Oracle中的UNION原理
Oracle中的UNION操作用于合并多个SELECT语句的结果集,并自动去除重复行。其核心原理可分为以下几个步骤:
1. 执行各个子查询
-
每个
SELECT语句独立执行,生成各自的结果集。 -
如果子查询包含过滤条件(如
WHERE)、排序(如ORDER BY)或分组(如GROUP BY),会先处理这些操作。
2. 合并结果集
-
所有子查询的结果集会被合并到一个临时工作区(通常在临时表空间)。
-
UNION会隐式执行UNION ALL操作(即不去重的合并),然后对合并后的结果进行去重。 -
如果使用
UNION ALL,则跳过去重步骤,直接合并结果,性能更高。
3. 去重(仅UNION)
-
排序去重(Sort Unique):
-
Oracle默认对合并后的结果集进行排序(
SORT ORDER BY),然后移除相邻的重复行。 -
排序可能消耗大量内存和I/O资源,尤其是处理大数据集时。
-
-
哈希去重(Hash Unique):
-
若优化器认为更高效,可能使用哈希算法(
HASH UNIQUE)在内存中构建哈希表,快速判断重复行。
-
-
去重的依据是所有列的值的组合。只有当两行的所有列值完全相同时,才会被视为重复。
4. 返回最终结果
-
去重后的结果集返回给用户。
-
如果查询包含
ORDER BY,最终结果会按指定排序。
性能影响因素
-
数据量大小:大数据集排序/哈希会消耗更多资源。
-
索引利用:若子查询能利用索引,可能减少排序开销。
-
临时表空间:排序操作依赖临时表空间,配置不足可能导致磁盘I/O瓶颈。
与UNION ALL的区别:
-
UNION ALL直接拼接结果,不去重,性能显著优于UNION。 -
仅在需要去重时使用
UNION。
优化建议:
-
优先使用
UNION ALL,除非明确需要去重。 -
为子查询的过滤条件添加索引,减少全表扫描。
-
监控临时表空间使用,避免磁盘溢出(
Temp Space不足)。
资源消耗的核心原理及关键因素:
1. 子查询执行阶段的资源消耗
-
I/O消耗:
每个子查询可能需要全表扫描或索引扫描,具体取决于查询条件和索引是否可用。若子查询涉及大表且缺少索引,会导致高I/O开销。 -
CPU消耗:
子查询中的过滤(WHERE)、聚合(GROUP BY)或排序(ORDER BY)操作会占用CPU资源。 -
内存消耗:
若子查询使用哈希连接或排序操作(如GROUP BY),需要内存(PGA)存储中间结果。
2. 合并与去重的资源消耗
UNION的核心资源消耗来源于去重操作,而UNION ALL无需去重,因此资源消耗显著更低。
(1)去重机制与资源消耗
-
排序去重(
SORT UNIQUE):-
原理:Oracle将合并后的结果集按所有列进行排序,然后遍历移除相邻重复行。
-
资源消耗:
-
内存:排序操作优先使用内存(PGA的排序区),若数据量超出内存容量,会使用临时表空间进行磁盘排序。
-
I/O:磁盘排序会产生大量临时文件读写,导致高I/O开销。
-
CPU:排序算法的复杂度(如快速排序)导致高CPU占用,尤其是大结果集。
-
-
典型场景:结果集较小或内存充足时,排序去重效率较高。
-
-
哈希去重(
HASH UNIQUE):-
原理:Oracle在内存中构建哈希表,逐行计算哈希值,仅保留唯一哈希值对应的行。
-
资源消耗:
-
内存:哈希表需要足够内存存储所有唯一行的哈希值。若内存不足,会触发磁盘溢出(Hash Area Size不足)。
-
CPU:哈希计算和冲突处理(如链表法)需要CPU资源。
-
-
典型场景:结果集较大且内存充足时,哈希去重比排序更高效。
-
(2)合并结果集的资源消耗
-
临时表空间:
合并和去重操作可能需要将中间结果写入临时表空间,尤其是在内存不足时。 -
数据传输:
多个子查询的结果需要传输到合并工作区(内存或磁盘),网络或I/O带宽可能成为瓶颈(如分布式查询)。
3. 关键影响因素
(1)数据量大小
-
结果集越大,去重所需的排序或哈希操作消耗的资源(CPU、内存、I/O)呈指数级增长。
-
阈值:当结果集超过PGA或临时表空间容量时,性能急剧下降。
(2)列数与数据类型
-
列数:列数越多,排序或哈希的计算量越大(需比较所有列的值)。
-
数据类型:
-
长文本(
CLOB)或二进制(BLOB)类型会增加比较的复杂度。 -
隐式类型转换(如
VARCHAR2转NUMBER)可能导致额外CPU开销。
-
(3)索引与过滤条件
-
若子查询能通过索引快速缩小结果集(如
WHERE条件命中索引),可显著减少后续去重的数据量。 -
无索引时,全表扫描会导致高I/O和CPU消耗。
(4)并行处理
-
若启用并行查询(
PARALLEL提示),资源消耗会分散到多个进程,但可能增加总体CPU和内存使用。
4. 资源消耗优化建议
(1)避免不必要的去重
-
优先使用
UNION ALL:除非明确需要去重,否则用UNION ALL替代UNION,直接跳过排序/哈希步骤。
(2)优化子查询
-
添加过滤条件:减少每个子查询的结果集大小。
-
利用索引:确保子查询的
WHERE、JOIN条件能命中索引。 -
避免
SELECT *:仅选择必要的列,减少数据传输和处理量。
(3)调整内存配置
-
增大PGA:
调整PGA_AGGREGATE_TARGET或MEMORY_TARGET,确保排序和哈希操作尽量在内存中完成。 -
临时表空间优化:
使用高速存储(如SSD)并确保临时表空间足够大,避免磁盘排序成为瓶颈。
(4)监控与调优工具
-
执行计划分析:
使用EXPLAIN PLAN或DBMS_XPLAN查看是否触发了SORT UNIQUE或HASH UNIQUE。
EXPLAIN PLAN FOR
SELECT col1 FROM table1
UNION
SELECT col2 FROM table2;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
总结
Oracle UNION的资源消耗主要集中于去重阶段的排序或哈希操作,其性能受数据量、内存配置、索引利用等因素直接影响。优化方向包括:
-
减少数据量(过滤条件、索引)。
-
避免不必要的去重(优先
UNION ALL)。 -
调整内存和临时表空间。
-
利用执行计划分析工具定位瓶颈。
相关文章:

Oracle中的UNION原理
Oracle中的UNION操作用于合并多个SELECT语句的结果集,并自动去除重复行。其核心原理可分为以下几个步骤: 1. 执行各个子查询 每个SELECT语句独立执行,生成各自的结果集。 如果子查询包含过滤条件(如WHERE)、排序&…...

算法设计学习7
实验目的及要求: 目标是通过实验深入理解堆栈(Stack)和队列(Queue)这两种常见的数据结构,掌握它们的基本操作及应用场景,提高对数据结构的认识和应用能力。通过本实验,学生将深化对堆…...

AF3 OpenFoldDataset类解读
AlphaFold3 data_modules 模块的 OpenFoldDataset 类是一个自定义的数据集类,继承自 torch.utils.data.Dataset。它的目的是在训练时实现 随机过滤器(stochastic filters),用于从多个不同的数据集(OpenFoldSingleDataset 或 OpenFoldSingleMultimerDataset)中进行样本选择…...
Hive数仓三大核心特性解剖:面向主题性、集成性、非易失性如何重塑企业数据价值?)
大数据(4)Hive数仓三大核心特性解剖:面向主题性、集成性、非易失性如何重塑企业数据价值?
目录 背景:企业数据治理的困境与破局一、Hive数据仓库核心特性深度解析1. 面向主题性(Subject-Oriented):从业务视角重构数据2. 集成性(Integrated):打破数据孤岛的统一视图3. 非易失…...

AI模拟了一场5亿年的进化
蛋白质是生命的基石。从驱动肌肉运动的分子引擎,到捕捉光能的光合作用机器,再到细胞内的信息处理系统,这些功能复杂的分子贯穿了生命的每一个环节。尽管科学界早已解析了蛋白质的化学结构,但蛋白质的设计逻辑于人类而言࿰…...
大模型应用初学指南
随着人工智能技术的快速发展,检索增强生成(RAG)作为一种结合检索与生成的创新技术,正在重新定义信息检索的方式,RAG 的核心原理及其在实际应用中的挑战与解决方案,通用大模型在知识局限性、幻觉问题和数据安…...

如何通过管理系统提升团队协作效率
在现代企业管理中,团队协作效率的高低直接关系到企业的竞争力和运营效率。随着信息技术的不断发展,管理系统作为提升团队协作效率的重要工具,逐渐受到企业的重视。本文将深入探讨如何通过管理系统提升团队协作效率,为企业提供实用…...

云手机如何防止设备指纹被篡改
云手机如何防止设备指纹被篡改 云手机作为虚拟化设备,其设备指纹的防篡改能力直接关系到账户安全、反欺诈和隐私保护。以下以亚矩阵云手机为例,讲解云手机防止设备指纹被篡改的核心技术及实现方式: 系统层加固:硬件级安全防护 1…...

XT1870 同步升压 DC-DC 变换器
1、 产品概述 XT1870 系列产品是一款低功耗、高效率、低纹波、工 作频率高的 PFM 控制升压 DC-DC 变换器。 XT1870 系列产品仅需要 3 个外部元器 , 即可完成低输 入的电池电压输入。 2、用途 数码相机、电子词典 LED 手电筒、 LED 灯 血压计、MP3 、遥控玩具 …...
、1、sentinel介绍、安装及初始化服务监控)
Sentinel实战(一)、1、sentinel介绍、安装及初始化服务监控
spring cloud Alibaba -Sentinel、sentinel介绍、安装及初始化服务监控 一、Sentinel简单了解一)、Sentinel基本概念二)、Sentinel设计理念1、流量控制2、熔断降级1)、什么是熔断降级2)、熔断降级的设计理念3、系统负载保护三)、Sentinel工作机制二、Sentinel服务安装一)…...

如何重构前端项目
重构前端项目是指对现有的前端代码进行重新设计和改造,以提高代码质量、可维护性、可扩展性和性能。 重构前端项目的一般步骤: 1.评估项目: 了解项目的规模、复杂度、技术栈和现有的问题和挑战,以及重构的目标和范围。 2.制定计划: 制定一个详细的计划…...

seaweedfs分布式文件系统
seaweedfs https://github.com/seaweedfs/seaweedfs.git go mod tidy go -o bin ./… seaweed占不支持smb服务,只能用fuse的方式mount到本地文件系统 weed master 默认端口:9333,支持浏览器访问 weed volume 默认端口:8080 weed …...

Spring Boot后端开发全攻略:核心概念与实战指南
🧑 博主简介:CSDN博客专家、全栈领域优质创作者、高级开发工程师、高级信息系统项目管理师、系统架构师,数学与应用数学专业,10年以上多种混合语言开发经验,从事DICOM医学影像开发领域多年,熟悉DICOM协议及…...

PostgreSQL pg_repack 重新组织表并释放表空间
pg_repack pg_repack是 PostgreSQL 的一个扩展,它允许您从表和索引中删除膨胀,并可选择恢复聚集索引的物理顺序。与CLUSTER和VACUUM FULL不同,它可以在线工作,在处理过程中无需对已处理的表保持独占锁定。pg_repack 启动效率高&a…...

通过 Markdown 改进 RAG 文档处理
通过 Markdown 改进 RAG 文档处理 作者:Tableau 原文地址:https://zhuanlan.zhihu.com/p/29139791931 通过 Markdown 改进 RAG 文档处理https://mp.weixin.qq.com/s/LOBOKNA71dANXHuwxe7yxw 如何将 PDF 转换为 Markdown 以获得更好的 LLM RAG 结果 Mar…...
高速电路 PCB 设计要点一
3 高速电路 PCB 设计要点 3.1 PCB设计与信号完整性 随着电子技术的发展,电路的规模越来越大,单个器件集成的功能越来越多,速率越来越高,而器件的尺寸越来越小。由于器件尺寸的减小,器件引脚信号变化沿的速率变得越来…...

【Centos】centos7内核升级-亲测有效
相关资源 通过网盘分享的文件:脚本升级 链接: https://pan.baidu.com/s/1yrCnflT-xWhAPVQRx8_YUg?pwd52xy 提取码: 52xy –来自百度网盘超级会员v5的分享 使用教程 将脚本文件上传到服务器的一个目录 执行更新命令 yum install -y linux-firmware执行脚本即可 …...
Opencv计算机视觉编程攻略-第八节 检测兴趣点
目录 1.检测图像中的角点 2.快速检测特征 3.尺度不变特征的检测 4.多尺度FAST 特征的检测 在计算机视觉领域,兴趣点(也称关键点或特征点)应用包括目标识别、图像配准、视觉跟踪、三维重建等。这个概念的原理是,从图像中选取某…...

On Superresolution Effects in Maximum Likelihood Adaptive Antenna Arrays论文阅读
On Superresolution Effects in Maximum Likelihood Adaptive Antenna Arrays 1. 论文的研究目标与实际问题意义1.1 研究目标1.2 解决的实际问题1.3 实际意义2. 论文提出的新方法、模型与公式2.1 核心创新:标量化近似表达式关键推导步骤:公式优势:2.2 与经典方法的对比传统方…...
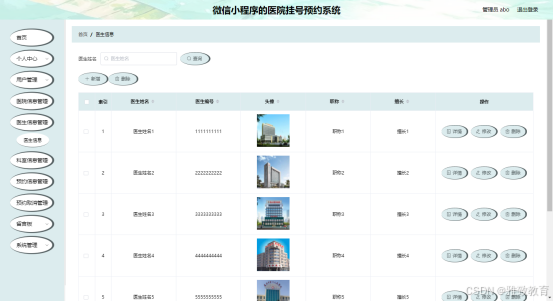
基于微信小程序的医院挂号预约系统设计与实现
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本微信小程序医院挂号预约系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大…...
如何保障话费api接口的稳定性?
保障话费接口的稳定性是确保服务高效运行的关键。以下是基于最新信息的建议: 1. 选择可靠的API服务提供商 信誉和稳定性:选择有良好声誉和稳定服务记录的提供商,查看其服务水平协议(SLA)以确保高可用性。技术支持&…...
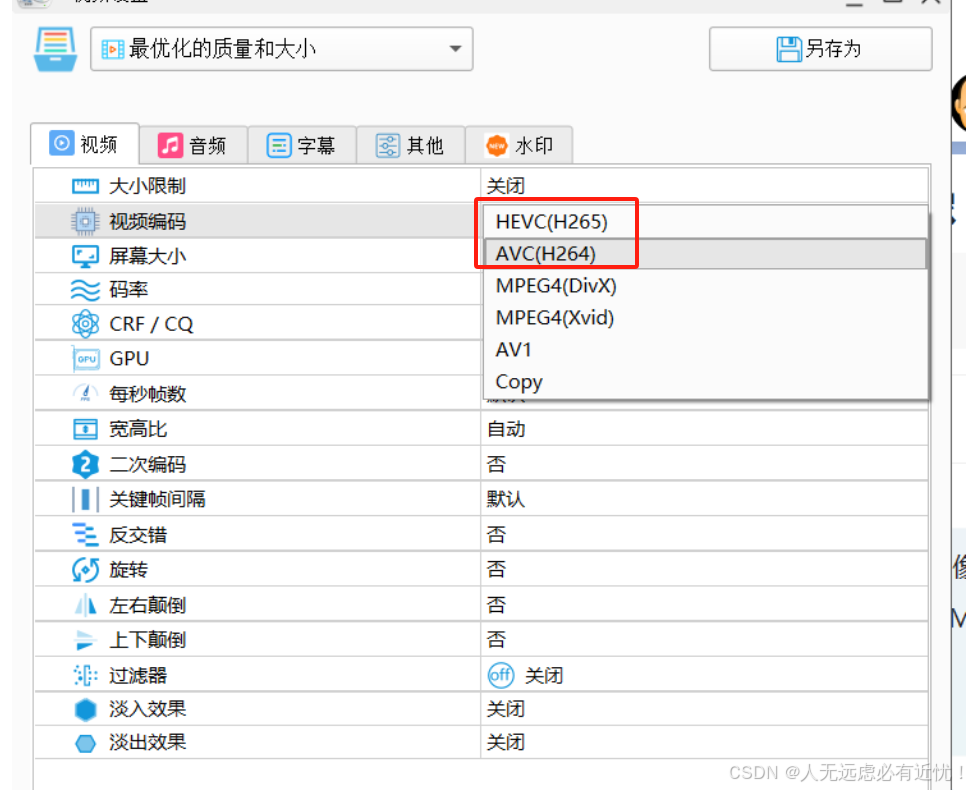
video标签播放mp4格式视频只有声音没有图像的问题
video标签播放mp4格式视频只有声音没有图像的问题 这是由于视频格式是hevc(H265)编码的,这种编码格式视频video播放有问题主要是由于以下两种原因导致的: 1、浏览器没有开启硬加速模式: 开启方法(以谷歌浏览器为例)&a…...

解决docker部署的容器第二天访问报错139的问题
前阵子我部署项目,把数据库放宿主机上,结果电脑一重启,Docker 直接把数据库删了个精光!我当时的表情 be like 😱:"我的数据呢???" 连备份都没来得及做…...

如何对接银行卡二要素核验接口?
银行卡二要素核验接口是一种通过API(应用程序编程接口)实现对用户提供的银行卡信息进行基本身份验证的技术服务,主要用于核验银行卡号与持卡人姓名是否一致,从而确认用户身份的真实性和操作合法性。 银行卡二要素核验接口通过调用…...

高效深度学习lecture01
lecture01 零样本学习(Zero-Shot Learning, ZSL): 模型可以在没有见过某种特定任务或类别的训练样本的情况下,直接完成对应的任务 利用知识迁移 模型在一个任务上训练时学到的知识,能够迁移到其他任务上比如,模型知道“狗”和“…...

用ChatGPT-5自然语言描述生成完整ERP模块
一、技术实现原理 1.1 语义理解能力 理解维度技术指标典型应用业务术语识别准确率98.7%物料需求计划流程逻辑上下文关联度0.92生产排程设计数据关系实体识别F1值0.95财务科目设置约束条件规则匹配率89%库存警戒规则 1.2 模块生成流程 五阶段生成机制: 需求澄清…...

深度学习——深入解读各种卷积的应用场景优劣势与实现细节
前言 卷积操作在深度学习领域中占据着核心地位,其在多种神经网络架构中发挥着关键作用。然而,卷积的种类繁多,每种卷积都有其独特的定义、应用场景和优势。 对于那些对深度学习中不同卷积类型(例如 2D 卷积、3D 卷积、11 卷积、转…...

python大数据相关职位,还需要学习java哪些知识
一、核心需要掌握的 Java 知识 1. Java 基础语法 语法基础:变量、数据类型、流程控制、异常处理(对比 Python 的差异)。面向对象编程(OOP):类、继承、多态、接口(Java 的 OOP 比 Pyth…...

easyPan技术回顾day4
1.主页删除接口(移动到回收站) 流程: 1.先查询要删除的文件是否存在。 2.递归获取选中的内容,以及(状态为USING)的所有子目录将其放到(delFilePidList) 3.将delFilePidList的所有子…...
Pyinstaller 打包flask_socketio为exe程序后出现:ValueError: Invalid async_mode specified
Pyinstaller 打包flask_socketio为exe程序后出现:ValueError: Invalid async_mode specified 一、详细描述问题描述 Traceback (most recent call last): File "app_3.py", line 22, in <module> File "flask_socketio\__init__.py"…...