42.C++11-右值引用与移动语义/完美转发
⭐上篇文章:41.C++哈希6(哈希切割/分片/位图/布隆过滤器与海量数据处理场景)-CSDN博客
⭐本篇代码:c++学习/22.C++11新特性的使用 · 橘子真甜/c++-learning-of-yzc - 码云 - 开源中国 (gitee.com)
⭐标⭐是比较重要的部分
目录
一. 右值引用的概念
1.1 左值引用与右值引用
1.2 右值引用引用左值,左值引用引用右值
编辑 1.3 右值与左值在函数参数中的匹配⭐
二. 纯右值与将亡值
三. 移动语义 ⭐
3.1 右值引用做函数参数 - 移动构造
3.2 右值引用做函数参数 - 移动赋值
3.3 右值引用与返回值问题
四. 完美转发 ⭐
4.1 万能引用
4.2 std::forward实现完美转发
五. 引用总结
一. 右值引用的概念
1.1 左值引用与右值引用
引用是给对象取别名,左值引用是给左值取别名,右值引用是给右值取别名。
左值一般为用户定义的可修改的变量,而右值一般是常量,返回值,表达式等临时变量。
一般认为:左值是能够取地址的,而右值无法取地址。
一般使用&&符号去引用右值。如下面代码中的常量10,表达式x+y
#include <iostream>
using namespace std;int main()
{// 1.使用 &去引用左值int a = 10, b = 5;int &a1 = a, &b1 = b;cout << a1 << " " << b1 << endl;// 2.使用&&去引用右值int x = 10, y = 20;int &&x1 = 10;int &&x2 = x + y;cout << x1 << " " << x2 << endl;x1 = 12;x2 = 10;cout << x1 << " " << x2 << endl;return 0;
}1.2 右值引用引用左值,左值引用引用右值
一般来说,这两种操作都是无法直接实现的。
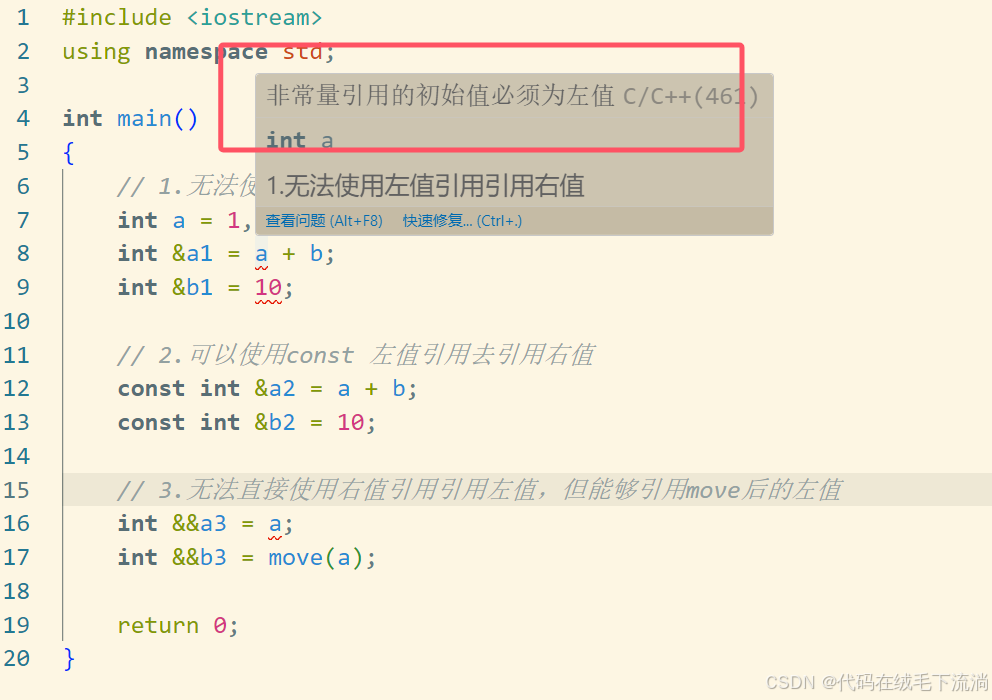
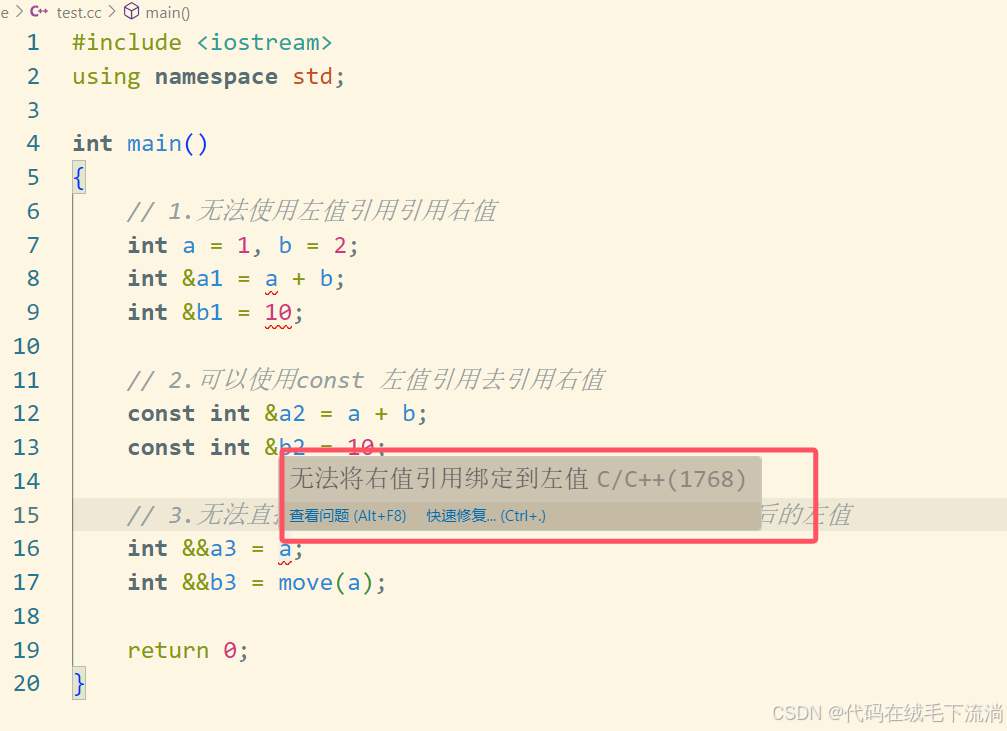 1.3 右值与左值在函数参数中的匹配⭐
1.3 右值与左值在函数参数中的匹配⭐
假如有三个重载函数,一个参数为左值引用,一个为const 左值引用,一个为右值引用(没有const 右值引用,因为右值引用过程有资源转移)。
使用这些函数去调用左值/const左值与右值,最终会匹配哪一个函数呢?测试代码如下:
#include <iostream>
using namespace std;template <class T>
void f1(T &a)
{cout << "void f1(T &a)" << endl;
}template <class T>
void f1(const T &a)
{cout << "void f1(const T &a)" << endl;
}template <class T>
void f1(T &&a)
{cout << "void f1(T &&a)" << endl;
}int main()
{int a = 1, b = 2;const int c = 10;f1(a);f1(c);f1(a + b);f1(10);return 0;
}首先根据代码推测一下运行的结果:第一条应该是T&a,第二条是const T&a,第三条/四条是T&&a
运行结果如下:
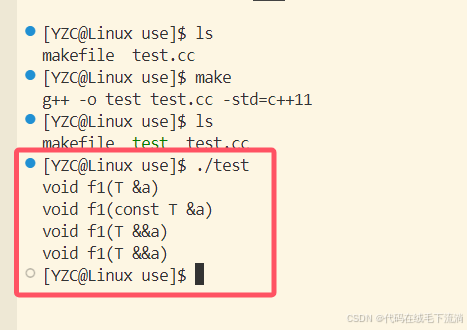
可以看到,推测的结果是正确的!
如果我将右值引用的重载函数注释掉呢?理论来说,此时调用右值应该匹配的是const版本。
运行结果如下:
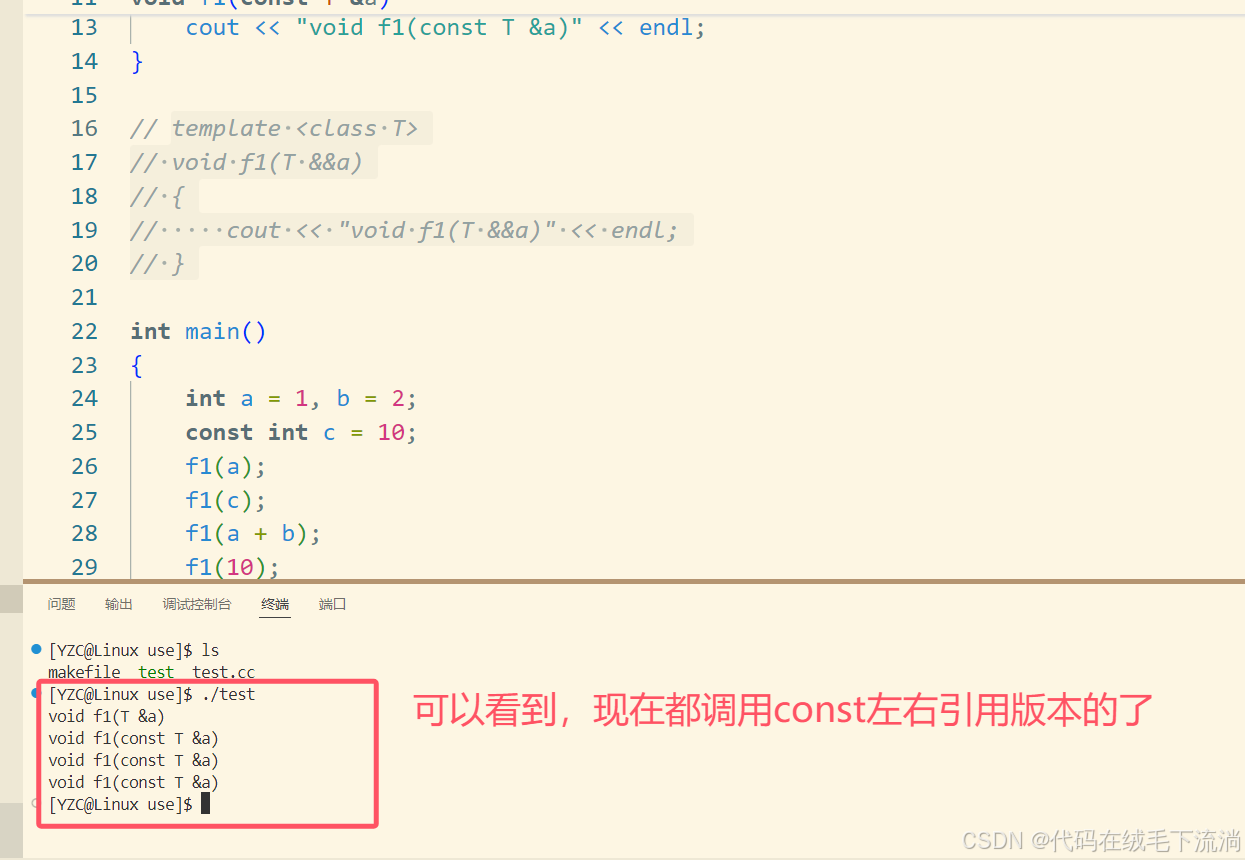
这表示:编译器可以识别右值与左值。
二. 纯右值与将亡值
纯右值是指纯粹的右值:比如常量( 10,"hello" ),非引用类型的返回值( int func() ),表达式(a +b),临时对象。这些值一般无标识,无法取地址。
而将亡值是即将销毁的左值,比如move(左值),右值引用的函数调用。将亡值常用来实现移动语义。
三. 移动语义 ⭐
移动语义指的是,将一个对象的资源直接转移到另一个对象中,减少深拷贝的消耗。通过移动语义来实现右值引用作为参数和右值引用返回,从而达到减少数据的拷贝。
移动语义移动的值是不再使用的值,如传值返回,传入临时对象/右值对象做函数参数。
使用移动语义的时候,一般将函数标记为noexcept,即不会抛出异常。这样编译器就会减少异常处理的代码,并且执行更为激进的操作,比如直接转移资源以提高性能
3.1 右值引用做函数参数 - 移动构造
测试代码如下:分别使用左值引用拷贝构造和右值引用实现移动构造。
#include <iostream>
#include <cstring>
using namespace std;class String
{
public:String(const char *str = ""){if (nullptr == str)str = "";_str = new char[strlen(str) + 1];strcpy(_str, str);}// 右值引用,但是是深拷贝String(const String &s): _str(new char[strlen(s._str) + 1]){cout << " String(const String &s) 深拷贝" << endl;strcpy(_str, s._str);}String(String &&s) noexcept: _str(s._str){cout << " String(String &&s) noexcept 移动拷贝" << endl;s._str = nullptr;}~String(){if (_str)delete[] _str;}private:char *_str;
};String f(const char *str)
{return String(str);
}int main()
{String s("123");cout << " ------------------------------" << endl;String s1(s);cout << " ------------------------------" << endl;// 由于编译器优化,直接转移资源,不调用移动构造cout << " ------------------------------" << endl;String s2(String("临时对象-右值"));cout << " ------------------------------" << endl;cout << " ------------------------------" << endl;String s3(f("临时返回值-右值"));cout << " ------------------------------" << endl;// 通过move强制使用移动构造cout << " ------------------------------" << endl;String s4(move(s1));cout << " ------------------------------" << endl;return 0;
}测试结果如下:

这样一来,我们就能够避免传入右值对象的时候使用深拷贝这种开销大的操作了。
假如我们将移动构造注释掉,就会发生使用右值对象传参的时候调用深拷贝。
测试如下:
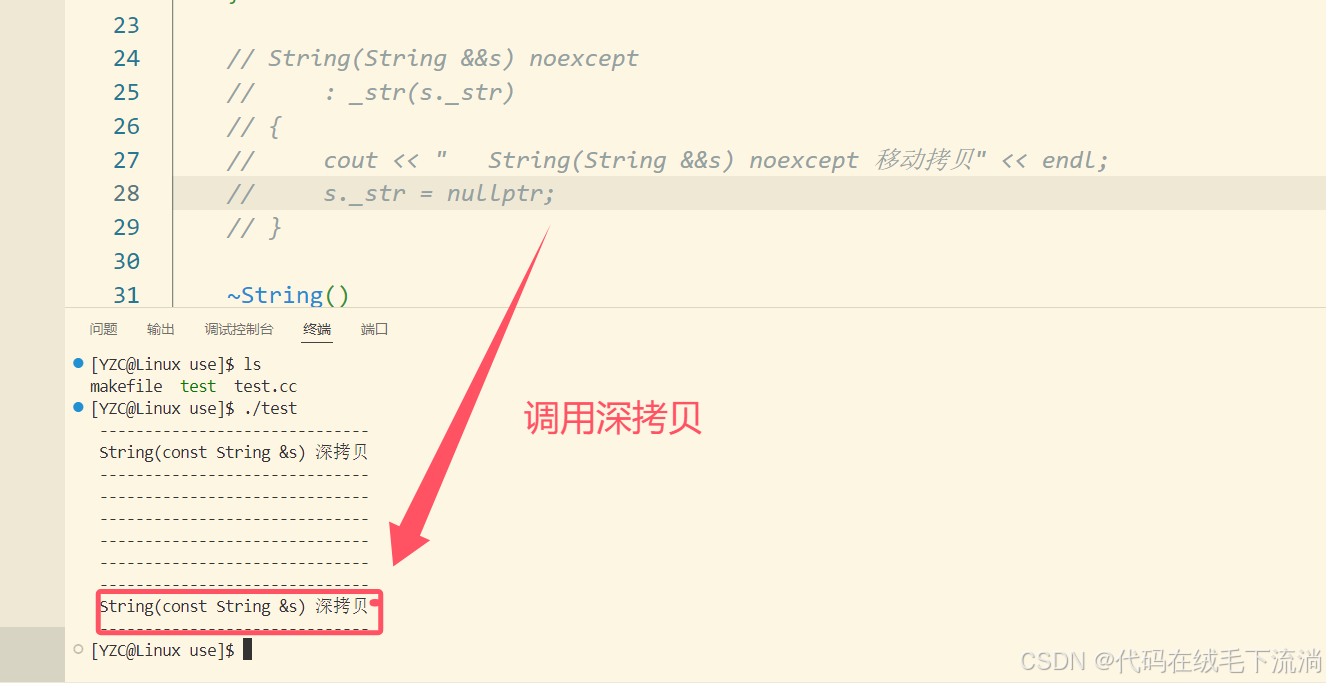
3.2 右值引用做函数参数 - 移动赋值
类中除了拷贝函数,还有重载赋值运算符。此时如果不使用右值引用做参数,并实现移动拷贝。传入右值就会调用开销大的深拷贝!
#include <iostream>
#include <cstring>
using namespace std;class String
{
public:String(const char *str = ""){if (nullptr == str)str = "";_str = new char[strlen(str) + 1];strcpy(_str, str);}// 右值引用,但是是深拷贝String(const String &s): _str(new char[strlen(s._str) + 1]){cout << " String(const String &s) 深拷贝" << endl;strcpy(_str, s._str);}String(String &&s) noexcept: _str(s._str){cout << " String(String &&s) noexcept 移动拷贝" << endl;s._str = nullptr;}String &operator=(const String &s){if (this != &s){cout << "左值-String& operator=(const String& s)-深拷贝" << endl;delete[] _str; // 防止内存泄漏_str = new char[strlen(s._str) + 1];strcpy(_str, s._str);}return *this;}String &operator=(String &&s) noexcept // 不能使用const,否则无法swap{cout << "右值-- String& operator=(String&& s) -- 移动拷贝赋值效率高)" << endl;swap(_str, s._str);return *this;}~String(){if (_str)delete[] _str;}private:char *_str;
};String f(const char *str)
{return String(str);
}int main()
{String s("123");String s5;s5 = s;s5 = String("临时对象-右值");s5 = f("临时返回值-右值");return 0;
}运行结果如下:
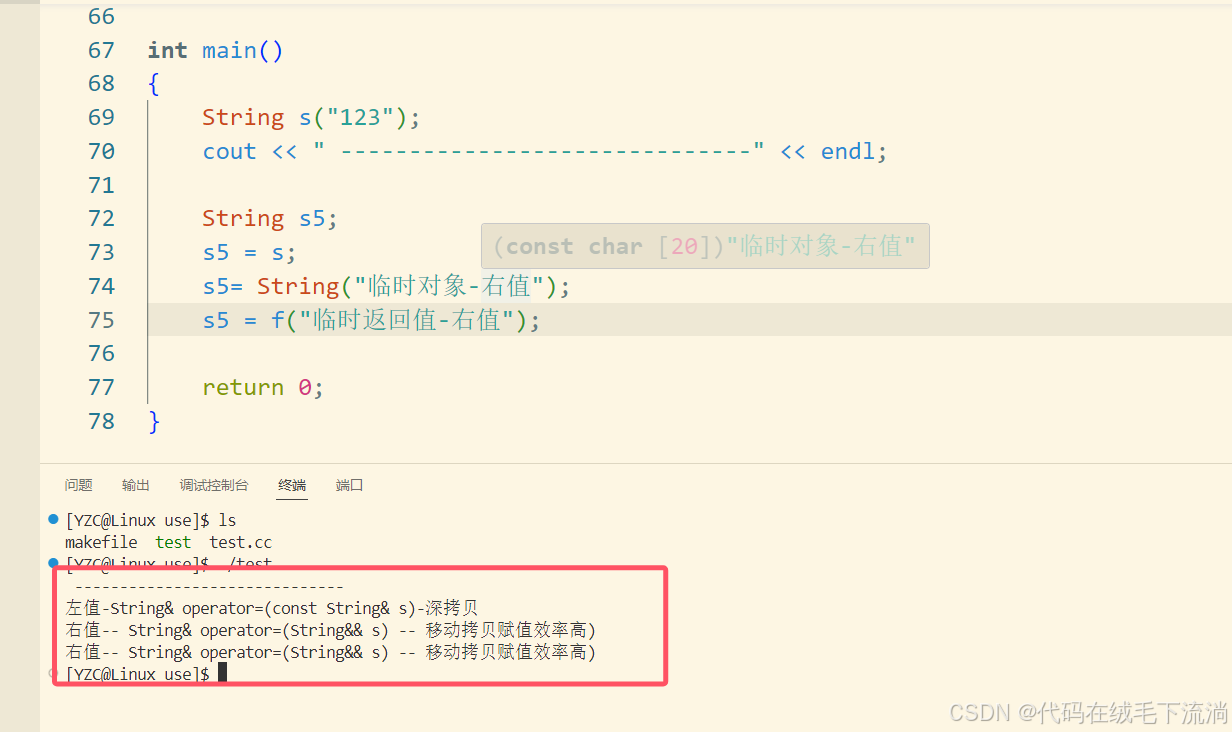
可以看到,当传入的值是右值时候,会调用移动赋值来减少深拷贝,从而提高效率。
同理:如果注释了移动赋值,传入右值就会调用深拷贝!
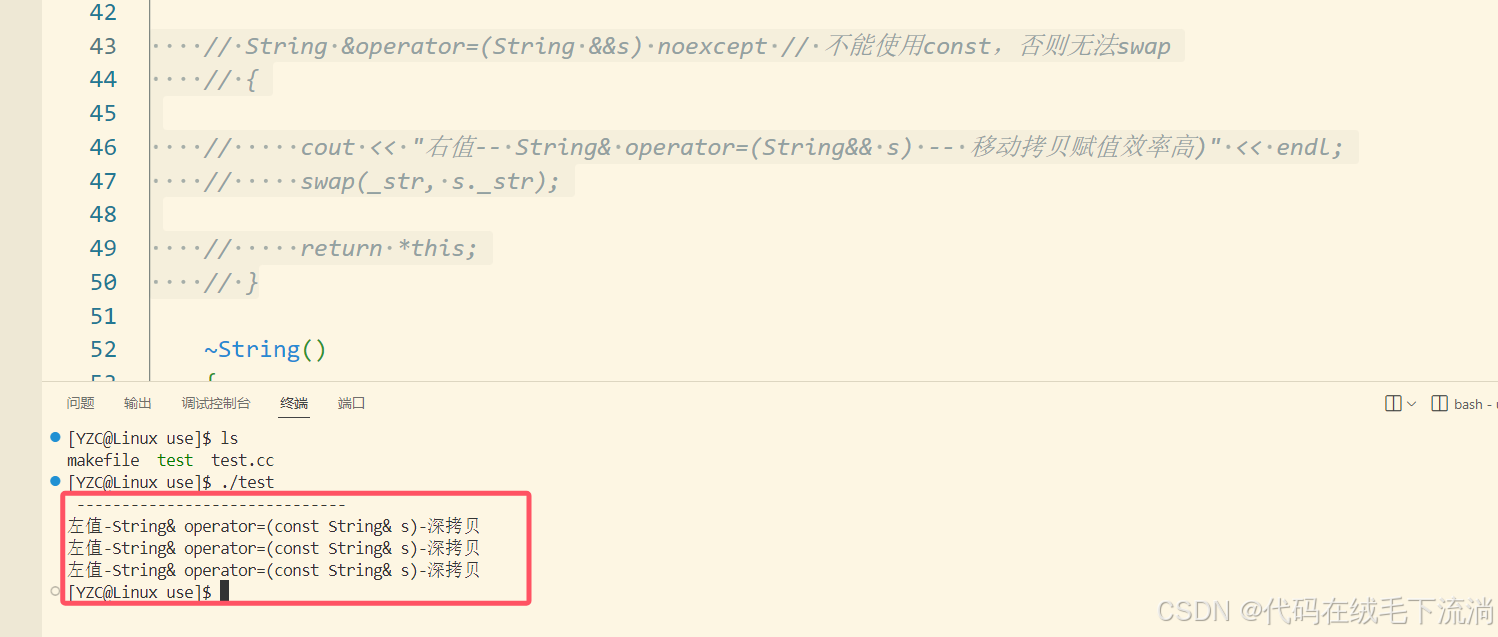
3.3 右值引用与返回值问题
正常的传值返回,首先需要深拷贝构造一个临时对象,然后在根据临时对象深拷贝获取我们需要的结果。
而有了右值引用,传值返回的时候就只需要一次深拷贝和一次移动赋值即可。1 深拷贝构造一个临时对象。2 调用移动赋值/拷贝将数据转移给返回的对象。
四. 完美转发 ⭐
完美转发是:在函数模板中,完全依照依照模板的参数类型,将参数传递给函数模板中调用的另一个函数。即保留参数的原始属性和类型传递。
为何需要完美转发:因为在函数传参的过程中,有可能将右值看成左值,这样就不会触发移动语义,造成性能的损失。
4.1 万能引用
当使用 T&&作为模板参数的时候,可以匹配任意类型的左值和右值。
如下面的代码:
#include <iostream>
using namespace std;void Fun(int &x) { cout << "lvalue ref" << endl; }
void Fun(int &&x) { cout << "rvalue ref" << endl; }
void Fun(const int &x) { cout << "const lvalue ref" << endl; }
void Fun(const int &&x) { cout << "const rvalue ref" << endl; }template <typename T>
void PerfectForward(T &&t)
{Fun(t); // 都调用了左值,右值引用会在第二次传参的时候,其属性丢失Fun(move(t)); // 都调用了右值,右值引用会在第二次传参的时候,其属性丢失
}int main()
{int a;PerfectForward(a); // lvalue refPerfectForward(move(a)); // rvalue refconst int b = 8;PerfectForward(b); // const lvalue refPerfectForward(move(b)); // const rvalue refreturn 0;
}虽然我们传入的值有右值,有左值。但是直接调用Func会导致传入的类型改变。Func直接传入模板的参数,只会调用左值引用的函数。而move参数只会调用右值引用的函数。
运行结果如下:

4.2 std::forward实现完美转发
使用std::forward即可实现完美转发。
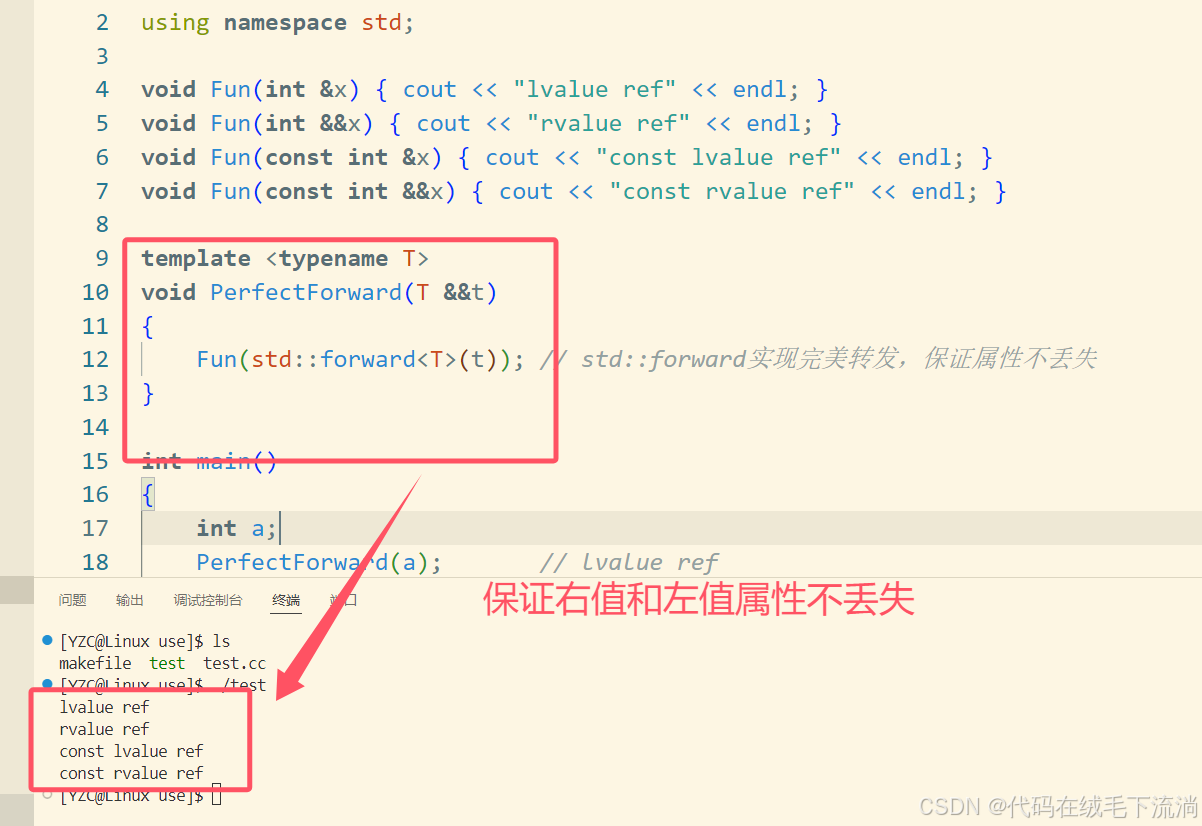
通过完美转发,可以帮助完美正确的调用右值,从而实现移动语义,减少拷贝语义带来的性能上的损失。提高代码的效率。
五. 引用总结
1 无论是左值引用还是右值引用,本质都是为了减少不必要的拷贝来提高程序的运行效率。
2 右值引用是左值引用的补充,通过移动构造/赋值减少临时对象的拷贝次数。
左值引用:
1 做参数:解决参数需要拷贝的问题
2 做返回值:用于直接返回在堆上创建的数据,减少拷贝
右值引用:
1 做参数:解决使用临时对象还需要拷贝的问题,直接将临时对象转移到我创建的对象上
2 返回值优化:减少接收返回值的时候需要两次深拷贝的问题,第二次直接将临时对象的资源转移到我接收的对象中。
相关文章:
42.C++11-右值引用与移动语义/完美转发
⭐上篇文章:41.C哈希6(哈希切割/分片/位图/布隆过滤器与海量数据处理场景)-CSDN博客 ⭐本篇代码:c学习/22.C11新特性的使用 橘子真甜/c-learning-of-yzc - 码云 - 开源中国 (gitee.com) ⭐标⭐是比较重要的部分 目录 一. 右值引用…...

LeetCode题二:判断回文
查阅资料我得到的结果远没有大佬们的做法更省时间,而且还很麻烦 我的代码(完整): class Solution:def isPalindrome(self, x: int) -> bool:# 若 x 为负数,由于负数不可能是回文数,直接返回 Falseif x < 0:return False# …...

[王阳明代数讲义]琴语言类型系统工程特性
琴语言类型系统工程特性 层展物理学组织实务与艺术与琴生生.物机.械科.技工.业研究.所软凝聚态物理开发工具包社会科学气质砥砺学人生意气场社群成员魅力场与心气微积分社会关系力学 意气实体过程图论信息编码,如来码导引 注意力机制道装Transformer架构的发展标度律…...
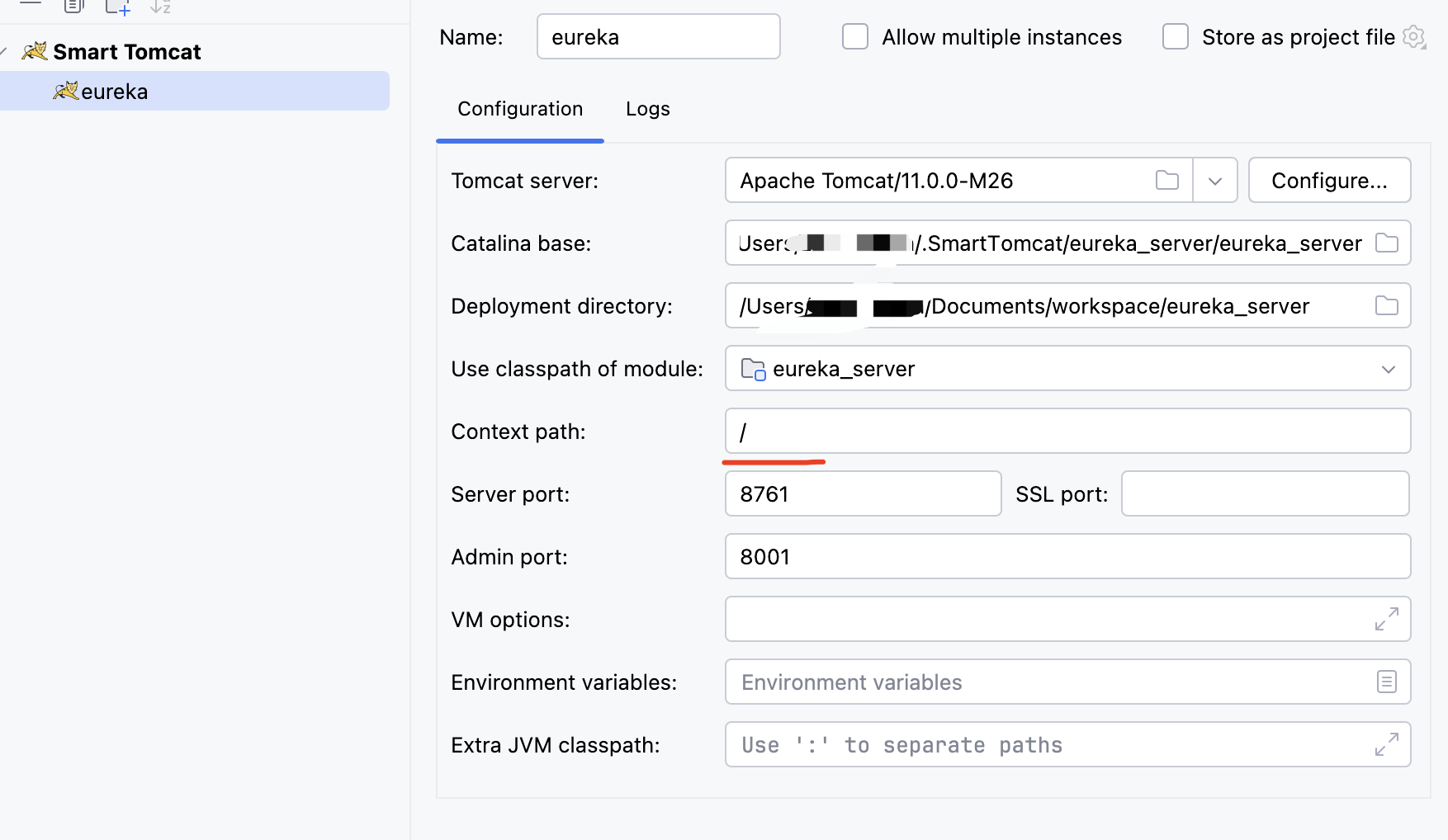
问题:tomcat下部署eureka双重路径
开发时在tomcat下启动eureka服务 客户端注册时需要地址需要注意 http://localhost:8761/eureka/eureka 后面一个eureka与tomcat context-path有关系按实际配置替换 如果不想要两个path可将tomcat context-path写为 / 建议使用 / 避免出现其他问题 如图...

JUC系列JMM学习之随笔
JUC: JUC 是 Java 并发编程的核心工具包,全称为 Java Util Concurrent,是 java.util.concurrent 包及其子包的简称。它提供了一套强大且高效的并发编程工具,用于简化多线程开发并提高性能。 CPU核心数和线程数的关系:1核处理1线程(同一时间单次) CPU内核结构: 工作内…...

React(九)React Hooks
初识Hook 我们到底为什么需要hook那? 函数组件类组件存在问题 函数组件存在的问题: import React, { PureComponent } from reactfunction HelloWorld2(props) {let message"Hello world"// 函数式组件存在的缺陷:// 1.修改message之后&a…...
)
PyTorch嵌入层(nn.Embedding)
在 PyTorch 中,nn.Embedding 层(即 model.user_embedding)除了 .weight 这个核心属性外,还有其他属性和方法。以下是完整的解析: 1. 主要属性 (1) weight(核心参数) 作用:存储所有…...

AIGC7——AIGC驱动的视听内容定制化革命:从Sora到商业化落地
引言:个性化视听时代的到来 2024年,OpenAI发布视频生成模型Sora,可生成60秒高清视频;中国团队推出的Vidu模型实现16秒镜头连贯生成。这些突破标志着AIGC正式进入高质量视听内容定制化阶段。据Gartner预测,到2027年&am…...

接上文,SpringBoot的线程池配置以及JVM监控
接上篇文章, 拿SpringBoot举个例 1.1 默认线程池的隐患 Spring Boot的Async默认使用SimpleAsyncTaskExecutor(无复用线程),频繁创建/销毁线程易引发性能问题。 1.2 自定义线程池配置 Configuration EnableAsync public class A…...

《AI大模型应知应会100篇》加餐篇:LlamaIndex 与 LangChain 的无缝集成
加餐篇:LlamaIndex 与 LangChain 的无缝集成 问题背景:在实际应用中,开发者常常需要结合多个框架的优势。例如,使用 LangChain 管理复杂的业务逻辑链,同时利用 LlamaIndex 的高效索引和检索能力构建知识库。本文在基于…...

部署大模型实战:如何巧妙权衡效果、成本与延迟?
目录 部署大模型实战:如何巧妙权衡效果、成本与延迟? 一、为什么要进行权衡? 二、权衡的三个关键维度 三、如何进行有效权衡?(实操策略) (一)明确需求场景与优先级 (…...
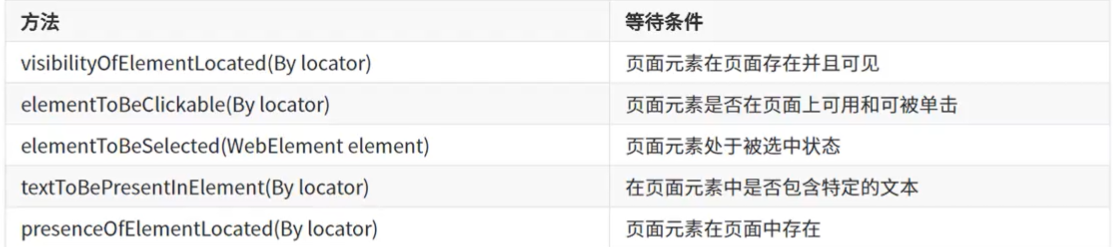
元素三大等待
硬性等待(强制等待) 线程休眠,强制等待 Thread.sleep(long millis);这是最简单的等待方式,使用time.sleep()方法来实现。在代码中强制等待一定的时间,不论元素是否已经加载完成,都会等待指定的时间后才继…...

【DY】信息化集成化信号采集与处理系统;生物信号采集处理系统一体机
MD3000-C信息化一体机生物信号采集处理系统 实验平台技术指标 01、整机外形尺寸:1680mm(L)*750mm(w)*2260mm(H); 02、实验台操作面积:750(w)*1340(L)(长*宽); 03、实验台面离地高度…...
康谋分享 | 仿真驱动、数据自造:巧用合成数据重构智能座舱
随着汽车向智能化、场景化加速演进,智能座舱已成为人车交互的核心承载。从驾驶员注意力监测到儿童遗留检测,从乘员识别到安全带状态判断,座舱内的每一次行为都蕴含着巨大的安全与体验价值。 然而,这些感知系统要在多样驾驶行为、…...
)
YOLO学习笔记 | 基于YOLOv5的车辆行人重识别算法研究(附matlab代码)
基于YOLOv5的车辆行人重识别算法研究 🥥🥥🥥🥥🥥🥥🥥🥥🥥🥥🥥🥥🥥🥥 摘要 本文提出了一种基于YOLOv5的车辆行人重识别(ReID)算法,结合目标检测与特征匹配技术,实现高效的多目标跟踪与识别。通过引入注意力机制、优化损失函数和轻量化网络结构…...

Vue 数据传递流程图指南
今天,我们探讨一下 Vue 中的组件传值问题。这不仅是我们在日常开发中经常遇到的核心问题,也是面试过程中经常被问到的重要知识点。无论你是初学者还是有一定经验的开发者,掌握这些传值方式都将帮助你更高效地构建和维护 Vue 应用 目录 1. 父…...

Node.js 与 MySQL:深入理解与高效实践
Node.js 与 MySQL:深入理解与高效实践 引言 随着互联网技术的飞速发展,Node.js 作为一种高性能的服务端JavaScript运行环境,因其轻量级、单线程和事件驱动等特点,受到了广大开发者的青睐。MySQL 作为一款开源的关系型数据库管理系统,以其稳定性和可靠性著称。本文将深入…...
)
鸿蒙NEXT开发缓存工具类(ArkTs)
import { ObjectUtil } from ./ObjectUtil;/*** 缓存工具类** 该类提供了一组静态方法,用于操作缓存数据。* 主要功能包括:获取缓存数据、存储缓存数据、删除缓存数据、检查键是否存在、判断缓存是否为空以及清空缓存。** author CSDN-鸿蒙布道师* since…...
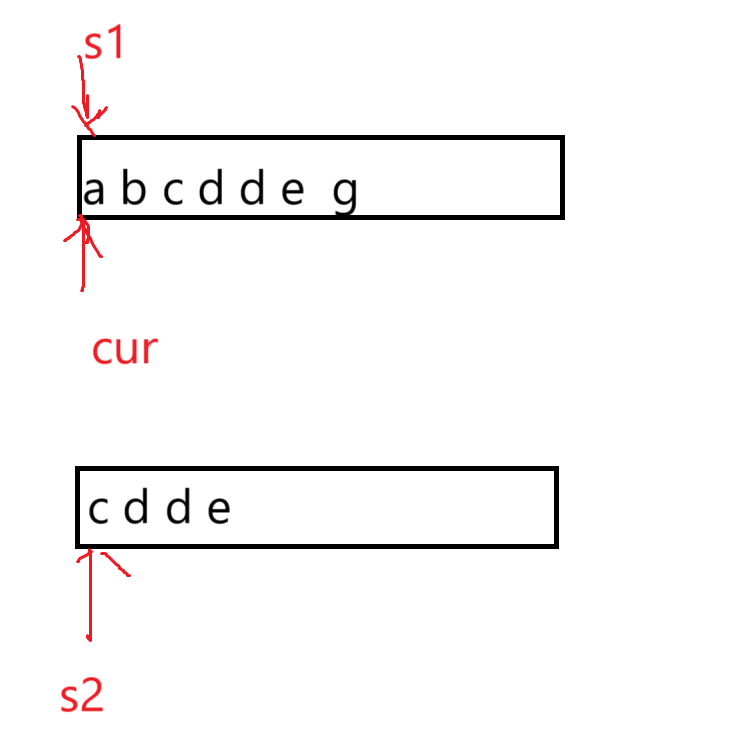
【C语言】strstr查找字符串函数
一、函数介绍 strstr 是 C 语言标准库 <string.h> 中的字符串查找函数,用于在主字符串中查找子字符串的首次出现位置。若找到子串,返回其首次出现的地址;否则返回 NULL。它是处理字符串匹配问题的核心工具之一。 二、函数原型 char …...

使用pkexec 和其策略文件安全提权执行外部程序
一、pkexec 基本机制 pkexec 是 Linux 桌面环境下基于 PolicyKit 的安全提权工具,可通过交互式图形界面获取用户授权后,以 root 权限执行指定程序。其核心特点包括: 图形化密码输入:调用时自动弹出系统认证对话框&a…...

NVIDIA显卡
NVIDIA显卡作为全球GPU技术的标杆,其产品线覆盖消费级、专业级、数据中心、移动计算等多个领域,技术迭代贯穿架构创新、AI加速、光线追踪等核心方向。以下从技术演进、产品矩阵、核心技术、生态布局四个维度展开深度解析: 一、技术演进&…...
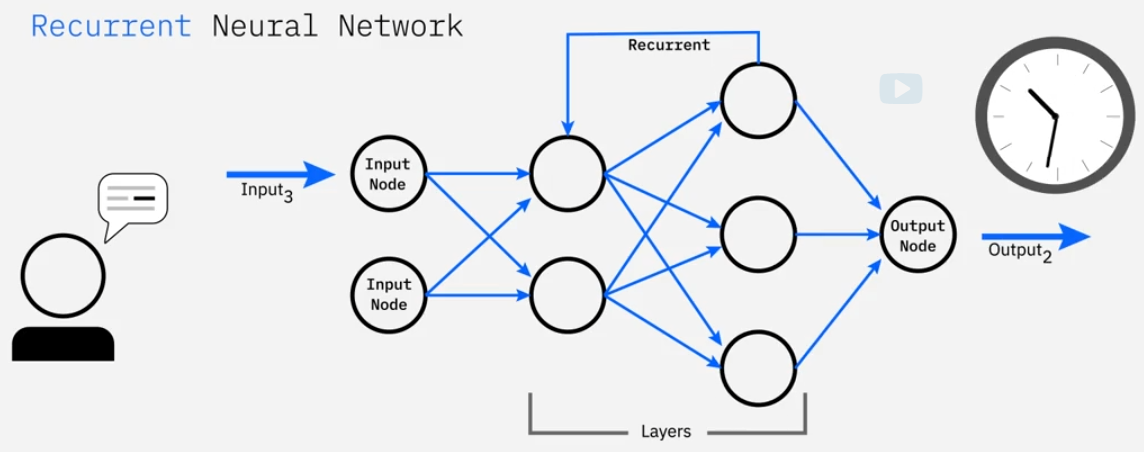
机器学习、深度学习和神经网络
机器学习、深度学习和神经网络 术语及相关概念 在深入了解人工智能(AI)的工作原理以及它的各种应用之前,让我们先区分一下与AI密切相关的一些术语和概念:人工智能、机器学习、深度学习和神经网络。这些术语有时会被交替使用&#…...

数字孪生在智慧城市中的前端呈现与 UI 设计思路
一、数字孪生技术在智慧城市中的应用与前端呈现 数字孪生技术通过创建城市的虚拟副本,实现了对城市运行状态的实时监控、分析与预测。在智慧城市中,数字孪生技术的应用包括交通流量监测、环境质量分析、基础设施管理等。其前端呈现主要依赖于Web3D技术、…...

黑莓手机有望回归:搭载 Android 15、支持 AI
据 3 月 31 日快科技消息,有博主称一家英国的初创公司正悄悄努力复活 BlackBerry Classic 及 OnwardMobility 未完成的产品。 从爆料的信息看,黑莓新手机将具备 5G、AMOLED 显示屏、12GB RAM 和 256GB 或 512GB 存储空间等高端配置,同时运行 …...

Android OpenGLES 360全景图片渲染(球体内部)
概述 360度全景图是一种虚拟现实技术,它通过对现实场景进行多角度拍摄后,利用计算机软件将这些照片拼接成一个完整的全景图像。这种技术能够让观看者在虚拟环境中以交互的方式查看整个周围环境,就好像他们真的站在那个位置一样。在Android设备…...

LETTERS(DFS)
【题目描述】 给出一个rowcolrowcol的大写字母矩阵,一开始的位置为左上角,你可以向上下左右四个方向移动,并且不能移向曾经经过的字母。问最多可以经过几个字母。 【输入】 第一行,输入字母矩阵行数RR和列数SS,1≤R,S≤…...

嵌入式海思Hi3861连接华为物联网平台操作方法
1.1 实验目的 快速演示 1、认识轻量级HarmonyOS——LiteOS-M 2、初步掌握华为云物联网平台的使用 3、快速驱动海思Hi3861 WIFI芯片,连接互联网并登录物联网平台...
:3D机房大屏全景解析)
CMDB平台(进阶篇):3D机房大屏全景解析
在数字化转型的浪潮中,数据中心作为企业信息架构的核心,其高效、智能的管理成为企业竞争力的关键因素之一,其运维管理方式也正经历着革命性的变革。传统基于二维平面图表的机房监控方式已难以满足现代企业对运维可视化、智能化的需求。乐维CM…...
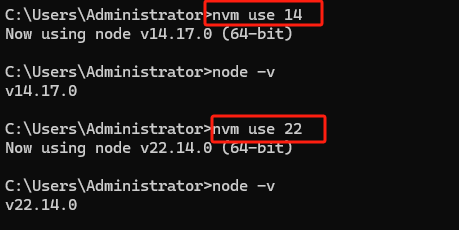
NVM 多版本Node.js 管理全指南(Windows系统)
🧑 博主简介:CSDN博客专家、全栈领域优质创作者、高级开发工程师、高级信息系统项目管理师、系统架构师,数学与应用数学专业,10年以上多种混合语言开发经验,从事DICOM医学影像开发领域多年,熟悉DICOM协议及…...
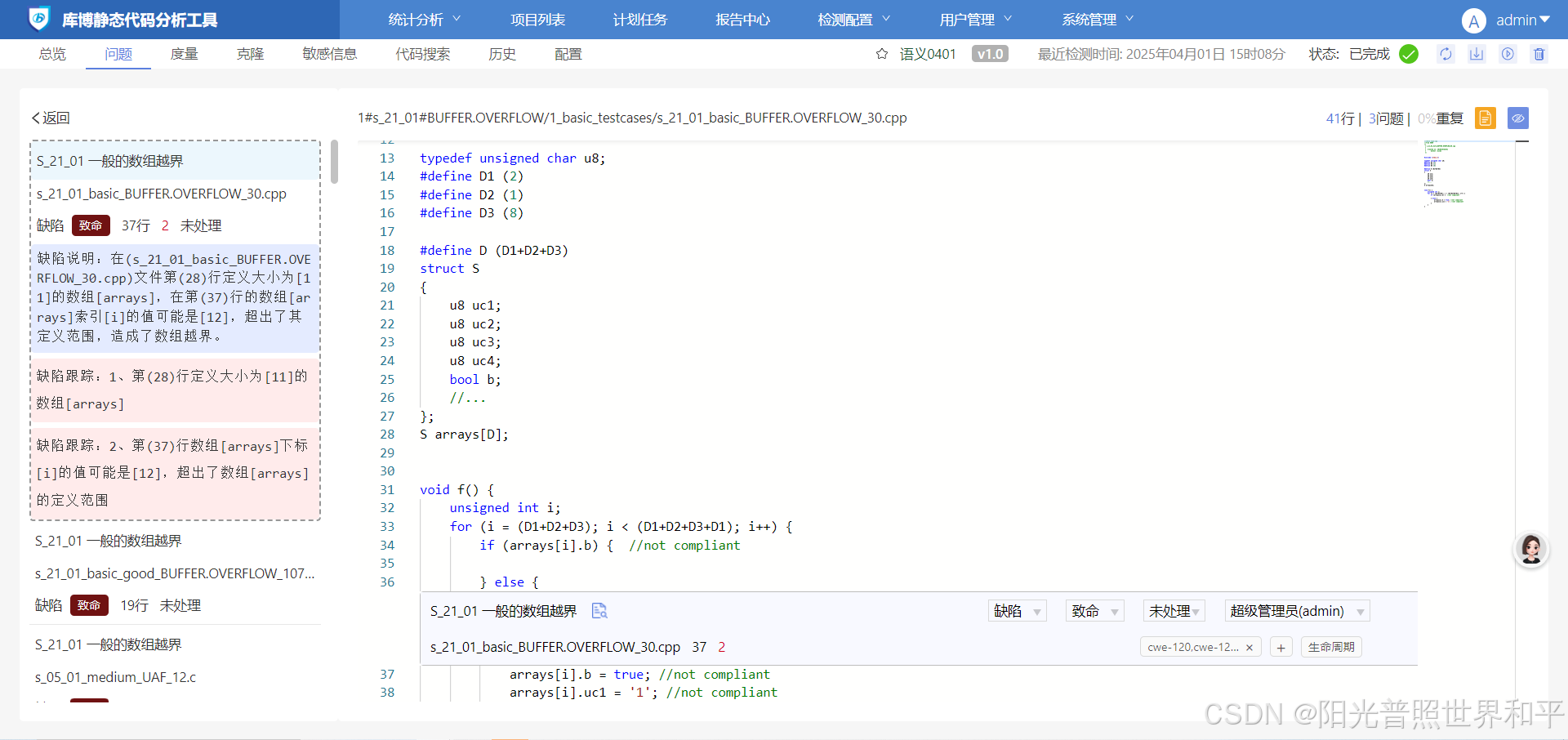
C,C++语言缓冲区溢出的产生和预防
缓冲区溢出的定义 缓冲区是内存中用于存储数据的一块连续区域,在 C 和 C 里,常使用数组、指针等方式来操作缓冲区。而缓冲区溢出指的是当程序向缓冲区写入的数据量超出了该缓冲区本身能够容纳的最大数据量时,额外的数据就会覆盖相邻的内存区…...