https://blog.csdn.net/eli960/article/details/146802313 本协程库 支持 DNS查询 协程化. 禁用所有 UDP 协程化 zvar_coroutine_disable_udp 1;禁用 53 端口的UDP 协程化 zvar_coroutine_disable_ud…...

强化学习_Paper_1988_Learning to predict by the methods of temporal differences
paper Link: sci-hub: Learning to predict by the methods of temporal differences 1. 摘要 论文介绍了时间差分方法(TD 方法),这是一种用于预测问题的增量学习方法。TD 方法通过比较连续时间步的预测值之间的差异来调整模型,…...
话费充值业务回调补偿)
虚拟电商-话费充值业务(六)话费充值业务回调补偿
一、话费充值回调业务补偿 业务需求:供应商对接下单成功后充吧系统将订单状态更改为:等待确认中,此时等待供应商系统进行回调,当供应商系统回调时说明供应商充值成功,供应商回调充吧系统将充吧的订单改为充值成功&…...
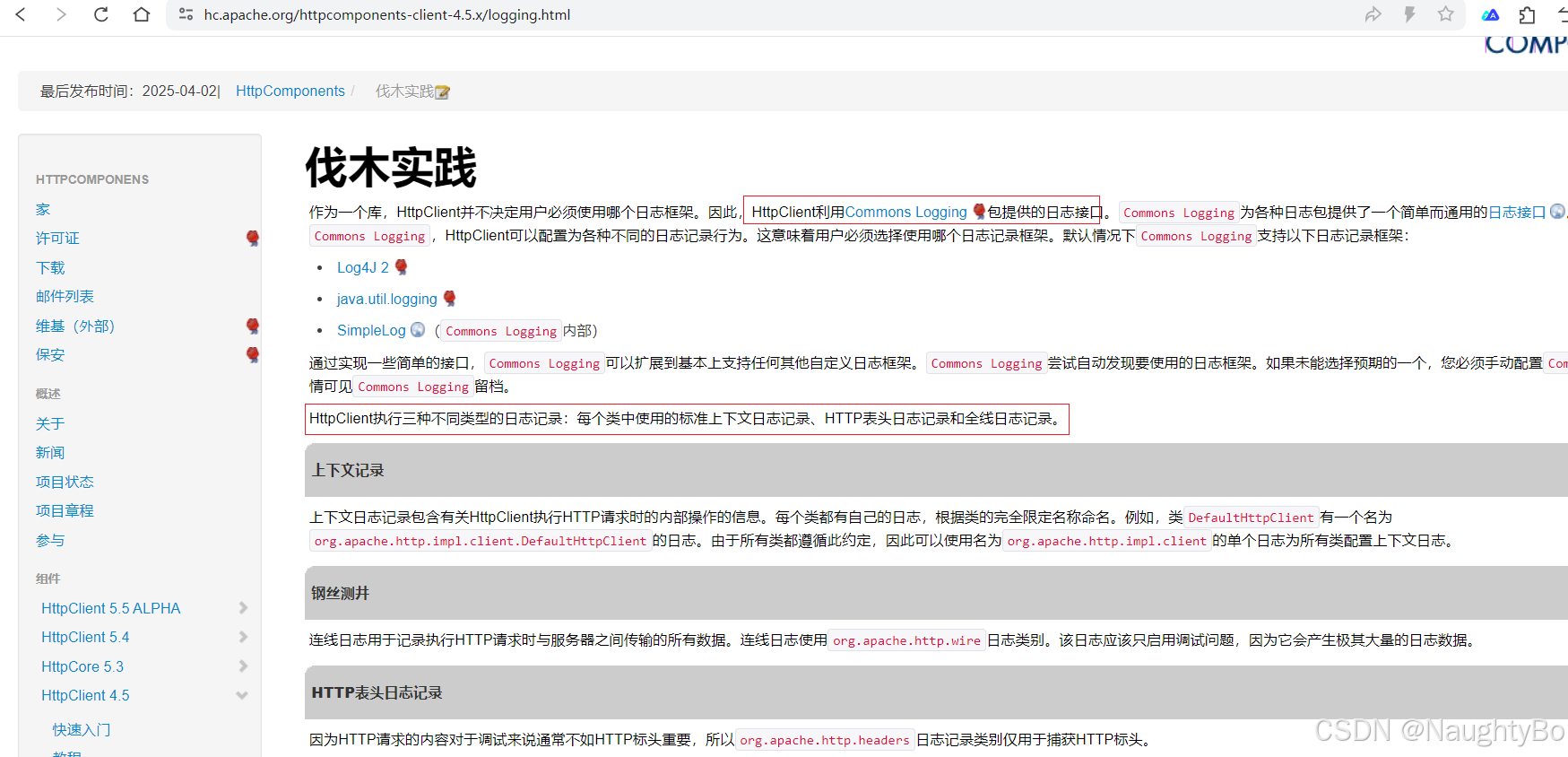
Apache httpclient okhttp
学习链接 okhttp github okhttp官方使用文档 SpringBoot 整合okHttp okhttp3用法 Java中常用的HTTP客户端库:OkHttp和HttpClient(包含请求示例代码) 深入浅出 OkHttp 源码解析及应用实践 httpcomponents-client github apache httpclie…...

SQL Server 2022 读写分离问题整合
跟着热点整理一下遇到过的SQL Server的问题,这篇来聊聊读写分离遇到的和听说过的问题。 一、读写分离实现方法 1. 原生高可用方案 1.1 Always On 可用性组(推荐方案) 配置步骤: -- 1. 启用Always On功能 USE [master] GO ALT…...
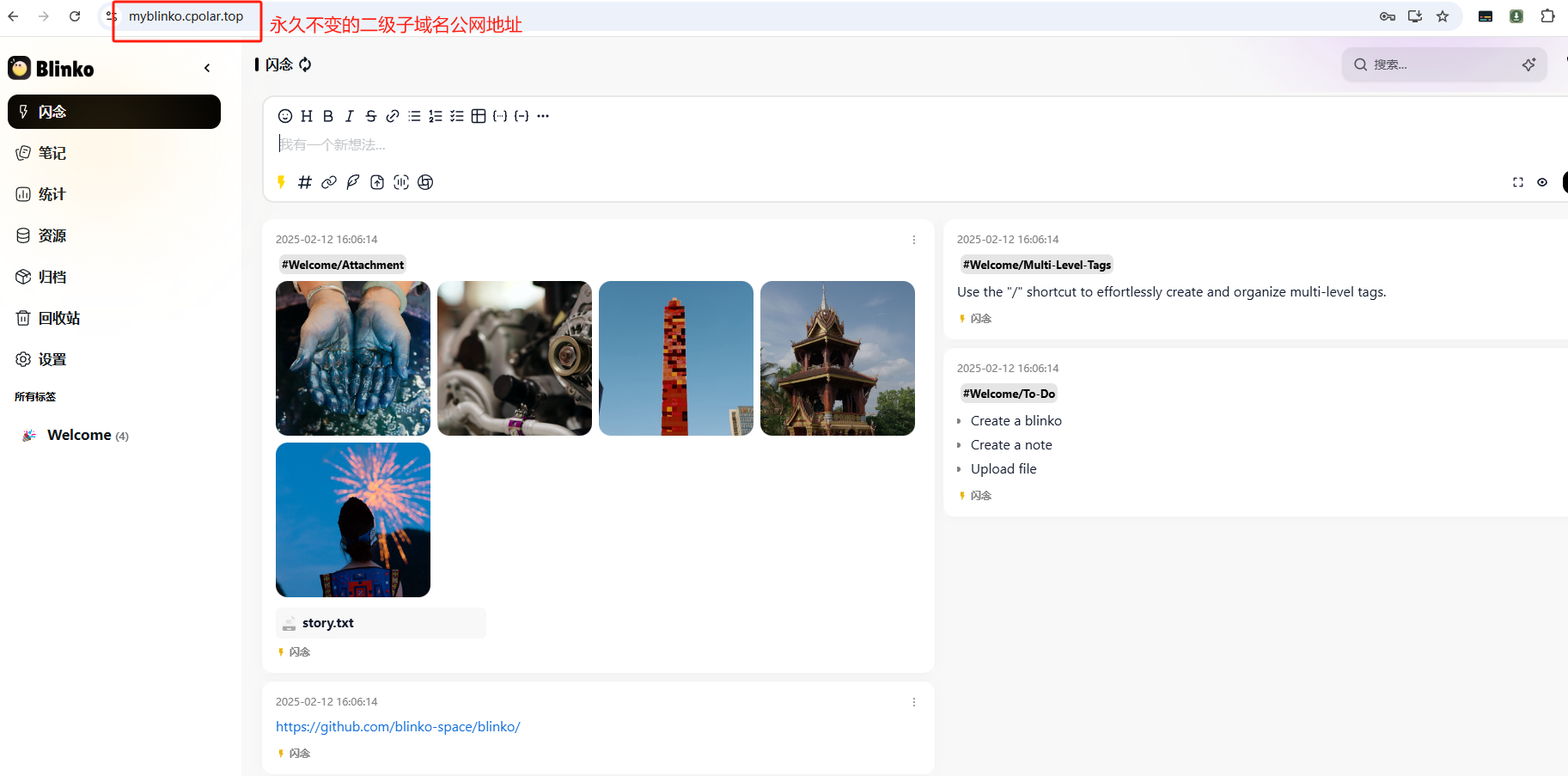
Docker部署Blinko:打造你的个性化AI笔记助手与随时随地访问
文章目录 前言1. Docker Compose一键安装2. 简单使用演示3. 安装cpolar内网穿透4. 配置公网地址5. 配置固定公网地址 前言 嘿,小伙伴们,是不是觉得市面上那些单调乏味的笔记应用让人提不起劲?今天,我要给大家安利一个超炫酷的开源…...

Python Cookbook-5.2 不区分大小写对字符串列表排序
任务 你想对一个字符串列表排序,并忽略掉大小写信息。举个例子,你想要小写的a排在大写的 B 前面。默认的情况下,字符串比较是大小写敏感的(比如所有的大写字符排在小写字符之前)。 解决方案 采用 decorate-sort-undecorate(DSU)用法既快又…...

安全业务的manus时代即将到来
“(人)把业务流程任务化,把任务工具化,再把工具服务化,剩下的交给智能体。” 一、自动化与智能化浪潮下的安全业务变革 近期,笔者着迷于模型上下文协议(Model Context Protocol,简称MCP),这项技术所带来的变革性力量令人惊叹。在对多个技术案例进行实践的过程中,笔者…...
:DMP与DSP对接及数据统计原理剖析)
程序化广告行业(55/89):DMP与DSP对接及数据统计原理剖析
程序化广告行业(55/89):DMP与DSP对接及数据统计原理剖析 大家好呀!在数字化营销的大趋势下,程序化广告已经成为众多企业实现精准营销的关键手段。上一篇博客我们一起学习了程序化广告中的人群标签和Look Alike原理等知…...