Kafka+Zookeeper从docker部署到spring boot使用完整教程
文章目录
- 一、Kafka
- 1.Kafka核心介绍:
- 核心架构
- 核心特性
- 典型应用
- 2.Kafka对 ZooKeeper 的依赖:
- 3.去 ZooKeeper 的演进之路:
- 注:(本文采用ZooKeeper3.8 + Kafka2.8.1)
- 二、Zookeeper
- 1.核心架构与特性
- 2.典型应用场景
- 3.优势与局限
- 三、Zookeeper安装部署
- 1.拉取镜像
- 2.创建数据卷
- 3.创建容器
- 4.Zookeepe可视化工具-prettyZoo下载和安装
- 5.prettyZoo使用
- 四、Kafka安装部署
- 1.拉取镜像
- 2.创建数据卷
- 3.创建容器
- 4.Kakfa可视化操作工具kafka-ui安装
- 4.1、拉镜像
- 4.2、创建容器
- 4.3、访问kafka-ui
- 5.Kakfa可视化操作工具kafka-ui使用
- 五、Spring Boot使用Kafka
- 1.pom文件引入关键jar
- 2.yml文件引入配置
- 3.Topic配置
- 4.消息体创建
- 5.Producer实现
- 6.Consumer实现
- 7.启动类配置
- 8.Controller测试发送
- 9.测试验证
- 总结
一、Kafka
kafka官方文档
1.Kafka核心介绍:
Apache Kafka 是由 Apache 软件基金会开发的开源分布式流处理平台,最初由 LinkedIn 团队设计,旨在解决大规模实时数据管道问题。其核心功能是作为高吞吐、低延迟的分布式发布-订阅消息系统,支持每秒百万级消息处理能力。
核心架构
Topic(主题):消息的逻辑分类,生产者按主题发布数据,消费者按主题订阅。
Partition(分区):每个主题划分为多个分区,实现数据并行处理和水平扩展。
Broker(代理):Kafka 集群中的服务节点,负责存储和路由消息。
Producer/Consumer:生产者推送消息至 Broker,消费者从 Broker 拉取数据,支持消费者组(Consumer Group)实现负载均衡。
核心特性
持久化与高可靠:消息持久化到磁盘,通过多副本机制(Replication)保障数据容错。
水平扩展:通过分区和 Broker 动态扩容,支持万级节点和 PB 级数据存储。
实时流处理:与 Spark、Flink 等框架集成,支持实时计算、日志聚合、监控报警等场景。
典型应用
日志收集:统一收集多源日志,供离线分析或实时监控。
消息队列:解耦系统组件,如电商订单与库存服务异步通信。
实时推荐:基于用户行为流(如点击、搜索)实时生成个性化推荐。
数据管道:作为 CDC(变更数据捕获)工具,同步数据库变更至数据湖或搜索引擎。
Kafka 凭借其高性能和灵活性,已成为大数据生态的核心组件,适用于金融、物联网、电商等领域的实时数据处理需求。
2.Kafka对 ZooKeeper 的依赖:
Apache Kafka 在 4.0 版本之前 高度依赖 ZooKeeper,主要用于集群元数据管理(如 Broker 注册、Topic 分区分配)、控制器选举、消费者偏移量存储(旧版本)等核心功能。ZooKeeper 作为分布式协调服务,承担了 Kafka 集群的“大脑”角色,但存在运维复杂、性能瓶颈(如万级分区下元数据同步延迟)等问题。
3.去 ZooKeeper 的演进之路:
Kafka 2.8.0(2021年):
首次引入 KRaft 模式(KIP-500),作为实验性功能,允许用户通过 KRaft 协议替代 ZooKeeper 管理元数据。但此时仍需 ZooKeeper 作为过渡支持,且未默认启用。
Kafka 3.3.x(2022年):
KRaft 模式逐步稳定,支持生产环境部署,但仍需用户手动配置切换模式。
Kafka 4.0.0(2025年3月18日发布):
正式移除对 ZooKeeper 的依赖,默认仅支持 KRaft 模式。用户无法再以 ZooKeeper 模式启动集群,需通过 KRaft 完成元数据管理和控制器选举。
注:(本文采用ZooKeeper3.8 + Kafka2.8.1)
我们本文还是使用kafka+zookeeper结合的方式来学习Kafka,在学习kafka的同时也能学习到zookeeper的使用,现在大部分公司还都在使用这种方式。
二、Zookeeper
Zookeeper官网
ZooKeeper 是一款由雅虎开源的分布式协调服务框架,旨在为分布式系统提供高效、可靠的一致性服务。其核心功能包括配置管理、分布式锁、服务注册与发现等,广泛应用于大数据和微服务领域(如 Kafka、HBase、Dubbo)。
1.核心架构与特性
数据模型
采用树形结构的 ZNode(数据节点)存储数据,每个节点可保存数据并包含子节点,类似于文件系统。节点分为四类:
持久节点:长期存在,需手动删除
临时节点:会话结束自动删除
顺序节点:自动追加全局唯一序号,适用于分布式队列
一致性保障
基于 ZAB(ZooKeeper Atomic Broadcast)协议,确保数据顺序一致性、原子性和可靠性。通过 Leader 选举机制(半数以上节点投票)实现高可用,集群需奇数节点(如 3、5 台)以防止脑裂。
动态监听(Watcher)
客户端可监听节点变化(数据修改、子节点增减),触发事件通知实现实时响应。
2.典型应用场景
配置管理:集中存储配置信息,动态推送到所有服务节点
分布式锁:通过临时顺序节点实现互斥资源访问
服务注册与发现:如 Dubbo 使用 ZooKeeper 维护全局服务地址列表
集群管理:监控节点状态,自动处理故障切换
3.优势与局限
优势:简化分布式系统开发,提供高性能(内存存储)和强一致性
局限:不适用于海量数据存储,写性能受集群规模限制
ZooKeeper 通过封装复杂的一致性算法,成为分布式系统的“基础设施”,尤其适用于需要协调与状态同步的场景。
三、Zookeeper安装部署
1.拉取镜像
docker pull zookeeper:3.8

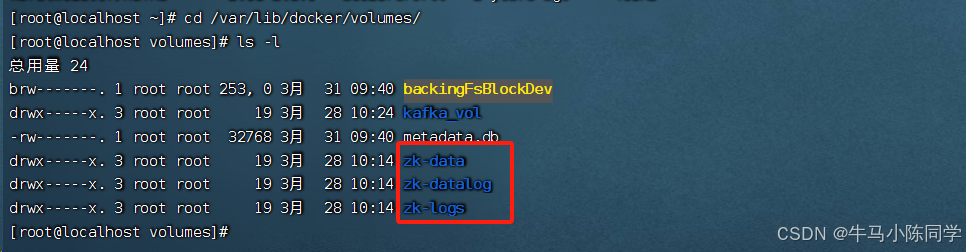
2.创建数据卷
创建数据卷,方便数据持久化
docker volume create zk-data
docker volume create zk-datalog
docker volume create zk-logs
3.创建容器
创建zookeeper-test容器,同时挂载数据卷和并指定端口映射(2181)
docker run -d --name zookeeper-test -p 2181:2181 \--env ZOO_MY_ID=1 \-v zk-data:/data \-v zk-datalog:/datalog \-v zk-logs:/logs \zookeeper:3.8

4.Zookeepe可视化工具-prettyZoo下载和安装
PrettyZoo 是一款基于 Apache Curator 和 JavaFX 开发的开源 Zookeeper 图形化管理客户端,专为简化 Zookeeper 运维设计。其核心功能包括:
多平台支持:提供 Windows(msi)、Mac(dmg)、Linux(deb/rpm)安装包,无需额外安装 Java 运行时即可运行;
可视化操作:支持节点增删改查(CRUD)、实时数据同步、ACL 权限配置、SSH 隧道连接,以及 JSON/XML 数据格式化与高亮显示;
命令行集成:内置终端支持 80% 的 Zookeeper 命令,并可直接执行四字命令(如 stat、ruok 等)监控集群状态;
多集群管理:可同时连接多个 Zookeeper 服务器,支持配置导入导出,提升运维效率。
该工具界面简洁美观,适合开发测试及中小规模环境,大幅降低 Zookeeper 的操作复杂度。
GitHub下载地址
我这里是在windows上下载使用,所以选择windows版本。
安装很简单,傻瓜式安装即可,没有特殊配置。


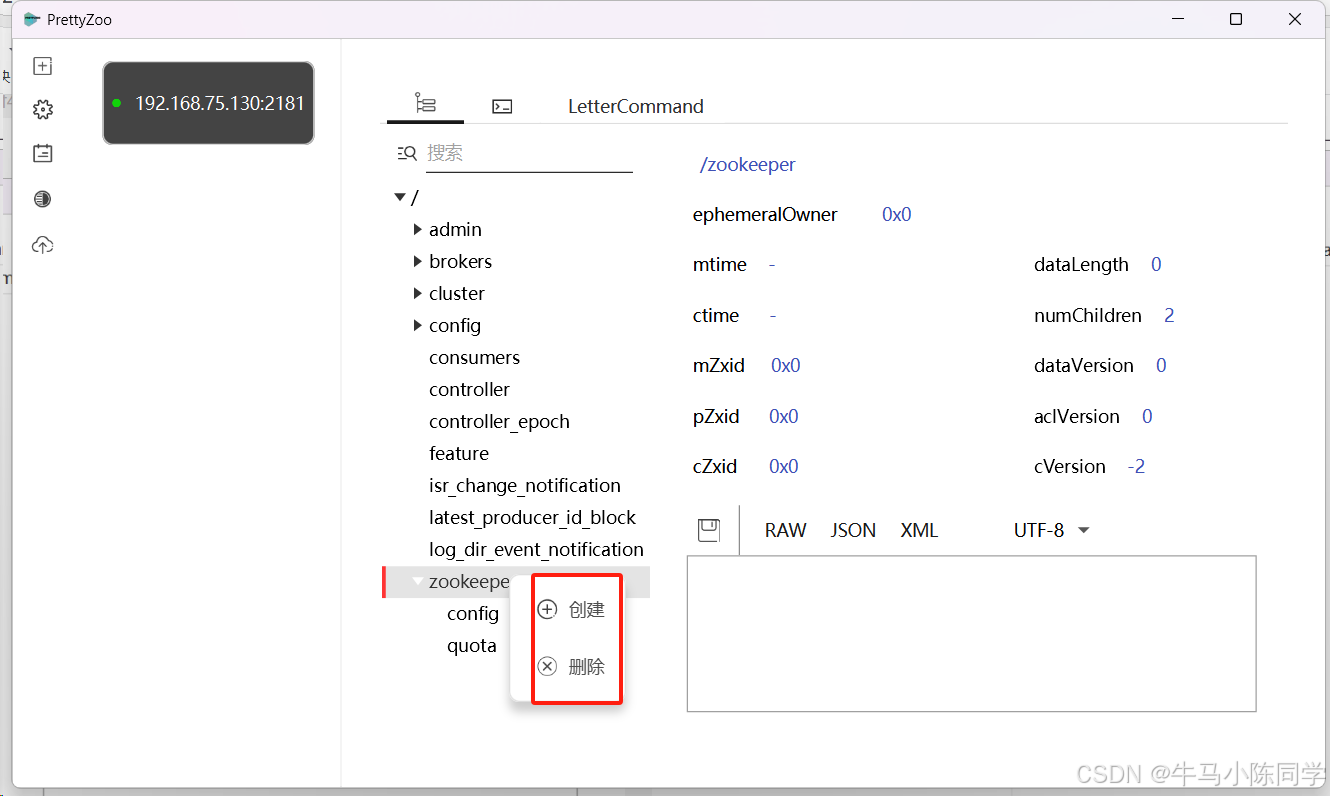
5.prettyZoo使用
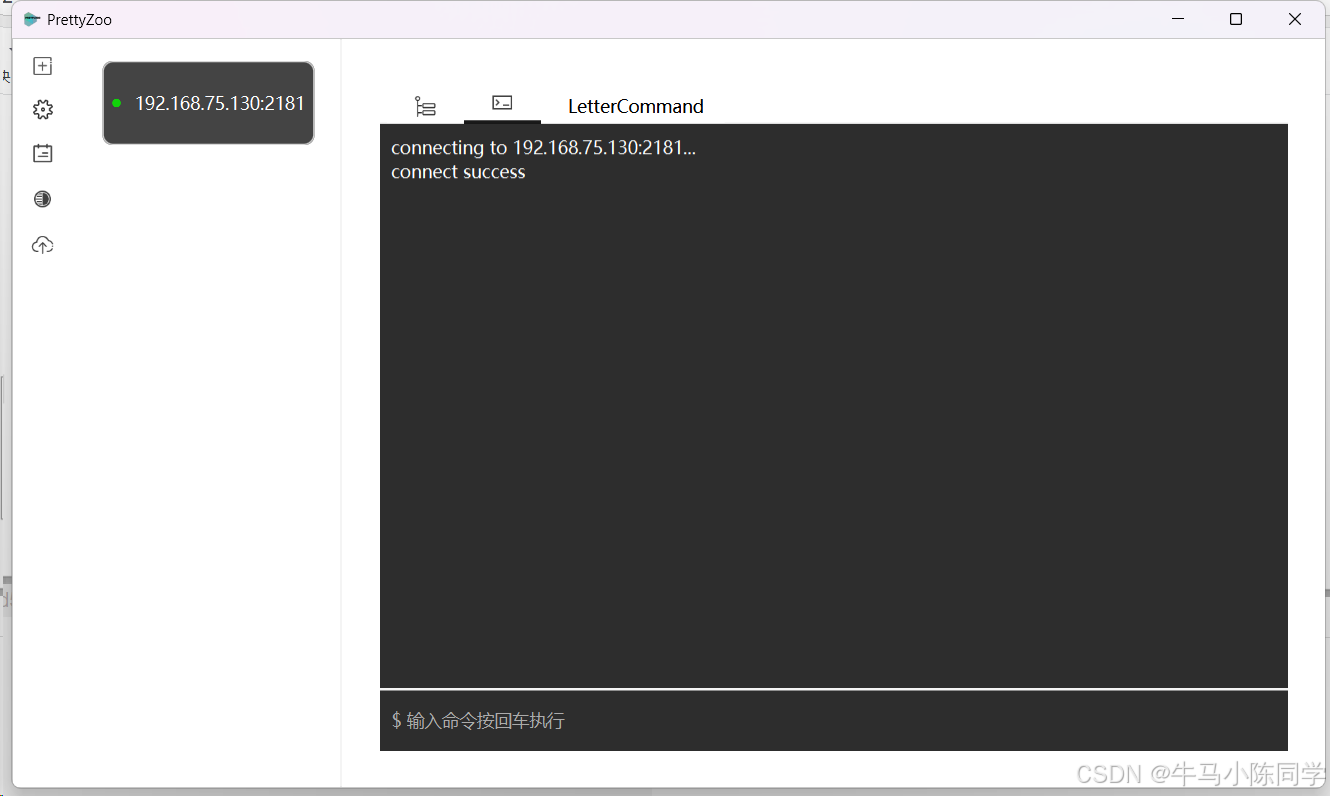
填写IP和端口进行连接。
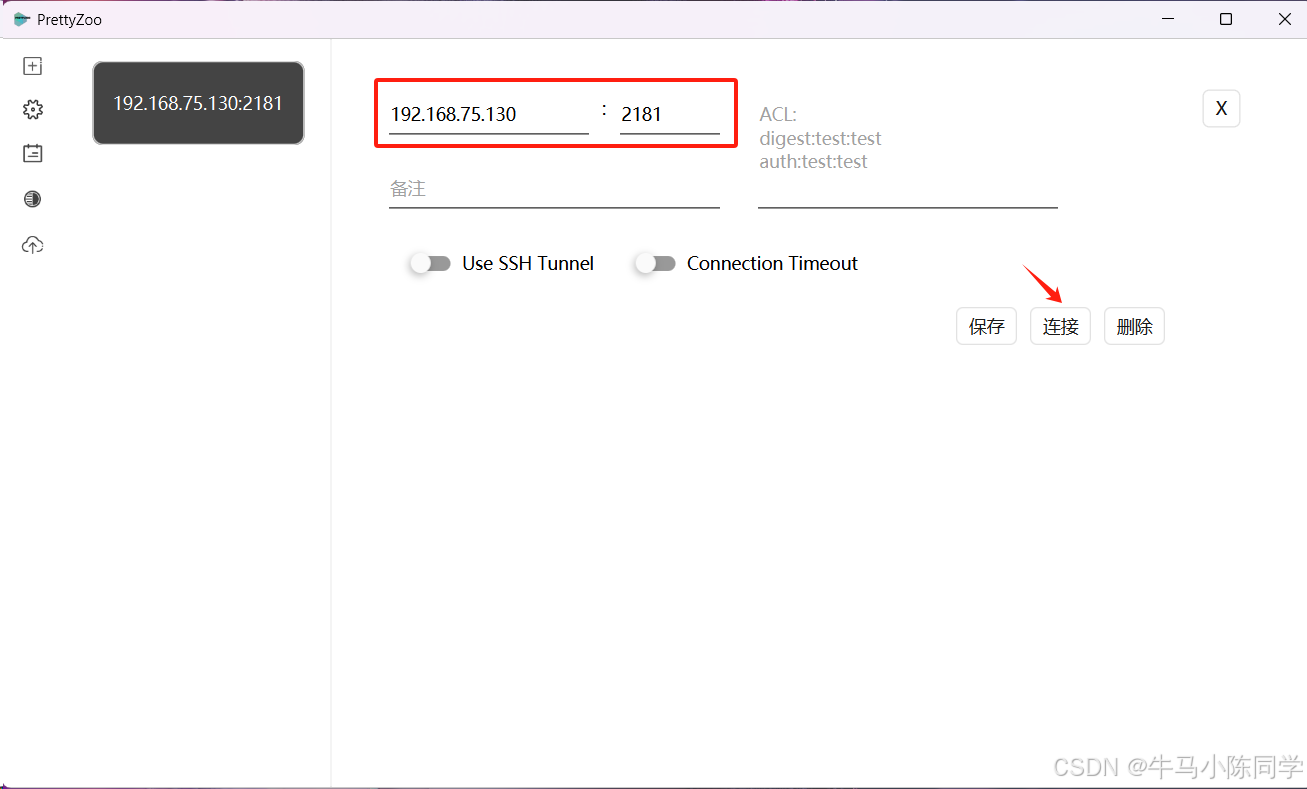
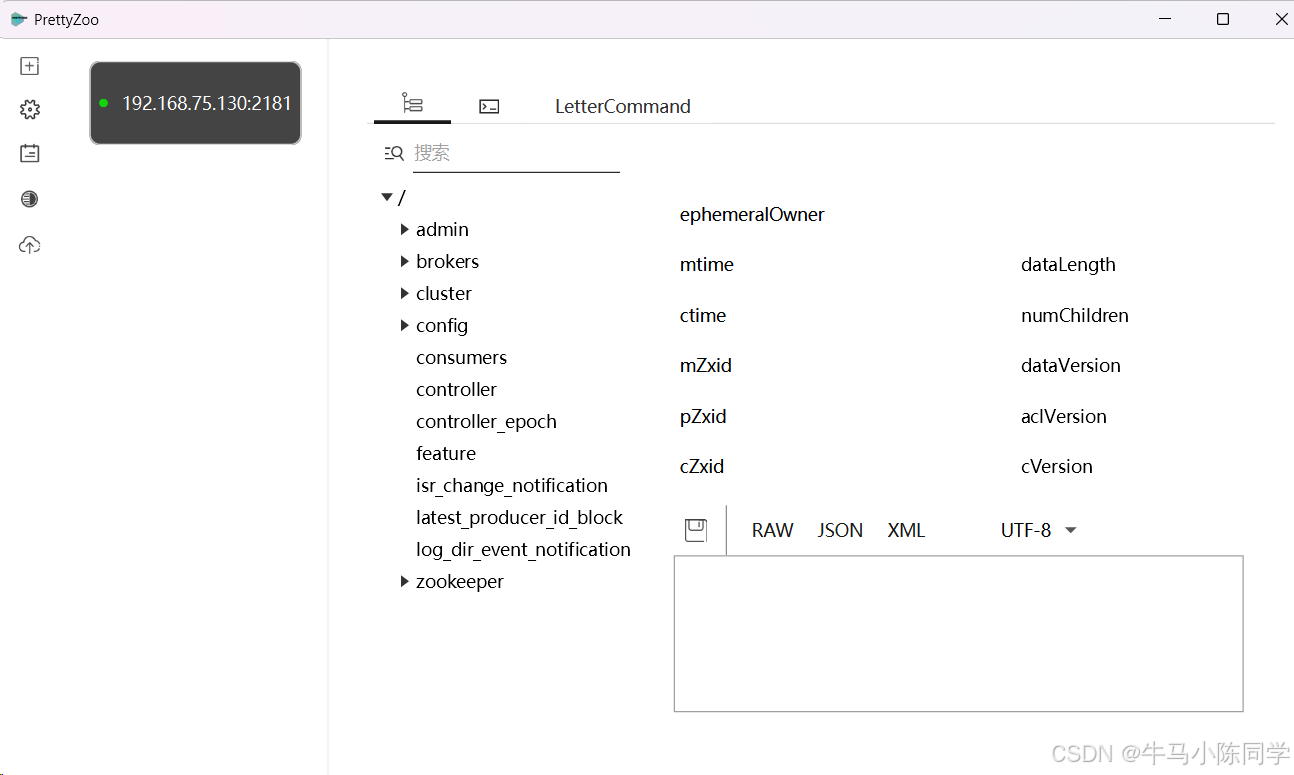
连接成功后,目录结构就能看到了,可以直接在工具上创建和删除节点。还可以编写命令进行操作。工具使用就简单介绍一下,感兴趣的同学可以下载玩一玩。
四、Kafka安装部署
1.拉取镜像
wurstmeister/kafka 适合开发/测试,但生产环境建议使用官方或企业版(如 Confluent)。
2.13-2.8.1 代表Kafka 依赖的 Scala 版本为2.13,kafka自身的版本为2.8.1。
docker pull wurstmeister/kafka:2.13-2.8.1

2.创建数据卷
创建数据卷,方便数据持久化
docker volume create kafka_vol

3.创建容器
创建kafka-test容器,同时挂载数据卷和并指定端口映射(9092),并将zookeeper-test链接到该容器,使Kafka可以成功访问到zookeeper-test,Kafka相关参数通过环境变量(—env)设置。
docker run -d --name kafka-test -p 9092:9092 \
--link zookeeper-test \
--env KAFKA_ZOOKEEPER_CONNECT=zookeeper-test:2181 \
--env KAFKA_ADVERTISED_HOST_NAME=192.168.75.130 \
--env KAFKA_ADVERTISED_PORT=9092 \
--env KAFKA_LOG_DIRS=/kafka/logs \
-v kafka_vol:/kafka \
wurstmeister/kafka:2.13-2.8.1

4.Kakfa可视化操作工具kafka-ui安装
Kafka-UI 是一款开源的 Web 可视化工具,专为管理和监控 Apache Kafka 集群设计,提供轻量、高效的运维体验。它支持多集群统一管理,可实时查看集群状态(如 Broker、Topic、分区和消费者组详情),并支持消息浏览(JSON、纯文本、Avro 格式)。用户可通过界面动态配置 Topic,管理消费者偏移量,并集成数据脱敏、权限控制等功能。其部署灵活,支持 Docker、Kubernetes 等多种方式,适合开发测试及中小规模生产环境,大幅降低 Kafka 的运维复杂度
4.1、拉镜像
docker pull provectuslabs/kafka-ui

4.2、创建容器
docker run -it --name kafka-ui -p 8080:8080 -e DYNAMIC_CONFIG_ENABLED=true provectuslabs/kafka-ui

4.3、访问kafka-ui
访问地址为你部署的服务器地址:http://localhost:8080/ (http://192.168.75.130:8080/)
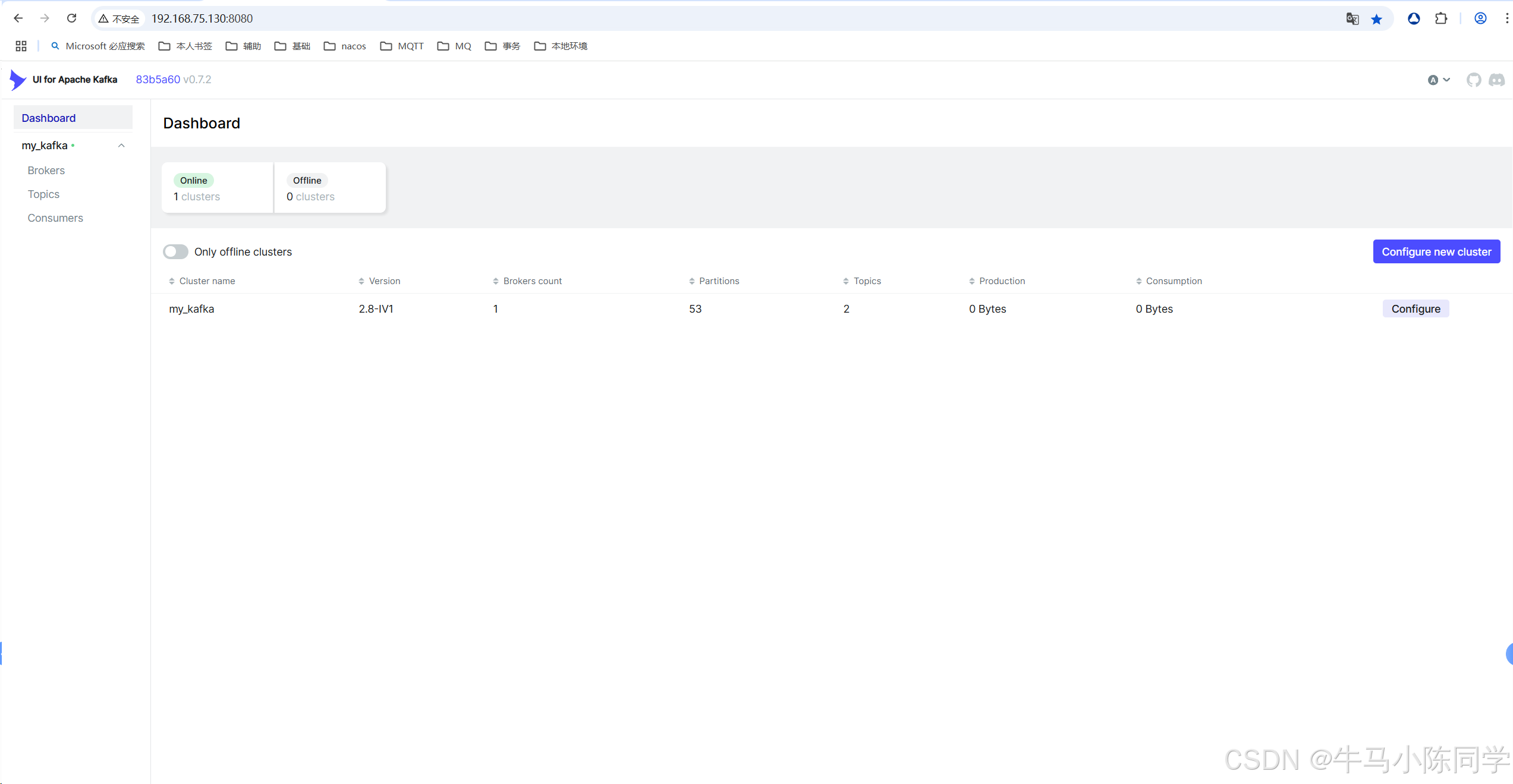
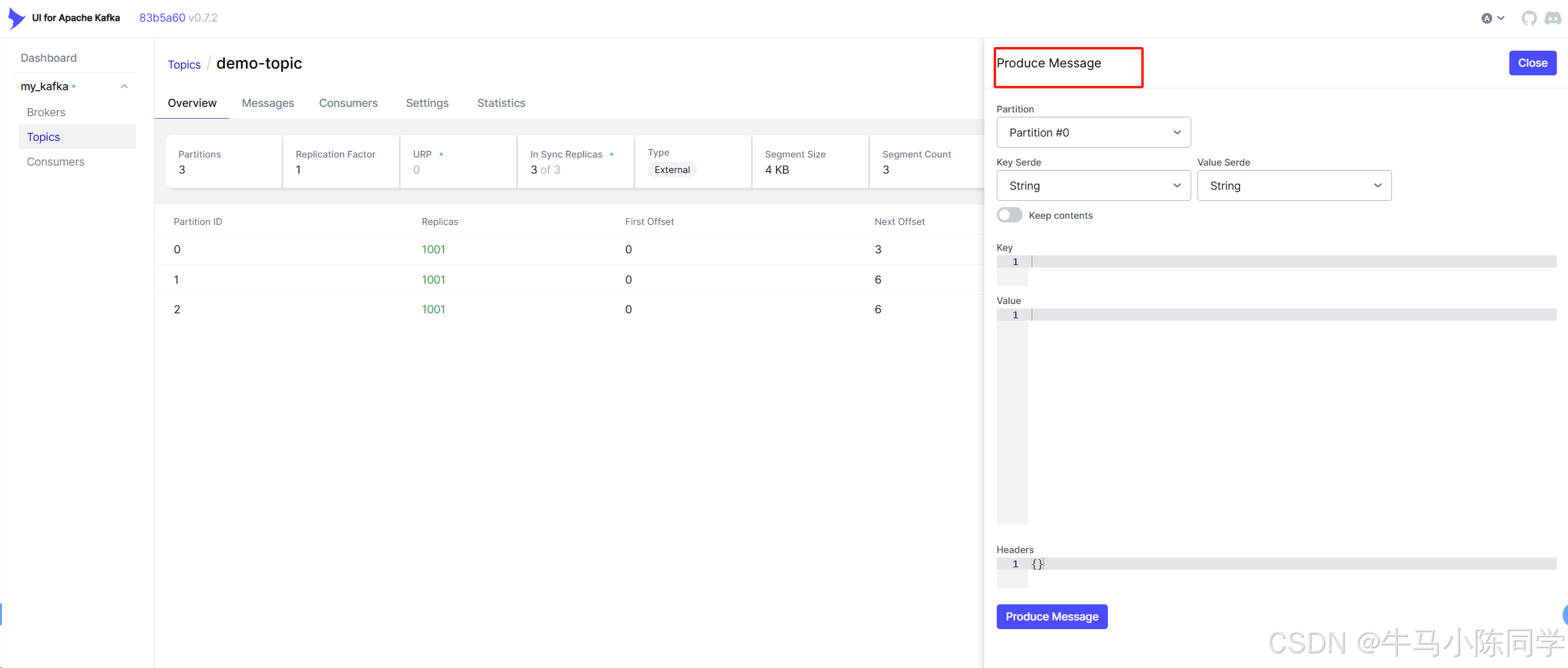
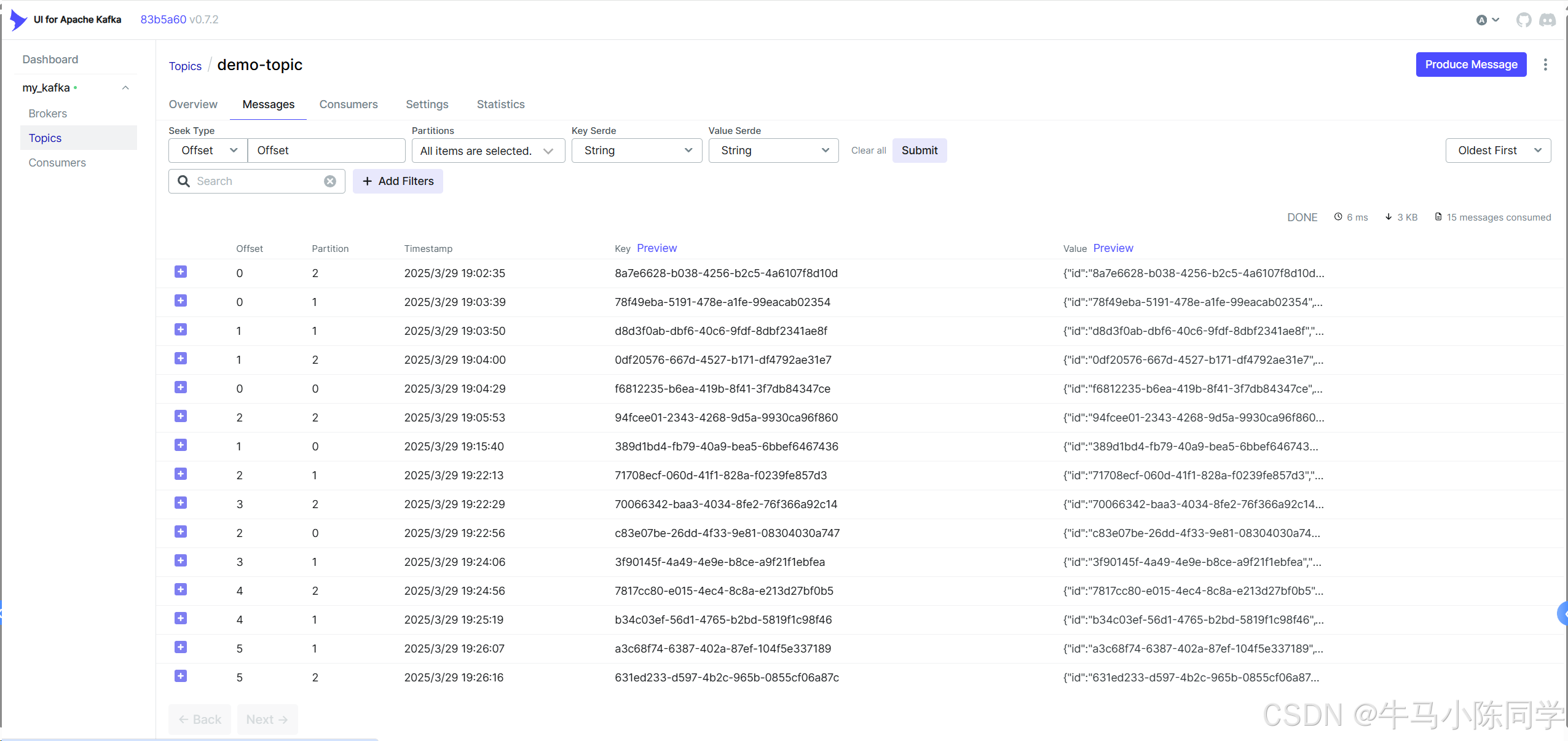
5.Kakfa可视化操作工具kafka-ui使用
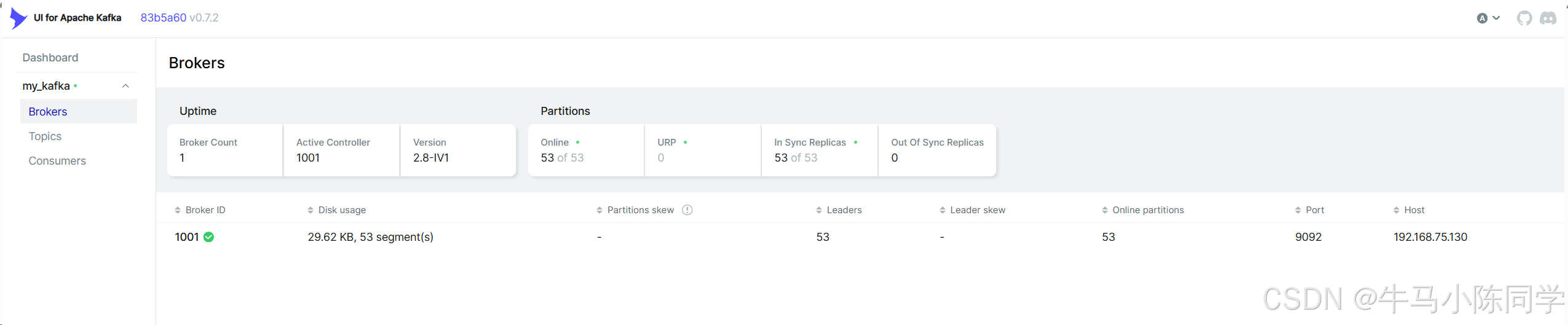
创建连接:

连接后可以查看Brokers、Consumers,可以操作Topics,可以查看消息,也可以模拟Produce生产消息等等。详细操作功能就不再描述了,各位同学可以自行部署尝试。


五、Spring Boot使用Kafka
因为kafka部署的是2.8.1,需要对应Spring boot 2.7.x系列,我这里使用spring boot 2.7.6进行案例。
1.pom文件引入关键jar
<properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><!-- spring boot版本 --><spring-boot.version>2.7.6</spring-boot.version><!-- kafka版本 --><spring-kafka.version>2.8.1</spring-kafka.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!-- Kafka 核心依赖 --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>${spring-kafka.version}</version></dependency><!-- Lombok 简化代码 --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><!-- JSON 序列化支持 --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.13.3</version></dependency></dependencies>
2.yml文件引入配置
spring:kafka:# 集群地址(多个用逗号分隔)bootstrap-servers: 192.168.75.130:9092# 生产者配置producer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.springframework.kafka.support.serializer.JsonSerializerretries: 3 # 失败重试次数acks: all # 确保消息可靠投递batch-size: 16384 # 批量发送优化# 消费者配置consumer:group-id: demo-group # 消费组IDauto-offset-reset: earliestkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.springframework.kafka.support.serializer.JsonDeserializerenable-auto-commit: false # 手动提交偏移量properties:spring.json.trusted.packages: "*" # 允许反序列化任意包# 监听器配置listener:ack-mode: MANUAL # 手动ACKconcurrency: 3 # 消费线程数# 自定义主题名称
kafka:topic:demo: demo-topic3.Topic配置
@Configuration
public class KafkaTopicConfig {@Value("${kafka.topic.demo}")private String demoTopic;@Beanpublic NewTopic demoTopic() {return TopicBuilder.name(demoTopic)// 分区数.partitions(3)// 副本数.replicas(1).config(TopicConfig.RETENTION_MS_CONFIG, "604800000") // 保留7天.build();}
}
4.消息体创建
@Data
@AllArgsConstructor
@NoArgsConstructor
public class DemoMessage {private String id;// 内容private String content;// 时间戳private LocalDateTime timestamp;
}5.Producer实现
@Slf4j
@Service
public class KafkaProducerService {private final KafkaTemplate<String, Object> kafkaTemplate;@Autowiredpublic KafkaProducerService(KafkaTemplate<String, Object> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}// 发送消息(支持回调)public void sendMessage(String topic, DemoMessage message) {// 普通发送消息(支持回调)kafkaTemplate.send(topic, message.getId(), message).addCallback(success -> {if (success != null) {log.info("发送成功: Topic={}, Offset={}",success.getRecordMetadata().topic(),success.getRecordMetadata().offset());}},ex -> log.error("发送失败: {}", ex.getMessage()));// 事务性发送消息(支持回调)
// kafkaTemplate.executeInTransaction(operations -> {
// operations.send(topic, message.getId(), message)
// .addCallback(
// success -> {
// if (success != null) {
// log.info("发送成功: Topic={}, Offset={}",
// success.getRecordMetadata().topic(),
// success.getRecordMetadata().offset());
// }
// },
// ex -> log.error("发送失败: {}", ex.getMessage())
// );
// return true;
// });}
}
6.Consumer实现
@Slf4j
@Service
public class KafkaConsumerService {@KafkaListener(topics = "${kafka.topic.demo}", groupId = "demo-group")public void consumeMessage(@Payload DemoMessage message, Acknowledgment ack) {try {log.info("收到消息: Content={}", message.getContent());// 幂等处理if (isMessageProcessed(message.getId())) {log.warn("消息已处理: ID={}", message.getId());ack.acknowledge();return;}// 业务处理// ...// 手动提交偏移量ack.acknowledge();} catch (Exception e) {log.error("处理异常: {}", e.getMessage());}}private boolean isMessageProcessed(String messageId) {// 实现幂等检查(如查数据库)return false;}
}
7.启动类配置
@EnableKafka
@SpringBootApplication
public class MyKafkaApplication {public static void main(String[] args) {SpringApplication.run(MyKafkaApplication.class, args);}}8.Controller测试发送
@RestController
@RequestMapping("/kafka")
public class kafakTestController {@Autowiredprivate KafkaProducerService producerService;@RequestMapping("/sendMessage")public String sendMessage(@RequestParam(value = "message") String message) {DemoMessage message1 = new DemoMessage(UUID.randomUUID().toString(),message,LocalDateTime.now());producerService.sendMessage("demo-topic", message1);return "消息发送成功!";}
}
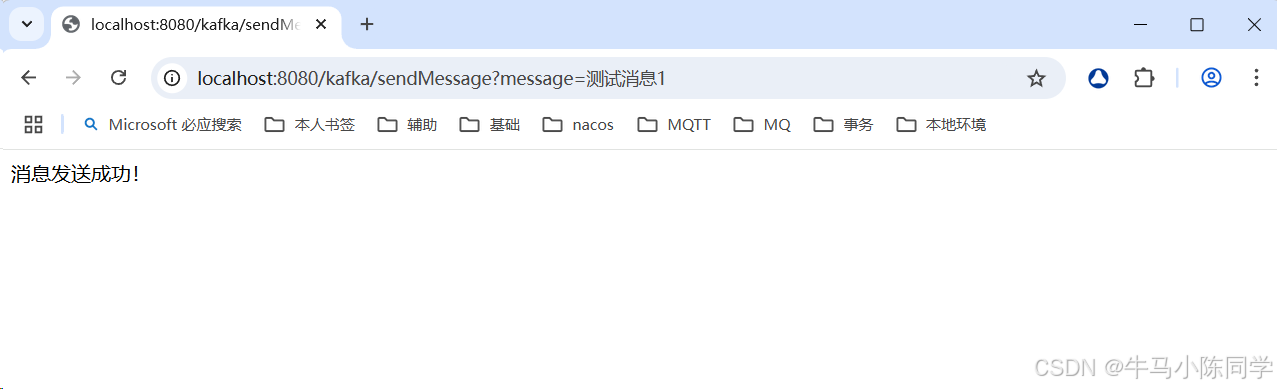
9.测试验证
模拟生产者生产消息,验证生产者和消费者是否正常工作。测试可用。

总结
总结了kafka使用的完整教程,加强一下自己对于kafka的整体概念,给想使用kafka的同学们入个门。
相关文章:
Kafka+Zookeeper从docker部署到spring boot使用完整教程
文章目录 一、Kafka1.Kafka核心介绍:核心架构核心特性典型应用 2.Kafka对 ZooKeeper 的依赖:3.去 ZooKeeper 的演进之路:注:(本文采用ZooKeeper3.8 Kafka2.8.1) 二、Zookeeper1.核心架构与特性2.典型…...
RK3568驱动 SPI主/从 配置
一、SPI 控制器基础配置(先说主的配置,后面说从的配置) RK3568 集成高性能 SPI 控制器,支持主从双模式,最高传输速率 50MHz。设备树配置文件路径通常为K3568/rk356x_linux_release_v1.3.1_20221120/kernel/arch/arm64/boot/dts/rockchip。 …...

【全队项目】智能学术海报生成系统PosterGenius--风格个性化调整
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏🏀大模型实战训练营 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 1.前言 PosterGenius致力于开发一套依托DeepSeek…...
【系统移植】(六)第三方驱动移植
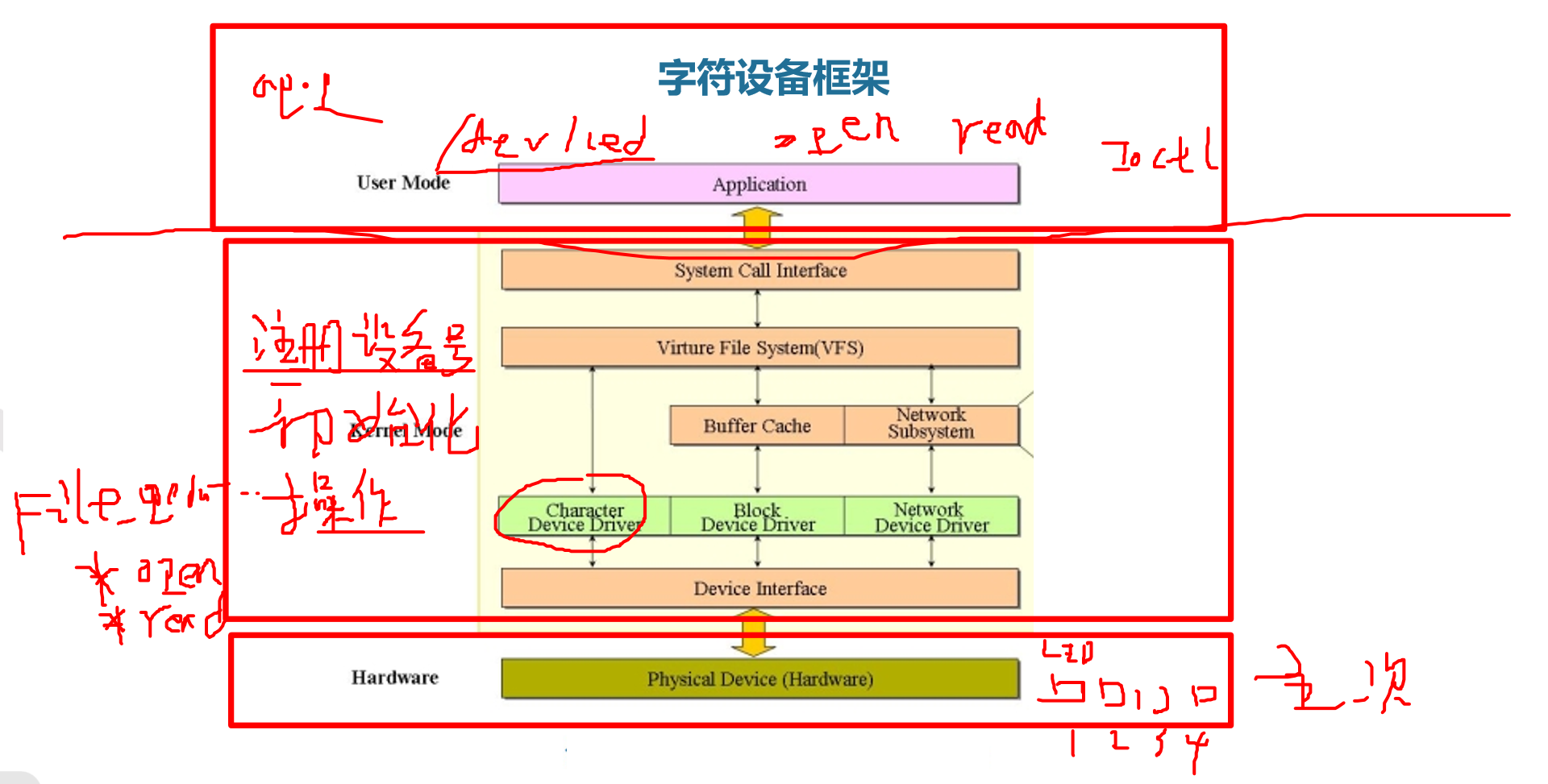
【系统移植】(六)第三方驱动移植 文章目录 【系统移植】(六)第三方驱动移植1.编译驱动进内核方法一:编译makefile方法二:编译kconfig方法三:编译成模块 2.字符设备框架 编译驱动进内核a. 选择驱…...
STM32实现一个简单电灯
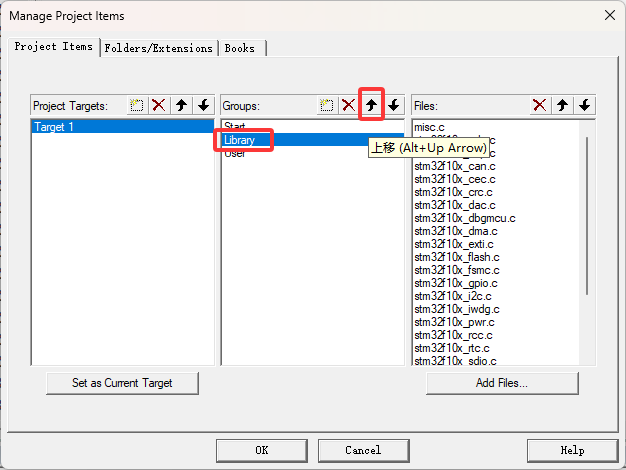
新建工程的步骤 建立工程文件夹,Keil中新建工程,选择型号工程文件夹里建立Start、Library、User等文件夹,复制固件库里面的文件到工程文件夹工程里对应建立Start、Library、User等同名称的分组,然后将文件夹内的文件添加到工程分组…...

【shiro】shiro反序列化漏洞综合利用工具v2.2(下载、安装、使用)
1 工具下载 shiro反序列化漏洞综合利用工具v2.2下载: 链接:https://pan.baidu.com/s/1kvQEMrMP-PZ4K1eGwAP0_Q?pwdzbgp 提取码:zbgp其他工具下载: 除了该工具之外,github上还有其他大佬贡献的各种工具,有…...
vue进度条组件
<div class"global-mask" v-if"isProgress"><div class"contentBox"><div class"progresstitie">数据加载中请稍后</div><el-progress class"progressStyle" :color"customColor" tex…...
:矩阵加减法与SIMD集成)
【C++游戏引擎开发】《线性代数》(2):矩阵加减法与SIMD集成
一、矩阵加减法数学原理 1.1 定义 逐元素操作:运算仅针对相同位置的元素,不涉及矩阵乘法或行列变换。交换律与结合律: 加法满足交换律(A + B = B + A)和结合律( ( A + B ) + C = A + ( B + C ) )。 减法不满足交换律(A − B ≠ B − A)。1.2 公式 C i j = …...

UE5Actor模块源码深度剖析:从核心架构到实践应用
UE5 Actor模块源码深度剖析:从核心架构到实践应用 a. UE5 Actor模块架构概述 在UE5引擎中,Actor扮演着至关重要的角色,它是整个游戏世界中各类可交互对象的基础抽象。从本质上来说,所有能够被放置到关卡中的对象都属于Actor的范畴,像摄像机、静态网格体以及玩家起始位置…...

【3.软件工程】3.6 W开发模型
W模型全解析:开发与测试并行的质量保障框架 ⚡ 一、W模型核心流程图 #mermaid-svg-YfU8WQvqa6iDUKz3 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-YfU8WQvqa6iDUKz3 .error-icon{fill:#552222;}#merm…...

基于大模型的主动脉瓣病变预测及治疗方案研究报告
目录 一、引言 1.1 研究背景 1.2 研究目的 1.3 研究意义 二、大模型预测主动脉瓣病变原理 2.1 大模型介绍 2.2 数据收集与处理 2.3 模型训练与优化 三、术前预测与评估 3.1 主动脉瓣病变类型及程度预测 3.2 患者整体状况评估 3.3 手术风险预测 四、术中应用与监测…...

CSRF跨站请求伪造——入门篇【DVWA靶场low级别writeup】
CSRF跨站请求伪造——入门篇 0. 前言1. 什么是CSRF2. 一次完整的CSRF攻击 0. 前言 本文将带你实现一次完整的CSRF攻击,内容较为基础。需要你掌握的基础知识有: 了解cookie;已经安装了DVWA的靶场环境(本地的或云的)&am…...
)
拦截、限流,针对场景详细信息(一)
以下是一个基于Java Spring Boot Redis 的完整限流实现案例,针对同一接口前缀(如 /one/ )的IP访问频率控制: 场景:用户不用登录即可访问接口,网站会有被攻击的风险 URL:one/two/three one/…...

Qt基础:主界面窗口类QMainWindow
QMainWindow 1. QMainWindow1.1 菜单栏添加菜单项菜单项信号槽 1.2 工具栏添加工具按钮工具栏的属性设置 1.3 状态栏1.4 停靠窗口(Dock widget) 1. QMainWindow QMainWindow是标准基础窗口中结构最复杂的窗口, 其组成如下: 提供了菜单栏, 工具栏, 状态…...

第十四届蓝桥杯大赛软件赛省赛Python 研究生组:4.互质数的个数
题目1 互质数的个数 给定 a,b,求 1≤x<ab 中有多少个 x 与 ab 互质。 由于答案可能很大,你只需要输出答案对 998244353 取模的结果。 输入格式 输入一行包含两个整数分别表示 a,b,用一个空格分隔。 输出格式 输出一行包含一个整数表…...
32f4,usart2fifo,2025
usart2fifo.h #ifndef __USART2FIFO_H #define __USART2FIFO_H#include "stdio.h" #include "stm32f4xx_conf.h" #include "sys.h" #include "fifo_usart2.h"//extern u8 RXD2_TimeOut;//超时检测//extern u8 Timer6_1ms_flag;exte…...
激光模拟单粒子效应试验如何验证CANFD芯片的辐照阈值?
在现代航天电子系统中,CANFD(Controller Area Network with Flexible Data-rate)芯片作为关键的通信接口元件,其可靠性与抗辐射性能直接关系到整个系统的稳定运行。由于宇宙空间中存在的高能粒子辐射,芯片可能遭受单粒…...
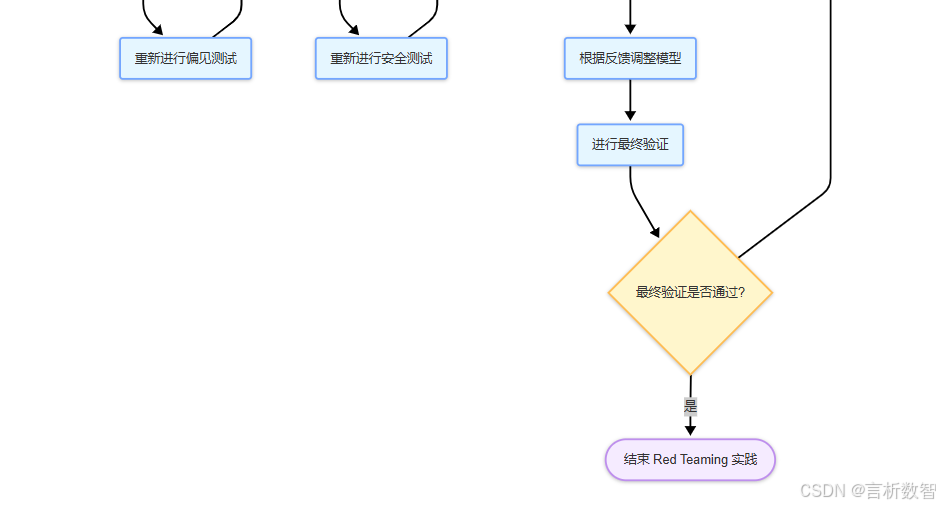
从零构建大语言模型全栈开发指南:第五部分:行业应用与前沿探索-5.2.1模型偏见与安全对齐(Red Teaming实践)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 大语言模型全栈开发指南:伦理与未来趋势 - 第五部分:行业应用与前沿探索5.2.1 模型偏见与安全对齐(Red Teaming实践)一、模型偏见的来源与影响1. 偏见的定义与分类2. 偏见的实际影响案例二、安全对齐…...
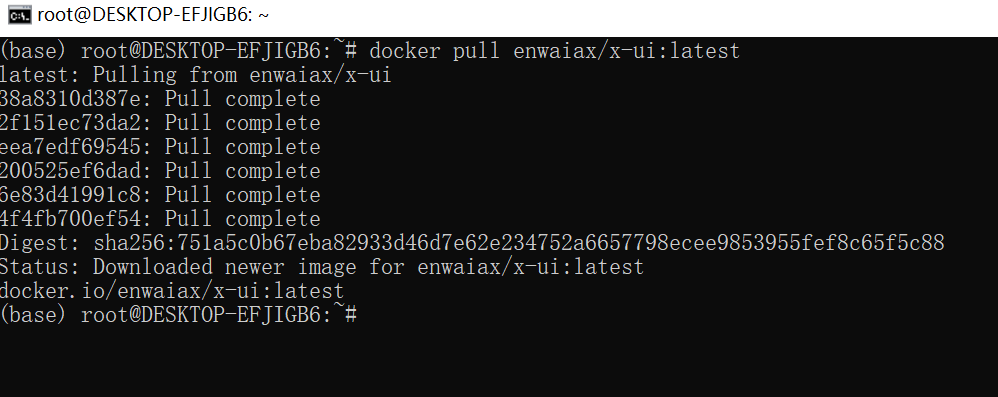
Docker安装开源项目x-ui详细图文教程
本章教程,主要介绍如何使用Docker部署开源项目x-ui 详细教程。 一、拉取镜像 docker pull enwaiax/x-ui:latest二、运行容器 mkdir x-ui && cd x-ui docker run -itd --network=host \-v $PWD<...

检索增强生成(RAG) 优化策略
检索增强生成(RAG) 优化策略篇 一、RAG基础功能篇 1.1 RAG 工作流程 二、RAG 各模块有哪些优化策略?三、RAG 架构优化有哪些优化策略? 3.1 如何利用 知识图谱(KG)进行上下文增强? 3.1.1 典型RAG架构中,向…...
)
Educational Codeforces Round 172 (Rated for Div. 2)
AB略 C 答案没有单调性,无法用二分答案写。b比a多的得分s1*0s2*1.......sn*(n-1),s代表这一段中b比a多的数量。这里s的处理可以想到用前缀和来,于是得到(s1-0)*0(s2-s1)*1(s3-s2)*2......(sn-sn-1)*(n-1)-s1-s2-s3.....sn*(n-1),…...

前端:v-html和v-text在使用上的区别
v-html 和 v-text 在 Vue 中的核心区别如下: 一、解析机制 v-text 将数据作为纯文本渲染,不解析 HTML 标签。 例如数据 <strong>Hello</strong> 会直接输出为字符串 <strong>Hello</strong>。v-html 将数据解析为…...

【面试篇】Kafka
一、基础概念类 问题:请简述 Kafka 是什么,以及它的主要应用场景有哪些? 答案:Kafka 是一个分布式流处理平台,它以高吞吐量、可持久化、可水平扩展等特性而闻名。其主要应用场景包括: 日志收集:…...
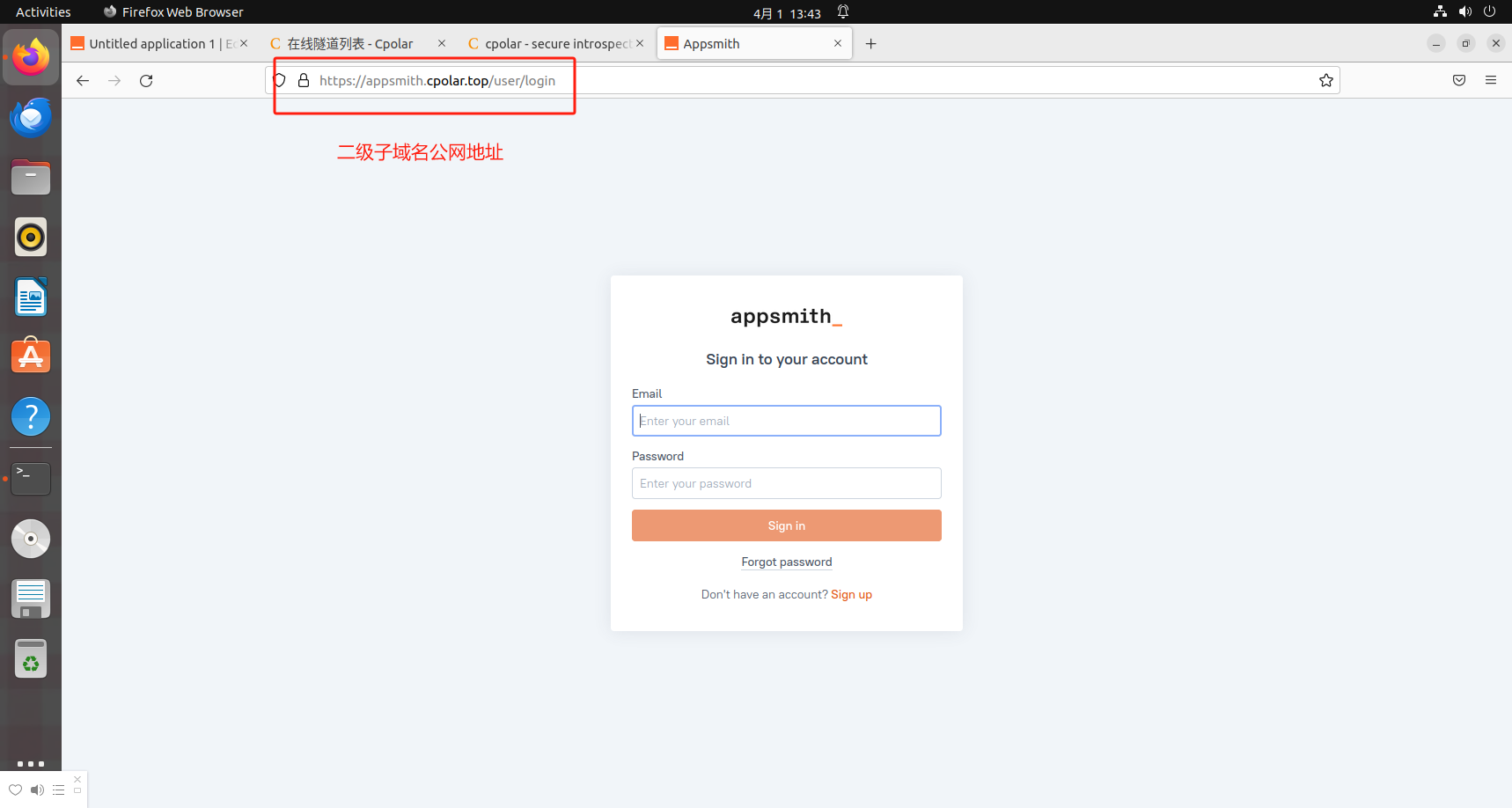
零基础玩转树莓派5!从系统安装到使用VNC远程控制树莓派桌面实战
文章目录 前言1.什么是Appsmith2.Docker部署3.Appsmith简单使用4.安装cpolar内网穿透5. 配置公网地址6. 配置固定公网地址总结 前言 你是否曾因公司内部工具的开发周期长、成本高昂而头疼不已?或是突然灵感爆棚想给团队来点新玩意儿,却苦于没有专业的编…...

SAP CEO引领云端与AI转型
在现任首席执行官克里斯蒂安克莱因(Christian Klein)的领导下,德国软件巨头 SAP 正在经历一场深刻的数字化转型,重点是向云计算和人工智能方向发展。他提出的战略核心是“RISE with SAP”计划,旨在帮助客户从传统本地部…...

【MyBatis】深入解析 MyBatis:关于注解和 XML 的 MyBatis 开发方案下字段名不一致的的查询映射解决方案
注解查询映射 我们再来调用下面的 selectAll() 这个接口,执行的 SQL 是 select* from user_info,表示全列查询: 运行测试类对应方法,在日志中可以看到,字段名一致,Mybatis 就成功从数据库对应的字段中拿到…...

图像退化对目标检测的影响 !!
文章目录 引言 1、理解图像退化 2、目标检测中的挑战 3、应对退化的自适应方法 4、新兴技术与研究方向 5、未来展望 6、代码 7、结论 引言 在计算机视觉领域,目标检测是一项关键任务,它使计算机能够识别和定位数字图像中的物体。这项技术支撑着从自动驾…...

《AI大模型应知应会100篇》第57篇:LlamaIndex使用指南:构建高效知识库
第57篇:LlamaIndex使用指南:构建高效知识库 摘要 在大语言模型(LLM)驱动的智能应用中,如何高效地管理和利用海量知识数据是开发者面临的核心挑战之一。LlamaIndex(原 GPT Index) 是一个专为构建…...

目标检测中COCO评估指标中每个指标的具体含义说明:AP、AR
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...

鸿蒙应用元服务开发-Account Kit概述
Account Kit(华为账号服务)提供简单、快速、安全的登录功能,让用户快捷地使用华为账号登录元服务。用户授权后,Account Kit可提供头像、手机号码等信息,帮助元服务更了解用户。Account Kit提供的SampleCode示例工程体现…...