AI大模型从0到1记录学习 day13
第 13 章 Python高级语法
13.1 浅拷贝与深拷贝
直接赋值:对象的引用(别名),不产生拷贝。
浅拷贝:拷贝父对象,不会拷贝对象的内部的子对象。拷贝后只有第一层是独立的。
深拷贝:完全拷贝了父对象及其子对象。拷贝后所有层都是独立的。
13.1.1 如何浅拷贝
切片操作(如 [:])。
使用工厂函数(如 list() / set())。
使用 copy 模块的 copy() 函数。
13.1.2 案例
(1)创建一个列表,其中包含整型和列表元素,使用 copy() 对其浅拷贝。使用 id() 查看列表地址和列表中各个元素的地址。
import copy
list1 = [1, 2, 3, [100, 200, 300]]
print(id(list1), id(list1[0]), id(list1[1]), id(list1[2]), id(list1[3]), list1)
3060924684544 140732039489976 140732039490008 140732039490040 3060924682624 [1, 2, 3, [100, 200, 300]]
list2 = copy.copy(list1)
print(id(list2), id(list2[0]), id(list2[1]), id(list2[2]), id(list2[3]), list2)
3060926299456 140732039489976 140732039490008 140732039490040 3060924682624 [1, 2, 3, [100, 200, 300]]
可以看到拷贝后新的列表地址改变了,但列表中各个元素还是同一地址。
(2)修改 list1[0] 整型元素
list1[0] = 100 # 修改list1[0]整型元素
print(id(list1), id(list1[0]), id(list1[1]), id(list1[2]), id(list1[3]), list1)
3060924684544 140732039493144 140732039490008 140732039490040 3060924682624 [100, 2, 3, [100, 200, 300]]
print(id(list2), id(list2[0]), id(list2[1]), id(list2[2]), id(list2[3]), list2)
3060926299456 140732039489976 140732039490008 140732039490040 3060924682624 [1, 2, 3, [100, 200, 300]]
list[0] 为不可变类型元素,因此可以看到 list[0] 指向了新的引用。
(3)修改 list[3] 列表元素
list1[3].append(400) # 修改list1[3]列表元素,向列表中添加新值
print(id(list1), id(list1[0]), id(list1[1]), id(list1[2]), id(list1[3]), list1)
3060924684544 140732039493144 140732039490008 140732039490040 3060924682624 [100, 2, 3, [100, 200, 300, 400]]
print(id(list2), id(list2[0]), id(list2[1]), id(list2[2]), id(list2[3]), list2)
3060926299456 140732039489976 140732039490008 140732039490040 3060924682624 [1, 2, 3, [100, 200, 300, 400]]
list[3] 为可变类型元素,修改不会产生新对象。
13.1.3 如何深拷贝
使用 copy 模块的 deepcopy() 函数。
13.1.4 案例
(1)创建一个列表,其中包含整型和列表元素,使用 deepcopy() 对其深拷贝。使用 id() 查看列表地址和列表中各个元素的地址。
import copy
list1 = [1, 2, 3, [100, 200, 300]]
print(id(list1), id(list1[0]), id(list1[1]), id(list1[2]), id(list1[3]), list1)
3060924684544 140732039489976 140732039490008 140732039490040 3060924682624 [1, 2, 3, [100, 200, 300]]
list3 = copy.deepcopy(list1)
print(id(list3), id(list3[0]), id(list3[1]), id(list3[2]), id(list3[3]), list3)
3060926299520 140732039489976 140732039490008 140732039490040 3060926299584 [1, 2, 3, [100, 200, 300]]
可以看到拷贝后,新的列表地址与列表中各个可变类型元素的地址都发生了改变,不可变类型元素拷贝后地址不变。
(2)修改 list1[0] 整型元素
list1[0] = 100 # 修改list1[0]整型元素
print(id(list1), id(list1[0]), id(list1[1]), id(list1[2]), id(list1[3]), list1)
3060924684544 140732039493144 140732039490008 140732039490040 3060924682624 [100, 2, 3, [100, 200, 300]]
print(id(list3), id(list3[0]), id(list3[1]), id(list3[2]), id(list3[3]), list3)
3060926299520 140732039489976 140732039490008 140732039490040 3060926299584 [1, 2, 3, [100, 200, 300]]
(3)修改 list[3] 列表元素
list1[3].append(400) # 修改list1[3]列表元素,向列表中添加新值
print(id(list1), id(list1[0]), id(list1[1]), id(list1[2]), id(list1[3]), list1)
3060924684544 140732039493144 140732039490008 140732039490040 3060924682624 [100, 2, 3, [100, 200, 300, 400]]
print(id(list3), id(list3[0]), id(list3[1]), id(list3[2]), id(list3[3]), list3)
3060926299520 140732039489976 140732039490008 140732039490040 3060926299584 [1, 2, 3, [100, 200, 300]]
13.1.5 拷贝的特殊情况
(1)非容器类型(如数字、字符串、和其他“原子”类型的对象)无法拷贝
import copy
var1 = 1
print(id(var1), var1) # 140732039489976 1
var2 = copy.copy(var1)
print(id(var2), var2) # 140732039489976 1
var3 = copy.deepcopy(var1)
print(id(var3), var3) # 140732039489976 1
(2)元组变量如果只包含原子类型对象,则不能对其深拷贝
import copy
tuple1 = (1, 2, 3) # 元组只包含原子类型对象
print(id(tuple1), tuple1) # 1653947230848 (1, 2, 3)
tuple2 = copy.deepcopy(tuple1)
print(id(tuple2), tuple2) # 1653947230848 (1, 2, 3)
tuple1 = (1, 2, 3, []) # 元组不只包含原子类型对象
print(id(tuple1), tuple1) # 1653947152432 (1, 2, 3, [])
tuple2 = copy.deepcopy(tuple1)
print(id(tuple2), tuple2) # 1653947148912 (1, 2, 3, [])
13.2 迭代器
迭代是是遍历容器中元素的一种方式,而迭代器是一个可以记住遍历的位置的对象。迭代器对象从容器的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。字符串,列表或元组对象都可用于创建迭代器。
13.2.1 可迭代对象
1)什么是可迭代对象
我们发现大多数容器对象都可以使用 for 语句:
import os
for element in [1, 2, 3]:
print(element)
for element in (1, 2, 3):
print(element)
for key in {“one”: 1, “two”: 2}:
print(key)
for char in “123”:
print(char)
with open(“myfile.txt”, “w”) as f:
f.write(“H\ne\nl\nl\no\n \nW\no\nr\nl\nd\n”)
for line in open(“myfile.txt”):
print(line, end=“”)
os.remove(“myfile.txt”)
可以直接作用于 for 循环的数据类型有以下几种:
容器,如 list 、 tuple 、 dict 、 set 、 str 等。
generator ,包括生成器和带 yield 的generator function。
这些可以直接作用于 for 循环的对象统称为可迭代对象:Iterable。
2)判断是否是可迭代对象(Iterable)
from collections.abc import Iterable
print(isinstance([], Iterable)) # True
print(isinstance((), Iterable)) # True
print(isinstance(set(), Iterable)) # True
print(isinstance({}, Iterable)) # True
print(isinstance(“100”, Iterable)) # True
print(isinstance(100, Iterable)) # False
3)判断是否是迭代器(Iterator)
from collections.abc import Iterator
print(isinstance([], Iterator)) # False
print(isinstance((), Iterator)) # False
print(isinstance(set(), Iterator)) # False
print(isinstance({}, Iterator)) # False
print(isinstance(“100”, Iterator)) # False
print(isinstance((x for x in range(10)), Iterator)) # True
13.2.2 使用迭代器
迭代器有两个基本的方法:iter() 和 next()。
在容器对象上使用 for 语句时,在幕后,for 语句会在容器对象上调用 iter()。该函数返回一个定义了 next() 方法的迭代器对象,此方法将逐一访问容器中的元素。当元素用尽时,next() 将引发 StopIteration 异常来通知终止 for 循环。 你可以使用 next() 内置函数来调用 next() 方法。
我们可以使用 iter() 获取一个可迭代对象的迭代器,并使用 next() 遍历迭代器:
list = [1, 2, 3]
it = iter(list) # 创建迭代器对象
print(next(it)) # 输出迭代器的下一个元素,1
print(next(it)) # 2
print(next(it)) # 3
print(next(it)) # StopIteration
也可以使用 for 来遍历迭代器:
list = [1, 2, 3]
it = iter(list) # 创建迭代器对象
for i in it:
print(i)
13.2.3 创建迭代器
了解了迭代器协议背后的机制后,就可以为类添加迭代器行为了。定义 iter() 方法用于返回一个带有 next() 方法的对象。如果类已定义了 next(),那么 iter() 可以简单地返回 self。
class Reverse:
“”“对一个序列执行反向循环的迭代器。”“”
def __init__(self, data):self.data = dataself.index = len(data)def __iter__(self):return selfdef __next__(self):if self.index == 0:raise StopIterationself.index = self.index - 1return self.data[self.index]
rev = Reverse([2, 3, 5, 7, 11, 13, 17, 19])
iter(rev)
for char in rev:
print(char)
13.3 生成器
13.3.1 什么是生成器
生成器(generator)是一个用于创建迭代器的简单而强大的工具。它的写法类似于标准的函数,但当它要返回数据时会使用 yield 语句。当在生成器函数中使用 yield 语句时,函数的执行将会暂停,并将 yield 后的表达式作为当前迭代的值返回。
每次调用生成器的 next() 方法或使用 for 循环进行迭代时,函数会从上次暂停的地方继续执行(它会记住上次执行语句时的所有数据值),直到再次遇到 yield 语句。这样,生成器函数可以逐步产生值,而不需要一次性计算并返回所有结果。
生成器函数的优势是它们可以按需生成值,避免一次性生成大量数据并占用大量内存。此外,生成器还可以与其他迭代工具(如for循环)无缝配合使用,提供简洁和高效的迭代方式。
13.3.2 创建生成器
1)使用推导式创建生成器
generator = (x for x in range(5)) # 创建生成器
print(generator) # <generator object at 0x0000026C2066CB80>
for x in generator:
print(x)
2)使用函数创建生成器
def fibo(): # 斐波那契数列
a, b = 0, 1
while True:
yield b
a, b = b, a + b
f = fibo()
print(next(f)) # 1
print(next(f)) # 1
print(next(f)) # 2
print(next(f)) # 3
print(next(f)) # 5
如果我们要获取生成器中 return 的值,我们需要捕获 StopIteration异常:
def fibo(n): # 斐波那契数列
a, b, counter = 0, 1, 0
while counter < n:
yield b
a, b, counter = b, a + b, counter + 1
return “done”
f = fibo(10)
try:
while True:
print(next(f))
except StopIteration as result:
print(“StopIteration”, result) # StopIteration done
13.3.3 send()
1)向生成器发送值
恢复执行并向生成器函数“发送”一个值。 这个值作为当前 yield 表达式的结果。 send() 方法会返回生成器所产生的下一个值,或者如果生成器没有产生下一个值就退出则会引发 StopIteration。
使用 send() 发送任务id,使生成器交替执行两个任务:
def gen():
task_id = 0
int_value = 0
char_value = “A”
while True:
# task_id 为 0 则 int_value +1,task_id 为 1 则 char_value +1
match task_id:
case 0:
task_id = yield int_value # 返回 int_value,并接收 send() 发送来的值给 task_id
int_value += 1
case 1:
task_id = yield char_value # 返回 char_value,并接收 send() 发送来的值给 task_id
char_value = chr(ord(char_value) + 1)
case _:
task_id = yield # 返回 None
g = gen()
print(next(g)) # 0
print(g.send(1)) # A
print(g.send(0)) # 1
print(g.send(1)) # B
print(g.send(0)) # 2
2)使用 send(None) 启动生成器
当调用 send() 来启动生成器时,它必须以 None 作为调用参数,因为这时没有可以接收值的 yield 表达式。
def gen():
task_id = 0
int_value = 0
char_value = “A”
while True:
# task_id 为 0 则 int_value +1,task_id 为 1 则 char_value +1
match task_id:
case 0:
task_id = yield int_value # 返回 int_value,并接收 send() 发送来的值给 task_id
int_value += 1
case 1:
task_id = yield char_value # 返回 char_value,并接收 send() 发送来的值给 task_id
char_value = chr(ord(char_value) + 1)
case _:
task_id = yield # 返回 None
g = gen()
print(g.send(None)) # 0
print(g.send(1)) # A
print(g.send(0)) # 1
13.4 命名空间
13.4.1 什么是命名空间
命名空间(Namespace)是从名称到对象的映射,现在,大多数命名空间都使用Python字典实现。各个命名空间是独立的,没有任何关系的,所以一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响。
13.4.2 三种命名空间
一般有三种命名空间,在不同时刻创建,且拥有不同的生命周期:
1)内置名称
内置名称的命名空间是在 Python 解释器启动时创建的,永远不会被删除。
2)一个模块的全局名称
模块的全局命名空间在读取模块定义时创建。通常,模块的命名空间也会持续到解释器退出。
从脚本文件读取或交互式读取的,由解释器顶层调用执行的语句,是 main 模块调用的一部分,也拥有自己的全局命名空间。
内置名称实际上也在模块里,即 builtins。
3)一个函数调用中的局部名称
函数的局部命名空间在函数被调用时被创建,并在函数返回或抛出未在函数内被处理的异常时被删除(实际上,用“遗忘”来描述实际发生的情况会更好一些)。当然,每次递归调用都有自己的局部命名空间。
13.5 作用域
13.5.1 什么是作用域
一个命名空间的作用域是Python代码中的一段文本区域,从这个区域可直接访问该命名空间。
13.5.2 四种作用域
最内层作用域(Local),包含局部名称,并首先在其中进行搜索
那些外层闭包函数的作用域(Enclosing):包含“非局部、非全局”的名称,从最靠内层的那个作用域开始,逐层向外搜索。
倒数第二层作用域(Global):包含当前模块的全局名称
最外层(最后搜索)的作用域(Built-in):是内置名称的命名空间
global 语句用于表明特定变量在全局作用域里,并应在全局作用域中重新绑定。
nonlocal 语句表明特定变量在外层作用域中,并应在外层作用域中重新绑定。
在最内层作用域访问全局作用域或外层作用域的变量时,若不使用 global 或 nonlocal 语句,这些变量将为只读,尝试写入这样的变量将在最内层作用域中创建一个新的局部变量,而使得同名的外部变量保持不变。
13.6 闭包
13.6.1 什么是闭包
当调用的函数执行完毕后,函数内的变量就会被销毁。但有时希望在调用函数后函数内的数据能够保存下来重复使用,这时候可以用到闭包。闭包可以避免使用全局值,并提供某种形式的数据隐藏。
构建闭包的条件:
外部函数内定义一个内部函数。
内部函数用到外部函数中的变量。
外部函数将内部函数作为返回值。
13.6.2 使用闭包
构建闭包
def linear(a, b):
def inner(x):
return a * x + b
return inner
y1 = linear(1, 1)
print(y1) # <function linear..inner at 0x00000291279D19E0>
print(y1(5)) # 6
将调用 linear() 后返回的函数对象赋值给 y1,虽然 linear() 函数已经执行完毕,但是我们调用 y1() 时,y1() 仍然记得 linear() 中 a 和 b 的值。
13.6.3 查看闭包中的值
所有函数对象都有一个 closure 属性,如果它是一个闭包函数,则该属性返回单元格对象的元组。
def linear(a, b):
def inner(x):
return a * x + b
return inner
y1 = linear(1, 2)
objects = y1.closure
print(objects)
print(objects[0].cell_contents) # 1
print(objects[1].cell_contents) # 2
13.7 装饰器
13.7.1 什么是装饰器
装饰器允许在不修改原有函数代码的基础上,动态地增加或修改函数的功能。装饰器本质上是一个接收函数作为输入并返回一个新的包装过后的函数的对象。
13.7.2 使用装饰器
1)语法
def decorator(func):
def inner(参数):
# 添加功能
func(参数)
# 添加功能
return inner
decorator 是一个装饰器函数,它接受一个函数 func 作为参数,并返回一个内部函数 inner。在 inner 函数内部,我们可以执行一些额外的操作,然后调用原始函数 func,并返回其结果。
2)闭包实现装饰器
from math import sqrt
def func(x):
“”“开根号”“”
return sqrt(x)
def decorator(f):
def inner(x):
x = abs(x) # 求x的绝对值
return f(x)
return inner
func = decorator(func)
print(func(-4)) # 2.0
3)@decorator使用装饰器
当我们使用 @decorator 前缀在 func 定义前,Python会自动将 func 作为参数传递给 decorator,然后将返回的 inner 函数替换掉原来的 func。
from math import sqrt
def decorator(f):
def inner(x):
x = abs(x) # 求x的绝对值
return f(x)
return inner
@decorator
def func(x):
“”“开根号”“”
return sqrt(x)
print(func(-4)) # 2.0
13.7.3 多层装饰器
多个装饰器的装饰过程:离函数最近的装饰器先装饰,然后外面的装饰器再进行装饰。
from math import sqrt
将参数转化为整型
def get_integer(f):
def inner(x):
x = int(x)
return f(x)
return inner
将参数转换为非负数
def get_absolute(f):
def inner(x):
x = abs(x)
return f(x)
return inner
@get_integer
@get_absolute
def func(x):
“”“开根号”“”
return sqrt(x)
print(func(“-4”)) # 2.0
13.7.4 带参数的装饰器
from math import sqrt
求根号n次
def times(n):
# 将参数转换为非负数
def get_absolute(f):
def inner(x):
x = abs(x)
for i in range(n):
x = f(x)
return x
return innerreturn get_absolute
@times(2)
def func(x):
“”“开根号”“”
return sqrt(x)
print(func(-16)) # 2.0
13.7.5 类装饰器
类装饰器是包含 call() 方法的类,它接受函数作为参数,并返回新的函数。
from math import sqrt
class DecoratorClass:
def init(self, f):
self.f = f
def __call__(self, x):x = abs(x)return self.f(x)
@DecoratorClass
def func(x):
“”“开根号”“”
return sqrt(x)
print(func(-4)) # 2.0
相关文章:

AI大模型从0到1记录学习 day13
第 13 章 Python高级语法 13.1 浅拷贝与深拷贝 直接赋值:对象的引用(别名),不产生拷贝。 浅拷贝:拷贝父对象,不会拷贝对象的内部的子对象。拷贝后只有第一层是独立的。 深拷贝:完全拷贝…...
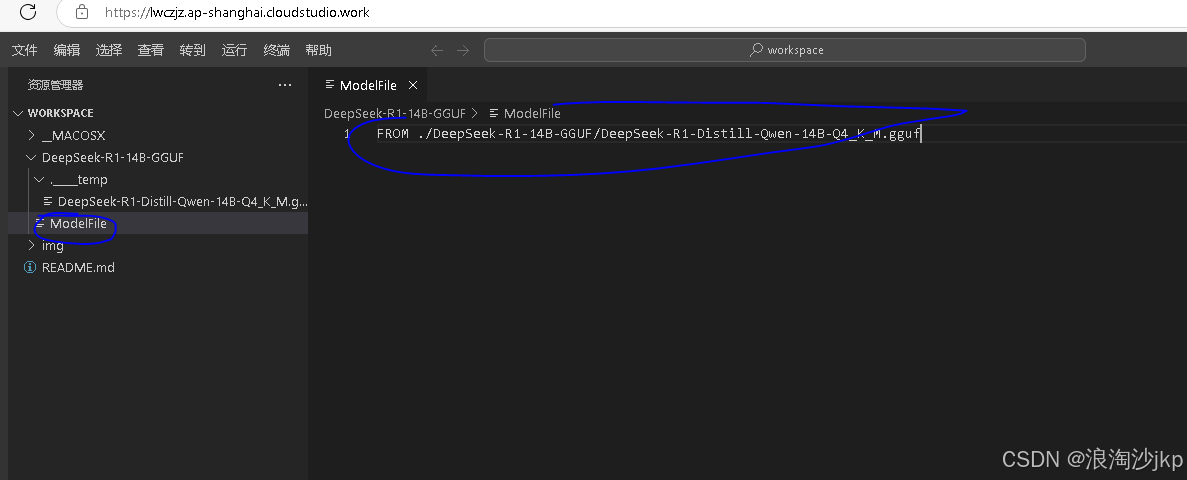
大模型学习三:DeepSeek R1蒸馏模型组ollama调用流程
一、说明 目前DeepSeek R1及其蒸馏模型均支持使用ollama进行调用,可以在模型主页查看调用情况 deepseek-r1https://ollama.com/library/deepseek-r1 显存需求 ,我们显存是16G,可以玩好几个 二、以14B模型演示 1、安装ollama curl -fsSL htt…...
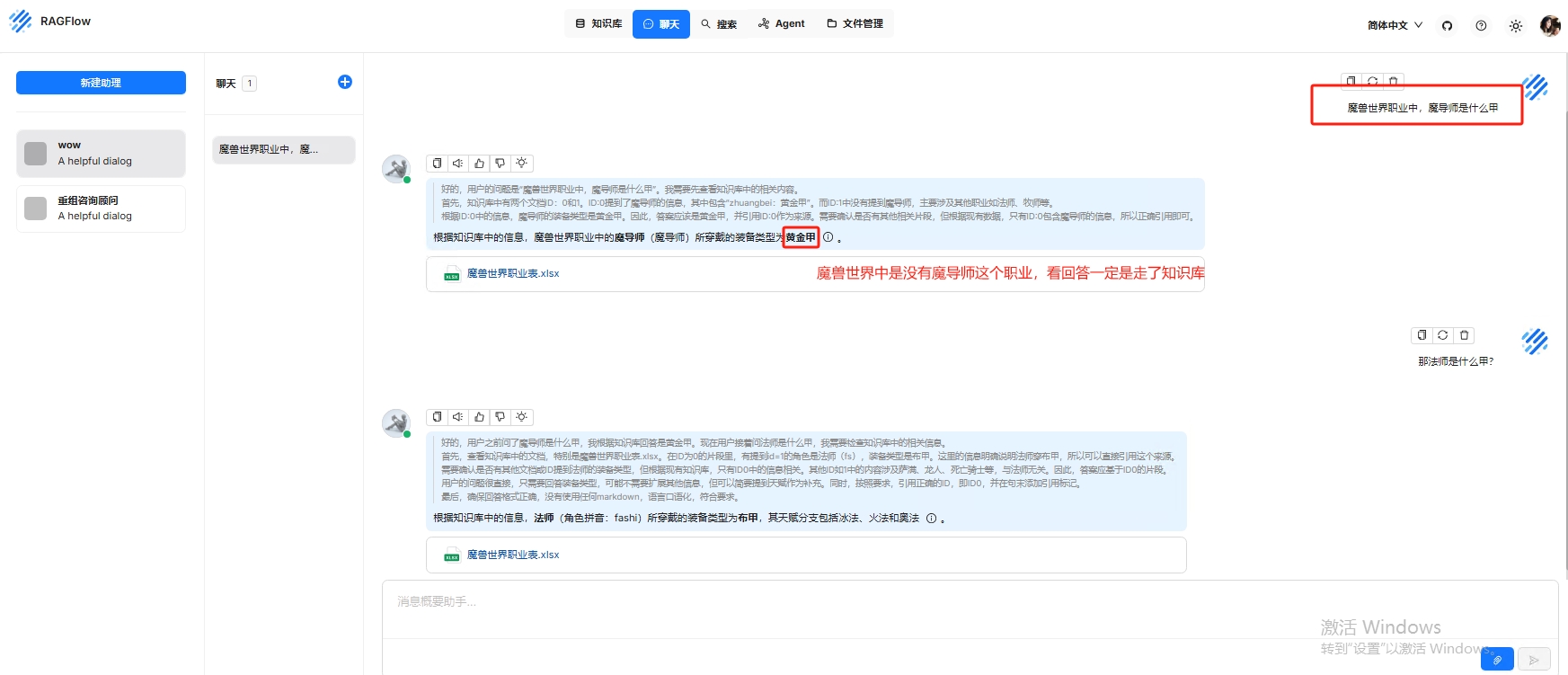
RAGFlow部署与使用介绍-深度文档理解和检索增强生成
ragflow部署与使用教程-智能文档处理与知识管理的创新引擎 1. ragflow简介 RAGFlow作为新一代智能文档处理平台,深度融合检索增强生成(RAG)技术与自动化工作流引擎,为企业级知识管理提供全栈解决方案。通过结合多模态解析、语…...

一文读懂 UML:基础概念与体系框架
UML 图是一种标准化的建模语言,在软件开发和系统设计等领域有着广泛的应用。以下是对 UML 图各类图的详细介绍: 1.用例图 定义:用例图是从用户角度描述系统功能的模型图,展现了系统的参与者与用例之间的关系。作用:帮…...
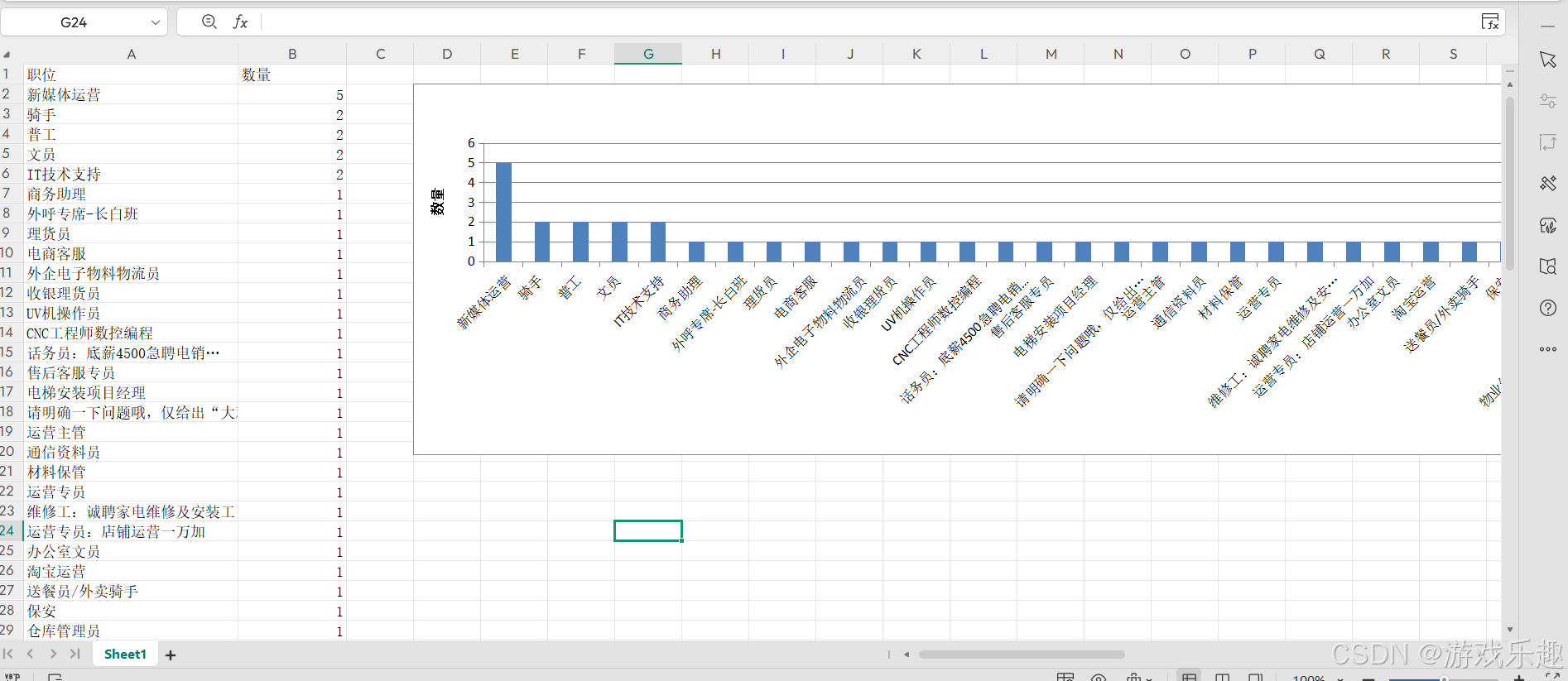
【AI赋能:58招聘数据的深度剖析之旅】
影刀出鞘,抓取数据 在当今数字化时代,数据分析已成为企业决策和发展的关键驱动力。而获取高质量的数据则是数据分析的首要任务。在这个信息爆炸的时代,网络上蕴含着海量的数据,其中招聘网站的数据对于人力资源分析、市场趋势研究…...
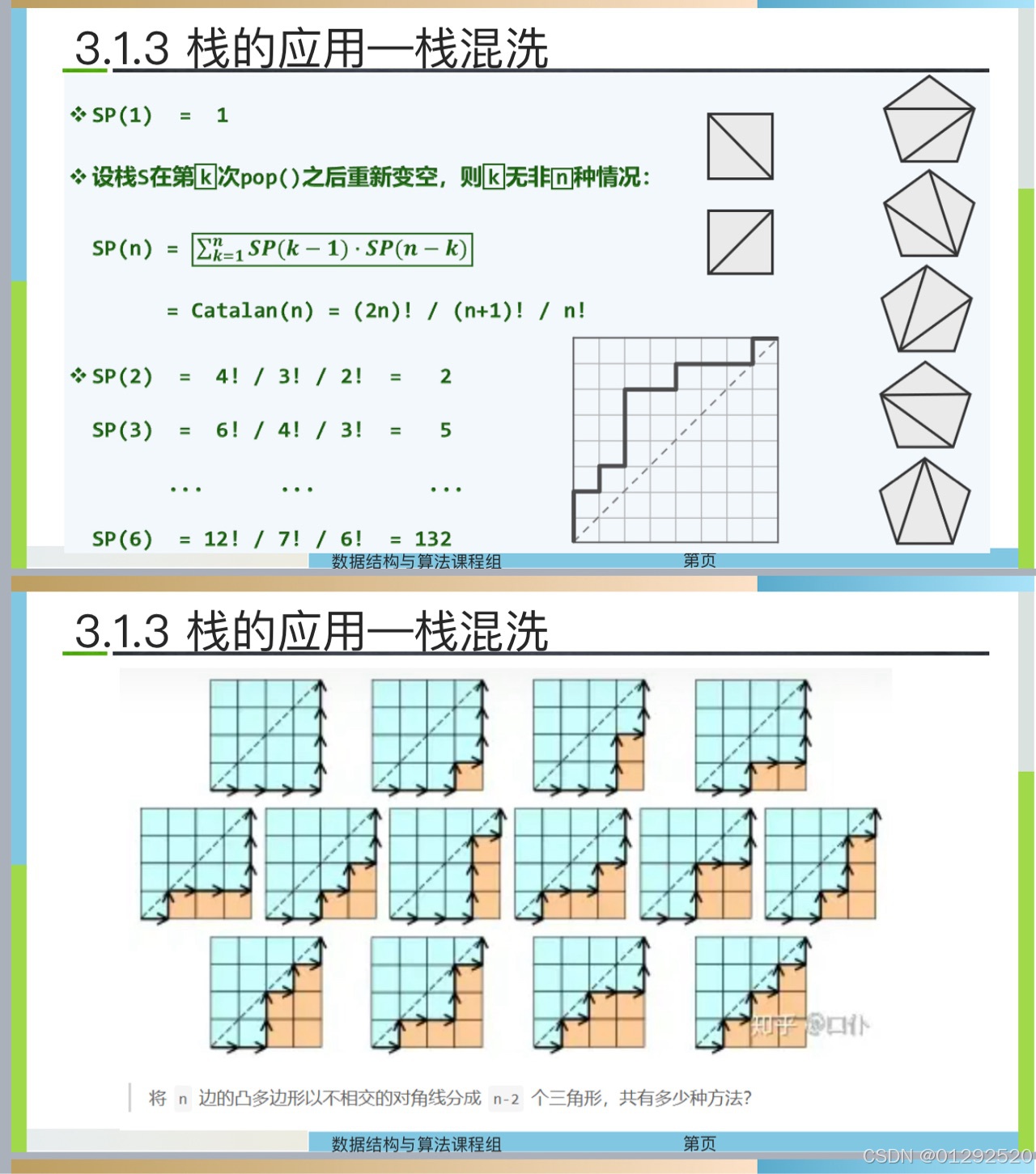
几何法证明卡特兰数_栈混洗
模型: 考虑从坐标原点 (0, 0) 到点 (n, n) 的路径,要求路径只能向右(x 方向)或向上(y 方向)移动,并且路径不能越过直线 y x(即始终满足 y< x )。这样的路径数量就是…...

Kafka的安装与使用(windows下python使用等)
一、下载 可以去官网下载:https://kafka.apache.org/downloads 版本可选择,建议下载比较新的,新版本里面自带zookeeper 二、安装 创建一个目录,此处是D:\kafka,将文件放进去解压 如果文件后缀是gz,解压…...

DataPermissionInterceptor源码解读
原文首发在我的博客:https://blog.liuzijian.com/post/mybatis-plus-source-data-permission-interceptor.html 目录 一、概述二、源码解读2.1 beforeQuery2.2 beforePrepare2.3 processSelect2.4 setWhere2.5 processUpdate2.6 processDelete2.7 getUpdateOrDelete…...

大模型中的参数规模与显卡匹配
在大模型训练和推理中,显卡(GPU/TPU)的选择与模型参数量紧密相关,需综合考虑显存、计算能力和成本。以下是不同规模模型与硬件的匹配关系及优化策略: 一、参数规模与显卡匹配参考表 模型参数量训练阶段推荐显卡推理阶…...

数据结构初阶: 顺序表的增删查改
顺序表 概念 顺序表是⽤⼀段物理地址连续的存储单元依次存储数据元素的线性结构,⼀般情况下采⽤数组存储。如图1: 顺序表和数组有什么区别? 顺序表的底层是用数组实现的,是对数组的封装,实现了增删查改等接口。 分…...

Spring Boot项目中策略模式的应用与实现
前言 在Spring Boot项目中,策略模式是一种非常重要的设计模式,它能够让我们定义一系列算法,并使它们可以互相替换。 策略模式通过将算法封装到独立的类中,从而使得代码中的算法可以独立于使用它的客户端变化。 这对于某些需求频…...

【机器学习中的基本术语:特征、样本、训练集、测试集、监督/无监督学习】
机器学习基本术语详解 1. 特征(Feature) 定义:数据的属性或变量,用于描述样本的某个方面。作用:模型通过学习特征与目标之间的关系进行预测。示例: 预测房价时,特征可以是 面积、地段、房龄。…...

MySQL全链路指南
目录 前言 第一章 MySQL基础入门 1.1 MySQL简介与安装 1.2 数据库基本操作 1.3 表结构与数据类型 第二章 SQL语言深度解析 2.1 DDL(数据定义语言) 2.2 DML(数据操作语言) 2.3 DQL(数据查询语言) 2…...
)
System.arraycopy()
在 Java 编程中,数组是一种常用的数据结构,用于存储相同类型的元素集合。在处理数组时,经常需要进行数组复制操作,例如将一个数组的部分或全部元素复制到另一个数组中。System.arraycopy() 方法是 Java 提供的一个高效的数组复制工…...
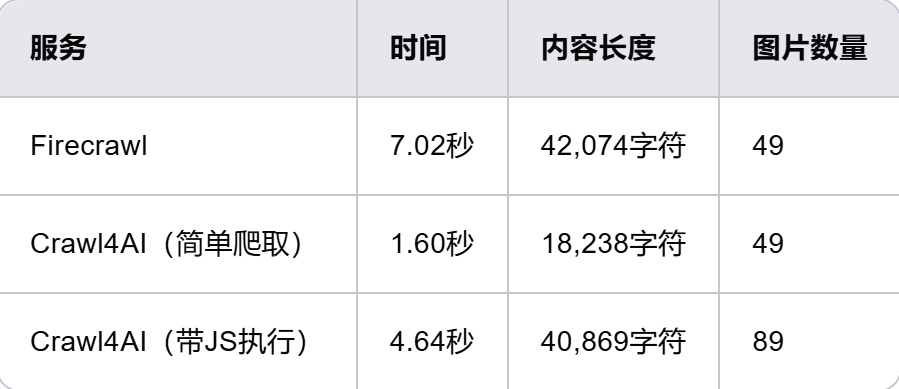
详解AI采集框架Crawl4AI,打造智能网络爬虫
大家好,Crawl4AI作为开源Python库,专门用来简化网页爬取和数据提取的工作。它不仅功能强大、灵活,而且全异步的设计让处理速度更快,稳定性更好。无论是构建AI项目还是提升语言模型的性能,Crawl4AI都能帮您简化工作流程…...
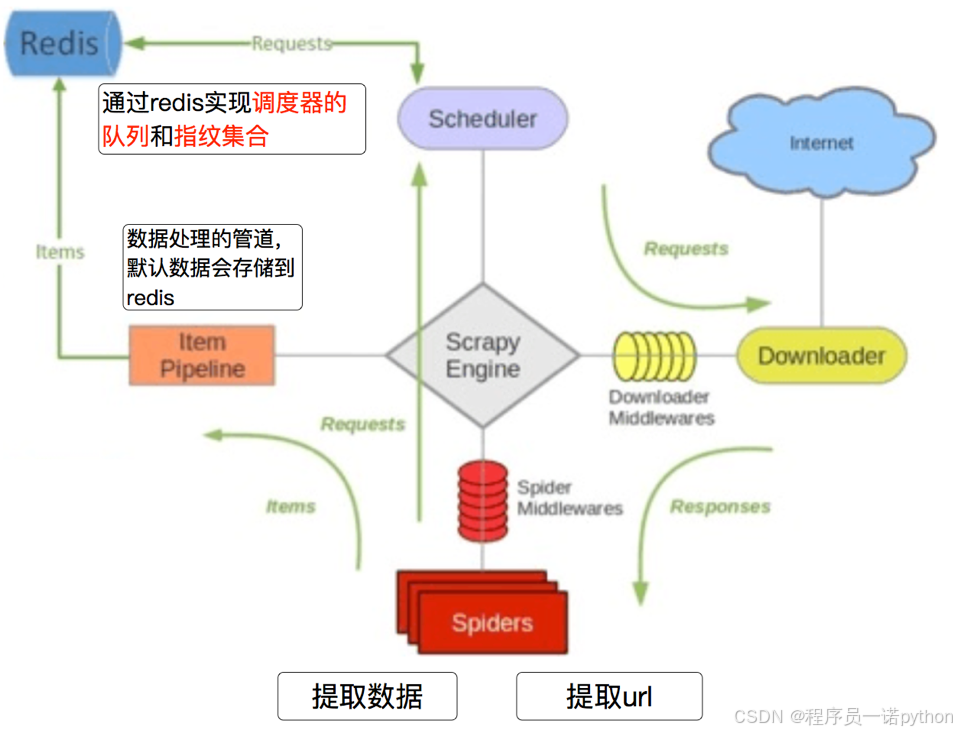
【爬虫开发】爬虫开发从0到1全知识教程第14篇:scrapy爬虫框架,介绍【附代码文档】
本教程的知识点为:爬虫概要 爬虫基础 爬虫概述 知识点: 1. 爬虫的概念 requests模块 requests模块 知识点: 1. requests模块介绍 1.1 requests模块的作用: 数据提取概要 数据提取概述 知识点 1. 响应内容的分类 知识点:…...

MySQL索引原理:从B+树手绘到EXPLAIN
最近在学后端,学到了这里做个记录 一、为什么索引像书的目录? 类比:500页的技术书籍 vs 10页的目录缺点:全表扫描就像逐页翻找内容优点:索引将查询速度从O(n)提升到O(log n) 二、B树手绘课堂 1. 结构解剖࿰…...
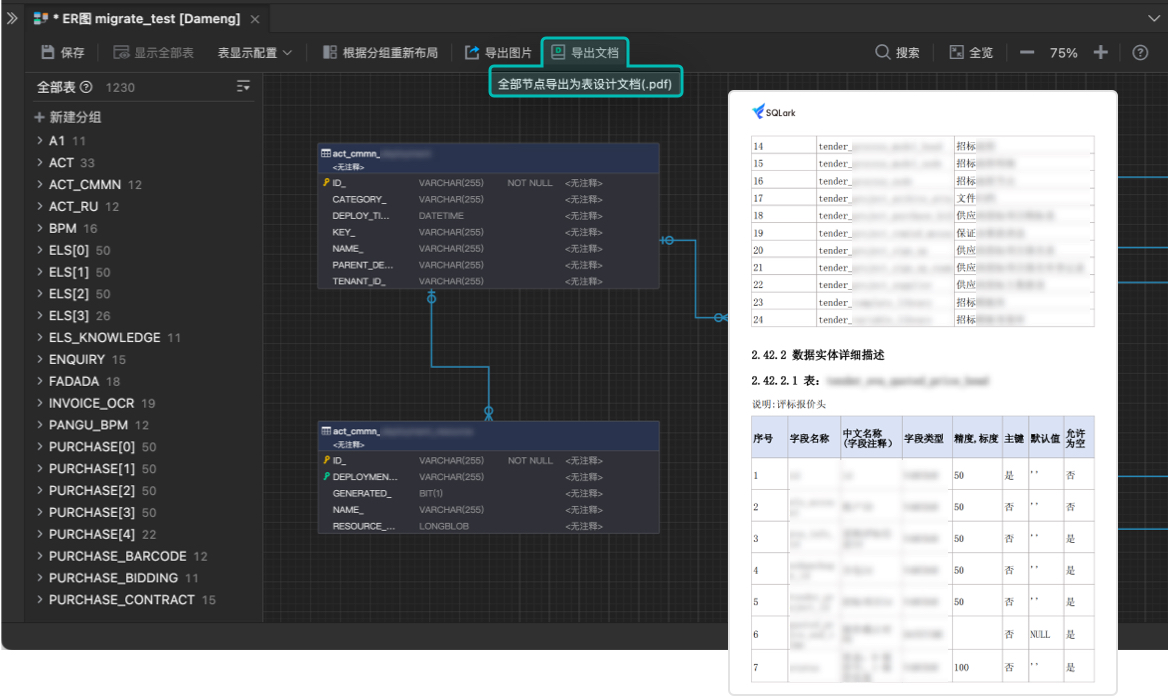
SQLark:一款国产免费数据库开发和管理工具
SQLark(百灵连接)是一款面向信创应用开发者的数据库开发和管理工具,用于快速查询、创建和管理不同类型的数据库系统,目前可以支持达梦数据库、Oracle 以及 MySQL。 对象管理 SQLark 支持丰富的数据库对象管理功能,包括…...

防爆对讲机VS非防爆对讲机,如何选择?
在通信设备的广阔市场中,对讲机以其高效、便捷的特点,成为众多行业不可或缺的沟通工具。而面对防爆对讲机与非防爆对讲机,许多用户常常陷入选择困境。究竟该如何抉择,且听我为您细细道来。 防爆对讲机,专为危险作业场…...

微信小程序开发:开发实践
微信小程序开发实践研究 摘要 随着移动互联网的迅猛发展,微信小程序作为一种轻量化、无需安装的应用形式,逐渐成为开发者和用户的首选。本文以“个人名片”小程序为例,详细阐述了微信小程序的开发流程,包括需求分析、项目规划、…...

操作 Office Excel 文档类库Excelize
Excelize 是 Go 语言编写的一个用来操作 Office Excel 文档类库,基于 ECMA-376 OOXML 技术标准。可以使用它来读取、写入 XLSX 文件,相比较其他的开源类库,Excelize 支持操作带有数据透视表、切片器、图表与图片的 Excel 并支持向 Excel 中插…...

青铜与信隼的史诗——TCP与UDP的千年博弈
点击下面图片带您领略全新的嵌入式学习路线 🔥爆款热榜 88万阅读 1.6万收藏 第一章 契约之匣与自由之羽 熔岩尚未冷却的铸造台上,初代信使长欧诺弥亚将液态秘银倒入双生模具。左侧模具刻着交握的青铜手掌,右侧则是展开的隼翼纹章。当星辰…...
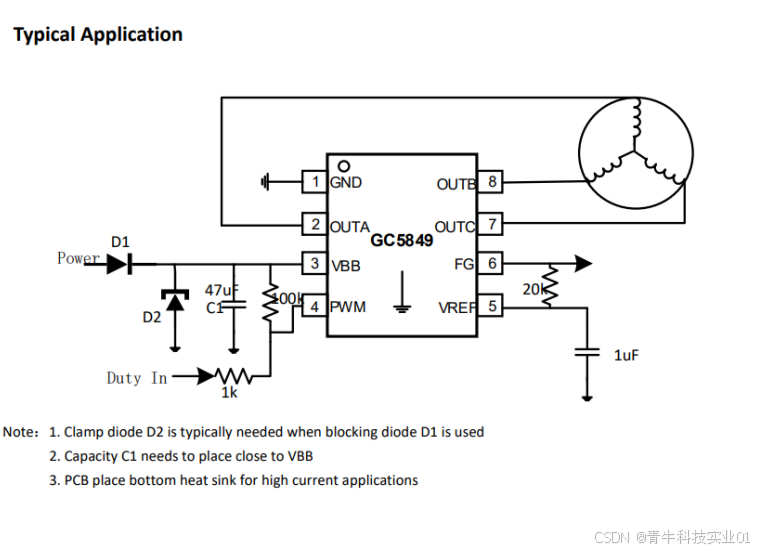
「青牛科技」GC5849 12V三相无感正弦波电机驱动芯片
芯片描述: • 4 ~ 20V 工作电压, 30V 最大耐压 • 驱动峰值电流 2.0A ,连续电流 800mA 以内 • 芯片内阻: 900mΩ (上桥 下桥) • eSOP-8 封装,底部 ePAD 散热,引…...

Java基础之反射的基本使用
简介 在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意属性和方法;这种动态获取信息以及动态调用对象方法的功能称为Java语言的反射机制。反射让Java成为了一门动…...
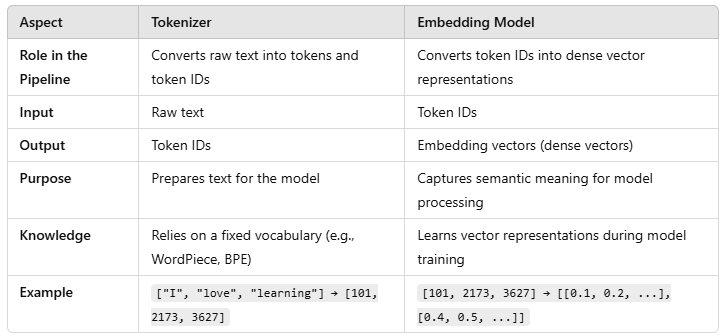
大语言模型中的嵌入模型
本教程将拆解什么是嵌入模型、为什么它们在NLP中如此重要,并提供一个简单的Python实战示例。 分词器将原始文本转换为token和ID,而嵌入模型则将这些ID映射为密集向量表示。二者合力为LLMs的语义理解提供动力。图片来源:[https://tzamtzis.gr/2024/coding/tokenization-by-an…...

【从零实现Json-Rpc框架】- 项目实现 - 服务端主题实现及整体封装
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
的作用)
位置编码(Positional Encoding, PE)的作用
在神经网络(尤其是Transformer、RNN等序列模型)中,位置编码(Positional Encoding, PE)的作用是为模型提供序列中元素的位置信息,以弥补模型本身对顺序感知的不足。 为什么Transformer需要位置编码…...
开源的 LLM 应用开发平台Dify的安装和使用
文章目录 前提环境应用安装deocker desktop镜像源配置Dify简介Dify本地docker安装Dify安装ollama插件Dify安装硅基流动插件简单应用练习进阶应用练习数据库图像检索与展示助手echart助手可视化 前提环境 Windows环境 docker desktop魔法环境:访问Dify项目ollama电脑…...
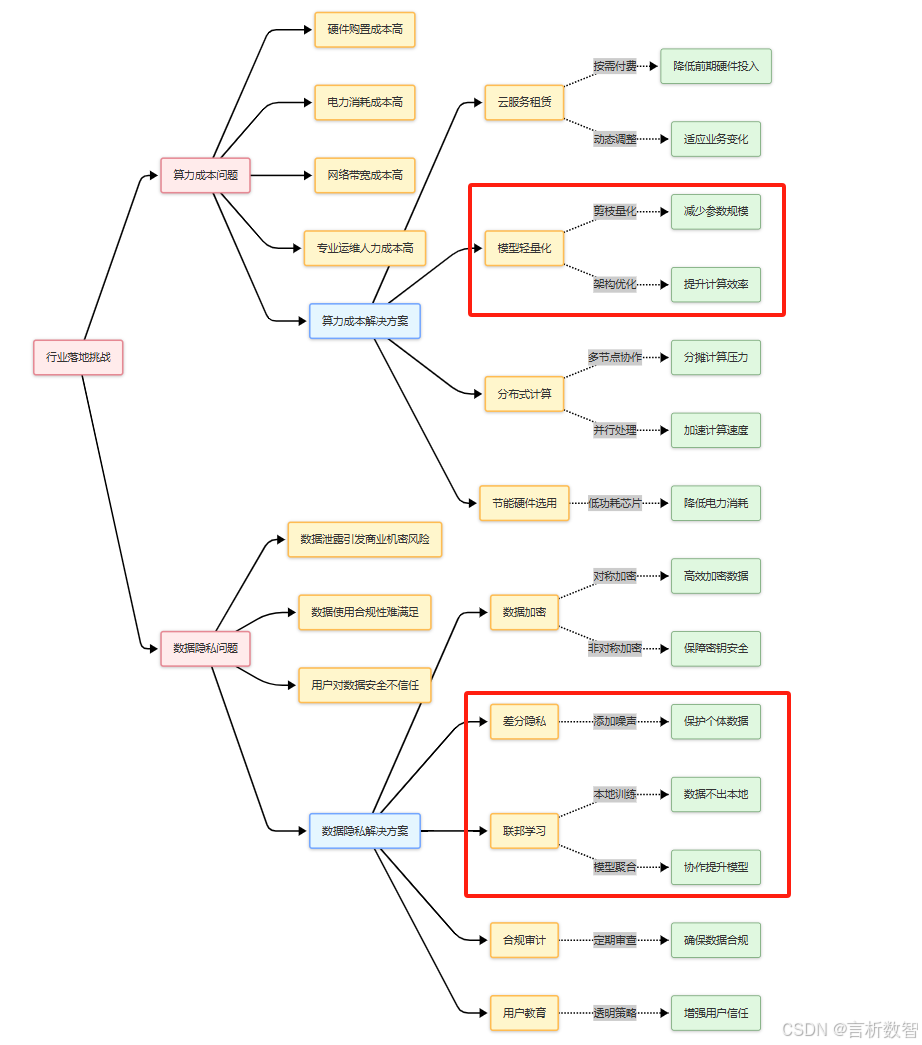
从零构建大语言模型全栈开发指南:第五部分:行业应用与前沿探索-5.1.2行业落地挑战:算力成本与数据隐私解决方案
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 从零构建大语言模型全栈开发指南-第五部分:行业应用与前沿探索5.1.2 行业落地挑战:算力成本与数据隐私解决方案1. 算力成本挑战与优化策略1.1 算力成本的核心问题1.2 算力优化技术方案2. 数据隐私挑战…...
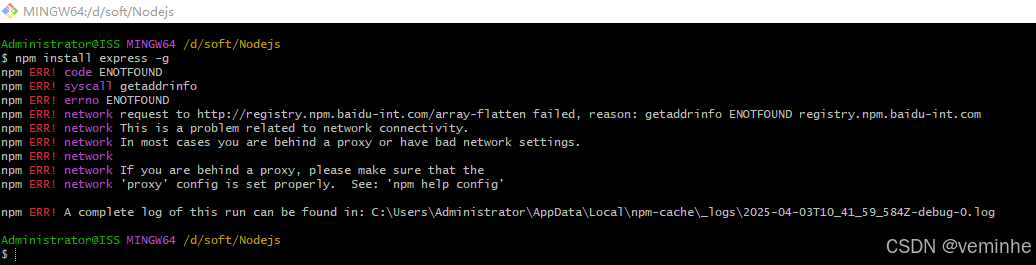
NodeJS--NPM介绍使用
1、使用npm install命令安装模块 1.1、本地安装 npm install express 1.2、全局安装 npm install express -g 1.3、本地安装和全局安装的区别...