科普:One-Class SVM和SVDD
SVM(支持向量机)算法是用于解决二分类问题的,它在样本空间(高维空间)中找一个最优超平面,使得两类数据点中离超平面最近的点(称为支持向量)到超平面的距离最大。
对于极少数“坏样本”的二分类场景,我们可以换个思路:将所有样本视为一类(而不是二类),而将极少数“坏样本”视为这一类的异常。这样,用于二分类的SVM就可以改造为用于一分类的One-Class SVM和SVDD。
One-Class SVM(单类支持向量机)与SVDD(支持向量数据描述)是单类分类领域的两大核心算法,它们的目标均为通过仅使用目标类样本建模,实现异常检测或数据描述。两者在理论基础和实现方式上存在紧密联系,但在决策边界形式、优化目标和应用场景上也有显著差异。以下是具体分析:
1. 核心联系:基于核方法的单类分类框架
1.1 共同的理论基础
- 核技巧:两者均通过核函数将数据映射到高维特征空间,以处理非线性分布问题。例如,使用RBF核将数据映射到无限维空间后,SVDD在高维空间中寻找最小超球体,而One-Class SVM则寻找最优超平面。
- 对偶优化:两者的优化问题均可转化为二次规划问题,并通过拉格朗日对偶方法求解。支持向量(Support Vectors)在两种算法中均起关键作用,决定决策边界的形状。
- 参数敏感性:均依赖惩罚参数(如One-Class SVM的 n u nu nu或SVDD的 C C C)平衡模型复杂度与异常点容忍度,且核函数参数(如RBF核的 γ γ γ)需谨慎调优。
1.2 数学等价性
- 特定条件下的等价性:当使用满足 k ( x , x ) = 1 k(x, x) = 1 k(x,x)=1的核函数(如归一化RBF核)时,One-Class SVM与SVDD的决策函数等价。例如,对于高斯核 k ( x , x ′ ) = e x p ( − γ ∣ ∣ x − x ′ ∣ ∣ 2 ) k(x, x') = exp(-γ||x-x'||²) k(x,x′)=exp(−γ∣∣x−x′∣∣2),若归一化为 k ( x , x ′ ) = e x p ( − γ ∣ ∣ x − x ′ ∣ ∣ 2 ) / e x p ( − γ ∣ ∣ x ∣ ∣ 2 ) e x p ( − γ ∣ ∣ x ′ ∣ ∣ 2 ) k(x, x') = exp(-γ||x-x'||²)/exp(-γ||x||²)exp(-γ||x'||²) k(x,x′)=exp(−γ∣∣x−x′∣∣2)/exp(−γ∣∣x∣∣2)exp(−γ∣∣x′∣∣2),则两者的超平面与超球体决策边界在数学上等价。
- 渐近一致性:在数据分布接近球状时,两者的分类结果趋近于一致。例如,当目标类数据在高维空间中近似正态分布时,SVDD的超球体与One-Class SVM的超平面可能重合。
2. 关键区别:决策边界与优化目标
2.1 决策边界形状
- One-Class SVM:
通过超平面(Hyperplane)将目标类数据与原点(或其他参考点)分离。其优化目标是最大化超平面与原点的距离,同时允许少量样本跨越超平面(通过松弛变量)。例如,在二维空间中,超平面表现为一条直线,将目标类数据与原点分隔开。 - SVDD:
通过超球体(Hypersphere)将目标类数据紧密包围。其优化目标是最小化超球体的体积,同时允许部分样本位于球体外(通过松弛变量)。例如,在二维空间中,超球体表现为一个圆,尽可能紧凑地包含目标类数据。
2.2 优化目标差异
- One-Class SVM:
目标函数为:
min w , ρ , ξ 1 2 ∥ w ∥ 2 − ρ + 1 ν n ∑ i = 1 n ξ i \min_{\mathbf{w}, \rho, \xi} \quad \frac{1}{2}\|\mathbf{w}\|^2 - \rho + \frac{1}{\nu n} \sum_{i=1}^n \xi_i w,ρ,ξmin21∥w∥2−ρ+νn1i=1∑nξi
约束条件:
w T ϕ ( x i ) ≥ ρ − ξ i , ξ i ≥ 0 \mathbf{w}^T \phi(\mathbf{x}_i) \geq \rho - \xi_i, \quad \xi_i \geq 0 wTϕ(xi)≥ρ−ξi,ξi≥0
其中, w \mathbf{w} w 是超平面的法向量, ρ \rho ρ 是超平面到原点的距离, ν \nu ν 控制异常点比例。
ϕ \phi ϕ把从原始空间中的特征向量 x \mathbf{x} x映射成特征空间中的特征向量 ϕ ( x ) \phi(\mathbf{x}) ϕ(x),下同。 - SVDD:
目标函数为:
min R , a , ξ R 2 + C ∑ i = 1 n ξ i \min_{R, \mathbf{a}, \xi} \quad R^2 + C \sum_{i=1}^n \xi_i R,a,ξminR2+Ci=1∑nξi
约束条件:
∥ ϕ ( x i ) − a ∥ 2 ≤ R 2 + ξ i , ξ i ≥ 0 \|\phi(\mathbf{x}_i) - \mathbf{a}\|^2 \leq R^2 + \xi_i, \quad \xi_i \geq 0 ∥ϕ(xi)−a∥2≤R2+ξi,ξi≥0
其中, a \mathbf{a} a 是超球体的中心, R R R 是半径, C C C 平衡球体体积与异常点数量。
2.3 几何直观
- One-Class SVM:
超平面的位置由目标类数据与原点的距离决定。若数据分布集中,超平面可能远离原点;若数据分散,超平面可能靠近原点以减少误判。 - SVDD:
超球体的大小和位置由数据的紧凑程度决定。若数据集中,超球体体积较小;若数据分散,超球体体积较大以包含更多样本。
3. 应用场景对比
| 场景 | One-Class SVM | SVDD |
|---|---|---|
| 数据分布 | 适用于数据分布接近线性可分或具有明确方向的场景。例如,文本数据的主题分布。 | 适用于数据分布呈团状或球状的场景。例如,图像中的物体轮廓。 |
| 异常点敏感性 | 对异常点较敏感,因为超平面可能被离群点显著影响。 | 对异常点较鲁棒,因为超球体可通过松弛变量排除极端值。 |
| 计算复杂度 | 训练复杂度与样本数呈二次方关系( O ( n 3 ) O(n^3) O(n3)),适用于小样本。 | 训练复杂度与样本数呈二次方关系( O ( n 3 ) O(n^3) O(n3)),但可通过分解算法优化。 |
| 参数调优 | 参数 n u nu nu直接控制异常点比例,更易解释。 | 参数 C C C和核函数参数需联合调优,对用户经验要求较高。 |
| 典型应用 | 网络入侵检测、信用卡欺诈识别(需快速决策)。 | 工业缺陷检测、医学影像分析(需紧凑数据描述)。 |
4. 如何选择?
- 优先选择One-Class SVM:
当数据分布具有明确方向性(如文本、时序数据),或需要直接控制异常点比例时。例如,在信用卡欺诈检测中, n u nu nu参数可直接设定允许的欺诈交易比例。 - 优先选择SVDD:
当数据分布呈团状或球状(如图像、传感器数据),或需要更紧凑的数据描述时。例如,在工业质检中,SVDD的超球体可精确圈定合格产品的特征范围。 - 等价性场景:
若使用归一化RBF核且数据分布近似球状,两者效果接近,可根据计算效率或参数调优便利性选择。
5. 决策边界、原点与异常点
在 One-Class SVM 和 SVDD 中,在特征空间中,算法所找到的超平面和超球面对应到原始空间中就是这类型状,通常是一个超曲面,称为决策边界。
现在我们考察在原始空间中三者(决策边界、原点与异常点)的位置关系。
- One-Class SVM:原点与异常点同侧,因为超平面的设计目标是将正常数据与原点分离,异常点被视为与原点更接近的样本。
- SVDD:原点与异常点的位置关系不确定,取决于数据分布。若原点在超球体内,异常点与原点异侧;若原点在球体外,异常点与原点同侧。
- 选择建议:
- 若需要明确控制异常点与原点的位置关系(如同侧),优先选择 One-Class SVM。
- 若数据分布复杂且原点位置不明确,SVDD 更灵活,但需通过数据预处理或参数调优控制原点与异常点的关系。
5.1 One-Class SVM:原点与异常点
1. 决策边界与原点的关系
- 超平面分离:
One-Class SVM 的核心是在特征空间中寻找一个超平面,将目标类数据与原点(或其他参考点)最大化分离。其优化目标是:
min w , ρ , ξ 1 2 ∥ w ∥ 2 − ρ + 1 ν n ∑ i = 1 n ξ i \min_{\mathbf{w}, \rho, \xi} \quad \frac{1}{2}\|\mathbf{w}\|^2 - \rho + \frac{1}{\nu n} \sum_{i=1}^n \xi_i w,ρ,ξmin21∥w∥2−ρ+νn1i=1∑nξi
约束条件为:
w T ϕ ( x i ) ≥ ρ − ξ i ( ξ i ≥ 0 ) \mathbf{w}^T \phi(\mathbf{x}_i) \geq \rho - \xi_i \quad (\xi_i \geq 0) wTϕ(xi)≥ρ−ξi(ξi≥0)
其中, w \mathbf{w} w是超平面的法向量, ρ \rho ρ是超平面到原点的距离。- 正常样本:位于超平面的一侧( w T ϕ ( x i ) ≥ ρ \mathbf{w}^T \phi(\mathbf{x}_i) \geq \rho wTϕ(xi)≥ρ)。
- 原点:位于超平面的另一侧( w T ϕ ( 0 ) < ρ \mathbf{w}^T \phi(0) < \rho wTϕ(0)<ρ),因为超平面的设计目标是将正常数据与原点分隔开。
2. 异常点的位置
- 异常点的定义:
若测试样本 x \mathbf{x} x满足 w T ϕ ( x ) < ρ \mathbf{w}^T \phi(\mathbf{x}) < \rho wTϕ(x)<ρ,则被判定为异常点。 - 与原点的关系:
异常点位于超平面的另一侧,即与原点同侧。这是因为超平面的设计目标是将正常数据与原点分离,而异常点被视为与原点“更接近”的样本。- 几何直观:在二维空间中,超平面将正常数据与原点分隔,异常点位于原点所在的一侧。例如,若正常数据分布在右侧,超平面可能是一条垂直直线,原点和异常点位于左侧。
3. 核函数的影响
- 特征空间变换:
核函数(如 RBF 核)将数据映射到高维特征空间,原点在特征空间中的位置可能与输入空间不同。例如,使用 RBF 核时,原点的特征向量可能与输入空间的原点无关。 - 决策逻辑不变:
无论核函数如何,超平面始终将正常数据与特征空间的原点分离,异常点仍位于原点所在的一侧。
5.2 SVDD:原点与异常点
1. 决策边界与原点的关系
- 超球体包围:
SVDD 的目标是在特征空间中找到一个最小体积的超球体,尽可能紧密地包围目标类数据。其优化目标为:
min R , a , ξ R 2 + C ∑ i = 1 n ξ i \min_{R, \mathbf{a}, \xi} \quad R^2 + C \sum_{i=1}^n \xi_i R,a,ξminR2+Ci=1∑nξi
约束条件为:
∥ ϕ ( x i ) − a ∥ 2 ≤ R 2 + ξ i ( ξ i ≥ 0 ) \|\phi(\mathbf{x}_i) - \mathbf{a}\|^2 \leq R^2 + \xi_i \quad (\xi_i \geq 0) ∥ϕ(xi)−a∥2≤R2+ξi(ξi≥0)
其中, a \mathbf{a} a是超球体的中心, R R R是半径。- 正常样本:位于超球体内( ∥ ϕ ( x i ) − a ∥ 2 ≤ R 2 \|\phi(\mathbf{x}_i) - \mathbf{a}\|^2 \leq R^2 ∥ϕ(xi)−a∥2≤R2)。
- 原点:其位置由数据分布决定,可能在超球体内或外。
2. 异常点的位置
- 异常点的定义:
若测试样本 x \mathbf{x} x满足 ∥ ϕ ( x ) − a ∥ 2 > R 2 \|\phi(\mathbf{x}) - \mathbf{a}\|^2 > R^2 ∥ϕ(x)−a∥2>R2,则被判定为异常点。 - 与原点的关系:
- 若原点在超球体内:异常点位于球体外,与原点异侧。
- 若原点在超球体外:异常点也位于球体外,与原点同侧。
- 示例:
- 若目标类数据分布在远离原点的区域,超球体可能不包含原点,此时原点和异常点均位于球体外(同侧)。
- 若目标类数据分布在原点附近,超球体可能包含原点,此时异常点位于球体外(异侧)。
3. 数据分布的影响
- 原点的位置:
超球体的中心 a \mathbf{a} a和半径 R R R由数据分布决定。例如:- 若数据集中在原点附近, a \mathbf{a} a可能接近原点,超球体包含原点。
- 若数据分布在远离原点的区域, a \mathbf{a} a也会远离原点,超球体可能不包含原点。
- 异常点的位置:
无论原点是否在超球体内,异常点始终位于球体外,但与原点的相对位置取决于数据分布。
5.3 数学推导与验证
1. One-Class SVM 的决策函数
- 函数形式:
f ( x ) = w T ϕ ( x ) − ρ f(\mathbf{x}) = \mathbf{w}^T \phi(\mathbf{x}) - \rho f(x)=wTϕ(x)−ρ- 正常样本: f ( x ) ≥ 0 f(\mathbf{x}) \geq 0 f(x)≥0(位于超平面一侧)。
- 原点: f ( 0 ) = w T ϕ ( 0 ) − ρ < 0 f(0) = \mathbf{w}^T \phi(0) - \rho < 0 f(0)=wTϕ(0)−ρ<0(位于另一侧)。
- 异常点: f ( x ) < 0 f(\mathbf{x}) < 0 f(x)<0(与原点同侧)。
2. SVDD 的决策函数
- 函数形式:
f ( x ) = ∥ ϕ ( x ) − a ∥ 2 − R 2 f(\mathbf{x}) = \|\phi(\mathbf{x}) - \mathbf{a}\|^2 - R^2 f(x)=∥ϕ(x)−a∥2−R2- 正常样本: f ( x ) ≤ 0 f(\mathbf{x}) \leq 0 f(x)≤0(位于球体内)。
- 原点: f ( 0 ) = ∥ ϕ ( 0 ) − a ∥ 2 − R 2 f(0) = \|\phi(0) - \mathbf{a}\|^2 - R^2 f(0)=∥ϕ(0)−a∥2−R2,其符号取决于 a \mathbf{a} a和 R R R。
- 异常点: f ( x ) > 0 f(\mathbf{x}) > 0 f(x)>0(位于球体外)。
相关文章:

科普:One-Class SVM和SVDD
SVM(支持向量机)算法是用于解决二分类问题的,它在样本空间(高维空间)中找一个最优超平面,使得两类数据点中离超平面最近的点(称为支持向量)到超平面的距离最大。 对于极少数“坏样本…...

Vue 3 中按照某个字段将数组分成多个数组
方法一:使用 reduce 方法 const originalArray [{ id: 1, category: A, name: Item 1 },{ id: 2, category: B, name: Item 2 },{ id: 3, category: A, name: Item 3 },{ id: 4, category: C, name: Item 4 },{ id: 5, category: B, name: Item 5 }, ];const grou…...

冒泡排序笔记
核心思想 通过相邻元素的比较和交换,使较大的元素逐渐“浮”到数组的末尾(像气泡从水底冒到水面一样) 基础冒泡排序 public class BubbleSort{public static void bubbleSort(int[] arr){for(int i 0; i < arr.length - 1; i){//冒泡…...
)
【ABAP】REST/HTTP技术(一)
1、概念 1.1、SAP 如何提供 Http Service 如果要将 SAP 应用程序服务器 (application server)作为 http 服务提供者,需要定义一个类,这个类必须实现 IF_HTTP_EXTENSION 接口。IF_HTTP_EXTENSION 接口只有一个方法 HANDLE_REQUEST。…...

Flutter PopupMenuButton 深度解析:从入门到架构级实战
在移动应用交互设计中,上下文菜单如同隐形的魔法师,在有限屏幕空间中优雅地扩展操作维度。作为Flutter框架中的核心交互组件,PopupMenuButton绝非简单的菜单触发器,其背后蕴含着Material Design的交互哲学、声明式UI的架构智慧以及…...

C语言基础要素(019):输出ASCII码表
计算机以二进制处理信息,但二进制对人类并不友好。比如说我们规定用二进制值 01000001 表示字母’A’,显然通过键盘输入或屏幕阅读此数据而理解它为字母A,是比较困难的。为了有效的使用信息,先驱者们创建了一种称为ASCII码的交换代…...

VSCode开发者工具快捷键
自动生成浏览器文件.html的快捷方式 在文本里输入: ! enter VSCode常用快捷键列表 代码格式化:Shift Alt F向上或向下移动一行:Alt Up 或者 Alt Down快速复制一行代码:Shift Alt Up 或者 Shift Alt Down快速保…...

CI/CD(九) Jenkins共享库与多分支流水线准备
后端构建 零:安装插件 Pipeline: Stage View(阶段视图)、SSH Pipeline Steps(共享库代码中要调用sshCommond命令) 一、上传共享库 二、Jenkins配置共享库 3、新增静态资源与修改配置 如果是docker和k8s启动…...

使用Deployment运行无状态应用
使用Deployment运行无状态应用 文章目录 使用Deployment运行无状态应用[toc]一、工作负载资源与控制器二、ReplicationController、ReplicaSet和Deployment1. ReplicationController(已淘汰)2. ReplicaSet(ReplicationController 的增强版&am…...

pip安装timm依赖失败
在pycharm终端给虚拟环境安装timm库失败( pip install timm),提示你要访问 https://rustup.rs/ 来下载并安装 Rust 和 Cargo 直接不用管,换一条命令 pip install timm0.6.13 成功安装 简单粗暴...

详解隔离级别(4种),分别用表格展示问题出现的过程及解决办法
选择隔离级别的时候,既需要考虑数据的一致性,避免脏数据,又要考虑系统性能的问题。下面我们通过商品抢购的场景来讲述这4种隔离级别的区别 未提交读(read uncommitted) 未提交读是最低的隔离级别,其含义是…...
NO.63十六届蓝桥杯备战|基础算法-⼆分答案|木材加工|砍树|跳石头(C++)
⼆分答案可以处理⼤部分「最⼤值最⼩」以及「最⼩值最⼤」的问题。如果「解空间」在从⼩到⼤的「变化」过程中,「判断」答案的结果出现「⼆段性」,此时我们就可以「⼆分」这个「解空间」,通过「判断」,找出最优解。 这个「⼆分答案…...

深层储层弹塑性水力裂缝扩展机理
弹性与弹塑性储层条件下裂缝形态对比 参考: The propagation mechanism of elastoplastic hydraulic fracture in deep reservoir | International Journal of Coal Science & Technology...
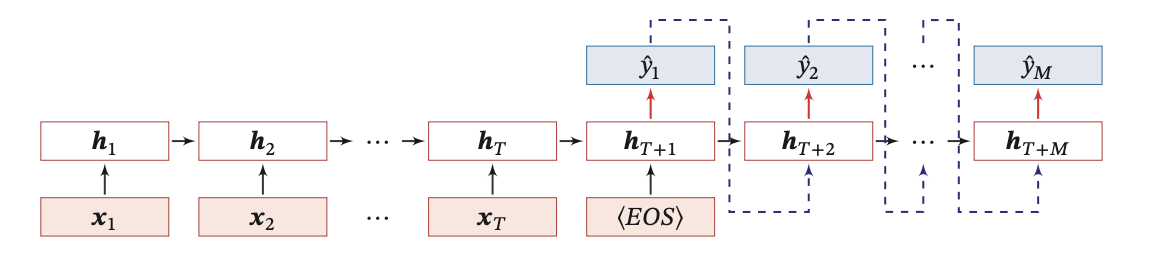
循环神经网络 - 机器学习任务之异步的序列到序列模式
前面我们学习了机器学习任务之同步的序列到序列模式:循环神经网络 - 机器学习任务之同步的序列到序列模式-CSDN博客 本文我们来学习循环神经网络应用中的第三种模式:异步的序列到序列模式! 一、基本概述: 异步的序列到序列模式…...
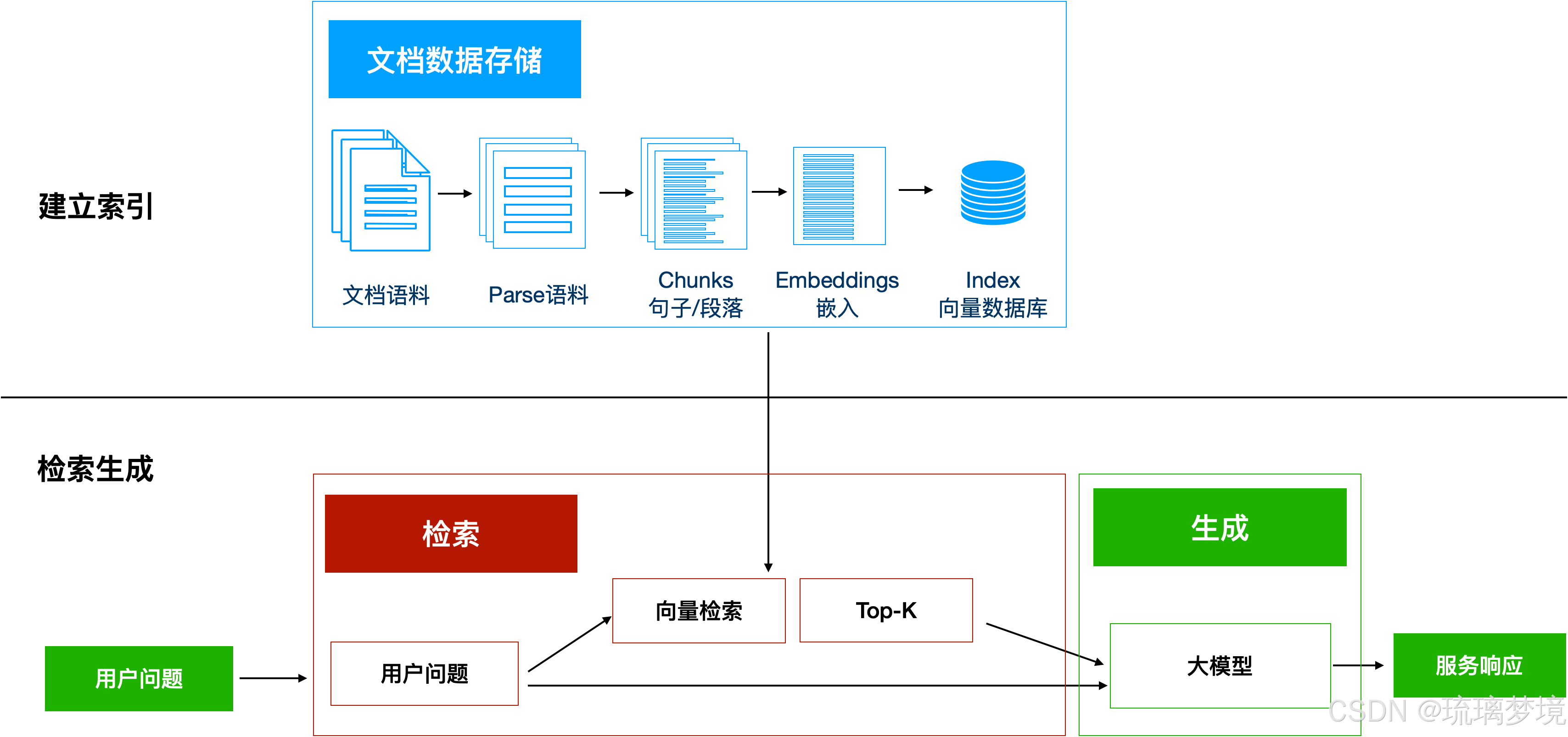
什么是检索增强生成(RAG)
1、什么是检索增强生成(RAG) 1.1 检索增强生成的概念 检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合了信息检索和文本生成技术的新型自然语言处理方法。这种方法增强了模型的理解和生成能力。 相较于经典生成…...
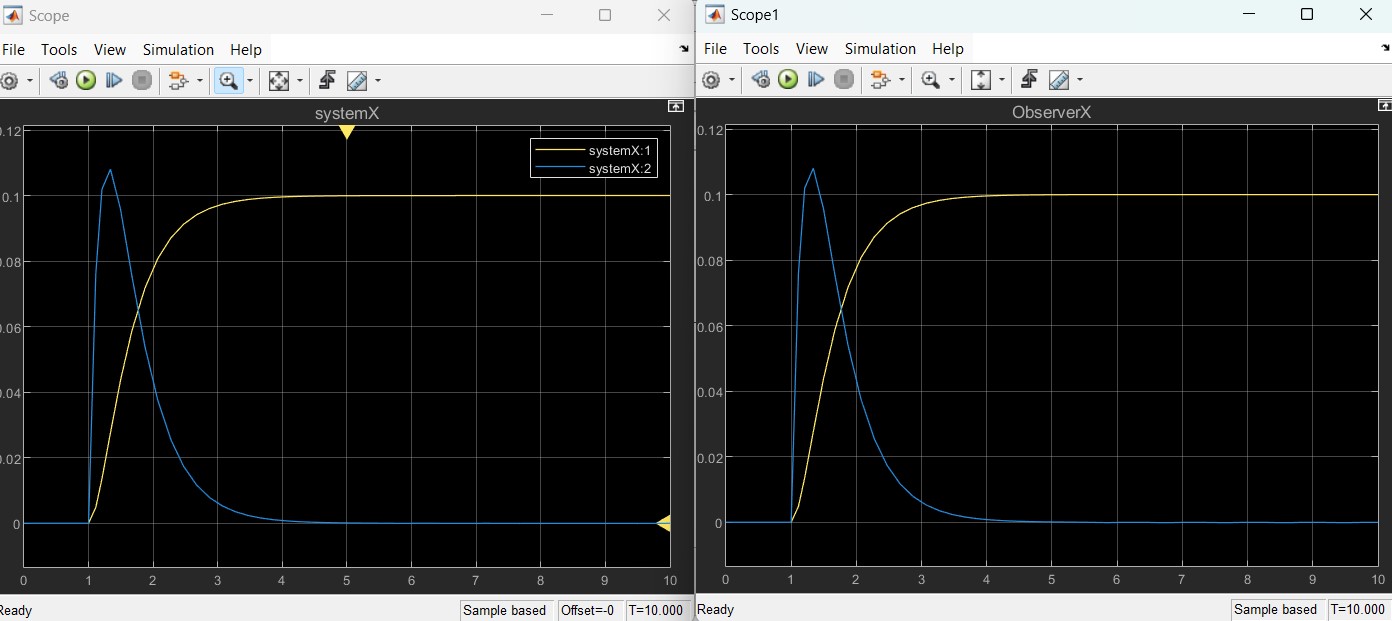
MATLAB 控制系统设计与仿真 - 33
状态反馈控制系统 -全维状态观测器的实现 状态观测器的建立解决了受控系统不能测量的状态重构问题,使得状态反馈的工程实现成为可能。 考虑到系统的状态方程表达式,如果{A,B}可控,{A,C}可观,且安装系统的性能指标,可…...

PM2 在 Node.js 项目中的使用与部署指南
一、PM2 简介 PM2 是一个带有负载均衡功能的 Node.js 应用程序的进程管理器。它可以让你的 Node.js 应用程序始终保持运行状态,即使出现错误或服务器重启也能自动恢复。同时,它还提供了诸如日志管理、性能监控等实用功能,极大地简化了 Nod…...
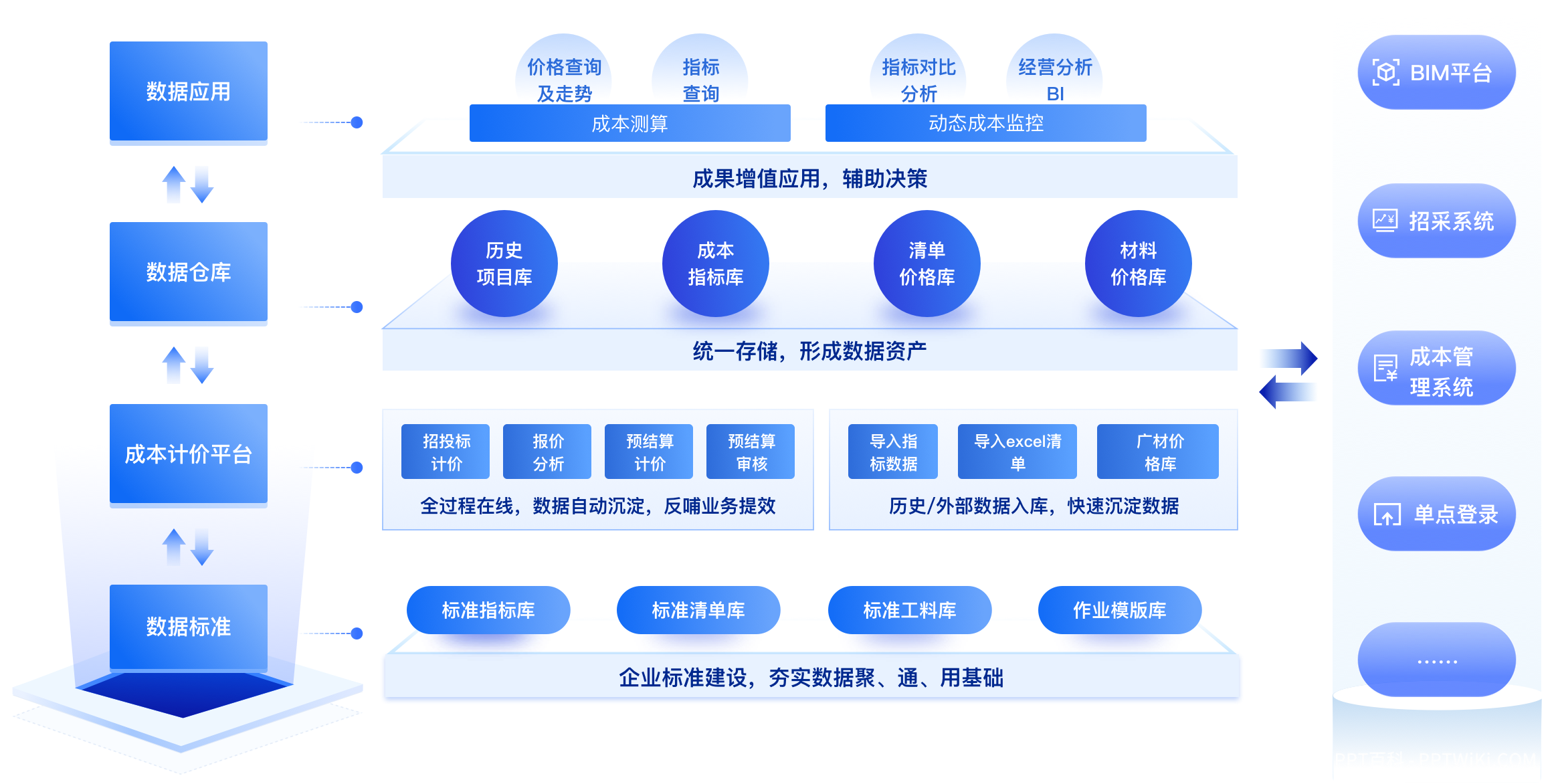
企业管理系统的功能架构设计与实现
一、企业管理系统的核心功能模块 企业管理系统作为现代企业的中枢神经系统,涵盖了多个核心功能模块,以确保企业运营的顺畅与高效。这些功能模块通常包括: 人力资源管理模块:负责员工信息的录入、维护、查询及统计分析,…...

RTOS基础 -- NXP M4小核的RPMsg-lite与端点机制回顾
一、RPMsg-lite与端点机制回顾 在RPMsg协议框架中: Endpoint(端点) 是一个逻辑通信端口,由本地地址(local addr)、远程地址(remote addr)和回调函数组成。每个消息都会发送到特定的…...

Cursor的主要好处
以下是Cursor的主要好处: 代码生成与优化 • 快速生成代码:根据简短描述或部分代码片段,Cursor能快速生成完整代码模块,还能智能预测下一步操作,将光标放在合适位置,让开发者一路Tab键顺滑编写代码。 • …...

覆盖学术、职场、生活的专业计算工具
软件介绍 今天要给大家介绍一款超给力的工具软件——CalcKit 计算器。它就像是你口袋里的智能计算专家,轻松化解日常生活中的各类计算难题。无论是简单的数字加减乘除,还是复杂的专业运算,它都不在话下。 这款软件内置了极为强大的计算功能…...

【大模型系列篇】大模型基建工程:基于 FastAPI 自动构建 SSE MCP 服务器 —— 进阶篇
🔥🔥🔥 上期 《大模型基建工程:基于 FastAPI 自动构建 SSE MCP 服务器》中我们使用fastapi-mcp自动挂载fastapi到mcp工具,通过源码分析和实践,我们发现每次sse请求又转到了内部fastapi RESTful api接口&…...

嵌入式硬件篇---USBUART串口
文章目录 前言一、UART 通信原理1.发送原理2.接收原理二、单片机UART接收十六进制数的处理方式1.数据解析2.数据存储3.执行相应操作三、USB通信原理四、USB 转串口通信1.硬件连接2.驱动程序3.数据传输过程五、通信特点与应用场景1.USB通信特点与应用场景2.串口通过特点与应用场…...

湖南移动广东电信DNS
湖南移动DNS: DNS 1: 111.8.14.18 DNS 2: 211.142.211.124 DNS 3: 2409:8050:2000::1 DNS 4: 2409:8050:2000:1000::1 湖南电信DNS: DNS 1: 59.51.78.210 DNS 2: 222.246.129.80 DNS 3: 240e:50:c800::210 DNS 4: 240e:50:5000::80 广东电信DNS: DNS 1…...

百度查询的ip与命令行输入 ipconfig 显示的IP地址有以下主要区别:
IP类型不同 百度中的IP是公网IP(WAN IP),由运营商分配,用于在互联网上标识你的网络出口。 ipconfig 显示的是本地IP(LAN IP),通常是路由器分配给设备的私有地址(如192.168.x.x、10.…...

【python】Plot a Square
文章目录 1、功能描述2、代码实现3、效果展示4、完整代码5、涉及到的库函数 更多有趣的代码示例,可参考【Programming】 1、功能描述 用 python 实现,以 A和B两个点为边长,方向朝 C 绘制正方形 思路: 计算向量 AB 和 AC。使用向…...
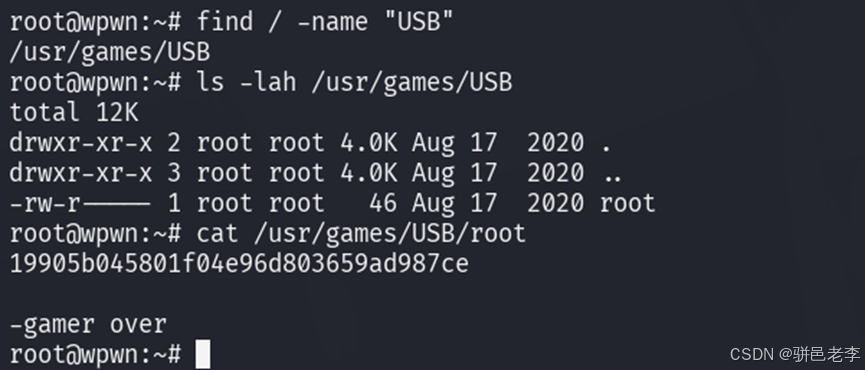
实战打靶集锦-37-Wpwnvm
文章目录 1. 主机发现2. 端口扫描&服务枚举3. 服务探查4. 系统提权 靶机地址:https://download.vulnhub.com/wpwn/wpwnvm.zip 1. 主机发现 目前只知道目标靶机在192.168.37.xx网段,通过如下的命令,看看这个网段上在线的主机。 $ nmap -…...
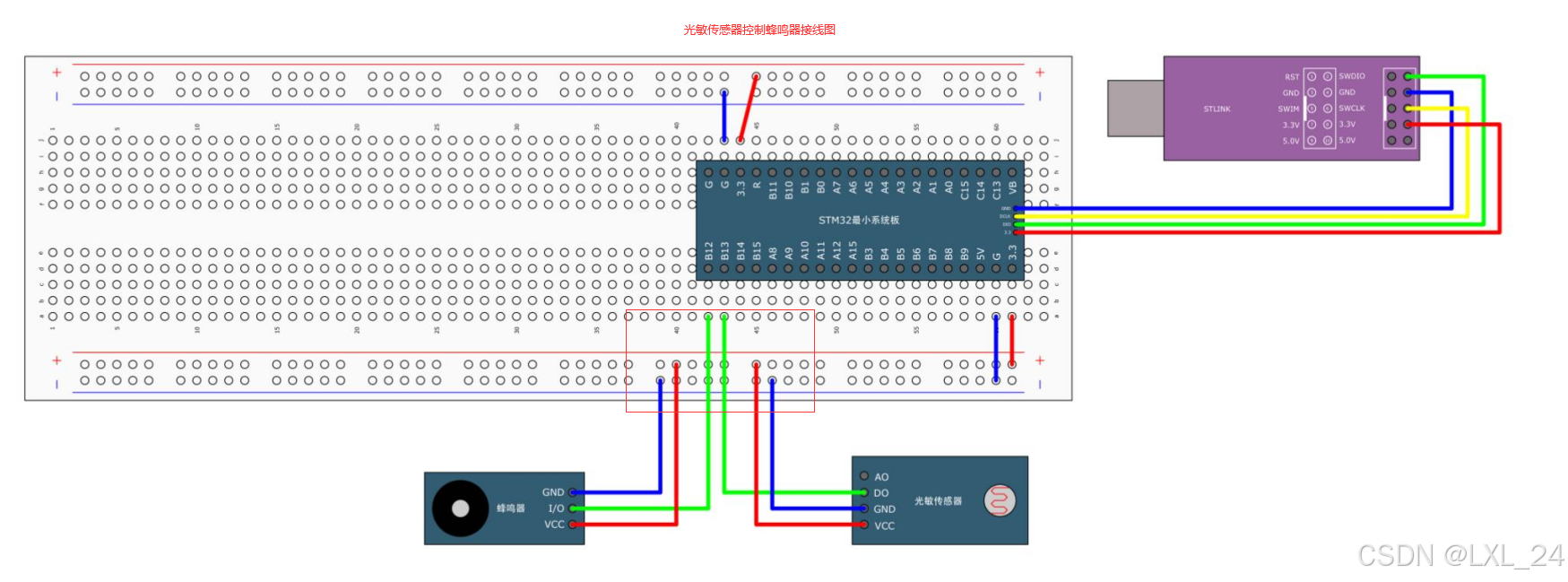
三、GPIO
一、GPIO简介 GPIO(General Purpose Input Output)通用输入输出口GPIO引脚电平:0V(低电平)~3.3V(高电平),部分引脚可容忍5V 容忍5V,即部分引脚输入5V的电压,…...

Guava Cache 实战:构建高并发场景下的字典数据缓存
一、场景背景 在系统开发中,字典数据(如状态类型、分类数据)具有以下特点: 高频读取(每个请求都可能涉及)低频变化(管理员修改后才会变更)数据一致性要求适中(允许分钟…...

混杂模式(Promiscuous Mode)与 Trunk 端口的区别详解
一、混杂模式(Promiscuous Mode) 1. 定义与工作原理 定义:混杂模式是网络接口的一种工作模式,允许接口接收通过其物理链路的所有数据包,而不仅是目标地址为本机的数据包。工作层级:OSI 数据链路层&#x…...