强化学习_Paper_1988_Learning to predict by the methods of temporal differences
paper Link: sci-hub: Learning to predict by the methods of temporal differences
1. 摘要
论文介绍了时间差分方法(TD 方法),这是一种用于预测问题的增量学习方法。TD 方法通过比较连续时间步的预测值之间的差异来调整模型,而不是传统的通过预测值与实际结果之间的差异来调整。
对于大多数现实的预测问题,TD方法比传统方法需要更少的内存和更少的峰值计算,并且可以产生更准确的预测。
2. 简介
传统预测学习方法依赖于预测值与实际结果之间的差异来分配“信用”(即调整权重),这种方法在多步预测问题中效率较低。TD 方法通过比较连续时间步的预测值之间的差异来更新模型。
对于 每天预测下周六是否会下雨 的问题:
- 传统方法:compare each prediction to the actual outcome whether or not it does rain on Saturday.
- 会根据周六的实际结果增加或减少预估权重。
- TD方法: compare each day’s prediction with that made on the following.
- 如果预测周一50%可能下雨,周二有75%可能下雨,TD方法会增加与周一类似几天的预测,而不是等到周六的实际结果出来
TD方法2个优势:
- 计算效率更高:TD 方法可以**更增量地更新预测值**,减少了计算量和存储需求。
- 更快的收敛速度:TD 方法在多步预测问题中表现更好,能够更快地收敛并产生更准确的预测。
3. TD和监督学习
主要关注多步预测。很多问题被定义成single-step预测问题,实际上将其认为multi-step预测问题会更加自然,比如一些感知学习问题:视频或语音识别问题,一般都是作为简单监督学习(a training set of isolated, correctly-classified input patterns.)。但是当人类听到或看到事物时,他们会随着时间的推移收到一系列输入,并不断更新他们对所看到或听到的事物的假设。
- 现在(2025)的很多语音识别都是
Transformer-Decoder方式,也是考虑到了前面的输入对后一个的影响。deepseek的multi-Token Prediction本质也是一样的
3.1 理论分析
一般监督回归模型参数更新方法(基于正态分布-最大似然):
- y ∼ N ( y ^ , σ 2 ) = 1 σ 2 π e − ( y − y ^ ) 2 2 σ 2 y \sim N(\hat{y}, \sigma ^ 2) = \frac{1}{\sigma\sqrt{2 \pi }} e^{-\frac{(y-\hat{y})^2}{2\sigma^2}} y∼N(y^,σ2)=σ2π1e−2σ2(y−y^)2
- m a x L = ∏ 1 n f ( y ∣ y ^ , σ 2 ) = ∏ i = 1 n 1 σ 2 π e − ( y − y ^ i ) 2 2 σ 2 = ( 2 π ) − n / 2 σ − n e − 1 2 σ 2 ∑ i = 1 n ( y − y i ) 2 max L = \prod_1^{n} f(y|\hat{y}, \sigma^2) =\prod_{i=1}^n \frac{1}{\sigma\sqrt{2 \pi }} e^{-\frac{(y-\hat y_i)^2}{2\sigma^2}}=(2\pi)^{-n/2}\sigma^{-n} e^{-\frac{1}{2\sigma^2}\sum_{i=1}^n(y-y_i)^2} maxL=∏1nf(y∣y^,σ2)=∏i=1nσ2π1e−2σ2(y−y^i)2=(2π)−n/2σ−ne−2σ21∑i=1n(y−yi)2
- m a x l n ( L ) ∼ − ∑ i = 1 n ( y − y i ) 2 → m i n M S E = ∑ i = 1 n ( y − y i ) 2 max ln(L) \sim -\sum_{i=1}^n(y-y_i)^2 \rightarrow min\ MSE=\sum_{i=1}^n(y-y_i)^2 maxln(L)∼−∑i=1n(y−yi)2→min MSE=∑i=1n(y−yi)2
- 更新力度为:
- Δ w = α ∑ t = 1 m w t ; Δ w t = α ( z − P t ) ∇ w P t \Delta w = \alpha \sum_{t=1}^m w_t;\Delta w_t = \alpha(z-P_t) \nabla _w P_t Δw=α∑t=1mwt;Δwt=α(z−Pt)∇wPt
- 线性回归: Δ w t = α ( w T x − z ) x \Delta w_t = \alpha(w^Tx-z) x Δwt=α(wTx−z)x
- 主要是基于真实值与预测值的偏差。在多步预测的时候,z已知之前无法确定
- 无法进增量计算
python-example:
class multiReg:def __init__(self, feature_dim=7, learning_rate=0.1):self.w = np.random.randn(feature_dim).reshape(-1, 1)self.learning_rate = learning_ratedef predict(self, x):return np.matmul(x, self.w)def fit(self, x, y, batch_size=25, n_rounds=100):n = x.shape[0]idx = np.arange(n)tq_bar = tqdm(range(n_rounds))for round_i in tq_bar:tq_bar.set_description(f'[ {round_i + 1} / {n_rounds}]')np.random.shuffle(idx) idx_l = [min(i, n) for i in range(0, n + batch_size, batch_size)]for st, ed in zip(idx_l[:-1], idx_l[1:]):batch_x = x[st:ed, ...]batch_y = y[st:ed, ...]# x @ wp_t = self.predict(batch_x) # (p_t - z)e = p_t.reshape(batch_x.shape[0], -1) - batch_y# \sum_{t=1}^T (p_t - z) @ xgrad = np.matmul(batch_x.transpose(0, 2, 1), e[..., np.newaxis]).mean(axis=0)self.w -= self.learning_rate * gradTD方法,同样的更新策略,但是可以进行增量计算
- z − P t = ∑ k = t m ( P k + 1 − P k ) ; w h e r e P m + 1 = z z-P_t = \sum_{k=t}^m(P_{k+1}-P_{k}); \ \ \ where\ \ P_{m+1}=z z−Pt=∑k=tm(Pk+1−Pk); where Pm+1=z
- Δ w = α ∑ t = 1 m Δ w t = α ∑ t = 1 m ∑ k = t m ( P k + 1 − P k ) ∇ w P t = ∑ t = 1 m α ( P t + 1 − P t ) ∑ k = 1 t ∇ w P k \Delta w = \alpha \sum_{t=1}^m\Delta w_t=\alpha \sum_{t=1}^m \sum_{k=t}^m(P_{k+1}-P_{k})\nabla _w P_t=\sum_{t=1}^m \alpha(P_{t+1}-P_{t})\sum_{k=1}^t \nabla _w P_k Δw=α∑t=1mΔwt=α∑t=1m∑k=tm(Pk+1−Pk)∇wPt=∑t=1mα(Pt+1−Pt)∑k=1t∇wPk
- Δ w t = α ( P t + 1 − P t ) ∑ k = 1 t ∇ w P k \Delta w_t = \alpha(P_{t+1}-P_{t})\sum_{k=1}^t \nabla _w P_k Δwt=α(Pt+1−Pt)∑k=1t∇wPk
- 加入 λ ∈ [ 0 , 1 ] \lambda \in [0, 1] λ∈[0,1]
- Δ w t = α ( P t + 1 − P t ) ∑ k = 1 t λ t − k ∇ w P k \Delta w_t = \alpha(P_{t+1}-P_{t})\sum_{k=1}^t \lambda^{t-k} \nabla _w P_k Δwt=α(Pt+1−Pt)∑k=1tλt−k∇wPk
- 越接近预估时间t权重越大
- e t + 1 = ∑ k = 1 t + 1 λ t + 1 − k ∇ w P k = ∇ w P t + 1 + λ ∑ k = 1 t λ t − k ∇ w P k = ∇ w P t + 1 + λ e t e_{t+1}=\sum_{k=1}^{t+1}\lambda ^{t+1-k} \nabla _w P_k=\nabla _w P_{t+1} + \lambda\sum_{k=1}^{t}\lambda ^{t-k} \nabla _w P_k=\nabla _w P_{t+1} + \lambda e_{t} et+1=∑k=1t+1λt+1−k∇wPk=∇wPt+1+λ∑k=1tλt−k∇wPk=∇wPt+1+λet
- λ = 0 → α ( P t + 1 − P t ) ∇ w P t \lambda = 0 \rightarrow \alpha(P_{t+1}-P_{t})\nabla _w P_{t} λ=0→α(Pt+1−Pt)∇wPt
python-example:
class multiTDReg:def __init__(self, feature_dim=7, learning_rate=0.1, time_step=9, lmbda=0.9, incre_update=True):self.w = np.random.randn(feature_dim).reshape(-1, 1)self.learning_rate = learning_rateself.lmbda = lmbdaself.time_step = time_stepself.incre_update = incre_updatedef predict(self, x):return np.matmul(x, self.w)def get_nabla(self, batch_x):lmbda = self.lmbdae_t_list = [0]for t in range(self.time_step):e_t_1 = batch_x[:, t, :] + e_t_list[-1] * lmbdae_t_list.append(e_t_1)return np.stack(e_t_list[1:], axis=1)def fit(self, x, y, batch_size=25, n_rounds=100):n = x.shape[0]idx = np.arange(n)tq_bar = tqdm(range(n_rounds))for round_i in tq_bar:tq_bar.set_description(f'[ {round_i + 1} / {n_rounds}]')np.random.shuffle(idx) idx_l = [min(i, n) for i in range(0, n + batch_size, batch_size)]for st, ed in zip(idx_l[:-1], idx_l[1:]):batch_x = x[st:ed, ...]batch_y = y[st:ed, ...]p_t = self.predict(batch_x) p_t_c = np.concatenate([p_t, batch_y[..., np.newaxis]], axis=1)e = p_t_c[:, :-1, :] - p_t_c[:, 1:, :] # -(p_{t+1} -p_t) # b, time_step, 1# e \sum_{k=1}^t lmbda^{t-k} \nabla_w P_k nabla = self.get_nabla(batch_x) # b, time_step, 7# print(f'{nabla.shape=} {e.shape=}')if not self.incre_update:grad = np.matmul(nabla.transpose(0, 2, 1), e).mean(axis=0)self.w -= self.learning_rate * gradcontinue# incrementally update:for t in range(self.time_step):grad_t = nabla[:, t, :] * e[:, t, :]self.w -= self.learning_rate * grad_t.mean(axis=0).reshape(-1, 1)3.2 案例
每当数据序列由动态系统(by a system that has a state which evolves and is partially revealed over time.)生成时, TD方法会发挥更大的作用
Random-walk Env example : github: 1988_randomWalk_td.py
P ( s = G ∣ s = x ) → z = E [ V ( S = x ) ] P(s=G|s=x) \rightarrow z=E[V(S=x)] P(s=G∣s=x)→z=E[V(S=x)]
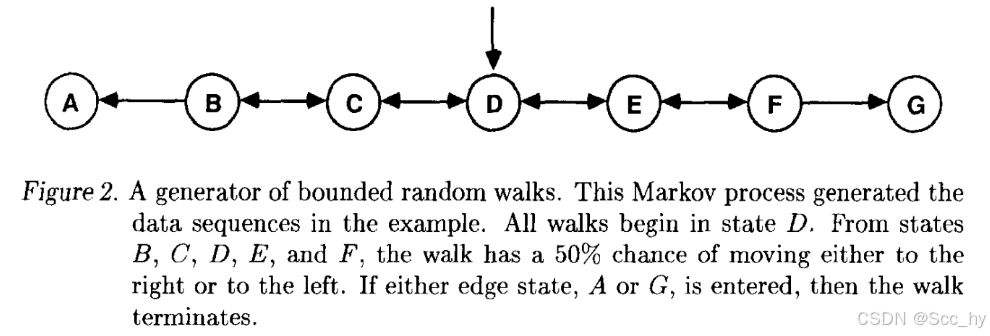
env python example:
class SimpleRandomWalk(gym.Env):def __init__(self):super(SimpleRandomWalk, self).__init__()self.states = ['A', 'B', 'C', 'D', 'E', 'F', 'G']self.action_space = gym.spaces.Discrete(2, start=0)self.observation_space = gym.spaces.Discrete(len(self.states))self.start_state = 'D'self.current_state = self.start_stateself.rewards = {'A': 0, 'G': 1}def step(self, action):index = self.states.index(self.current_state)if action == 0: # 左移if index > 0:self.current_state = self.states[index - 1]elif action == 1: # 右移if index < len(self.states) - 1:self.current_state = self.states[index + 1]reward = self.rewards.get(self.current_state, 0)done = self.current_state in ['A', 'G']return self._state_to_index(self.current_state), reward, done, False, {}def reset(self):self.current_state = self.start_statereturn self._state_to_index(self.current_state), {}def render(self, mode='human'):print(f"Current state: {self.current_state}")def _state_to_index(self, state):return self.states.index(state)
Learning result : TD-Reg is mush more easy to learn
- train set (seq nums, seq length):
train_seq_pairs = [ (10, 4), (90, 6), (150, 8), (200, 10), (150, 12), (100, 14), (100, 16), (100, 18), (100, 20), ]

总结
Richard S. Sutton 的这篇论文为时间差分方法奠定了理论基础,并展示了其在多步预测问题中的优势。
TD 方法不仅在理论上具有收敛性和最优性,而且在实际应用中也表现出了更高的效率和更快的收敛速
相关文章:
强化学习_Paper_1988_Learning to predict by the methods of temporal differences
paper Link: sci-hub: Learning to predict by the methods of temporal differences 1. 摘要 论文介绍了时间差分方法(TD 方法),这是一种用于预测问题的增量学习方法。TD 方法通过比较连续时间步的预测值之间的差异来调整模型,…...
话费充值业务回调补偿)
虚拟电商-话费充值业务(六)话费充值业务回调补偿
一、话费充值回调业务补偿 业务需求:供应商对接下单成功后充吧系统将订单状态更改为:等待确认中,此时等待供应商系统进行回调,当供应商系统回调时说明供应商充值成功,供应商回调充吧系统将充吧的订单改为充值成功&…...
Apache httpclient okhttp
学习链接 okhttp github okhttp官方使用文档 SpringBoot 整合okHttp okhttp3用法 Java中常用的HTTP客户端库:OkHttp和HttpClient(包含请求示例代码) 深入浅出 OkHttp 源码解析及应用实践 httpcomponents-client github apache httpclie…...

SQL Server 2022 读写分离问题整合
跟着热点整理一下遇到过的SQL Server的问题,这篇来聊聊读写分离遇到的和听说过的问题。 一、读写分离实现方法 1. 原生高可用方案 1.1 Always On 可用性组(推荐方案) 配置步骤: -- 1. 启用Always On功能 USE [master] GO ALT…...
Docker部署Blinko:打造你的个性化AI笔记助手与随时随地访问
文章目录 前言1. Docker Compose一键安装2. 简单使用演示3. 安装cpolar内网穿透4. 配置公网地址5. 配置固定公网地址 前言 嘿,小伙伴们,是不是觉得市面上那些单调乏味的笔记应用让人提不起劲?今天,我要给大家安利一个超炫酷的开源…...

Python Cookbook-5.2 不区分大小写对字符串列表排序
任务 你想对一个字符串列表排序,并忽略掉大小写信息。举个例子,你想要小写的a排在大写的 B 前面。默认的情况下,字符串比较是大小写敏感的(比如所有的大写字符排在小写字符之前)。 解决方案 采用 decorate-sort-undecorate(DSU)用法既快又…...

安全业务的manus时代即将到来
“(人)把业务流程任务化,把任务工具化,再把工具服务化,剩下的交给智能体。” 一、自动化与智能化浪潮下的安全业务变革 近期,笔者着迷于模型上下文协议(Model Context Protocol,简称MCP),这项技术所带来的变革性力量令人惊叹。在对多个技术案例进行实践的过程中,笔者…...
:DMP与DSP对接及数据统计原理剖析)
程序化广告行业(55/89):DMP与DSP对接及数据统计原理剖析
程序化广告行业(55/89):DMP与DSP对接及数据统计原理剖析 大家好呀!在数字化营销的大趋势下,程序化广告已经成为众多企业实现精准营销的关键手段。上一篇博客我们一起学习了程序化广告中的人群标签和Look Alike原理等知…...
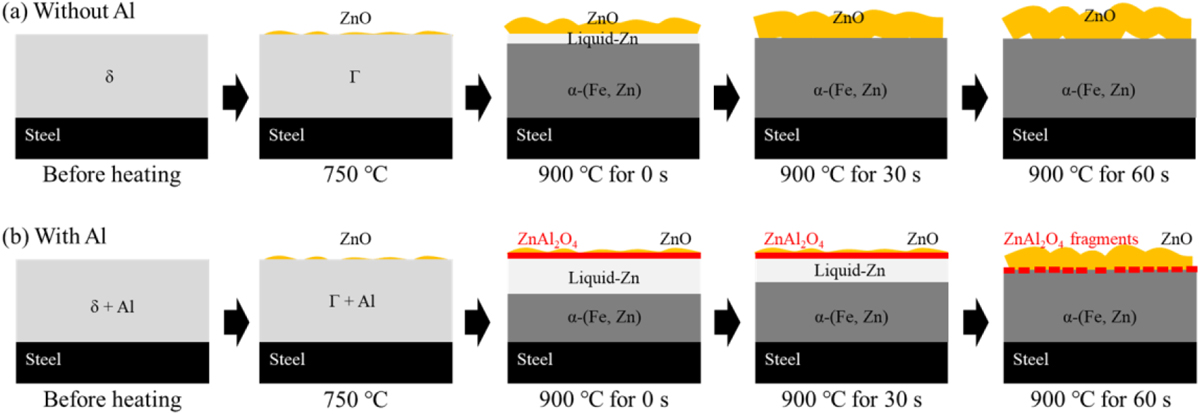
【文献研究】铝对热冲压加热过程中锌氧化的影响
在热冲压过程中,镀锌铁板和镀锌板等镀锌钢板表面发生Zn氧化。为了阐明镀锌层中的Al对Zn氧化的影响,本研究研究了镀锌钢板上添加和不添加Al时形成的ZnO量。发现添加铝后ZnO量减少。对添加铝的镀锌钢板的显微组织分析表明,添加的Al在热冲压后Zn…...
Win11本地从零开始部署dify全流程
1.安装wsl和打开Hyper-V功能(前置准备) 这个是为了支持我们的Docker Desktop运行。 1.1.安装wsl 使用管理员身份运行命令行。 如果显示 “无法与服务器建立连接就执行“,表示没有安装wsl,如果更新成功,那就不用执行…...

从代码学习深度学习 - RNN PyTorch版
文章目录 前言一、数据预处理二、辅助训练工具函数三、绘图工具函数四、模型定义五、模型训练与预测六、实例化模型并训练训练结果可视化总结前言 循环神经网络(RNN)是深度学习中处理序列数据的重要模型,尤其在自然语言处理和时间序列分析中有着广泛应用。本篇博客将通过一…...
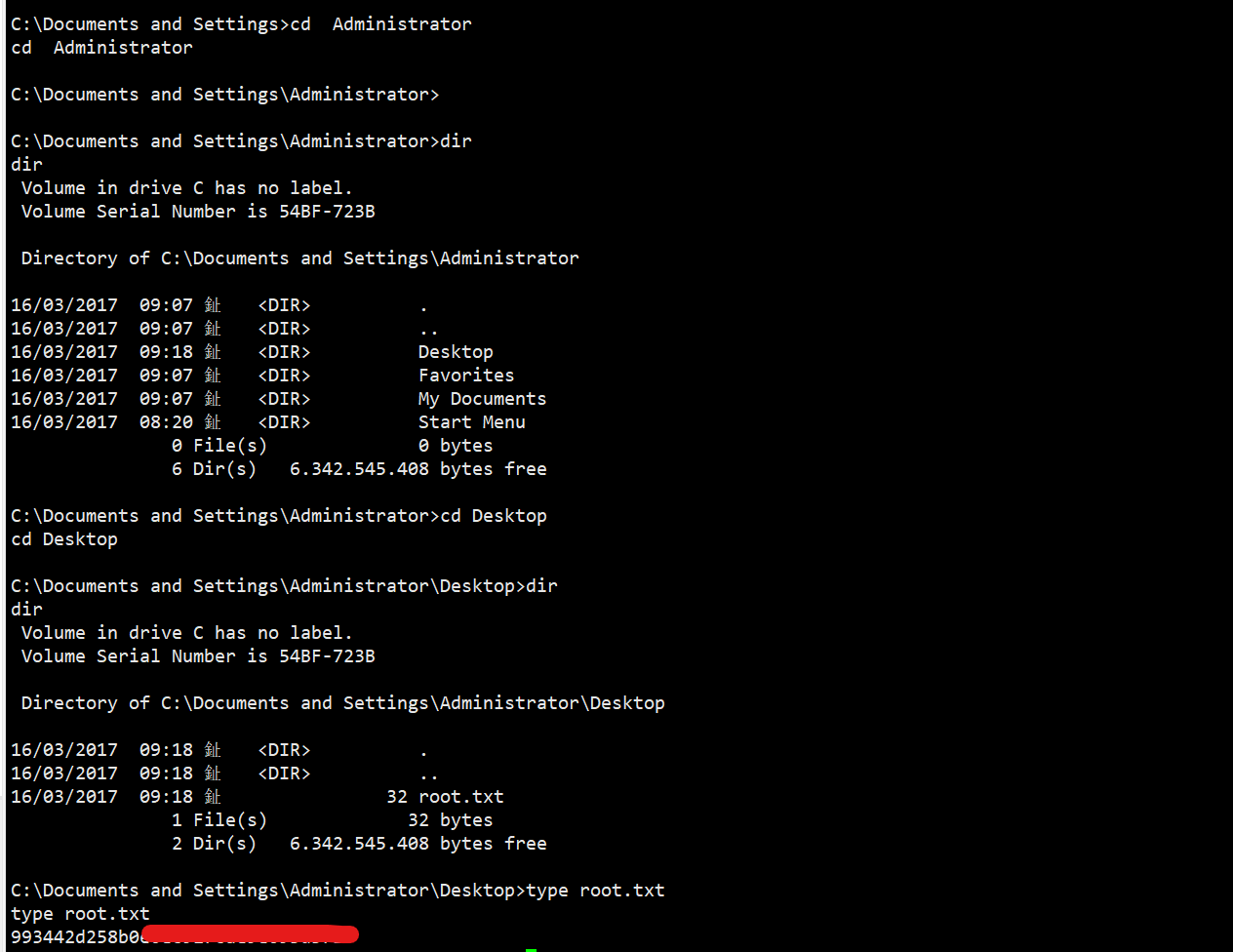
【HTB】Windwos-easy-Legacy靶机渗透
靶机介绍,一台很简单的WIndows靶机入门 知识点 msfconsole利用 SMB历史漏洞利用 WIndows命令使用,type查看命令 目录标题 一、信息收集二、边界突破三、权限提升 一、信息收集 靶机ip:10.10.10.4攻击机ip:10.10.16.26 扫描TC…...
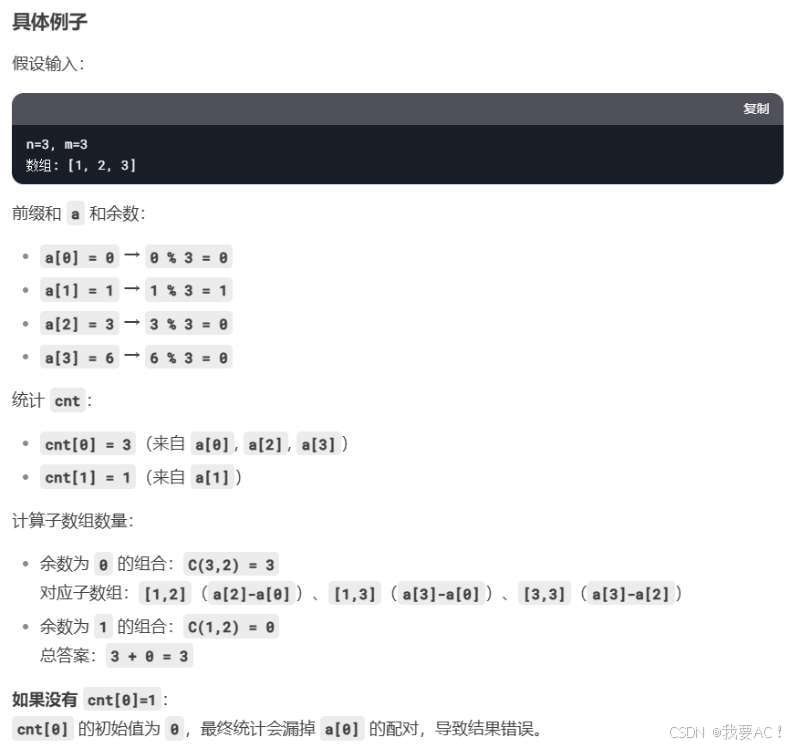
蓝桥杯真题———k倍区间
题目如下 代码如下 记录余数 cnt[0] 1 的初始化是为了处理 空前缀和 说明...

LeetCode 891 -- 贡献度思想
题目描述 子序列宽度之和 思路 ref 代码 相似题 子数组范围和 acwing...

无人机等非合作目标公开数据集2025.4.3
一.无人机遥感数据概述 1.1 定义与特点 在遥感技术的不断发展中,无人机遥感数据作为一种新兴的数据源,正逐渐崭露头角。它是通过无人驾驶飞行器(UAV)搭载各种传感器获取的地理空间信息,具有 覆盖范围大、综合精度高、…...

机器视觉--python基础语法
Python基础语法 1. Python标识符 在 Python 里,标识符由字母、数字、下划线组成。 在 Python 中,所有标识符可以包括英文、数字以及下划线(_),但不能以数字开头。 Python 中的标识符是区分大小写的。 以下划线开头的标识符是有特殊意义的…...
司南评测集社区 3 月上新一览!
司南评测集社区 CompassHub 作为司南评测体系的重要组成部分,旨在打创新性的基准测试资源导航社区,提供丰富、及时、专业的评测集信息,帮助研究人员和行业人士快速搜索和使用评测集。 2025 年 3 月,司南评测集社区新收录了一批评…...
介绍及操作手册)
TrollStore(巨魔商店)介绍及操作手册
TrollStore(巨魔商店)介绍及操作手册 一、TrollStore 简介 TrollStore 是一款针对 iOS 设备开发的第三方应用安装工具,它允许用户在不越狱设备的情况下,安装和使用未经过苹果官方 App Store 审核的应用程序。该工具利用了 iOS 系…...

SSE与Streamable HTTP的区别:协议与技术实现的深度对比
引言 在现代Web开发中,实时数据传输是许多应用的核心需求,从聊天应用到股票市场更新,从游戏服务器到AI模型通信。为了满足这一需求,各种技术应运而生,其中Server-Sent Events (SSE)和Streamable HTTP是两种重要的实时…...

android 之简述屏幕分辨率、屏幕密度、屏幕最小宽度
一、屏幕分辨率 屏幕分辨率是指屏幕显示的像素数量,通常以水平像素数乘以垂直像素数表示,例如 1920x1080。它直接影响屏幕的显示效果,包括图像的清晰度和细节。不同的设备可能有不同的屏幕分辨率。 1、常见的屏幕分辨率 标准分辨率&#x…...

mac环境中Nginx安装使用 反向代理
安装 如没有Homebrew 先安装Homebrew 国内镜像: /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" 安装成功后安装nginx: brew install nginx 启动nginx: nginx 或者 brew services st…...

2025年3月个人工作生活总结
本文为 2025年3月工作生活总结。 研发编码 一个curl下载失败问题的记录 问题: 某程序,指定IP和账户密码配置,再使用curl库连接sftp服务器,下载文件。在CentOS系统正常,但在某国产操作系统中失败,需要用命…...
实战打靶集锦-36-Deception
文章目录 1. 主机发现2. 端口扫描3. 服务枚举4. 服务探查5. 系统提权6. 写在最后 靶机地址:https://download.vulnhub.com/haclabs/Deception.ova 1. 主机发现 目前只知道目标靶机在192.168.56.xx网段,通过如下的命令,看看这个网段上在线的主…...

前端开发技术演进与就业现实:顺应时代方能不被淘汰-优雅草卓伊凡
前端开发技术演进与就业现实:顺应时代方能不被淘汰-优雅草卓伊凡 在技术浪潮汹涌的当下,常有人发问:“学习CSS、HTML、JS以后可以干什么?”对此,卓伊凡可以明确地给出答案:单纯学习这些过于基础的Web前端开…...

敏捷开发:以人为本的高效开发模式
目录 前言1. 什么是敏捷开发?1.1 敏捷开发的核心理念1.2 敏捷开发的优势 2. 敏捷宣言:四大核心价值观2.1 个体和交互胜过工具和过程2.2 可工作的软件胜过大量的文档2.3 客户合作胜过合同谈判2.4 响应变化胜过遵循计划 3. 敏捷开发的实践3.1 Scrum&#x…...

HarmonyOS 基础组件和基础布局的介绍
1. HarmonyOS 基础组件 1.1 Text 文本组件 Text(this.message)//文本内容.width(200).height(50).margin({ top: 20, left: 20 }).fontSize(30)//字体大小.maxLines(1)// 最大行数.textOverflow({ overflow: TextOverflow.Ellipsis })// 超出显示....fontColor(Color.Black).…...
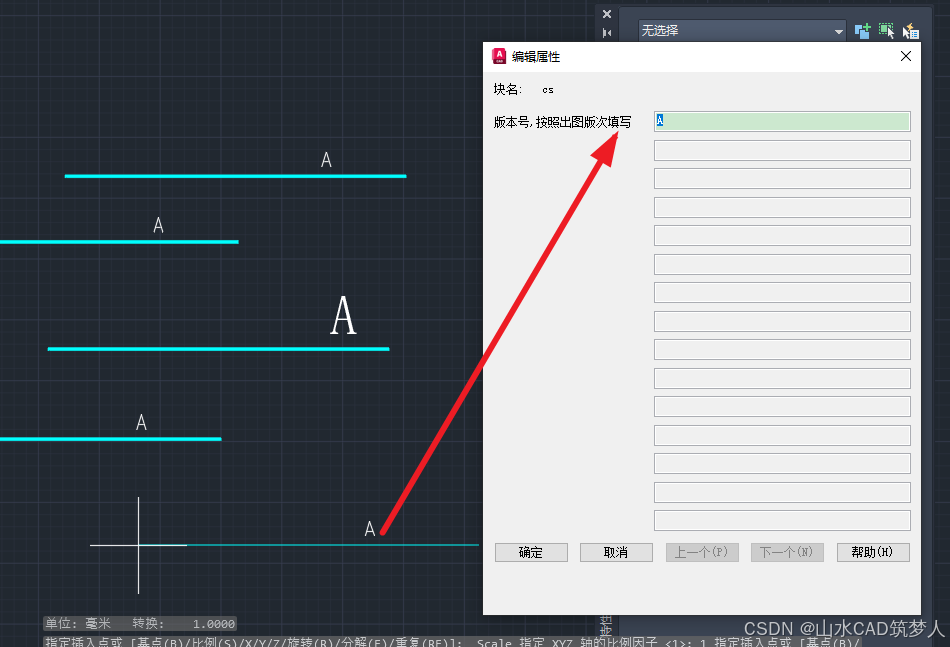
CAD插入属性块 弹窗提示输入属性值——CAD知识讲堂
插入属性块时,有时会遇到不弹窗输入属性值的情况,解决方案如下: 最好关闭块编辑器并保存,插入属性块即可弹窗。...

Redis 主要能够用来做什么
Redis(Remote Dictionary Server)是一种基于内存的键值存储数据库,它的性能极高,广泛应用于各种高并发场景。以下是 Redis 常见的用途: 1. 缓存(Cache) 作用:存储热点数据…...

MySQL GROUP BY 和 HAVING 子句中 ‘Unknown column‘ 错误的深入解析
在使用 MySQL 进行数据分析和报表生成时,GROUP BY 和 HAVING 子句是非常强大的工具。然而,很多开发者在使用它们时会遇到一个常见的错误:"Unknown column column_name in having clause"。本文将深入解析这个错误的原因,…...
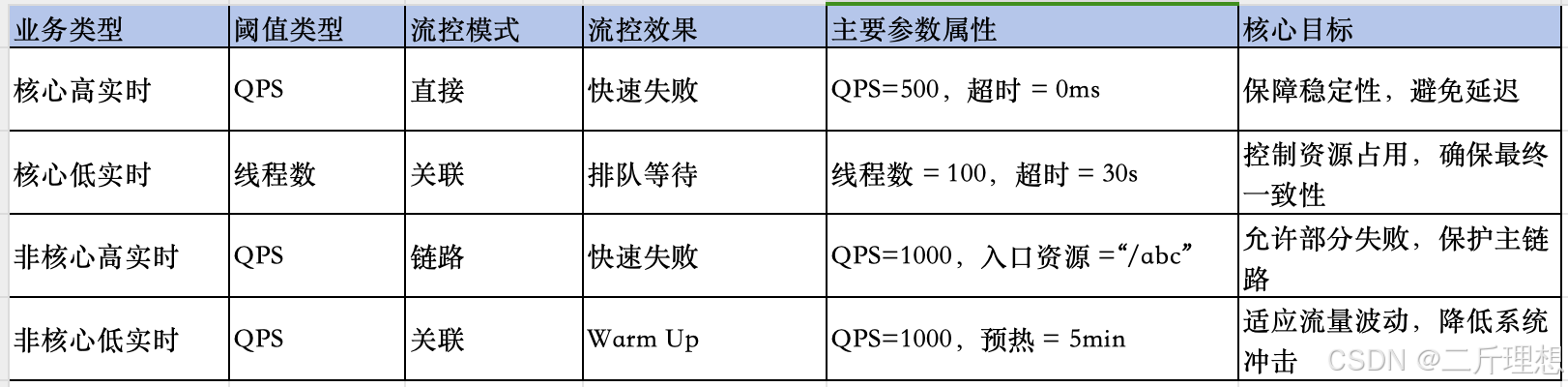
Sentinel实战(三)、流控规则之流控效果及流控小结
spring cloud Alibaba-Sentinel实战(三)、流控效果流控小结 一、流控规则:流控效果一)、流控效果:预热1、概念含义2、案例流控规则设置测试结果 二)、流控效果:排队等待1、概念含义2、案例流控规…...