verl单机多卡与多机多卡使用经验总结
文章目录
- I. 前言
- II. SFT
- 2.1 单机多卡
- 2.2 多机多卡
- III. RL (GRPO)
- 3.1 单机多卡
- 3.2 多机多卡
- 2.3 模型转换
I. 前言
在上一篇文章verl:一个集SFT与RL于一体的灵活大模型post-training框架 (快速入门)
中,初步探讨了verl框架的基础使用方法。在实际工业级模型训练场景中,分布式训练往往是必须的。在这篇文章中,将主要探讨verl框架在单机多卡和多机多卡场景下的使用细节,力求小白也能上手使用。
与上一篇文章一致,这篇文章也将分别对SFT和RL(以GRPO为例)两个场景下的分布式训练进行讨论。上一篇文章中的配置文件是几个月前的版本了,verl后续对RL的配置文件新增了一些字段,所以这篇文章中也展开介绍下。
II. SFT
2.1 单机多卡
在verl中,训练前需要先写一个yaml配置文件。我一般习惯将yaml文件放置在verl/verl/trainer/config文件夹下,当然你也可以放在任何路径下,然后像我上一篇文章讲的那样在脚本里传入一个config文件路径即可。现在假设config路径下有一个sft.yaml文件:
data:train_batch_size: 64micro_batch_size: null # will be deprecated, use micro_batch_size_per_gpumicro_batch_size_per_gpu: 1 # 单卡上的bsztrain_files: data/alpaca_zh.parquet # parquet文件val_files: data/alpaca_zh.val.parquetprompt_key: prompt # prompt字段response_key: response # response字段max_length: 12288 # 输入的最大长度为12K,即prompt + response长度最大为12Ktruncation: right # 超出12K后从右边截断balance_dp_token: Falsechat_template: null
model:partial_pretrain: models/Qwen2.5-7B-Instruct # 待微调的模型路径fsdp_config:wrap_policy:min_num_params: 0cpu_offload: False # 是否使用cpu offloadoffload_params: False # 是否将参数进行offload,如果显存较小,这两个可以都写为Trueexternal_lib: nullenable_gradient_checkpointing: True # 打开会节约一点显存trust_remote_code: Falselora_rank: 0 # Set to positive value to enable LoRA (e.g., 32)lora_alpha: 16 # LoRA scaling factortarget_modules: all-linear # Target modules for LoRA adaptationuse_liger: False
optim:lr: 1e-6 # 学习率betas: [0.9, 0.95]weight_decay: 0.01warmup_steps_ratio: 0.1clip_grad: 1.0
ulysses_sequence_parallel_size: 2
use_remove_padding: True
trainer:default_local_dir: verl_sft/Qwen25_7b_sft # 训练后的模型的保存路径default_hdfs_dir: null # change the hdfs path hereresume_path: nullproject_name: ""experiment_name: ""total_epochs: 3 # epoch数save_freq: 100 # 多少个step后保存模型,这里可以根据你数据集数量重新算一下total_training_steps: nulllogger: ['console']seed: 1
接着,自己新写一个运行脚本run_sft.sh放到script文件夹下:
set -xCONFIG_PATH="/xxx/verl/verl/trainer/config/sft.yaml" # 刚刚写的脚本,这里应该写绝对路径nproc_per_node=8 # 单个机器的卡数量torchrun --standalone --nnodes=1 --nproc_per_node=$nproc_per_node --master_port=65536 \-m verl.trainer.fsdp_sft_trainer \--config_path=$CONFIG_PATH# bash scripts/run_sft.sh 2>&1 | tee -a scripts/log/sft_log_file.txt
然后
bash scripts/run_sft.sh 2>&1 | tee -a scripts/log/sft_log_file.txt
就可以启动单机多卡任务了,相关的训练日志保存在scripts/log/sft_log_file.txt。
在训练中我一般使用swanlab来记录相关日志,如需使用,只需将配置文件中logger的属性值改为['console', 'swanlab']即可。修改后再次运行时会提示登录账号,如果不想登录可做如下设置:
export SWANLAB_MODE=local # 包含四种模式:cloud云端跟踪模式(默认)、cloud-only仅云端跟踪本地不保存文件、local本地跟踪模式、disabled完全不记录用于debug
export SWANLAB_LOG_DIR=/xxx/RL/swanlab_log # 设置本地日志存储路径
设置后由于各种乱七八糟的原因,可能不会直接生效。我解决的办法是直接修改源码,找到verl/verl/utils/tracking.py:

2.2 多机多卡
SFT的多机多卡实现十分简单。将数据集、模型、verl文件夹在多个机器上安装布置好,然后每个机器上都写一个run_multi_node_7b_sft.sh脚本:
set -xnnodes=4 # 机器数量
nproc_per_node=8 # 每台机器上的卡数量
CONFIG_PATH="verl/verl/trainer/config/sft.yaml" # 这里一定要修改成你自己机器上的绝对路径
MAIN_NODE_IP=00.00.00.00 # head机器的ip,可以是第一台机器的ip
node_rank=0 # 这台机器的rank,第一台为0,剩下的依次为123
port=8324python3 -m torch.distributed.run --nnodes=$nnodes --nproc_per_node=$nproc_per_node \--node_rank=$node_rank --master_addr=$MAIN_NODE_IP --master_port=$port \-m verl.trainer.fsdp_sft_trainer \--config_path=$CONFIG_PATH# bash scripts/run_multi_node_7b_sft.sh 2>&1 | tee -a scripts/log/qwen_7b_sft.txt
这里假设有4台机器,4台机器的上述脚本只有node_rank不一致,其他均保持一致。
启动多机多卡训练任务的方式是依次在各台机器上运行:
bash scripts/run_multi_node_7b_sft.sh 2>&1 | tee -a scripts/log/qwen_7b_sft.txt
模型日志和ckpt最后都会保存在MAIN_NODE_IP对应的机器上。
III. RL (GRPO)
跑GRPO的话,这里就直接使用网络上比较常见的gsm8k数据集。从huggingface上下载到本地后一定记得使用verl提供的代码对数据进行处理:
import re
import os
import datasetsdef extract_solution(solution_str):solution = re.search("#### (\\-?[0-9\\.\\,]+)", solution_str)assert solution is not Nonefinal_solution = solution.group(0)final_solution = final_solution.split('#### ')[1].replace(',', '')return final_solutionif __name__ == '__main__':data_source = 'data/gsm8k'dataset = datasets.load_dataset(data_source, 'main')train_dataset = dataset['train']test_dataset = dataset['test']instruction_following = "Let's think step by step and output the final answer after \"####\"."# add a row to each data item that represents a unique iddef make_map_fn(split):def process_fn(example, idx):question_raw = example.pop('question')question = question_raw + ' ' + instruction_followinganswer_raw = example.pop('answer')solution = extract_solution(answer_raw)data = {"data_source": data_source,"prompt": [{"role": "user","content": question,}],"ability": "math","reward_model": {"style": "rule","ground_truth": solution},"extra_info": {'split': split,'index': idx,'answer': answer_raw,"question": question_raw,}}return datareturn process_fntrain_dataset = train_dataset.map(function=make_map_fn('train'), with_indices=True)test_dataset = test_dataset.map(function=make_map_fn('test'), with_indices=True)train_dataset.to_parquet('data/gsm8k_train.parquet')test_dataset.to_parquet('data/gsm8k_test.parquet')
上述代码中将question进行了包装:
[{"role": "user","content": question,
}]
这样处理的原因是后续在训练时会对prompt添加对话模板,如果私人数据集中prompt字段是str格式,一定一定要提前处理一下变成上述格式,不然会有致命错误。
3.1 单机多卡
与SFT一样,这里同样需要写一个yaml配置文件,假设路径为verl/verl/trainer/config/grpo_trainer.yaml:
data:tokenizer: nulltrain_files: data/gsm8k_train.parquet # 数据集路径val_files: data/gsm8k_test.parquet # 同上prompt_key: prompt # prompt字段max_prompt_length: 512 # prompt的最大长度max_response_length: 512 # response的最大长度train_batch_size: 64 # bszval_batch_size: null # DEPRECATED: Validation datasets are sent to inference engines as a whole batch, which will schedule the memory themselvesreturn_raw_input_ids: False # This should be set to true when the tokenizer between policy and rm differsreturn_raw_chat: Falseshuffle: True # 是否打乱数据集filter_overlong_prompts: False # for large-scale dataset, filtering overlong prompts could be timeconsuming. You should disable this and set `truncation='left'truncation: error # 截断策略,这里一般选error,保证prompt长度小于max_prompt_lengthimage_key: imagesactor_rollout_ref:hybrid_engine: Truemodel:path: models/Qwen2.5-7B-Instruct # SFT模型路径external_lib: nulloverride_config: { }enable_gradient_checkpointing: Trueuse_remove_padding: Trueactor:strategy: fsdp # This is for backward-compatibilityppo_mini_batch_size: 64ppo_micro_batch_size: null # will be deprecated, use ppo_micro_batch_size_per_gpuppo_micro_batch_size_per_gpu: 1use_dynamic_bsz: True # False则启用梯度累积ppo_max_token_len_per_gpu: 16384 # n * ${data.max_prompt_length} + ${data.max_response_length}grad_clip: 1.0clip_ratio: 0.2entropy_coeff: 0.001use_kl_loss: True # True for GRPOuse_torch_compile: True # False to disable torch compilekl_loss_coef: 0.04 # for grpo,kl_loss的系数kl_loss_type: low_var_kl # for grpoppo_epochs: 1shuffle: Falseulysses_sequence_parallel_size: 2 # sp sizecheckpoint:contents: ['model', 'hf_model', 'optimizer', 'extra'] # with 'hf_model' you can save whole model as hf format, now only use sharded model checkpoint to save spaceoptim:lr: 1e-6 # 学习率lr_warmup_steps: -1 # Prioritized. Negative values mean delegating to lr_warmup_steps_ratio.lr_warmup_steps_ratio: 0.1 # the total steps will be injected during runtimemin_lr_ratio: null # only useful for warmup with cosinewarmup_style: cosine # select from constant/cosinetotal_training_steps: -1 # must be override by programfsdp_config:wrap_policy:# transformer_layer_cls_to_wrap: Nonemin_num_params: 0param_offload: Trueoptimizer_offload: Truefsdp_size: -1ref:fsdp_config:param_offload: Truewrap_policy:# transformer_layer_cls_to_wrap: Nonemin_num_params: 0log_prob_micro_batch_size: null # will be deprecated, use log_prob_micro_batch_size_per_gpulog_prob_micro_batch_size_per_gpu: nulllog_prob_use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}log_prob_max_token_len_per_gpu: ${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}ulysses_sequence_parallel_size: ${actor_rollout_ref.actor.ulysses_sequence_parallel_size} # sp sizerollout:name: vllmtemperature: 0.9top_k: -1 # 0 for hf rollout, -1 for vllm rollouttop_p: 0.95use_fire_sampling: False # https://arxiv.org/abs/2410.21236prompt_length: ${data.max_prompt_length} # not use for opensourceresponse_length: ${data.max_response_length}# for vllm rolloutdtype: bfloat16 # should align with FSDPgpu_memory_utilization: 0.8ignore_eos: Falseenforce_eager: True # vllm 0.8.1需要关闭free_cache_engine: True # vllm 0.8.1需要关闭load_format: dummy_dtensortensor_model_parallel_size: 4max_num_batched_tokens: 12288max_model_len: 12288max_num_seqs: 1024log_prob_micro_batch_size: null # will be deprecated, use log_prob_micro_batch_size_per_gpulog_prob_micro_batch_size_per_gpu: nulllog_prob_use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}log_prob_max_token_len_per_gpu: ${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}disable_log_stats: Trueenable_chunked_prefill: False # may get higher throughput when set to True. When activated, Please increase max_num_batched_tokens or decrease max_model_len.# for hf rolloutdo_sample: True# number of responses (i.e. num sample times)n: 16 # > 1 for grpoval_kwargs:# sampling parameters for validationtop_k: -1 # 0 for hf rollout, -1 for vllm rollouttop_p: 1.0temperature: 0n: 1do_sample: False # default eager for validationcritic:strategy: fsdpoptim:lr: 1e-6lr_warmup_steps_ratio: 0. # the total steps will be injected during runtimemin_lr_ratio: null # only useful for warmup with cosinewarmup_style: constant # select from constant/cosinetotal_training_steps: -1 # must be override by programmodel:path: ~/models/deepseek-llm-7b-chattokenizer_path: ${actor_rollout_ref.model.path}override_config: { }external_lib: ${actor_rollout_ref.model.external_lib}enable_gradient_checkpointing: Trueuse_remove_padding: Falsefsdp_config:param_offload: Falseoptimizer_offload: Falsewrap_policy:# transformer_layer_cls_to_wrap: Nonemin_num_params: 0fsdp_size: -1ppo_mini_batch_size: ${actor_rollout_ref.actor.ppo_mini_batch_size}ppo_micro_batch_size: null # will be deprecated, use ppo_micro_batch_size_per_gpuppo_micro_batch_size_per_gpu: nullforward_micro_batch_size: ${critic.ppo_micro_batch_size}forward_micro_batch_size_per_gpu: ${critic.ppo_micro_batch_size_per_gpu}use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}ppo_max_token_len_per_gpu: 32768 # (${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}) * 2forward_max_token_len_per_gpu: ${critic.ppo_max_token_len_per_gpu}ulysses_sequence_parallel_size: 1 # sp sizeppo_epochs: ${actor_rollout_ref.actor.ppo_epochs}shuffle: ${actor_rollout_ref.actor.shuffle}grad_clip: 1.0cliprange_value: 0.5checkpoint:contents: ['model', 'hf_model', 'optimizer', 'extra'] # with 'hf_model' you can save whole model as hf format, now only use sharded model checkpoint to save spacereward_model:enable: Falsestrategy: fsdpmodel:input_tokenizer: ${actor_rollout_ref.model.path} # set this to null if the chat template is identicalpath: ~/models/FsfairX-LLaMA3-RM-v0.1external_lib: ${actor_rollout_ref.model.external_lib}use_remove_padding: Falsefsdp_config:wrap_policy:min_num_params: 0param_offload: Falsefsdp_size: -1micro_batch_size: null # will be deprecated, use micro_batch_size_per_gpumicro_batch_size_per_gpu: null # set a numbermax_length: nullulysses_sequence_parallel_size: 1 # sp sizeuse_dynamic_bsz: ${critic.use_dynamic_bsz}forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}reward_manager: naivecustom_reward_function:path: nullname: compute_scorealgorithm:gamma: 1.0lam: 1.0adv_estimator: grpokl_penalty: kl # how to estimate kl divergencekl_ctrl:type: fixedkl_coef: 0.04trainer:balance_batch: Truetotal_epochs: 1total_training_steps: nullproject_name: "xxx"experiment_name: "xxx"logger: ['console', 'swanlab'] # remove wandbval_generations_to_log_to_wandb: 0nnodes: 1n_gpus_per_node: 8save_freq: 10# auto: find the last ckpt to resume. If can't find, start from scratchresume_mode: disable # or disable or resume_path if val_before_train: Falseresume_from_path: nulltest_freq: 0critic_warmup: 0default_hdfs_dir: nulldel_local_ckpt_after_load: Falseremove_previous_ckpt_in_save: Falsedefault_local_dir: output/Qwen2.5-7B-GRPO # 模型的保存路径max_actor_ckpt_to_keep: nullmax_critic_ckpt_to_keep: null
接着,同样写一个启动脚本,假设为scripts/run_grpo.sh:
set -xexport VLLM_ATTENTION_BACKEND=XFORMERS
export CUDA_LAUNCH_BLOCKING=1nproc_per_node=8 # 卡数量
CONFIG_PATH="verl/verl/trainer/config/grpo_trainer.yaml" # 替换为刚刚配置文件的绝对路径python3 -m verl.trainer.main_ppo \--config_path=$CONFIG_PATH# bash scripts/run_grpo.sh 2>&1 | tee -a scripts/log/grpo_log_file.txt
最后启动训练:
bash scripts/run_grpo.sh 2>&1 | tee -a scripts/log/grpo_log_file.txt
3.2 多机多卡
RL的多机多卡比SFT稍微复杂一点。首先要做的依然是在多台机器上配置好环境,同时各个机器上要同时存在数据集和模型,并且路径要保持一致,即配置文件中的路径。
这里以两台机器A和B为例,并且A为head节点,也就是启动训练的机器。接着,在2台机器上新建一个ray的启动脚本worker_start.sh:
#!/bin/bashexport VLLM_ATTENTION_BACKEND=XFORMERSHEAD_IP=192.168.0.1 # 这里为head节点的IP,也就是机器A的IP
LOCAL_IP=192.168.0.1 # 这里为本机ip
PORT=8888 # 这里的port需要和前面的保持一致# ray status
# 判断本机IP是否为Head节点的IP
if [ "$LOCAL_IP" == "$HEAD_IP" ]; thenecho "本机 $LOCAL_IP 是Head节点,启动Head节点..."ray start --head --port=$PORT --min-worker-port=20122 --max-worker-port=20999
elseecho "本机 $LOCAL_IP 是Worker节点,连接到Head节点 $HEAD_IP..."ray start --address=$POD_0_IP:$PORT --min-worker-port=20122 --max-worker-port=20999
fi
两台机器的上述脚本的唯一区别就是LOCAL_IP,其他均保持不变。然后,首先在机器A上运行该脚本,接着机器B上运行该脚本。启动完毕后,在机器A上可以使用ray status命令查看当前有几台机器。
最后,在机器A上启动多机多卡训练:
set -xexport VLLM_ATTENTION_BACKEND=XFORMERS
export NCCL_DEBUG=INFOCONFIG_PATH="verl/verl/trainer/config/multi_node_grpo.yaml" # 这里替换为绝对路径python3 -m verl.trainer.main_ppo \--config_path=$CONFIG_PATH# bash scripts/run_multi_node_7b_grpo.sh 2>&1 | tee -a scripts/log/multi_node_7b_grpo.txt
multi_node_grpo.yaml和之前单机多卡配置文件的区别就是nnodes(机器数量)和n_gpus_per_node(每台机器上的GPU数量)两个参数,修改一下即可。
2.3 模型转换
RL训练完毕后模型会被保存在多个机器上,并且不是hf格式,因此需要转换。具体来说,将其他所有机器上某个step文件夹下model开头的pt文件都移到head机器中,然后运行如下脚本进行转换:
from typing import List, Tuple, Dict
import re
import os
import torch
import argparse
from transformers import AutoConfig, AutoModelForCausalLM, AutoModelForTokenClassification, AutoTokenizer
from concurrent.futures import ThreadPoolExecutor
from torch.distributed._tensor import DTensor, Shard, Placementdef merge_by_placement(tensors: List[torch.Tensor], placement: Placement):if placement.is_replicate():return tensors[0]elif placement.is_partial():raise NotImplementedError("Partial placement is not supported yet")elif placement.is_shard():return torch.cat(tensors, dim=placement.dim).contiguous()else:raise ValueError(f"Unsupported placement: {placement}")if __name__ == '__main__':step = 100local_dir = f"output/Qwen2.5-7B-GRPO/global_step_{step}/actor" # 这里需要替换为绝对路径hf_path = f"output/Qwen2.5-7B-GRPO/global_step_{step}/actor/huggingface" # 这里需要替换为绝对路径output_path = f"models/Qwen2.5-7B-Instruct-GRPO" # 这里需要替换为绝对路径# copy rank zero to find the shape of (dp, fsdp)rank = 0world_size = 0for filename in os.listdir(local_dir):match = re.match(r"model_world_size_(\d+)_rank_0\.pt", filename)if match:world_size = match.group(1) break assert world_size, "No model file with the proper format"state_dict = torch.load(os.path.join(local_dir, f'model_world_size_{world_size}_rank_{rank}.pt'), map_location='cpu')pivot_key = sorted(list(state_dict.keys()))[0]weight = state_dict[pivot_key]assert isinstance(weight, torch.distributed._tensor.DTensor)# get sharding infodevice_mesh = weight.device_meshmesh = device_mesh.meshmesh_dim_names = device_mesh.mesh_dim_namesprint(f'Got device mesh {mesh}, mesh_dim_names {mesh_dim_names}')assert mesh_dim_names in (('fsdp',),), f'Unsupported mesh_dim_names {mesh_dim_names}'if 'tp' in mesh_dim_names:# fsdp * tptotal_shards = mesh.shape[-1] * mesh.shape[-2]mesh_shape = (mesh.shape[-2], mesh.shape[-1])else:# fsdptotal_shards = mesh.shape[-1]mesh_shape = (mesh.shape[-1],)print(f'Processing model shards with {total_shards} {mesh_shape} in total')model_state_dict_lst = []model_state_dict_lst.append(state_dict)model_state_dict_lst.extend([""] * (total_shards - 1))def process_one_shard(rank):model_path = os.path.join(local_dir, f'model_world_size_{world_size}_rank_{rank}.pt')state_dict = torch.load(model_path, map_location='cpu', weights_only=False)model_state_dict_lst[rank] = state_dictreturn state_dictwith ThreadPoolExecutor(max_workers=min(32, os.cpu_count())) as executor:for rank in range(1, total_shards):executor.submit(process_one_shard, rank)state_dict = {}param_placements: Dict[str, List[Placement]] = {}keys = set(model_state_dict_lst[0].keys())for key in keys:state_dict[key] = []for model_state_dict in model_state_dict_lst:try:tensor = model_state_dict.pop(key)except:print("-"*30)print(model_state_dict)if isinstance(tensor, DTensor):state_dict[key].append(tensor._local_tensor.bfloat16())placements = tuple(tensor.placements)# replicated placement at dp dimension can be discardedif mesh_dim_names[0] == 'dp':placements = placements[1:]if key not in param_placements:param_placements[key] = placementselse:assert param_placements[key] == placementselse:state_dict[key] = tensor.bfloat16()del model_state_dict_lstfor key in sorted(state_dict):if not isinstance(state_dict[key], list):print(f"No need to merge key {key}")continue# merge shardsplacements: Tuple[Shard] = param_placements[key]if len(mesh_shape) == 1:# 1-D list, FSDP without TPassert len(placements) == 1shards = state_dict[key]state_dict[key] = merge_by_placement(shards, placements[0])else:# 2-D list, FSDP + TPraise NotImplementedError("FSDP + TP is not supported yet")print('Writing to local disk')hf_path = os.path.join(local_dir, 'huggingface')config = AutoConfig.from_pretrained(hf_path)if 'ForTokenClassification' in config.architectures[0]:auto_model = AutoModelForTokenClassificationelif 'ForCausalLM' in config.architectures[0]:auto_model = AutoModelForCausalLMelse:raise NotImplementedError(f'Unknown architecture {config["architectures"]}')with torch.device('meta'):model = auto_model.from_config(config, torch_dtype=torch.bfloat16)model.to_empty(device='cpu')print(f'Saving model to {output_path}')tokenizer = AutoTokenizer.from_pretrained(hf_path)tokenizer.save_pretrained(output_path)model.save_pretrained(output_path, state_dict=state_dict)
相关文章:
verl单机多卡与多机多卡使用经验总结
文章目录 I. 前言II. SFT2.1 单机多卡2.2 多机多卡 III. RL (GRPO)3.1 单机多卡3.2 多机多卡2.3 模型转换 I. 前言 在上一篇文章verl:一个集SFT与RL于一体的灵活大模型post-training框架 (快速入门) 中,初步探讨了verl框架的基础使用方法。在实际工业级…...

胶铁一体化产品介绍
•一体化结构特点介绍 胶框/铁框一体化技术最早在韩国采用,07年以来由于要求背光越做越薄。在采用0.4mm及以下厚度的LGP时,胶框及背光就会变得异常软,胶框不易组装,铁框松动等问题。 由于胶框和铁框是紧紧粘合在一起的,这正可以解…...

蓝桥杯刷题记录【并查集001】(2024)
主要内容:并查集 并查集 并查集的题目感觉大部分都是模板题,上板子!! class UnionFind:def __init__(self, n):self.pa list(range(n))self.size [1]*n self.cnt ndef find(self, x):if self.pa[x] ! x:self.pa[x] self.fi…...

基于BusyBox构建ISO镜像
1. 准备 CentOS 7.9 3.10.0-957.el7.x86_64VMware Workstation 建议:系统内核<3.10.0 使用busybox < 1.33.2版本 2. 安装busybox # 安装依赖 yum install syslinux xorriso kernel-devel kernel-headers glibc-static ncurses-devel -y# 下载 wget https://…...
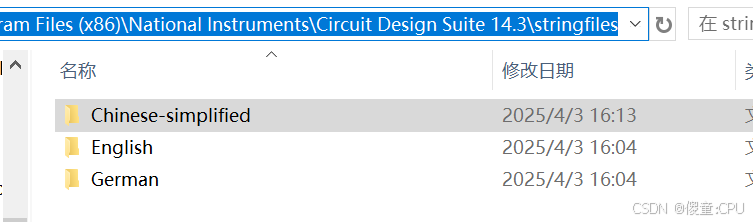
Multisim14.3的安装步骤
Multisim14.3的安装步骤 安装包链接 右击Install.exe,以管理员身份运行 激活前关闭杀毒软件 右击,以管理员身份运行 依次右键【Base Edition】、【Full Edition】、【Power ProEdition】、【Full Edition】、【Power ProEdition】,选择【…...
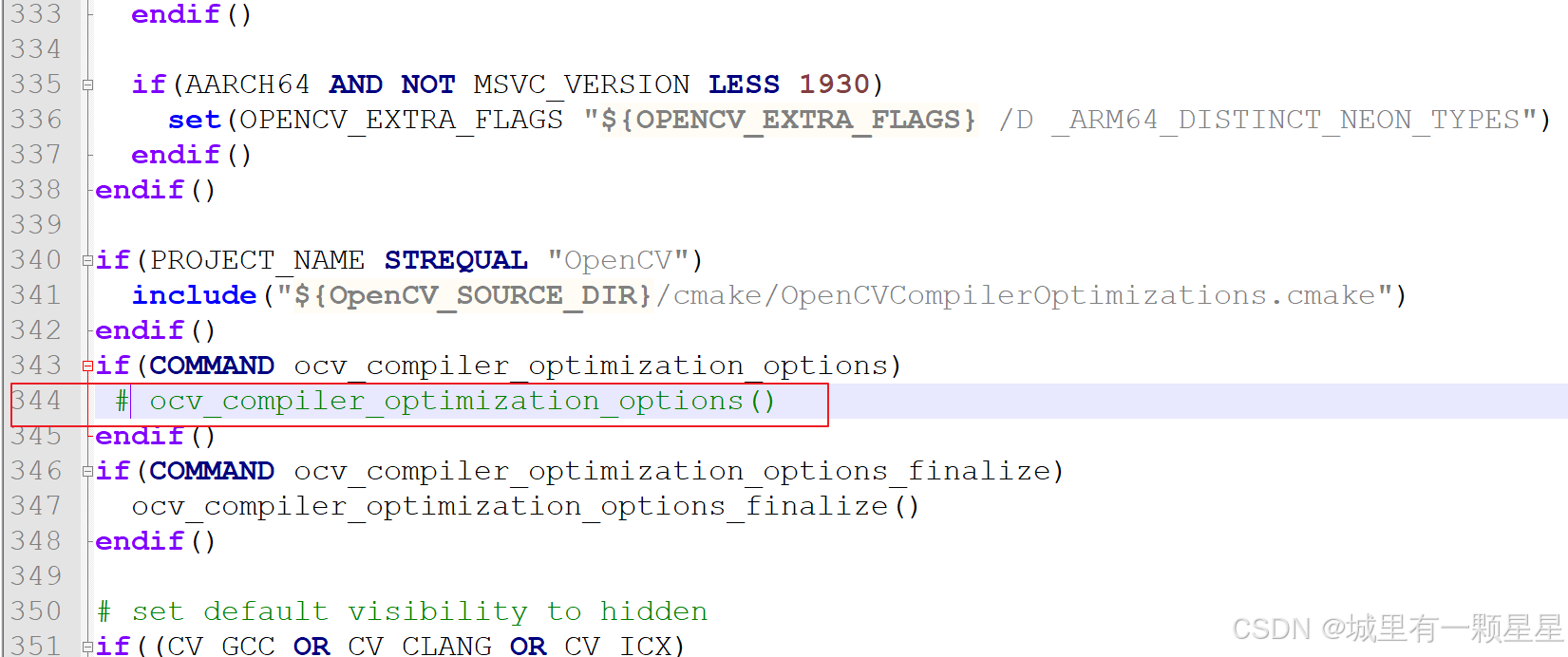
搭建环境-opencv-qt
CMake Error at cmake/OpenCVCompilerOptimizations.cmake:647 (message): Compiler doesnt support baseline optimization flags: Call Stack (most recent call first): cmake/OpenCVCompilerOptions.cmake:344 (ocv_compiler_optimization_options) CMakeList 解决方…...

【愚公系列】《高效使用DeepSeek》050-外汇交易辅助
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...
SparkAudio 是什么,和其他的同类 TTS 模型相比有什么优势
欢迎来到涛涛聊AI 在当今数字化时代,音频处理技术已经成为人们生活和工作中不可或缺的一部分。无论是制作有声读物、开发语音助手,还是进行影视配音,我们都离不开高效、精准的音频处理工具。然而,传统的音频处理技术往往存在诸多…...

jvm 的attach 和agent机制
Java 的 Attach 和 Agent 机制在实际应用中得到了广泛的成功应用,尤其是在监控、调试、性能分析、故障排查等方面。以下是这两种机制在实际场景中的一些成功应用案例: 1. 性能监控与分析 Java Agent 和 Attach 机制广泛应用于性能监控和分析࿰…...
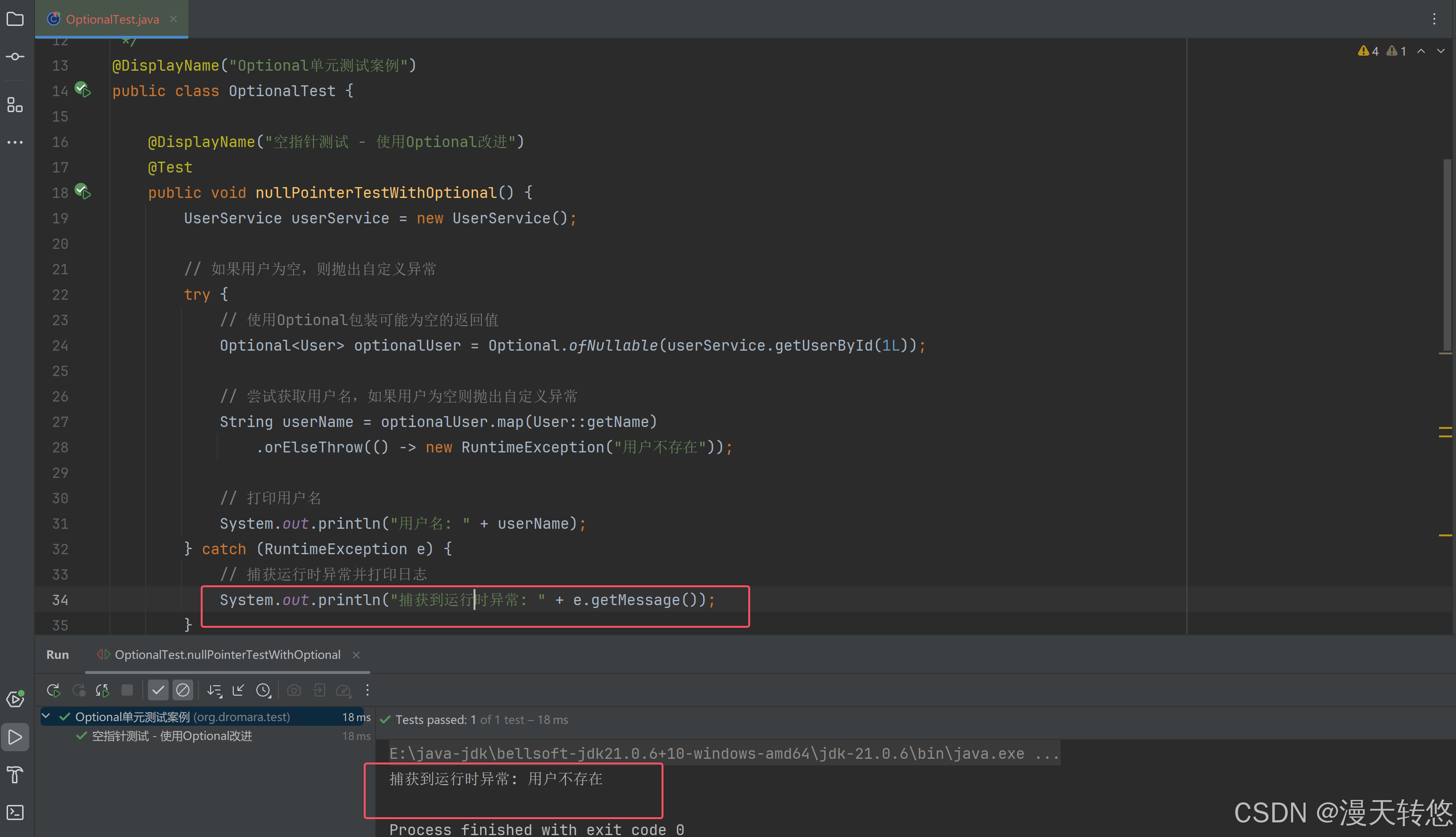
Java 8 到 Java 21 系列之 Optional 类型:优雅地处理空值(Java 8)
Java 8 到 Java 21 系列之 Optional 类型:优雅地处理空值(Java 8) 系列目录 Java8 到 Java21 系列之 Lambda 表达式:函数式编程的开端(Java 8)Java 8 到 Java 21 系列之 Stream API:数据处理的…...
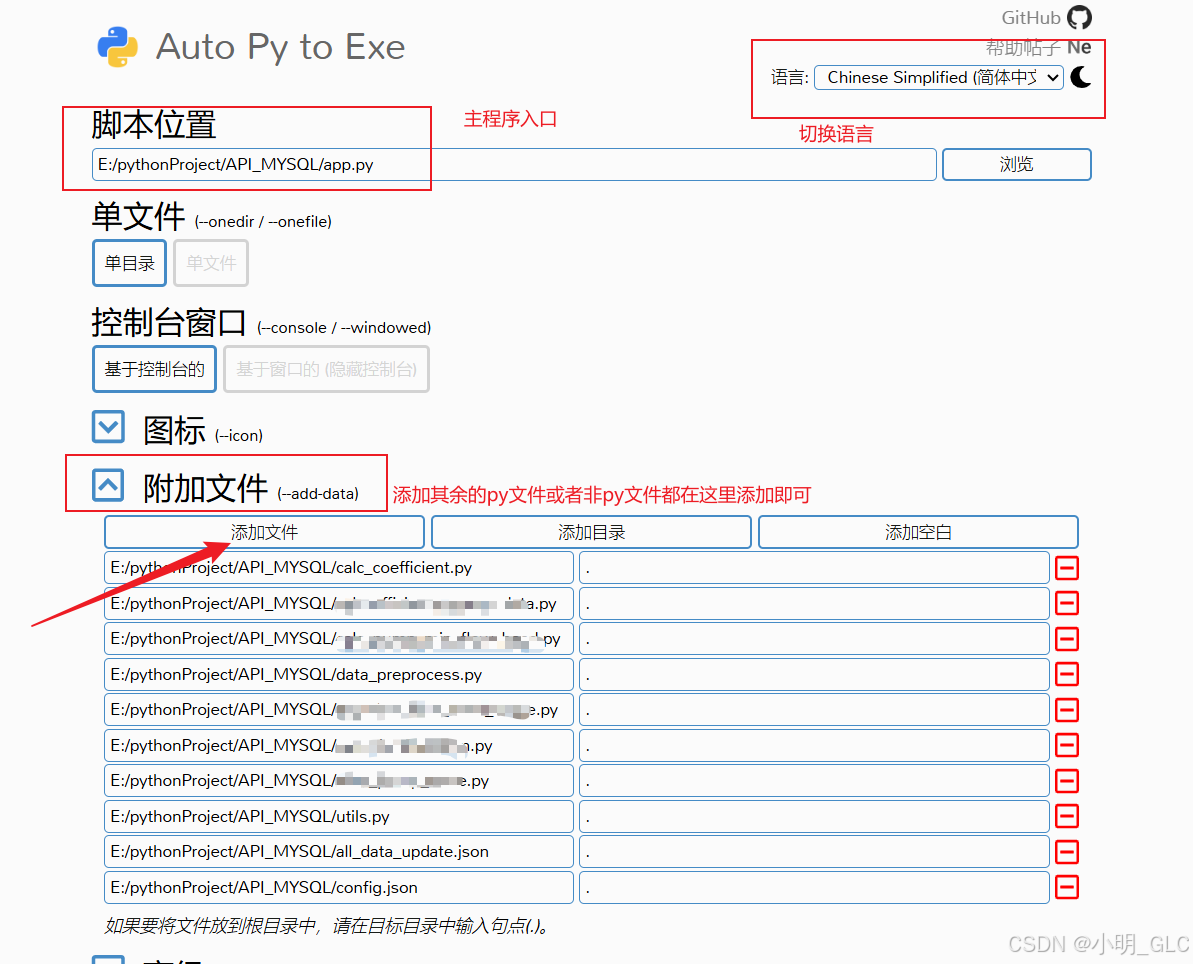
py文件打包为exe可执行文件,涉及mysql连接失败
py文件打包为exe可执行文件,涉及mysql连接失败 项目场景:使用flask框架封装算法接口,并使用pyinstaller打包为exe文件。使用pyinstaller打包多文件的场景,需要自己手动去.spec文件中添加其他文件,推荐使用auto-py-to-e…...

Ubuntu 系统 Docker 中搭建 CUDA cuDNN 开发环境
CUDA 是 NVIDIA 推出的并行计算平台和编程模型,利用 GPU 多核心架构加速计算任务,广泛应用于深度学习、科学计算等领域。cuDNN 是基于 CUDA 的深度神经网络加速库,为深度学习框架提供高效卷积、池化等操作的优化实现,提升模型训练…...
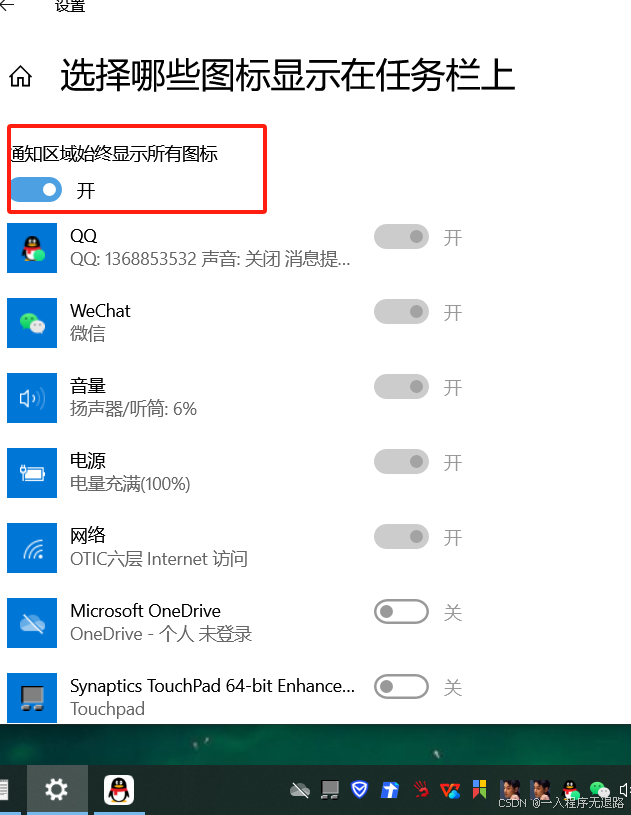
win10彻底让图标不显示在工具栏
关闭需要不显示的软件 打开 例此时我关闭了IDEA的显示 如果说只是隐藏,鼠标拖动一个道理 例QQ 如果说全部显示不隐藏...

Java服务端性能优化:从理论到实践的全面指南
目录 引言:性能优化的重要性 用户体验视角 性能优化的多维度 文章定位与价值 Java代码层性能优化方案 实例创建与管理优化 单例模式的合理应用 批量操作策略 并发编程优化 Future模式实现异步处理 线程池合理使用 I/O性能优化 NIO提升I/O性能 压缩传输…...
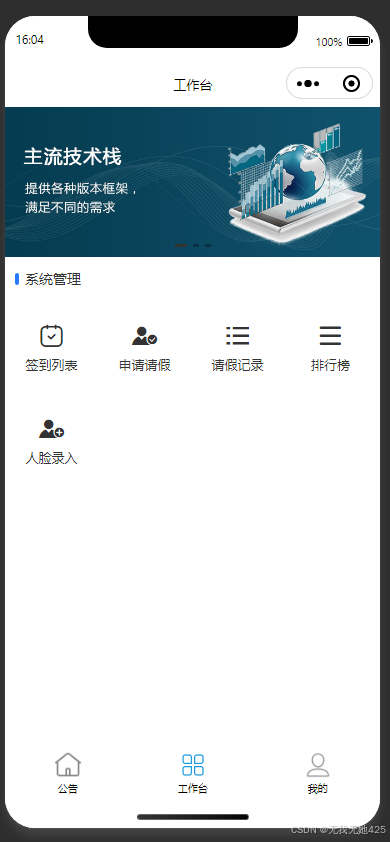
人脸识别和定位别的签到系统
1、功能 基于人脸识别及定位的宿舍考勤管理小程序 (用户:宿舍公告、宿舍考勤查询、宿舍考勤(人脸识别、gps 定 位)、考勤排行、请假申请 、个人中心 管理员:宿舍管理、宿舍公告管理 学生信息管理、请假审批、发布宿舍…...

基于YOLOv8的热力图生成与可视化:支持自定义模型与置信度阈值的多维度分析
目标检测是计算机视觉领域的重要研究方向,而YOLO(You Only Look Once)系列算法因其高效性和准确性成为该领域的代表性方法。YOLOv8作为YOLO系列的最新版本,在目标检测任务中表现出色。然而,传统的目标检测结果通常以边…...

echarts+HTML 绘制3d地图,加载散点+散点点击事件
首先,确保了解如何本地引入ECharts库。 html 文件中引入本地 echarts.min.js 和 echarts-gl.min.js。 可以通过官网下载或npm安装,但这里直接下载JS文件更简单。需要引入 echarts.js 和 echarts-gl.js,因为3D地图需要GL模块。 接下来是HTM…...
Design Compiler:库特征分析(ALIB)
相关阅读 Design Compilerhttps://blog.csdn.net/weixin_45791458/category_12738116.html?spm1001.2014.3001.5482 简介 在使用Design Compiler时,可以对目标逻辑库进行特征分析,并创建一个称为ALIB的伪库(可以被认为是缓存)&…...

便携式雷达信号模拟器 —— 打造实战化电磁环境的新利器
在现代战争中,雷达信号的侦察与干扰能力直接关系到作战的成败。为了提升雷达侦察与干扰装备的实战能力,便携式雷达信号模拟器作为一款高性能设备应运而生,为雷达装备的训练、测试和科研提供了不可或缺的支持。 核心功能 便携式雷达信号模拟…...

TypeScript工程集成
以下是关于 TypeScript 工程集成 的系统梳理,涵盖基础配置、进阶优化、开发规范及实际场景的注意事项,帮助我们构建高效可靠的企业级 TypeScript 项目: 一、基础知识点 1. 项目初始化与配置 tsconfig.json 核心配置:{"compilerOptions": {"target": &…...

《P1246 编码》
题目描述 编码工作常被运用于密文或压缩传输。这里我们用一种最简单的编码方式进行编码:把一些有规律的单词编成数字。 字母表中共有 26 个字母 a,b,c,⋯,z,这些特殊的单词长度不超过 6 且字母按升序排列。把所有这样的单词放在一起,按字典…...

基于Transformer框架实现微调后Qwen/DeepSeek模型的非流式批量推理
在基于LLamaFactory微调完具备思维链的DeepSeek模型之后(详见《深入探究LLamaFactory推理DeepSeek蒸馏模型时无法展示<think>思考过程的问题》),接下来就需要针对微调好的模型或者是原始模型(注意需要有一个本地的模型文件,全量微调就是saves下面的文件夹,如果是LoRA,…...

什么是 CSSD?
文章目录 一、什么是 CSSD?CSSD 的职责 二、CSSD 是如何工作的?三、CSSD 为什么会重启节点?情况一:网络和存储都断联(失联)情况二:收到其他节点对自己的踢出通知(外部 fencing&#…...

服务器磁盘io性能监控和优化
服务器磁盘io性能监控和优化 全文-服务器磁盘io性能监控和优化 全文大纲 磁盘IO性能评价指标 IOPS:每秒IO请求次数,包括读和写吞吐量:每秒IO流量,包括读和写 磁盘IO性能监控工具 iostat:监控各磁盘IO性能,…...

CentOS Linux升级内核kernel方法
目录 一、背景 二、准备工作 三、升级内核 一、背景 某些情况需要对Linux发行版自带的内核kernel可能版本较低,需要对内核kernel进行升级。例如:CentOS 7.x 版本的系统默认内核是3.10.0,该版本的内核在Kubernetes社区有很多已知的Bug&#…...
入门)
使用MetaGPT 创建智能体(1)入门
metagpt一个多智能体框架 官网:MetaGPT | MetaGPT 智能体 在大模型领域,智能体通常指一种基于大语言模型(LLM)构建的自主决策系统,能够通过理解环境、规划任务、调用工具、迭代反馈等方式完成复杂目标。具备主动推理…...

AF3 OpenFoldMultimerDataset类解读
AlphaFold3 data_modules 模块的 OpenFoldMultimerDataset 类是 OpenFoldDataset 类的子类,专门用于 多链蛋白质(Multimer) 数据集的训练。它通过引入 AlphaFold Multimer 论文 中描述的过滤步骤,来实现多链蛋白质的训练。这个类扩展了父类的功能,特别是为了处理多链蛋白质…...
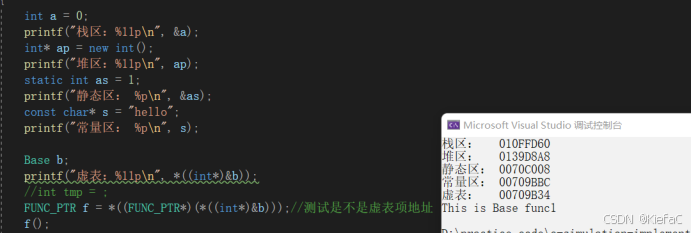
【C++】多态功能细节问题分析
多态是在不同继承关系的类对象去调用同一函数,产生了不同的行为。值得注意的是,虽然多态在功能上与隐藏是类似的,但是还是有较大区别的,本文也会进行多态和隐藏的差异分析。 在继承中要构成多态的条件 1.1必须通过基类的指针或引用…...

[CISSP] [5] 保护资产安全
数据状态 1. 数据静态存储(Data at Rest) 指存储在磁盘、数据库、存储设备上的数据,例如: 硬盘、SSD服务器、数据库备份存储、云存储 安全措施 加密(Encryption):如 AES-256 加密磁盘和数据…...

EIP-712:类型化结构化数据的哈希与签名
1. 引言 以太坊 EIP-712: 类型化结构化数据的哈希与签名,是一种用于对类型化结构化数据(而不仅仅是字节串)进行哈希和签名 的标准。 其包括: 编码函数正确性的理论框架,类似于 Solidity 结构体并兼容的结构化数据规…...